渗透测试
开发板评测
零基础python教程
web
labview
ux
开发板
测试工具
GFCTF2022
ps
skill
时间
Junit常用注解
知识计算
安卓毕设
贵州茅台
倍福
onnx
MBP
路径规划
flink
2024/4/11 15:00:03
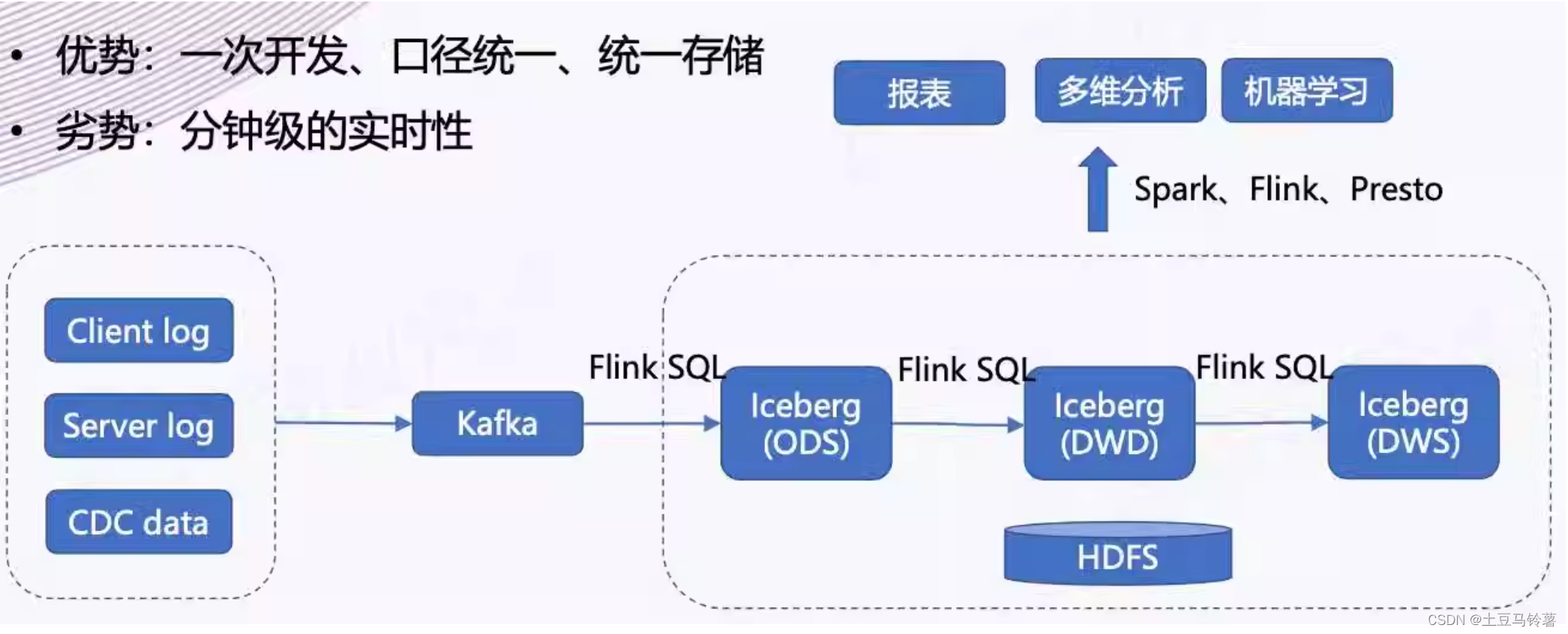
计算机毕业设计之Spark+Flink+Python考研预测分析 考研院校推荐系统 考研大数据分析大屏
功能
1 协同过滤
这边由于学校内的专业分数信息不全,所以推荐出来学校,下面可能是看不到专业的分数信息的。
2 大屏
基于spark和flink的实现,flink是 kaoyan-flink 项目运行后会把统计结果存在mysql中, 然后kaoyan-server 项目…

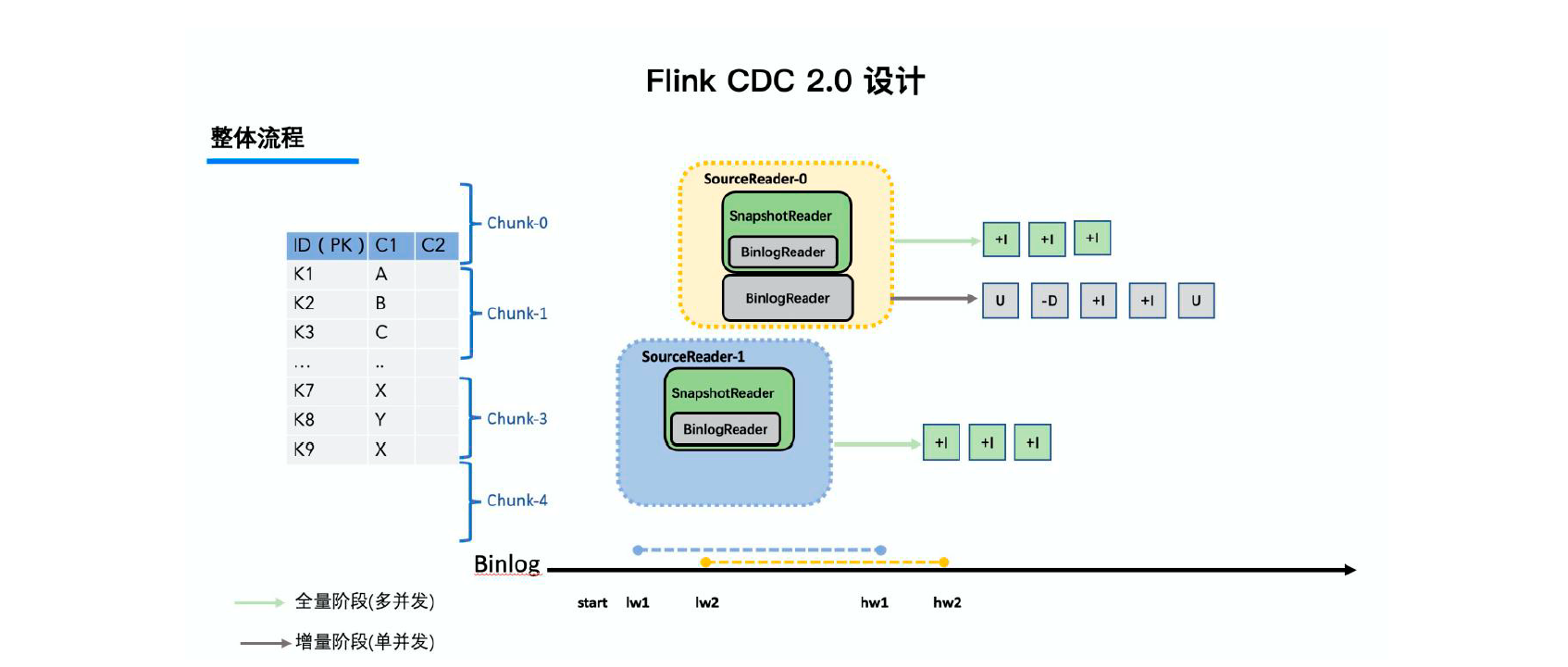
【flink】cdc 1.x 分析
不足与疑问
直至flink cdc 2.3,只有mysql全面支持了无锁的增量快照和动态加表等高级特性,有部分其它connector也集成了增量快照框架,很遗憾准备使用的postgres还停留在1.x,都知道1.x有很多使用限制,例如: …

手推FlinkML2.2(一)
Java
快速入门 # 本文档提供了一个关于如何使用Flink ML的快速入门。阅读本文档的用户将被指导提交一个简单的Flink作业,用于训练机器学习模型并提供预测服务。
求助,我卡住了!# 如果你遇到困难,请查看社区支持资源。特别是&…
Flink / Scala - 6.WatermarkStrategy 与 EventTime 生成详解
一.引言
Flink 提供三种时间机制,分别是 EventTime、ProcessingTime、IngestionTime: 时间机制时间语义EventTime事件发生时间,其包含在源数据 T 中,即 DataStream[T] 中的每个元素ProcessingTime执行机器的系统时间,可能受执行机器的 ClockTime 影响IngestionTime事件进…

【Apache Flink】基于时间和窗口的算子-配置时间特性
文章目录 前言配置时间特性将时间特性设置为事件时间时间戳分配器周期性水位线分配器创建一个实现AssignerWithPeriodicWatermarks接口的类,目的是为了周期性生成watermark 定点水位线分配器示例 参考文档 前言 Apache Flink 它提供了多种类型的时间和窗口概念&…

flink 反压原理
背景
在flink中由于数据倾斜或者数据处理速率的不匹配,很容易引起反压,本文就看一下flink反压的原理
flink反压原理
flink全流程pineline的反压实现其实依赖于TaskManager之间的反压和TaskManager内部的反压来实现
1.TaskManager之间的反压
2.Task…
【开发篇】一、处理函数:定时器与定时服务
文章目录 1、基本处理函数2、定时器和定时服务3、KeyedProcessFunction下演示定时器4、process重获取当前watermark 前面API篇完结,对数据的转换、聚合、窗口等,都是基于DataStream的,称DataStreamAPI,如图:
在Flink…
【Flink实战系列】Flink 是如何实现 exactly-once 语义的
Flink跟其他的流计算引擎相比,最突出或者做的最好的就是状态的管理.什么是状态呢?比如我们在平时的开发中,需要对数据进行count,sum,max等操作,这些中间的结果(即是状态)是需要保存的,因为要不断的更新,这些值或者变量就可以理解为是一种状态,拿读取kafka为例,我们需要记录数据…
Flink 1.入门Demo详解
一.引言:
Apach Flink 是全新的流处理系统,在Spark Straming的基础上添加了很多特性,主要在于其提供了基于时间和窗口计算的算子,并且支持有状态的存储和 Checkpoint 的重启机制,下面假设有多个温度传感器持续传输当前温度,Flink流处理需要每一段时间提供该时间段内的传…
flink之addSource fromSource 、addSink SinkTo
一、addSource & fromSource 、addSink & SinkTo 这两组算子区别在于:addSource和addSink需要自己实现SourceFunction或者是SinkFunction,其中读取数据的逻辑,容错等都需要自己实现;fromSource和SinkTo,是flin…
Flink CDC学习笔记
第一章 CDC简介
1.1 什么是CDC
CDC (Change Data Capture 变更数据获取)的简称。核心思想就是,检测并获取数据库的变动(增删查改),将这些变更按发生的顺序记录下来,写入到消息中间件以供其它服务进行订…
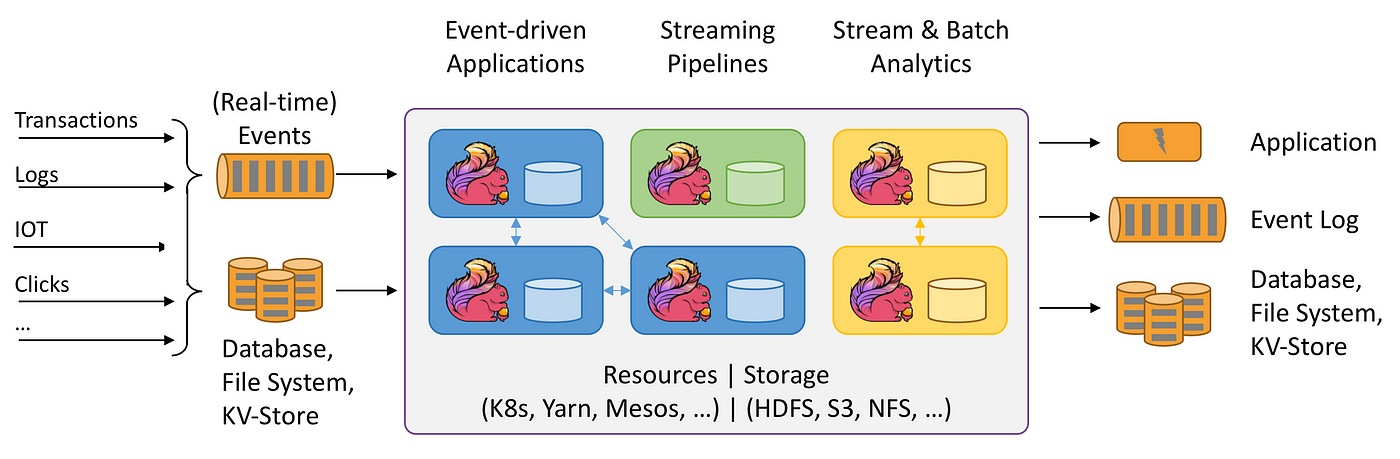
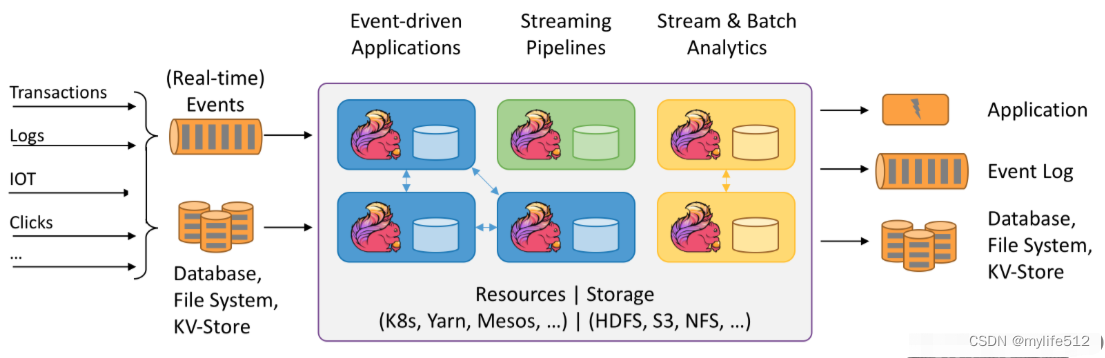
Flink学习笔记(一):Flink重要概念和原理
文章目录 1、Flink 介绍2、Flink 概述3、Flink 组件介绍3.1、Deploy 物理部署层3.2、Runtime 核心层3.3、API&Libraries 层3.4、扩展库 4、Flink 四大基石4.1、Checkpoint4.2、State4.3、Time4.4、Window 5、Flink 的应用场景5.1、Event-driven Applications【事件驱动】5.…
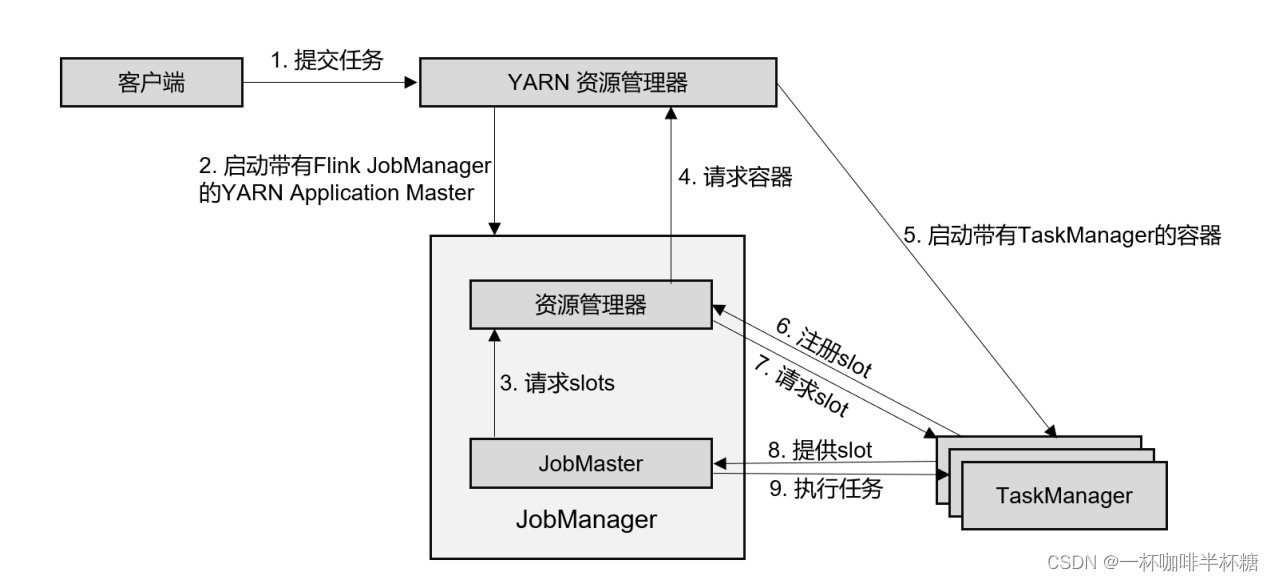
【Flink】Flink提交流程
我们通常在学习的时候需要掌握大数据组件的原理以便更好的掌握这个大数据组件,Flink实际生产开发过程中最常见的就是提交到yarn上进行调度,模式使用的Per-Job模式,下面我们就给大家讲下Flink提交Per-Job任务到yarn上的流程,流程图…
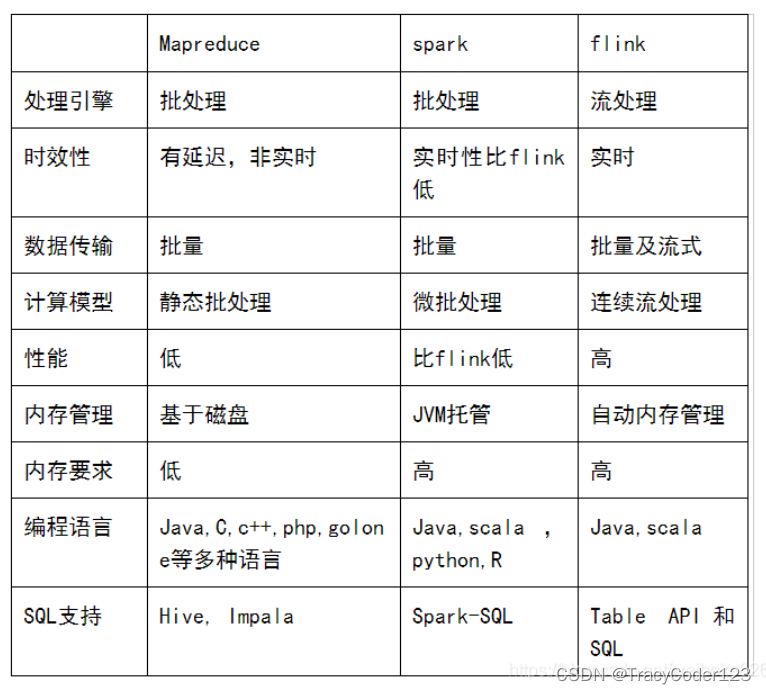
Flink-两阶段提交(two-phase-commit,2PC)
前面提到的各种实现exactly-once的方式,多少都有点缺陷;而更好的方法就是传说中的两阶段提交(2PC)。
顾名思义,它的想法是分成两个阶段:先做“预提交”,等检查点完成之后再正式提交。这种提交方…

Flink日志收集到数据库/kafka
引言
我们做项目过程中发现flink日志不同模式启动,存放位置不同,查找任务日志很不方便,具体问题如下:
原始flink的日志配置文件log4j-cli.properties appender.file.append false,取消追加,直接覆盖掉上…
flink1.18.0 自适应调度器 资源弹性缩放 flink帮你决定并行度
jobmanager.scheduler Elastic Scaling | Apache Flink 配置文件修改并重启flink后,webui上会显示调整并行度的按钮,他可以自己调整,你也可以通过webUI手动调整: 点击 之后: 调整完成后:
【实战-08】flink DataStream 如何实现去重
摘要
假设我们有一批订单数据实时接入kafka, flink需要对订单数据做处理,值得注意的是订单数据 要求绝对不可以重复处理。 考虑到订单数据上报到kafka的时候存在重复上报的可能性,因此需要我们flink处理的时候 避免进行重复处理。在flinksql 中我们有去…
Flink: Only supported for operators
Exception in thread "main" java.lang.UnsupportedOperationException: Only supported for operators.at org.apache.flink.streaming.api.scala.DataStream.name(
【实战-08】flink 消费kafka自定义序列化
目的
让从kafka消费出来的数据,直接就转换成我们的对象
mvn pom
<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
…
Flink使用Log4j将日志发送到Kafka
文章目录背景自定义KafkaAppenderlog4j.properties配置文件修改启动命令指定配置文件在Kafka中消费数据格式字段说明一键应用参考链接背景
Flink版本:1.14.3
自定义KafkaAppender
可以在自己项目中自定义这个类,也可以将该类打成Jar包方式引用
/*** …
Flink 学习七 Flink 状态(flink state)
Flink 学习七 Flink 状态(flink state)
1.状态简介
流式计算逻辑中,比如sum,max; 需要记录和后面计算使用到一些历史的累计数据,
状态就是:用户在程序逻辑中用于记录信息的变量
在Flink 中 ,状态state 不仅仅是要记录状态;在程序运行中如果失败,是需要重新恢复,所以这个状态…

flink的window和windowAll的区别
背景
在flink的窗口函数运用中,window和windowAll方法总是会引起混淆,特别是结合上GlobalWindow的组合时,更是如此,本文就来梳理下他们的区别和常见用法
window和windowAll的区别
window是KeyStream数据流的方法,其…
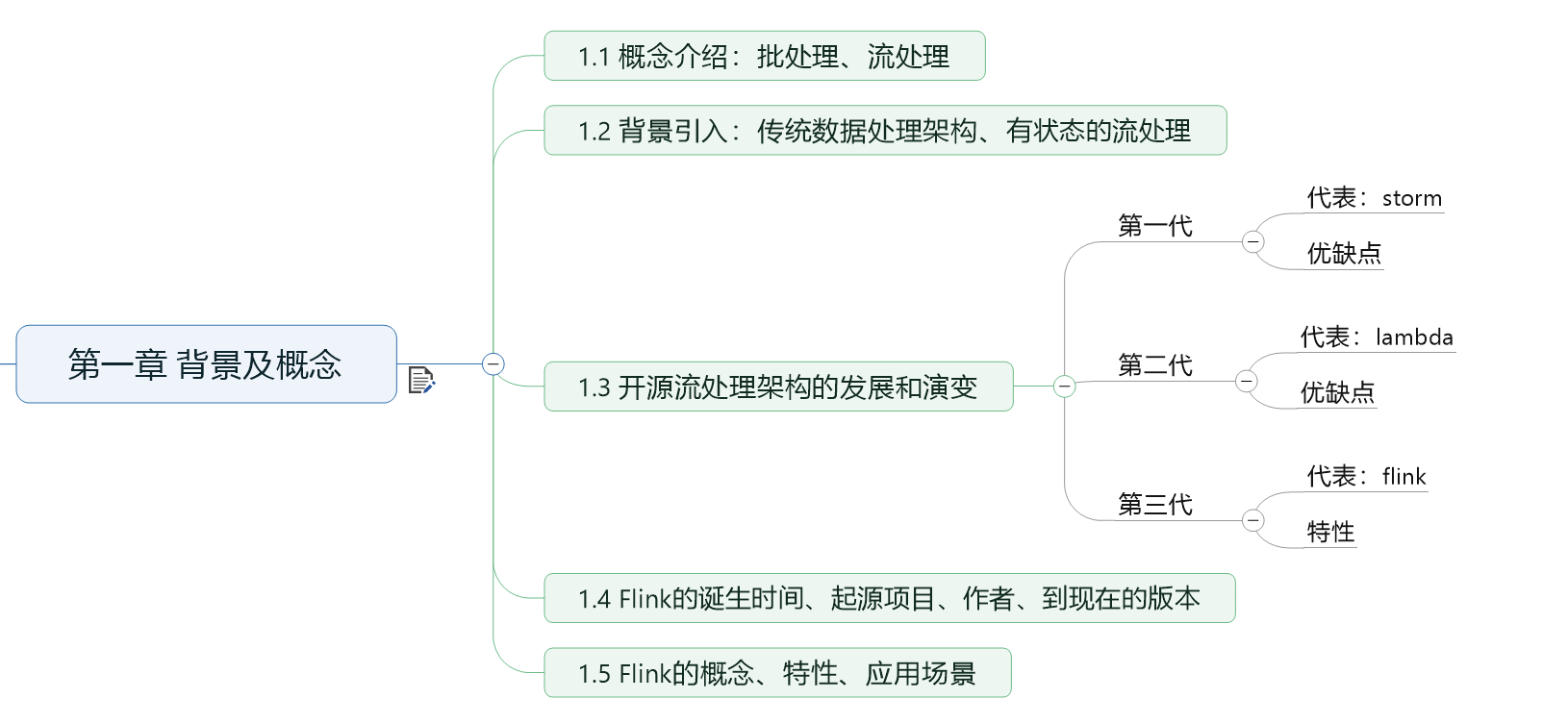
《Flink学习笔记》——第一章 概念及背景
什么是批处理和流处理,然后由传统数据处理架构为背景引出什么是有状态的流处理,为什么需要流处理,而什么又是有状态的流处理。进而再讲解流处理的发展和演变。而Flink作为新一代的流处理器,它有什么优势?它的相关背…

Flink 实战 - 7.大规模状态 ValueState IO 实践与优化
一.引言
工业场景下 Flink 经常使用 ValueState + RocksDBStateBackend 的组合,针对不断增大的 ValueState 或者数量过大的 ValueState,RocksDBStateBackend 使用了 TaskManager 所在机器的本地目录,从而突破 JVM Heap 的限制,满足了大量 ValueState 存储的场景,下面介绍…
2、Calcite 源码编译与运行
Calcite 源码编译与运行
一、概述
1)简介
Calcite是一个数据库查询优化器。
2)使用方式
1.将Calcite作为独立的服务,向下对接异构数据源,上层应用则使用Calcite原生的JDBC接口,利用SQL语句进行请求和响应。
2.将…
flink1.17 实现 udf scalarFunctoin get_json_object 支持 非标准化json
特色
相比官方的json_value,该函数支持非标准化json,比如v是个object,但是非标准json会外套一层引号,内部有反引号.
eg: {"kkkk2": "{\"kkkk1\":\"vvvvvvv\"}" }
支持value为 100L 这种java格式的bigint. {"k":999L…
flink 时间窗需要设置断链
tag:简单记录,回头整理
flink带有时间窗的任务设置并发度从1改为大于1的值,并从savepoint恢复任务会出现 并发度大于maxParallism(1)的报错,是因为当时间窗的算子与其前后算子并发度相同时,其会…
0基础学习PyFlink——流批模式在主键上的对比
假如我们将《0基础学习PyFlink——使用PyFlink的Sink将结果输出到外部系统》中的模式从批处理(batch)改成流处理(stream),则其在print连接器上产生的输出是不一样。
批处理 env_settings EnvironmentSettings \.new_…

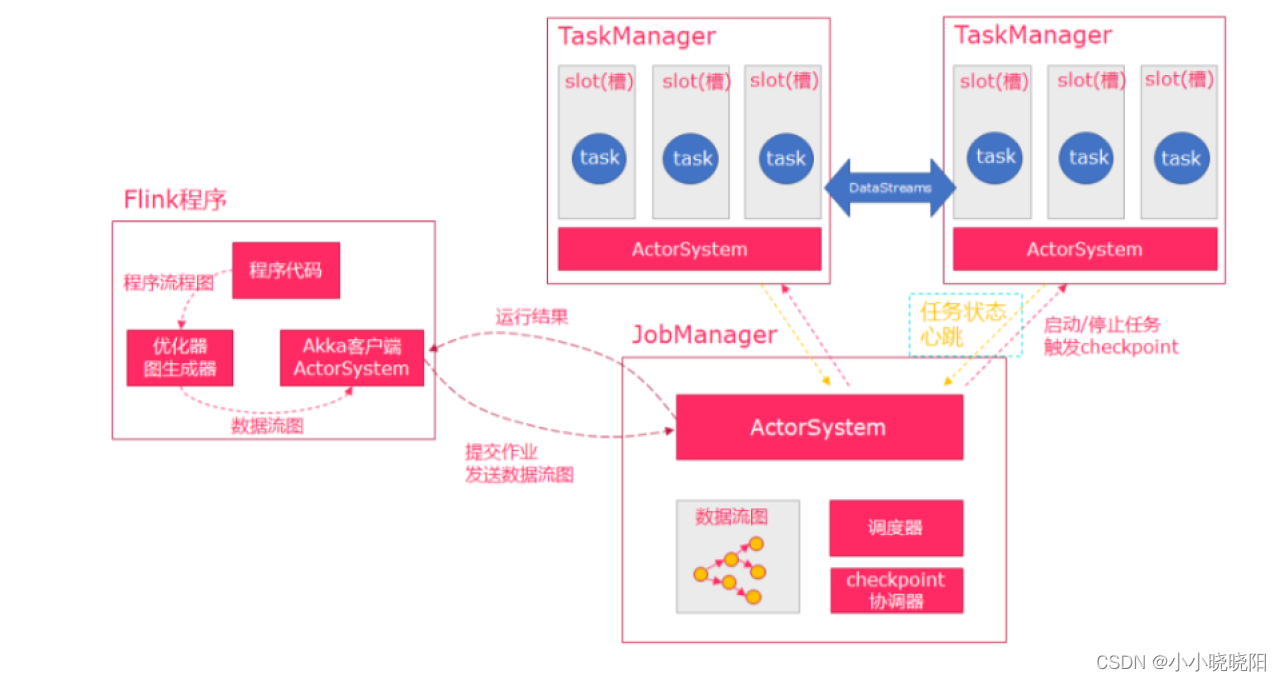
Flink内核源码解析--Flink中重要的工作组件和机制
Flink内核源码
1、掌握Flink应用程序抽象2、掌握Flink核心组件整体架构抽象3、掌握Flink Job三种运行模式4、理解Flink RPC网络通信框架Akka详解5、理解TaskManager为例子,分析Flink封装Akka Actor的方法和整个调用流程6、理解Flink高可用服务HighAvailabilityServ…
【Flink实战】用户统计:按照省份维度统计新老用户
🚀 作者 :“大数据小禅” 🚀 文章简介 :【Flink实战】用户统计:按照省份维度统计新老用户 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 目录导航 数据源JSON格式数据统计分析IP提取测试…
flink中使用异步函数的几个注意事项
背景
在flink系统中,我们为了补充某个流事件成一个完整的记录,经常需要调用外部接口获取一些配置数据,流事件结合这些配置数据就可以组合成一条完整的记录,然而如果同步调用外部系统接口来实现,那么会有很大的性能瓶颈…
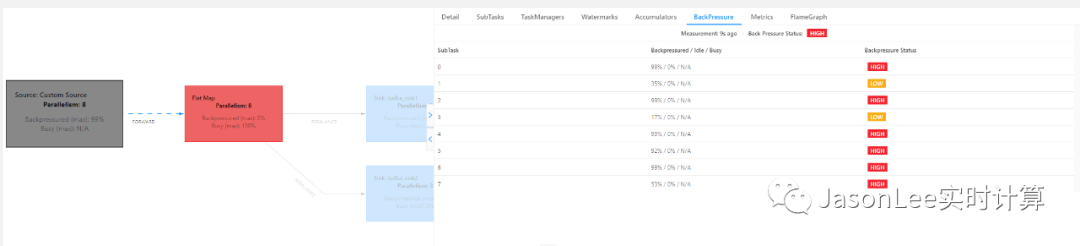
Flink 任务 Jackson 解析 JSON 使用不当引发的反压问题
背景 最近业务方反馈线上一个 topic 的数据延迟比较大,然后我查看了这个 topic 的数据是由一个 Flink 任务产生的,于是就找到了这个任务开始排查问题,发现这个任务是一个非常简单的任务,大致的逻辑是 kafka source -> flatmap -> filter -> map -> sink kafka.中间…
【Flink实战系列】Flink 1.14.0 消费 kafka 数据自定义反序列化器
Flink 1.14.0 消费 kafka 数据自定义反序列类
在最近刚发布的 Flink 1.14.0 版本中 Source 接口进行了重构,API 的变化还是非常大的,那在新的接口下消费 kafka 的时候如何自定义反序列类呢?
Kafka Source
使用
Kafka source 提供了一个构建类来构造 KafkaSource 的实例。下…
人工智能Java SDK:flink-情感倾向分析【英文】
flink-情感倾向分析【英文】SDK
情感倾向分析(Sentiment Classification) 针对带有主观描述的文本,可自动判断该文本的情感极性类别并给出相应的置信度, 能够帮助企业理解用户消费习惯、分析热点话题和危机舆情监控,为…
Flink - 12.CountTrigger ProcessingTimeTriger 详解
一.引言
Flink 针对 window 提供了多种自定义 trigger,其中常见的有 CountTrigger 和 ProcessingTimeTrigger,下面通过两个 demo 了解一下两个 Trigger 的内部实现原理与窗口触发的相关知识。 二.辅助知识
介绍上述两个 Trigger 之前,首先重新回顾下之前提高的 trigger 基…
《Flink学习笔记》——第二章 Flink的安装和启动、以及应用开发和提交
介绍Flink的安装、启动以及如何进行Flink程序的开发,如何运行部署Flink程序等 2.1 Flink的安装和启动 本地安装指的是单机模式 0、前期准备
java8或者java11(官方推荐11)下载Flink安装包 https://flink.apache.org/zh/downloads/hadoop&a…
怎么使用 Flink 向 Apache Doris 表中写 Bitmap 类型的数据
Bitmap是一种经典的数据结构,用于高效地对大量的二进制数据进行压缩存储和快速查询。Doris支持bitmap数据类型,在Flink计算场景中,可以结合Flink doris Connector对bitmap数据做计算。
社区里很多小伙伴在是Doris Flink Connector的时候&…
Streaming System是第一章翻译
GIthub链接,欢迎志同道合的小伙伴一起翻译
Chapter 1.Streaming101
如今,流数据处理在大数据中是非常重要的,其主要原因是:
企业渴望对他们的数据有更及时的了解,而转换到流处理是实现更低延迟的一个好方法…
Flink - 16.有状态算子和应用Demo详解
一.引言
入门Demo讲到了Flink的一个处理特性就是通过时间窗口对一段时间的数据进行处理,这次有状态算子则是另一种基于时间的处理,有状态算子根据自身状态的过期时间,可以根据一定时间内的状态改变做出相对应的变化,相比于传统流式处理,状态的引入丰富了事件的处理方式。…
Flink 中的 Window Function(窗口函数)及示例代码
定义窗口分配器后,我们需要指定要在每个窗口上执行的计算。这是Window Fucntion的职责,一旦系统确定窗口已准备好进行处理,就可以处理每个窗口的元素。
窗口函数可以是ReduceFunction,AggregateFunction,FoldFunction…
Flink 中Operators(操作符)及示例代码
Transformations(转换)
DataStream → DatasTREAM
Map 获取一个元素并生成一个元素。将输入流的值加倍的映射函数:
dataStream.map( x > x * 2)FlatMap 接受一个元素并生成零个、一个或多个元素。将句子分割成单词的平面图功能:
dataStream.flatM…

Flink是什么?如何简单应用?
文章目录Flink是什么?Flink介绍处理无界和有界数据部署应用程序在任何地方以任何规模运行应用程序利用内存中的性能Flink Demo展示利用maven导入依赖利用Scala 进行wordcount利用Java进行wordcount利用Java进行wordcount2Source 展示source1_CollectSource2_FileSou…

Flink Window窗口机制
文章目录Flink Window窗口机制Demo 1Demo 2Demo 3Flink Window窗口机制
Window是无限数据流处理的核心,Window将一个无限的stream拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。本文主要聚焦于在Flink中如何进行窗口操作,以…

骆驼iptv_骆驼中的事件处理
骆驼iptv在上一篇有关骆驼-小水车的帖子中,我介绍了骆驼-小水车的组件,并使用骆驼路线中的规则实现了一些简单的面向任务的过程。 今天,我将展示如何通过添加事件处理来扩展此示例。 那么如何描述一个事件呢? 每个事件在某个时间发…

快速启动flink项目
按照这个步骤1分钟内创建完成
idea-----File----new---Project------Maven----Create from archetype----Add Archetype
弹出框:
GroupId填org.apache.flink
ArtifactId填flink-quickstart-java
Version填1.14.0
选中刚刚添加的Archetype,点Next
填写你要创建的这个fl…

用户画像系列——数据中台之OneID (ID-Mapping)核心架构设计
一.引言
大家在上网的过程中是不是经常有这样的体验,我在百度(或者京东、淘宝)上搜索一件商品(比如说:我搜索了一台iphone 手机看了看,但是没买),奇怪的是过两天,我竟然在某视频平台或者某网页上又看到了它࿱…
Flink系列-7、Flink DataSet—Sink广播变量分布式缓存累加器
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 大数据系列文章目录
官方网址:https://flink.apache.org/
学习资料:https://flink-learning.org.cn/ 目录 数据输出Da…
大数据开发平台(Data Platform)在有赞的最佳实践
前言
随着公司规模的增长,对大数据的离线应用开发的需求越来越多,这些需求包括但不限于离线数据同步(MySQL/Hive/Hbase/Elastic Search 等之间的离线同步)、离线计算(Hive/MapReduce/Spark 等)、定时调度、运行结果的查询以及失败场景的报警等等。
在统…

Apache Flink v1.8 本地单机环境安装和运行Flink应用
Flink 运行环境
Flink 执行环境分为:本地单机环境和集群环境
本地单机环境:主要是为了方便用户编写、调试代码使用。
集群环境:用于正式环境,可以借助Hadoop YARN、Mesos、Kubernetes等不同的资源管理器部署自己的应用。 搭建本…

Flink 异常- 7.NoSuchMethodError: com.twitter.chill.java.Java8ClosureRegistrar.areOnJava8()Z
一.引言
使用 Flink 1.13.1 + scala 2.11.12 的组合进行 Flink 本地测试是,报错 .NoSuchMethodError: com.twitter.chill.java.Java8ClosureRegistrar.areOnJava8()Z,经过前面多次的 noSuchMethod 的折磨,现在已经轻车熟路,直接开始排查。 二.错误分析
1.字面含义 报错显…
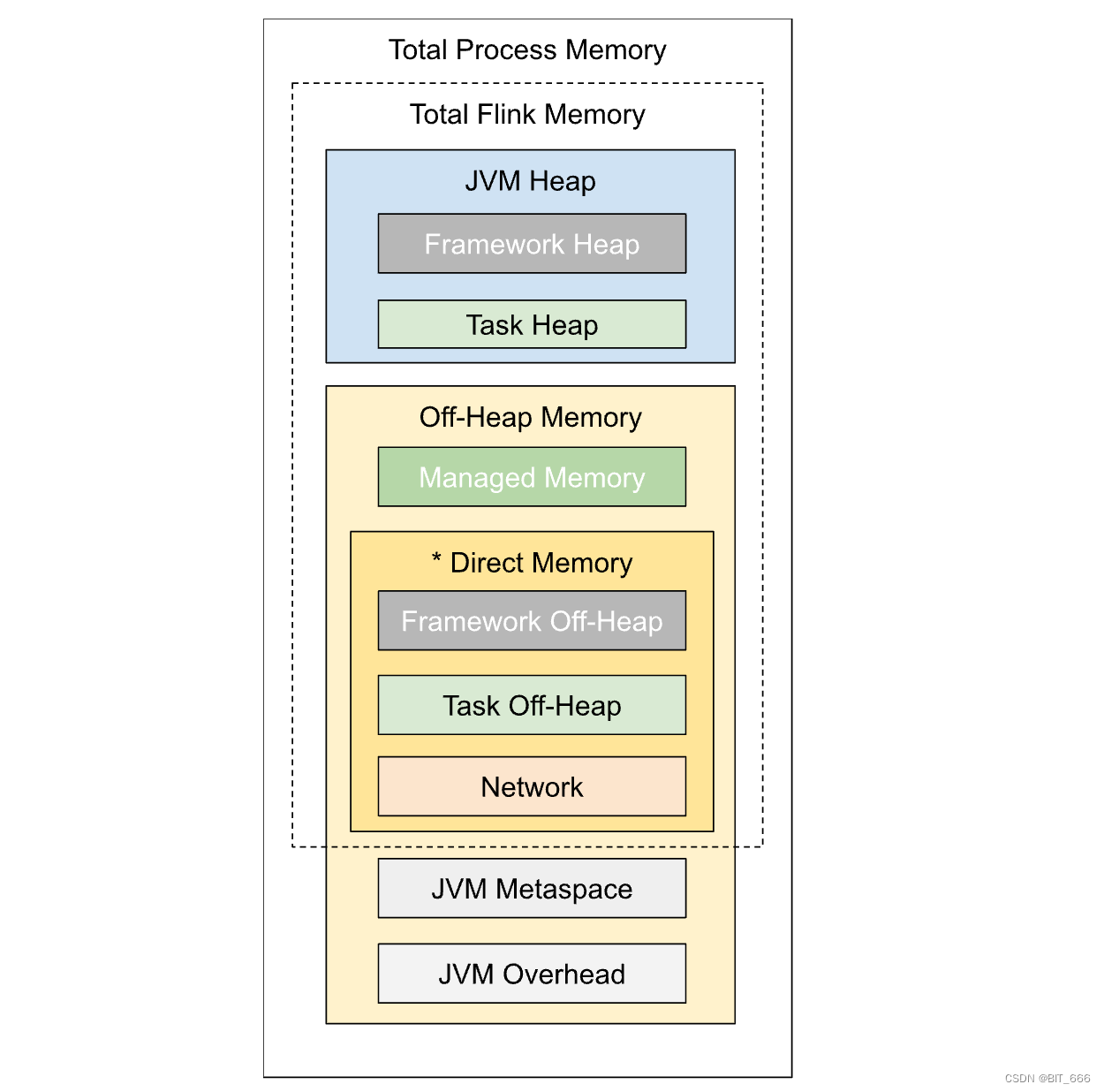
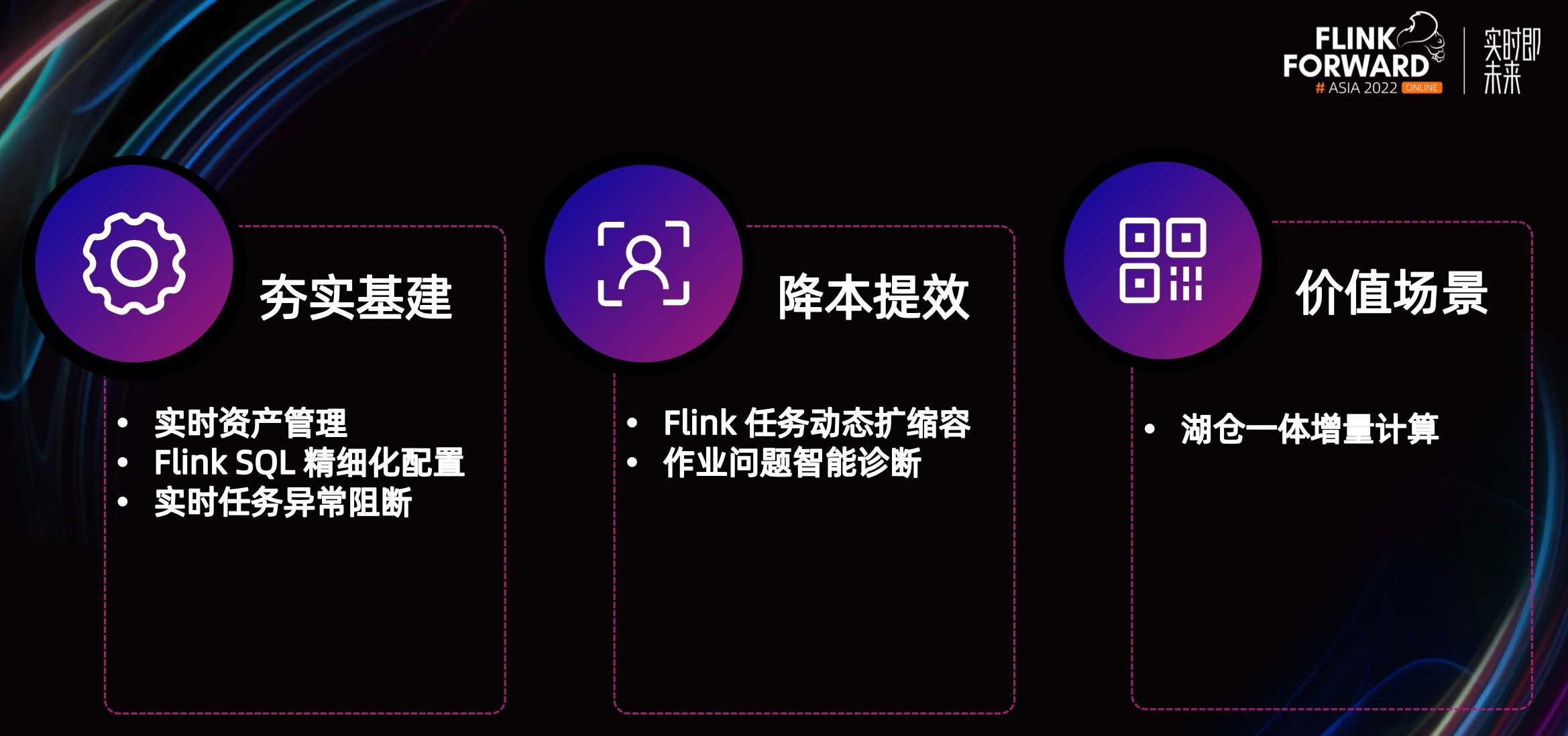
Flink - 14.内存模型详解
一.引用
TaskManager 在 Flink 中运行用户代码,根据任务需要配置合适的内存可以合理利用资源、提高程序稳定性,相比于 JobManager 的 内存模型,TaskManager 的内存模型与其有很多相似之处同时也更复杂,所以本文主要分析 TaskManager 内存模型,版本基于 1.13.x。 二.内存模…
Flink / Scala 实战 - 12.Aggregate 详解与 UV、PV 统计实战
目录
一.引言
二.Aggregate 简介
三.Aggregate Demo
1.AggregateFunction Demo
2.实践 Source 类
2.1 Event Class
2.2 Source Class

【Flink学习】入门教程之Fault Tolerance via State Snapshots
文章目录通过状态快照实现容错处理State Backends状态快照定义状态快照如何工作?确保精确一次(exactly once)端到端精确一次原文地址通过状态快照实现容错处理
State Backends 状态后端 ? 状态的后端处理方式?键控的状态&#x…
Flink Table API 读写MySQL
Flink Table API 读写 MySQL
import org.apache.flink.connector.jdbc.table.JdbcConnectorOptions;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Envi…
Flink之SQL查询操作
SQL查询 基本SELECT查询生成测试数据WITHWHEREDISTINCTORDER BYLIMIT 窗口函数概述创建数据表滚动窗口 TUMBLE滑动窗口 HOP累积窗口 CUMULATE窗口偏移 聚合窗口聚合分组聚合OVER聚合 TOP-N普通Top-N窗口Top-N 联结Join查询内部等连接外部等连接间隔联结 集合操作UNION 和 UNION…
k8s-镜像构建Flink集群Native session
一.Flink安装包下载 wget https://dlcdn.apache.org/flink/flink-1.14.6/flink-1.14.6-bin-scala_2.12.tgz 二.构建基础镜像推送私服 docker pull apache/flink:1.14.6-scala_2.12 docker tag apache/flink:1.14.6-scala_2.12 172.25.152.2:30002/dmp/flink:

浅谈大数据之Flink
1.3.4 Flink
Flink是由德国3所大学发起的学术项目,后来不断发展壮大,并于2014年年末成为Apache顶级项目之一。在德语中,“flink”表示快速、敏捷,以此来表征这款计算框架的特点。
Flink主要面向流处理,如果说Spark是批处理界的“王者”,那么Flink就是流处理领域冉冉升…
使用Flink处理Kafka中的数据_题库子任务_Java语言实现
2024年职业院校技术大赛-高职大数据应用开发赛项专题。
使用Flink处理Kafka中的数据_题库子任务1、2、3_Java语言实现使用Flink处理Kafka中的数据_题库子任务4、5、6_Java语言实现使用Flink处理Kafka中的数据_题库子任务7、8、9_Java语言实现

大数据-玩转数据-Flink CEP编程
一、Flink CEP
FlinkCEP(Complex event processing for Flink) 是在Flink实现的复杂事件处理库。它可以让你在无界流中检测出特定的数据,有机会掌握数据中重要的那部分。 是一种基于动态环境中事件流的分析技术,事件在这里通常是有意义的状态变化&#…

【入门Flink】- 07Flink DataStream API【万字篇】
DataStream API 是 Flink 的核心层 API。一个 Flink 程序,其实就是对DataStream的各种转换。 代码基本上都由以下几部分构成: 执行环境(Execution Environment)
1)创建执行环境StreamExecutionEnvironment
StreamExe…
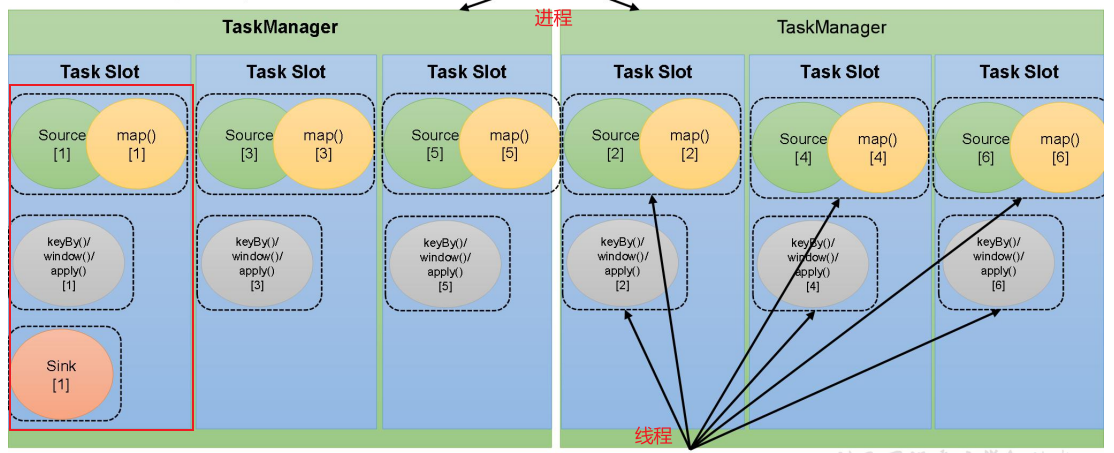
【入门Flink】- 05Flink运行时架构以及一些核心概念
系统架构
Flink运行时架构Standalone会话模式为例 1)作业管理器(JobManager)
JobManager 是一个 Flink 集群中任务管理和调度的核心,是控制应用执行的主进程。每个应用都应该被唯一的 JobManager 所控制执行。
JobManger 又包含…
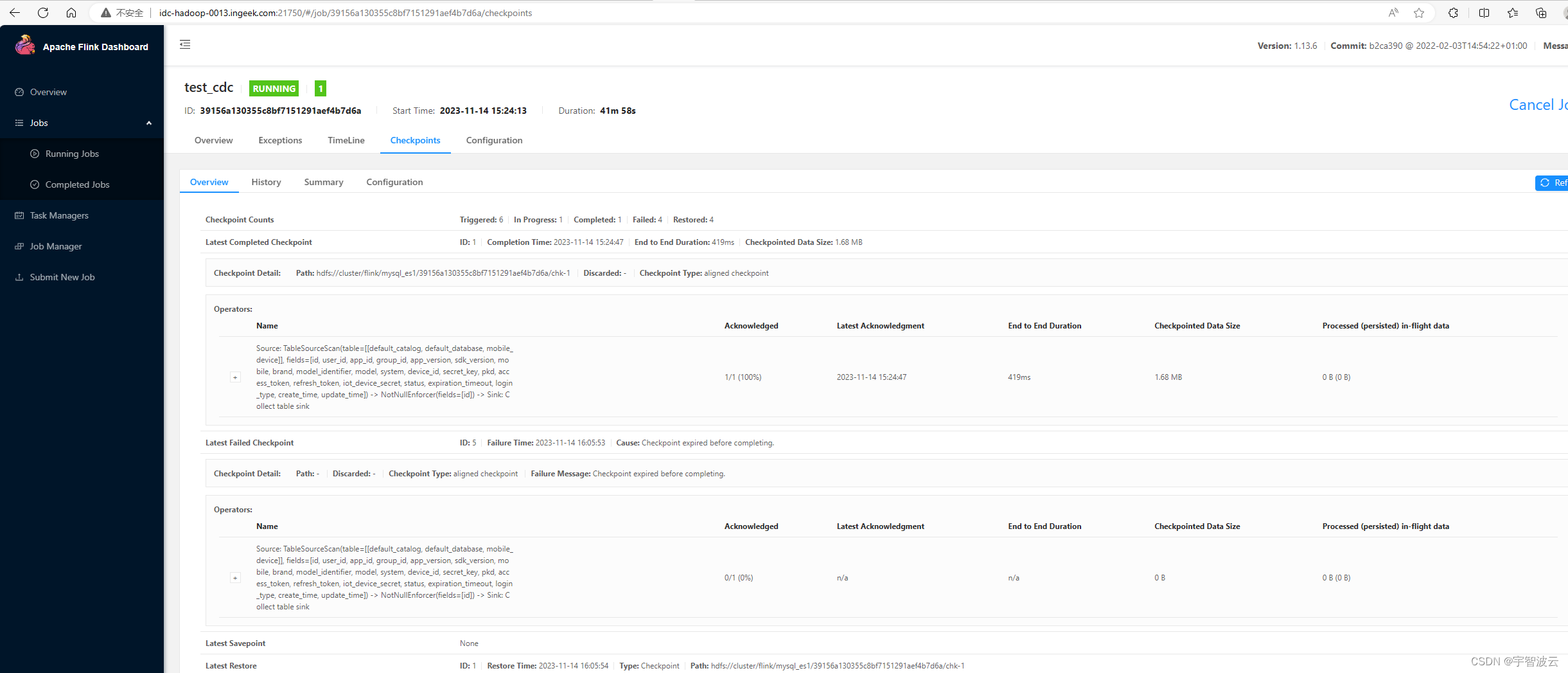
修炼k8s+flink+hdfs+dlink(七:flinkcdc)
一 :flinkcdc官网链接。 https://ververica.github.io/flink-cdc-connectors/release-2.1/content/about.html 二:在flink中添加jar包。
在flink lib目录下增加你所需要的包。 https://kdocs.cn/join/gv467qi?f101 邀请你加入共享群「工作使用重要工具…
五分钟,Docker安装flink,并使用flinksql消费kafka数据
1、拉取flink镜像,创建网络
docker pull flink
docker network create flink-network2、创建 jobmanager
# 创建 JobManager docker run \-itd \--namejobmanager \--publish 8081:8081 \--network flink-network \--env FLINK_PROPERTIES"jobmanager.rpc.ad…
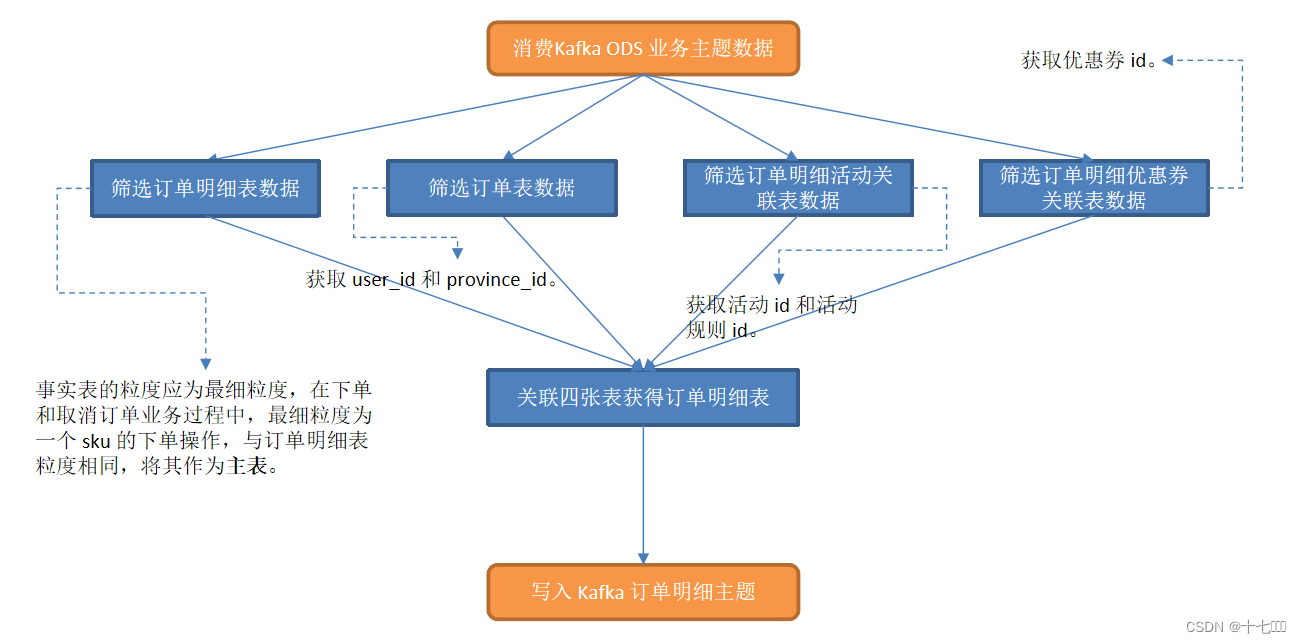
基于Flink实时数仓——准备业务数据 DWD 层(2)
业务数据的变化,我们可以通过 FlinkCDC 采集到,但是 FlinkCDC 是把全部数据统一写入一个 Topic 中, 这些数据包括事实数据,也包含维度数据,这样显然不利于日后的数据处理,所以这个功能是从 Kafka 的业务数据 ODS 层读取…

flink和机器学习模型的常用组合方式
背景
flink是一个低延迟高吞吐的系统,每秒处理的数据量高达数百万,而机器模型一般比较笨重,虽然功能强大,但是qps一般都比较低,日常工作中,我们一般是如何把flink和机器学习模型组合起来一起使用呢?
fli…
【Flink】Standalone运行模式
独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景…

Flink之常用处理函数
常用处理函数 处理函数概述 基本处理函数ProcessFunction介绍使用示例 按键分区处理函数KeyedProcessFunction介绍定时器Timer和定时服务TimerService使用示例其他 窗口处理函数ProcessWindowFunction介绍ProcessAllWindowFunction介绍使用示例 流的合并处理函数CoProcessFunct…
FLink中火焰图的说明
flink 配置火焰图追踪堆栈的信息
火焰图主要是用来跟踪堆栈线程重复多次采样而生成的,每个方法的调用表示为一个长方形,长方形的长度和在采样中出现的次数成正比。
图的解释;
y轴: 表示调用栈,每一层都是一个函数,调用栈越深。…
Flink从入门到放弃之入门篇(一)-Flink快速上手
1.Flink介绍
1.1 Flink简介
Apache Flink是一个面向分布式数据流处理和批量数据 处理的开源计算平台,可以对有限数据流和无限数据流进行有状态计算,即提供支持流处理和批处理两种类型的功能
1.2 Flink特点 批流统一 支持高吞吐、低延迟‘高性能的流…

基于Flink实时数仓——DWS 层的设计访客主题宽表(6)
DWS 层的定位是什么 轻度聚合,因为 DWS 层要应对很多实时查询,如果是完全的明细那么查询的压力是非常大的。将更多的实时数据以主题的方式组合起来便于管理,同时也能减少维度查询的次数。 DWS 层-访客主题宽表的计算 设计一张 DWS 层的表其实…

FlinkCDC系列:通过skipped.operations参数选择性处理新增、更新、删除数据
在flinkCDC源数据配置,通过debezium.skipped.operations参数控制,配置需要过滤的 oplog 操作。操作包括 c 表示插入,u 表示更新,d 表示删除。默认情况下,不跳过任何操作,以逗号分隔。配置多个操作ÿ…

Flink / Scala - 2.DataSource 之 DataSet 获取数据总结
一.引言 数据源创建初始数据集,这里主要以 DataSet 数据源为例,例如从文件或者从 collection 中创建,后续介绍 DataStreaming 的数据源获取方法。创建数据集的机制一般抽象在 InputFormat 后面,这里有点类似 spark 的 sparkContext,Flink 的 ExecutionEnvironment 也提供了…
【Flink实战系列】Flink 如何实现全链路延迟监控
Flink 如何实现全链路延迟监控
需求 & 背景
在实际的生产环境中,我们希望可以监控一个任务整个链路的延迟情况,用来分析 Flink 应用的性能表现.
分析
Flink 的全链路延迟监控指的是从任务的 source 经过中间的 operator 到最后的 sink 端到端的延迟,这是一个非常重要的…

flink1.14 sql基础语法(二) flink sql表定义详解
flink1.14 sql基础语法(二) flink sql表定义详解
一、表的概念和类别
1.1 表的标识结构
每一个表的标识由 3 部分组成: catalog name (常用于标识不同的“源”,比如 hive catalog,inner catalog 等) database name…
flink-note笔记:flink-state模块中broadcast state(广播状态)解析
github开源项目flink-note的笔记。本博客的实现代码都写在项目的flink-state/src/main/java/state/operator/BroadcastStateDemo.java文件中。 项目github地址: github 1. 广播状态是什么
网上关于flink广播变量、广播状态的讲解很杂。我翻了flink官网发现,实际上在1.15里面…


基于 Flink CDC 的现代数据栈实践
摘要:本文整理自阿里云技术专家,Apache Flink PMC Member & Committer、Flink CDC Maintainer 徐榜江和阿里云高级研发工程师,Apache Flink Contributor & Flink CDC Maintainer 阮航,在 Flink Forward Asia 2022 数据集成…
Apache Flink v1.9-SNAPSHOT 源码编译
Apache Flink v1.9-SNAPSHOT 源码编译 下载源码
Flink 源码可以从官方 github repository上下载。 git clone https://github.com/apache/flink.git 下载时间会比较长,慢慢等吧。 编译源码
Flink源码编译依赖于 JDK和Maven的环境,JDK 必须在1.8 版本之…
1.Flink源码编译
目录
目录
1.1软件安装
1.1.1 jdk
1.1.2 maven
1.1.3 node js
1.2 下载flink源码
1.3 编译源码
1.4 idea打开flink源码
1.5 运行wordcount 1.1软件安装
软件地址
链接:https://pan.baidu.com/s/1ZxYydR8rBfpLCcIdaOzxVg 提取码:12xq
1.1.1 …
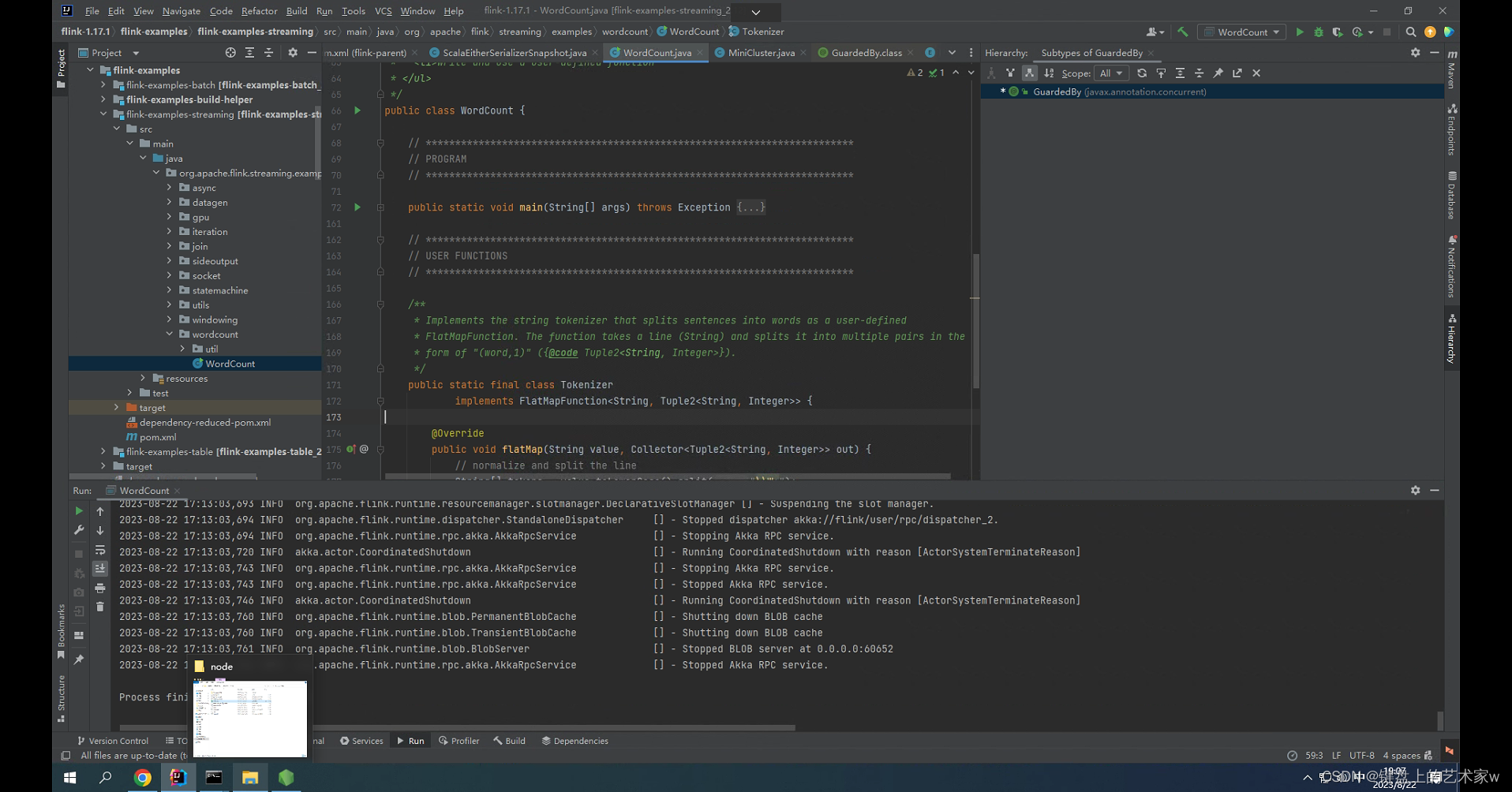
人工智能Java SDK:大数据如何与AI结合使用 - flink-句向量提取【支持15种语言】
flink-句向量提取【支持15种语言】SDK
句向量是指将语句映射至固定维度的实数向量。 将不定长的句子用定长的向量表示,为NLP下游任务提供服务。 支持 15 种语言: Arabic, Chinese, Dutch, English, French, German, Italian, Korean, Polish, Portugues…
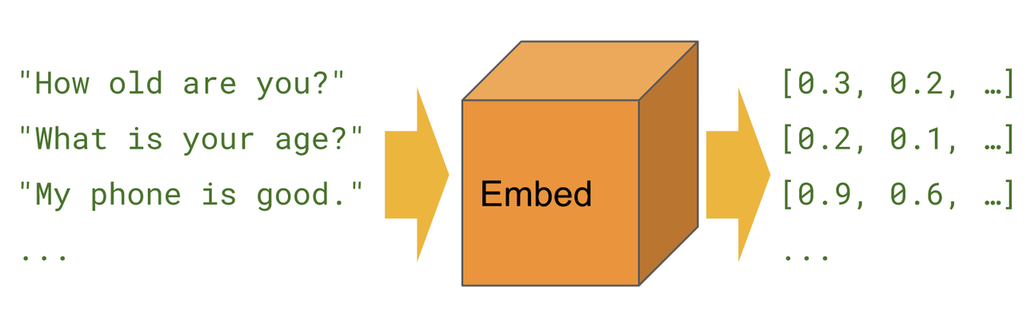
Flink/Hbase 异常 - 4.Sink 背压100% 与 hbase.util.RetryCounter.sleepUntilNextRetry 异常分析与排查
一.引言 Flink 程序内有读取 hbase 的需求,近期任务启动后偶发 sink 端背压 100% 导致无数据写入下游且无明显 exception 报错,重启任务后有较大概率恢复服务,但也有可能继续背压 100% 从而堵塞任务,遂开始排查。 二.问题描述
程序执行一段时间后,查看监控发现 Source + …

深入理解 Flink(二)Flink StateBackend 和 Checkpoint 容错深入分析
Flink State 设计详解 State 简单说,就是 Flink Job 的 Task 在运行过程中,产生的一些状态数据。这些状态数据,会辅助 Task 执行某些有状态计算,同时也涉及到 Flink Job 的重启状态恢复。所以,保存和管理每个 Task 的状…
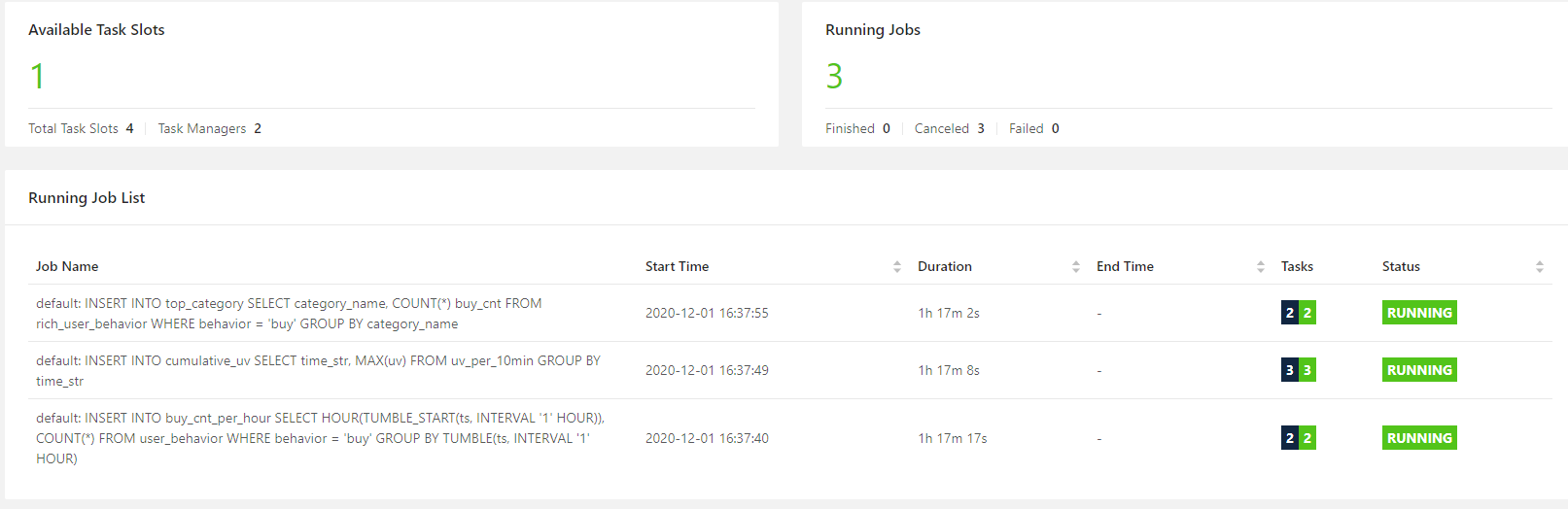
计算机毕设 flink大数据淘宝用户行为数据实时分析与可视化
文章目录 0 前言1、环境准备1.1 flink 下载相关 jar 包1.2 生成 kafka 数据1.3 开发前的三个小 tip 2、flink-sql 客户端编写运行 sql2.1 创建 kafka 数据源表2.2 指标统计:每小时成交量2.2.1 创建 es 结果表, 存放每小时的成交量2.2.2 执行 sql &#x…

Flink java 工具类
flink 环境构建工具类
public class ExecutionEnvUtil {/*** 从配置文件中读取配置(生效优先级:配置文件<命令行参数<系统参数)** param args* return org.apache.flink.api.java.utils.ParameterTool* date 2023/8/4 - 10:05 AM*/public static …
flink1.17安装
Flink1.17安装
官网地址: https://nightlies.apache.org/flink/flink-docs-release-1.17/zh//docs/try-flink/local_installation/
安装jdk11
ps:只能安装openjdk11,昨天安装的oracle jdk17,结果怎么也运行不起来。
sudo apt …
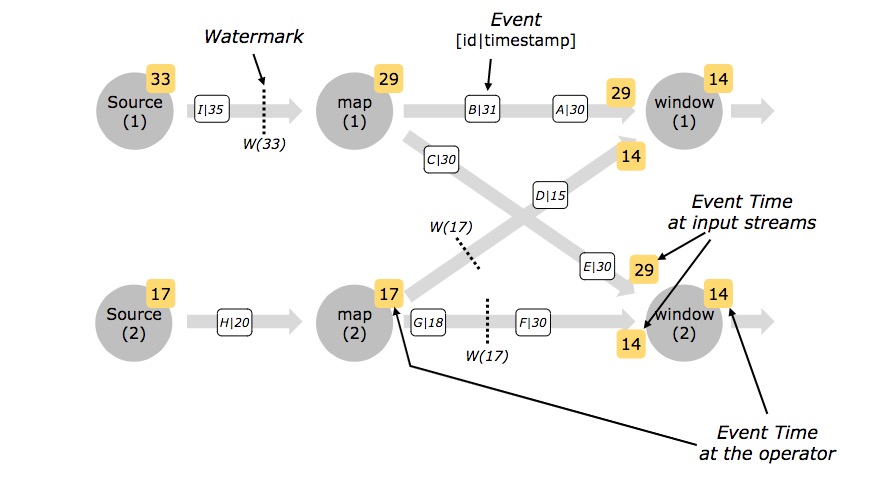
flink中的Watermark
Watermark
实时计算可以基于时间属性对数据进行窗口聚合。基于Event Time时间属性的窗口函数作业中,数据源表的声明中需要使用Watermark方法。
定义
由于实时计算的输入数据是持续不断的,因此我们需要一个有效的进度指标,来帮助我们确定关…
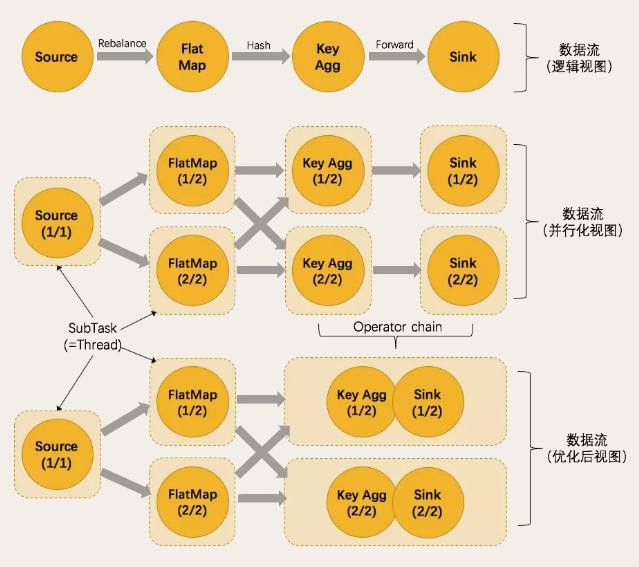
第四章 Flink 运行架构
Flink 运行时的组件
Flink 运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作: 作业管理器(JobManager)、资源管理器(ResourceManager)、任务管理器(TaskManager…

flink状态不能跨算子
背景
在flink中进行状态的维护和管理应该是我们经常做的事情,但是有些同学认为名称一样的状态在不同算子之间的状态是同一个,事实是这样吗?
flink状态在保存点中的存放示意图
事实上,每个状态都归属于对应的算子,也…
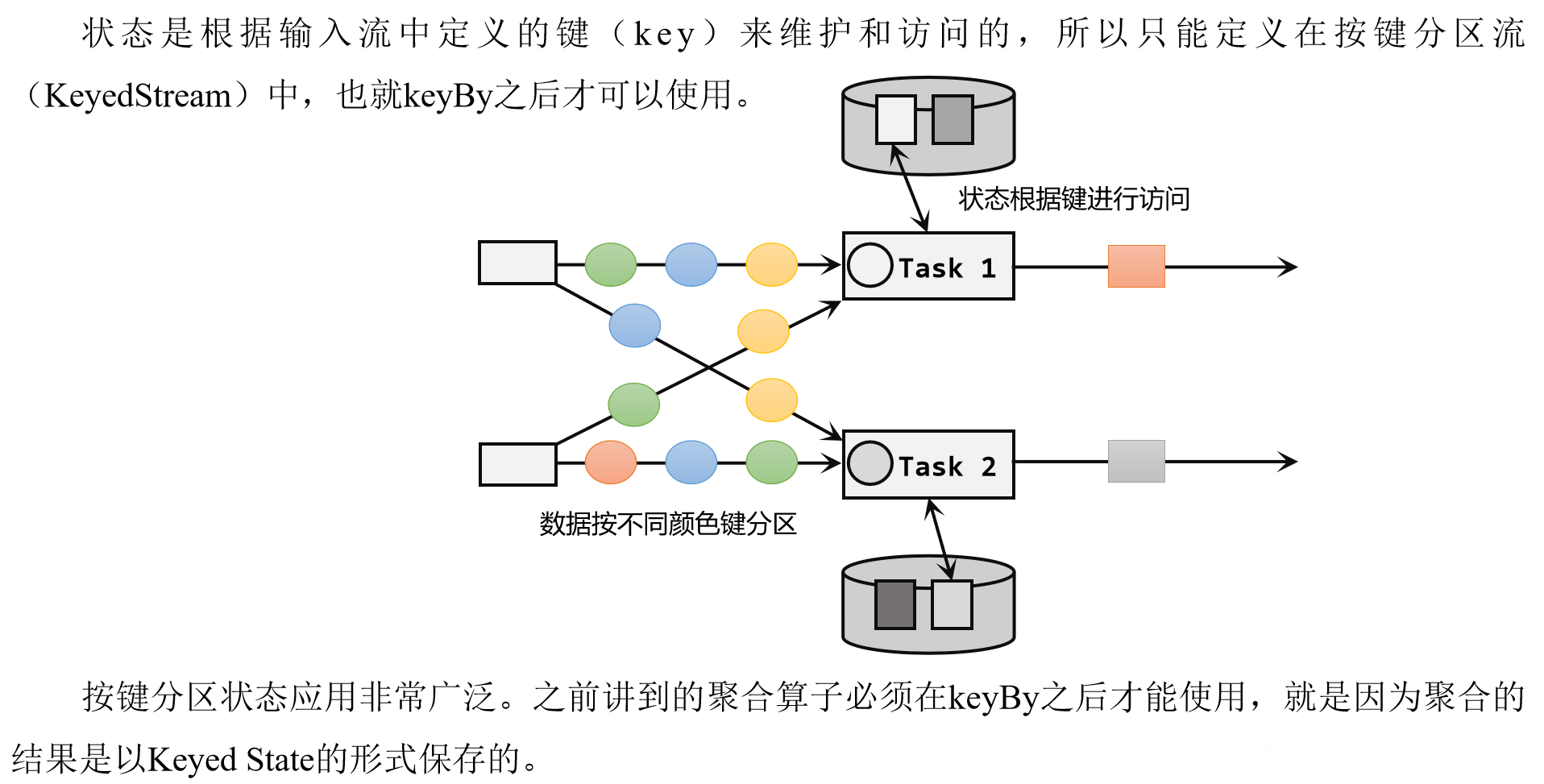
Flink1.17实战教程(第五篇:状态管理)
系列文章目录
Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…

Flink CDC 在京东的探索与实践
摘要:本文整理自京东资深技术专家韩飞,在 Flink Forward Asia 2022 数据集成专场的分享。本篇内容主要分为四个部分: 京东自研 CDC 介绍京东场景的 Flink CDC 优化业务案例未来规划点击查看直播回放和演讲 PPT 一、京东自研 CDC 介绍 京东自研…
Fink Data Sink
Flink Sink
一、Data Sinks
在使用 Flink 进行数据处理时,数据经 Data Source 流入,然后通过系列 Transformations 的转化,最终可以通过 Sink 将计算结果进行输出,Flink Data Sinks 就是用于定义数据流最终的输出位置。Flink 提供了几个较为简单的 Sink API 用于日常的开…
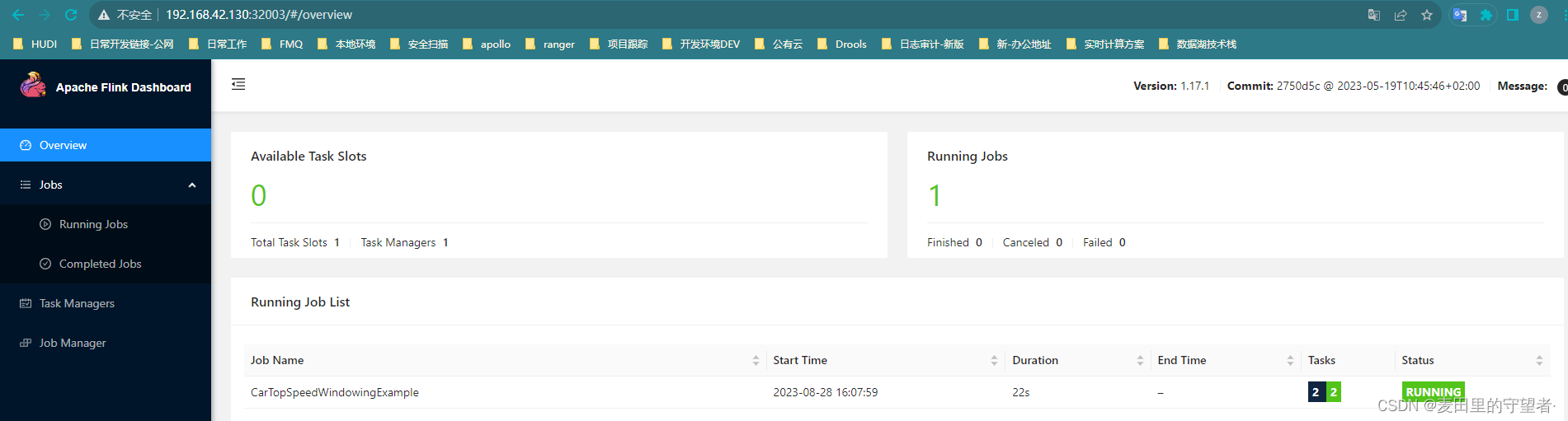
Flink Kubernates Native - 入门
创建 namespace
[rootCentOSA flink-1.17.1]# kubectl create ns flink-native
[rootCentOSA flink-1.17.1]# kubectl config set-context --current --namespaceflink-native命令空间添加资源限制
[rootCentOSA flink-1.17.1]# vim namespace-ResourceQuota.yamlapiVersion:…

flink solt概念详解
ask是flink中的一个逻辑概念,一个任务由一个或者多个算子组合而成(多个算子构成一个任务是需要满足一定的条件才可以,有兴趣的老铁可以来了解一下 Operator Chain),为了提升任务执行的效率,可以对任务配置并行度,使任务在实际运行…

flink教程(2)-source- sink
一、flink可识别的source分类 Sources are where your program reads its input from. You can attach a source to your program by using StreamExecutionEnvironment.addSource(sourceFunction). Flink comes with a number of pre-implemented source functions, but you c…
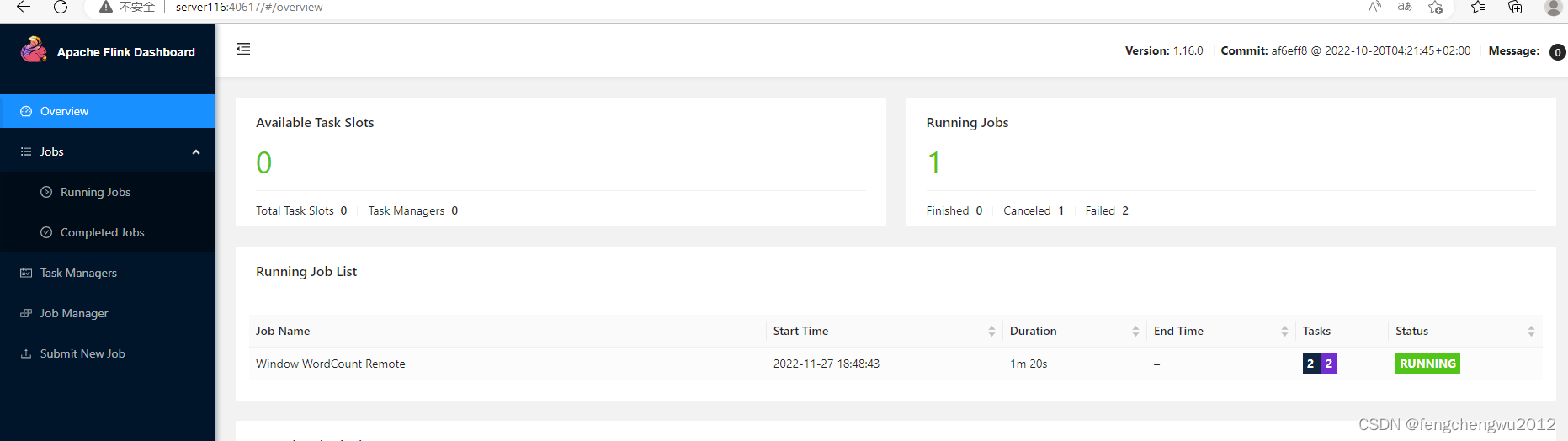
Yarn模式部署Flink集群
一、环境准备
1、准备两台服务器server115 和server116安装好hadoop环境,其中server115配置hdfs的namenode,在server116上配置hdfs的SecondaryNameNode,server116配置yarn的 ResourceManager,启动hadoop集群 2、配置hadoop环境变…
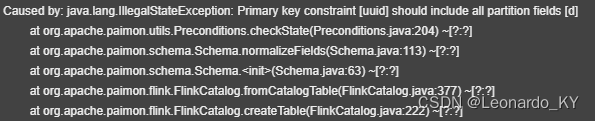
新一代数据湖存储技术Apache Paimon入门Demo
目录
前言
1. 什么是 Apache Paimon
一、本地环境快速上手
1、本地Flink伪集群
2、IDEA中跑Paimon Demo
2.1 代码
2.2 IDEA中成功运行
3、IDEA中Stream读写
3.1 流写
3.2 流读(toChangeLogStream)
二、进阶:本地(IDEA&…
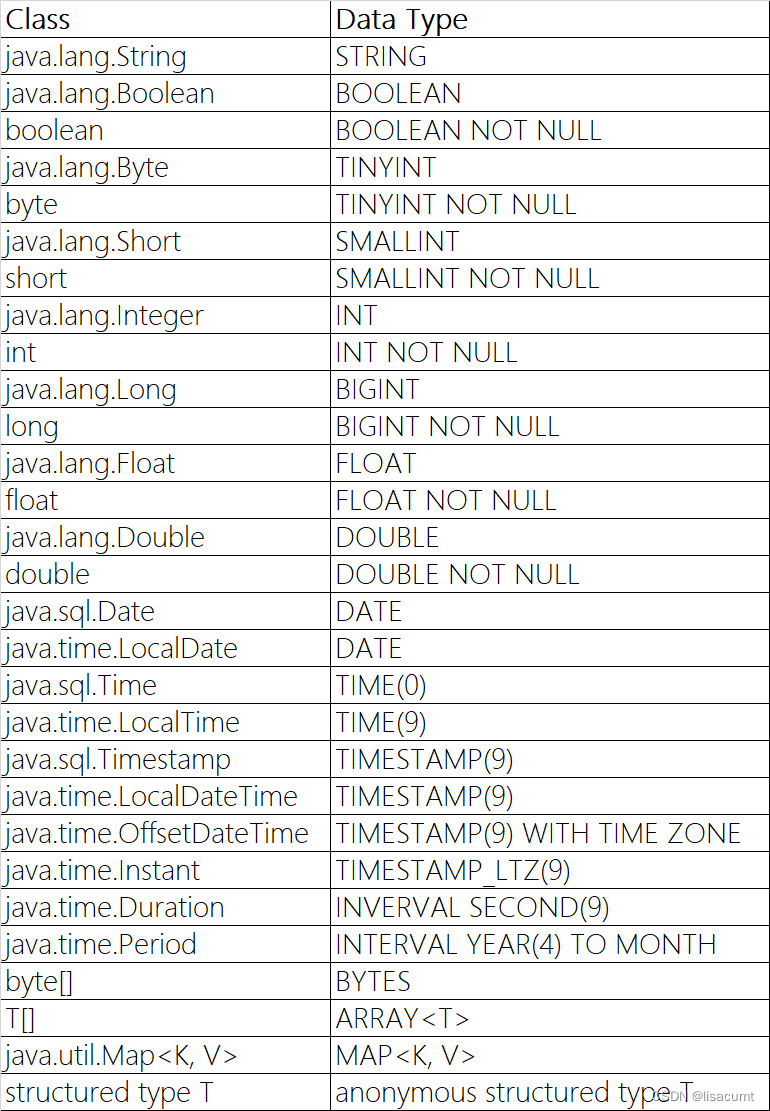
Flink 类型机制 及 Stream API和Table API类型推断和转换
注:本文使用flink 版本是0.13
一、类型体系
Flink 有两大API (1)stream API 和 (2)Table API ,分别对应TypeInformation 和 DataType类型体系。
1.1 TypeInformation系统
TypeInformation系统是使用Stream一定会用…
Flink 的 Kafka Table API Connector
Flink datastream connectors 和 Flink table api connectors 的区别:
Flink DataStream Connectors和Table API Connectors是Flink中用于连接外部数据源的两种不同的连接器。
1. Flink DataStream Connectors: - Flink DataStream Connectors是用于将外部数据源连…
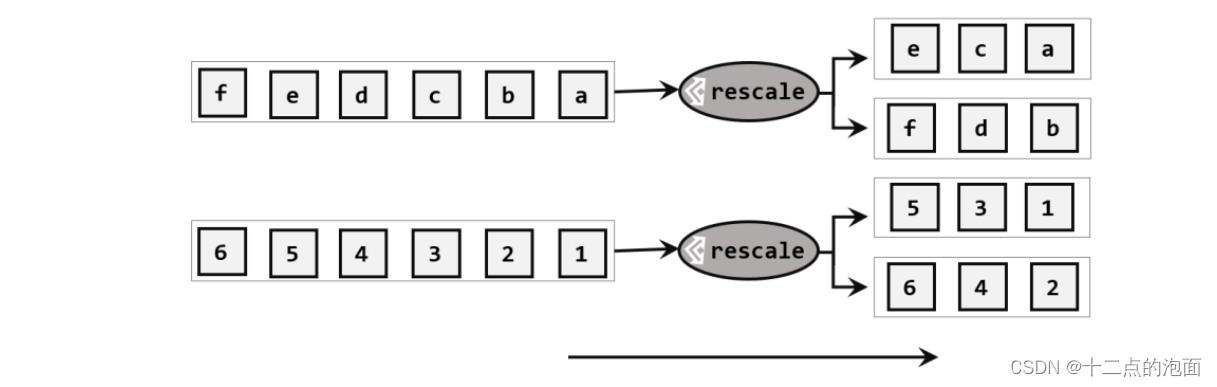
Flink 中的Physical partitioning(物理分区)及示例代码
Flink通过以下方法对转换后的确切流分区进行了低级控制。
Rebalancing(Round-robin partitioning)
分区元素循轮询,为每个分区创建相等的负载。有助于在数据不对称的情况下优化性能。在存在数据偏斜的情况下对性能优化有用。
val env Stre…
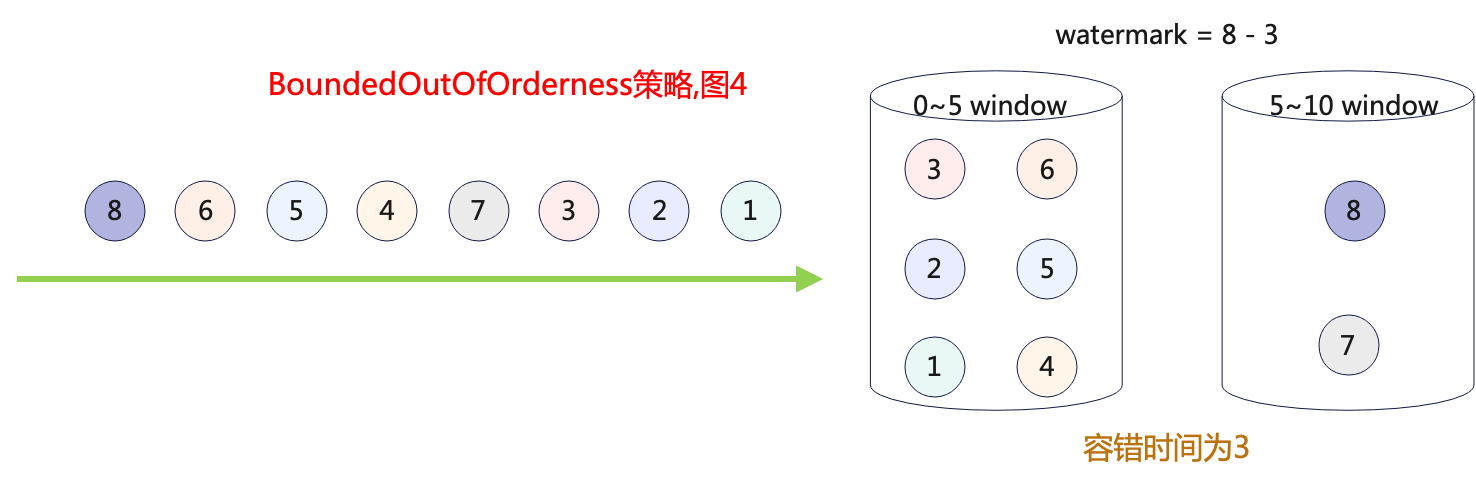
Flink之Watermark生成策略
在Flink1.12以后,watermark默认是按固定频率周期性的产生. 在Flink1.12版本以前是有两种生成策略的:
AssignerWithPeriodicWatermarks周期性生成watermarkAssignerWithPunctuatedWatermarks[已过时] 按照指定标记性事件生成watermark
新版本API内置的watermark策略 单调递增的…
【Flink on k8s】- 14 - Flink kubernetes operator 使用经验分享
目录
一、集成 flink maven 项目发布到私有库
1、环境准备
2、使用 maven 创建 java 项目
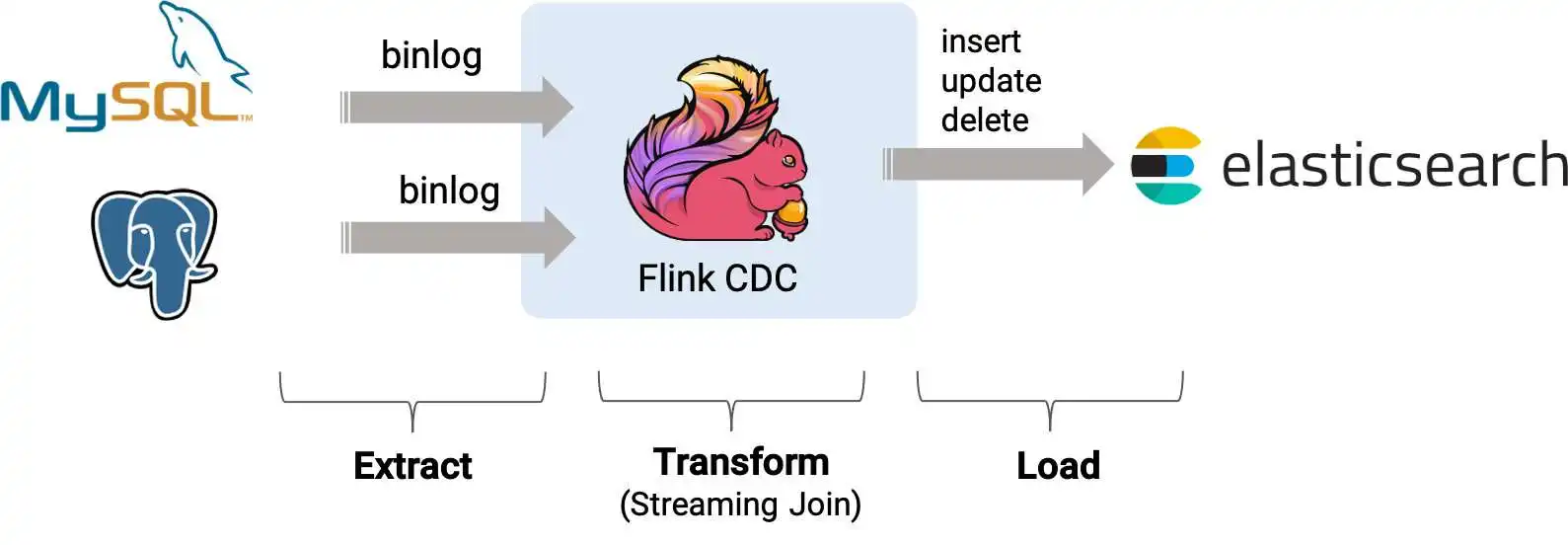
FlinkCDC数据实时同步Mysql到ES
考大家一个问题,如果想要把数据库的数据同步到别的地方,比如es,mongodb,大家会采用哪些方案呢? ::: 定时扫描同步? 实时日志同步?
定时同步是一个很好的方案,比较简单,但是如果对实时要求比较高的话,定…

Flink-DataStream API介绍(源算子、转换算子、输出算子)
文章目录DataStream API(基础篇)Flink 支持的数据类型执行环境(Execution Environment)创建执行环境执行模式(Execution Mode)触发程序执行源算子准备工作从集合中读取数据从文件读取数据从 Socket 读取数据从 Kafka 读取数据自定…

【入门Flink】- 06Flink作业提交流程【待完善】
Standalone 会话模式作业提交流程 代码生成任务的过程:
逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→物理图(Physical Graph)。 作业图算子链…

Apache Celeborn 让 Spark 和 Flink 更快更稳更弹性
摘要:本文整理自阿里云/数据湖 Spark 引擎负责人周克勇(一锤)在 Streaming Lakehouse Meetup 的分享。内容主要分为五个部分: Apache Celeborn 的背景Apache Celeborn——快Apache Celeborn——稳Apache Celeborn——弹Evaluation…
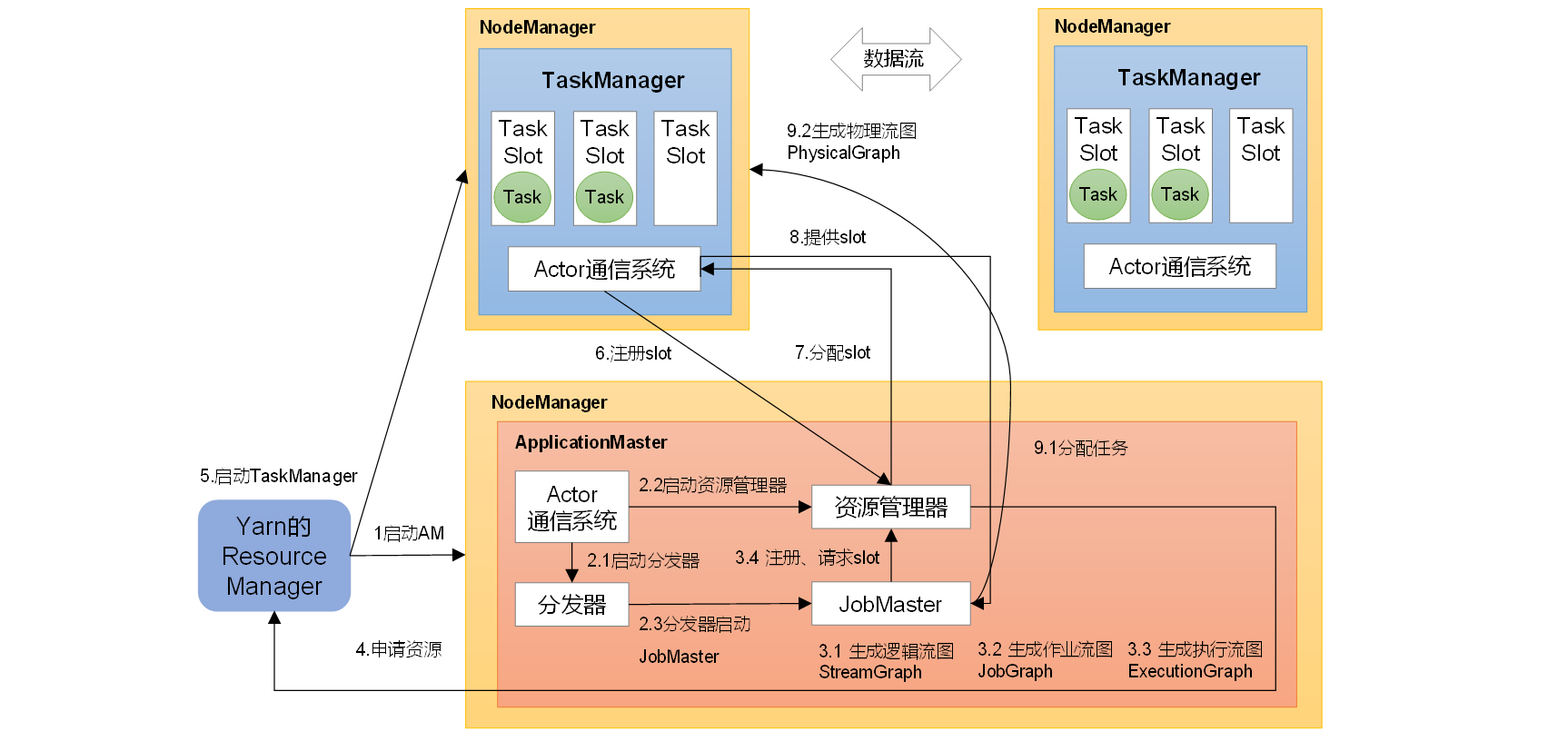
《Flink学习笔记》——第四章 Flink运行时架构
4.1 系统架构
Flink运行时架构 Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。
1、作业管理器(JobManager)
JobManager是一个Flink集群中任务管理和调度的核心,是控制应用执行的主进程。也就…

【大数据】Flink 详解(六):源码篇 Ⅰ
Flink 详解(六):源码篇 Ⅰ 55、Flink 作业的提交流程?56、Flink 作业提交分为几种方式?57、Flink JobGraph 是在什么时候生成的?58、那在 JobGraph 提交集群之前都经历哪些过程?59、看你提到 Pi…
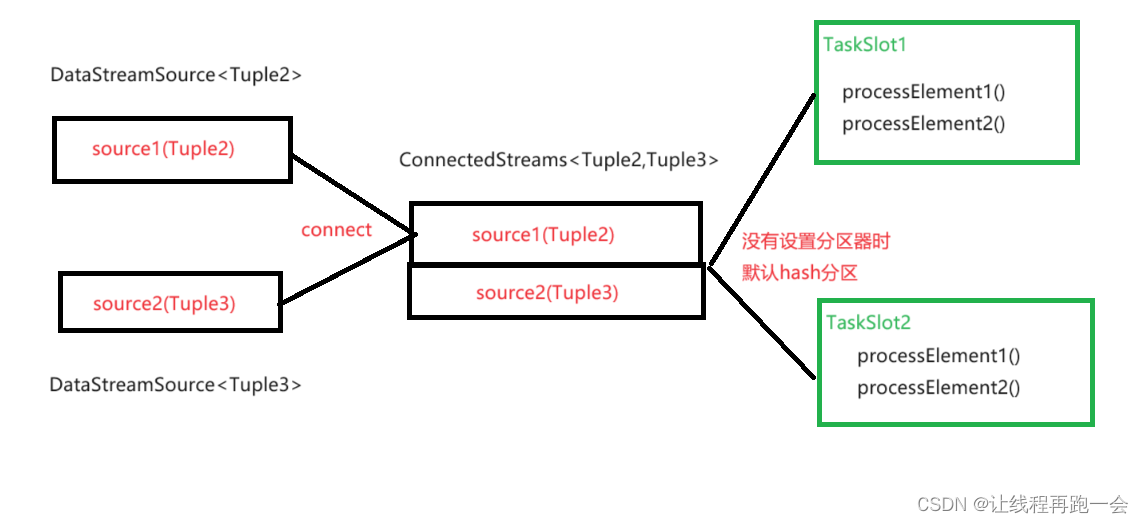
Flink(六)【DataFrame 转换算子(下)】
前言 今天学习剩下的转换算子。
1、物理分区算子
常见的物理分区策略有随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast),下边我们分别来做…
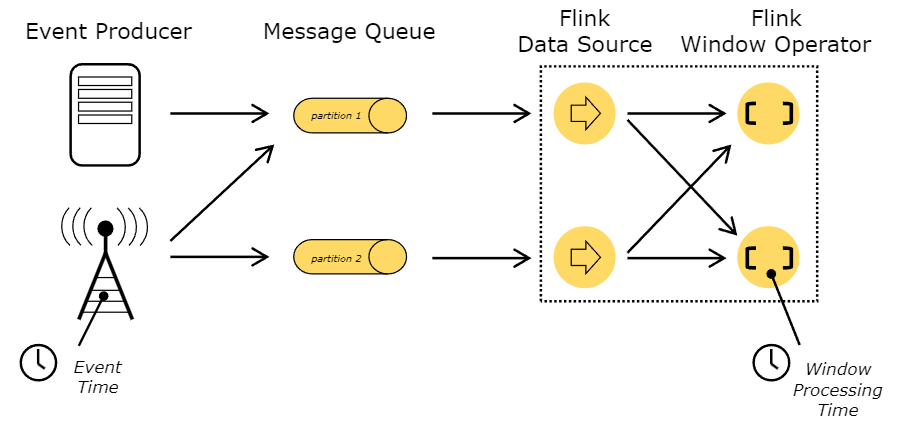
【入门Flink】- 08Flink时间语义和窗口概念
Flink-Windows 是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window)。 注意:Flink 中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗…
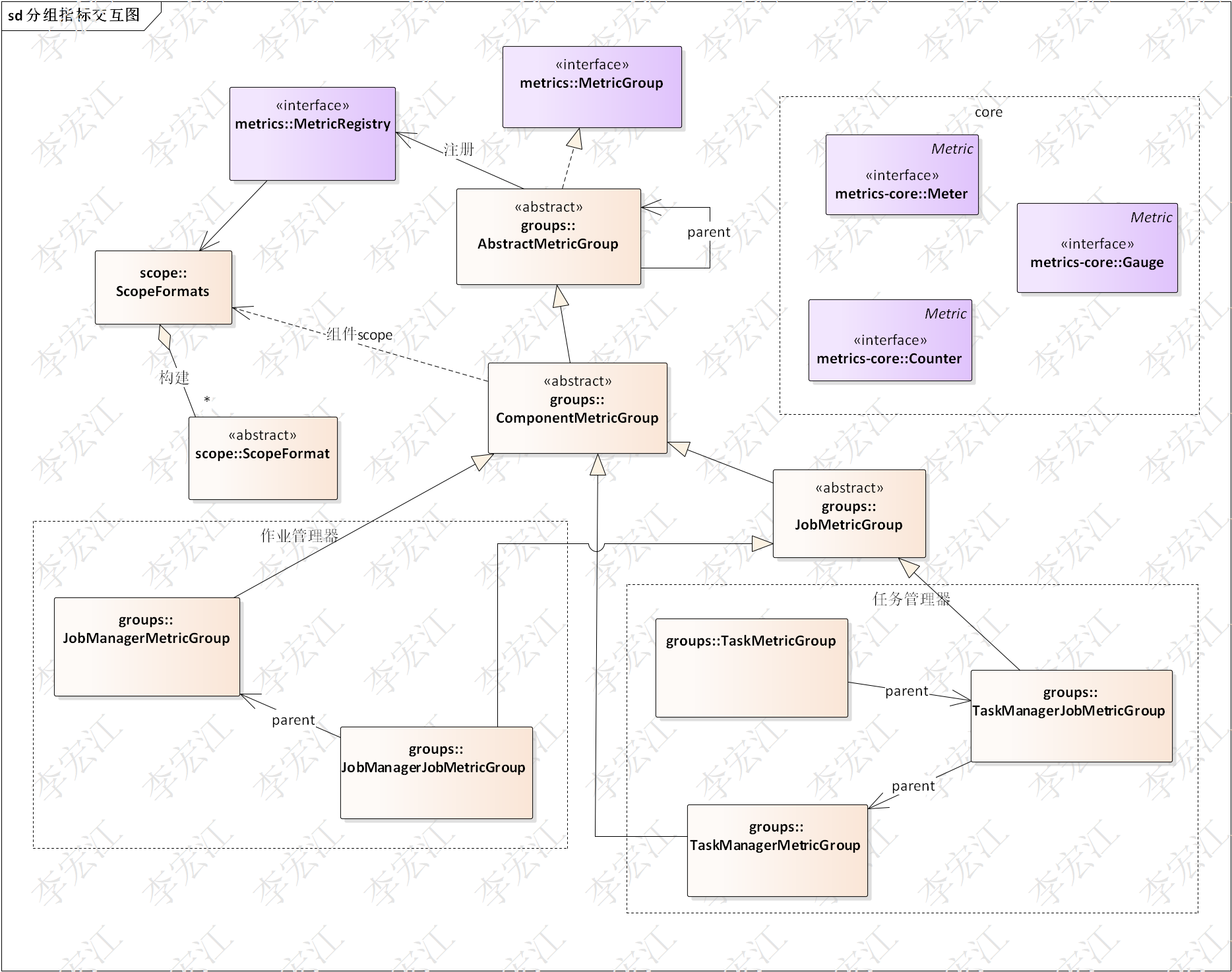
flink源码分析之功能组件(一)-metrics
简介 本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metric,future。其中kubeclient上一个系列介绍过,本系列不在介绍。 本文介绍flink metrics组件,metric…
【Flink on k8s】- 8 - Flink kubernetes operator 的架构和设计
目录
1、整体介绍
2、架构体系
2.1 架构介绍
2.2 Control loop(控制循环)
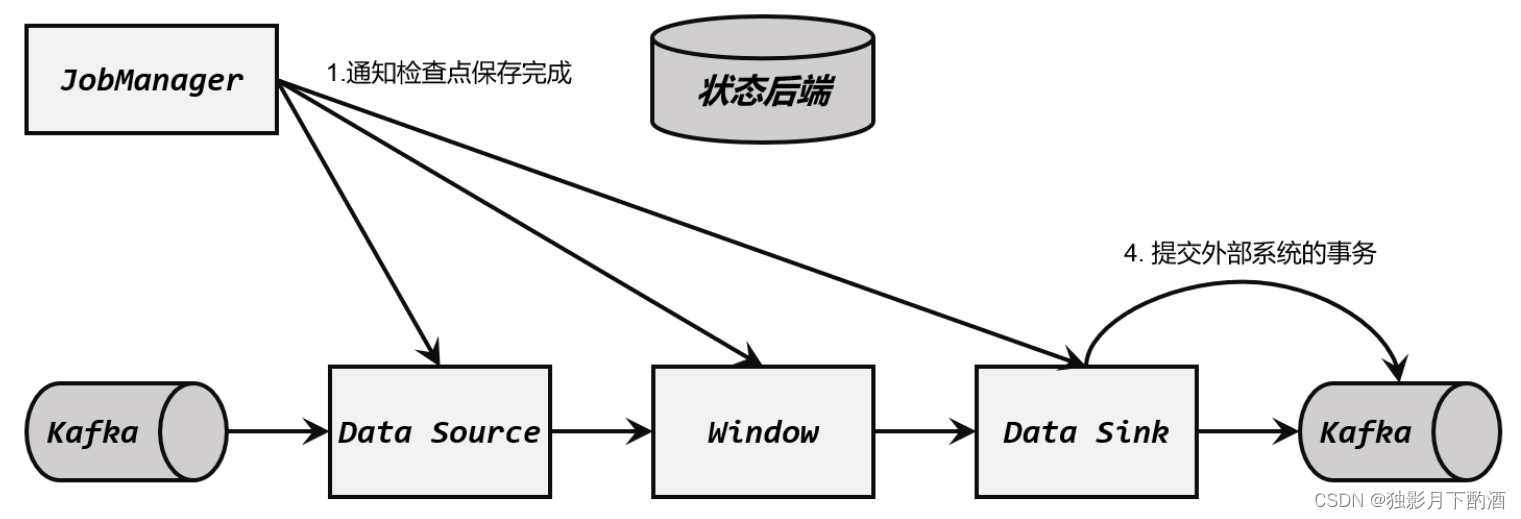
Flink中的状态一致性
1.概念 一致性其实就是结果的正确性。对于分布式系统而言,从不同节点读取时总能得到相同的值;而对于事务而言,是要求提交更新操作后,能够读取到新的数据。
有状态的流处理,内部每个算子任务都可以有自己的状态。对于流…
Flink: checkPoint
序言
依据1.17.1 最新版本的内容研究下期运作原理,总的来说其实就是设置一些参数,这些参数就会影响到如何存储checkpoint的问题.用起来没什么难的,参数配置的组合到是挺多cuiyaonan2000163.com 参考资料:
Checkpointing | Apache FlinkState Backends | Apache Flink Checkpo…
大数据-玩转数据-Flink SQL编程实战 (热门商品TOP N)
一、需求描述
每隔30min 统计最近 1hour的热门商品 top3, 并把统计的结果写入到mysql中。
二、需求分析
1.统计每个商品的点击量, 开窗2.分组窗口分组3.over窗口
三、需求实现
3.1、创建数据源示例
input/UserBehavior.csv
543462,1715,1464116,pv,1511658000
662867,22…
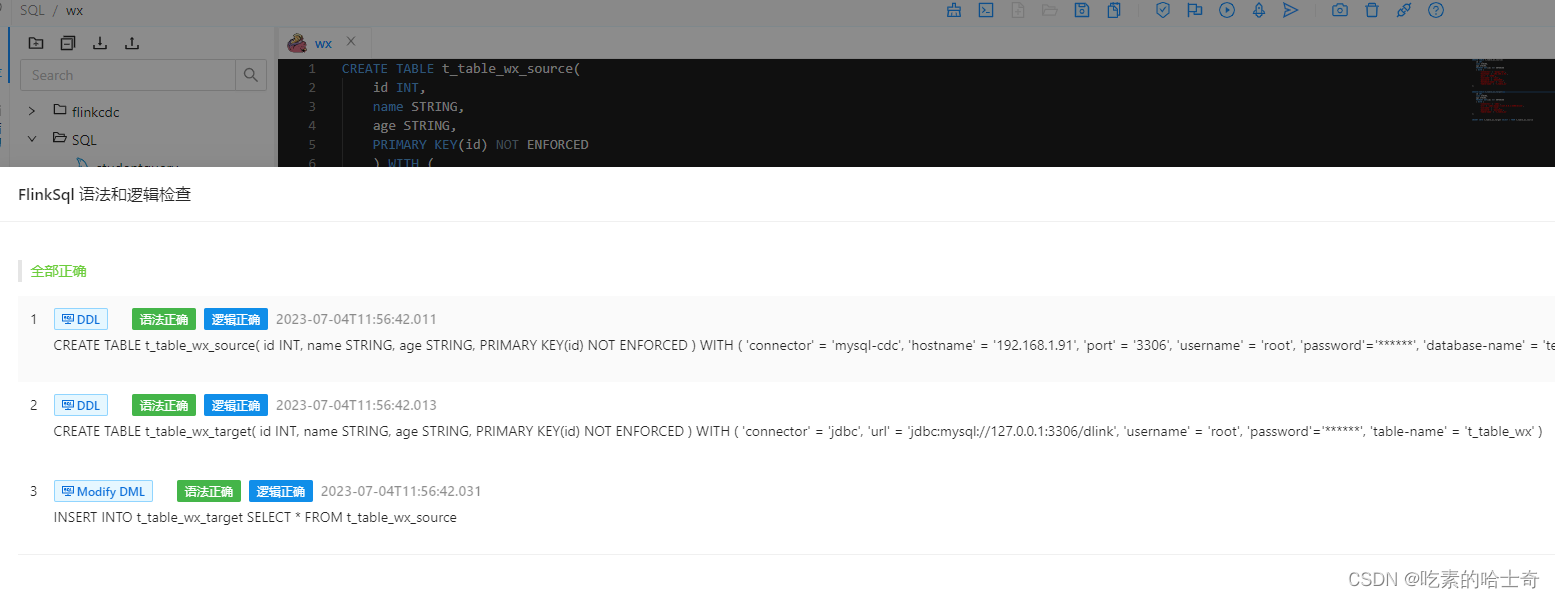
【现场问题】flink-cdc,sql一直校验不通过,为什么,明明sql没有错误
flink-cdc 问题展示问题解决校验结果 问题展示 这里的flink-cdc的sql对了好几遍,都没问题,包括单个执行create,也是显示校验通过 如图: 但是多个一起就报错了: java.lang.IllegalArgumentException: only single state…
Kubernetes外挂配置管理—ConfigMap介绍
目录贴:Kubernetes学习系列 其他容器编排调度工具会大谈特谈“轻应用”、“十二要素应用”,这样就势必会对企业级复杂应用做很大的改动。Kubernetes是为了解决“如何合理使用容器支撑企业级复杂应用”这个问题而诞生的,所以它的设计理念是要支…
【Flink】FlinkCDC自定义反序列化器
在我们用FlinkCDC采集mysql数据(或其他数据源)的时候,FlinkCDC输出的格式不标准,不利于我们后续做数据处理,我们通常会使用自定义反序列化器来格式化采集数据方便后续处理
常规的反序列化器如下: public class FlinkDataStreamCDC {public static void main(String[] ar…

幸福里基于 Flink Paimon 的流式数仓实践
摘要:本文整理自字节跳动基础架构工程师李国君,在 Streaming Lakehouse Meetup 的分享。幸福里业务是一种典型的交易、事务类型的业务场景,这种业务场景在实时数仓建模中遇到了诸多挑战。本次分享主要介绍幸福里业务基于 Flink & Paimon …
Hologres + Flink 流式湖仓建设
Hologres + Flink 流式湖仓建设 1 Flink + Hologres 特性1.2 实时维表 Lookup1.3 高性能实时写入与更新1.4 多流合并1.5 Hologres 作为 Flink 的数据源1.6 元数据自动发现与更新2 传统实时数仓分层方案2.1传统实时数仓分层方案 1:流式 ETL2.2 传统实时数仓分层方案 2:定时调度…
Hudi的Flink配置项(1)
名词
FallbackKeys
备选 keys,可理解为别名,当指定的 key 不存在是,则找备选 keys,在这里指配置项的名字。
相关源码
FlinkOptions
// https://github.com/apache/hudi/blob/master/hudi-flink-datasource/hudi-flink/src/ma…
【FLink】水位线(Watermark)
目录
1、关于时间语义
1.1事件时间
1.2处理时间编辑
2、什么是水位线
2.1 顺序流和乱序流
2.2乱序数据的处理
2.3 水位线的特性
3 、水位线的生成
3.1 生成水位线的总体原则
3.2 水位线生成策略
3.3 Flink内置水位线
3.3.1 有序流中内置水位线设置
3.4.2 断点式…
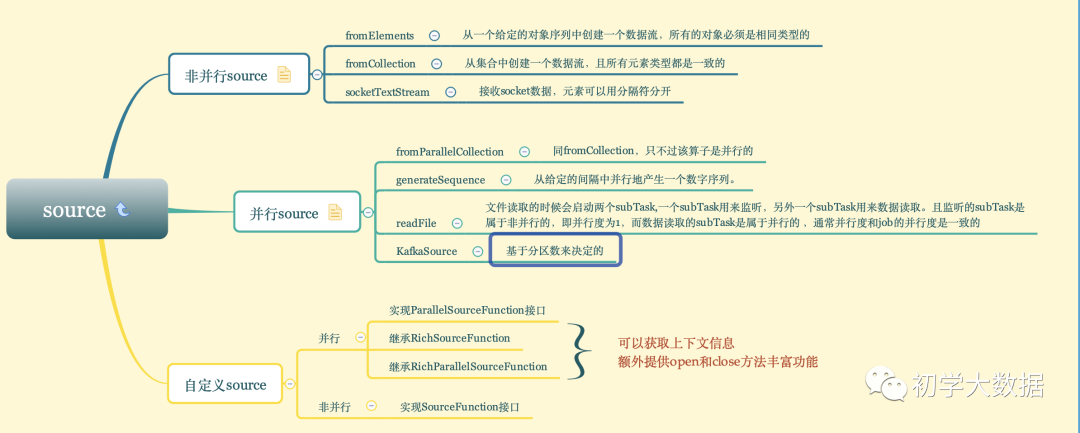
flink从入门到放弃之入门篇(二)-Source操作
1.Flink预定义Source操作
在flink中,source主要负责数据的读取。
flink预定义的source中又分为「并行source(主要实现ParallelSourceFunction接口)「和」非并行source(主要实现了SourceFunction接口)」
附上官网相关的说明:
you can always write …

【Flink学习】入门教程之概览
文章目录概览整套教程的目标与覆盖范围基础概念Stream Processing 流处理Parallel Dataflows 并行DataflowsTimely Stream Processing 自定义时间流处理Stateful Stream Processing 有状态流处理Fault Tolerance via State Snapshots 通过状态快照实现的容错概览
官网文章地址…

【需要继续修改】Flink简介及安装部署
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。
Flink支持一下安装部署模式࿱…
Flink 中的 Evictors(剔除器) 部分源码剖析 及示例代码
Flink的窗口模型允许除了WindowAssigner和Trigger之外还指定一个可选的Evictou。可以试用evictor(…)方法来完成此操作。Evictor可以在Trigger处罚后,应用Window Function之前或之后从窗口中删除元素。
源码:
public interface Evictor<T, W extend…


Flink 中的EventTime详细概念 及示例代码
Flink时间窗口的计算中,支持多种时间的概念:Processsing,IngestionTime,EventTime。 如果在Flink中用户不做任何设置,默认使用的是ProcesssingTime,其中ProcesssingTime,IngestionTime都是由计算…

Apache Flink(六):Apache Flink快速入门 - Flink案例实现
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录
Flink 中Join操作概念及 示例代码
Window Join
窗口join将共享相同key并位于同一窗口中的两个流的元素连接在一起。可以试用WindowAssigner定义这些窗口,并根据两个流的元素对其进行评估。然后将双方的元素传递到用户定义的JoinFunction或FlatJoinFunction,在此用户可以发出满足连接条件…
第二章 flink安装启动,完成批处理、流处理任务
2.1 搭建 maven 工程 FlinkTutorial 2.1.1 pom 文件 <?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation…

Flink 中的 Window Assigners(窗口分配器)
Window Assigners
指定流是否为keyed之后,下一步是定义Window Assigner。Window Assigners定义了如何将元素分配给Window。这是通过window (...)(对于keyed流)或windowAll()(对于非keyed流)调用中指定您选择的WindowA…
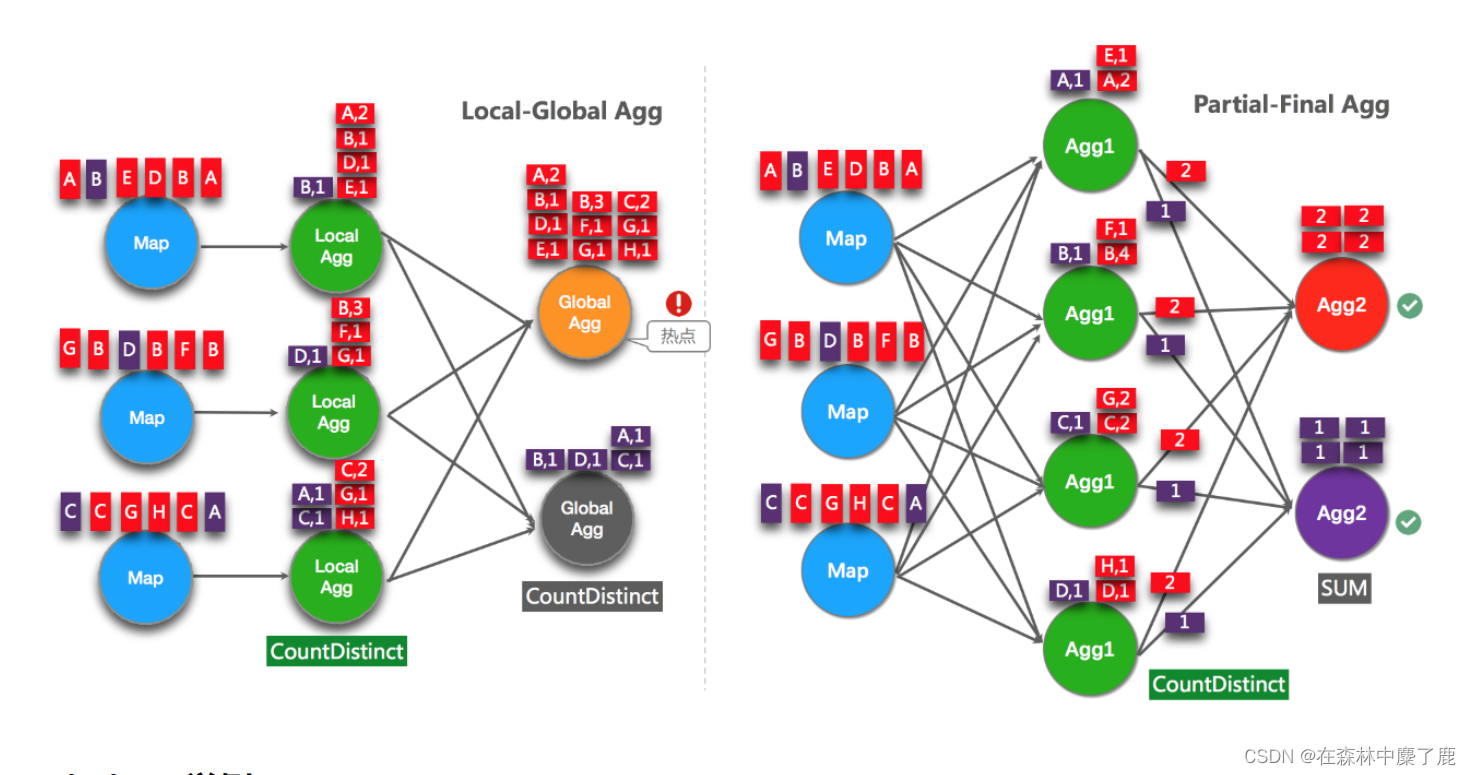
Flink 优化(六) --------- FlinkSQL 调优
目录一、设置空闲状态保留时间二、开启 MiniBatch三、开启 LocalGlobal四、开启 Split Distinct五、多维 DISTINCT 使用 Filter六、设置参数总结FlinkSQL 官网配置参数:
https://ci.apache.org/projects/flink/flink-docs-release-1.13/dev/table/config.html
一、…
【Apache-StreamPark】Flink 开发利器 StreamPark 的介绍、安装、使用
【Apache-StreamPark】Flink 开发利器 StreamPark 的介绍、安装、使用 1)框架介绍与引入1.1.🚀 什么是 StreamPark1.2.🎉 Features1.3.🏳🌈 组成部分1.4.引入 StreamPark 2)安装部署2.1.环境要求2.2.Hado…
GZ033 大数据应用开发赛题第03套
2023年全国职业院校技能大赛
赛题第03套 赛项名称: 大数据应用开发
英文名称: Big Data Application Development
赛项组别: 高等职业教育组
赛项编号: GZ033 …
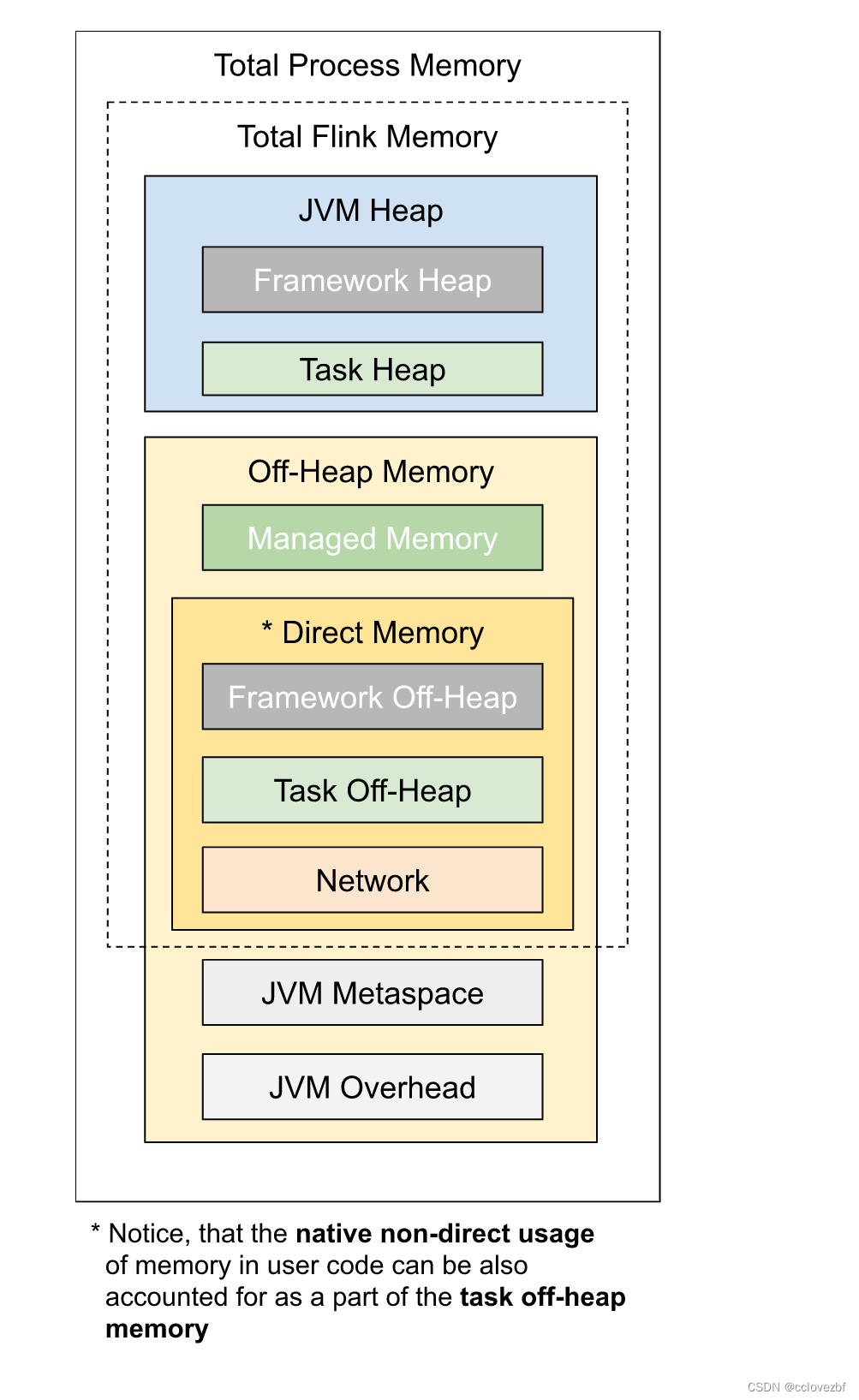
SparkStreaming与Flink的区别 (面试层面~)
Flink 是标准的实时处理引擎,基于事件驱动。而 Spark Streaming 是微批(Micro-Batch)的模型。 可以由下面几个方面介绍两个框架的主要区别:
运行角色:
Spark Streaming 运行时的角色(standalone 模式)主要有…
【Flink实战系列】Flink累加器的使用(accumulator)
Flink的Accumulator即累加器,与Saprk Accumulator 的应用场景差不多,都能很好地观察task在运行期间的数据变化 可以在Flink job任务中的算子函数中操作累加器,但是只能在任务执行结束之后才能获得累加器的最终结果。spark的累加器用法.
Flink中累加器的用法非常的简单:
1:…
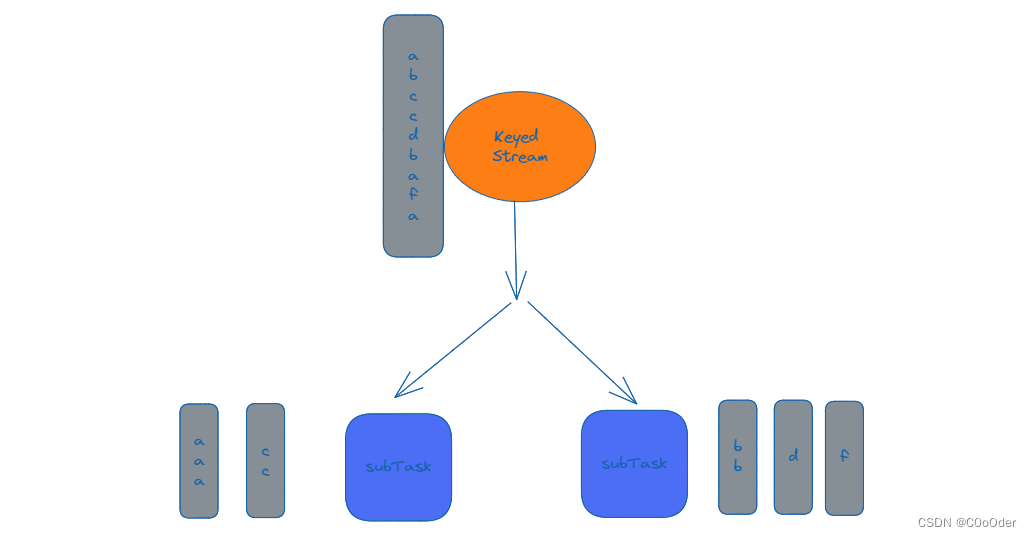
Flink中KeyedStateStore实现--怎么做到一个Key对应一个State
背景
在Flink中有两种基本的状态:Keyed State和Operator State,Operator State很好理解,一个特定的Operator算子共享同一个state,这是实现层面很好做好的。 但是 Keyed State 是怎么实现的?一般来说,正常的…

大数据Flink(一百零二):SQL 聚合函数(Aggregate Function)
文章目录
SQL 聚合函数(Aggregate Function) SQL 聚合函数(Aggregate Function)
Python UDAF,即 Python AggregateFunction。Python UDAF 用来针对一组数据进行聚合运算,比如同一个 window 下的多条数据、或者同一个 key 下的多条数据等。针对同一组输入数据,Python A…

flink中如何把DB大表的配置数据加载到内存中对数据流进行增强处理
背景
在处理flink的数据流时,比如处理商品流时,一般我们从kafka中只拿到了商品id,此时我们需要把商品的其他配置信息比如品牌品类等也拿到,此时就需要关联上外部配置表来达到丰富数据流的目的,如果外部配置表很大&…
【Flink】FlinkSQL中执行计划以及如何用代码看执行计划
FilnkSQL怎么查询优化 Apache Flink 使用并扩展了 Apache Calcite 来执行复杂的查询优化。 这包括一系列基于规则和成本的优化,例如: • 基于 Apache Calcite 的子查询解相关 • 投影剪裁 • 分区剪裁 • 过滤器下推 • 子计划消除重复数据以避免重复计算 • 特殊子查询重写,…
Flink kafka 数据汇不指定分区器导致的问题
背景
在flink中,我们经常使用kafka作为flink的数据汇,也就是目标数据的存储地,然而当我们使用FlinkKafkaProducer作为数据汇连接器时,我们需要注意一些注意事项,本文就来记录一下
使用kafka数据汇连接器
首先我们看…

Flink构造宽表实时入库案例介绍
1. 安装包准备 Flink 1.15.4 安装包 Flink cdc的mysql连接器 Flink sql的sdb连接器 MySQL驱动 SDB驱动 Flink jdbc的mysql连接器 2. 入库流程图 3. Flink安装部署
上传Flink压缩包到服务器,并解压 tar -zxvf flink-1.14.5-bin-scala_2.11.tgz -C /opt/
复…
17、Flink 之Table API: Table API 支持的操作(2)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
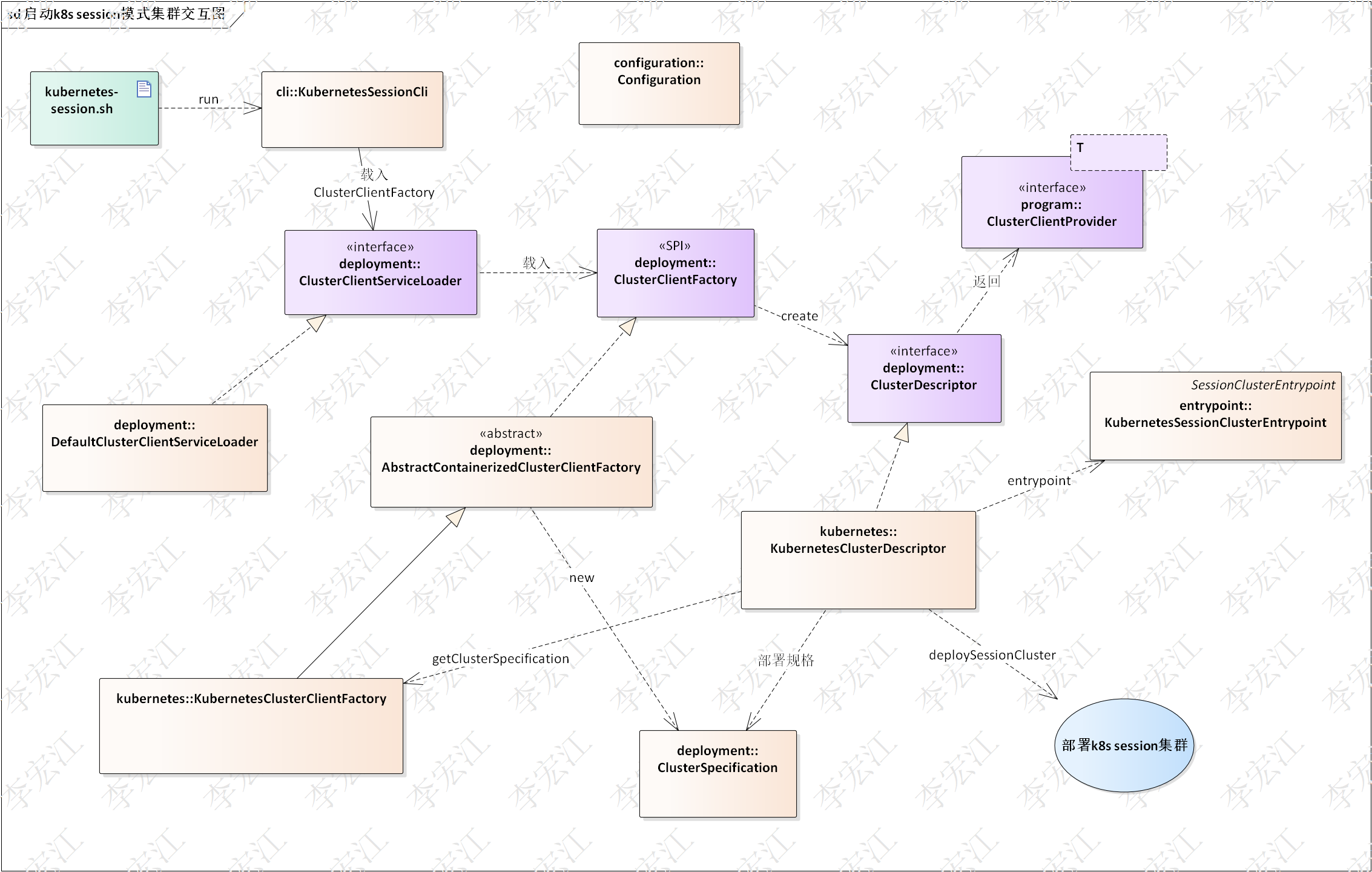
flink集群与资源@k8s源码分析-集群
0 介绍
本文是flink集群与资源@k8s源码分析系列的第二篇-集群
1 场景 下面详细分析各用例
2 启动k8s集群
k8s集群支持session和application模式,job模式将会被废弃,本文分析session模式集群 Configuration作为配置容器,几乎所有的构建需要从配置类获取配置项,这里不显示…

flink 1.18 sql gateway /sql gateway jdbc
一 sql gateway
注意 之所以直接启动gateway 能知道yarn session 主要还是隐藏的配置文件,但是配置文件可以被覆盖,多个session 保留最新的applicationid
1 安装flink (略)
2 启动sql-gatway(sql-gateway 通过官网介绍只能运行…

Flink/Doris生产环境方案选型的一些思考
各位总监,技术负责人,架构师们大家好。今天的文章有点短,是一些个人思考,仅做记录。 以Flink为主的计算组件和以Doris为代表的存储计算一体的方案选择问题是我们在技术选型过程中最常见的问题之一。也是很多公司和业务支持过程中会…
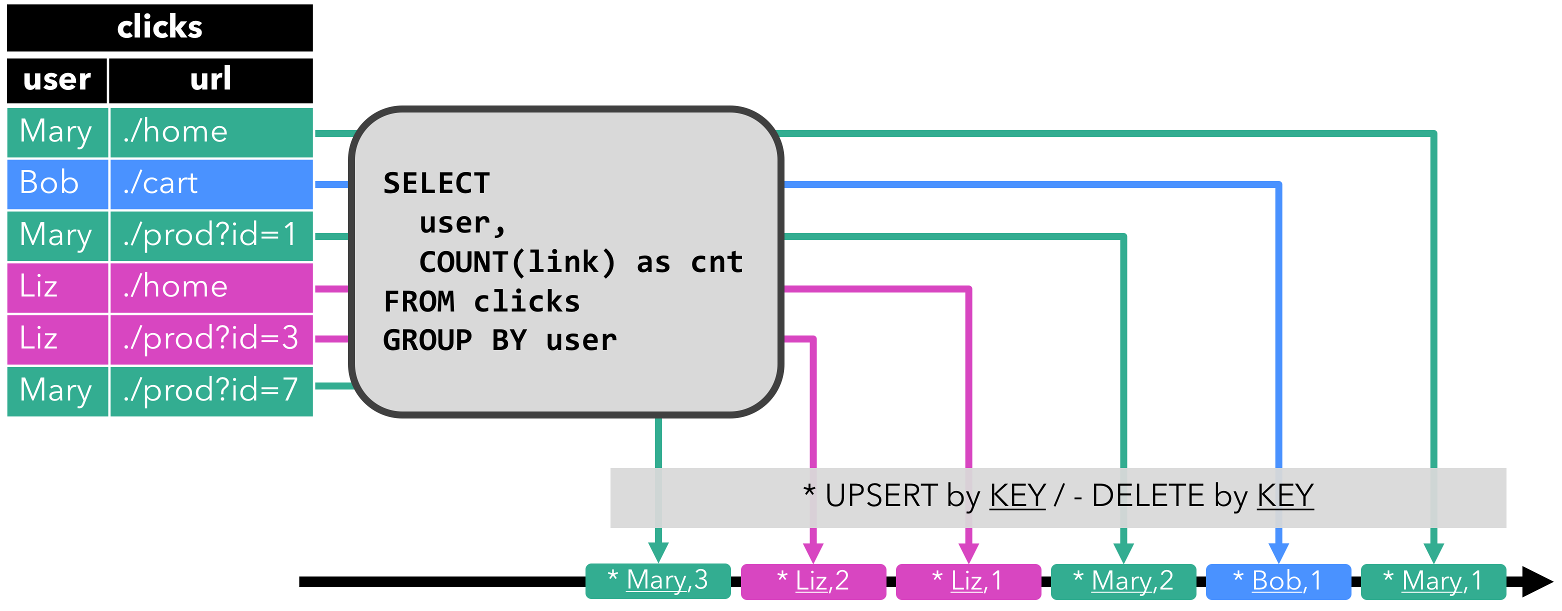
Flink-SQL——动态表 (Dynamic Table)
动态表 (Dynamic Table) 文章目录 动态表 (Dynamic Table)DataStream 上的关系查询动态表 & 连续查询(Continuous Query)在流上定义表连续查询更新和追加查询查询限制 表到流的转换总结 SQL 和关系代数在设计时并未考虑流数据。因此,在关系代数(和 SQL)之间几乎…

超越大数据的边界:Apache Flink实战解析【上进小菜猪大数据系列】
上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货。欢迎订阅专栏
Apache Flink是一种快速、可靠、可扩展的开源流处理框架,被广泛应用于大数据领域。本文将介绍Apache Flink的实战运用,包括其核心概念、架构设…
【Flink实战系列】Sort on a non-time-attribute field is not supported
org.apache.flink.table.api.TableException: Sort on a non-time-attribute field is not supported.
背景说明
在 Flink Streaming 场景下,执行一条非常简单的排序 SQL 语句
select * from test1 order by id desc提交任务的时候抛出下面的异常:
org.apache.flink.clie…
【Flink-1.17-教程】-【一】Flink概述、Flink快速入门
【Flink-1.17-教程】-【一】Flink概述、Flink快速入门 1)Flink 是什么1.1.有界流和无界流1.2.Flink 的发展史 2)Flink 特点3)Flink vs SparkStreaming4)Flink 的应用场景5)Flink 分层 API6)Flink 快速入门6…

Flink-容错机制
Flink中的容错机制
流式数据连续不断地到来,无休无止;所以流处理程序也是持续运行的,并没有一个明确的结束退出时间。机器运行程序,996 起来当然比人要容易得多,不过希望“永远运行”也是不切实际的。因为各种硬件软件…
MockKafka数据Flink消费写入Mysql/Oralce-工作实例
以下都是需要先在host文件配置映射的
首先看pom
<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownersh…
Flink - 11.Scala/Java trigger 简介与使用
一.引言
Flink 使用 windowAll 生成 AllwindowedStream 后调用 Trigger 执行窗口触发逻辑,下面对 Trigger 触发器做一个基本的了解。 二.Trigger 简介
Trigger 翻译为触发,扳机,其作用为在一定条件下触发窗口进行计算,如果是内部 operator 则执行对应 operator,如果自定…
【Flink实战系列】Flink SQL 字符串类型的字段如何实现列转行?
Flink SQL 字符串类型的字段如何实现列转行?
问题描述
普通的列转行可以参考这篇文章,https://mp.weixin.qq.com/s/3oQRUO0A8G96qbM97UuisA
通常情况下,列转行的需求都是在一个 Array 里面是 Row 类型这样的结构下才可以使用上面的方式,那如果字段是 String 类型的,而且…

修炼k8s+flink+hdfs+dlink(四:k8s(一)概念)
一:概念
1. 概述
1.1 kubernetes对象.
k8s对象包含俩个嵌套对象字段。 spec(规约):期望状态 status(状态):当前状态 当创建对象的时候,会按照spec的状态进行创建,如果…
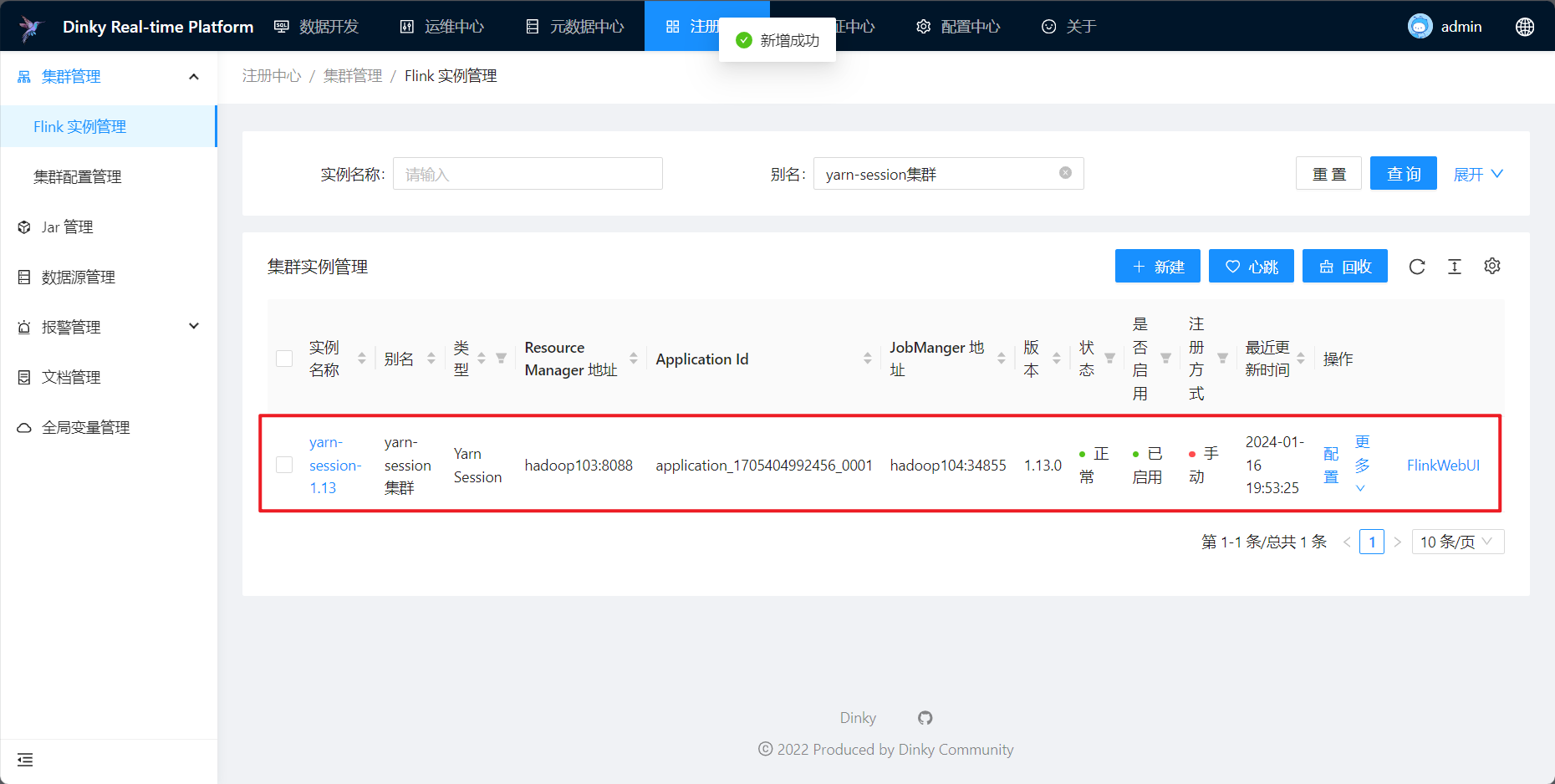
Dinky创建Flink实例报错
Dinky版本:0.7.3
Flink版本:1.13.0
问题描述
问题1:已有实例不显示
在Dinky的【注册中心】—【Flink实例管理】中: hadoop集群以及zookeeper重启后,之前创建的一个yarn-session实例莫名其妙找不到了;
…

Flink 学习五 Flink 时间语义
Flink 学习五 Flink 时间语义
1.时间语义
在流式计算中.时间是一个影响计算结果非常重要的因素! (窗口函数,定时器等) Flink 可以根据不同的时间概念处理数据。
处理时间: process time System.currentTimeMillis()是指执行相应操作的机器系统时间(也称为纪元时间…
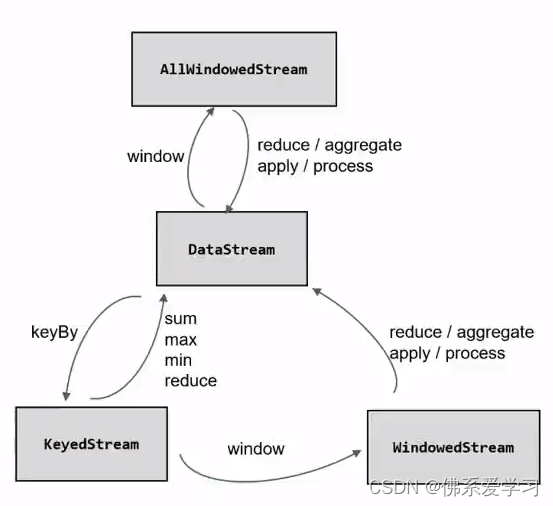
Flink中的时间和窗口(时间语义,水位线,窗口,迟到数据的处理)
目录
Flink中的时间和窗口 1时间语义
1.1Flink中的时间语义 1.1.1处理时间 1.1.2事件时间
1.2那种时间语义更重要 2 水位线
2.1 事件时间和窗口
2.2 什么是水位线
2.3 如何生成水位线
2.3.1使用WatermarkGenerator
2.3.2使用SourceFunction
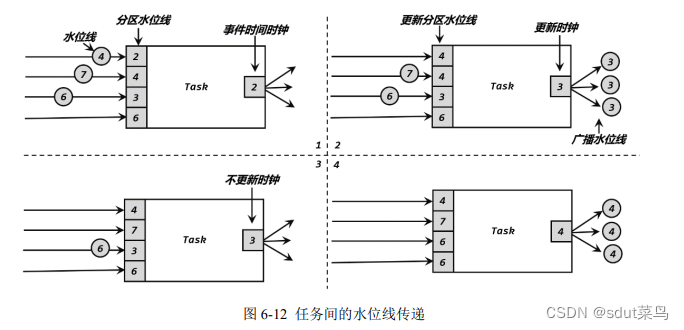
2.4 水位线的传递
2.5 水位…
Flink自定义聚合函数与滑动时间窗口共同实现环比
业务场景:后五分钟的数据和前五分钟的数据做环比,得出比值再进行后续的操作,即使有此函数,还是需要和 滑动时间窗口(HOP) 一起使用,,阿里云FlinkSQL滑动窗口介绍 不能触碰公司红线,所以代码是从flink官方文…

大数据平台框架、组件以及处理流程详解
数据产品和数据密不可分作为数据产品经理理解数据从产生、存储到应用的整个流程,以及大数据建设需要采用的技术框架Hadoop是必备的知识清单,以此在搭建数据产品时能够从全局的视角理解从数据到产品化的价值。本篇文章从三个维度:
1.大数据的…
Flink面试题(二)
什么是 Flink 的窗口函数?它们有哪些类型?
答:Flink 窗口函数用于将流数据按照一定的规则划分成窗口,并对每个窗口的数据进行聚合或转换操作。常见的窗口类型包括滚动窗口、滑动窗口和会话窗口。
解释一下 Flink 的状态管理是如…
【极数系列】Flink环境搭建(02)
【极数系列】Flink环境搭建(02)
引言
1.linux
直接在linux上使用jdk11flink1.18.0版本部署
2.docker
使用容器部署比较方便,一键启动停止,方便参数调整
3.windows
搭建Flink 1.18.0版本需要使用Cygwin或wsl工具模拟unix环境…

大数据时代个人学习篇
众志成城抗击疫情,不要出门,在家学习,共度难关。
牛津大学职业研究分析报告可以看到,大数据智能时代首先取代的是比较有规则的职业,如重复性、机械性的会被淘汰,终身学习、人文沟通、信息化与数字化、智能…
FlinkAPI开发之状态管理
案例用到的测试数据请参考文章: Flink自定义Source模拟数据流 原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048
Flink中的状态
概述
有状态的算子 状态的分类
托管状态(Managed State)和原始状态&…
Flink / Scala - 10.TimeWindow And TimeWindowAll 详解
一.引言
Flink 流处理用于处理源源不断的数据,之前介绍过 processFunction,该方法会对单个元素进行处理,除此之外,还有一种批量数据处理的方法就是 TimeWindow 以及 TimeWindowAll,Flink 时间窗口可以看作是对无线数据流设置的有限数据集,即流处理框架下的批处理。窗口下…

Flink CEP 在抖音电商的业务实践
摘要:本文整理自抖音电商实时数仓研发工程师张健,在 FFA 实时风控专场的分享。本篇内容主要分为四个部分:Flink CEP 简介业务场景与挑战解决方案实践未来展望Tips:点击「阅读原文」查看原文视频&演讲 ppt01Flink CEP 简介Flin…
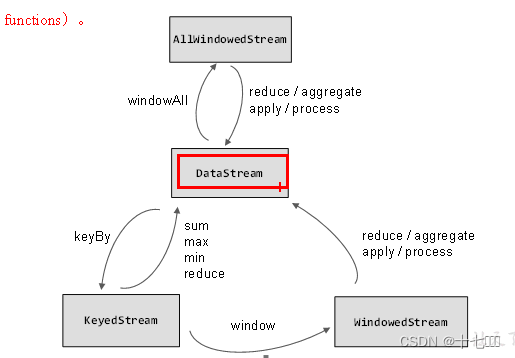
Flink之流的转换
ProcessFuncion处理函数
功能 拥有富函数功能 - 生命周期方法 - 状态编程对元素的处理功能processElement, 在不同的处理函数中,该方法的名字略有区别定时器编程 TimeService:定时服务,可以用于注册定时器,删除定时器ontimer():定时器触发后会自动调用该…

Flink - 15.最新 StateBackend 状态后端详解
一.引言
使用 DataStreaming 编写流式程序时通常结合 KeyedStream 实现状态的读取与更新,为了防止数据丢失并持续恢复,状态在检查点的持久化方式和位置取决于 StateBackend,下面基于 1.8.x 和 1.13.x 新老版本的状态后端进行分析以及工程环境下状态后端的使用与调优。 二. …
Flink - 13.CountAndProcessingTimeTrigger 基于 Count 和 Time 触发窗口
一.引言
上一篇文章提到了 CountTrigger && ProcessingTimeTriger,前者 CountTrigger 指定 count 数,当窗口内元素满足逻辑时进行一次触发,后者通过 TimeServer 注册窗口过期时间,到期后进行一次触发,本文自定义 Trigger 实现二者的合并即 Count 和 ProcessingTi…

Flink(九)【时间语义与水位线】
前言 2023-12-02-20:05,终于写完啦,最近状态不错。刚写完又收到了她的消息哈哈哈哈,开心。 再去全力打拼一次,奋战一场,就算最后打了败仗也无所谓,至少你留下了足迹。 《解忧杂货店》 1、时间语义 …

生态扩展:Flink Doris Connector
生态扩展:Flink Doris Connector
官网地址: https://doris.apache.org/zh-CN/docs/dev/ecosystem/flink-doris-connector flink的安装:
tar -zxvf flink-1.16.0-bin-scala_2.12.tgz
mv flink-1.16.0-bin-scala_2.12.tgz /opt/flinkflink环境…
RocketMQ Flink Catalog 设计与实践
摘要:本文为 RocketMQ Flink Catalog 使用指南。主要内容包括: Flink 和 Flink CatalogRocketMQ Flink ConnectorRocketMQ Flink Catalog 作者:李晓双 ,Apache RocketMQ Contributor
Mentor:蒋晓峰,Apache…
GZ033 大数据应用开发赛题第08套
2023年全国职业院校技能大赛 赛题第08套 赛项名称: 大数据应用开发 英文名称: Big Data Application Development 赛项组别: 高等职业教育组 赛项编号: GZ033 …
Flink从入门到精通系列(三)
4、Flink 运行时架构
4.1、系统架构
Flink 就是一个分布式的并行流处理系统,简单来说,它会由多个进程构成,这些进程一般会分布运行在不同的机器上。
对于一个分布式系统来说,需要面对很多棘手的问题,其中的核心问题…
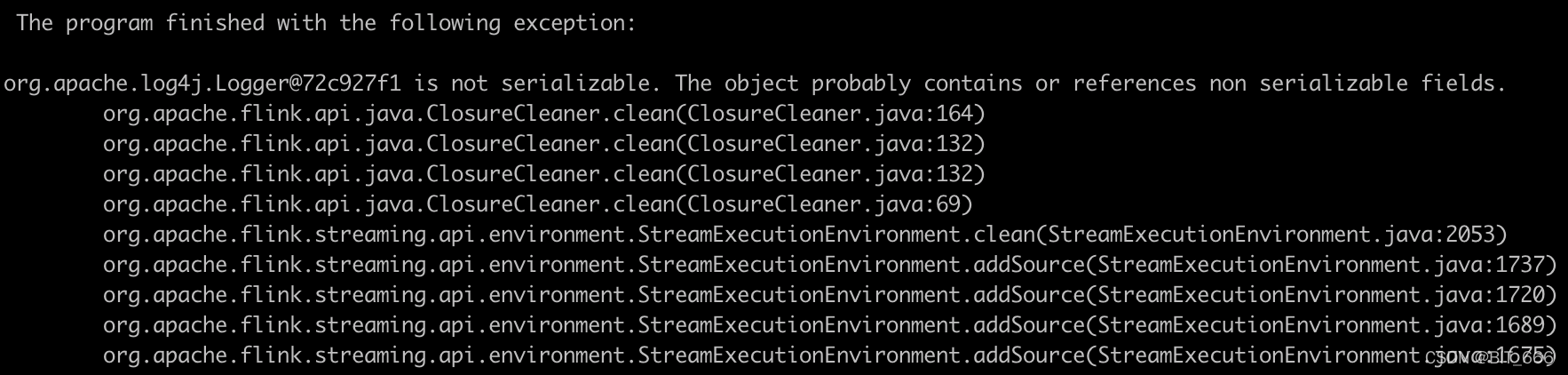
Flink 异常 - 2.The object probably contains or references non serializable fields 无法序列化问题
一.引言
使用 Flink 自定义 Source 生成数据时,集群提交任务时显示 org.apache.log4j.Logger@72c927f1 is not serializable. The object probably contains or references non serializable fields. 报错序列化相关错误 : 二.问题解决
1.Scala Class 初始化不需要对应变量 …

Flink 异常 - 10.checkpoint Failure reason: Not all required tasks are currently running
一.引言
Flink 程序增加 readFile 生成文件流后,最初运行期间 CheckPoint 存储没有问题,待文件流 Finished 后 CheckPoint 存储报错: checkpoint Failure reason: Not all required tasks are currently running,下面分析并解决下。 二.错误分析与解决
1.问题排查
Flink …

Elasticsearch 集成--Flink 框架集成
一、Flink 框架介绍 Apache Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。 Apache Spark 掀开了内存计算的先河,以内存作为赌注,赢得了内存计算的飞速发展。 但是在其火热的同时,开发人员发现,在 Spark …
RecordWriter核心设计实现
文章目录 1.准备RecordWriter2.RecordSerializer序列化3.拷贝到MemorySegment获取BufferBuilder数据拷贝到MemorySegment中 StreamTask所对应的OperatorChain内的最后一个StreamOperator处理后的数据,是通过RecordWriterOutput输出到网络的,而RecordWrit…

Flink从入门到精通之-06Flink 中的时间和窗口
Flink从入门到精通之-06Flink 中的时间和窗口
我们已经了解了基本 API 的用法,熟悉了 DataStream 进行简单转换、聚合的一些操作。除此之外,Flink 还提供了丰富的转换算子,可以用于更加复杂的处理场景。 在流数据处理应用中,一个…
45、Flink 的指标体系介绍及验证(1)-指标类型及指标实现示例
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
cdh6.3.2 Flink On Yarn taskmanager任务分配倾斜问题的解决办法
业务场景:
Flink On Yarn任务启动
组件版本:
CDH:6.3.2 Flink:1.13.2 Hadoop:3.0.0
问题描述:
在使用FLink on Yarn调度过程中,发现taskmanager总是分配在集中的几个节点上,集群…
Flink算子如何限流
目录
使用方法
调用类图
内部源码
GuavaFlinkConnectorRateLimiter
RateLimiter 使用方法
重写AbstractRichFunction中的open()方法,在处理数据前调用limiter.acquire(1);
调用limiter.open(getRuntimeContext())的源码,实际内部是RateLimiter,根据并行度算出subTask…
Flink从入门到放弃之入门篇(四)-剖析窗口生命周期
一、应用场景
Apache Flink可以说是目前大数据实时流处理最流行的技术,功能非常强大,支持开发和运行多种不同类型的应用程序。主要特性包括:批流一体化、状态管理、事件时间支持以及精准一次的状态一致性保障等。目前Flink的应用场景整体概括…
Flink有状态计算的状态容错
状态容错 State Fault Tolerance
首先来说一说状态容错。Flink 支持有状态的计算,可以把数据流的结果一直维持在内存(或 disk)中,比如累加一个点击数,如果某一时刻计算程序挂掉了,如何保证下次重启的时候&…
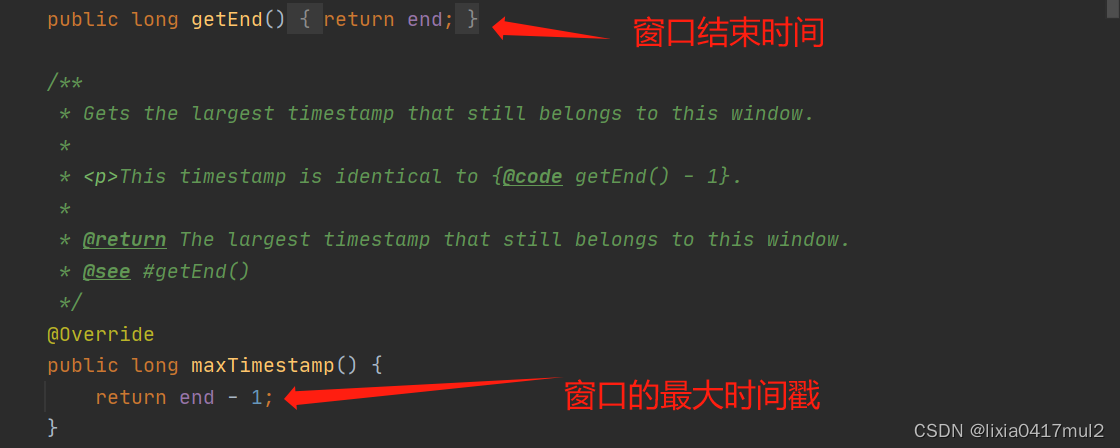
flink自定义窗口分配器
背景
我们知道处理常用的滑动窗口分配器,滚动窗口分配器,全局窗口分配器,会话窗口分配器外,我们可以实现自己的自定义窗口分配器,以实现我们的自己的窗口逻辑
自定义窗口分配器的实现
package wikiedits.assigner;i…
【实操记录】Oracle数据整库同步至Apache Doris
本文是Oracle数据整库同步至Apache Doris实操记录,仅供参考
参考:https://cn.selectdb.com/blog/104
1、Oracle 配置
[rootnode1 oracle]# pwd
/u01/app/oracle
[rootnode1 oracle]# mkdir recovery_area
[rootnode1 oracle]# chown -R oracle:dba re…
源码解析flink的GenericWriteAheadSink为什么做不到精确一次输出
背景
GenericWriteAheadSink是可以用于几乎是精准一次输出的场景,为什么说是几乎精准一次呢?我们从源码的角度分析一下
GenericWriteAheadSink做不到精准一次输出的原因
首先我们看一下flink检查点完成后通知GenericWriteAheadSink开始进行分段的记录…

计算机毕业设计之Spark+Flink餐饮大数据 外卖大数据 订餐推荐系统 外卖推荐系统 美食推荐系统 外卖数据分析 大数据毕业设计(大屏+支付+推荐算法)
开发技术
Spark
Flink
SpringBoot
Vue.js
支付宝沙箱支付
运行截图

⑦Flink常用核心概念
在 Flink 这个框架中,有很多独有的概念,比如分布式缓存、重启策略、并行度等,这些概念是我们在进行任务开发和调优时必须了解的,这一课时我将会从原理和应用场景分别介绍这些概念。
分布式缓存 熟悉 Hadoop 的你应该知道,分布式缓存最初的思想诞生于 Hadoop 框架,Hadoop…
GZ033 大数据应用开发赛题第02套
2023年全国职业院校技能大赛
赛题第02套 赛项名称: 大数据应用开发
英文名称: Big Data Application Development
赛项组别: 高等职业教育组
赛项编号: GZ033
背景描述
大数据时代背景下,电…
手把手教会如何使用Flink实现Mongo到Doris的数据同步
相关资料教程地址
flink 包下载地址
https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mongodb-cdc/flink-cdc 资料
https://github.com/ververica/flink-cdc-connectors/wiki/FAQ(ZH)
https://ververica.github.io/flink-cdc-connectors/release-2.1/conte…
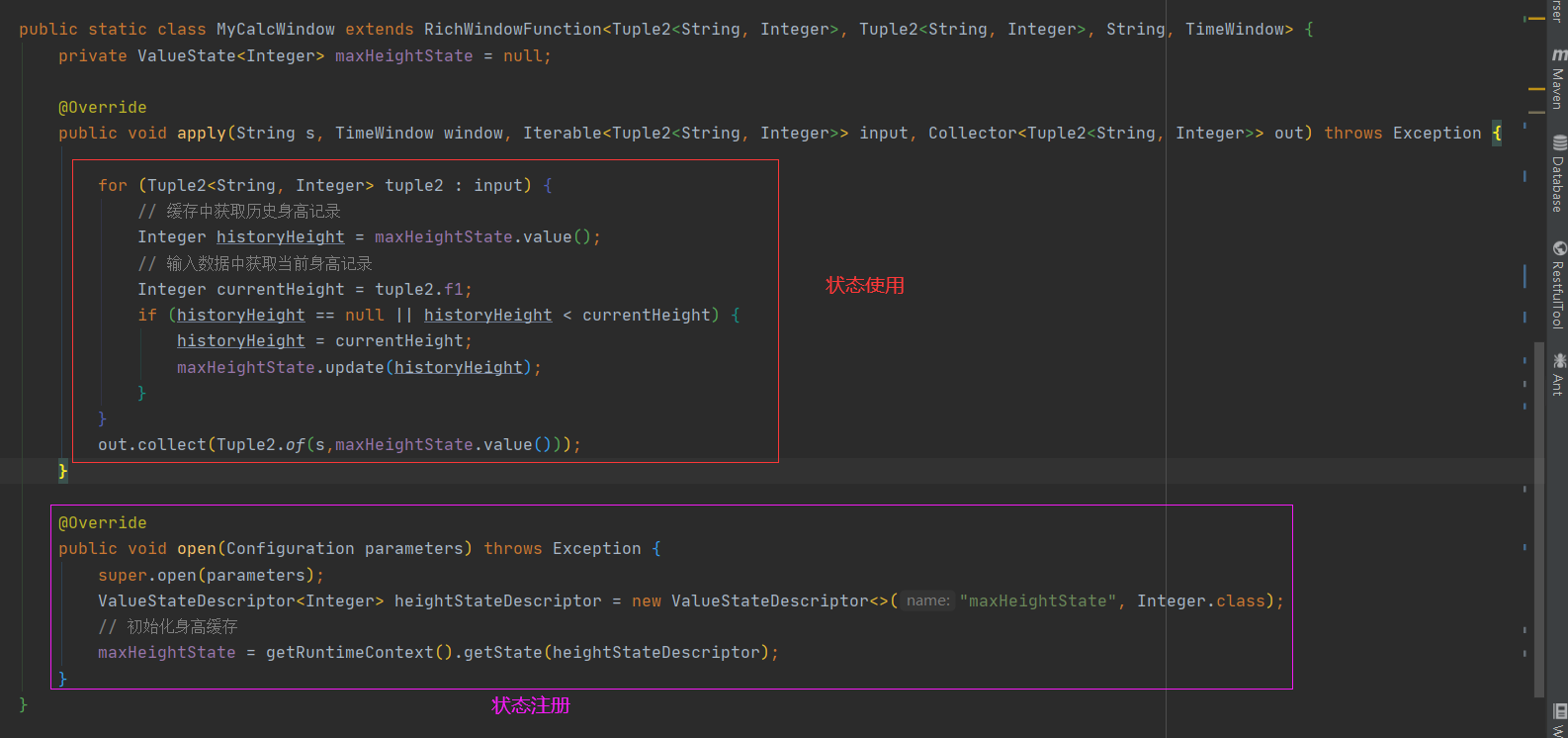
Flink Keyed State 使用步骤
前提
Keyed State作用在Keyed Stream流基础上(必要条件) 状态注册
Keyed State 需要通过 RuntimeContext 访问,因此Operator (算子)必须需要 是一个RichFunction或其实现
我们要对状态进行定义状态描述器࿰…

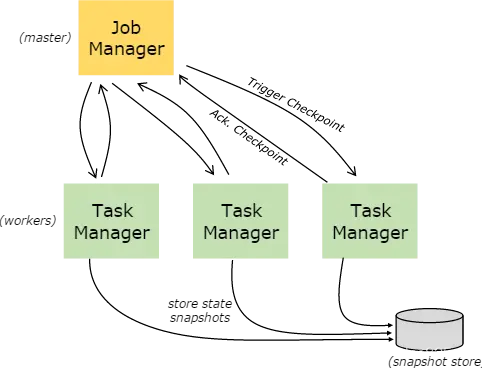
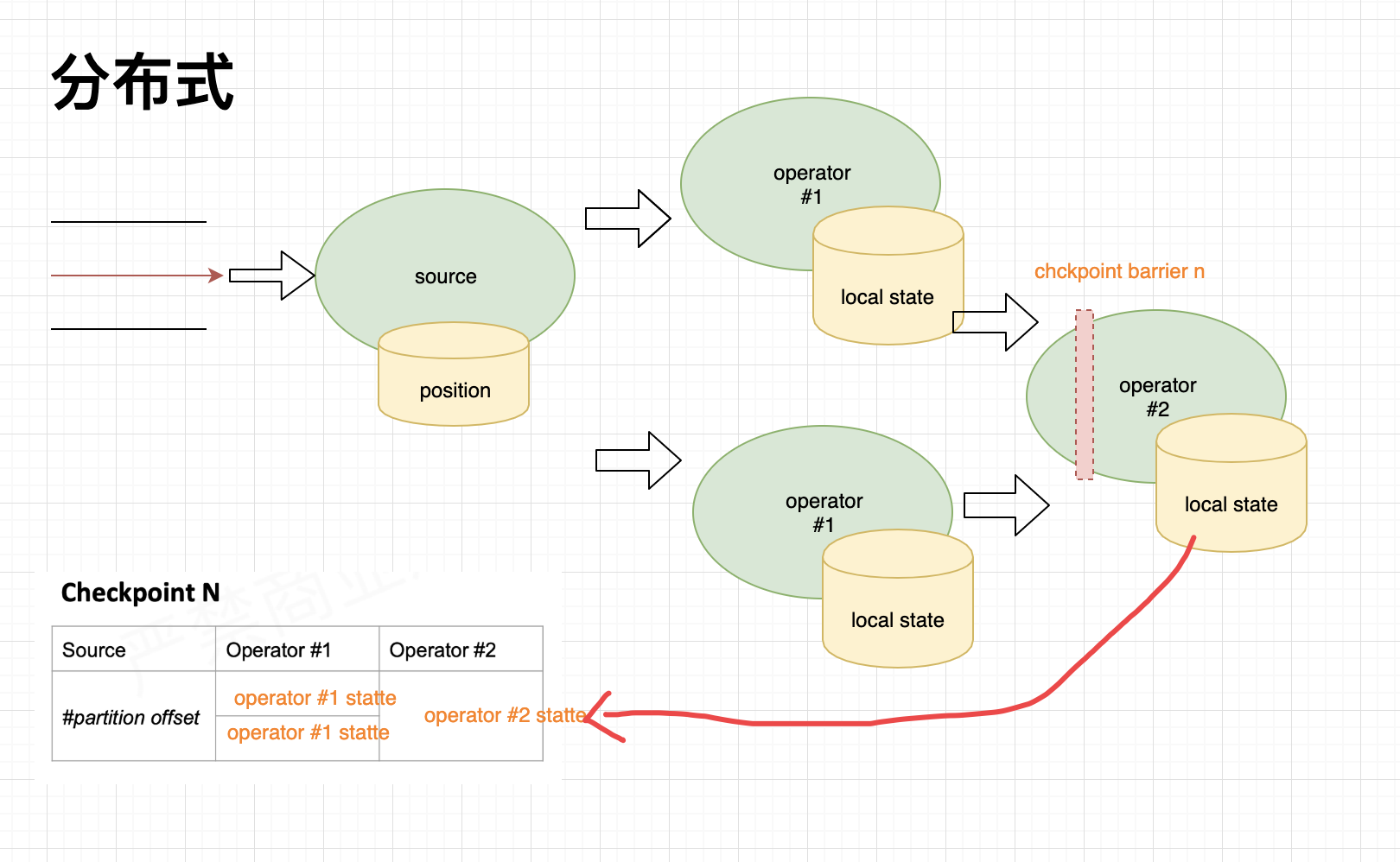
Flink---13、容错机制(检查点(保存、恢复、算法、配置)、状态一致性、端到端精确一次)
星光下的赶路人star的个人主页 大鹏一日同风起,扶摇直上九万里 文章目录 1、容错机制1.1 检查点(CheckPoint)1.1.1 检查点的保存1.1.2 从检查点恢复状态1.1.3 检查点算法1.1.3.1 检查点分界线(barrier)1.1.3.2 分布式快…
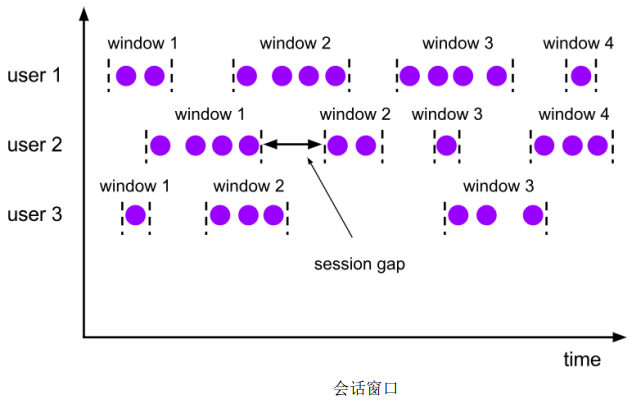
Flink学习——Flink中的时间语义和窗口
一、时间语义
1.1 为什么会出现时间语义? flink是一个大数据处理引擎,它的最大特点就是分布式。每一个机器都有自己的时间,那么集群当中的时间应该以什么为准呢? 比如:我们希望统计8-9点的数据时,对并行任…
【Flink on k8s】- 4 - 在 Kubernetes 上运行容器
目录
1、准备 k8s 集群环境、Docker 环境
2、启用 kubernetes
2.1 查询 k8s 集群基本状态
Flink-使用filter和SideOutPut进行分流操作
文章目录1.什么是分流?2. 过滤器(filter)3. 使用侧输出流(SideOutput)💎💎💎💎💎 更多资源链接,欢迎访问作者gitee仓库:https://gitee.com/fanggaolei/learni…

Flink 异常 - 5.本地执行 Failed to start the Queryable State Data Server
一.引言 Flink 本地执行任务报错 Failed to start the Queryable State Data Server 以及 Unable to start Queryable State Server. All ports in provided range are occupied. 根据报错分析是因为本地端口被占用,没有足够端口供 Flink Queryable DataServer启动,所以解决方…
Flink / Scala - 5.DataStream Transformations 常用转换函数详解
一.引言
本文介绍 Flink 的主要数据形式: DataStream,即流式数据的常用转换函数,通过 Transformation 可以将一个 DataStream 转换为新的 DataStream。
Tips:
下述介绍 demo 均采用如下 case class 作为数据类型,并通过自定义的 SourceFromCycle 函数每s 生成10个元素。特…

聊聊Hadoop、Storm、Spark Streaming、Flink在大数据领域的现状
Hadoop 生态组件竞争激烈,Spark 优势明显,MapReduce 已进入维护模式
曾有开发人员表示,Hadoop 主要是被 MapReduce 拖累了,其实 HDFS 和 YARN 都还不错。堵俊平( 腾讯云专家研究员)则认为 MapReduce 拖累 …
第三章 Flink 部署
Standalone 模式 安装
解压缩flink-1.10.1-bin-scala_2.12.tgz, 进入 conf 目录中。 修改 flink/conf/flink-conf.yaml 文件: 修改 /conf/slaves 文件:分发给另外两台机子: 启动:访问 http://localhost:8081 可以对 fl…

Flink1.17实战教程(第三篇:时间和窗口)
系列文章目录
Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…
Flink SQL -- 命令行的使用
1、启动Flink SQL
首先启动Flink的集群,选择独立集群模式或者是session的模式。此处选择是时session的模式:yarn-session.sh -d 在启动Flink SQL的client:
sql-client.sh
2、kafka SQL 连接器
在使用kafka作为数据源的时候需要上传jar包到…
flink cdc同步Oracle数据库资料到Doris问题集锦
问题1:flink 1.14 包 org.apache.flink.shaded.guava 版本冲突 java.lang.NoClassDefFoundError: org/apache/flink/shaded/guava18/com/google/common/util/concurrent/ThreadFactoryBuilder at com.ververica.cdc.debezium.DebeziumSourceFunction.open(DebeziumS…
Flink / SQL - 7.一文搞懂常规 Sql TopN 与 Sql Window TopN
目录
一.引言
二.数据准备
1.Event 事件类
2.Source 自定义源
3.DataStream To Table
三.常规 SQL TopN

尚硅谷大数据项目《在线教育之实时数仓》笔记008
视频地址:尚硅谷大数据项目《在线教育之实时数仓》_哔哩哔哩_bilibili 目录
第10章 数仓开发之DWS层
P066
P067
P068
P069
P070
P071
P072
P073
P074
P075
P076
P077
P078
P079
P080
P081
P082 第10章 数仓开发之DWS层
P066 第10章 数仓开发之DW…

【Flink-Bug】Flink 自定义 Sink 重写 RichSinkFunction 方法时重复调用 open 的解决方案
【Flink-Bug】Flink 自定义 Sink 重写 RichSinkFunction 方法时重复调用 open 的解决方案 Flink 自定义 RichinkFunction 时可能会重写 open 方法进行某些连接的初始化操作,但是会出现重复调用 open 方法的问题,如:MQ,如果重复调用…
【大数据】-- flink kubernetes operator 入门与实践
课程链接:https://edu.csdn.net/course/detail/38831
目录
课程链接:https://edu.csdn.net/course/detail/38831https://edu.csdn.net/course/detail/38831
一、你将收获
Flink学习笔记(四)State管理与恢复
一、什么是State State是指在Flink流处理系统中的状态,默认保存在Java的堆内存中,它是指在一个流处理任务中需要保存和维护的数据。这些数据可以是任何类型的,例如计数器、累加器、列表等。Flink State是在Flink应用程序的运行过程中创建和维…
Flink Table API 与 SQL 编程整理
Flink API总共分为4层这里主要整理Table API的使用
Table API是流处理和批处理通用的关系型API,Table API可以基于流输入或者批输入来运行而不需要进行任何修改。Table API是SQL语言的超集并专门为Apache Flink设计的,Table API是Scala和Java语言集成式…
Flink Watermark【博学谷学习记录】
1.概述
生活中有种场景:
车辆进入隧道,信号不好,出了隧道后,信号就正常了。
正常情况下,车辆进入隧道后,如果车辆正常,没有事故,会正常驶出隧道。
在正常的隧道行驶过程中&#…
Flink学习(一)
分布式计算框架
Java可以使用分布式计算来处理大规模的数据和计算任务,提高计算效率和性能。以下是一些Java分布式计算的例子: Apache Hadoop:Hadoop是一个开源的分布式计算框架,可以处理大规模数据集的分布式存储和处理。它使用Java编写,可以在分布式环境中运行MapReduc…
使用 Apache Flink 开发实时 ETL
Apache Flink 是大数据领域又一新兴框架。它与 Spark 的不同之处在于,它是使用流式处理来模拟批量处理的,因此能够提供亚秒级的、符合 Exactly-once 语义的实时处理能力。Flink 的使用场景之一是构建实时的数据通道,在不同的存储之间搬运和转…

基于Flink实时数仓——DWM 层-支付宽表(5)
需求分析与思路 支付宽表的目的,最主要的原因是支付表没有到订单明细,支付金额没有细分到商品上, 没有办法统计商品级的支付状况。 所以本次宽表的核心就是要把支付表的信息与订单宽表关联上。
解决方案有两个:
把订单宽表输出到…
Flink流批一体计算(10):PyFlink Tabel API
简述
PyFlink 是 Apache Flink 的 Python API,你可以使用它构建可扩展的批处理和流处理任务,例如实时数据处理管道、大规模探索性数据分析、机器学习(ML)管道和 ETL 处理。
如果你对 Python 和 Pandas 等库已经比较熟悉&#x…

flink小试牛刀(java版本)-实现wordCount
导语:flink是一款优秀的批处理和流处理的大数据计算引擎,本文将通过flink的java api实现wordCount.
环境准备:idea, maven
实验: 1、maven 内容:
<!-- flink--><!-- https://mvnrepository.com/art…

Flink 学习三 Flink 流 process function API
Flink 学习三 Flink 流&process function API
1.Flink 多流操作
1.1.split 分流 (deprecated)
把一个数据流根据数据分成多个数据流 1.2 版本后移除
1.2.分流操作 (使用侧流输出)
public class _02_SplitStream {public static void main(String[] args) throws Excep…
flink 本地调试报 No ExecutorFactory found to execute the application.
使用idea和maven本地调试flink报 No ExecutorFactory found to execute the application.,在网上找了一圈,说是少了 client 依赖包。不同版本的依赖包,包名写法有一些差异。可以直接去maven仓库找需要的依赖 maven仓库地址
Flink流批一体计算(6):Flink配置
目录 配置说明
配置详情 配置说明
Flink所有的配置参数都可以在客户端侧进行配置,建议用户直接修改客户端的配置文件flink-conf.yaml进行配置:
配置文件路径: flink/conf/flink-conf.yaml。文件的配置格式为key: value。
例:t…
【Flink实战系列】Flink 如何读取 excel 文件并注册成表处理数据
Flink提供了一个CsvTableSource来读取scv文件,返回的是CsvTableSource,然后利用registerTableSource注册为一张表,我们就可以写sql操作这张表了,非常的方便,废话不多说了,直接看下面的demo
package flink.tableimport org.apache.flink.api.scala.ExecutionEnvironment
import…
Flink实时电商数仓(五)
FlinkSQL的join
Regular join普通join,两条流的数据都时存放在内存的状态中,如果两条流数据都很大,对内存压力很大。Interval Join: 适合两条流到达时间有先后关系的;一条流的存活时间短,一条流的存活时间长。Lookup …
Flink入门学习(一)
Flink
1. 概述
分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。 有界流:有定义流的开始&am…
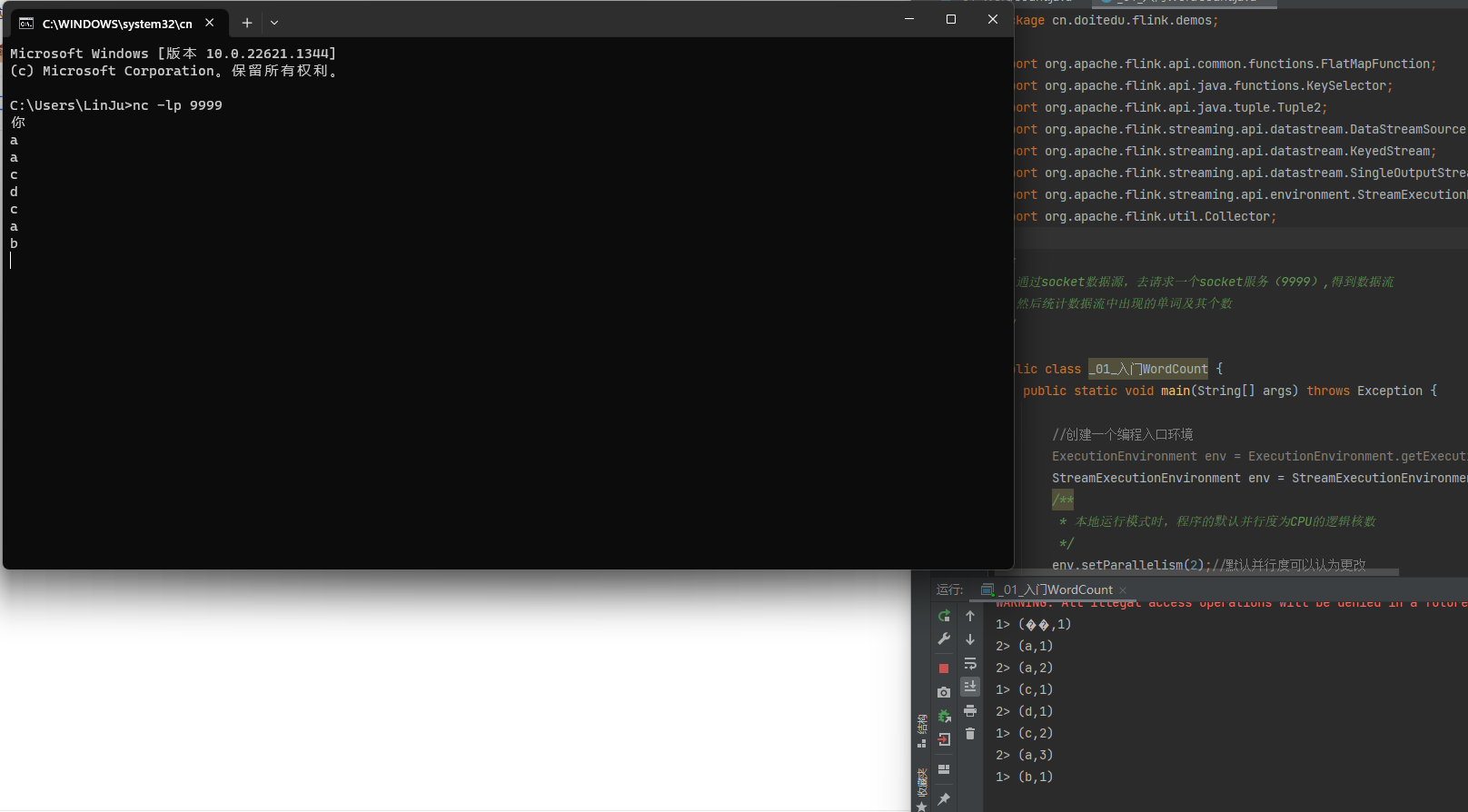
Flink学习-单词统计WordCount
WordCount(流处理)通过socket数据源,去请求一个socket服务(9999),得到数据流然后统计数据流中出现的单词及其个数1.创建一个编程入口,生成环境StreamExecutionEnvironment streamEnv StreamExecutionEnvir…

FLINK 学习随笔一
Flink 如何支持事件驱动的应用程序?
事件驱动应用程序的限制取决于流处理器处理时间和状态的能力。Flink 的许多出色功能都围绕这些概念展开。Flink 提供了一组丰富的状态原语,可以管理非常大的数据量(高达数 TB),并保…

Flink 异常 - 1.新增 BroadcastStream 无 watermark 导致数据流异常
一.问题分析
原始程序使用 EventTime,JobGraph 为 Source + KeyBy + ProcessFunction + Window + Sink 形式,其中 ProcessFunction 内设置了 ValueState 与 onTimer 的机制,由于需要定时更新一些任务需要的实时变量,故引入 BroadcastStream 实现实时变量的不定时更新,经过…
08-Flink的interval join的实现原理?join不上的怎么办?
一:题目
Flink的interval join的实现原理?join不上的怎么办?二:答案
底层调用的是keybyconnect ,处理逻辑: 1)判断是否迟到(迟到就不处理了) 2)每条流都存了…
一款宝藏面试题平台上线了(再也不用担心找不到面试题了)
首先申明:这不是一篇割韭菜的文章。
将近有一个多月没有输出文章,因为一直在做一件事:复盘。
先跟大家分享一个小故事:在国外有位大学教授曾做过这样一次实验,他当着学生们的面拿出一张10英镑的钱,问学生…
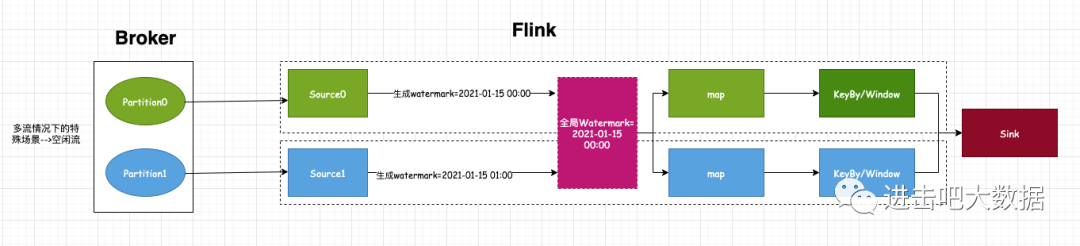
Flink从入门到放弃之入门篇(五)-关于乱序那点事
引入
通过对上篇Flink从入门到放弃之入门篇(四)-剖析窗口生命周期的讲解,我们对flink窗口的整个生命周期有了一个大致的了解,并掌握了窗口的作用。这里给出一个常见的生产案例,如统计每分钟的点击用户数,技术实现上一般是flink对…
Flink从入门到放弃(十二)-企业实战之事件驱动型场景踩坑(一)
需求背景
某日,小明早上10点打卡到公司,先来一杯热水润润嗓子,打开音乐播放器带上心爱的降噪耳机看看新闻,静静等待11点半吃午饭。突然消息框亮了起来,这个时候小明心想要么来需求了,要么数据就有问题了。…
![Flink Kafka[输入/输出] Connector](https://img-blog.csdnimg.cn/direct/8a54a4ce359b4291b6acbf895ff3881e.png)
Flink Kafka[输入/输出] Connector
本章重点介绍生产环境中最常用到的Flink kafka connector。使用Flink的同学,一定会很熟悉kafka,它是一个分布式的、分区的、多副本的、 支持高吞吐的、发布订阅消息系统。生产环境环境中也经常会跟kafka进行一些数据的交换,比如利用kafka con…
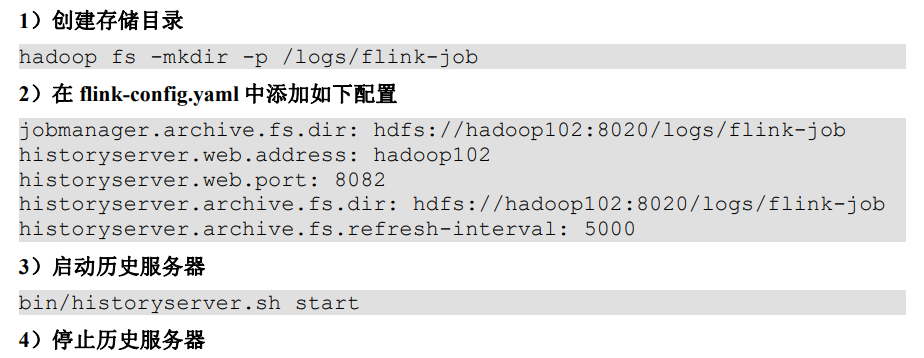
【入门Flink】- 04Flink部署模式和运行模式【偏概念】
部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink为各种场景提供了不同的部署模式,主要有以下三种:会话模式(Session Mode)、单作业模式(Per-Job Mode&…

Flink从入门到放弃(十二)-企业实战之事件循环驱动型场景(二)
上文Flink从入门到放弃(十二)-企业实战之事件驱动型场景踩坑(一)为大家介绍了Flink基于事件驱动场景下的渠道流量分析实时需求以及遇到的坑。 本文继续讲解基于事件驱动场景来讲解下关于响应时效、服务质量类的需求方案设计以及遇到的坑 (关于Flink主题的所有文章已…


大数据下Flink on YarnSession 高可用集群环境部署开辟资源发布任务
前言:搭建大数据环境集群环境算是比较麻烦的一个事情,并且对硬件要求也比较高其中搭建大数据环境需要准备jdk环境和zk环境,还有hdfs,还有ssh之间的免密操作,还有主机别名访问不通的问题 等。必然会出现的问题ÿ…
第一章 Flink 简介
第一章 Flink 简介 初识Flink
Flink 起源于 Stratosphere 项目,Stratosphere 是在 2010~2014 年由 3 所地处柏林的大学和欧洲的一些其他的大学共同进行的研究项目, 2014 年 4 月 Stratosphere 的代码被复制并捐赠给了 Apache 软件基金会, 参加…
Flink系列-5、Flink DataSet API介绍
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 大数据系列文章目录
官方网址:https://flink.apache.org/
学习资料:https://flink-learning.org.cn/ 目录Flink DataSe…

Flink学习笔记(5)——算子
基本转换算子 map:输入一条记录,输出一个结果,不允许不输出 flatmap:输入一条记录,可以输出0或者多个结果 filter:如果结果为真,则仅发出记录 package transform;import org.apache.flink.api…

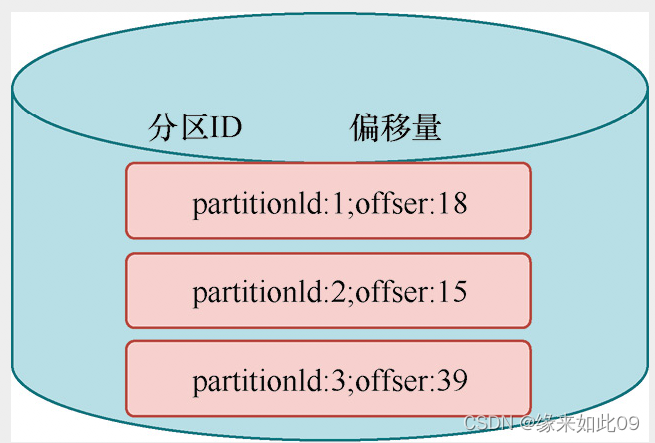
Flink获取kafka的offset
前言
在工作的时候,一直想知道flink消费kafka的时候怎么去获取offset,以便有时候自己管理offset。在网上找了很多资料也没有找到。 研究源码,发现SimpleStringSchema主要是实现了DeserializationSchema,继续深入发现了KeyedDeser…
Flink-DataStream执行环境和数据读取
编辑执行环境 创建执行环境 执行模式 触发程序执行
源算子(Source) 读取有界数据流 读取无界数据 读取自定义数据源(源算子) DataStream是一个 Flink 程序,其实就是对 DataStream 的各种转换。具体来说,…

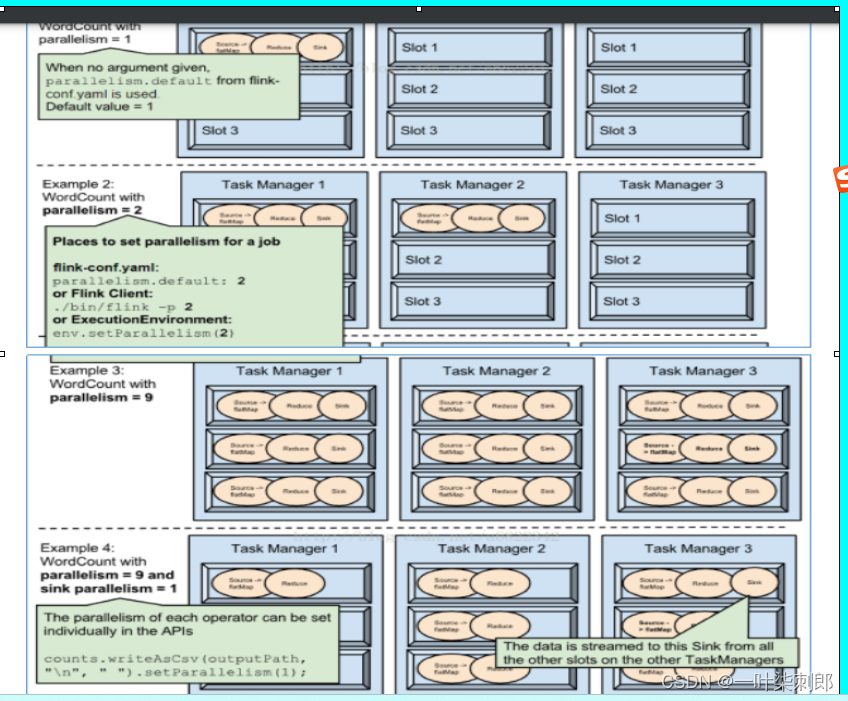
Flink学习笔记(3)——运行时架构中的四大组件|任务提交流程|任务调度原理|Slots和并行度中间的关系|数据流|执行图|数据得传输形式|任务链
前言
Flink运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作:作业管理器(JobManager)、资源管理器(ResourceManager)、任务管理器(TaskManager),…
Flink学习笔记(2)——任务提交模式
文章目录前言Standalone模式yarn模式前言
本文介绍flink的任务提交模式。
Standalone模式 Web UI提交job 打开flink的Web UI,在Web UI的Submit New Job提交jar包。 Job参数: Entry Class:程序的入口,指定入口类(类…

Flink学习笔记(1)——流批处理
文章目录pom文件批处理流处理总结学习flink怎么能少得了wordcount呢?pom文件
flink1.0版本及以下
<properties><flink.version>1.10.0</flink.version><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.targ…

Spark和Flink的对比,谁才是大数据计算引擎王者?
文章目录简介区别总结简介
Spark简介
Spark的历史比较悠久,已经发展了很长时间,目前在大数据领域也有了一定的地位.Spark是Apache的一个顶级项目。它是一种快速的、轻量级、基于内存、分布式迭代计算的大数据处理框架。,Spark最初由美国加州伯克利大学(UCBerkeley…

基于Flink实时数仓——DWS 层-商品主题宽表的计算(7)
代码实现:
public class ProductStatsApp {public static void main(String[] args) throws Exception {//TODO 1.获取执行环境StreamExecutionEnvironment env StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//1.1 设置CK&状…
Flink / Scala 实战 - 15.Stream 基本合流操作 - Union Connect
目录
一.引言
二.数据准备
1.Event 事件类
2.Source 数据源
三.Union
1.简介
2.union 示例
<
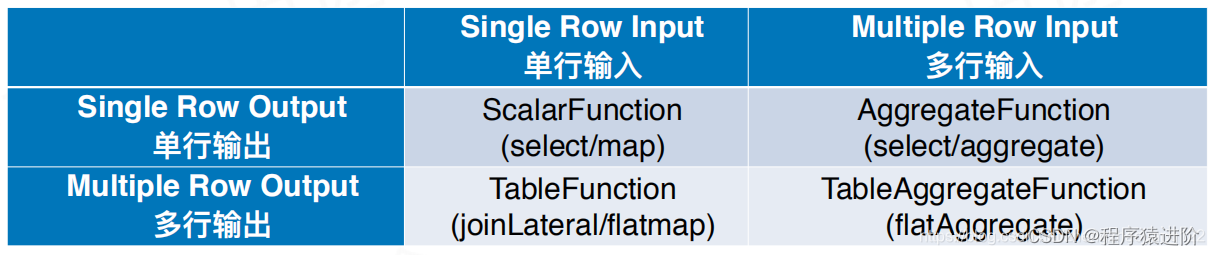
Flink自定义函数之表值聚合函数(UDTAGG函数)
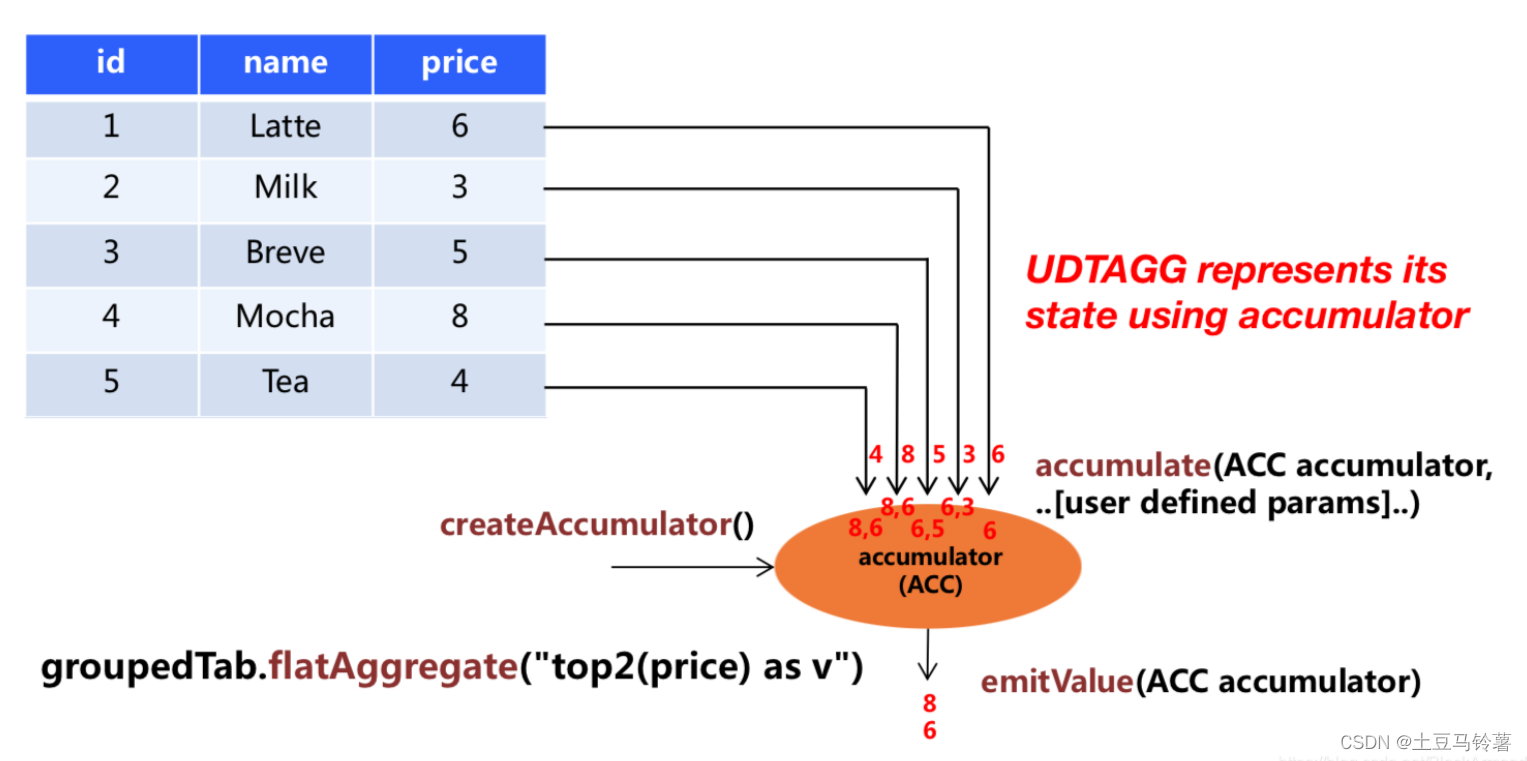
1.表值聚合函数概念
自定义表值聚合函数(UDTAGG)可以把一个表(一行或者多行,每行有一列或者多列)聚合成另一张表,结果中可以有多行多列。 理解:假设有一个饮料的表,这个表有 3 列&a…
Flink / Scala 实战 - 13.TimeWindow 处理迟到数据详解
目录 一.引言
二.Flink TimeWindow 丢数据示例
1.代码分析
2.Watermark 生成逻辑
3.丢失数据代码测试
Flink状态编程:为什么不建议在ValueState里面存Map?
文章目录 先说结论性能:TTL: State需要存什么数据Heap 模式 ValueState 和 MapState 如何存储StateBackend模式 如何存储和读写State 数据1. RocksDB 模式 ValueState 和 MapState 如何存储1.1 ValueState如何映射为RocksDB的kv1.2 MapState如何映射为Ro…
Flink 实战 - 10.ProcessFunction 使用缓存详解
目录
一.引言
二. LRUCache
1.源码浅析
2.Flink 使用 Cache
3.LRUcache 测试
3.1.初始化 LRUCache

Flink 实战 - 9.Kafka 下发消息过大异常分析与 Kafka Producer 源码浅析
一.引言
Flink 使用 kafka 作为 Sink,大部分时间运行正常,偶发报错显示 Kafka Producer 发送消息超过 kafka 设置的最大请求即 max.request.size,下面分析排查并解决该问题: org.apache.flink.streaming.connectors.kafka.FlinkKafkaException: Failed to send data to Ka…
三十一:Flink 和 Kafka 整合时间窗口设计
在计算 PV 和 UV 等指标前,用 Flink 将原始数据进行了清洗,清洗完毕的数据被发送到另外的 Kafka Topic 中,接下来我们只需要消费指定 Topic 的数据,然后就可以进行指标计算了。
Flink 消费 Kafka 数据反序列化
上一课时定义了用户的行为信息的 Java 对象,我们现在需要消…
Flink / Scala 实战 - 6.使用 Jedis、JedisPool 作为 Source 读取数据
一.引言
现在有一批数据写入多台 Redis 相同 key 的队列中,需要消费 Redis 队列作为 Flink Source,为了提高可用性,下面基于 JedisPool 进行队列的消费。队列数据示例: 1,2,3,4,5、A,B,C,D,E,程序将字符串解析并 split(",") 然后分别写到下游。 二.Flink Source…
Flink / Scala 异常 - 8.java.lang.NumberFormatException: Not a version: 9
一.引言
Flink V1.13.1 + Scala 2.11.8 提交任务后,报错 Caused by: org.apache.flink.shaded.guava18.com.google.common.util.concurrent.UncheckedExecutionException: java.lang.NumberFormatException: Not a version: 9 ,遂排查与解决。 二.报错分析
1.LocalCache
异…
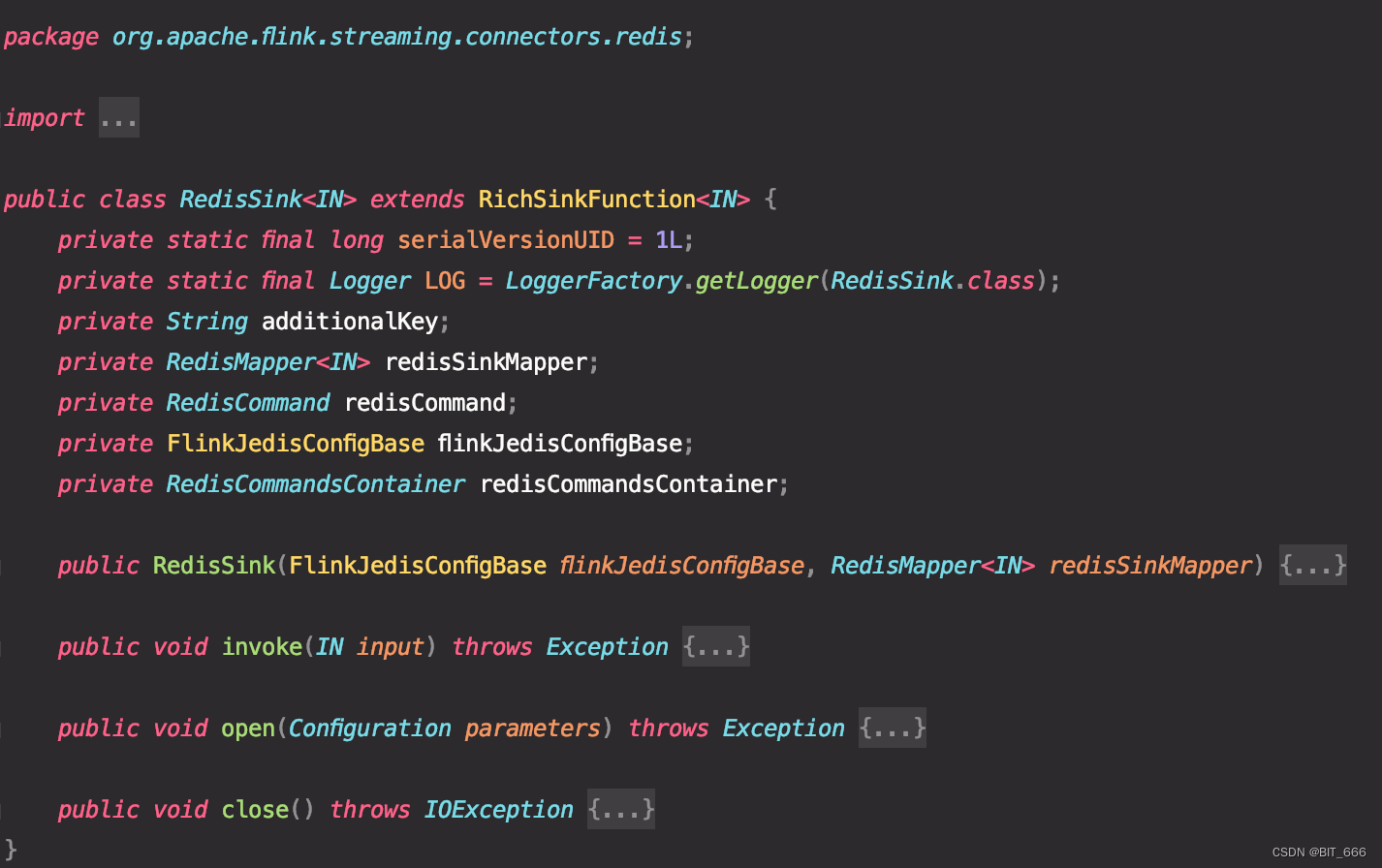
Flink / Scala 实战 - 2.使用 RedisSink 存储数据
一.引言
现在有一批流数据想要存储到 Redis 中,离线可以使用 Spark + foreach 搞定,由于是多流 join 且带状态,所以 SparkStreaming + foreach 也无法实现,而 Flink 不支持 foreach 操作触发 execute,这里采用 RedisSink 代替实现 foreach 逻辑。 二.RedisSink 简介
1.源…
①Flink应用场景和模型构建,核心特性
Flink 自从 2019 年初开源以来,迅速成为大数据实时计算领域炙手可热的技术框架。作为 Flink 的主要贡献者阿里巴巴率先将其在全集团进行推广使用,另外由于 Flink 天然的流式特性,更为领先的架构设计,使得 Flink 一出现便在各大公司掀起了应用的热潮。 阿里巴巴、腾讯、百度…
关于flink学习时的想法
近期,由于项目需要,学习flink的使用。 在此次技术架构中,用到了阿里的多款产品,如rds,datahub,flink。其实对于这三个工具都不是很熟悉,所以最开始的时候,只能先看这些产品的简介,看其特性、功能…

Flink / Scala 实战 - 1.使用 CountWindow 实现按条数触发窗口
一.引言
CountWindow 数量窗口分为滑动窗口与滚动窗口,类似于之前 TimeWindow 的滚动时间与滑动时间,这里滚动窗口不存在元素重复而滑动窗口存在元素重复的情况,下面 demo 场景为非重复场景,所以将采用滚动窗口。 二.CountWindow 简介 这里最关键的一句话是: A Window tha…
【Flink】Flink 中的时间和窗口之水位线(Watermark)
1. 时间语义
这里先介绍一下什么是时间语义,时间语义在Flink中是一种很重要的概念,下面介绍的水位线就是基于时间语义来讲的。
在Flink中我们提到的时间语义一般指的是事件时间和处理时间:
处理时间(Processing Time),一般指执…
Flink读取数据的4种方式
Flink读取数据的4种方式 从文件中读取数据从Socket中读取数据从Kafka中读取数据从自定义数据源读取数据 从文件中读取数据
这是最简单的数据读取方式。当需要进行功能测试时,可以将数据保存在文件中,读取后验证流处理的逻辑是否符合预期。
程序代码&am…

Flink 实战 - 3.读取 Parquet 文件 By Scala / Java
一.引言
parquet 文件常见与 Flink、Spark、Hive、Streamin、MapReduce 等大数据场景,通过列式存储和元数据存储的方式实现了高效的数据存储与检索,下面介绍 Flink 场景下如何读取 Parquet。Parquet 相关知识可以参考:Spark - 一文搞懂 parquet。 二.Parquet Read By Scala…

Flink 异常 - 3.java.lang.InternalError: Malformed class name
一.引言 本地执行 Flink 程序报错 java.lang.InternalError: Malformed class name。 二.解决
Malformed class name 代表非常规的 class,引起该问题的原因是 case class 的定义放在了 main 函数中,导致上述报错。
错误写法:
object TestF…
如何保证 flink-connector-elasticsearch 的幂等性
好的,下面是您所需的内容。
官方文档连接
Flink 官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.11/Flink Elasticsearch Connector 文档:https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/connec…
Iceberg从入门到精通系列之十一:Flink DataStream读取Iceberg表
Iceberg从入门到精通系列之十一:Flink DataStream读取Iceberg表 一、完整代码二、效果如下所示 一、完整代码
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datast…
Flink窗口核心概念-有KEY窗口和无KEY窗口
文章目录(一)WIndow与WindowAll区别(二)有KEY 窗口和无KEY窗口(1)有KEY窗口(2)无KEY窗口(三)有KEY窗口 无KEY窗口验证(1)有KEY窗口执行…
Flink原理概括及Blink的一些优势
JobManager调度task,协调checkpoint的报错并进行恢复。 JobManager接收到客户端发来的打包任务信息,将信息分配给taskmanager,taskmanager获取到task信息,将task分配给slot进行处理。 一个process(进程)对应…

Flink:standalone模式下start-cluster.sh之后taskmanager没起来
我的版本:Flink1.7.2、jdk1.8.0_201
下午照着Flink官网部署了一下standalone模式,通过start-cluster.sh命令启动Flink集群后发现只有StandaloneSessionClusterEntrypoint进程起来了,并没有TaskManagerRunner,并且8081网页中taskm…
Flink-Connectors(连接器)(1)JDBC
什么是连接器
预定义的源和接收器
Flink内置了一些基本数据源和接收器,这些数据源和接收器始终可用。该预定义的数据源包括文件、Mysql、RabbitMq、Kafka、ES
等,同时也支持数据输出到文件、Mysql、RabbitMq、Kafka、ES等。
简单的说ÿ…

flink sql 流 join (上)(转)
1.序篇
下面即是文章目录,也对应到本文的结论,小伙伴可以先看结论快速了解本文能给你带来什么帮助:
背景及应用场景介绍:join 作为离线数仓中最常见的场景,在实时数仓中也必然不可能缺少它,flink sql 提供…

FlinkKafkaProducer 数据一致性
什么是数据的一致性
这所说的数据一致性指,在一个 Flink 任务遇到不可坑因素整体死掉或者部分死掉,已经外部存储介质死掉后,将死掉的部分重写启动后,计算结果和出现故障之前一致,不会产生任何的影响。
如果要实现这种…

Flink_窗口的底层实现逻辑
目的
写这篇文目的是为了加深对窗口和 watermark 的理解。 先感谢这位博主的辛勤劳动。我做的分析就是基于这位大侠做的。
下面上正题。
正题
窗口总体流程
窗口是用来切割无线流的,它把无线流切分成有限个碎片,通过计算碎片来计算流的某些性质。就…
FlinkX的安装与使用
文章目录1.安装2.使用2.1 MySQL向HDFS导入数据2.2 更多示例见1.安装
1、上传flinkx-1.10.zip 文件,解压 项目地址:https://github.com/DTStack/flinkx FlinkX压缩包为zip格式,需要安装unzip 安装unzip:yum install unzip 解压 2…

Flink学习笔记(5)——window
文章目录基本概念window类型滚动窗口(Tumbling Windows)滑动窗口(Sliding Windows)会话窗口(Session Windows)window api概述创建不同类型的窗口window function其他api基本概念
一般真实的流都是无限的,怎么处理无界的数据?在实际生产中,需…
Java大数据开发之HDFS详解
Java大数据开发——HDFS详解
1. HDFS 介绍• 什么是HDFS 首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件。 其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务…
大数据开发 | MapReduce
1. MapReduce 介绍
1.1MapReduce的作用
假设有一个计算文件中单词个数的需求,文件比较多也比较大,在单击运行的时候机器的内存受限,磁盘受限,运算能力受限,而一旦将单机版程序扩展到集群来分布式运行,将极…
Java大数据技术学习指南与成长路线
对于普通在校大学生来说,参加岗前实训能够有效的把理论和实践结合起来,快速获得动手能力的提升并到达企业对于软件工程师的技能要求,从而获得更高的职业起点和更好的职业发展前景的有效途径。Java发展成熟、功能强大、使用Java开发的大数据框…
大数据开发:Flink入门(三)——环境与部署
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性、高吞吐、低延迟等优势,本文简述flink在windows和linux中安装步骤,和示例程序的运行,包括本地调试环境,集群环境。另外介绍Flin…
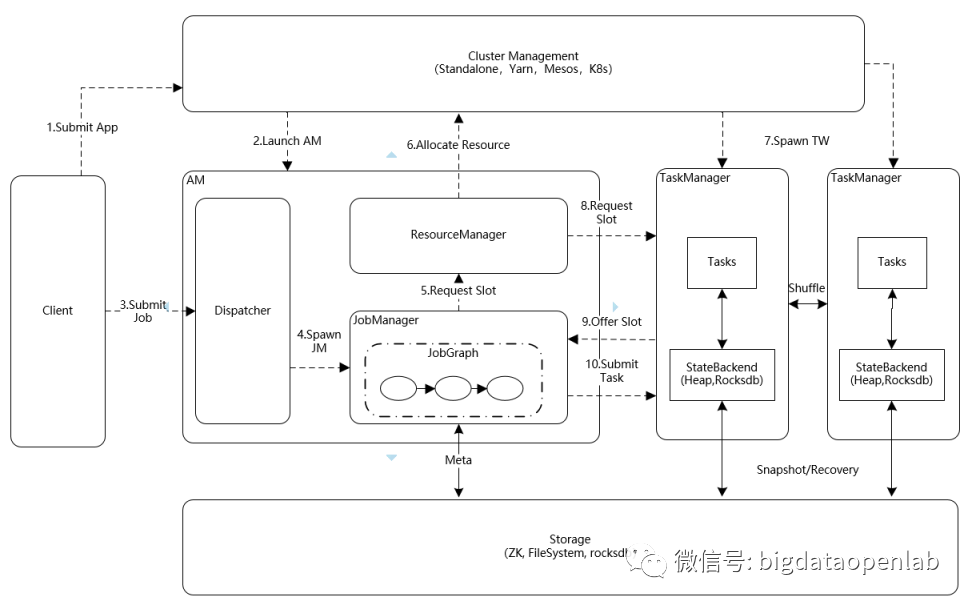
分布式计算技术(下):Impala、Apache Flink、星环Slipstream
实时计算的发展历史只有十几年,它与基于数据库的计算模型有本质区别,实时计算是固定的计算任务加上流动的数据,而数据库大多是固定的数据和流动的计算任务,因此实时计算平台对数据抽象、延时性、容错性、数据语义等的要求与数据库…
大数据基本操作锦集之Hive的基本操作
目录
简介hive的数据类型hive的数据存储hive的数据模型hive的DDL(数据库定义语言)hive的DML操作hive加载数据hive导出数据hive udf使用介绍正文 简介
hive在hadoop生态圈属于数据仓库角色,他能够管理hadoop中的数据,同时可以查询…
从Hadoop到Spark、Flink,大数据处理框架十年激荡发展史
当前这个数据时代,各领域各业务场景时时刻刻都有大量的数据产生,如何理解大数据,对这些数据进行有效的处理成为很多企业和研究机构所面临的问题。本文将从大数据的基础特性开始,进而解释分而治之的处理思想,最后介绍一…
Flink入门(五)——DataSet Api编程指南
##Apache Flink
Apache Flink 是一个兼顾高吞吐、低延迟、高性能的分布式处理框架。在实时计算崛起的今天,Flink正在飞速发展。由于性能的优势和兼顾批处理,流处理的特性,Flink可能正在颠覆整个大数据的生态。 DataSet API
首先要想运行Fli…
FlinkCDC写入kafka计算后写入写出hbase-工作实例
设计思路: 事实表走kafka触发数据的流动,维表变化缓慢留在hbase。两边join得出结果,
存在的问题: 如果多个事实表走kafka,存在kafka中数据只保存七天的,有超时数据关联不上的问题。但是如果一个事实表在kakfa,一个事实表在hbase,实际上hbase中的数据依然是流写入的,依…
Flink面试篇-基础/源码
基础
面试题 1:请介绍一下 Flink 这道题是一道很简单的入门题,考察我们队 Flink 整体的掌握情况,我们应该从以下几个基本的概念入手。
Flink 是大数据领域的分布式实时和离线计算引擎,其程序的基础构建模块是流(Streams)和转换(Transformations),每一个数据…

三十:Kakfa模拟Json数据生成和发送
在计算 PV 和 UV 的过程中关键的一个步骤就是进行日志数据的清洗。实际上在其他业务,比如订单数据的统计中,我们也需要过滤掉一些“脏数据”。
所谓“脏数据”是指与我们定义的标准数据结构不一致,或者不需要的数据。因为在数据清洗 ETL 的过程中经常需要进行数据的反序列化…

大数据Flink(八十三):SQL语法的DML:With、SELECT WHERE、SELECT DISTINCT 子句
文章目录
SQL语法的DML:With、SELECT & WHERE、SELECT DISTINCT 子句
一、DML:With 子句
flink-cdc-connectors-release-2.4.1编译记录
增加国内依赖仓地址配置: <repositories><repository><id>tbds</id><url>https://maven.aliyun.com/repository/public</url><snapshots><enabled>true</enabled><updatePolicy>always</updatePoli…
二十二:MockKafka消息并发送
大数据消息中间件的王者——Kafka
在上一课时中提过在实时计算的场景下,我们绝大多数的数据源都是消息系统。所以,一个强大的消息中间件来支撑高达几十万的 QPS,以及海量数据存储就显得极其重要。
Kafka 从众多的消息中间件中脱颖而出,主要是因为高吞吐、低延迟的特点;另…

④Flink常用DataSet和DataStreamAPI
现状
在前面的课程中,曾经提到过,Flink 很重要的一个特点是“流批一体”,然而事实上 Flink 并没有完全做到所谓的“流批一体”,即编写一套代码,可以同时支持流式计算场景和批量计算的场景。目前截止 1.10 版本依然采用了 DataSet 和 DataStream 两套 API 来适配不同的应用…
Flink的面试问题
flink消费Kafka的数据,怎么保证数据不丢失
上游可以调整偏移量, 下游事务写和幂等写, 中间靠checkpoint Savepoint和Checkpoint分别是什么? Savepoint 是用来为整个流处理应用在某个“时间点”(point-in-time)进行快照生成的功能。该快照包含了数据源读取到的偏移量(offs…
scalac: Class org.apache.flink.api.common.state.CheckpointListener not found - continuing with a stu
flink消费kafka数据 报错 org.apache.flink flink-connector-kafka_2.11 1.12.0 官方给的版本可能太新了。。 自己换了个版本就没问题了 org.apache.flink flink-connector-kafka_2.11 1.9.1
c语言中赋值运算符优先级_C / C ++中的赋值运算符
c语言中赋值运算符优先级Assignment operators are used to assign the value/result of the expression to a variable (constant – in case of constant declaration). While executing an assignment operator based statement, it assigns the value (or the result of th…

Flink 数据集成服务在小红书的降本增效实践
摘要:本文整理自实时引擎研发工程师袁奎,在 Flink Forward Asia 2022 数据集成专场的分享。本篇内容主要分为四个部分: 小红书实时服务降本增效背景Flink 与在离线混部实践实践过程中遇到的问题及解决方案未来展望 点击查看原文视频 & 演…
flink笔记16 flink table windows(Group Windows/Over Windows)
目录
1.介绍
2.Group Windows(分组窗口)
tumbling window(滚动窗口)
Sliding Windows(滑动窗口)
Session Windows(会话窗口)
实例
3.Over Windows
无界的Over Windows
有界的Over Windows
实例
4.SQL中的Group Windows和OverWindows
Group Windows
Over Windows 1…

flink笔记15 flink table表的时间属性
表的时间属性 1.时间属性介绍
2.处理时间(ProcessingTime)
在创建表的DDL中定义
在 DataStream 到 Table 转换时定义
使用 TableSource 定义
3.事件时间(ProcessingTime)
在DataStream转换成Table时定义
在创建表的DDL中定义
使用 TableSource 定义 1.时间属性介绍
像…
分析Flink,源和算子并行度不一致时,运行一段时间后,看似不再继续消费的问题,提供解决思路。
文章目录 背景分析 问题来了比较一开始的情况解决方式 背景
之前有分析过一次类似问题,最终结论是在keyby之后,其中有一个key数量特别庞大,导致对应的subtask压力过大,进而使得整个job不再继续运作。在这个问题解决之后ÿ…

flink笔记6 DataStream API(二)Transform、sink介绍和使用
Transform、sink介绍和使用
3.Transform
(1) 简单转换算子
(2)键控流转换算子
(3)多流转换算子
4.sink 3.Transform
(1) 简单转换算子
① Map:输入一个元素,然后返回一个元素,中间可以做一些清洗转换等操作
object Transform1 {def …
Hadoop、Spark与Flink的基础架构及其关系和优异
Hadoop、Spark与Flink的基础架构及其关系和优异 前言Hadoop基础架构优点不足 Spark基础架构优点不足 Flink基础架构优点不足 结语:大数据框架的选择 前言
Hadoop、Spark和Flink是目前重要的三大分布式计算系统。它们都可以用于大数据处理,但在处理方式和…
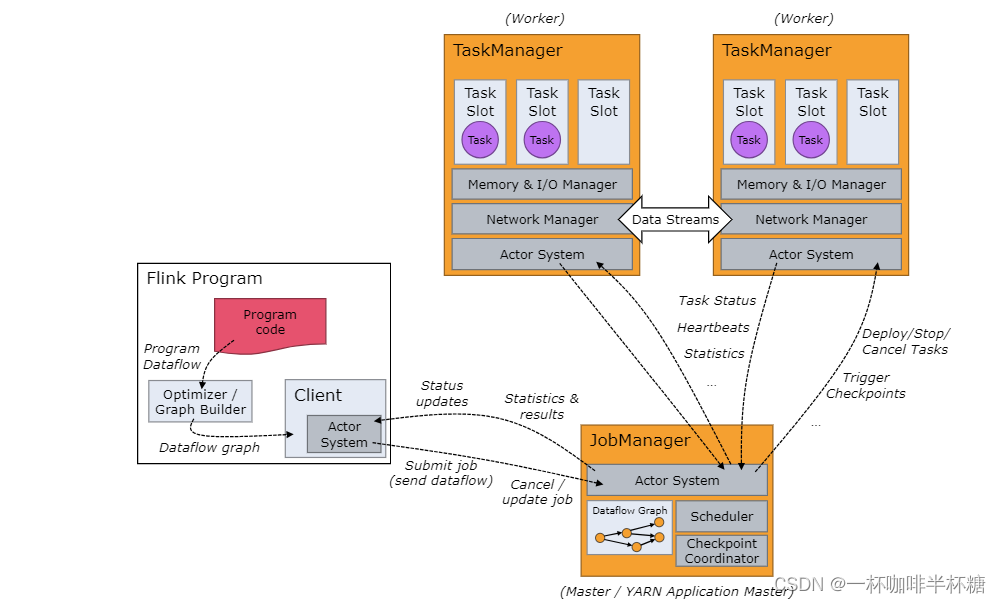
【Flink】Flink架构及组件
我们学习大数据知识的时候,需要知道大数据组件如何安装以及架构组件,这将帮助我们更好的了解大数据组件
对于大数据Flink,架构图图下: 整个架构图有三种关键组件
1、Client:负责作业的提交。调用程序的 main 方法&am…


自定义sink实现方式
为什么说继承RichSinkFunction是最优解?
我们点开RichSinkFunction,发现其继承了AbstractRichFunction,又实现了SinkFuction,其类本身没有任何方法或功能,更类似于一个中间商 我们点开AbstractRichFunction 发现AbstractRichFunction 又实现…
Flink 程序Sink(数据输出)操作(2)文件
文章目录(1)方式一 writeAsText(2)方式二 StreamingFileSink 有时候,我们需要将我们Flink程序的计算结果输出到文件中(本地文件/HDFS)文件 Flink程序本身便支持这种操作
(1&…

Flink程序加载数据源(3)自定义数据源(1)
文章目录代码实现① 准备环境② 获取数据源③ 从Mysql中获取数据源示例 flink 可以从我们常用的各种DB、文件(HDFS/LOCAL)、SCOKET、MQ等等…中加载数据,Flink官方也提供了一些connectors(连接器 理解为springboot-start-xx即可)࿰…
Flink的两阶段提交是什么
两阶段提交 Two-Phase-Commit,简称 2PC,是很常用的解决分布式事务问题的方式,它可以保证在分布式事务中,要么所有参与进程都提交事务,要么都取消,即实现 ACID 中的 A (原子性)。在数…

Flink入门:Flink架构介绍
1、基本组件栈
了解Spark的朋友会发现Flink的架构和Spark是非常类似的,在整个软件架构体系中,同样遵循着分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富且友好的接口。 Flink分为架构分为三层&…
Hbase入门——安装与配置
本文讲述如何安装,部署,启停HBase集群,如何通过命令行对Hbase进行基本操作。
并介绍Hbase的配置文件。
在安装前需要将所有先决条件安装完成。 一、先决条件
1、JDK
和Hadoop一样,Hbase需要JDK1.6或者更高的版本,所…


Flink 读取 Kafka 消息写入 Hudi 表无报错但没有写入任何记录的解决方法
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,京东购书链接:https://item.jd.com/12677623.html,扫描左侧二维…
三十四:FlinkCEP复杂事件处理
背景 我们在第 11 课时“Flink CEP 复杂事件处理”已经介绍了 Flink CEP 的原理,它是 Flink 提供的复杂事件处理库,也是 Flink 提供的一个非常亮眼的功能,当然更是 Flink 中最难以理解的部分之一。 Complex Event Processing(CEP)允许我们在源源不断的数据中通过自定义的模…
Flink standalone集群部署配置
文章目录 简介软件依赖部署方案二、安装1.下载并解压2.ssh免密登录3.修改配置文件3.启动集群4.访问 Web UI 简介
Flink独立模式(Standalone)是部署 Flink 最基本也是最简单的方式:所需要的所有 Flink 组件, 都只是操作系统上运行…
基于数据湖的多流拼接方案-HUDI实操篇
目录
一、前情提要
二、代码Demo
(一)多写问题
(二)如果要两个流写一个表,这种情况怎么处理? (三)测试结果
三、后序 一、前情提要
基于数据湖对两条实时流进行拼接࿰…
Flink如何基于事件时间消费分区数比算子并行度大的kafka主题
背景
使用flink消费kafka的主题的情况我们经常遇到,通常我们都是不需要感知数据源算子的并行度和kafka主题的并行度之间的关系的,但是其实在kafka的主题分区数大于数据源算子的并行度时,是有一些注意事项的,本文就来讲解下这些注…

flink 解决udf重复调用的问题(亲测有效)
问题 针对如图的情况,udf会被调用4次,如果udf是计算型的,后果很严重。接下来介绍一下解决的办法。 更改底层源码 大神的博客继续往下看,有测试过程测试UDF
1.写两个udf
public class Udf1 extends ScalarFunction {public long eval(long ordernumber
函数类(Function Classes)和 富函数类(Rich Function Classes)
目录
函数类(Function Classes)
富函数类(Rich Function Classes) 函数类(Function Classes) Flink暴露了所有UDF函数的接口,具体实现方式为接口或者抽象类,例如MapFunction、Filt…

Flink系列文档-(YY08)-Flink核心概念
1 核心概念
1.1 基础概念
用户通过算子api所开发的代码,会被flink任务提交客户端解析成jobGraph然后,jobGraph提交到集群JobManager,转化成ExecutionGraph(并行化后的执行图)然后,ExecutionGraph中的各个…
【大数据开发心得】合理使用Flink参数配置
在使用 Apache Flink 进行大数据开发时,合理配置 Flink 参数可以优化系统性能并提高数据处理效率。 调整并行度(Parallelism):并行度是 Flink 任务在集群中运行的并发度。根据你的数据量和集群规模,合理调整任务的并行…
Flink流批一体计算(19):PyFlink DataStream API之State
目录 keyed state
Keyed DataStream
使用 Keyed State
实现了一个简单的计数窗口
状态有效期 (TTL)
过期数据的清理
全量快照时进行清理
增量数据清理
在 RocksDB 压缩时清理
Operator State算子状态
Broadcast State广播状态 keyed state
Keyed DataStream
使用 k…
利用dockerfile升级flink的curl
最近Nusses扫出flink镜像有CURL漏洞,才发现要更新到最新版本 8.4.0,笔者当时flink版本为:
flink:1.17.1-scala_2.12-java8
官方镜像仓库:https://hub.docker.com/_/flinkapt源
我试了如上2种方法,都不能更新curl到8…
36、Flink 的 Formats 之Parquet 和 Orc Format
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

大数据Flink(一百零三):SQL 表值聚合函数(Table Aggregate Function)
文章目录
SQL 表值聚合函数(Table Aggregate Function) SQL 表值聚合函数(Table Aggregate Function)
Python UDTAF,即 Python TableAggregateFunction。Python UDTAF 用来针对一组数据进行聚合运算,比如同一个 window 下的多条数据、或者同一个 key 下的多条数据等,与…
尚硅谷大数据项目《在线教育之实时数仓》笔记007
视频地址:尚硅谷大数据项目《在线教育之实时数仓》_哔哩哔哩_bilibili 目录
第9章 数仓开发之DWD层
P053
P054
P055
P056
P057
P058
P059
P060
P061
P062
P063
P064
P065 第9章 数仓开发之DWD层
P053 9.6 用户域用户注册事务事实表 9.6.1 主要任务 读…
flink 键控状态(keyed state)
github开源项目flink-note的笔记。本博客的实现代码都写在项目的flink-state/src/main/java/state/keyed/KeyedStateDemo.java文件中。 项目github地址: github 1. flink键控状态
flink键控状态是作用与flink KeyedStream上的,也就是说需要将DataStream先进行keyby之后才能使…
Flink 流处理API
目录 一、环境
1.1getExecutionEnvironment
1.2createLocalEnvironment
1.3createRemoteEnvironment
二、从集合中读取数据
三、从文件中读取数据
四、从KafKa中读取数据
1.导入依赖
2.启动KafKa
3.java代码 一、环境
1.1getExecutionEnvironment
创建一个执行环境&…

flink ui含义图解
笔者最近开始学习flink,但是flink的webui上各种指标错综复杂,在网上也没有找到一个比较详尽的资料,于是个人整理了一下关于flink中taskmanager的webui各个指标的含义,供大家参考。
注:括号中仅为个人理解
如下图&…

深入理解 Flink(三)Flink 内核基础设施源码级原理详解
Hadoop 生态各大常见组件的 RPC 技术实现 Flink RPC 网络通信框架 Akka 详解 1、ActorSystem 是管理 Actor 生命周期的组件,Actor 是负责进行通信的组件。 2、每个 Actor 都有一个 MailBox,别的 Actor 发送给它的消息都首先储存在 MailBox 中,…
【API篇】十、生成Flink水位线
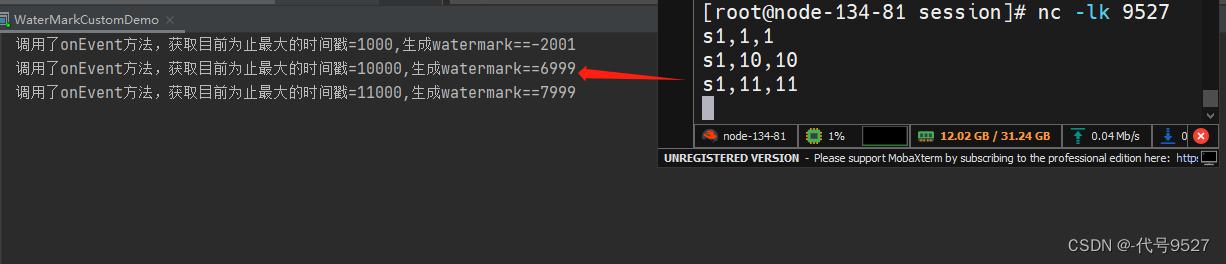
文章目录 1、水位线的生成原则2、有序流内置水位线3、乱序流内置水位线4、自定义周期性水位线生成器5、自定义断点式水位线生成器6、从数据源中发送水位线 1、水位线的生成原则
水位线出现,即代表这个时间之前的数据已经全部到齐,之后不会再出现之前的数…
Flink系列之:SELECT WHERE clause
Flink系列之:SELECT & WHERE clause 一、SELECT & WHERE clause二、SELECT DISTINCT 适用于流、批
一、SELECT & WHERE clause
SELECT 语句的一般语法是:
SELECT select_list FROM table_expression [ WHERE boolean_expression ]table_e…

Flink会话集群docker-compose一键安装
1、安装docker
参考,本人这篇博客:https://blog.csdn.net/taotao_guiwang/article/details/135508643?spm1001.2014.3001.5501
2、flink-conf.yaml
flink-conf.yaml放在/home/flink/conf/job、/home/flink/conf/task下面,flink-conf.yaml…

Kafka和Flink双剑合璧,Confluent收购Immerok引起业内广泛讨论
2023年开年开源界就出了一个大新闻,1月6日Kafka的商业化公司Confluent创始人宣布签署了收购 Immerok 的最终协议,而Immerok是一家为 Apache Flink 提供完全托管服务的初创公司,其创始团队正是Flink的创始团队。 无论是Kafka还是Flink&#x…
【大数据】-- 部署 Flink kubernetes operator
目录 1.说明
1.1 版本
1.2 kubernetes 环境
1.3 参考
2.安装步骤
2.1 安装本地 kubernetes 环境

flink笔记5 DataStream API(一)Environment、Source介绍和使用
Environment、Source介绍和使用
一.Environment
二.Source
1.内置数据源 2.第三方数据源 一.Environment
1. StreamExecutionEnvironment调用静态方法getExecutionEnvironment(),得到一个执行环境,用于执行我们的程序。
val env StreamExecutionEn…
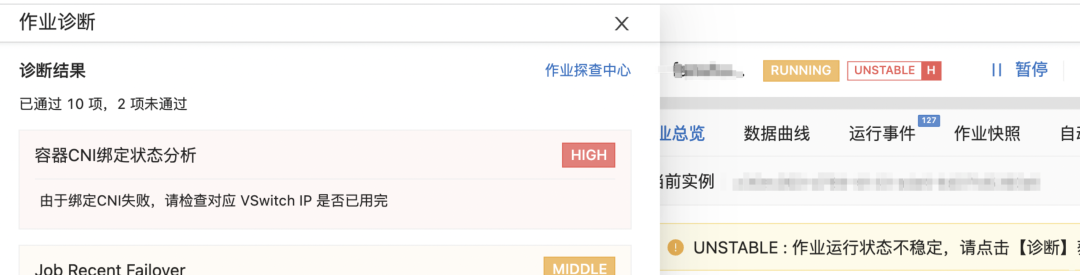
揭秘阿里云Flink智能诊断利器——Fllink Job Advisor
引言
阿里云实时计算Flink作为一款专业级别的高性能实时大数据处理系统,它在各种业务场景中都发挥了关键的作用。丰富而复杂的上下游系统让它能够支撑实时数仓、实时风控、实时机器学习等多样化的应用场景。然而,随着系统的复杂性增加,用户在…

Hudi(三)集成Flink
1、环境准备 将编译好的jar包放到Flink的lib目录下。
cp hudi-flink1.13-bundle-0.12.0.jar /opt/module/flink-1.13.2/lib
2、sql-client方式
2.1、修改flink-conf.yaml配置
vim /opt/module/flink-1.13.2/conf/flink-conf.yamlstate.backend: rocksdb
execution.checkpoi…

CDC 整合方案:Flink 集成 Confluent Schema Registry 读取 Debezium 消息写入 Hudi
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
Flink Native Library xxx is being loaded in another classloader
在使用flink连接tdengine时,第一次连接没有问题,当重启任务时,出现flink Native Library libtaos.so already loaded in another classloader异常。简单来说原因就是java的类加载机制,多个flink任务的类加载器,对tden…
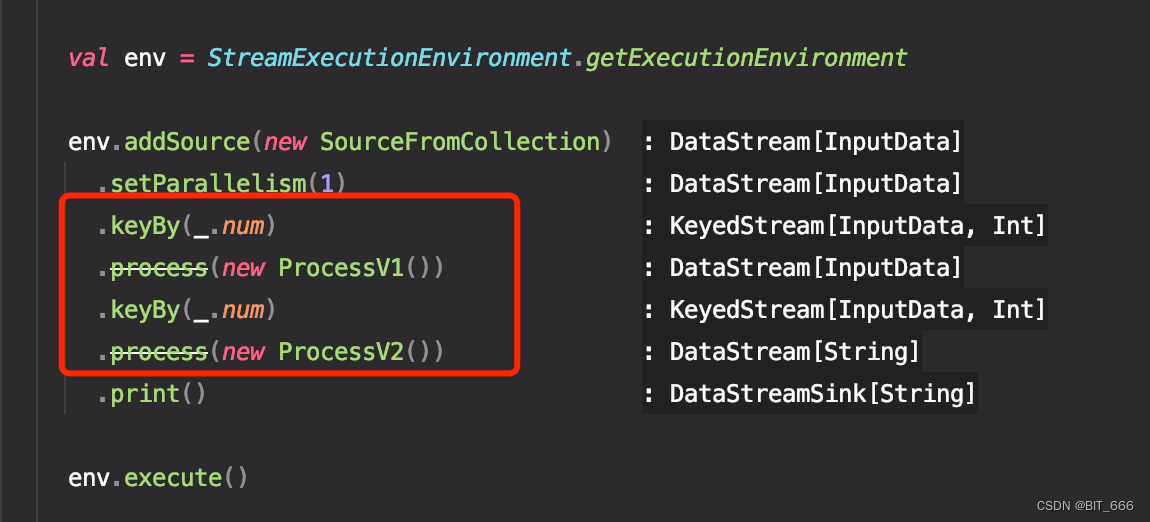
Flink / Scala 实战 - 5.ProcessFunction 之间共用缓存测试
一.引言
Flink 开发中有如下场景,数据需要经过两次 ProcessFunction 处理,第一步 ProcessV1 的一些信息重复不想通过每条数据传输至 ProcessV2,这时便捷的方法时对 ProcessV1 需要存储的元素进行去重缓存,保证全局共用一份缓存,可以有效减少储存空间,下面分别尝试三种缓…

八种Flink任务监控告警方式
目录
一、Flink应用分析
1.1 Flink任务生命周期
1.2 Flink应用告警视角分析
二、监控告警方案说明
2.1 监控消息队中间件消费者偏移量
2.2 通过调度系统监控Flink任务运行状态
2.3 引入开源服的SDK工具实现
2.4 调用FlinkRestApi实现任务监控告警
2.5 定时去查询目标库…
yarn on flink 监控 flink任务监控
Flink任务一般为实时不断运行的任务,如果没有任务监控, 任务异常时无法第一时间处理会比较麻烦。 这里通过调用API接口方式来获取参数,实现任务监控。 Flink任务监控(基于API接口编写shell脚本) 一 flink-on-yarn 模式 二 编写she…
数据湖存储解决方案之Iceberg
1.Iceberg是什么?
Apache Iceberg 是由 Netflix 开发开源的,其于2018年11月16日进入 Apache 孵化器,是 Netflix 公司数据仓库基础。Apache Iceberg设计初衷是为了解决Hive离线数仓计算慢的问题,经过多年迭代已经发展成为构建数据…
flink的异常concurrent.TimeoutException: Heartbeat of TaskManager with id的解决
背景
在使用flink进行集成测试时,我们会使用MiniClusterWithClientResource类,但是当我们断点导致在某个方法执行的时间比较长时,会有错误发生,那么该如何解决这个错误呢?
处理concurrent.TimeoutException: Heartbe…
大数据学习之Flink算子、了解(Transformation)转换算子(基础篇三)
Transformation转换算子(基础篇三) 目录
Transformation转换算子(基础篇三)
三、转换算子(Transformation)
1.基本转换算子
1.1 映射(Map)
1.2 过滤(filter…

Flink编程——基础环境搭建
基础环境搭建 文章目录 基础环境搭建准备环境搭建源码环境搭建克隆代码编译导入IDEA 集群环境搭建本地模式安装步骤 1:下载步骤 2:启动集群步骤 3:提交作业(Job)步骤 4:停止集群 总结 准备环境搭建
我们先…
Flink--8、时间语义、水位线(事件和窗口、水位线和窗口的工作原理、生产水位线、水位线的传递、迟到数据的处理)
星光下的赶路人star的个人主页 将自己生命力展开的人,他的存在,对别人就是愈疗 文章目录 1、时间语义1.1 Flink中的时间语义1.2 哪种时间语义更重要 2、水位线(Watermark)2.1 事件时间和窗口2.2 什么是水位线1.3 水位线和窗口的工…

Flink DataStream之从Kafka读数据
搭建Kafka
参考:centos7下kafka2.12-2.1.0的安装及使用_kafka2.12-2.1.0 steam_QYHuiiQ的博客-CSDN博客 启动zookeeper
[rootlocalhost kafka_2.12-2.8.1]# pwd
/usr/local/wyh/kafka/kafka_2.12-2.8.1
[rootlocalhost kafka_2.12-2.8.1]# ./bin/zookeeper-server…
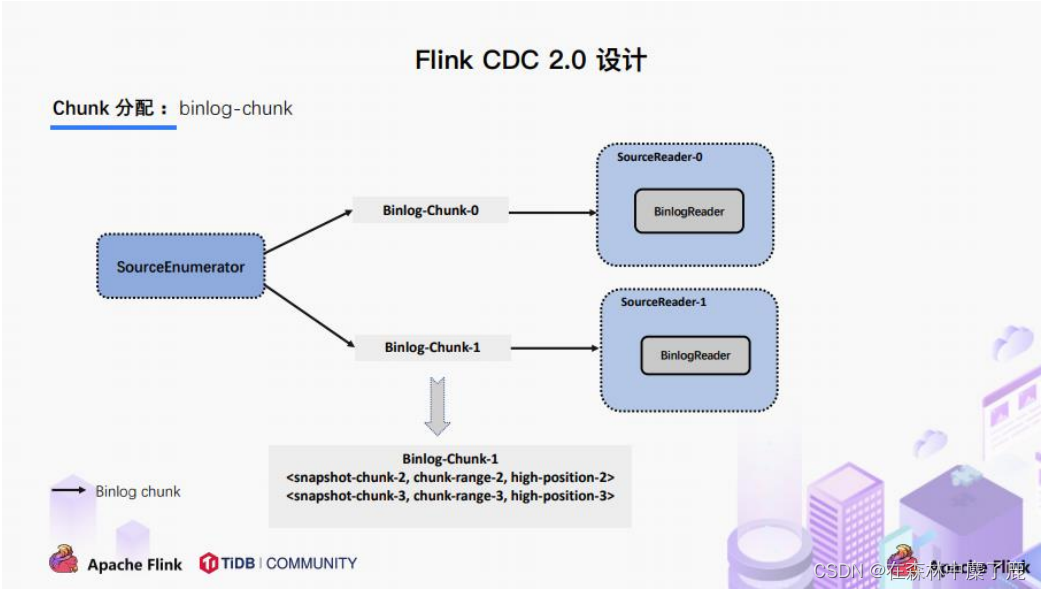
Flink CDC 详解
目录一、CDC 简介 ?二、Flink CDC 案例实操三、Flink-CDC 2.0四、核心原理分析一、CDC 简介 ?
什么是 CDC ?
CDC 是 Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、…
本科生自学Java大数据成功入职外企:大数据值得转吗?门槛高吗?
我今年大四,大二的时候先后在厦门的两家小公司实习 Java,大三的时候在 Apche Kylin 的贡献团队 Kyligence 实习,现在在一家西班牙集团就职大数据开发。
由于一路都是自己摸爬滚打过来的,而我又是一个喜欢总结且善于总结ÿ…
Fink CDC数据同步(三)Flink集成Hive
1 目的
持久化元数据
Flink利用Hive的MetaStore作为持久化的Catalog,我们可通过HiveCatalog将不同会话中的 Flink元数据存储到Hive Metastore 中。
利用 Flink 来读写 Hive 的表
Flink打通了与Hive的集成,如同使用SparkSQL或者Impala操作Hive中的数据…
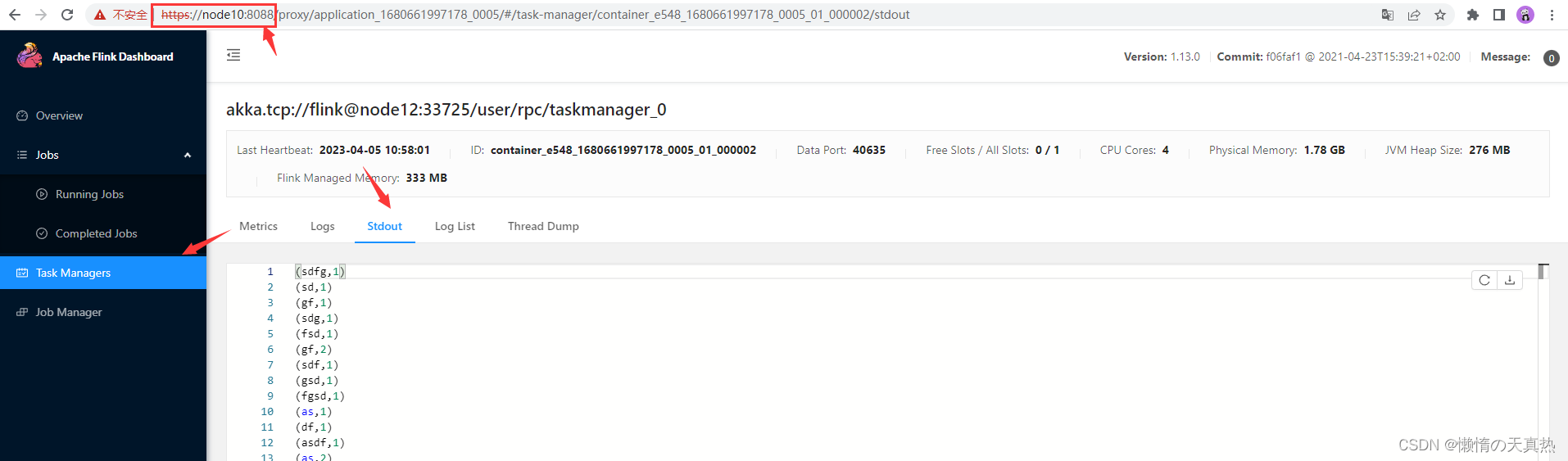
flink部署及相关使用教程
文章目录一、安装flink二、编写测试类三、flink处理测试类四、flink三种运行模式五、Flink资源管理方式六、yarn会话模式部署七、yarn单作业模式部署八、yarn应用模式部署九、部署问题一、安装flink 角色 节点服务器node10node11node12角色JobManagerTaskManagerTaskManager 下…

flink任务处理下线流水数据,数据遗漏不全(一)
背景
1、test3是单独接受T4301的mqtt主题数据 以下是flink代码 以下是node-red的 跟踪分析
拉出tdengine里面的数据曲线,看是否存在遗漏的情况 少2023-04-05 22:05:48的日志 贴上我的代码 小结
1、虽然下线记录比之前的多很多了,但是还是遗漏一些数据…
flink内存管理模型(二) ------ 内存分配
本文主要简单介绍TaskManager的内存管理策略,接上文https://blog.csdn.net/lhy18235303007/article/details/108477130。以下均为笔者个人观点,欢迎大家批评指正。
二、 内存分配
flink在启动一个TM的时候,只会通过两个启动参数限制的JVM的…
使用flink实现《实时数据分析》的案例 java版
目录 实时数据分析案例文档介绍环境数据源数据处理数据清洗数据转换数据聚合 数据输出总结 实时数据分析案例文档
介绍
本文档介绍了使用Java和Flink实现实时数据分析的案例。该案例使用Flink的流处理功能,从Kafka主题中读取数据,进行实时处理和分析&a…
实时数仓建设第3问:你不会认为Lookup维表缓存数据ttl策略和Redis key TTL策略一样吧
同事说维表缓存,当缓存项在指定的时间段内没有被读就会被回收,如果被读就会延长ttl时间。如果关联的维表数据变动就会导致无法获取最新维度数据,这种场景必须关闭缓存。
在flink 1.16之前缓存的创建方式如下:
CacheBuilder.newB…
spark 和 flink 的对比
一、设计理念 Spark 的数据模型是 弹性分布式数据集 RDD(Resilient Distributed Dattsets),这个内存数据结构使得spark可以通过固定内存做大批量计算。初期的 Spark Streaming 是通过将数据流转成批 (micro-batches),即收集一段时间(time-window)内到达的…
Flink多流处理之join(关联)
Flink的API中只提供了join的算子,并没有left join或者right join,这里我们就介绍一下join算子的使用,其实join算子底层调用的就是coGroup,具体原理这里就不过多介绍了,如果感兴趣可以看我前面发布的文章Flink多流操作之coGroup.
数据源➜ ~ nc -lk 1111
101,A
102,B
103,C
10…
【Flink】FlinkSQL中Table和DataStream互转
在我们实际使用Flink的时候会面临很多复杂的需求,很可能需要FlinkSQL和DataStream互相转换的情况,这就需要我们熟练掌握Table和DataStream互转,本篇博客给出详细代码以及执行结果,可直接使用,通过例子可学会Table和DataStream互转,具体步骤如下: maven如下<?xml ver…
Flink将数据写入CSV文件后文件中没有数据
Flink中有一个过时的sink方法:writeAsCsv,这个方法是将数据写入CSV文件中,有时候我们会发现程序启动后,打开文件查看没有任何数据,日志信息中也没有任何报错,这里我们结合源码分析一下这个原因.
这里先看一下数据处理的代码 代码中我是使用的自定义数据源生产数据的方式,为了方…
Flink DataStream之创建执行环境
新建project:
pom文件
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://ma…
flink 相关资料
相关链接 ververica中文网站: https://ververica.cn/ Apache Flink 视频教程: https://github.com/flink-china/flink-training-course Flink Forward Asia 2019: https://ververica.cn/developers/flink-forward-asia-2019/ Flink Forward China 2018: …
Iceberg从入门到精通系列之十三:Flink DataStream 往Iceberg表写入数据,实现append、upsert、overwrite
Iceberg从入门到精通系列之十三:Flink DataStream 往Iceberg表写入数据,实现append、upsert、overwrite 一、插入数据到iceberg表二、append、upsert、overwrite写入区别三、Flink DataStream 往Iceberg表写入数据四、写入后读取表 一、插入数据到iceber…
![flink笔记9 [实验]体验窗口开启时间和关闭时间(Eventtime)](https://img-blog.csdnimg.cn/2021052617033358.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzYzMTk5Nw==,size_16,color_FFFFFF,t_70)
flink笔记9 [实验]体验窗口开启时间和关闭时间(Eventtime)
体验窗口开启时间和关闭时间 实验数据
实验代码
实验结果
实验分析
窗口开始时间公式 实验数据
sensor_1,1619492107,36.2
sensor_1,1619492108,36.0
sensor_1,1619492109,36.5
sensor_1,1619492110,34.3
sensor_1,1619492111,34.3
sensor_1,1619492112,34.3
sensor_1,161…
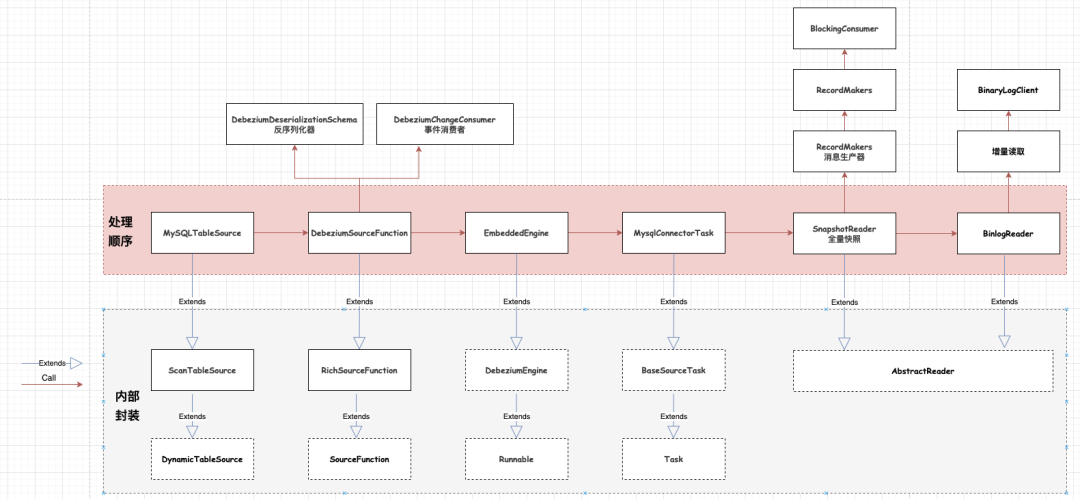
Flink从入门到放弃(九)-万字讲解CDC设计(1)
一、准备工作
在开始研究Flink CDC原理之前(本篇先以CDC1.0版本介绍,后续会延伸介绍2.0的功能),需要做以下几个工作(本篇以Flink1.12环境开始着手) 打开Flink官网(查看Connector模块介绍) 打开Github,下载源码(目前不能放链接,读者们自行在…
flink sink多个topic
flink stream数据 动态写入多个topic
flink1.15之前
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaProducer, KafkaSerializationSchema}
import org.apache.kafka.clients.producer.ProducerRecordobject…
Flink SQL - 2.Table API SQL 概述与常规 API
目录 一.引言
二.创建 TableEnvironment
三.Table API 与 SQL 项目简介
四.创建 Catalog 与 DataBase
五.查询表数据

flink运行时组件和调度原理
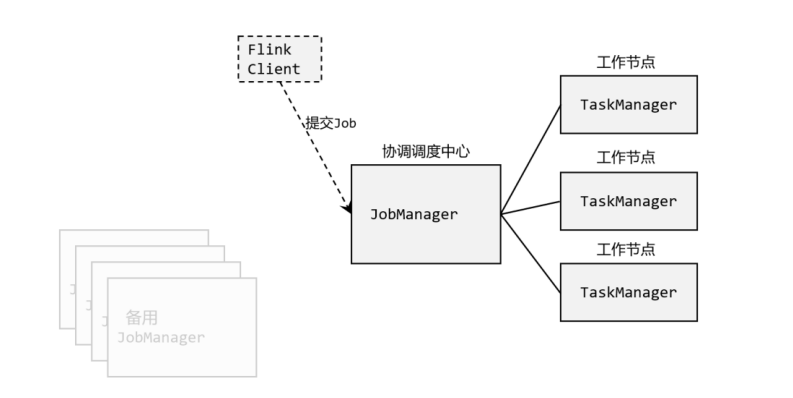
一、flink运行时组件、工作流程
1、flink运行时四大组件介绍 Flink运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作: 作业管理器(JobManager) 资源管理器(ResourceManager) 任务管…
Flink从入门到放弃之入门篇(十一)-Flink History Server(附源码经验分享)
背景
在我们实际生产开发中,Flink作业通常以per-job的模式提交到yarn集群上运行。当作业结束或因异常退出后,此时无法从yarn web ui上查看具体的日志信息来定位异常问题;如果yarn端未开启日志聚合,yarn logs命令就无法使用了&a…

Flink从入门到放弃之入门篇(三)-2w字深度剖析Transformation
转换算子
一个流的转换操作将会应用在一个或者多个流上面,这些转换操作将流转换成一个或者多个输出流,将这些转换算子组合在一起来构建一个数据流图。大部分的数据流转换操作都是基于用户自定义函数udf。udf函数打包了一些业务逻辑并定义了输入流的元素…
Hudi-集成Flink
文章目录集成Flink环境准备sql-client方式启动sql-client插入数据查询数据更新数据流式插入code 方式环境准备代码类型映射核心参数设置去重参数并发参数压缩参数文件大小Hadoop参数内存优化读取方式流读(Streaming Query)增量读取(Increment…

【Flink学习】入门教程之Streaming Analytics
文章目录流式分析概要使用 Event TimeWatermarks延迟 VS 正确性延迟使用 WatermarksWindows概要窗口分配器窗口应用函数ProcessWindowFunction 示例增量聚合示例晚到的事件深入了解窗口操作滑动窗口是通过复制来实现的时间窗口会和时间对齐window 后面可以接 window空的时间窗口…
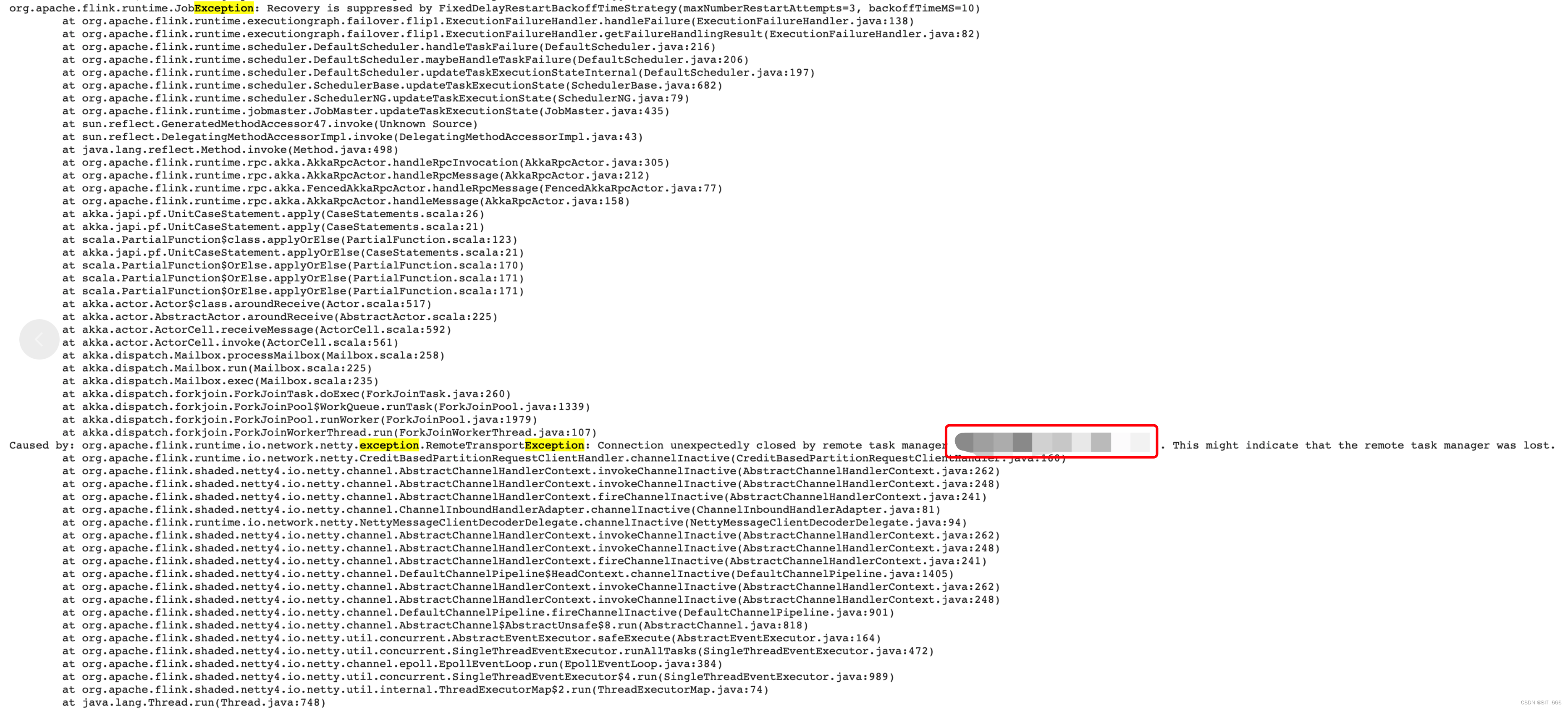
Flink / Kafka 异常 - 6.Recovery is suppressed by FixedDelayRestartBackoffTimeStrategy 排查与修复
一.引言
使用 Flink - Kafka 接数据 Source 时程序报错:
org.apache.flink.runtime.JobException: Recovery is suppressed by FixedDelayRestartBackoffTimeStrategy
任务每次启动后持续10min左右,然后 RUNNING -> FAILED,如此重启失败了多次。 二.问题现象
1.任务 …
快手基于 Apache Flink 的实时数仓建设实践
摘要:本文整理自快手实时数据开发工程师冯立,快手实时数据开发工程师羊艺超,在 Flink Forward Asia 2022 实时湖仓专场的分享。本篇内容主要分为四个部分: 快手实时数仓的发展实时数仓建设方法论实时数仓场景化实战未来规划点击查…
大数据开发|Hadoop分布式集群环境构建
一直想编写一系列有关大数据开发、数据挖掘、云计算等相关课程的学习资料,为零基础又想从事大数据行业的小伙伴提供一些参考。今天第一篇《Hadoop分布式集群环境构建(1)》终于和大家见面了。
一
集群主机规划 二
软件安装包准备
会将软件…
大数据案例 -- 互联网日志实时收集和实时计算的简单方案
作为互联网公司,网站监测日志当然是数据的最大来源。我们目前的规模也不大,每天的日志量大约1TB。后续90%以上的业务都是需要基于日志来完成,之前,业务中对实时的要求并不高,最多也就是准实时(延迟半小时以…
二十四:Flink 中 watermark 的定义和使用
我们提过窗口和时间的概念,Flink 框架支持事件时间、摄入时间和处理时间三种。Watermark(水印)的出现是用于处理数据从 Source 产生,再到转换和输出,在这个过程中由于网络和反压的原因导致了消息乱序问题。
那么在实际的开发过程中,如何正确地使用 Watermark 呢?
使用…

⑤FlinkSqlTable编程案例
前面使用 Flink Table & SQL 的 API 实现了最简单的 WordCount 程序。在这一课时中,将分别从 Flink Table & SQL 的背景和编程模型、常见的 API、算子和内置函数等对 Flink Table & SQL 做一个详细的讲解和概括,最后模拟了一个实际业务场景使用 Flink Table &…

③Flink入门程序WordCount和Sql实现
Flink 开发环境 通常来讲,任何一门大数据框架在实际生产环境中都是以集群的形式运行,而我们调试代码大多数会在本地搭建一个模板工程,Flink 也不例外。
Flink 一个以 Java 及 Scala 作为开发语言的开源大数据项目,通常我们推荐使用 Java 来作为开发语言,Maven 作为…
flink内存参数配置学习
直接上官网 配置 JobManager 内存 | Apache Flink配置 JobManager 内存 # JobManager 是 Flink 集群的控制单元。 它由三种不同的组件组成:ResourceManager、Dispatcher 和每个正在运行作业的 JobMaster。 本篇文档将介绍 JobManager 内存在整体上以及细粒度…
走近大数据——什么是大数据、计算架构的发展
文章目录 一、什么是大数据二、大数据计算架构的发展1.RDBMS阶段2.Hadoop Map-Reduce阶段3.Spark阶段4.Flink阶段 参考 一、什么是大数据
大数据是指无法在有限时间内用常规软件工具对其进行获取、存储、管理和处理的数据集合。 大数据的特点: 海量化:数…
【Flink SQL】基本概念
目录 一、时间属性Event TimeProcessing Time 二、水印作用定义watermark 策略 三、窗口函数作用分类Window聚合滚动窗口(TUMBLE)定义语法标识函数使用Event Time统计每个用户每分钟在指定网站的单击数示例测试数据测试语句测试结果使用Processing Time统…
Flink从入门到精通之-10容错机制
Flink从入门到精通之-10容错机制
流式数据连续不断地到来,无休无止;所以流处理程序也是持续运行的,并没有一个明确的结束退出时间。机器运行程序,996 起来当然比人要容易得多,不过希望“永远运行”也是不切实际的。因…
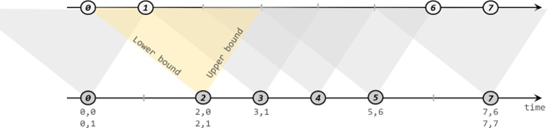
Flink CDC 实时mysql到mysql
CDC 的全称是 Change Data Capture ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。
mysqlcdc需要mysql开启binlog&a…
实时数仓建设第1问: 一直使用top N,为何duplicate状态和rank状态的TTL执行策略不一样?
在1.16之前 rank为了提高效率,会使用缓存降低对状态的访问。缓存就是一个普通的MAP集合,如果不适应定时器在状态过期后删除缓存数据就会导致缓存数据一直增大导致OOM。
kvSortedMap new LRUMap<>(lruCacheSize);
public class LRUMap<K, V>…
Flink实时计算资源如何优化
flink实时计算任务可以从以下四个方面进行优化 内存优化:Flink任务需要大量的内存来存储数据和状态信息。因此,我们需要尽可能地减少内存的使用量。可以通过以下几种方式来实现: 使用更小的窗口大小:窗口大小越大,需要…
centos7的flink安装过程
安装步骤
下载flink的tar.gz包修改flink的conf配置下载需要的lib包
具体代码(以flink1.15为例)
# 下载flink的tar.gz包
wget https://archive.apache.org/dist/flink/flink-1.15.4/flink-1.15.4-bin-scala_2.12.tgz
tar -zxvf flink-1.15.4-bin-scala…

16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
Caused by: java.lang.ClassNotFoundException: org.apache.flink.table.catalog.Catalog
Caused by: java.lang.ClassNotFoundException: org.apache.flink.table.catalog.Catalog
方法
在poml文件中,导入的flink-table依赖把“ <scope>”去掉就好了
比如:原依赖
<dependency><groupId>org.apache.flink</groupId>…

大数据-玩转数据-Flink窗口
一、Flink 窗口 理解
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击…
Flink流批一体计算(20):DataStream API和Table API互转
目录 举个例子
连接器
下载连接器(connector)和格式(format)jar 包
依赖管理 如何使用连接器 举个例子
StreamExecutionEnvironment集成了DataStream API,通过额外的函数扩展了TableEnvironment。
下面代码演示两…
《Flink学习笔记》——第九章 多流转换
无论是基本的简单转换和聚合,还是基于窗口的计算,我们都是针对一条流上的数据进行处理的。而在实际应用中,可能需要将不同来源的数据连接合并在一起处理,也有可能需要将一条流拆分开,所以经常会有对多条流进行处理的场…

第三章 Flink DataStream API
Flink 系列教程传送门
第一章 Flink 简介
第二章 Flink 环境部署
第三章 Flink DataStream API
第四章 Flink 窗口和水位线
第五章 Flink Table API&SQL
第六章 新闻热搜实时分析系统 一、DataStream API是什么?
Flink 中的 DataStream 程序是对数据流&a…
Flink / Scala - 20.Scala API Extensions 扩展
目录
一.引言
二.使用说明
三.Extensions API
1.[DataStream] map => mapWith
2.[DataStream] flatMap => flatMapWith
3.[Data
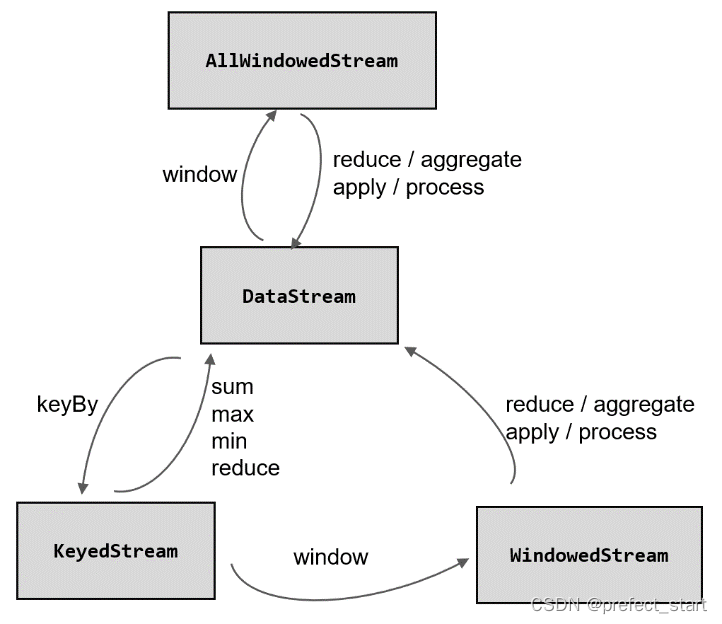
Flink从入门到精通系列(五)
6、Flink 中的时间和窗口
6.1、时间语义
6.1.1、Flink 中的时间语义
Flink 是一个分布式处理系统。分布式架构最大的特点,就是节点彼此独立、互不影响,这带来了更高的吞吐量和容错性。
但有利必有弊,在分布式系统中,节点“各自…
Flink-Connectors(连接器)(2)Redis
Flink-Connectors(连接器)(2)Redis
flink 提供了专门操作redis 的RedisSink,使用起来更方便,而且不用我们考虑性能的问题,接下来将主要介绍RedisSink 如何使用
https://bahir.apache.org/docs/flink/current/flink-s…

玩转大数据开发套件--(2)
目前大数据工具林林总总,能解决的问题各方各面,但是在真正落地到企业的时候却往往因使用问题遇到障碍。为此星环针对使用体验上的需求打造大数据开发套件Transwarp Studio,深化大数据技术的应用,在数字化浪潮下推动大数据技术对产…
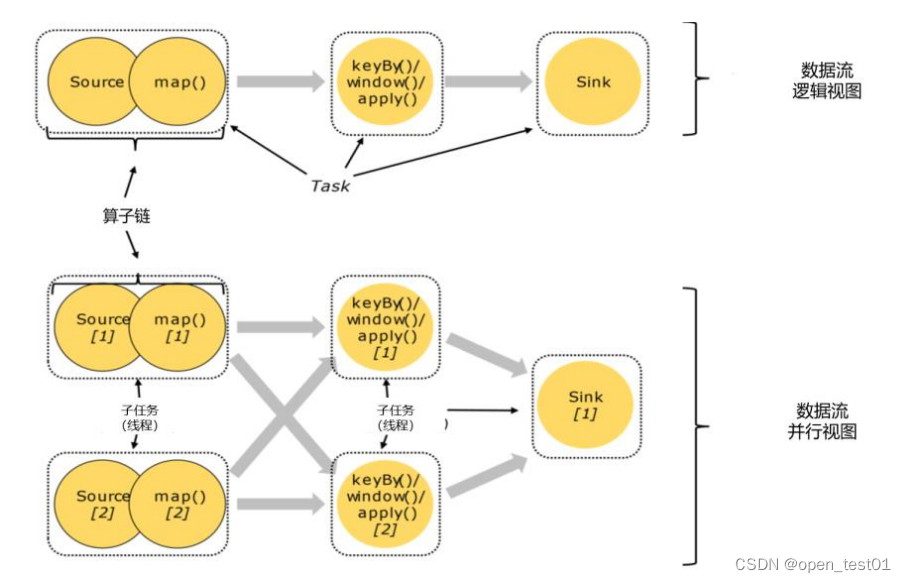
Flink概念基础-并行度、算子链
并行度
算子链 并行度 一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并 行子任务的数据流,就是并行数据流,它需要多个分区(stream partition&a…
如何成为一名大数据开发工程师,工作经验总结
如何成为一名大数据开发工程师,工作经验总结
原画心旗 2019-11-06 13:35:22
首先,我个人进入大数据行业也纯属偶然,当年实习的时候做的是纯纯的Java开发,后来正式毕业了以后找了份Java开发的工作,本以为和大多数Java…
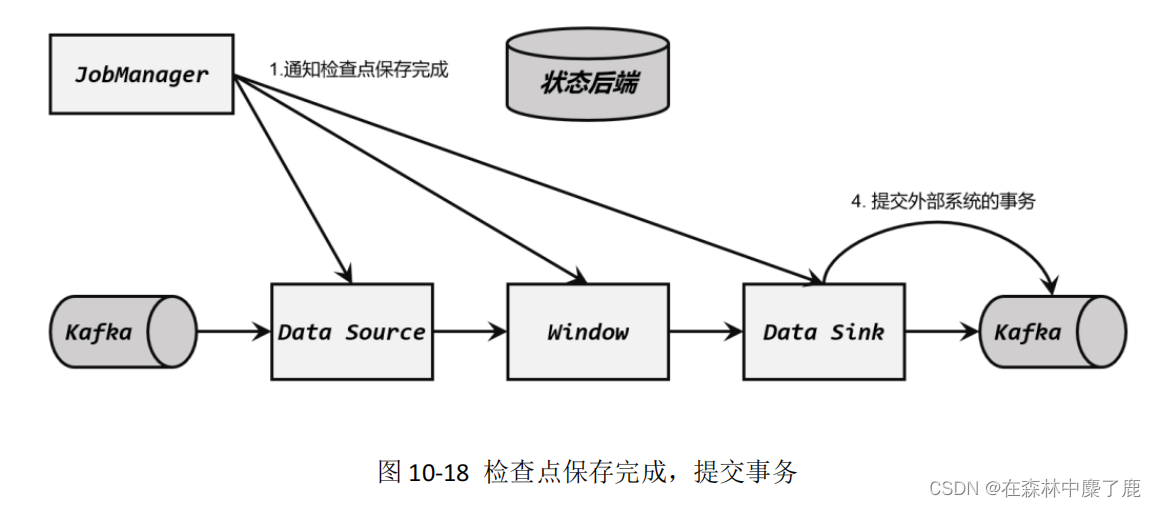
Flink (十) --------- 容错机制
目录一、 检查点(Checkpoint)1. 检查点的保存2. 从检查点恢复状态3. 检查点算法4. 检查点配置5. 保存点(Savepoint)二、状态一致性1. 一致性的概念和级别2. 端到端的状态一致性三、端到端精确一次(end-to-end exactly-…
构建高效实时数据流水线:Flink、Kafka 和 CnosDB 的完美组合
当今的数据技术生态系统中,实时数据处理已经成为许多企业不可或缺的一部分。为了满足这种需求,Apache Flink、Apache Kafka和CnosDB等开源工具的结合应运而生,使得实时数据流的收集、处理和存储变得更加高效和可靠。本篇文章将介绍如何使用 F…

Flink(java版)
watermark
时间语义和 watermark 注意:数据进入flink的时间:如果用这个作为时间语义就不存在问题,但是开发中往往会用处理时间
作为时间语义这里就需要考虑延时的问题。
如上图,数据从kafka中获取出来,从多个分区中获取…
【实战-05】 flinksql look up join
摘要
look up join 能做什么? 不饶关子直接说答案, look up join 就是 广播。 重要是事情说三遍,广播。flinksql中的look up join 就类似于flinks flink Datastream api中的广播的概念,但是又不完全相同,对于初次访问…
flink redis connector需要防止包冲突
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
<dependency><groupId>org.apache.bahir</groupId><artifactId

Flink基础实操-计算单词出现次数
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…
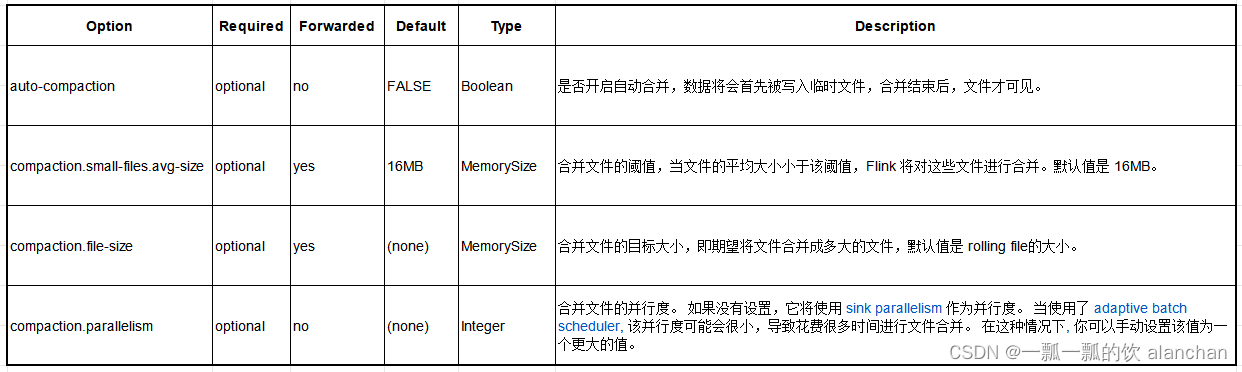
43、Flink之Hive 读写及详细验证示例
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
hivecatalog异常
Caused by: org.apache.flink.table.api.Valida ationException: Could not find any factory for identifier hive’that implementsorg. a apache. flink. table. planner. delegation. ParserFactory’in the classpath.
flink1.14.4使用hive catalog在hive中建表失败
参考…
实战:大数据Flink CDC同步Mysql数据到ElasticSearch
文章目录 前言知识积累CDC简介CDC的种类常见的CDC方案比较 Springboot接入Flink CDC环境准备项目搭建 本地运行集群运行将项目打包将包传入集群启动远程将包部署到flink集群 写在最后 前言
前面的博文我们分享了大数据分布式流处理计算框架Flink和其基础环境的搭建,…
flink学习之state
state作用
保留当前key的历史状态。
state用法
ListState<Integer> vipList getRuntimeContext().getListState(new ListStateDescriptor<Integer>("vipList", TypeInformation.of(Integer.class)));
有valueState listState mapstate 。冒失没有se…
实验8 Flink初级编程实践
由于CSDN上传md文件总是会使图片失效 完整的实验文档地址如下: https://download.csdn.net/download/qq_36428822/85814518 实验环境
实验环境:本机:Windows 10 专业版 Intel Core™ i7-4790 CPU 3.60GHz 8.00 GB RAM 64 位操作系统, 基于 …
Flink复习3-2-4-6-1(v1.17.0): 应用开发 - DataStream API - 状态和容错 - 数据类型序列化 - 概述
Data Types & Serialization Supported Data Types(支持的数据类型)Tuples and Case ClassesPOJOsPrimitive Types(基本数据类型)General Class Types(一般类型)ValuesHadoop WritablesSpecial Types&a…
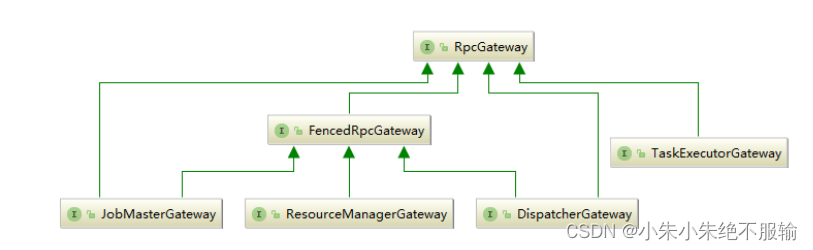
Flink内核源码(二)组件通信
最近在学习了尚硅谷的Flink内核源码解析,内容很多,因此想要整理学习一下。Flink的版本是1.12.0。
第二章就来从源码层面学习一下Flink的组件通信。
问题整理: 1. Flink组件之间是怎么通信的? 2. Flink中的RPC方法。
Flink 内…

flink时间处理语义
背景
在flink中有两种不同的时间处理语义,一种是基于算子处理时间的时间,也就是以flink的算子所在的机器的本地时间为准,一种是事件发生的实际时间,它只与事件发生时的时间有关,而与flink算子的所在的本地机器的本地时…
深入理解Flink Mailbox线程模型
文章目录 整体设计processMail1.Checkpoint Tigger2.ProcessingTime Timer Trigger processInput兼容SourceStreamTask 整体设计
Mailbox线程模型通过引入阻塞队列配合一个Mailbox线程的方式,可以轻松修改StreamTask内部状态的修改。Checkpoint、ProcessingTime Ti…

flink的几种常见的执行模式
背景
在运行flink时,我们经常会有几种不同的执行模式,比如在IDE中启动时,通过提交到YARN上,还有通过Kebernates启动时,本文就来记录一下这几种模式
flink的几种执行模式
flink嵌入式模式: 这是一种我们在…
Flink K8s Operator 如何提交flink SQL
[FLINK-32735] Flink SQL Gateway for Native Kubernetes Application Mode - ASF JIRA FLIP-316: Introduce SQL Driver - Apache Flink - Apache Software Foundation jar把sql套进去提交任务
等新版本实现
version: flink1.19.0
Flink CDC数据同步
背景
随着信息化程度的不断提高,企业内部系统的数量和复杂度不断增加,因此,数据库系统的同步问题已成为越来越重要的问题。
缓存失效
在缓存中缓存的条目(entry)在源头被更改或者被删除的时候立即让缓存中的条目失效。如果缓存在一个独立的…
flink sql热加载自定义函数 不重启flink集群
1. 流程
第一步 先写好udf 函数 // 自定义函数类public static class myFunction extends ScalarFunction{public int eval(String value) {return value.length();}}第二步打包后 放到一个位置比如:flink/lib 中
第三步: 进入flink 客户端 ./sql-cli…
centos安装flink,通过windows访问webui
1. 安装flink
1.1. flink的下载
通过flink官网下载flink安装包
https://flink.apache.org/ 下载安装包
1.2 flink在centos上的安装
将下载好的flink-1.17.1-bin-scala_2.12.tgz安装包放到centos目录下 解压文件:
[rootlocalhost ~]# tar -zxvf flink-1.17.…
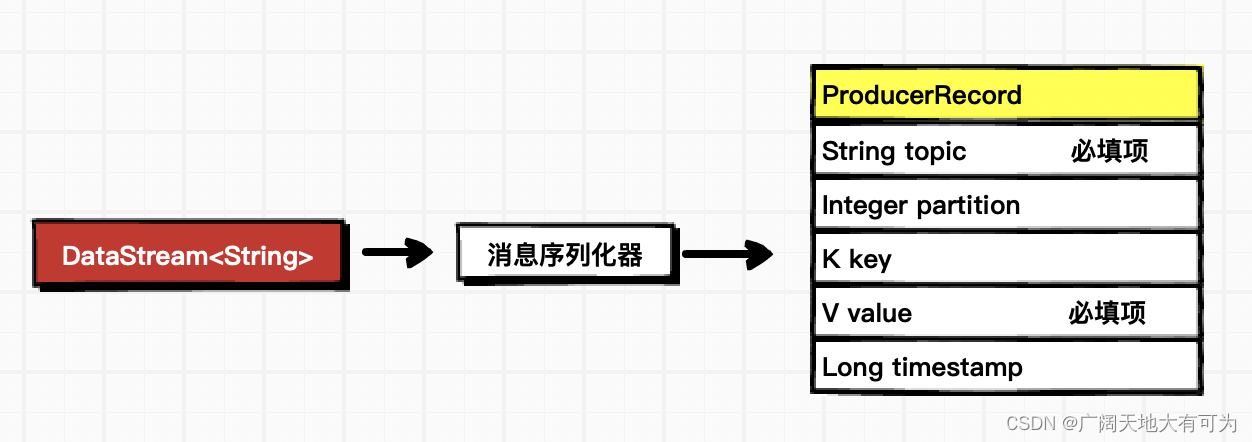
6.2、Flink数据写入到Kafka
目录
1、添加POM依赖
2、API使用说明
3、序列化器
3.1 使用预定义的序列化器
3.2 使用自定义的序列化器
4、容错保证级别
4.1 至少一次 的配置
4.2 精确一次 的配置
5、这是一个完整的入门案例 1、添加POM依赖
Apache Flink 集成了通用的 Kafka 连接器,使…
flink-1.14.4启动报错setPreferCheckpointForRecovery(Z)v
从flink1.12升级到flink1.14,修改了pom.xml的flink-version,打包的时候发现报错: // 当有较新的 Savepoint 时,作业也会从 Checkpoint 处恢复env.getCheckpointConfig().setPreferCheckpointForRecovery(true); 于是屏蔽了这段配置…
【flink进阶】-- Flink kubernetes operator 版本升级
目录
1、检查当前 flink kubernetes operator 版本 2、停止生产上正在运行的 flink job
3、升级 CRD

《Flink学习笔记》——第十一章 Flink Table API和 Flink SQL
Table API和SQL是最上层的API,在Flink中这两种API被集成在一起,SQL执行的对象也是Flink中的表(Table),所以我们一般会认为它们是一体的。Flink是批流统一的处理框架,无论是批处理(DataSet API&a…
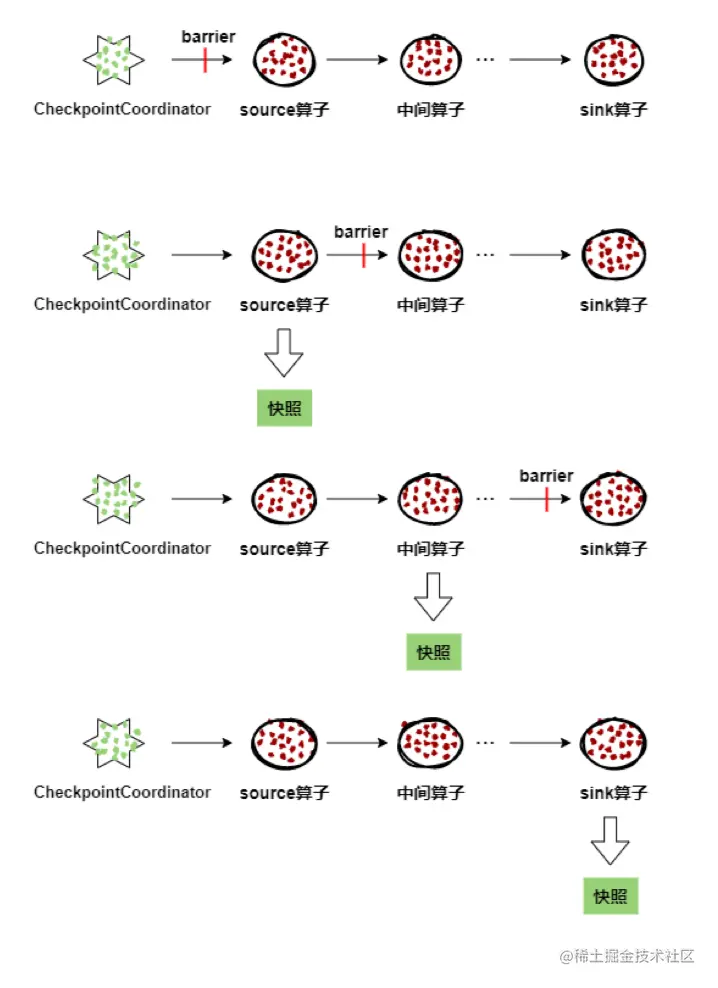
Flink的checkpoint是怎么实现的?
分析&回答
Checkpoint介绍
Checkpoint容错机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。Flink的Checkpoint机制原理来自“Chandy-Lamport alg…
Spark与Flink的区别
分析&回答
(1)设计理念 1、Spark的技术理念是使用微批来模拟流的计算,基于Micro-batch,数据流以时间为单位被切分为一个个批次,通过分布式数据集RDD进行批量处理,是一种伪实时。 2、Flink是基于事件驱动的,是面向流的处理框架, Flink基于…
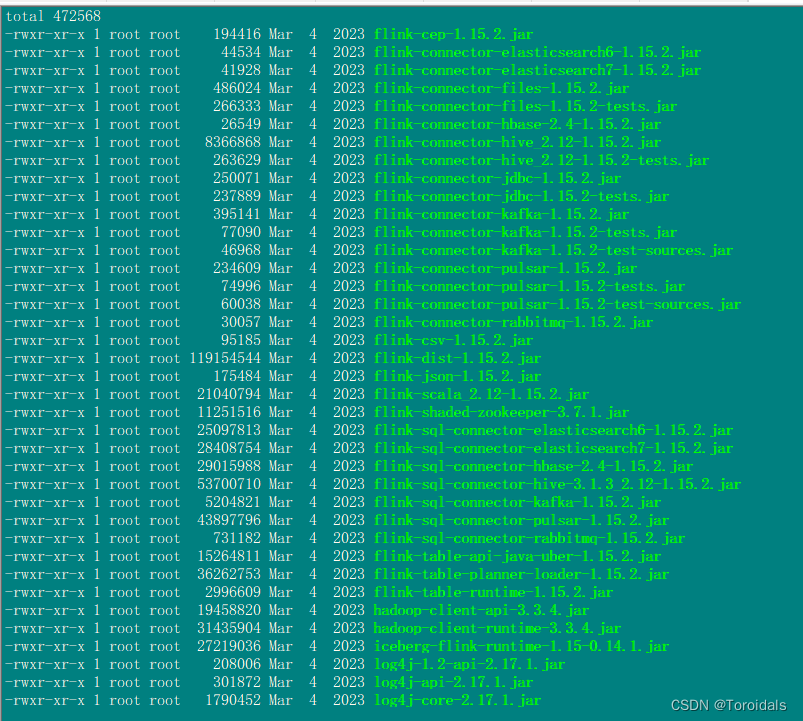
Flink、Spark、Hive集成Hudi
环境描述:
hudi版本:0.13.1
flink版本:flink-1.15.2
spark版本:3.3.2
Hive版本:3.1.3
Hadoop版本:3.3.4 一.Flink集成Hive
1.拷贝hadoop包到Flink lib目录
hadoop-client-api-3.3.4.jar
hadoop-client-runtime-3.3.4.jar
2.下载上传flink-hive的jar包
flink-co…
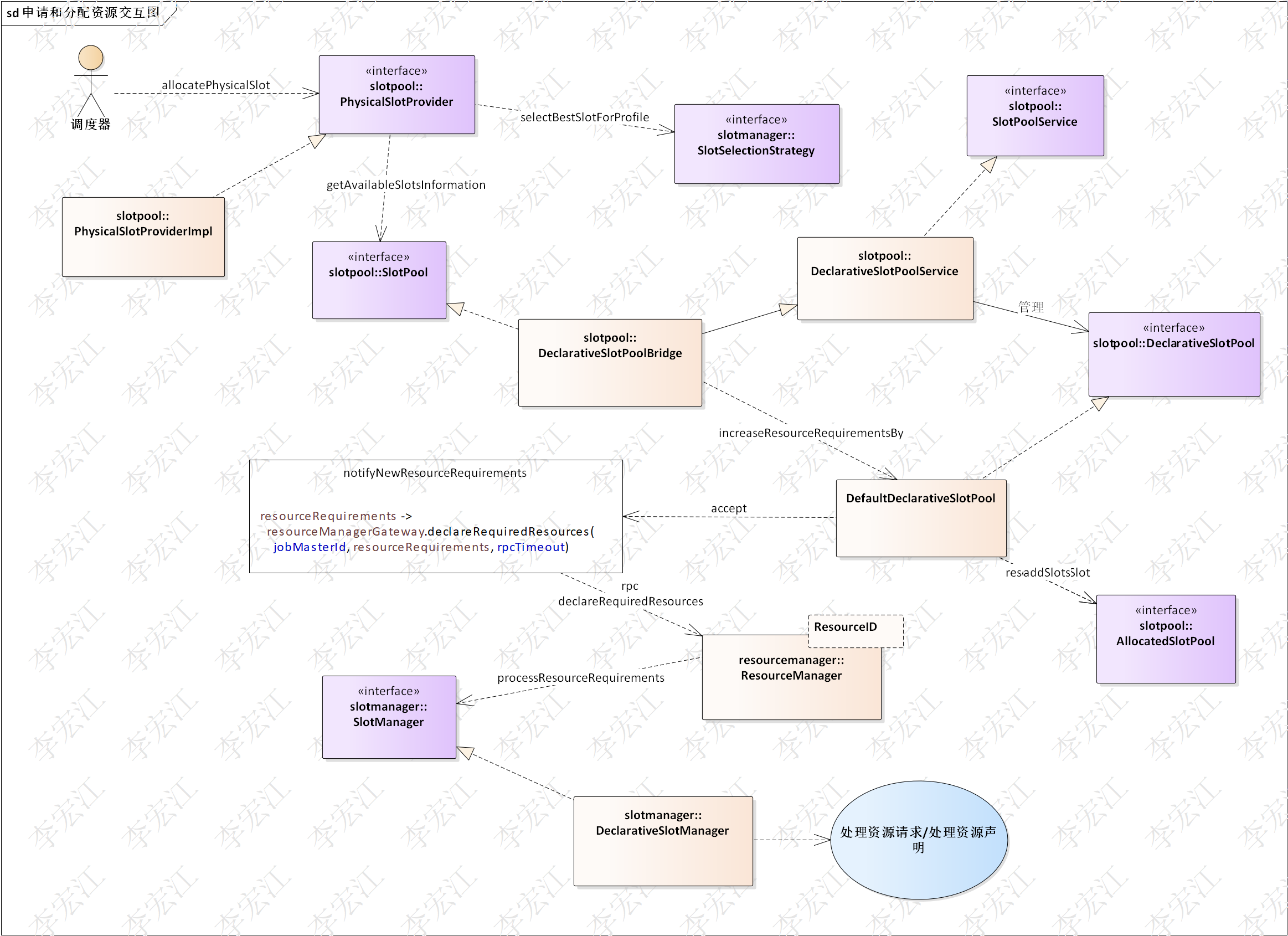
flink集群与资源@k8s源码分析-资源I 资源请求
1 资源
资源分析分3部分,资源请求,资源提供,声明式资源管理,本文是第一部分资源请求
2 场景 资源处理有声明式处理资源和细粒度处理资源 是两个实现,两者不是并行的两种实现策略,声明式是资源申请和分配方式,粒度是指资源分割方式,细粒度按需可变的资源,粗粒度是固定…
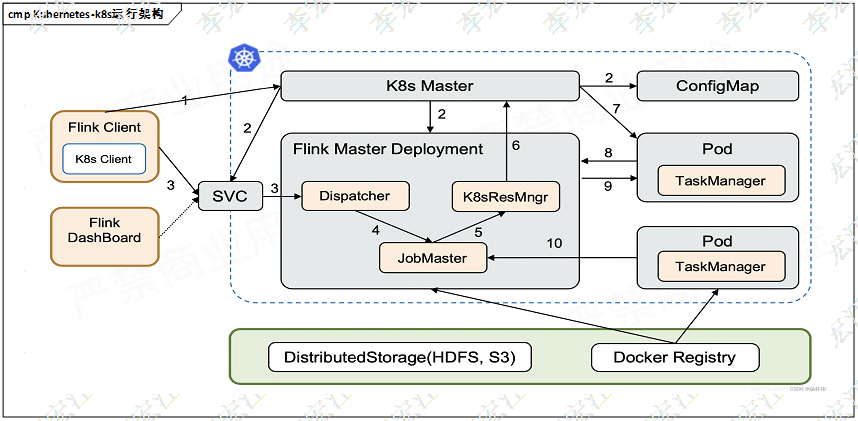
flink原理源码分析(一) 集群与资源@k8s
1 简介
集群和资源模块提供动态资源能力,是分布式系统关键基础设施,分布式datax,分布式索引,事件引擎都需要集群和资源的弹性资源能力,提高扩展和作业处理能力。本文分析flink的集群和资源的k8s模块,深入了…

如何排查 Flink Checkpoint 失败问题?
分析&回答
这是 Flink 相关工作中最常出现的问题,值得大家搞明白。
1. 先找到超时的subtask序号
图有点问题,因为都是成功没失败的,尴尬了。 借图: 2. 找到对应的机器和任务
方法很多,这里看自己习惯和公司提供…
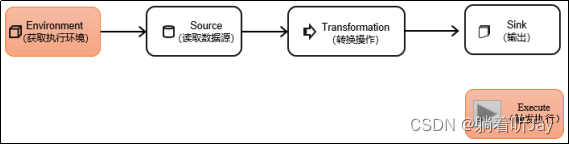
大数据之-Flink学习笔记
Flink
Apache Flink — 数据流上的有状态计算。
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算处理。
任何类型的数据都以事件流的形式生成。信用卡交易、传感器测量、机器日志或网站或移动应用程序 2上的用户交互,…
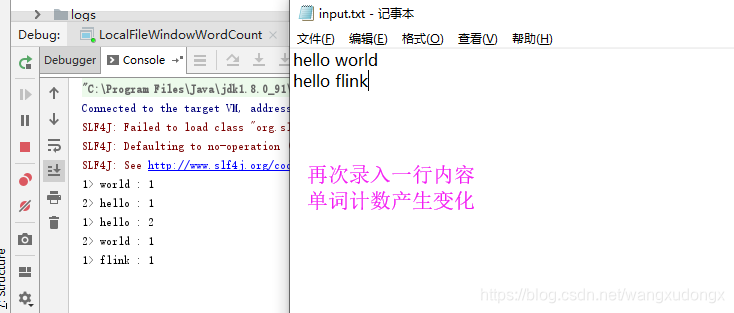
Flink系列文章 java实现增量文件WordCount,任务部署到yarn
Flink系列文章 java实现增量文件WordCount,任务部署到yarn我们的目标FileWindowWordCount引入依赖码代码在IDE里运行看下效果Apache Flink - 数据流上的有状态计算 Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计…
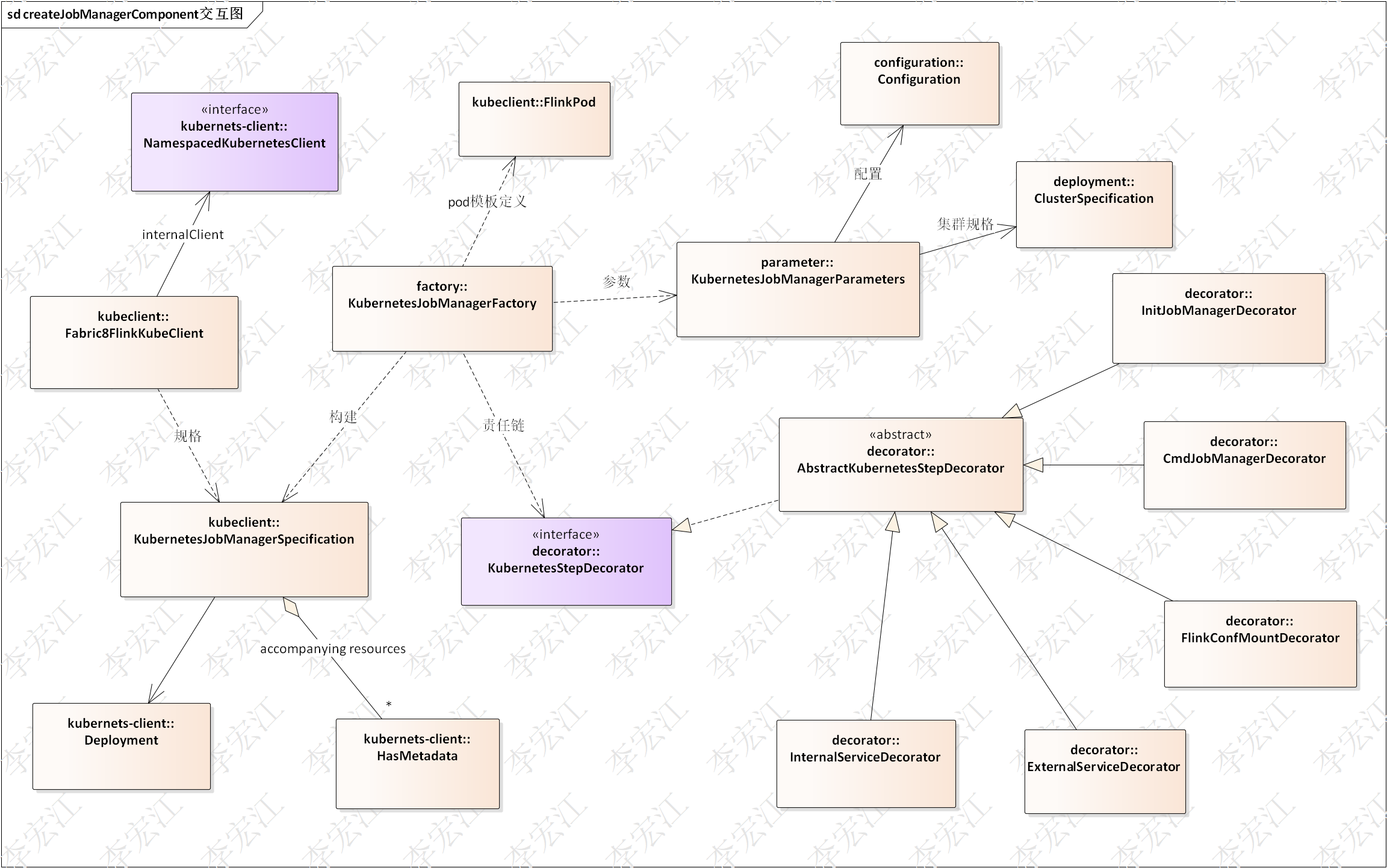
flink集群与资源@k8s源码分析-flink kubeclient
flink kubeclient是面向flink应用的fabric8 kubeclient的封装,本文分析flink如何封装kubeclient,核心组件是装饰器,资源和ServiceType,下面通过分析业务创建作业管理器组件(createJobManagerComponent)了解flink kubeclient
1 场景 2 新建作业管理器组件 1. KubernetesJob…
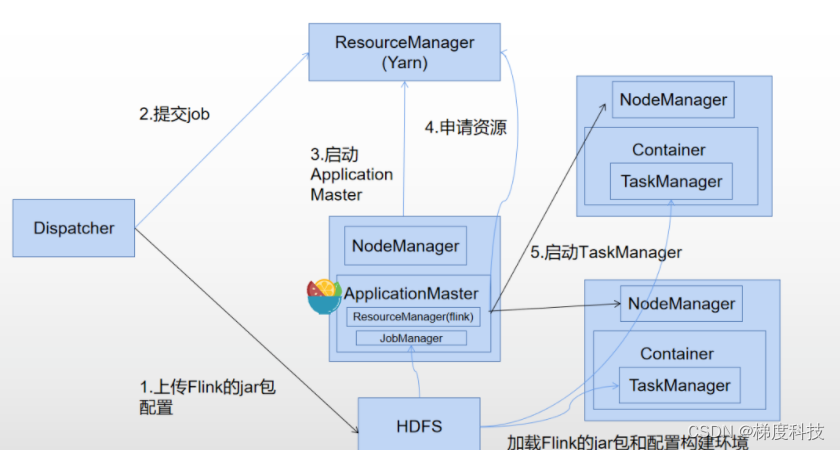

Flink-Kafka-MySQL
2018年开始处理大数据相关的业务,Flink作为流处理新秀,在实时计算领域发挥着越来越大作用,本文主要整理在以往开发中Flink使用Kafka作为数据源,计算处理之后,再将数据存到MySQL的处理过程。 前置条件 启动zookeeper&a…

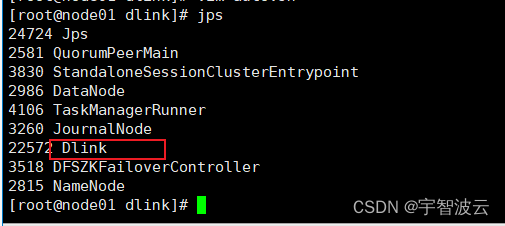
修炼k8s+flink+hdfs+dlink(一:安装dlink)
一:mysql初始化。
mysql -uroot -p123456
create database dinky;
grant all privileges on dinky.* to dinky% identified by dinky with grant option;
flush privileges;二:上传dinky。
上传至目录/opt/app/dlink
tar -zxvf dlink-release-0.7.4.t…
修炼k8s+flink+hdfs+dlink(三:安装dlink)
一:mysql初始化。
mysql -uroot -p123456
create database dinky;
grant all privileges on dinky.* to dinky% identified by dinky with grant option;
flush privileges;二:上传dinky。
上传至目录/opt/app/dlink
tar -zxvf dlink-release-0.7.4.t…

Flink中的时间和窗口
1.Flink的时间和窗口
在传统的批处理系统中,我们可以等到一批数据全部都到齐了之后,对其做相关的计算;但是在实时处理系统中,数据是源源不断的,正常情况下,我们就得来一条处理一条。那么,我们应…
Flink 中kafka broker缩容导致Task一直重启
背景
Flink版本 1.12.2 Kafka 客户端 2.4.1 在公司的Flink平台运行了一个读Kafka计算DAU的流程序,由于公司Kafka的缩容,直接导致了该程序一直在重启,重启了一个小时都还没恢复(具体的所容操作是下掉了四台kafka broker࿰…
Flink中jobmanager、taskmanager、slot、task、subtask、Parallelism的概念
场景 一个工厂有三个车间每个车间两条生产线 生产流程如下 原料->加工->过滤->分类->美化->包装->下线 JobManager:工厂
在上述场景中,工厂就是jobManager,负责协调、调度和监控整个生产过程
TaskManager:车间…

Flink on k8s容器日志生成原理及与Yarn部署时的日志生成模式对比
Flink on k8s部署日志详解及与Yarn部署时的日志生成模式对比
最近需要将flink由原先部署到Yarn集群切换到kubernetes集群,在切换之后需要熟悉flink on k8s的运行模式。在使用过程中针对日志模块发现,在k8s的容器中,flink的系统日志只有jobma…
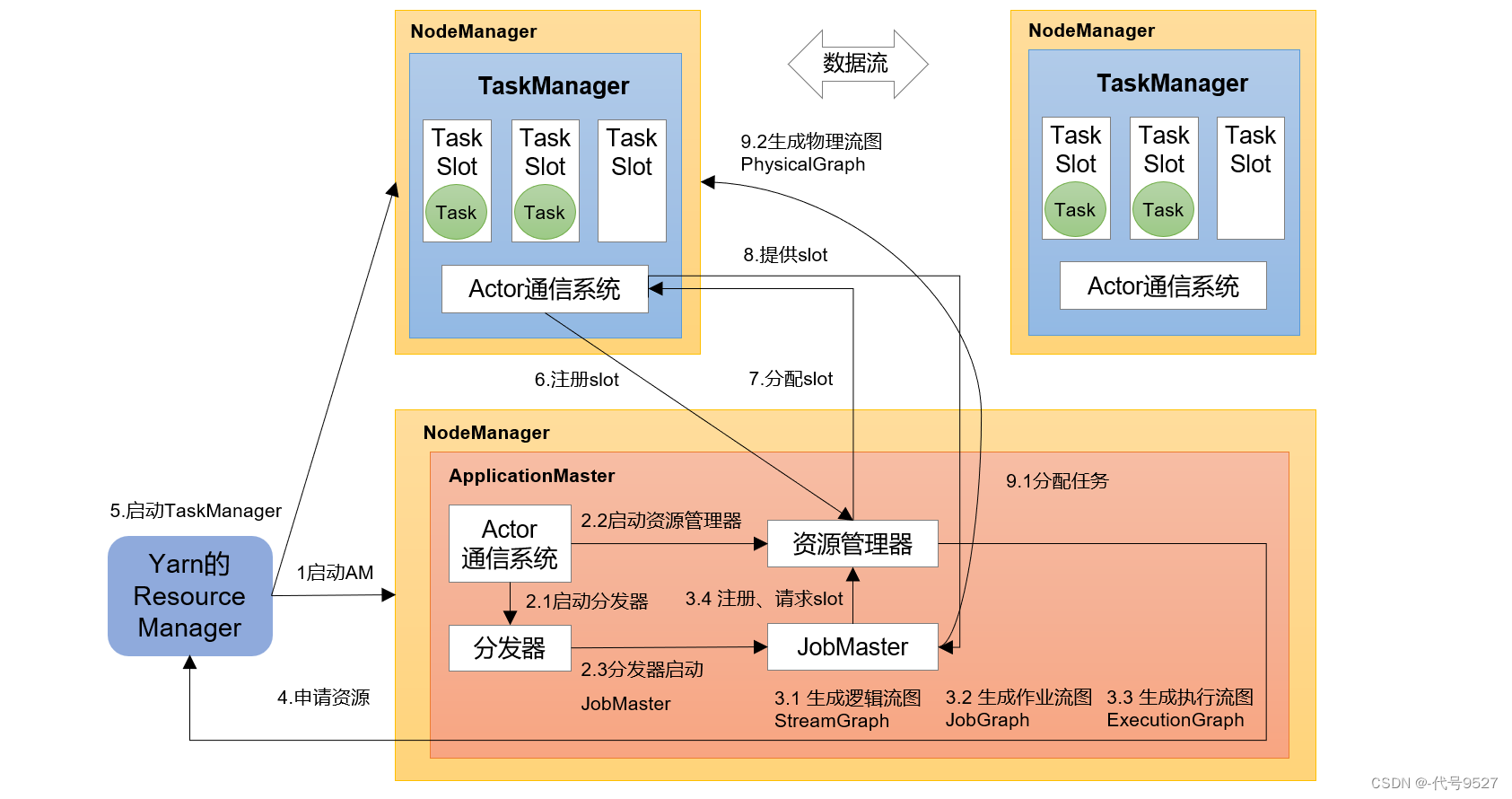
【基础篇】三、Flink集群角色、系统架构以及作业提交流程
文章目录 1、集群角色2、部署模式3、Flink系统架构3.1 作业管理器(JobManager)3.2 任务管理器(TaskManager) 4、独立部署会话模式下的作业提交流程5、Yarn部署的应用模式下作业提交流程 1、集群角色
Flink提交作业和执行任务&…

flink 写入数据到 kafka 后,数据过一段时间自动删除
版本
flink 1.16.0kafka 2.3
流程描述: flink利用KafkaSource,读取kafka的数据,然后经过一系列的处理,通过KafkaSink,采用 EXACTLY_ONCE 的模式,将处理后的数据再写入到新的topic中。 问题描述࿱…
Flink中KeyBy、分区、分组的正确理解
1.Flink中的KeyBy
在Flink中,KeyBy作为我们常用的一个聚合类型算子,它可以按照相同的Key对数据进行重新分区,分区之后分配到对应的子任务当中去。 源码解析 keyBy 得到的结果将不再是 DataStream,而是会将 DataStream 转换为 Key…
Flink--2、Flink部署(Yarn集群搭建下的会话模式部署、单作业模式部署、应用模式部署)
星光下的赶路人star的个人主页 你必须赢过,才可以说不在乎输赢 文章目录 1、Flink部署1.1 集群角色1.2 Flink集群搭建1.2.1 集群启动1.2.2 向集群提交作业 1.3 部署模式1.3.1 会话模式(Session Mode)1.3.2 单作业模式(Per-Job Mod…

大数据-玩转数据-Flink状态编程(中)
一、键控状态
键控状态是根据输入数据流中定义的键(key)来维护和访问的。 Flink为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态。当任务处理…
Flink的基于两阶段提交协议的事务数据汇实现
背景
在flink中可以通过使用事务性数据汇实现精准一次的保证,本文基于Kakfa的事务处理来看一下在Flink 内部如何实现基于两阶段提交协议的事务性数据汇.
flink kafka事务性数据汇的实现
1。首先在开始进行快照的时候也就是收到checkpoint通知的时候,在…
修炼k8s+flink+hdfs+dlink(五:安装dockers,cri-docker,harbor仓库)
一:安装docker。(所有服务器都要安装)
安装必要的一些系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2添加软件源信息
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/cent…

从入门到进阶 之 ElasticSearch SpringData 继承篇
🌹 以上分享 从入门到进阶 之 ElasticSearch SpringData 继承篇,如有问题请指教写。🌹🌹 如你对技术也感兴趣,欢迎交流。🌹🌹🌹 如有需要,请👍点赞…
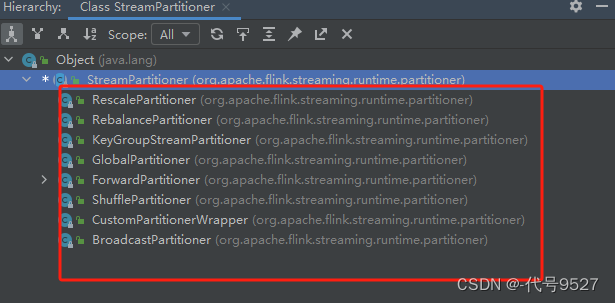
【API篇】四、Flink物理分区算子API
文章目录 1、 分区算子:随机分区2、分区算子:轮询分区3、分区算子:重缩放分区4、分区算子:广播5、分区算子:全局分区6、自定义分区 重分区,即数据"洗牌",将数据分配到下游算子的并行子…
修炼k8s+flink+hdfs+dlink(六:学习k8s)
一:增(创建)。
直接进行创建。
kubectl run nginx --imagenginx使用yaml清单方式进行创建。
二:删除。
kubectl delete pods/nginx
三:修改。
kubectl exec -it my-nginx – /bin/bash
四:查看。 …
0基础学习PyFlink——使用PyFlink的Sink将结果输出到外部系统
在《0基础学习PyFlink——使用PyFlink的SQL进行字数统计》一文中,我们直接执行了Select查询操作,在终端中直接看到了查询结果。
select word, count(1) as count from source group by word;
------------------------------------------------------
|…
0基础学习PyFlink——用户自定义函数之UDTF
大纲 表值函数完整代码 在《0基础学习PyFlink——用户自定义函数之UDF》中,我们讲解了UDF。本节我们将讲解表值函数——UDTF
表值函数
我们对比下UDF和UDTF
def udf(f: Union[Callable, ScalarFunction, Type] None,input_types: Union[List[DataType], DataTy…
大数据Flink简介与架构剖析并搭建基础运行环境
文章目录 前言Flink 简介Flink 集群剖析Flink应用场景Flink基础运行环境搭建Docker安装docker-compose文件编写创建并运行容器访问Flink web界面 前言
前面我们分别介绍了大数据计算框架Hadoop与Spark,虽然他们有的有着良好的分布式文件系统和分布式计算引擎,有的有…
《Flink学习笔记》——第十二章 Flink CEP
12.1 基本概念
12.1.1 CEP是什么 1.什么是CEP? 答:所谓 CEP,其实就是“复杂事件处理(Complex Event Processing)”的缩写;而 Flink CEP,就是 Flink 实现的一个用于复杂事件处理的库(…
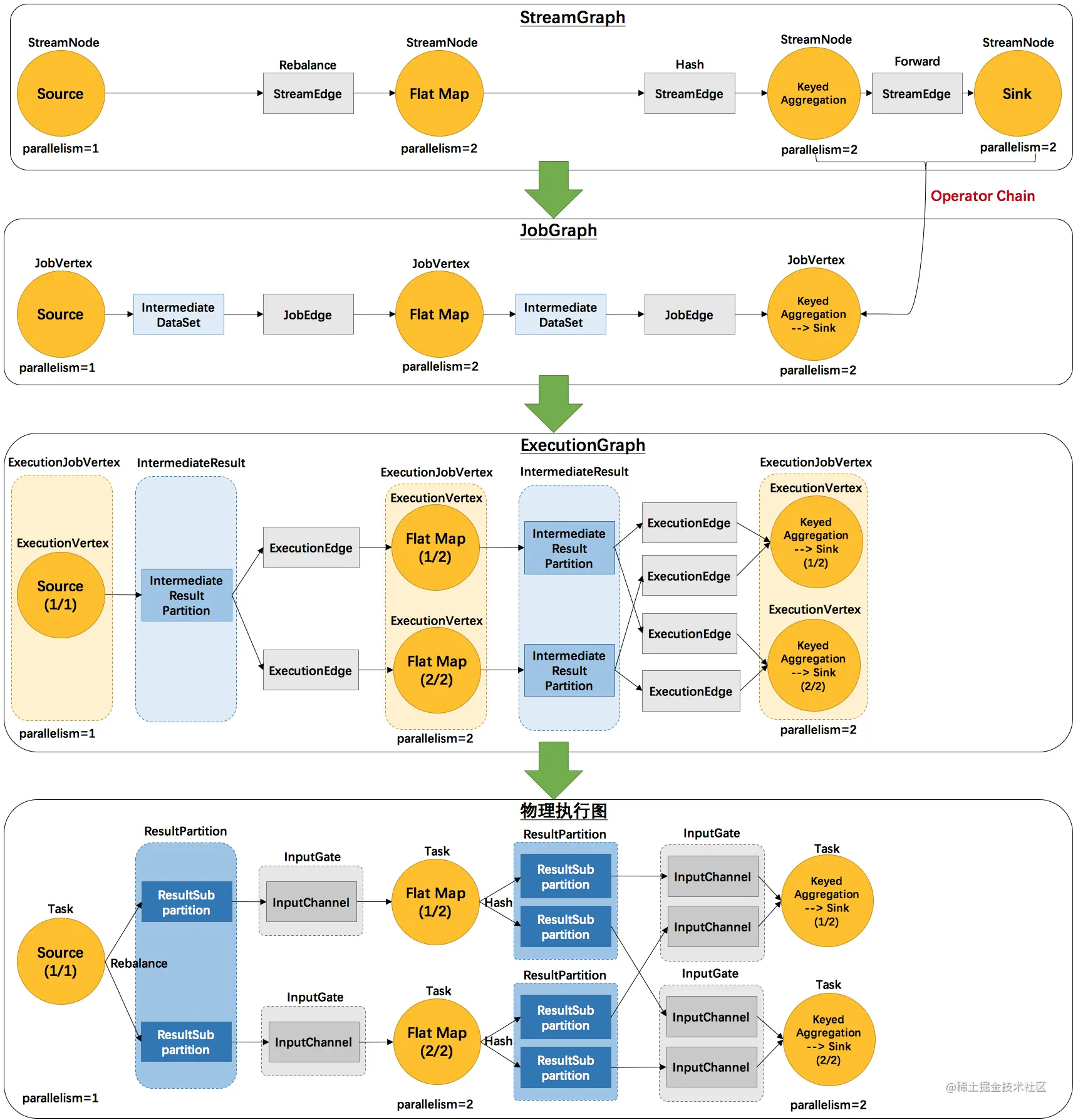
说说Flink on yarn的启动流程
分析&回答 核心流程
FlinkYarnSessionCli 启动的过程中首先会检查Yarn上有没有足够的资源去启动所需要的container,如果有,则上传一些flink的jar和配置文件到HDFS,这里主要是启动AM进程和TaskManager进程的相关依赖jar包和配置文件。接着…
Flink中RPC实现原理简介
前提知识
Akka是一套可扩展、弹性和快速的系统,为此Flink基于Akka实现了一套内部的RPC通信框架;为此先对Akka进行了解
Akka
Akka是使用Scala语言编写的库,基于Actor模型提供一个用于构建可扩展、弹性、快速响应的系统;并被应用…
如何处理 Flink 作业中的数据倾斜问题?
分析&回答
什么是数据倾斜?
由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点。
举例:一个 Flink 作业包含 200 个 Task 节点,其中有 199 个节点可以在很短的时间内完成计算。但是有一个节点执行时间…
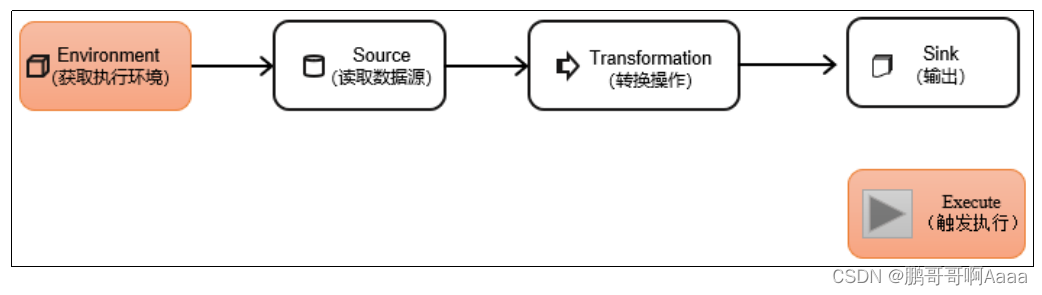
207.Flink(二):架构及核心概念,flink从各种数据源读取数据,各种算子转化数据,将数据推送到各数据源
一、Flink架构及核心概念
1.系统架构 JobMaster是JobManager中最核心的组件,负责处理单独的作业(Job)。一个job对应一个jobManager 2.并行度
(1)并行度(Parallelism)概念
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任…
部署和使用dinky问题总结
flink1.16 dinky(dlink)0.7.4 官方部署文档:http://www.dlink.top/docs/0.7/deploy_guide/build/ github部署文档:https://github.com/DataLinkDC/dinky/blob/v0.7.4/docs/docs/deploy_guide/deploy.md github issues:…
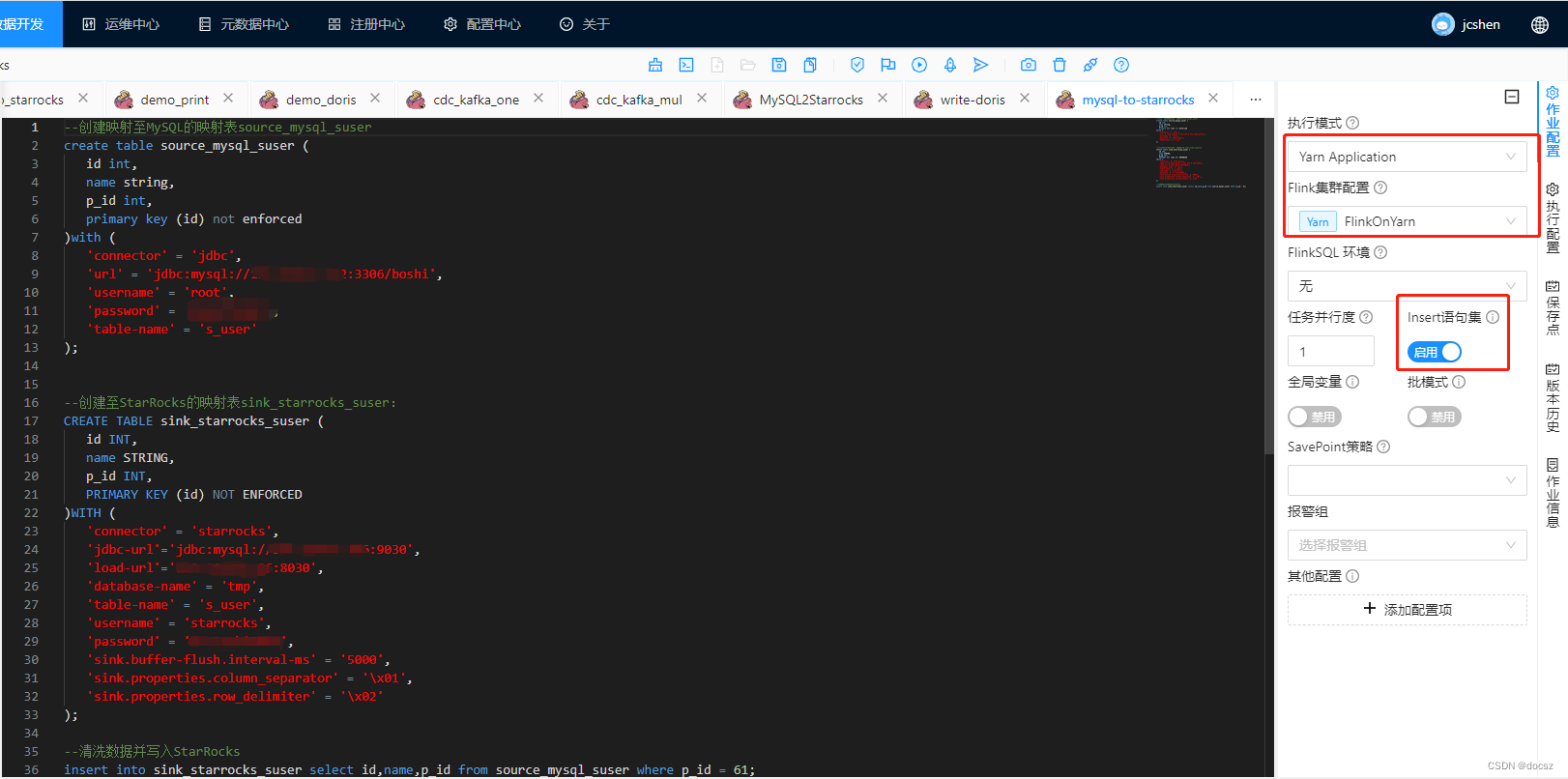
StarRocks数据导入
1、相关环境
Flink作为当前流行的流式计算框架,在对接StarRocks时,若直接使用JDBC的方式"流式"写入数据,对StarRocks是不友好的,StarRocks作为一款MVCC的数据库,其导入的核心思想还是"攒微批降频率&qu…

flink处理函数--副输出功能
背景
在flink中,如果你想要访问记录的处理时间或者事件时间,注册定时器,或者是将记录输出到多个输出流中,你都需要处理函数的帮助,本文就来通过一个例子来讲解下副输出
副输出
本文还是基于streaming-with-flink这本…

《十堂课学习 Flink SQL》第一章:引言和背景
第一章是关于 Flink SQL 课程的引言和背景。这一章旨在概述有关大数据处理、流处理以及 Flink SQL 的基础知识,以便接下来能够更好地结合上下文进行学习。 1.1 大数据处理的背景
1.1.1 大数据概述
大数据是指规模巨大、高度复杂且难以用传统数据库管理工具进行捕获…
Flink Flink中的分流
一、什么是分流
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个DataStream,定义一些筛选条件,将符合条件的数据拣选出来放到对应的流里。
二、基于filter算子的简单实现分流
其实根据条件筛选数据的需求…
Flink流批一体计算(21):Flink SQL之Flink DDL
目录
执行 CREATE 语句
Python脚本
Java代码
SQL语句
列定义
物理/常规列
元数据列
计算列
WATERMARK
PRIMARY KEY
PARTITIONED BY
AS select_statement Flink SQL是为了简化计算模型、降低您使用Flink门槛而设计的一套符合标准SQL语义的开发语言。
执行 CREATE 语…
自定义Flink kafka连接器Decoding和Serialization格式
前言
使用kafka连接器时:
1.作为source端时,接受的消息报文的格式并不是kafka支持的格式,这时则需要自定义Decoding格式。
2.作为sink端时,期望发送的消息报文格式并非kafka支持的格式,这时则需要自定义Serializati…
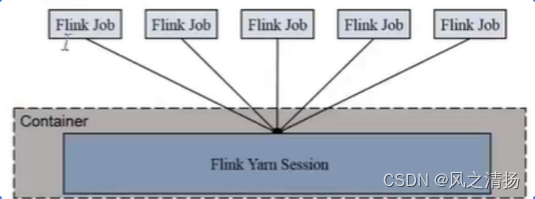
大数据flink篇之三-flink运行环境安装后续一yarn-session安装
前提: Hadoop 必須保证在 2.2 以上,且必須裝有 hdfs 服务。Hadoop安装后续会有相关说明。 具体的,在生产环境中,flink一般会交由yarn、k8s等资源管理平台来处理。本章主要讲解yarn模式下的session cluster模式。
flink Session-C…

Python 编写 Flink 应用程序经验记录(Flink1.17.1)
目录 官方API文档
提交作业到集群运行
官方示例
环境
编写一个 Flink Python Table API 程序
执行一个 Flink Python Table API 程序
实例处理Kafka后入库到Mysql
下载依赖
flink-kafka jar
读取kafka数据
写入mysql数据
flink-mysql jar 官方API文档
https://nigh…
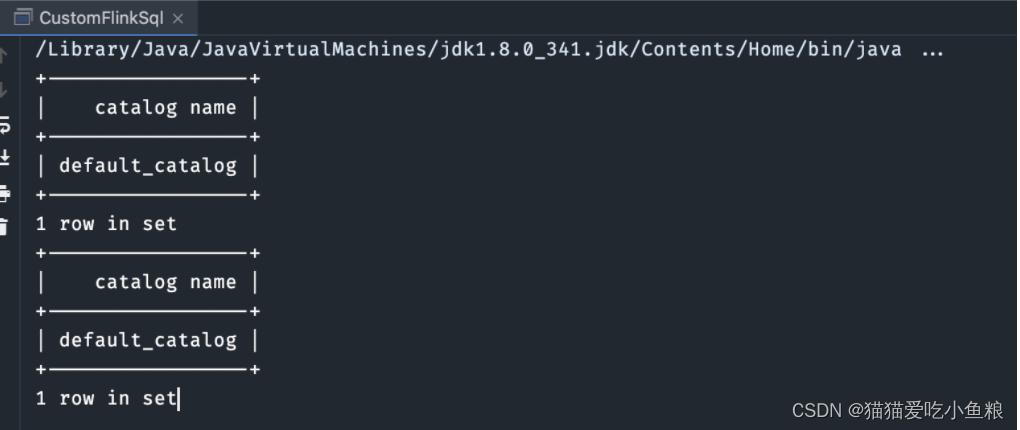
(二开)Flink 修改源码拓展 SQL 语法
1、Flink 扩展 calcite 中的语法解析
1)定义需要的 SqlNode 节点类-以 SqlShowCatalogs 为例
a)类位置
flink/flink-table/flink-sql-parser/src/main/java/org/apache/flink/sql/parser/dql/SqlShowCatalogs.java 核心方法:
Override
pu…
flink版本升级之 checkpoint和savepoint 代码和SQL
1 从checkpoint无法恢复的任务 很可能用savepoint可以恢复.
亲测 2 SQL 和 TableAPI 这两个官方不担保版本升级兼容chk/savepoint streamAPI基本兼容
官网有提到 连接自己找 总结 如果你的checkpoint不能丢 且后续可能存在flink版本升级 那就用代码实现(注意算子指定UID),…
centos7 部署 Flink
1. 准备
安装的前提是虚拟机里已安装了jdk
去官网下载 Flink 所有版本下载地址:https://archive.apache.org/dist/flink/
找到下图的安装包,下载即可 下载完后,将其上传至虚拟机的某个地方,本人将其放在 /home/flink/ 下 解压…
【flink】RowData copy/clone方式
说明:一般用户常用的是GenericRowData。flink内部则多使用BinaryRowData。
方法一、循环解决(不推荐):
代码较为复杂需要根据RowType获取到内部fields的logicalType,再使用RowData.createFieldGetter方法创建fieldGetters。 public static …
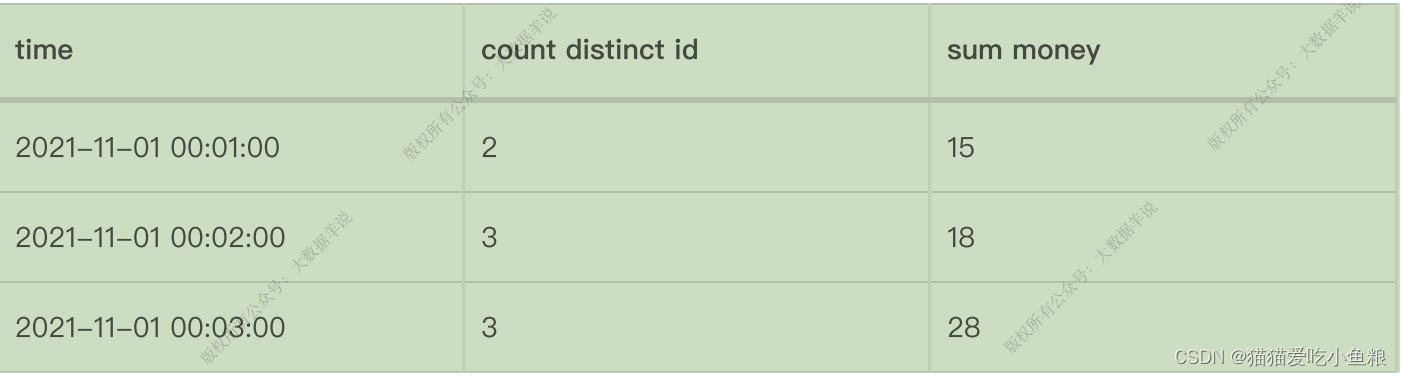
Flink SQL 窗口聚合详解
1.滚动窗⼝(TUMBLE)
**滚动窗⼝定义:**滚动窗⼝将每个元素指定给指定窗⼝⼤⼩的窗⼝,滚动窗⼝具有固定⼤⼩,且不重叠。
例如,指定⼀个⼤⼩为 5 分钟的滚动窗⼝,Flink 将每隔 5 分钟开启⼀个新…
Flink 支持三种时间语义
在 Apache Flink 中,时间在流处理中是一个重要的概念,而时间语义则用于定义事件发生的时间。Flink 支持三种时间语义,分别是:
Processing Time(处理时间): 以机器的系统时间为基准,…
【实战-09】flink DataStream 如何实现去重
摘要
假设我们有一批订单数据实时接入kafka, flink需要对订单数据做处理,值得注意的是订单数据 要求绝对不可以重复处理。 考虑到订单数据上报到kafka的时候存在重复上报的可能性,因此需要我们flink处理的时候 避免进行重复处理。在flinksql 中我们有去…
Flink之OperatorState
在Flink中状态主要分为三种:
Operator State(算子状态)Keyed State(键控状态)Broadcast State(广播状态)
这里简单介绍一下Operator State的使用,说到使用State就必然要使用到Flink的容错机制也就是Checkpoint.具体内容见代码注解
数据源 这里选用Socket作为Source输入,便于…
Flink---5、聚合算子、用户自定义函数、物理分区算子、分流、合流
星光下的赶路人star的个人主页 欲买桂花同载酒,终不似,少年游 文章目录 1、 聚合算子1.1 按键分区(KeyBy)1.2 简单聚合(Sum/Min/MinBy/MaxBy)1.3 归约聚合(Reduce) 2、用户自定义函数…

flink中配置Rockdb的重要配置项
背景
由于我们在flink中使用了状态比较大,无法完全把状态数据存放到tm的堆内存中,所以我们选择了把状态存放到rockdb上,也就是使用rockdb作为状态后端存储,本文就是简单记录下使用rockdb状态后端存储的几个重要的配置项
使用rockdb状态后端…
flink1.13.6版本的应用程序(maven版)
问题
想要一个指定flink版本的java计算任务hello world最简工程。
解决 mvn archetype:generate \-DarchetypeGroupIdorg.apache.flink \-DarchetypeArtifactIdflink-quickstart-java \-DarchetypeVersion1.13.6这里直接使用官方mave模版工程,指…

flink使用事件时间时警惕kafka不同分区的事件时间倾斜问题
背景
flink和kafka的消息组合消费模式几乎是实时流处理的标配,然后当在flink中使用事件时间处理时,需要注意kafka不同分区元素之间时间相差太大的问题,这样有可能会导致严重的数据堆积问题
kafka不同分区元素事件时间差异较大导致的问题 总…

Apache Flink(七):Apache Flink快速入门 - DataStream BATCH模式
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 下面使用Java代码使用DataStream…
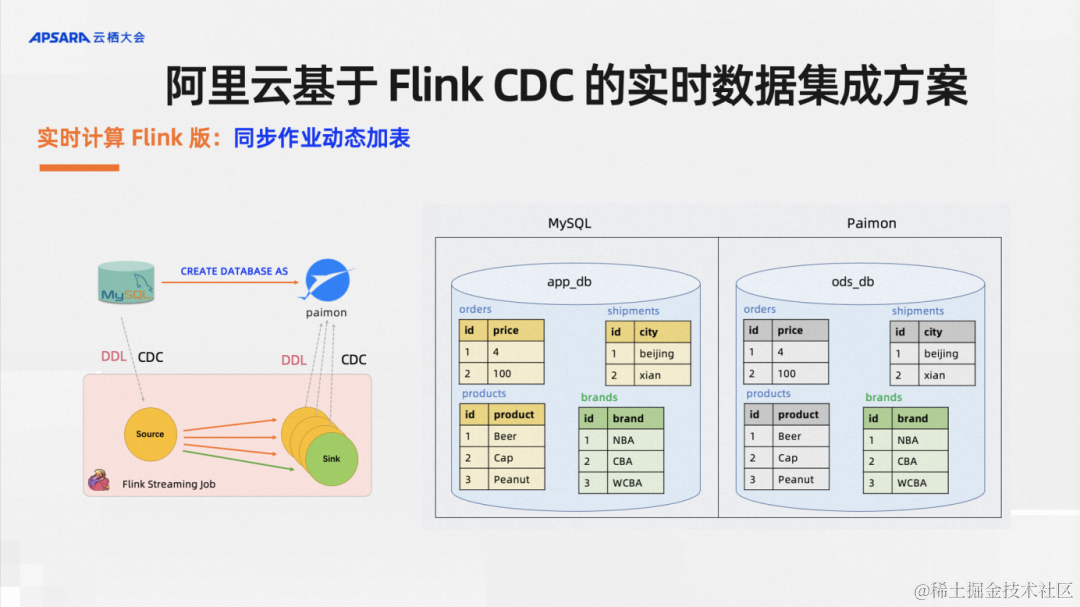
基于 Flink CDC 打造企业级实时数据集成方案
本文整理自Flink数据通道的Flink负责人、Flink CDC开源社区的负责人、Apache Flink社区的PMC成员徐榜江在云栖大会开源大数据专场的分享。本篇内容主要分为四部分:
CDC 数据实时集成的挑战Flink CDC 核心技术解读基于 Flink CDC 的企业级实时数据集成方案实时数据集…

Flink CDC -Sqlserver to Sqlserver java 模版编写
1.基本环境 <flink.version>1.17.0</flink.version>
2. 类文件
package com.flink.tablesql;import org.apache.commons.io.FileUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.streaming.api.environment.StreamExecutionEnviro…
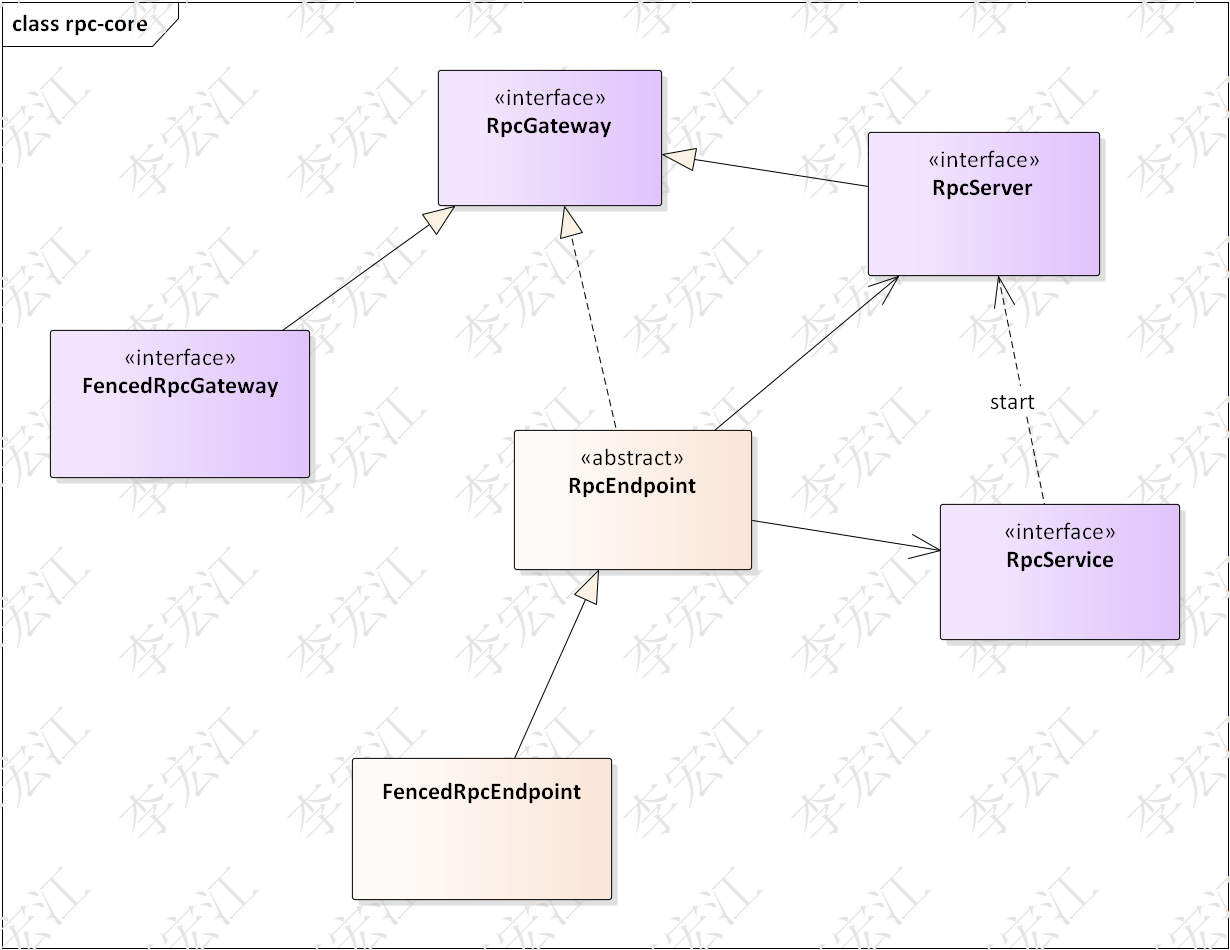
flink源码分析之功能组件(三)-rpc组件
简介 本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metrics,future。 本文解释rpc组件,rpc组件用于个核心组件,包括作业管理器,资源管理器和任务管理器之…
初学Flink 学后总结
最近开始学习Flink,一边学习一边记录,以下是基于【尚硅谷】Flink1.13实战教程总结的笔记,方便后面温习 目录 初始 Flink 一:基础概念 1.Flink是什么 2.Flink主要应用场景
Flink Flink数据写入Kafka
一、环境准备
flink 1.14写入Kafka,首先在pom.xml文件中导入相关依赖 <properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.14.6</flink.version><spark.version>2.4.3</spa…
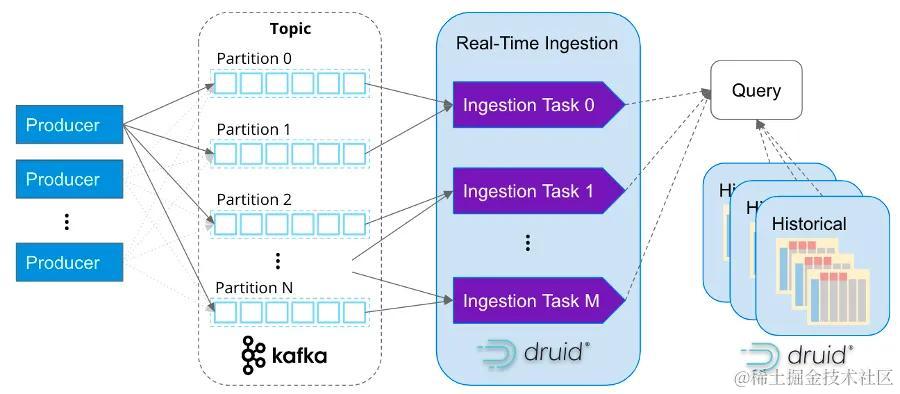
使用Kafka、Flink、Druid构建实时数据系统架构
1. 背景
对于很多数据团队来说,要满足实时需求并不容易。为什么?因为作流程(数据采集、预处理、分析、结果保存)涉及大量等待。等待数据发送到 ETL 工具,等待数据批量处理,等待数据加载到数据仓库中&#…
Flink-执行拓扑图与作业调度
算子与作业提交 一、Flink执行模式1.流执行模式2.批执行模式 二、Flink拓扑图1.基本概念2.拓扑图生成过程 三、拓扑生成和优化1.应用程序2.逻辑视图3.算子链4.Task Slots 四、作业调度1.调度2.拓扑图数据结构3.Job状态转化4.Task状态转化 总结参考链接 一、Flink执行模式
Flin…
【Flink on k8s】- 11 - 使用 Flink kubernetes operator 运行 Flink 作业
目录
1、创建本地镜像库
1.1 拉取私人仓库镜像
1.2 运行
1.3 本地浏览器访问 5000 端口
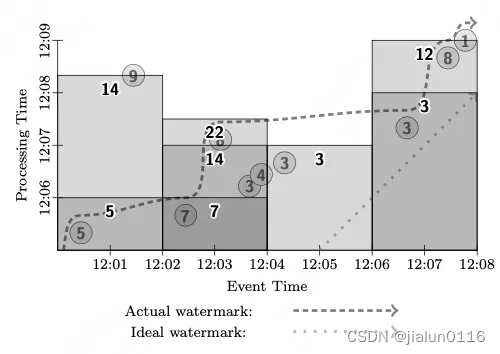
流批一体历史背景及基础介绍
目录 一、历史背景1.BI系统2.传统大数据架构3.流式架构4.Lambda架构5.Kappa架构 二、流批一体与数据架构的关系数据分析型应用数据管道型应用 三、流与批的桥梁Dataflow模型四、Dataflow模型的本质一个基本点两个时间域三个子模型1.窗口模型2.触发器模型3. 增量计算模型 四个分…
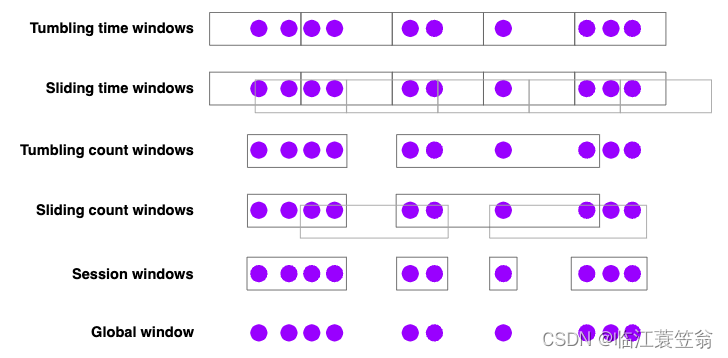
Flink-时间流与水印
时间流与水印 一、背景二、时间语义1.事件时间(event time)2.读取时间(ingestion time)3.处理时间(processing time) 三、水印-Watermarks1.延迟和正确性2.延迟事件3.顺序流4.无序流5.并行流 四、Windows1.…
物流实时数仓ODS层——Mysql到Kafka
目录
1.采集流程
2.项目架构
3.resources目录下的log4j.properties文件
4.依赖
5.ODS层——OdsApp
6.环境入口类——CreateEnvUtil
7.kafka工具类——KafkaUtil
8.启动集群项目 这一层要从Mysql读取数据,分为事实数据和维度数据,将不同类型的数据…

玩转大数据6:实时数据处理与流式计算
引言
在当今的数字化时代,数据正在成为一种新的资源,其价值随着时间的推移而不断增长。因此,实时数据处理和流式计算变得越来越重要。它们在许多领域都有广泛的应用,包括金融、医疗、交通、能源等。本文将探讨实时数据处理和流式…
《十堂课学习 Flink SQL》第四章:Flink 应用 java 开始典型案例
小伙伴们我们从本章开始将基于JAVA 进行Flink 应用开发,本章节主要介绍Maven开发环境搭建,日志配置,流计算案例以及批计算案例。一方面希望能借此规范化一下开发流程,另一方面也是简单案例入门,为接下来越来越复杂的案…

从0到1实现Flink 实战实时风控系统的经验总结
随着互联网金融的快速发展,实时风控系统成为保障业务安全和用户信任的关键。本文将分享从零开始构建Flink实时风控系统的经验,并提供相关示例代码。
一、搭建Flink环境 首先,我们需要搭建Flink环境。以下是一些基本步骤:
安装Ja…

Flink-源算子-读取数据的几种方式
Flink可以从各种来源获取数据,然后构建DataStream进行转换处理。一般将数据的输入来源称为数据源(data source),而读取数据的算子就是源算子(source operator)。所以,source就是我们整个处理程序…
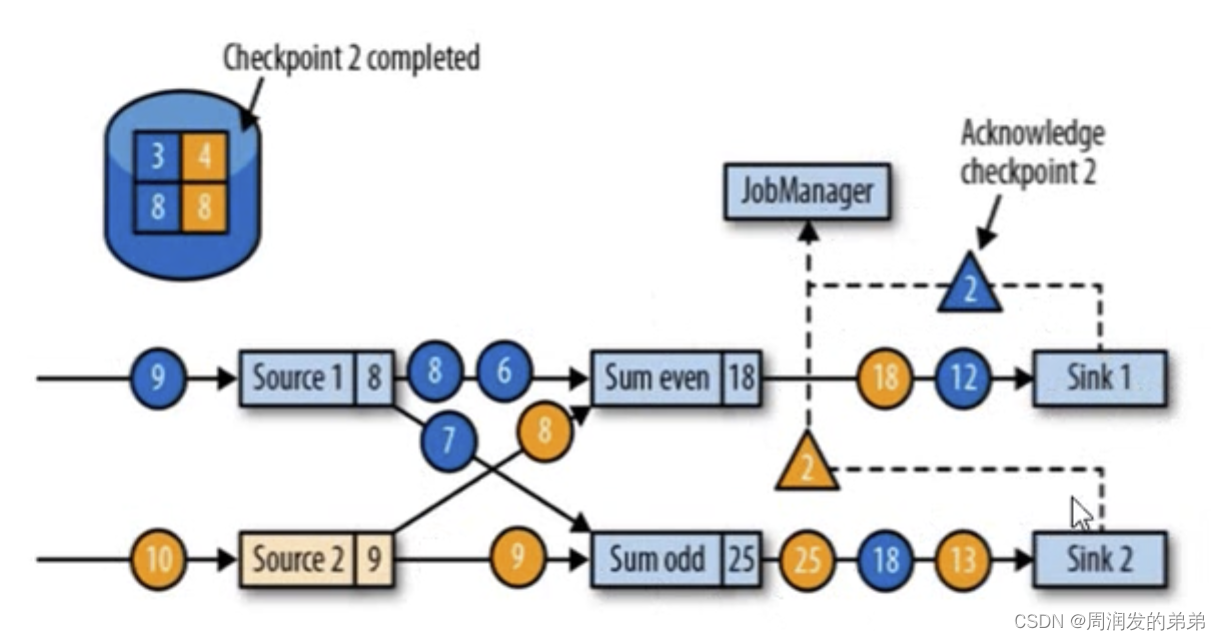
【Flink系列五】Checkpoint及Barrier原理
本章内容
一致性检查点从检查点恢复状态检查点实现算法-barrier保存点Savepoint状态后端(state backend)
本文先设置一个前提,流处理的数据都是可回放的(可以理解成消费的kafka的数据)
一致性检查点(che…
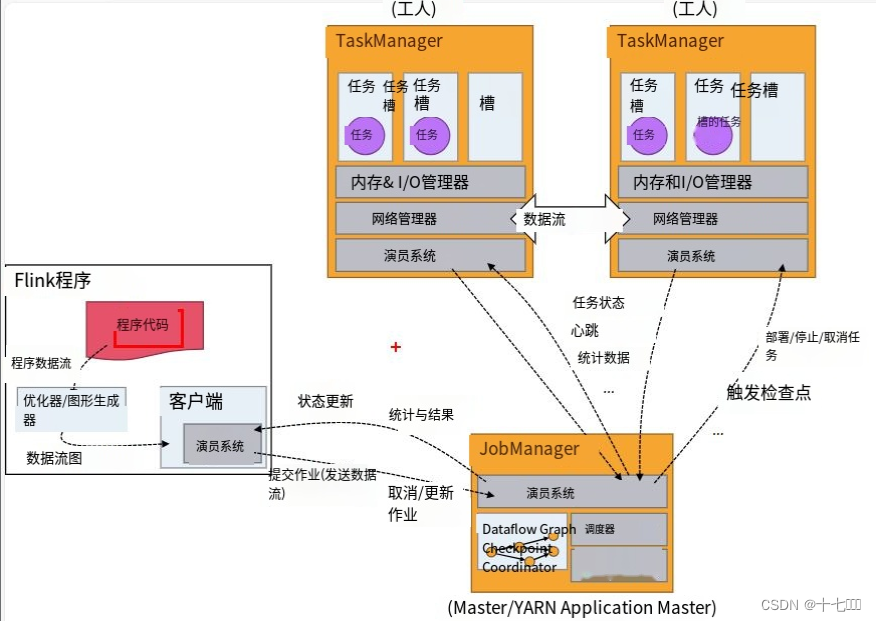
Flink运行时架构核心概念
Flink运行时架构 JobManager:协调,决定何时调度下一个task,对失败任务做恢复。 ResourceManager: 负责Flink集群中的资源提供、回收、分配,它负责管理task slot。standalone模式下,不能自行启动新的taskmanagerDispatc…

Flink往Starrocks写数据报错:too many filtered rows
Bug信息
Caused by: com.starrocks.data.load.stream.exception.StreamLoadFailException: {"TxnId": 2711690,"Label": "cd528707-8595-4a35-b2bc-39b21087d6ec","Status": "Fail","Message": "too many f…
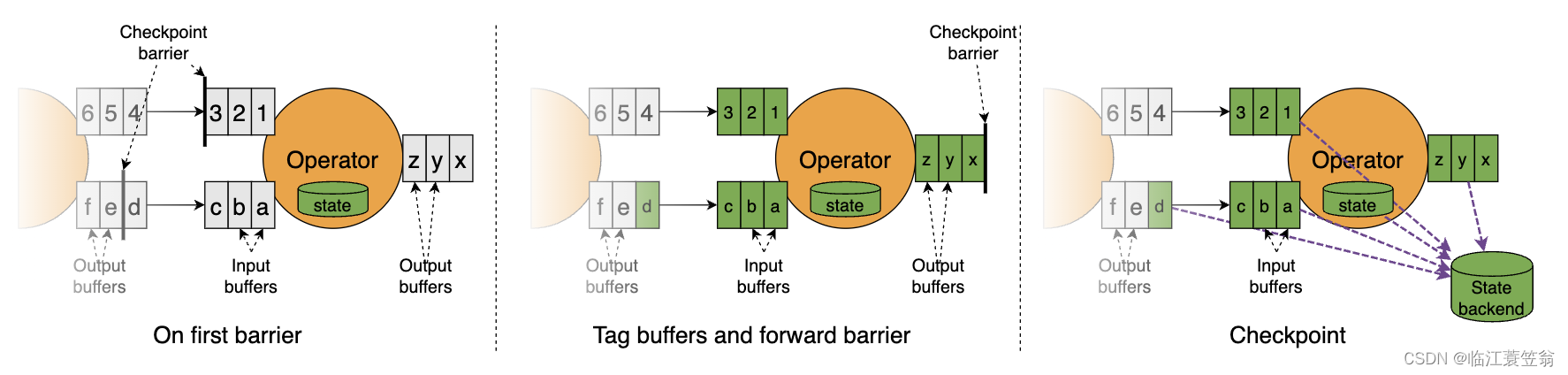
Flink-状态流与容错
状态流与容错 一、状态概念二、状态实现1.状态触发2.状态存储实现2.1 HashMapStateBackend2.2 EmbeddedRocksDBStateBackend2.3 状态存储对比 3.设置状态存储实现3.1 单个作业设置3.2 全局设置 三、容错机制1.状态快照2.状态快照生成3.Checkpoint Barrier4.Aligned Checkpointi…
Flink集群的搭建
1、Flink独立集群模式 1、首先Flink的独立集群模式是不依赖于Hadoop集群。 2、上传压缩包,配置环境:
1、解压:
tar -zxvf flink-1.15.2-bin-scala_2.12.tgz2、配置环境变量:vim /etc/profileexport FLINK_HOME/usr/local/soft/fl…
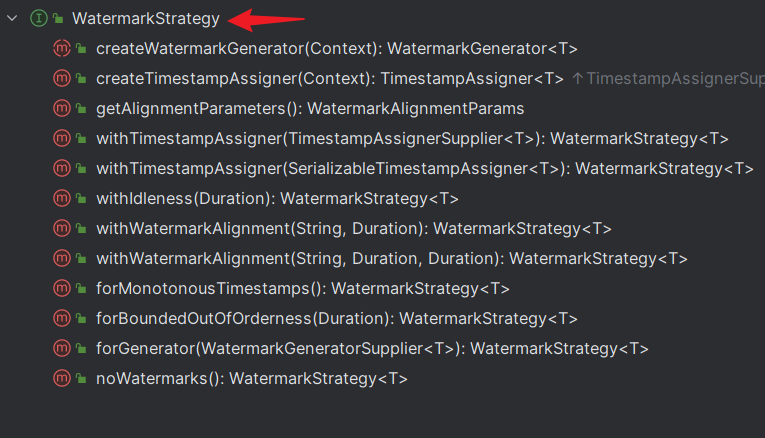
【入门Flink】- 09Flink水位线Watermark
在窗口的处理过程中,基于数据的时间戳,自定义一个“逻辑时钟”。这个时钟的时间不会自动流逝;它的时间进展,就是靠着新到数据的时间戳来推动的。 什么是水位线
用来衡量事件时间进展的标记,就被称作“水位线”&#x…
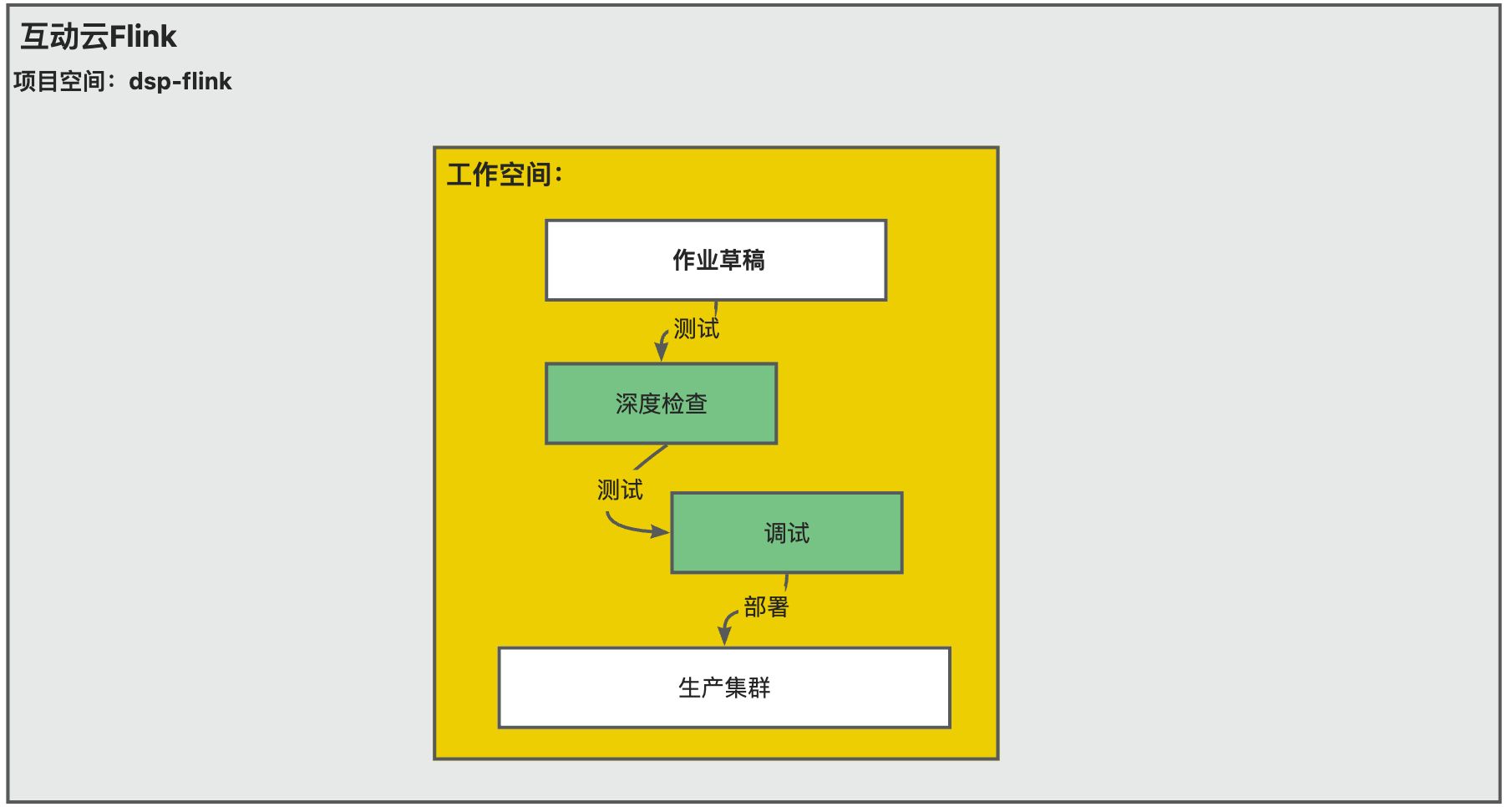
实时数仓-Flink使用总结
阿里云实时计算Flink版是阿里云基于Apache Flink构建的企业级、高性能实时大数据处理系统。具备一站式开发运维管理平台,支持作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。本期将对Flink的使用进行总结。 1. Flink产品回顾
阿里云实时计算…
flink的键值分区状态自动过期ttl配置
背景
flink的状态清理之前一直都是通过处理函数的ontimer设置定时器的方式清理掉那些无用的状态,但是这种方式容易出错而且代码也不优雅,使用flink提供的状态ttl的方式可以解决这个问题
flink键值分区状态ttl设置
文件系统/基于内存的状态后端的ttl设…
flink的副输出sideoutput单元测试
背景
处理函数中处理输出主输出的数据流数据外,也可以输出多个其他的副输出的数据流数据,当我们的处理函数有副输出时,我们需要测试他们功能的正确性,本文就提供一个测试flink副输出单元测试的例子
测试flink副输出单元测试
首先看一下处理…
【Flink on k8s】- 7 - 在本地运行第一个 flink wordcount job
目录
1、环境准备
2、代码开发
3、启动运行
4、在控制台找到 web ui,查看监控
【自定义Source、Sink】Flink自定义Source、Sink对ClickHouse进行读和批量写操作
ClickHouse官网文档
Flink 读取 ClickHouse 数据两种驱动
ClickHouse 官方提供Clickhouse JDBC.【建议使用】第3方提供的Clickhouse JDBC. ru.yandex.clickhouse.ClickHouseDriver ru.yandex.clickhouse.ClickHouseDriver.现在是没有维护 ClickHouse 官方提供Clickhouse JDBC…

【自定义Source、Sink】Flink自定义Source、Sink对redis进行读写操作
使用ParameterTool读取配置文件
Flink读取参数的对象
Commons-cli: Apache提供的,需要引入依赖ParameterTool:Flink内置 ParameterTool 比 Commons-cli 使用上简便; ParameterTool能避免Jar包的依赖冲突 建议使用第二种 使用Par…

【Table/SQL Api】Flink Table/SQL Api表转流读取MySQL
引入依赖
jdbc依赖
flink-connector-jdbc mysql-jdbc-driver 操作mysql数据库 <!-- Flink-Connector-Jdbc --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>…

玩转大数据14:分布式计算框架的选择与比较
1. 引言
随着大数据时代的到来,越来越多的企业和组织需要处理海量数据。分布式计算框架提供了一种有效的方式来解决大数据处理的问题。分布式计算框架将计算任务分解成多个子任务,并在多个节点上并行执行,从而提高计算效率。
2. 分布式计算…

Flink 流处理流程 API详解
流处理API的衍变
Storm:TopologyBuilder构建图的工具,然后往图中添加节点,指定节点与节点之间的有向边是什么。构建完成后就可以将这个图提交到远程的集群或者本地的集群运行。 Flink:不同之处是面向数据本身的,会把D…
批处理、流处理和批流一体
批处理
批处理是将一定量的数据集合在一起,形成一个数据批次,然后对这个批次中的数据进行处理。
Spark 和 Flink 都支持批处理:
Spark 使用的是批处理模型,即将一批数据一次性读入内存,然后对其进行处理,…

玩转大数据:2-揭秘Hadoop家族神秘面纱
1. 初识Hadoop家族
在当今的数字化时代,大数据已成为企业竞争的关键因素之一。为了有效地管理和分析这些庞大的数据,许多企业开始采用Hadoop生态系统。本文将详细介绍Hadoop生态系统的构成、优势以及应用场景。
首先,让我们来了解一下什么是…
48、Flink DataStream API 编程指南(1)- DataStream 入门示例
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

Apache Doris 整合 FLINK CDC 、Paimon 构建实时湖仓一体的联邦查询入门
1.概览
多源数据目录(Multi-Catalog)功能,旨在能够更方便对接外部数据目录,以增强Doris的数据湖分析和联邦数据查询能力。
在之前的 Doris 版本中,用户数据只有两个层级:Database 和 Table。当我们需要连…
《十堂课学习 Flink SQL》第四章:Flink 应用 java 开发开始典型案例
小伙伴们我们从本章开始将基于JAVA 进行Flink 应用开发,本章节主要介绍Maven开发环境搭建,日志配置,流计算案例以及批计算案例。一方面希望能借此规范化一下开发流程,另一方面也是简单案例入门,为接下来越来越复杂的案…
【Flink-Sql-Kafka-To-ClickHouse】使用 FlinkSql 将 Kafka 数据写入 ClickHouse
【Flink-Sql-Kafka-To-ClickHouse】使用 FlinkSql 将 Kafka 数据写入 ClickHouse 1)需求分析2)功能实现3)准备工作3.1.Kafka3.2.ClickHouse 4)Flink-Sql5)验证 1)需求分析
1、数据源为 Kafka,定…
Flink系列之:WITH clause
Flink系列之:WITH clause 适用流、批提供了一种编写辅助语句以在较大查询中使用的方法。这些语句通常称为公共表表达式 (CTE),可以被视为定义仅针对一个查询而存在的临时视图。
WITH 语句的语法为:
WITH <with_item_definition> [ , …

FlinkSQL中的窗口
多维分析
需求:有一张test表,表的字段为:A, B, C, amount, 其中A, B, C为维度字段,求以三个维度任意组合,统计sum(amount)
Union方案: A, B, C的任意组合共有8种,分别为(A, B,C,AB…
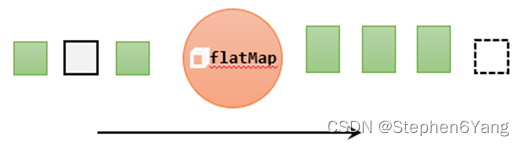
Flink基本转换算子map/filter/flatmap
map
map是大家非常熟悉的大数据操作算子,主要用于将数据流中的数据进行转换,形成新的数据流。简单来说,就是一个“一一映射”,消费一个元素就产出一个元素。 我们只需要基于DataStream调用map()方法就可以进行转换处理。方法需要…

基于 Flink CDC 构建 MySQL 的 Streaming ETL to MySQL
简介
CDC 的全称是 Change Data Capture ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。CDC 技术的应用场景非常广泛…
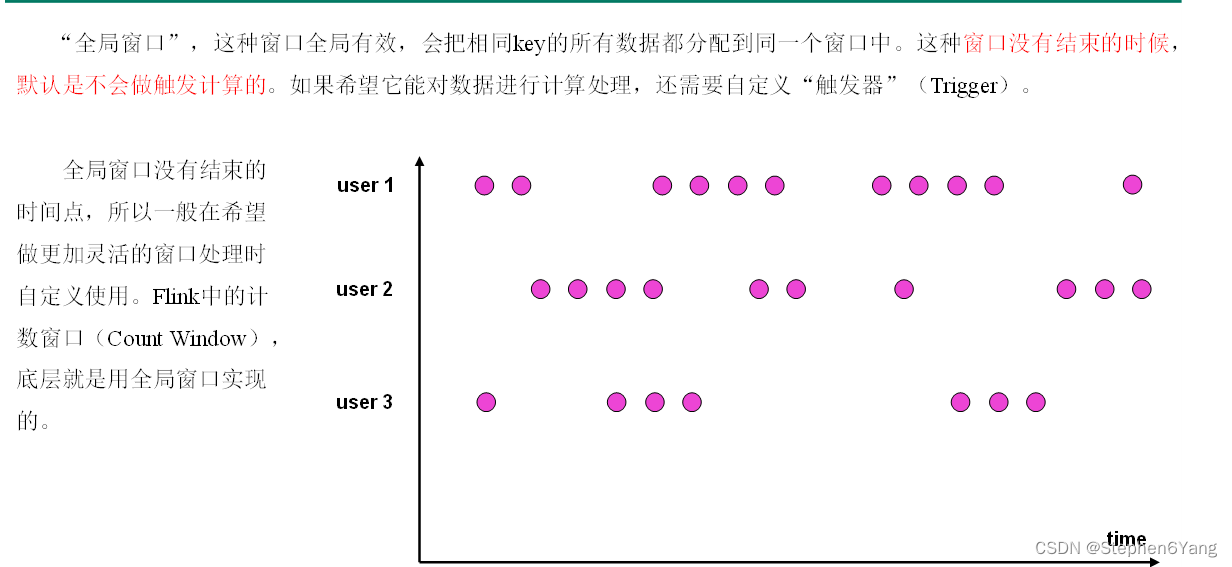
Flink窗口的概念和分类
窗口的概念
Flink是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window&#x…
Flink SQL填坑记2:Flink和MySQL的Bigdata类型不同导致ClassCastException报错
最近在开发Flink SQL的时候,需要关联Kafka事实表和MySQL维表,得到的数据写入Phoenix表中,但是其中有个字段,Kafka表、MySQL表和Phoenix表都是BigData类型,但是在实现的时候却报“java.math.BigInteger cannot be cast to java.lang.Long”异常,从报错信息来看,是由于Big…
《十堂课学习 Flink》第五章:Table API 以及 Flink SQL 入门
第四章中介绍了 DataStream API 以及 DataSet API 的入门案例,本章开始介绍 Table API 以及基于此的高层应用 Flink SQL 的基础。 5.1 Flink Table & SQL 基础知识
Flink 提供了两个关系API——Table API 和 SQL——用于统一的流和批处理。Table API 是一种针对…

Flink实时电商数仓(二)
GitLab的用户创建和推送
在root用户-密码界面重新设置密码添加Leader用户和自己使用的用户使用root用户创建相应的群组使用Leader用户创建对应的项目设置分支配置为“初始推送后完全保护”设置.gitignore文件,项目配置文件等其他非通用代码无需提交安装gitlab proj…

flink 读取 apache paimon表,查看source的延迟时间 消费堆积情况
paimon source查看消费的数据延迟了多久
如果没有延迟 则显示0 官方文档
Metrics | Apache Paimon

Flink 窗口(1)—— 基础概念
窗口:将无限数据切割成有限的“数据块”进行处理,以便更高效地处理无界流 在处理无界数据流时,把无界流进行切分,每一段数据分别进行聚合,结果只输出一次。这就相当于将无界流的聚合转化为了有界数据集的聚合 Flink “…

Hadoop学习笔记(HDP)-Part.18 安装Flink
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …
Flink流批一体计算(23):Flink SQL之多流kafka写入多个mysql sink
目录 1. 准备工作
生成数据
创建数据表
2. 创建数据表
创建数据源表
创建数据目标表
3. 计算
WITH子句 1. 准备工作
生成数据
source kafka json 数据格式 :
topic case_kafka_mysql:
{"ts": "20201011","id"…
Flink入门之DataStream API及kafka消费者
DataStream API
主要流程: 获取执行环境读取数据源转换操作输出数据Execute触发执行 获取执行环境 根据实际情况获取StreamExceptionEnvironment.getExecutionEnvironment(conf)创建本地环境StreamExecutionEnvironment.createLocalEnvironment()创建远程环境creat…
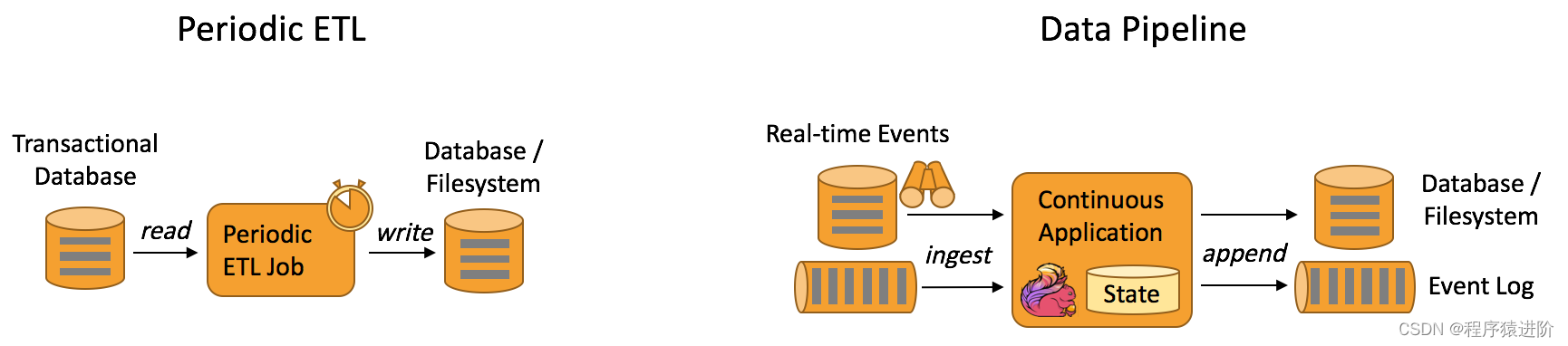
Flink 使用场景
Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、K8s 在内的多种资源管理框架上,还支持…
Flink 系列文章汇总索引
Flink 系列文章
一、Flink 专栏
本专栏系统介绍某一知识点,并辅以具体的示例进行说明。
本专栏的文章编号可能不是顺序的,主要是因为写的时候顺序没统一,但相关的文章又引入了,所以后面就没有调整了,按照写文章的顺…
Flink之JDBCSink连接MySQL
输出到MySQL
添加依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version>
</dependency>
<dependency><groupId>com.mysql</gr…

Flink State 状态原理解析 | 京东物流技术团队
一、Flink State 概念
State 用于记录 Flink 应用在运行过程中,算子的中间计算结果或者元数据信息。运行中的 Flink 应用如果需要上次计算结果进行处理的,则需要使用状态存储中间计算结果。如 Join、窗口聚合场景。
Flink 应用运行中会保存状态信息到 …

Flink 本地单机/Standalone集群/YARN模式集群搭建
准备工作
本文简述Flink在Linux中安装步骤,和示例程序的运行。需要安装JDK1.8及以上版本。
下载地址:下载Flink的二进制包 点进去后,选择如下链接: 解压flink-1.10.1-bin-scala_2.12.tgz,我这里解压到soft目录
[ro…
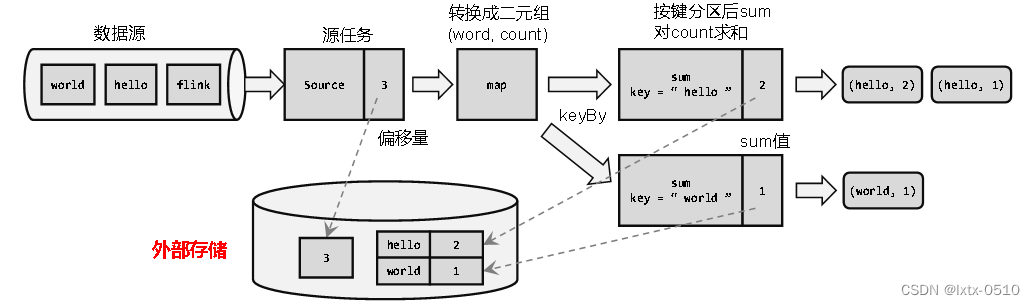
【Flink】容错机制
目录
1、检查点
编辑1.1 检查点的保存
1.1.1 周期性的触发保存
1.1.2 保存的时间点
1.1.3 时间点的保存与恢复
1.1.3.1保存
编辑
1.1.3.2 恢复的具体步骤:
1.2 检查点算法
1.2.1 检查点分界线(Barrier)
1.2.2 分布式快照算法(Barrier对齐的精准一次)
1.2.…
Flink 读写 HBase 总结
前言
总结 Flink 读写 HBase
版本 Flink 1.15.4HBase 2.0.2Hudi 0.13.0官方文档
https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/hbase/
Jar包
https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-hbase-2.2/1…
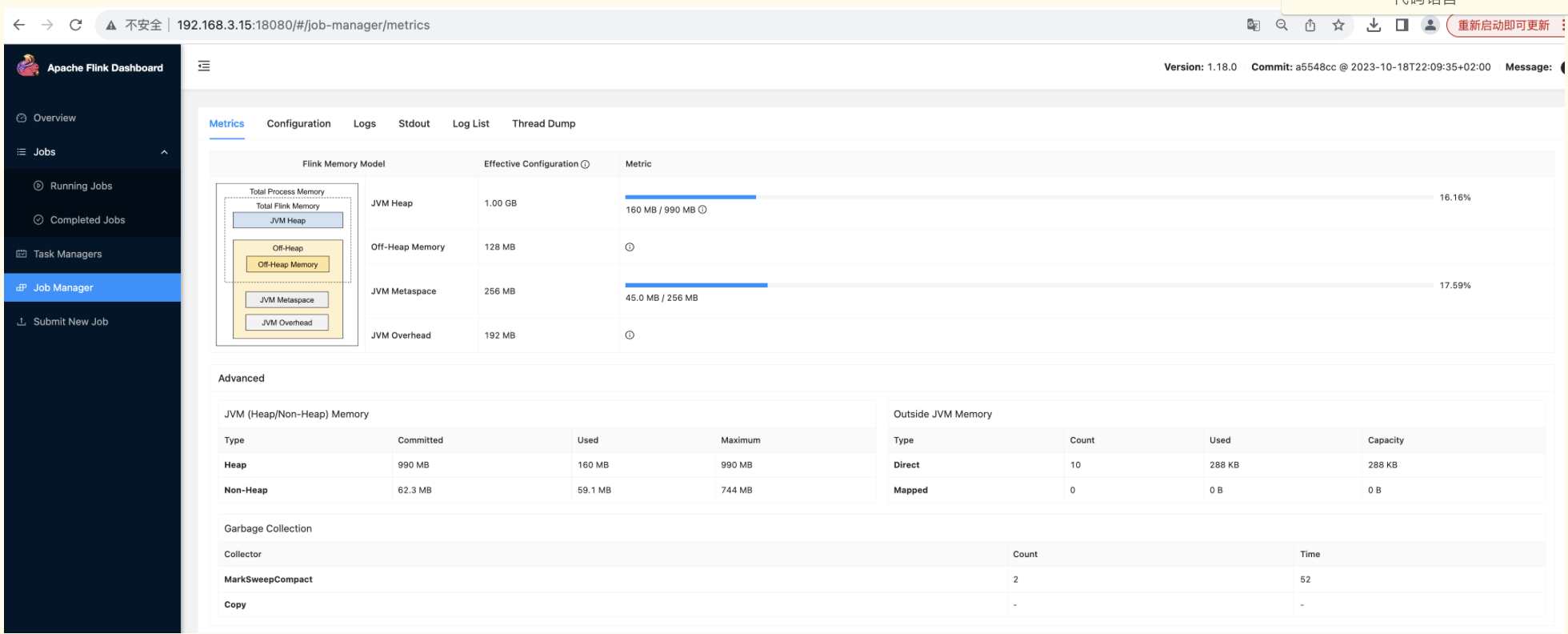
Flink快速部署集群,体验炸了!
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…
【flink】基于flink全量同步postgres表到doris
在不借助第三方组件的进行数据同步时,doris支持采用外部表进行insert select的方式进行导入,但是不适用于数据量大的表,除非自己手动做分片进行多次导入 。
flink提供了doris connector进行数据写入,实际是stream load方式&#…

flink yarn-session 启动失败retrying connect to server 0.0.0.0/0.0.0.0:8032
原因分析,启动yarn-session.sh,会向resourcemanager的端口8032发起请求: 但是一直无法请求到8032端口,触发重试机制会不断尝试 备注:此问题出现时,我的环境ambari部署的HA 高可用hadoop,三个节点…

深入解析 Flink CDC 增量快照读取机制
一、Flink-CDC 1.x 痛点
Flink CDC 1.x 使用 Debezium 引擎集成来实现数据采集,支持全量加增量模式,确保数据的一致性。然而,这种集成存在一些痛点需要注意: 一致性通过加锁保证:在保证数据一致性时,Debez…

Flink1.17实战教程(第七篇:Flink SQL)
系列文章目录
Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…
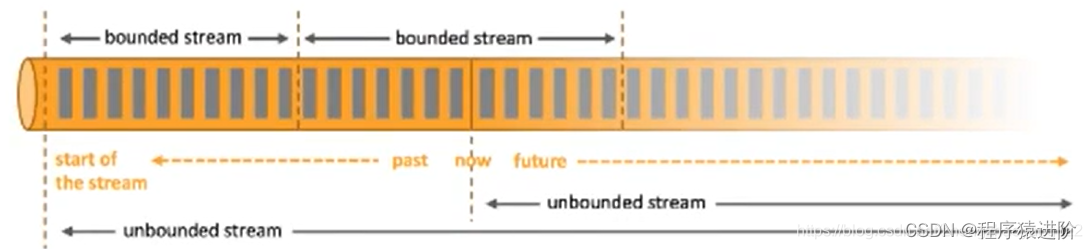
Flink 数据集类型
现实世界中,所有的数据都是以流式的形态产生的,不管是哪里产生的数据,在产生的过程中都是一条条地生成,最后经过了存储和转换处理,形成了各种类型的数据集。如下图所示,根据现实的数据产生方式和数据产生是…

Flink项目实战篇 基于Flink的城市交通监控平台(下)
系列文章目录
Flink项目实战篇 基于Flink的城市交通监控平台(上) Flink项目实战篇 基于Flink的城市交通监控平台(下) 文章目录 系列文章目录4. 智能实时报警4.1 实时套牌分析4.2 实时危险驾驶分析4.3 出警分析4.4 违法车辆轨迹跟…

Flink1.17实战教程(第四篇:处理函数)
系列文章目录
Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…
Flink系列之:使用flink查询数据和插入数据
SELECT 语句和 VALUES 语句是使用 TableEnvironment 的 sqlQuery() 方法指定的。该方法以表的形式返回 SELECT 语句(或 VALUES 语句)的结果。 Table 可以在后续的 SQL 和 Table API 查询中使用、转换为 DataStream 或写入 TableSink。 SQL 和 Table API …
Flink之keyby状态
Keyed State
值状态:维护一个具体的值 ValueState继承自StateT value(): 从状态中获取维护的数据update(): 更新状态 列表状态:可以当成List使用,维护多个值 add(): 添加一个状态addAll():添加多个状态,不会覆盖原有的…
PiflowX组件-ReadFromKafka
ReadFromKafka组件
组件说明
从kafka中读取数据。
计算引擎
flink
有界性
Unbounded
组件分组
kafka
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子kafka_hostKAFKA_HOST“”无是逗号分隔的Ka…

【Flink-cdc-Mysql-To-Kafka】使用 Flinksql 利用集成的 connector 实现 Mysql 数据写入 Kafka
【Flink-cdc-Mysql-To-Kafka】使用 Flinksql 利用集成的 connector 实现 Mysql 数据写入 Kafka 1)环境准备2)准备相关 jar 包3)实现场景4)准备工作4.1.Mysql4.2.Kafka 5)Flink-Sql6)验证 1)环境…
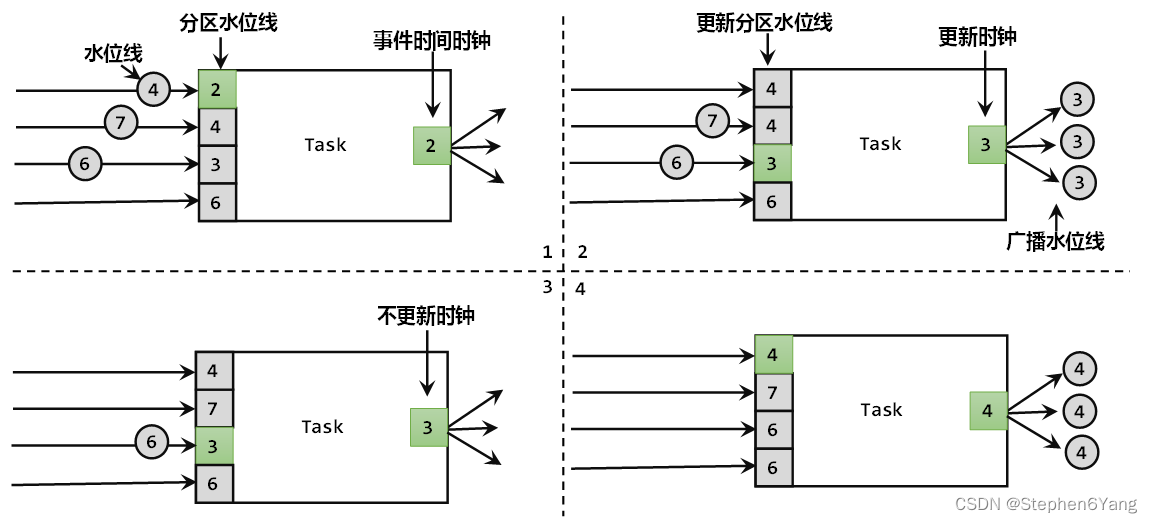
Flink-水位线和时间语义
Flink中的时间含义 在实际应用中,事件时间语义会更为常见。一般情况下,业务日志数据中都会记录数据生成的时间戳(timestamp),它就可以作为事件时间的判断基础。 在Flink中,由于处理时间比较简单,…
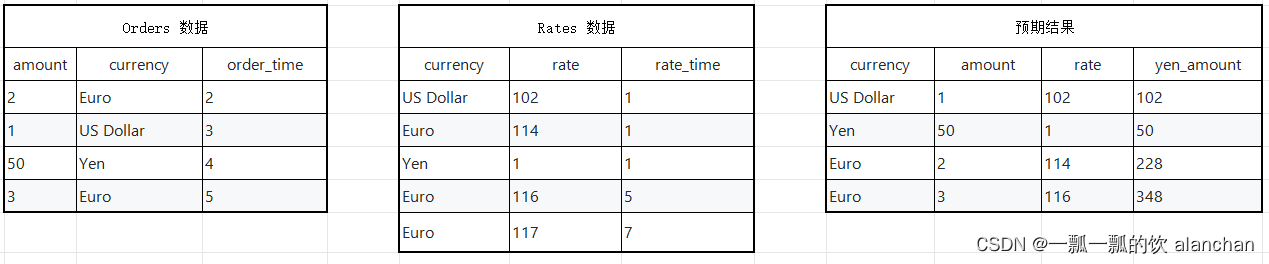
【flink番外篇】9、Flink Table API 支持的操作示例(14)- 时态表的join(java版本)
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…
flink如何写入es
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、写入到Elasticsearch5二、写入到Elasticsearch7总结 前言
Flink sink 流数据写入到es5和es7的简单示例。 一、写入到Elasticsearch5
pom maven依赖 <d…
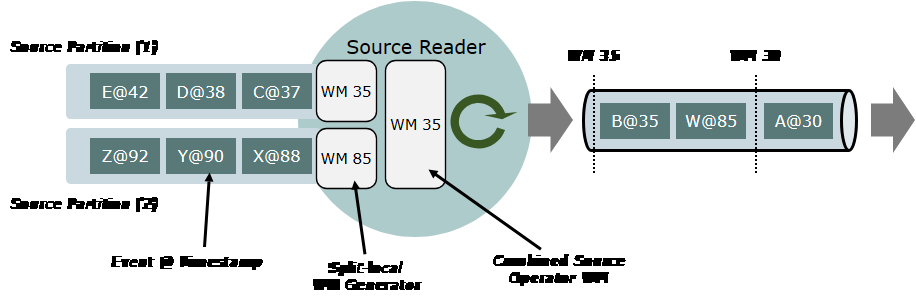
56、Flink 的Data Source 原理介绍
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…
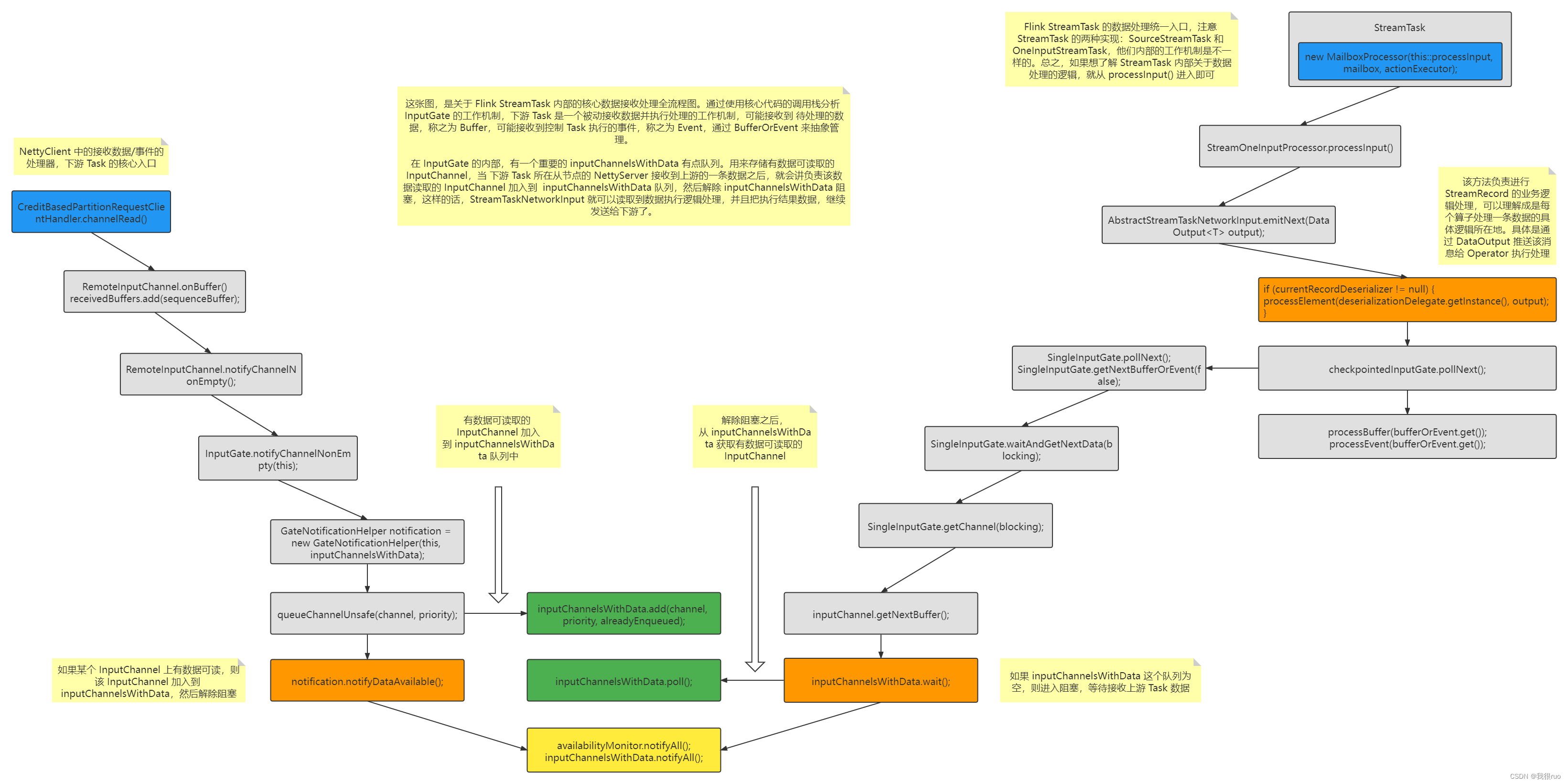
深入理解 Flink(八)Flink Task 部署初始化和启动详解
JobMaster 部署 Task
核心入口:
JobMaster.onStart();部署 Task 链条:JobMaster --> DefaultScheduler --> SchedulingStrategy --> ExecutionVertex --> Execution --> RPC请求 --> TaskExecutor
TaskExecutor 处理 JobMaster 的 …
Flink算子简单测试样例
Flink算子简单测试样例
1. 创建执行环境 // 创建执行环境StreamExecutionEnvironment env StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);2. 创建数据流 // 创建数据流DataStream<String> source env.addSource(new DataGeneratorSour…
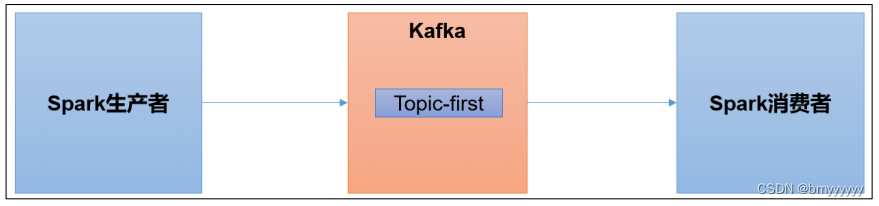
【Kafka-3.x-教程】-【六】Kafka 外部系统集成 【Flume、Flink、SpringBoot、Spark】
【Kafka-3.x-教程】专栏:
【Kafka-3.x-教程】-【一】Kafka 概述、Kafka 快速入门 【Kafka-3.x-教程】-【二】Kafka-生产者-Producer 【Kafka-3.x-教程】-【三】Kafka-Broker、Kafka-Kraft 【Kafka-3.x-教程】-【四】Kafka-消费者-Consumer 【Kafka-3.x-教程】-【五…
Flink常见异常解决办法
Flink启动报错
Caused by: java.lang.NoSuchMethodError: org.apache.flink.api.common.functions.RuntimeContext.getMetricGroup()Lorg/apache/flink/metrics/groups/OperatorMetricGroup;...at org.apache.flink.api.common.functions.util.FunctionUtils.openFunction(Fun…

【性能调优】local模式模式下flink处理离线任务能力分析
文章目录 一. flink的内存管理1.Jobmanager的内存模型2.TaskManager的内存模型2.1. 模型说明2.2. 通讯、数据传输方面2.3. 框架、任务堆外内存2.4. 托管内存 3.任务分析 二. 单个节点的带宽瓶颈1. 带宽相关理论2. 使用speedtest-cli 测试带宽3. 任务分析3. 其他工具使用介绍 本…
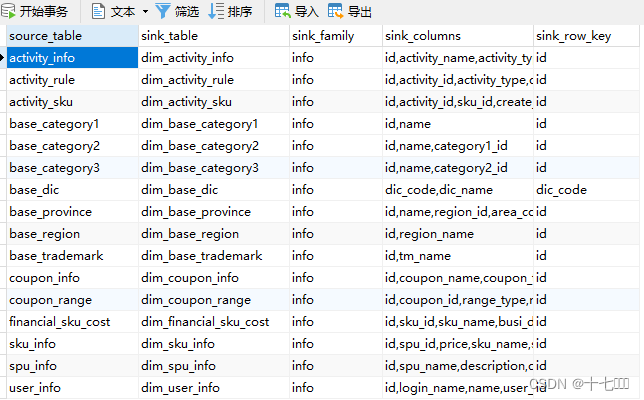
Flink电商实时数仓(三)
DIM层代码流程图
维度层的重点和难点在于实时电商数仓需要的维度信息一般是动态的变化的,并且由于实时数仓一般需要一直运行,无法使用常规的配置文件重启加载方式来修改需要读取的ODS层数据,因此需要通过Flink-cdc实时监控MySql中的维度数据…
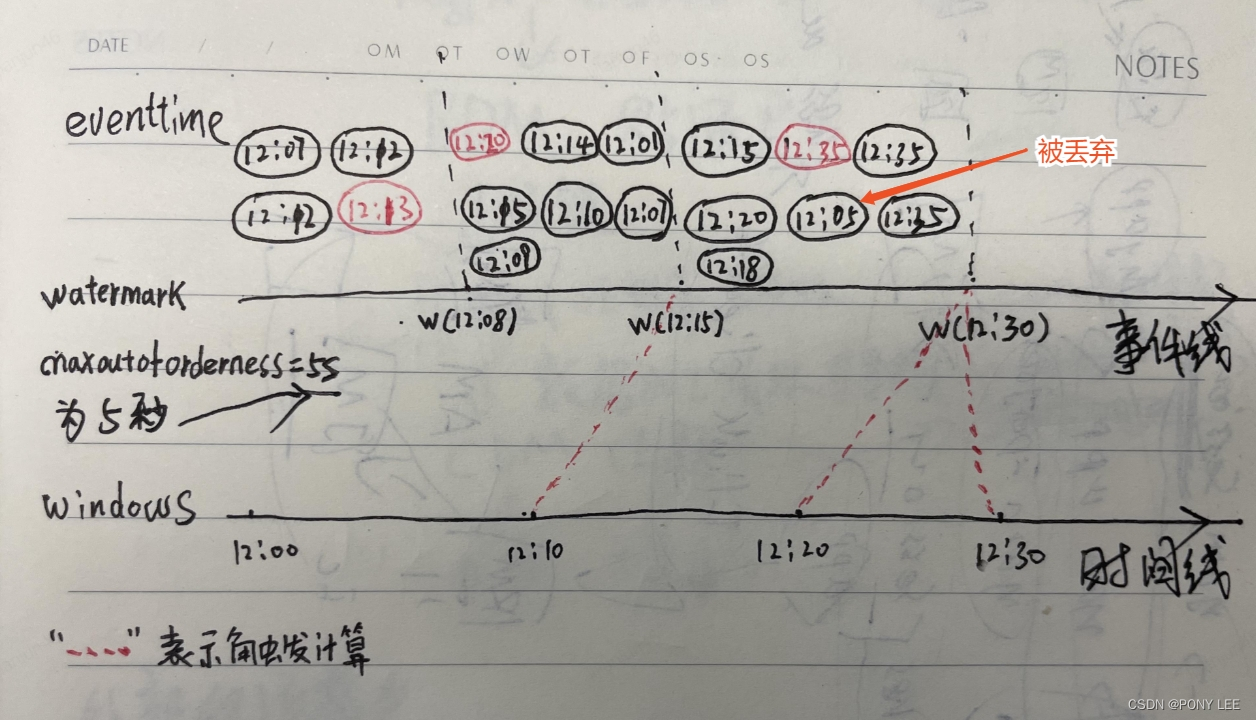
flink watermark 实例分析
WATERMARK 定义了表的事件时间属性,其形式为: WATERMARK FOR rowtime_column_name AS watermark_strategy_expression rowtime_column_name 把一个现有的列定义为一个为表标记事件时间的属性。该列的类型必须为 TIMESTAMP(3)/TIMESTAMP_LTZ(3),且是 sche…
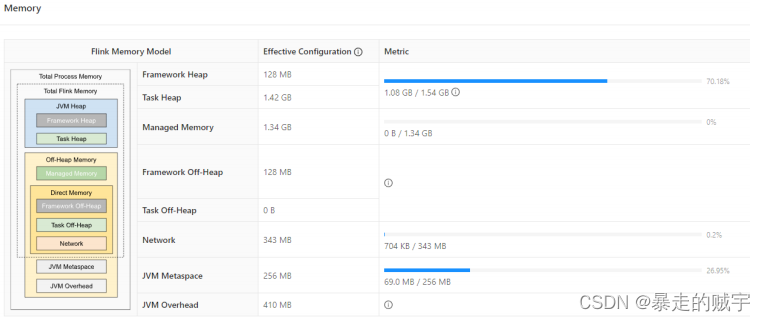
Flink TaskManager内存管理机制介绍与调优总结
内存模型 因为 TaskManager 是负责执行用户代码的角色,一般配置 TaskManager 内存的情况会比较多,所以本文当作重点讲解。根据实际需求为 TaskManager 配置内存将有助于减少 Flink 的资源占用,增强作业运行的稳定性。 TaskManager 内…
flink使用sql-client-defaults.yml无效
希望在flink sql脚本启动时自动选择catalog,减少麻烦。于是乎配置sql-client-defaults.yaml:
catalogs:- name: hive_catalogtype: icebergcatalog-type: hiveproperty-version: 1cache-enabled: trueuri: thrift://localhost:9083client: 5warehouse: …
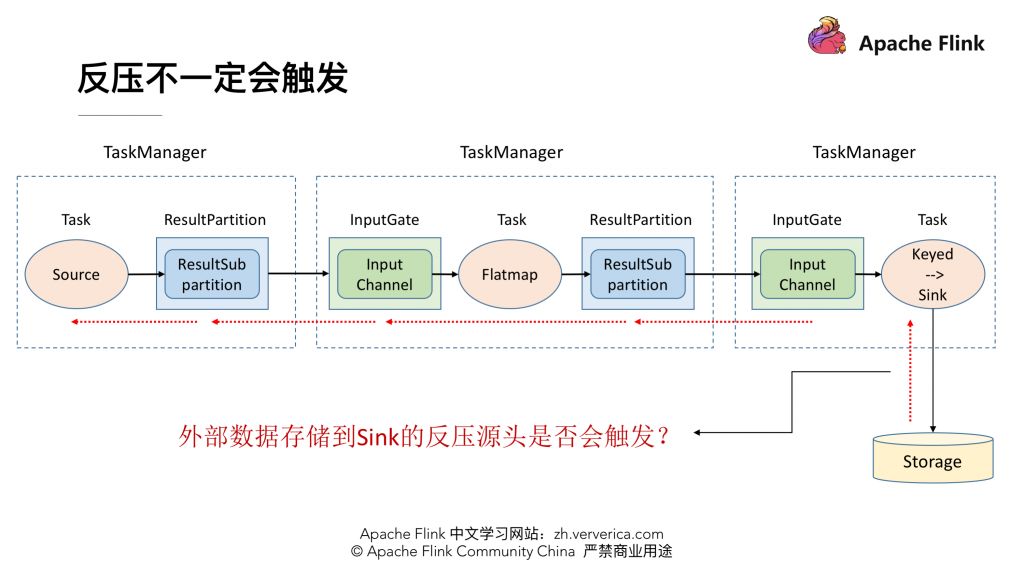
Apache Flink 进阶教程(七):网络流控及反压剖析
目录
前言
网络流控的概念与背景
为什么需要网络流控
网络流控的实现:静态限速
网络流控的实现:动态反馈/自动反压
案例一:Storm 反压实现
案例二:Spark Streaming 反压实现
疑问:为什么 Flink(bef…
Apache Flink 进阶教程(六):Flink 作业执行深度解析
目录
前言
Flink 四层转化流程
Program 到 StreamGraph 的转化
StreamGraph 到 JobGraph 的转化
为什么要为每个 operator 生成 hash 值?
每个 operator 是怎样生成 hash 值的?
JobGraph 到 ExexcutionGraph 以及物理执行计划
Flink Job 执行流程…
使用Flink的所有pom文件
Flink中所有的pom文件中的索引
<project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xs…
flink-cdc实战之oracle问题记录01
记录问题,温暖你我,上台
欢迎点赞留言关注 2024-01-26 11:02:56,168 ERROR Oracle|oracle_logminer|streaming Mining session stopped due to the {} [io.debezium.connector.oracle.logminer.LogMinerHelper]
io.debezium.DebeziumException: Sup…
【flink】状态清理策略(TTL)
flink的keyed state是有有效期(TTL)的,使用和说明在官网描述的篇幅也比较多,对于三种清理策略没有进行横向对比得很清晰。
全量快照清理(FULL_STATE_SCAN_SNAPSHOT)增量清理(INCREMENTAL_CLEANUP)rocksdb压缩清理(ROCKSDB_COMPACTION_FILTER) 注意&…
PiflowX组件-FileRead
FileRead组件
组件说明
从文件系统读取。
计算引擎
flink
组件分组
file
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子pathpath“”无是文件路径。hdfs://server1:8020/flink/test/text.txtfor…
第一个FLink程序之wordCount
前言
前几篇内容讲解的都是环境的部署安装,下面就关于安装好的环境,开始着手程序的编写和实现。 一、Flink批处理
批处理在flink中来说操作是有界的,比如对一个文件的单词进行统计,首选的话需要创建执行环境,此处使用…
【Flink】 Flink实时读取mysql数据
准备
你需要将这两个依赖添加到 pom.xml 中
mysql
mysql-connector-java
8.0.0
读取 kafka 数据
这里我依旧用的以前的 student 类,自己本地起了 kafka 然后造一些测试数据,这里我们测试发送一条数据则 sleep 10s,意味着往 kafka 中一分…
【大数据】Flink SQL 语法篇(一):CREATE
Flink SQL 语法篇(一) 1.建表语句2.表中的列2.1 常规列(物理列)2.2 元数据列2.3 计算列 3.定义 Watermark4.Create Table With 子句5.Create Table Like 子句 CREATE 语句用于向当前或指定的 Catalog 中注册库、表、视图或函数。注…
【极数系列】Flink集成DataSource读取文件数据(08)
文章目录 01 引言02 简介概述03 基于文件读取数据3.1 readTextFile(path)3.2 readFile(fileInputFormat, path)3.3 readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo)3.4 实现原理3.5 注意事项3.6 支持读取的文件形式 04 源码实战demo4.1 pom.xml依…
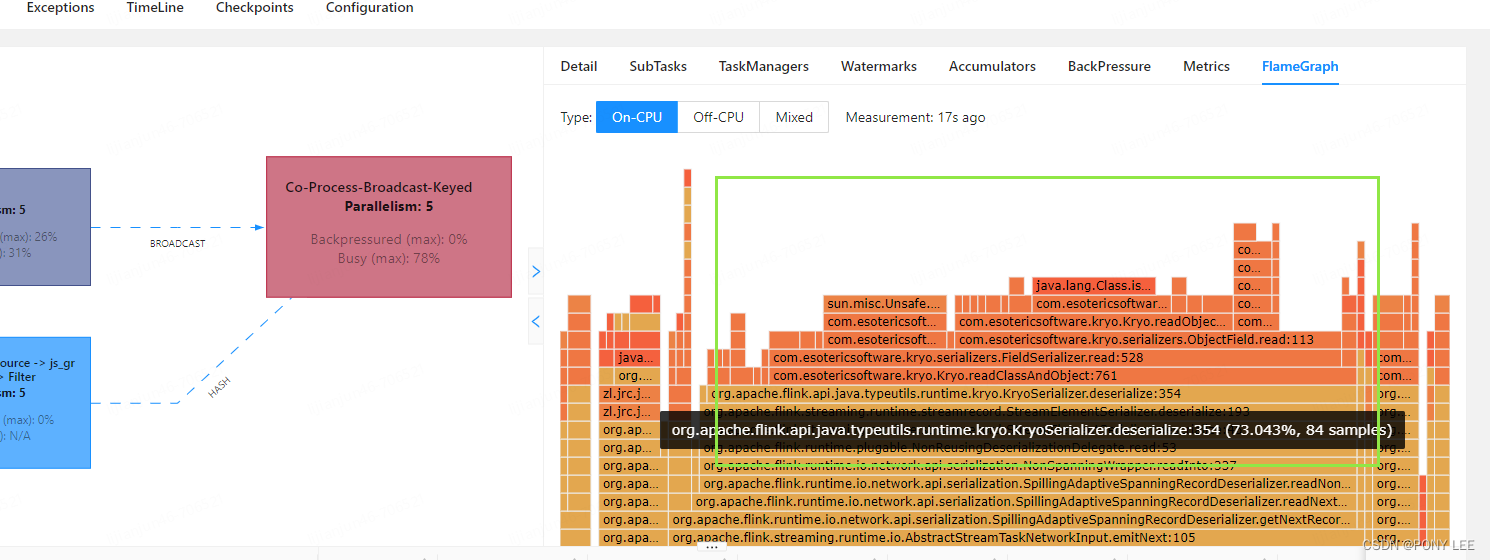
Flink问题解决及性能调优-【Flink rocksDB读写state大对象导致背压问题调优】
RocksDB是Flink中用于持久化状态的默认后端,它提供了高性能和可靠的状态存储。然而,当处理大型状态并频繁读写时,可能会导致背压问题,因为RocksDB需要从磁盘读取和写入数据,而这可能成为瓶颈。
遇到的问题
Flink开发…
【Flink-Kafka-To-Kafka】使用 Flink 实现 Kafka 数据写入 Kafka
【Flink-Kafka-To-Kafka】使用 Flink 实现 Kafka 数据写入 Kafka 1)导入依赖2)代码实现2.1.resources2.1.1.appconfig.yml2.1.2.log4j.properties2.1.3.log4j2.xml2.1.4.flink_backup_local.yml 2.2.utils2.2.1.DBConn2.2.2.CommonUtils 2.3.conf2.3.1.C…

Flink中StateBackend(工作状态)与Checkpoint(状态快照)的关系
State Backends
由 Flink 管理的 keyed state 是一种分片的键/值存储,每个 keyed state 的工作副本都保存在负责该键的 taskmanager 本地中。另外,Operator state 也保存在机器节点本地。Flink 定期获取所有状态的快照,并将这些快照复制到持…
Fink CDC数据同步(一)环境部署
1 背景介绍
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
Flink CDC 是 Apache Flink 的一组源连接器,基于数据库日志的…
flinksqlbug : AggregateFunction udf Could not extract a data type from
org.apache.flink.table.api.ValidationException: SQL validation failed. An error occurred in the type inference logic of function ‘default_catalog.default_database.CollectSetSort’. org.apache.flink.table.api.ValidationException: An error occurred in the t…
【大数据】Flink 中的 Slot、Task、Subtask、并行度
Flink 中的 Slot、Task、Subtask、并行度 1.并行度2.Task 与线程3.算子链与 slot 共享资源组4.Task slots 与系统资源5.总结 我们在使用 Flink 时,经常会听到 task,slot,线程 以及 并行度 这几个概念,对于初学者来说,这…
Flink SQL Client 安装各类 Connector、Format 组件的方法汇总(持续更新中....)
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…

Flink CEP(模式 API Pattern API )
目录
Flink CEP
模式 API(Pattern API) 1.个体模式
1.1基本形式
1.2 量词(Quantifiers )
1.3 条件(Conditions)
2.组合模式
2.1 初始模式(Initial Pattern)
2.2 近邻条件&a…
Flink(十一)【状态管理】
Flink 状态管理 我们一直称 Flink 为运行在数据流上的有状态计算框架和处理引擎。在之前的章节中也已经多次提到了“状态”(state),不论是简单聚合、窗口聚合,还是处理函数的应用,都会有状态的身影出现。状态就如同事务…
Flink cdc debug调试动态变更表结构
文章目录 前言调试流程1. 拉取代码本地打包2. 配置启动参数3. 日志配置4. 启动验证5. 断点验证 问题1. Cannot find factory with identifier "mysql" in the classpath.2.JsonFactory异常3. NoSuchMethodError异常其他 结尾 前言
接着上一篇Flink cdc3.0动态变更表…
Flink实时电商数仓(十)
common模块回顾
app BaseApp: 作为其他子模块中使用Flink - StreamAPI的父类,实现了StreamAPI中的通用逻辑,在其他子模块中只需编写关于数据处理的核心逻辑。BaseSQLApp: 作为其他子模块中使用Flink- SQLAPI的父类。在里面设置了使用SQL API的环境、并行…
Flink-【时间语义、窗口、水位线】
1. 时间语义
1.1 事件时间:数据产生的事件(机器时间);
1.2 处理时间:数据处理的时间(系统时间)。
🌰:可乐
可乐的生产日期 事件时间(可乐产生的时间&…
Flink实时电商数仓之旁路缓存
撤回流的处理
撤回流是指流式处理过程中,两表join过程中的数据是一条一条跑过来的,即原本可以join到一起的数据在刚开始可能并没有join上。
撤回流的格式: 解决方案 定时器:使用定时器定时10s(数据最大的时间差值&am…
【Flink入门修炼】1-2 Mac 搭建 Flink 源码阅读环境
在后面学习 Flink 相关知识时,会深入源码探究其实现机制。因此,需要现在本地配置好源码阅读环境。
本文搭建环境:
Mac M1(Apple Silicon)Java 8IDEAFlink 官方源码
一、 下载 Flink 源码
github 地址:h…
数据同步工具对比——SeaTunnel 、DataX、Sqoop、Flume、Flink CDC
在大数据时代,数据的采集、处理和分析变得尤为重要。业界出现了多种工具来帮助开发者和企业高效地处理数据流和数据集。本文将对比五种流行的数据处理工具:SeaTunnel、DataX、Sqoop、Flume和Flink CDC,从它们的设计理念、使用场景、优缺点等方…
StreamPark + PiflowX 打造新一代大数据计算处理平台
🚀 什么是PiflowX
PiFlow 是一个基于分布式计算框架 Spark 开发的大数据流水线系统。该系统将数据的采集、清洗、计算、存储等各个环节封装成组件,以所见即所得方式进行流水线配置。简单易用,功能强大。它具有如下特性: 简单易用…
52、Flink的应用程序参数处理-ParameterTool介绍及使用示例
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…
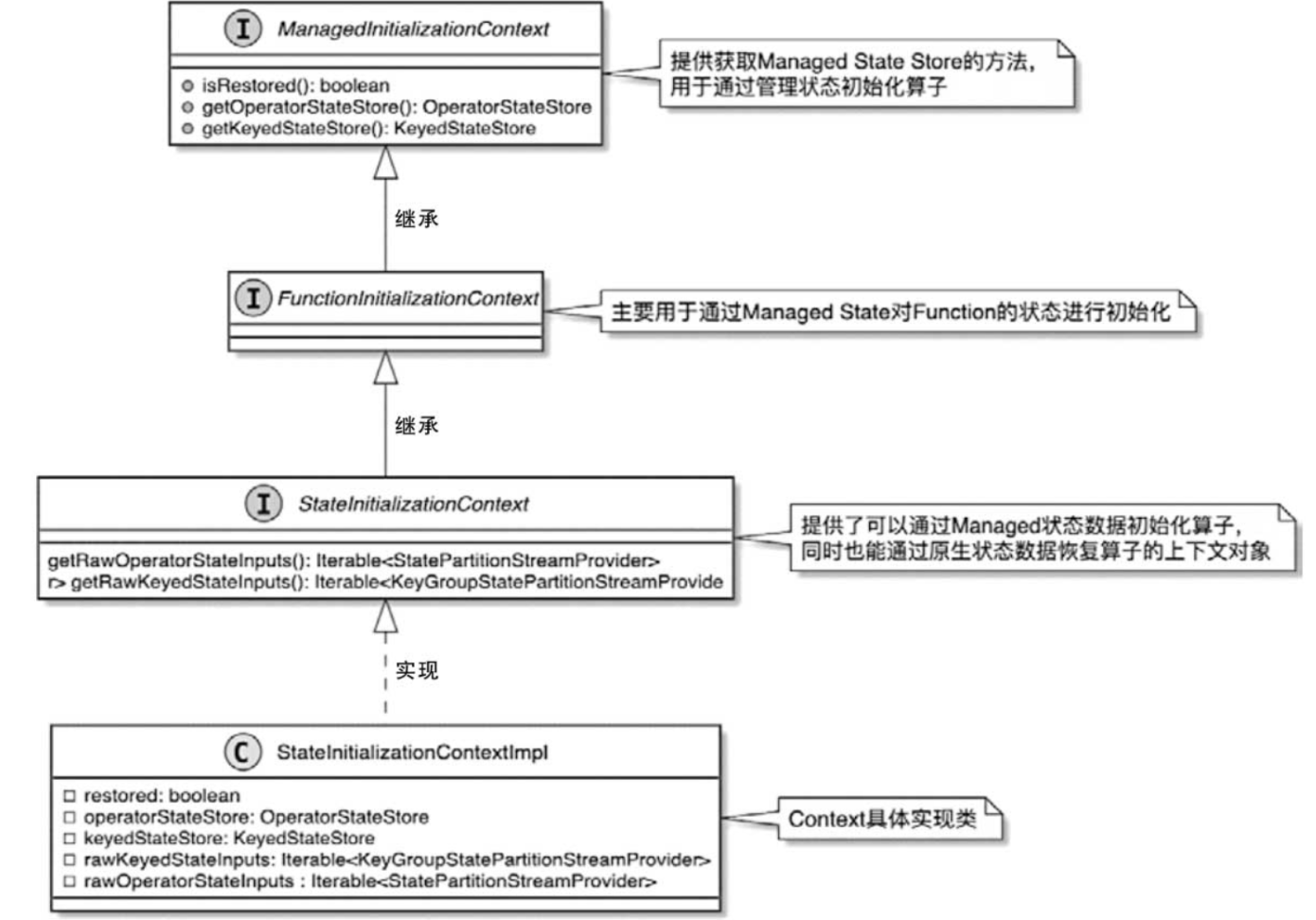
【flink状态管理(2)各状态初始化入口】状态初始化流程详解与源码剖析
文章目录 1. 状态初始化总流程梳理2.创建StreamOperatorStateContext3. StateInitializationContext的接口设计。4. 状态初始化举例:UDF状态初始化 在TaskManager中启动Task线程后,会调用StreamTask.invoke()方法触发当前Task中算子的执行,在…

flink反压及解决思路和实操
1. 反压原因
反压其实就是 task 处理不过来,算子的 sub-task 需要处理的数据量 > 能够处理的数据量,比如:
当前某个 sub-task 只能处理 1w qps 的数据,但实际上到来 2w qps 的数据,但是实际只能处理 1w 条&#…
flink中的row类型详解
在Apache Flink中,Row 是一个通用的数据结构,用于表示一行数据。它是 Flink Table API 和 Flink DataSet API 中的基本数据类型之一。Row 可以看作是一个类似于元组的结构,其中包含按顺序排列的字段。
Row 的字段可以是各种基本数据类型&…

Apache Flink连载(二十九):Flink细粒度资源管理(2)-用法、测试及局限性
🏡 个人主页:IT贫道-CSDN博客 🚩 私聊博主:私聊博主加WX好友,获取更多资料哦~ 🔔 博主个人B栈地址:豹哥教你学编程的个人空间-豹哥教你学编程个人主页-哔哩哔哩视频 目录
1.细粒度资源用法
Flink DataStream读写Hudi
一、pom依赖
测试案例中,pom依赖如下,根据需要自行删减。
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-ins…
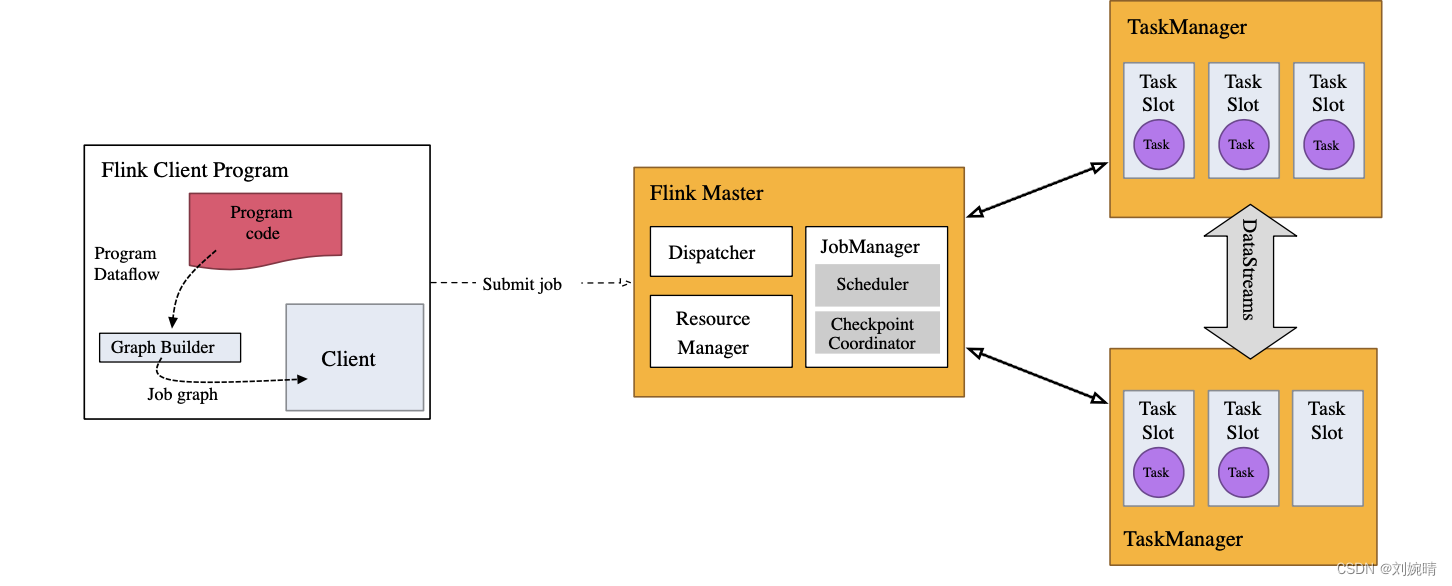
【Flink】Flink基础
Flink 官网地址 (官网介绍的非常详细,觉得看英文太慢的直接使用浏览器一键翻译,本文是阅读官方文档后进行的内容梳理笔记) https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/python/overview/ 这 Flink API …

Flink Upsert Kafka SQL Connector 介绍
一 前言
在某些场景中,比方GROUP BY聚合之后的后果,须要去更新之前的结果值。这个时候,须要将 Kafka 记录的 key 当成主键解决,用来确定一条数据是应该作为插入、删除还是更新记录来解决。在 Flink1.11 中,能够通过 f…
Apache Flink 1.15正式发布
Apache Flink 核心概念之一是流 (无界数据) 批 (有界数据) 一体。
流批一体极大的降低了流批融合作业的开发复杂度。在过去的几个版本中,Flink 流批一体逐渐成熟,Flink 1.15 版本中流批一体更加完善,后面我们也将继续推动这一方向的进展。目…
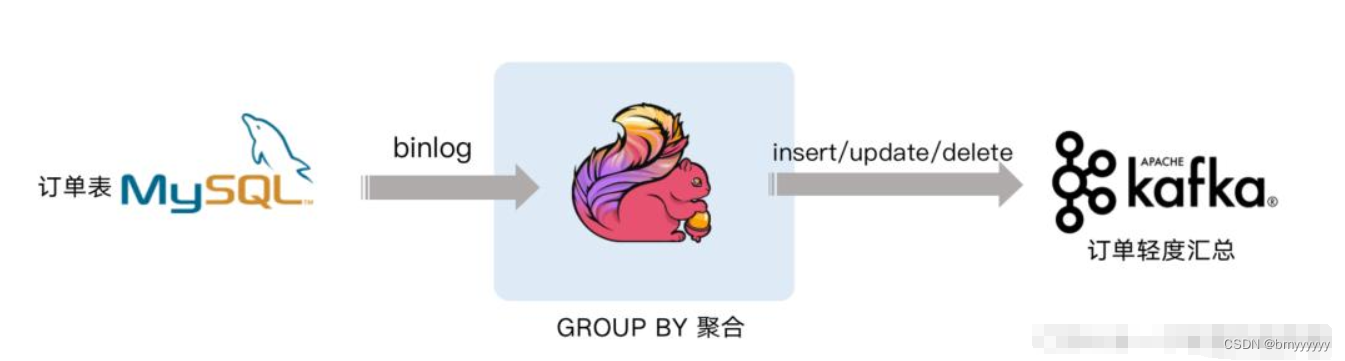
【Flink-CDC】Flink CDC 介绍和原理概述
【Flink-CDC】Flink CDC 介绍和原理概述 1)基于查询的 CDC 和基于日志的 CDC2)Flink CDC3)Flink CDC原理简述4)基于 Flink SQL CDC 的数据同步方案实践4.1.案例 1 : Flink SQL CDC JDBC Connector4.2.案例 2 : CDC Streaming ETL…
Flink状态编程之按键分区状态
简介
在实际应用中,我们一般都需要将数据按照某个 key 进行分区,然后再进行计算处理;所 以最为常见的状态类型就是 Keyed State。之前介绍到 keyBy 之后的聚合、窗口计算,算子所 持有的状态,都是 Keyed State。 另外,我们还可以通过富函数类(Rich Function)对转换算子…
【极数系列】Flink详细入门教程 知识体系 学习路线(01)
文章目录 01 引言02 Flink是什么2.1 Flink简介2.2 Flink架构2.3 Flink应用场景2.4 Flink运维 03 Flink环境搭建3.1 Flink服务端环境搭建3.2 Flink部署模式3.3 Flink开发环境搭建 04 Flink数据类型以及序列化4.1 数据类型4.2 数据序列化 05 Flink DataStream API5.1 执行模式5.2…
flink源码分析 - jar包中提取主类和第三方依赖
flink版本: flink-1.11.2
提取主类代码位置: org.apache.flink.client.program.PackagedProgram#getEntryPointClassNameFromJar
提取第三方依赖代码位置:org.apache.flink.client.program.PackagedProgram#getJobJarAndDependencies
代码逻辑比较简单,此处不再赘…

【极数系列】Flink配置参数如何获取?(06)
文章目录 gitee码云地址简介概述01 配置值来自.properties文件1.通过路径读取2.通过文件流读取3.通过IO流读取 02 配置值来自命令行03 配置来自系统属性04 注册以及使用全局变量05 Flink获取参数值Demo1.项目结构2.pom.xml文件如下3.配置文件4.项目主类5.运行查看相关日志 gite…
Flink Checkpoint 超时问题详解
第一种、计算量大,CPU密集性,导致TM内线程一直在processElement,而没有时间做CP【过滤掉部分数据;增大并行度】
代表性作业为算法指标-用户偏好的计算,需要对用户在商城的曝光、点击、订单、出价、上下滑等所有事件进…
Flink CDC 3.0 详解
一、Flink CDC 概述
Flink CDC 是基于数据库日志 CDC(Change Data Capture)技术的实时数据集成框架,支持全增量一体化、无锁读取、并行读取、表结构变更自动同步、分布式架构等高级特性。配合Flink 优秀的管道能力和丰富的上下游生态&#x…
【Flink】FlinkSQL的DataGen连接器(测试利器)
简介
我们在实际开发过程中可以使用FlinkSQL的DataGen连接器实现FlinkSQL的批或者流模拟数据生成,DataGen 连接器允许按数据生成规则进行读取,但注意:DataGen连接器不支持复杂类型: Array,Map,Row。 请用计算列构造这些类型
创建有界DataGen表 CREATE TABLE test ( a…
PiflowX新增Apache Beam引擎支持
参考资料:
Apache Beam 架构原理及应用实践-腾讯云开发者社区-腾讯云 (tencent.com)
在之前的文章中有介绍过,PiflowX是支持spark和flink计算引擎,其架构图如下所示: 在piflow高度抽象的流水线组件的支持下,我们可以…
2024.2.10 HCIA - Big Data笔记
1. 大数据发展趋势与鲲鹏大数据大数据时代大数据的应用领域企业所面临的挑战和机遇华为鲲鹏解决方案2. HDFS分布式文件系统和ZooKeeperHDFS分布式文件系统HDFS概述HDFS相关概念HDFS体系架构HDFS关键特性HDFS数据读写流程ZooKeeper分布式协调服务ZooKeeper概述ZooKeeper体系结构…
![[ 2024春节 Flink打卡 ] -- Paimon](https://img-blog.csdnimg.cn/direct/3c84841d55964805bf010c22ea80b83e.png)
[ 2024春节 Flink打卡 ] -- Paimon
Flink 社区希望能够将 Flink 的 Streaming 实时计算能力和 Lakehouse 新架构优势进一步结合,推出新一代的 Streaming Lakehouse 技术,促进数据在数据湖上真正实时流动起来,并为用户提供实时离线一体化的开发体验。原名 Flink Table Store &am…
flink+kafka 实现wordcount
以下内容基于flink1.12
pom依赖 <properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>…
wsl内置Ubuntu使用 Dinky 与 Flink 集成
Dinky 与 Flink 集成
说明
本文档介绍 Dinky 与 Flink 集成的使用方法,
如果您是 Dinky 的新用户, 请先阅读 本文档, 以便更好的搭建 Dinky 环境
如果您已经熟悉 Dinky 并已经部署了 Dinky, 请跳过本文档的前置要求部分, 直接阅读 Dinky 与 Flink 集成部分
注意: 本文档基…
【大数据面试题】008 谈一谈 Flink Slot 与 并行度
【大数据面试题】008 谈一谈 Flink Slot 与 并行度配置 并行度 Parallelism 概念作用Slot 概念作用如何设置TaskManager 任务管理器Flink submit 脚本 一步一个脚印,一天一道面试题 该文章有较多引用文章 https://zhuanlan.zhihu.com/p/572170629?utm_id0 并行度 P…
flink operator 1.7 更换日志框架log4j 到logback
更换日志框架 flink 1.18 1 消除基础flink框架log4j 添加logback jar
1-1 log4j
log4j-1.2-api-2.17.1.jar
log4j-api-2.17.1.jar
log4j-core-2.17.1.jar
log4j-slf4j-impl-2.17.1.jar
1-2 logback
logback-core-1.2.3.jar
logback-classic-1.2.3.jar
slf4j-api-1.7.25.jar2 …

flink如何利用checkpoint保证数据状态一致性
flink数据状态一致性 1状态一致性级别1.1 AT-MOST-ONCE (最多一次):1.2 AT-LEAST-ONCE (至少一次):1.3 EXACTLY-ONCE (精确一次):1.4 分布式快照与至少一次事件传递和重复数据删除的比较 2flink内部实现状态一致性3 端到端的一致性3.1 Source…

记一次 Flink 作业启动缓慢
记一次 Flink 作业启动缓慢
背景
应用发现,Hadoop集群的hdfs较之前更加缓慢,且离线ELT任务也以前晚半个多小时才能跑完。此前一直没有找到突破口所以没有管他,推测应该重启一下Hadoop集群就可以了。今天突然要重启一个Flink作业,…
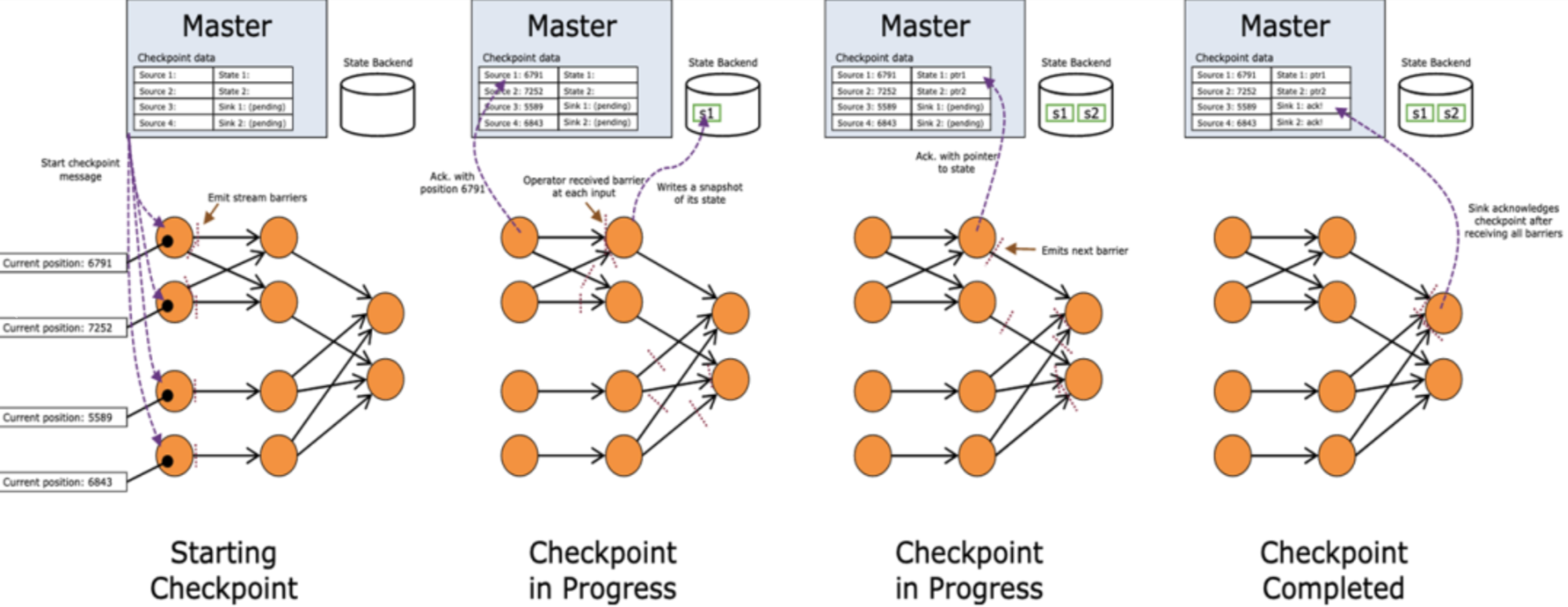
【Flink状态管理五】Checkpoint的设计与实现
文章目录 1. Checkpoint的整体设计2. Checkpoint创建源码解析2.1. DefaultExecutionGraphBuilder.buildGraph2.2. ExecutionGraph.enableCheckpointing 由于系统原因导致Flink作业无法正常运行的情况非常多,且很多时候都是无法避免的。对于Flink集群来讲,…
Flink 1.14.0 全新的 Kafka Connector
Apache Kafka Connector#Flink 提供了一个 Apache Kafka 连接器,用于从 Kafka Topic 读取数据和向 Kafka Topic 写入数据,并保证恰好一次次语义。Dependency#Apache Flink 附带了一个通用的 Kafka 连接器,它试图跟踪最新版本的 Kafka 客户端。…

flink内存管理,设置思路,oom问题,一文全
flink内存管理 1 内存分配1.1 JVM 进程总内存(Total Process Memory)1.2 Flink 总内存(Total Flink Memory)1.3 JVM 堆外内存(JVM Off-Heap Memory)1.4 JVM 堆内存(JVM Heap Memory)…

【Flink实战系列】Flink SQL 之 Retraction (回撤流)
什么是retraction(撤回)
通俗讲retract就是传统数据里面的更新操作,也就是说retract是流式计算场景下对数据更新的处理方式。
首先来看下流场景下的一个词频统计列子。 没有retract会导致最终结果不正确↑: 通过上面两个图可以很清楚的看到retract的作用,下面我们看一个…
【Flink实战系列】Flink各种报错汇总及解决方案(实时更新中)
这篇文章主要用来记录一下Flink中常见的报错以及解决方案(后面会持续更新)
1,Table is not an append-only table. Use the toRetractStream() in order to handle add and retract messages.
这个是因为动态表不是append-only模式的,需要用toRetractStream(回撤流)处理就好了…
CDC 整合方案:MySQL > Flink CDC > Kafka > Hudi
继上一篇 《CDC 整合方案:MySQL > Kafka Connect + Schema Registry + Avro > Kafka > Hudi》 讨论了一种典型的 CDC 集成方案后,本文,我们改用 Flink CDC 完成同样的 CDC 数据入湖任务。与上一个方案有所不同的是:借助现有的 Flink 环境,我们可以直接使用 Flink CDC 从…

flink内存管理模型(一) ------ 内存布局
本文主要简单介绍TaskManager的内存管理策略,以下均为笔者个人观点,欢迎大家批评指正。
一 、内存布局
在flink中,TaskManager内存主要分为三大块 JVM使用的内存 网络内存池 Flink自己管理的内存
Flink自己管理的内存:这个…
flink分区与算子链
flink分区与算子链 flink 分区策略flink 什么情况下才会把 Operator chain 在一起形成算子链? flink 分区策略
GlobalPartitioner 数据会被分发到下游算子的第一个实例中进行处理RebalancePartitioner 数 据会 被循 环发 送到 下 游的 每一 个实 例中 进 行处 理。…
Flink 深入理解任务执行计划,即Graph生成过程(源码解读)
深入理解Graph生成过程 1生成StreamGraph2生成JobGraph3生成ExecutionGraph:4生成物理执行图:5 批处理的物理执行计划同源实例的并行执行 我们先看一下,Flink 是如何描述作业的执行计划的。以这个 DataStream 作业为例,Flink 会基…
【Flink集群RPC通讯机制(三)】AkkaRpcActor设计与实现:接收RPC消息以及处理逻辑
文章目录 1. 创建Receiver2. 进行消息处理 RPC请求发送后接收方的处理逻辑 在RpcEndpoint中创建的RemoteRpcInvocation消息,最终会通过Akka系统传递到被调用方。例如TaskExecutor向ResourceManager发送SlotReport请求的时候,会在TaskExecutor中将Resourc…
docker打包当前dinky项目
以下是我的打包过程,大家可以借鉴。我也是第一次慢慢摸索,打包一个公共项目,自己上传。
如果嫌麻烦,可以直接使用我的镜像,直接跳到拉取镜像! <可以在任何地方的服务器进行拉取>
docker打包当前din…
深入理解Flink的检查点
检查点
Flink具体如何保证exactly-once呢?它使用一种被称为"检查点"(checkpoint)的特性,在出现故障时将系统重置回正确状态。 Flink的检查点算法Flink检查点的核心作用是确保状态正确,即使遇到程序中断,也要正确。记住这一基本点之后,Flink为用户提供了用来定…
Flink中常用的去重方案
Flink Sql去重方案
1、状态去重
将数据保存到状态中,进行累计
selectwindow_start, window_end, count(distinct devId) as cnt
from table (tumble(table source_table,descriptor(rt),interval 60 minute )) --滚动窗口
group by window_start,window_end; …
1理想的大数据处理框架设计
以下内容基于极客 蔡元楠老师的《大规模数据处理实战》做的笔记哈。感兴趣的去极客看蔡老师的课程即可。
MapReduce 缺点
高昂的维护成本
因为mapreduce模型只有map和reduce两个步骤。所以在处理复杂的架构的时候,需要协调多个map任务和多个reduce任务。
例如计…
Flink CDC、OGG、Debezium等基于日志开源CDC方案对比
先上一张图,后面再慢慢介绍: CDC概述
CDC 的全称是 Change Data Capture ,在广义的概念上,只要能捕获数据变更的技术,我们都可以称为 CDC 。我们目前通常描述的CDC 技术主要面向数据库的变更,是一种用于捕…
【第二章】分析一下 Flink中的流执行模式和批执行模式
目录
1、什么是有界流、无界流
2、什么是批执行模式、流执行模式
3、怎样选择执行模式?
4、怎样配置执行模式? 1、什么是有界流、无界流
有界流: 数据流定义了开始位置和结束位置,对一个计算任务而言,在计算前所有…
Flink学习:WaterMark
WaterMark一、什么是水位线?二、案例分析三、如何生成水位线?(一)、在SourceFunction中直接定义Timestamps和Watermarks(二)、自定义生成Timstamps和Watermarks一、什么是水位线?
通常情况下,由于网络或系统等外部因素影响,事件数据往往不能及时传输至Flink系统中,导致数据…

1-- Flink Kubernetes Operator 简介 2023
目录
1.历史发展
2.flink k8s operator 的适用场景
2.1 需要快速部署
2.2 需要高可用性
2.3 需要资源隔离
2.4 需要一定的灵活性
3.Flink k8s operater 的优点
3.1 相对于 yarn 的优点
3.2 相对于 flink native kubernetes 资源管理的优点
3.4.Flink k8s operator 自…

本期探究:Flink是怎样支持批流一体的呢?
今天咱们来聊一聊Flink是怎样支持批流一体的呢?
实现批处理的技术许许多多,从各种关系型数据库的sql处理,到大数据领域的MapReduce,Hive,Spark等等。这些都是处理有限数据流的经典方式。而Flink专注的是无限流处理&am…
【Flink学习】入门教程之Event-driven Applications
文章目录事件驱动应用处理函数(Process Functions)简介示例open() 方法processElement() 方法onTimer() 方法性能考虑旁路输出(Side Outputs)简介示例结语原文地址事件驱动应用
处理函数(Process Functions࿰…
Airwallex 基于 Flink 打造实时风控系统
摘要:本文整理自 Airwallex Risk ML Platform Team 董大凡,在 Flink Forward Asia 2022 实时风控专场的分享。本篇内容主要分为五个部分: 背景介绍应对方案技术挑战与亮点可用性保证线上表现点击查看直播回放和演讲 PPT 一、背景介绍 Airwall…
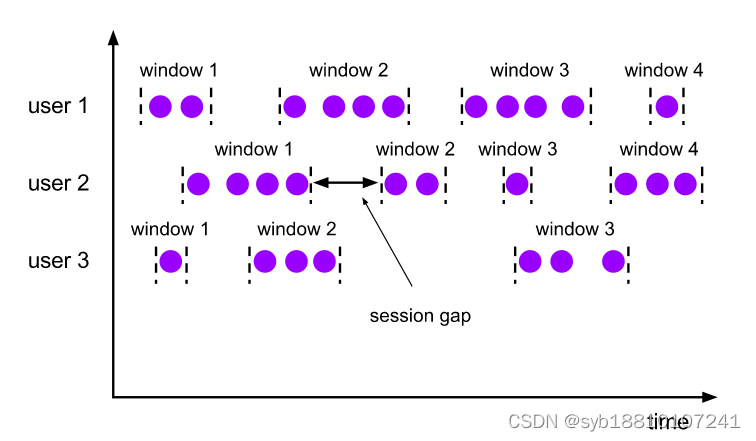
flink部署三种模式(案例操作)
文章目录一. Local模式1. 应用场景2. 操作二. Standalone 模式1. 应用场景2. 部署模式2.1 会话模式2.1.1 安装规划2.1.2 修改配置2.1.3 分发安装目录2.1.4 启动集群2.1.5 访问 Web UI2.2 单作业模式2.3 应用模式三. yarn模式(未实操)一. Local模式
1. 应…
flink 1.16 在centos安装 部署踩的坑
报错:
1 RESOURCES_DOWNLOAD_DIR : 这个错误是修改了 conf目录下 的 master 或 workers 等信息造成的.
2 修改了这个信息可能会造成输入密码的问题.
3 Could not connect to BlobServer at address localhost/127.0.0.1:39203 这个端口还会变化,这种问题可能是因为conf下的…
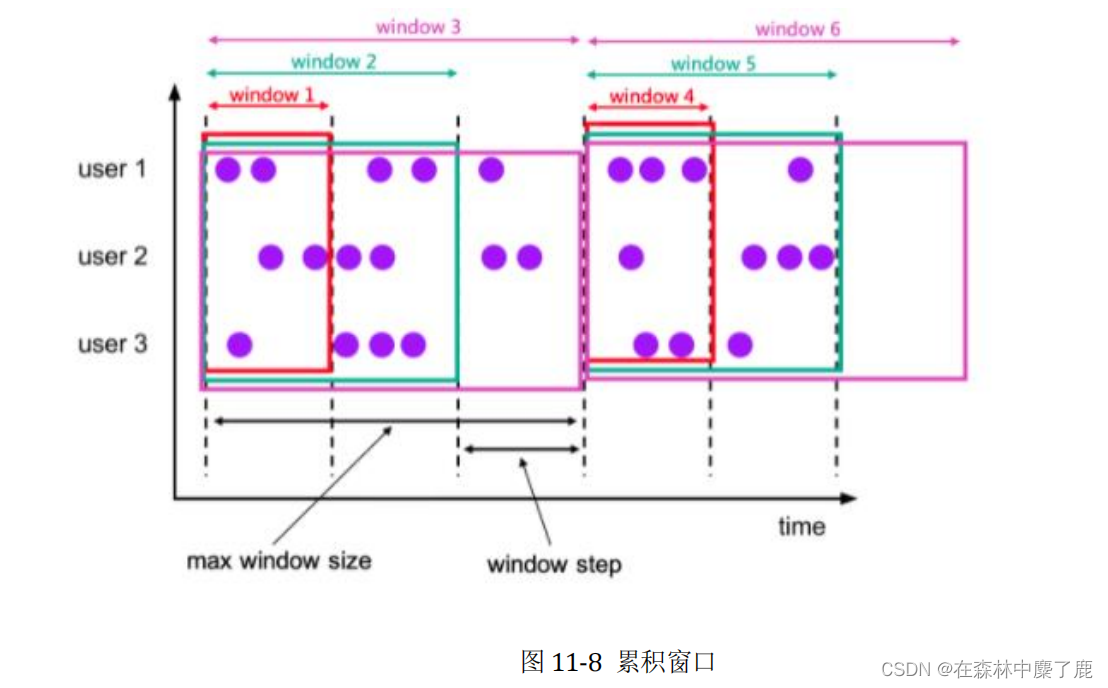
Flink (十一) --------- Table API 和 SQL
目录一、快速上手1. 需要引入的依赖2. 一个简单示例二、基本 API1. 程序架构2. 创建表环境3. 创建表4. 表的查询5. 输出表6. 表和流的转换三、流处理中的表1. 动态表和持续查询2. 将流转换成动态表3. 用 SQL 持续查询3. 将动态表转换为流四、时间属性和窗口1. 事件时间2. 处理时…

Flink CDC 2.4 正式发布,新增 Vitess 数据源,更多连接器支持增量快照,升级 Debezium 版本...
01 Flink CDC 简介 Flink CDC [1] 是基于数据库的日志 CDC 技术,实现了全增量一体化读取的数据集成框架。配合 Flink 优秀的管道能力和丰富的上下游生态,Flink CDC 可以高效实现海量数据的实时集成。 作为新一代的实时数据集成框架,Flink CDC…
Flink之state processor api读取checkpoint文件
什么是State Processor
API 官方文档说明:https://nightlies.apache.org/flink/flink-docs-release-1.12/zh/dev/libs/state_processor_api.html
目的
使用 State Processor API 可以 读取、写入和修改 savepoints 和 checkpoints ,也可以转为SQL查询来分析和处理…

基于Flink实时数仓——DWS 层-地区主题表(8)
这个主题使用FlinkSQL实现:数据直接从dwm_order_wide主题获取 代码实现:
public class ProvinceStatsSqlApp {public static void main(String[] args) throws Exception {//TODO 1.获取执行环境StreamExecutionEnvironment env StreamExecutionEnviro…

flink窗口详细说明
时间语义
Event Time : 事件创建的时间 (一般为kafka中消息中的时间字段,为事件消息的创建事件)
Ingestion Time:数据进入Flink的时间 (如source读取到kafka流时的时间)
Processing Time:执行…

基于Flink实时数仓——DWM 层-跳出明细计算(3.2)
什么是跳出?
跳出就是用户成功访问了网站的一个页面后就退出,不在继续访问网站的其它页面。而 跳出率就是用跳出次数除以访问次数。 关注跳出率,可以看出引流过来的访客是否能很快的被吸引,渠道引流过来的用户之间 的质量对比&am…
【Flink 源码系列】Flink 侧流输出源码解析
Flink 的 side output 为我们提供了侧流(分流)输出的功能,根据条件可以把一条流分为多个不同的流,之后做不同的处理逻辑,下面就来看下侧流输出相关的源码。 先来看下面的一个 Demo,一个流被分成了 3 个流&a…
Flink学习——DataStream API
一个flink程序,其实就是对DataStream的各种转换。具体可以分成以下几个部分: 获取执行环境(Execution Environment)读取数据源(Source)定义基于数据的转换操作(Transformations)定义…
【Flink 实战系列】Flink on yarn 为什么 Allocated CPU VCores 显示不正确?
Flink on yarn 为什么 Allocated CPU VCores 显示不正确?
一直有朋友问我这样的问题,在 flink on yarn 集群环境下,提交任务到 yarn,一个 TM 不管我设置多少个 slot,yarn 的 UI 界面 Allocated CPU VCores 一直显示的都是 1 呢?这个问题被问到了好多次,今天就来详细的解…
【Flink 实战系列】Flink pipeline.operator-chaining 参数使用以及源码解析
Flink pipeline.operator-chaining 参数使用和解析
当我们使用 Flink SQL 提交一个任务,没有给算子单独设置并行度的情况下,默认所有的算子会 chain 在一起,像下面的这样: 此时,整个 DAG 图只会显示一个算子,虽然这样有利于数据的传输,可以提高任务的性能,但是缺点也很…
Flink 1.14.0 消费 kafka 数据自定义反序列化类
在最近发布的 Flink 1.14.0 版本中对 Source 接口进行了重构,细节可以参考 FLIP-27: Refactor Source Interface重构之后 API 层面的改动还是非常大的,那在使用新的 API 消费 kafka 数据的时候如何自定义序列化类呢?Kafka SourceKafkaSource<String> source KafkaSourc…
【Flink实战系列】Flink SQL 如何实现 count window 功能?
Flink SQL 如何实现 count window 功能?
需求
在 Flink 里面窗口可以划分为两大类,分别是 TimeWindow 和 CountWindow.TimeWindow 是基于时间的,又可以细分为 Tumble Window, Hop Window, Session Window 这三种都是支持的,CountWindow 是基于个数的,目前在 Flink SQL 里面是…

深入解读 Flink 1.17
摘要:本文整理自阿里云技术专家,Apache Flink PMC Member & Committer、Flink CDC Maintainer 徐榜江(雪尽) 在深入解读 Flink 1.17 Meetup 的分享。内容主要分为四个部分: 1. Flink 1.17 Overview 2. Flink 1.17 Overall Story 3. Fli…
Flink自定义触发器
Flink自定义触发器
Apache Flink是一个流处理框架,它提供了许多内置的触发器来控制流处理作业的执行。但是,有时候内置的触发器不能满足我们的需求,这时候我们就需要自定义触发器,在编写自定义触发器之前,我们先来了解…
【Flink实战系列】Flink 1.9.0 on yarn 集群搭建过程报错
最近在搭建最新版本的Flink1.9.0 on yarn的过程中遇到这样一个报错.
Exception Details:Location:scala/collection/immutable/HashMap$HashTrieMap.split()Lscala/collection/immutable/Seq; @249: gotoReason:Error exists in the bytecodeBytecode:0000000: 2ab6 0064 04a0…
【Flink实战系列】Flink 最简单的 wordcount 示例
在上一篇中已经把flink的集群搭建好了,然后我们就先来写一个wordcount示例,直接看代码吧:
pom文件如下:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.11</artifactId><version>1.6.0</version><…
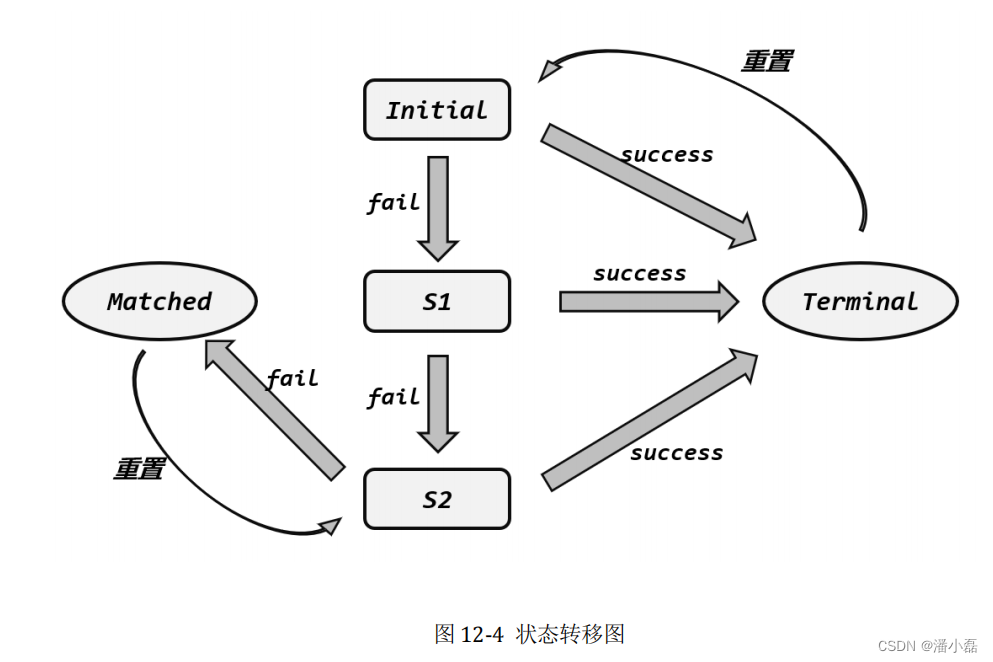
Flink从入门到精通之-12Flink CEP
Flink从入门到精通之-12Flink CEP
在 Flink 的学习过程中,从基本原理和核心层 DataStream API 到底层的处理函数、再到应用层的 Table API 和 SQL,我们已经掌握了 Flink 编程的各种手段,可以应对实际应用开发的各种需求了。 在大数据分析领域…
实时数仓建设第2问:怎样使用flink sql快速无脑统计当天下单各流程(已发货,确认收货等等)状态的订单数量
实时统计当天下单各流程状态(已支付待卖家发货,卖家通知物流揽收,待买家收货等等)中的订单数量。 订单表的binlog数据发送到kafka,flink从kafka接受消息进行指标统计。因为每笔订单的状态会发生变化,比如上午为【已支付待卖家发货】ÿ…
Flink开发环境搭建
1、POM依赖:
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache…

Flink窗口-时间窗口
(一)时间窗口的本质
前篇中,我们已经初略讲解了Flink中的数量窗口与时间窗口。
无论是哪一种窗口,他们的作用都类似于计算器(计算数量、时间)仅仅只是让数据堆积(不会像默认的流处理ÿ…
Flink消费kafka出现空指针异常
文章目录 出现场景:表现:问题:解决: tombstone : Kafka中提供了一个墓碑消息(tombstone)的概念,如果一条消息的key不为null,但是其value为null,那么此消息就是墓碑消息. …
Flink-Connectors(连接器)(3)RabbitMQ
flink 提供了专门操作RabbitMQ的连接器,使用起来更方便,配置连接信息即可快速实现数据读取与输出,但目前仅支持Queue模式,如需使用交换机模式,仍需要自定义RabbitMQ 数据源读取与数据
必要依赖
<dependency>&l…
Flink 程序Sink(数据输出)操作(5)自定义RabbitMq-Sink
Flink 程序Sink(数据输出)操作(5)自定义RabbitMq-Sink
自定义sink需要继承RichSinkFunction
ex:
public static class Demo extends RichSinkFunction<IN> {}自定义RabbitMQ sink必要依赖
<dependency><groupI…
Flink 程序Sink(数据输出)操作(4)自定义Redis-Sink
Flink 程序Sink(数据输出)操作(4)自定义Redis-Sink
自定义sink需要继承RichSinkFunction
ex:
public static class MyRedisSink extends RichSinkFunction<IN> {}必要依赖 <dependency><groupId>org.apache.…
Flink 程序Sink(数据输出)操作(3)自定义Mysql-Sink
Flink 程序Sink(数据输出)操作(3)自定义Mysql-Sink
自定义sink需要继承RichSinkFunction
ex:
public static class MysqlSink extends RichSinkFunction<IN> {}必要依赖
<dependency><groupId>mysql</gr…
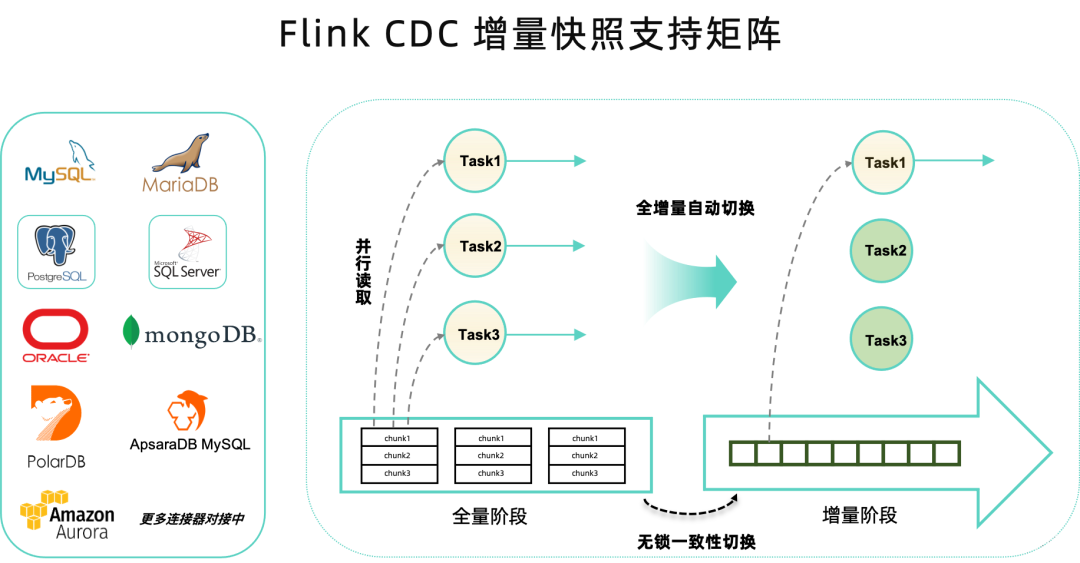
Flink CDC 2.4 正式发布,5分钟了解CDC 2.4新内容,新增 Vitess 数据源,更多连接器支持增量快照,升级 Debezium 版本
Flink CDC 2.4 正式发布,5分钟了解CDC 2.4新内容,新增 Vitess 数据源,更多连接器支持增量快照,升级 Debezium 版本 01. Flink CDC 简介02. Flink CDC 2.4 概览03. 详解核心特性和重要改进3.1 深入解读3.2 其他改进 04. 未来规划 来…
Flink CheckPoint 与 SavePoint 区别
CheckPoint 与 SavePoint 区别
概念
1. checkpoint
checkpoint主要目的是在意外作业失败的情况下提供一个恢复机制。checkpoint的生命周期由Flink管理,也就是说,checkpoint由Flink创建、拥有和释放–无需用户互动。由于checkpoint经常被触发ÿ…
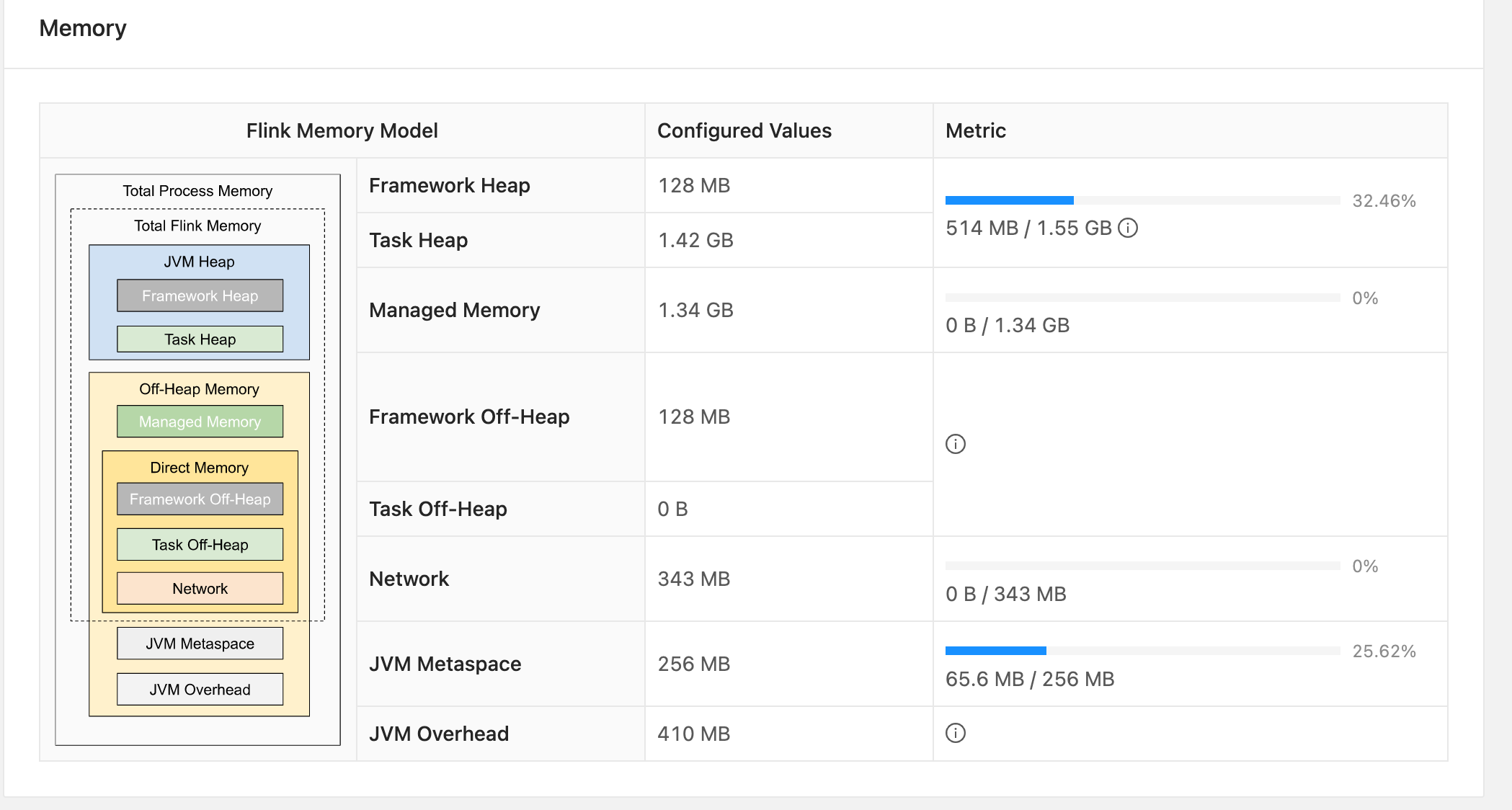
【性能调优】【离线任务】flink处理离线任务(8000个小文件?200多亿数据量?)稳定性与性能调优探索
文章目录一、场景描述1. 任务类型描述2. 问题任务二、相关理论1.Task Slots and Resources1.1. slots与资源的隔离和共享1.2 建议cpu和slot数关系2. tm的资源配置是否合适2.1. flink load problems2.2. 阿里 flink资源配置建议三、问题分析与解决1. 测试结果比对1.1. 任务11.2.…
![流批一体计算引擎-7-[Flink]的DataStream连接器](https://img-blog.csdnimg.cn/0f8a107145bd450683169a016f6d0830.png)
流批一体计算引擎-7-[Flink]的DataStream连接器
参考官方手册DataStream Connectors
1 DataStream连接器概述
一、预定义的Source和Sink 一些比较基本的Source和Sink已经内置在Flink里。 1、预定义data sources支持从文件、目录、socket,以及collections和iterators中读取数据。 2、预定义data sinks支持把数据写…
Flink程序加载数据源(3)自定义数据源(2)从Mysql 加载数据源
Flink程序加载数据源(3)自定义数据源(2)从Mysql 加载数据源
上文引出了Flink程序自定义数据源的方法,我们来再次回顾下。
Flink还提供了数据源接口(抽象类),我们实现该接口(…

flink笔记8 WaterMark
WaterMark
WaterMark介绍
WaterMark的特点
WaterMark设定方法 WaterMark介绍
流处理从事件产生,到流经 source,再到 operator,中间是有一个过程和时间的,由于网络、分布式等原因,可能导致乱序或迟到的产生。所谓乱…
![[实战系列]SelectDB Cloud Flink Connector 最佳实践](https://img-blog.csdnimg.cn/ce71b59848b3423bb570c64185bfe9f1.png)
[实战系列]SelectDB Cloud Flink Connector 最佳实践
概述
随着云基础设施的不断完善,云原生已经成为各行业数字化转型的必选项,越来越多的应用开始进行云原生化架构升级和应用迁移。
而云原生实时数仓的出现,让传统的数据仓库无论是成本、灵活性还是开放性等方面都显露出不足。拥有高性能、高…

flink笔记7 Flink时间语义和Window
Catalog
Flink的三种时间语义
Window
Window API Flink的三种时间语义 事件生成时间 Event time :事件自身的时间,一般就是数据本身携带的时间事件接入时间 Ingestion time :事件进入Flink的时间,在数据源操作处(进…

flink笔记2 Flink DataStream 设置并行度的几种方法
用于记录老师上课时讲的几种设置并行度的方法 1.创建执行环境后设置(1)
val env StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(4)
2.创建执行环境后设置(2)
val env StreamExecutionEnvironment.getExecutionEnvironmentStreamExecutionEnviron…

大数据文章汇总-Hadoop、MapReduce、Storm、Spark、Flink
Hadoop生态,包括HDFS、MapReduce、YARN、HBase等等。
大数据、Hadoop核心框架和MapReduce原理
CentOS 7 单机安装最新版Hadoop v3.1.2以及配置和简单测试
Hadoop v3.1.2 伪分布式安装(Pseudo-Distributed Operation)
Hadoop生态系统-新手…
Apache Flink快速入门-基本架构、核心概念和运行流程
Apache Flink 是什么?
Flink是一个基于流计算的分布式引擎,以前的名字叫stratosphere,从2010年开始在德国一所大学里发起,也是有好几年的历史了,2014年来借鉴了社区其它一些项目的理念,快速发展并且进入了…
Flink学习:Flink Table / Sql API的Window操作
Flink Window一、Table Api(一)、GroupBy Window(二)、OverWindow二、Sql(一)、GroupBy Window(二)、Over Window一、Table Api
(一)、GroupBy Window
groupBy window和DataStream/Dataset API中提供的窗口一致,都是将流式数据集根据窗口类型切分成有界数据集,然后在有界数据…

Flink之Sink
Flink 的 DataStream API 专门提供了向外部写入数据的方法:addSink。与 addSource 类似,addSink 方法对应着一个“Sink”算子,主要就是用来实现与外部系统连接、并将数据提交写入的;Flink 程序中所有对外的输出操作,一…

学会Flink看完这一篇就够了
Flink系列专题
近两年flink技术成为了大数据行业的主流,同时也成为了各大公司招聘的首选要求。笔者当初也是从零开始学习,网上找各种视频,看各种博客去学习,但一直没有总结整理成文章。我相信对于很多读者来说,学习一…

【Flink学习】入门教程之Data Pipelines ETL
文章目录数据管道 & ETL无状态的转换map()flatmap()Keyed StreamskeyBy()通过计算得到键Keyed Stream 的聚合(隐式的)状态reduce() 和其他聚合算子有状态的转换Flink 为什么要参与状态管理?Rich Functions一个使用 Keyed State 的例子清理…
大数据开发:Flink入门(四)——编程模型
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性、高吞吐、低延迟等优势,本文简述flink的编程模型。
数据集类型: 无穷数据集:无穷的持续集成的数据集合 有界数据集:有限不会改…
大数据开发:关于Zookeeper的几个核心知识点
为什么会有ZooKeeper
我们知道要写一个分布式应用是非常困难的,主要原因就是局部故障。一个消息通过网络在两个节点之间传递时,网络如果发生故障,发送方并不知道接收方是否接收到了这个消息。有可能是收到消息以后发生了网络故障࿰…
StarRocks简单使用
从clickhouse迁移到StarRocks,研究讨论后,决定使用flink进行kafka同步到StarRocks
1、数据模型
StarRocks 的数据模型主要分为3类:
Aggregate,聚合模型Unique,主键模型Duplicate,明细模型
因数据都是日志类数据&…
flink的Watermark 1.12版本的实现方式
watermark以前的实现方式 首先需要指定时间为eventTime env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);使用BoundedOutOfOrdernessTimestampExtractor类来生成watermark // 转换成SensorReading类型,分配时间戳和watermark
DataStream<SensorR…

Flink学习笔记(6)——时间语义与Wartmark及EventTime在Window中的使用
Flink中的时间语义
Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。 Ingestion Time:是数据进入Flink的时…

大数据平台架构及主流技术栈
互联网和移动互联网技术开启了大规模生产、分享和应用数据的大数据时代。面对如此庞大规模的数据,如何存储?如何计算?各大互联网巨头都进行了探索。Google的三篇论文 GFS(2003),MapReduce(2004),Bigtable(2006)为大数据…

Flink学习笔记(4)——source and sink
文章目录前言从集合读取数据从文件读取数据从socket读取数据从kafka读取数据自定义Sourcesink到kafkasink到redissink到Elasticsearchjdbc自定义前言
flink中提供了很多种数据源,有基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 s…
Flink 1.14测试cdc写入到kafka案例
测试案例
1、遇到的问题
1.1 bug1
io.debezium.DebeziumException: Access denied; you need (at least one of) the REPLICATION SLAVE privilege(s) for this operation Error code: 1227; SQLSTATE: 42000.at io.debezium.connector.mysql.MySqlStreamingChangeEventSour…

Flink之时间和窗口
Flink中的时间和窗口
在流数据处理应用中,一个很重要、也很常见的操作就是窗口计算。所谓的“窗口”,一 般就是划定的一段时间范围,也就是“时间窗”;对在这范围内的数据进行处理,就是所谓的 窗口计算。所以窗口和…
Flink CDC入门案例
由于Flink CDC是基于日志的方式,因此需要开启MySQL的binlog日志。
开启binlog日志的配置如下 #1.编辑MySQL的配置文件 vim /etc/my.cnf #添加如下内容 [mysqld] log-binmysql-bin # 开启 binlog binlog-formatROW # 选择 ROW 模式 server_id1 # 配置 MySQL replact…

Flink集群搭建教程
文章目录前言下载解压修改配置文件配置flink环境变量(三台主句修改/etc/profile)启动flink集群问题及解决办法前言
本次教程使用了三台主机分别是bigdata151、bigdata152、bigdata153。
下载
按照所需版本下载 比如scala版本 地址:https://flink.apache.org/down…

基于flink的流数据统计
一、统计流程 image.png
所有流计算统计的流程都是: 1、接入数据源 2、进行多次数据转换操作(过滤、拆分、聚合计算等) 3、计算结果的存储 其中数据源可以是多个、数据转换的节点处理完数据可以发送到一个和多个下一个节点继续处理数据
Flink程序构建的基本单元是…
flink入门原理简介
Apache Flink(以下简称Flink)项目是大数据处理领域最近冉冉升起的一颗新星,其不同于其他大数据项目的诸多特性吸引了越来越多人的关注。本文将深入分析Flink的一些关键技术与特性,希望能够帮助读者对Flink有更加深入的了解&#x…

基于Flink实时数仓——维表关联代码实现(4)
维表关联代码实现
维度关联实际上就是在流中查询存储在 HBase 中的数据表。但是即使通过主键的方式查询,HBase 速度的查询也是不及流之间的 join。外部数据源的查询常常是流式计算的性能瓶颈,所以咱们再这个基础上还有进行一定的优化。 优化1࿱…
三十二:Flink计算PV,UV代码实现
我们学习了 Flink 消费 Kafka 数据计算 PV 和 UV 的水印和窗口设计,并且定义了窗口计算的触发器,完成了计算 PV 和 UV 前的所有准备工作。 接下来就需要计算 PV 和 UV 了。在当前业务场景下,根据 userId 进行统计,PV 需要对 userId 进行统计,而 UV 则需要对 userId 进行去…
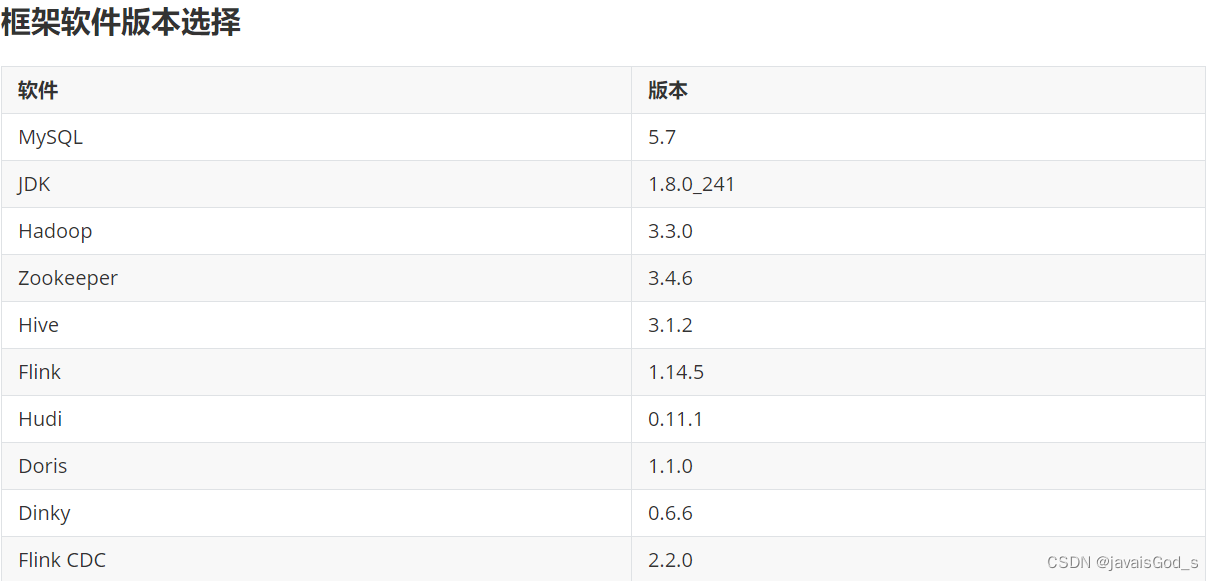
Flink、Hudi技术选型
Flink CDC 2.2的优势
相比Flink1.x,2.x的版本有如下的特点:
1) 并发读取,全量数据的读取性能可以水平扩展。
2) 全程无锁,不对线上业务产生锁的风险。
3) 断点续传,支持全量阶段的 Checkpoint。
Flink SQL的优势 …
基于Flink实时数仓——用户行为日志DWD层(1)
用户行为日志DWD层实现目标:
识别新老用户,虽然客户端有新老用户的标识,但是不准确,需要用实时计算再次确认利用侧输出流实现数据拆分,根据日志数据内容,将日志数据分为3类, 页面日志、启动日志和曝光日志。页面日志输…
flink Table API 与SQL入门实战
流处理和批处理都可以用,是非常的方便!导入依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table_2.11</artifactId><version>1.7.0</version>
</dependency>测试案例
import org.apache.flink.st…
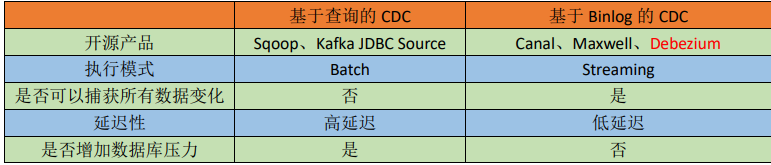
Flink-CDC和其他的CDC比较
什么是 CDC?
CDC 是 Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务…
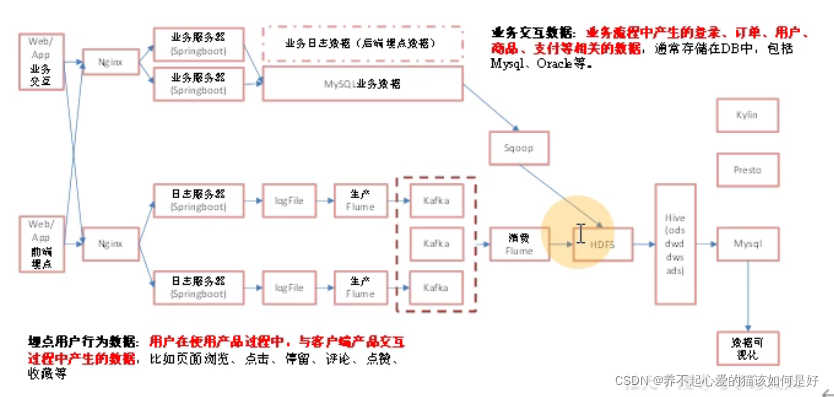
实时数仓与离线数仓架构对比、Flink消费流程
实时数仓架构图: 离线数仓:
与离线数仓区别:
MySQL业务数据采集改用FlinkCDC;FlinkCDC与Maxwell处理方式和Cannal一样通过监控binlog方式(行级别),而Sqoop是通过MR方式处理数据,这种方式太慢…
如何解决Flink任务的数据倾斜
如何解决flink任务的数据倾斜问题
Flink 任务的数据倾斜问题可以通过以下几种方法来解决: 使用滑动窗口:滑动窗口可以将窗口划分成多个子窗口,从而使数据更加均衡地分配到不同的计算节点中。同时,滑动窗口还可以使窗口内的数据更…
Flink / SQL - 6.Tumble、Slide、Session、Over Window 详解
目录
一.引言
二.模拟数据表
1.数据源 DataSource
2.DataStream To Table
三.滚动窗口 Tumble
1.By EventTime
Flink 实战 - 8.Timer 与 TimerService 源码分析与详解
目录
一.引言
二.Timer 简介与特性
1.Timer 四大特性
1.1 Timers are registered on a KeyedStream
1.2 Timers are automatically deduplicated
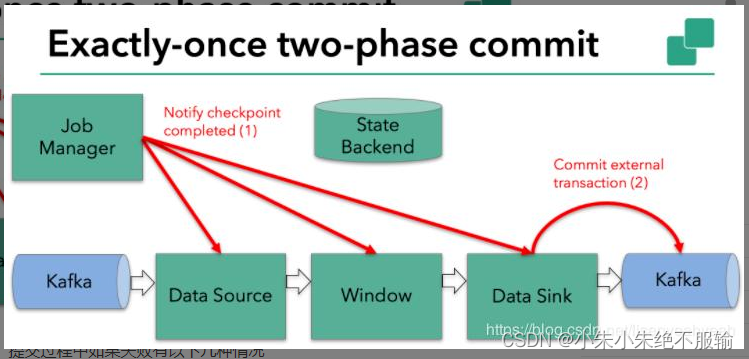
Flink内核源码(六)状态容错与两阶段提交
第六章就来学习一下Flink的状态(Checkpoint和Savepoint)容错与两阶段提交。
问题整理:
1. 什么是Flink的状态?状态后端?状态容错机制? 2. 什么是Flink的Checkpoints? 3. 什么是Flink的Savepoints? 4. Fli…

Flink 异常 - 9.The heartbeat of TaskManager with id container timed out 分析与 Heartbeat 简介
一.引言
Flink 运行任务期间报错 The heartbeat of TaskManager with id container timed out,对应任务由 Running 切换为 Failed,下面基于该问题进行排查与解决。 二.问题描述
该 Flink 任务 7x24 h 挂起,为 EventTime 模式下的有状态带 ValueState 作业,运行期间 Value…
Flink内核源码(一)任务提交流程
最近在学习了尚硅谷的Flink内核源码解析,内容很多,因此想要整理学习一下。Flink的版本是1.12.0。
第一章就来从源码层面学习一下Flink的任务提交流程。想要了解一个框架,需要了解它是怎么提交任务的。源码的解析跳转过程比较多,因…
Flink / Scala - 17.Metrics 使用与详解
一.引言
Flink 公开了一套度量系统,允许开发者收集运行中的数据并展示到外部系统,例如终端和监控页面,1.15.x 下 Flink 支持四套监控指标: A.Counter - 计数器,针对最基本的计数需求,类似 Accumulator 累加器B.Gauges - 仪表,针对自定义 T 的累加需求,结果通过 T.toSt…
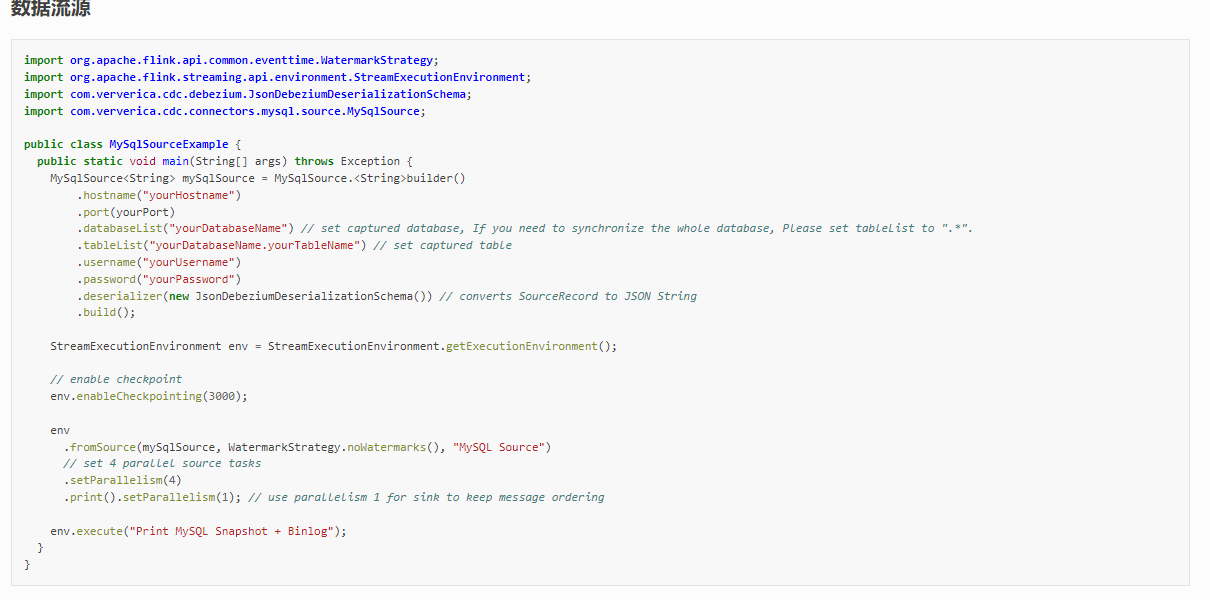
springboot集成flink-cdc
文章目录前文(1)什么是CDC(2)Flink-CDC是什么(3)Flink-CDC 特性CDC与Flink毕业版本Springboot项目整合Flink-CDC(1)说明(2)引入依赖(3)…
4.1、Flink任务怎样读取集合中的数据
1、API说明
非并行数据源: def fromElements[T: TypeInformation](data: T*): DataStream[T] def fromCollection[T: TypeInformation](data: Seq[T]): DataStream[T] def fromCollection[T: TypeInformation] (data: Iterator[T]): Data…
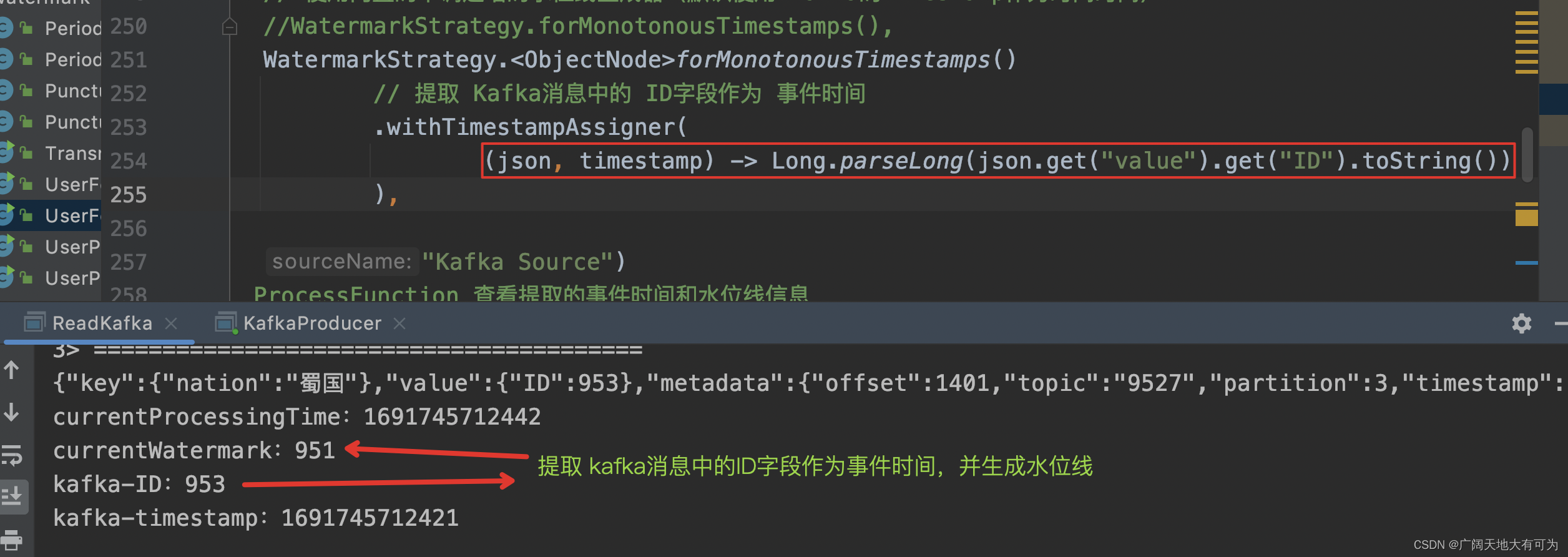
4.3、Flink任务怎样读取Kafka中的数据
目录
1、添加pom依赖
2、API使用说明
3、这是一个完整的入门案例
4、Kafka消息应该如何解析
4.1、只获取Kafka消息的value部分
4.2、获取完整Kafka消息(key、value、Metadata)
4.3、自定义Kafka消息解析器
5、起始消费位点应该如何设置
5.1、earliest()
5.2、lat…
深入理解Flink IntervalJoin源码
IntervalJoin基于connect实现,期间会生成对应的IntervalJoinOperator。
PublicEvolving
public <OUT> SingleOutputStreamOperator<OUT> process(ProcessJoinFunction<IN1, IN2, OUT> processJoinFunction,TypeInformation<OUT> outputTyp…
Flink Standlone集群搭建
文章目录Flink1.12 standalone集群模式搭建一、集群搭建准备(1)服务器资源(2)JAVA 执行环境(3)flink安装包(4)服务间需要配置免密登录① 执行生成SSH KEY 命令② 将公钥发送给需要免…
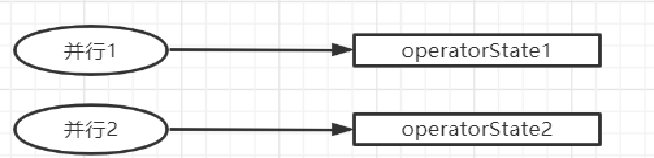
Flink-State
文章目录前言什么叫无状态计算什么叫有状态计算自己设计的状态管理Flink中的有状态计算Flink状态分类Managed State & Raw StateManaged State 分为两种,Keyed State 和 Operator StateKeyed State(键控状态)Operator State(算…
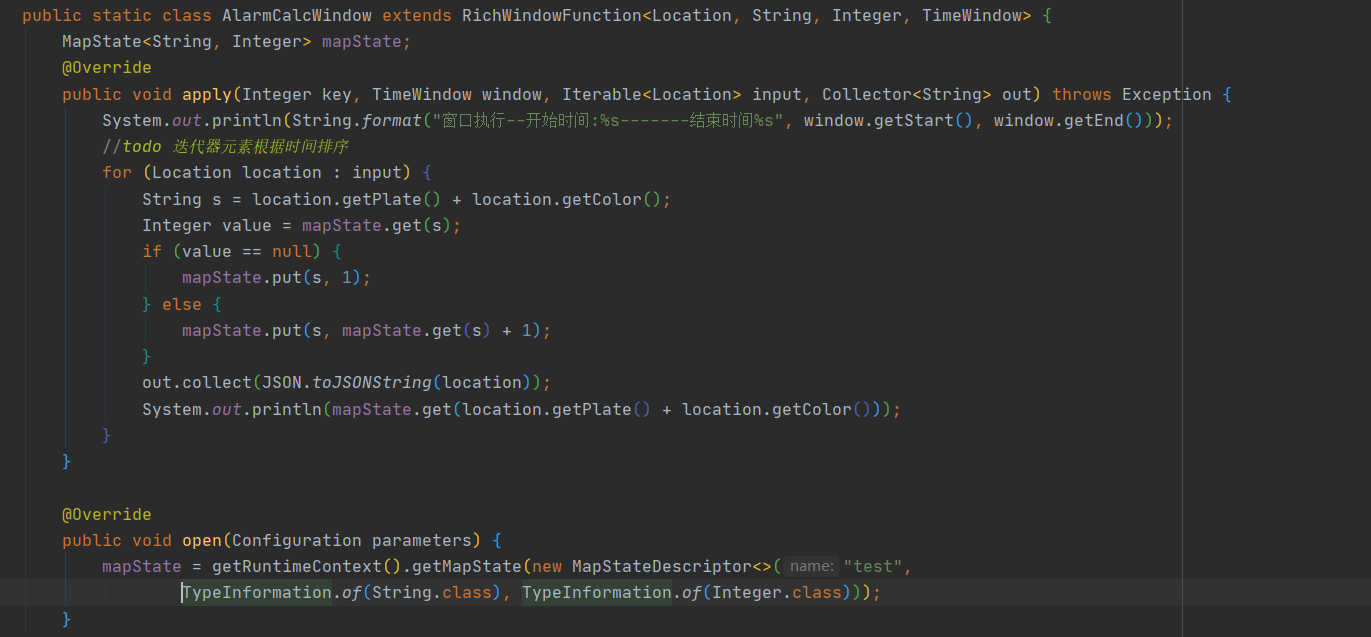
Flink- WaterMaker+Allowed-Lateness
文章目录(一)前言-回顾WaterMaker(二)前言-回顾窗口生命周期(三)Allowed-Lateness的作用(四)WaterMaker与Allowed-Lateness区别(五)Allowed-Lateness使用实战…

Flink 解决乱序问题之WaterMaker
前言
在前面的时间窗口中,我们初步使用了ProcesstimeWindow以及EventTimeWindow,我们注意到,在使用事件时间窗口的时候,系统提示我们要么设置WaterMaker,要么将时间处理模式切换为ProcessTime 完整错误信息:
Caused by: java.lang.RuntimeE…
实时数仓建设第3问:你不会认为Lookup维表缓存数据ttlicon策略和Redis key TTL策略一样吧
同事说维表缓存,当缓存项在指定的时间段内没有被读就会被回收,如果被读就会延长ttl时间。如果关联的维表数据变动就会导致无法获取最新维度数据,这种场景必须关闭缓存。
在flink 1.16之前缓存的创建方式如下:
CacheBuilder.newB…

Flink 流批一体在 Shopee 的大规模实践
摘要:本文整理自 Shopee 研发专家李明昆,在 Flink Forward Asia 2022 流批一体专场的分享。本篇内容主要分为四个部分: 1. 流批一体在 Shopee 的应用场景 2. 批处理能力的生产优化 3. 与离线生态的完全集成 4. 平台在流批一体上的建设和演进 …
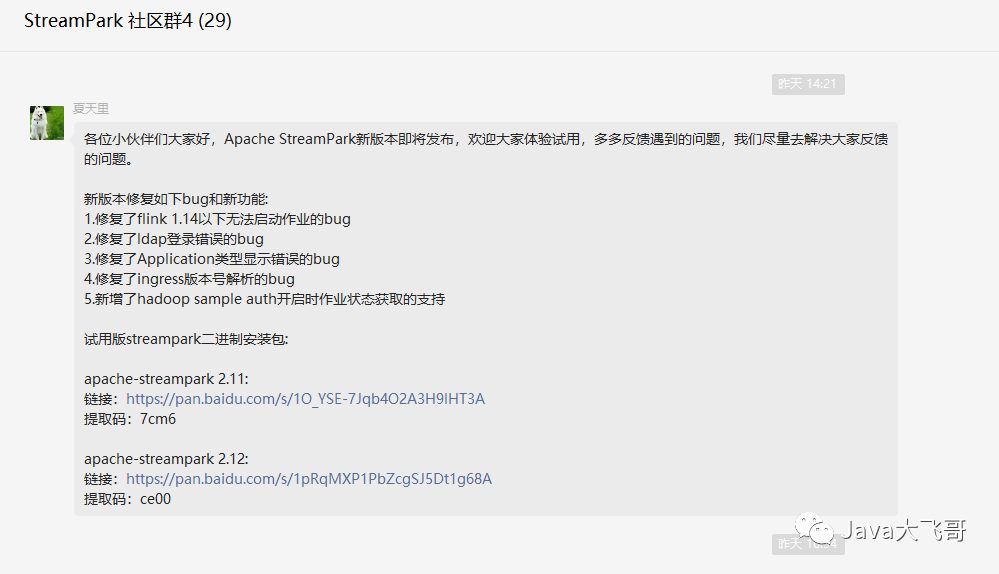
ApacheStreamPark2.1.0部署及执行flink-cdc任务同步mysql表的数据到es的实践
文章目录 [toc] 1.ApacheStreamPark是什么?2.介绍2.1 特性2.2 架构2.3 Zeppelin和StreamPark的对比 3.相关连接4.部署4.1 二进制包编译构建4.2 镜像构建4.3 初始化sql4.4 部署4.4.1 Docker-compose.yaml部署脚本4.4.2 配置文件准备4.4.3 flink启动配置4.4.4 streamp…
Flink的计数功能探索
探索flink计数功能,欢迎指正!!
使用场景:需要对经过算子处理后的DataStream中不同类型的数据进行全局统计个数(正解见第三种)
1.Metric
参考地址:https://ci.apache.org/projects/flink/flin…
flink-sql自定义rabbitmq connector
flink sql 自定义 rabbitmq connector
直接上代码
github 地址:
https://github.com/liutaobigdata/flink-sql-rabbitmq-connector
SourceFactory 代码 public class RabbitmqTableSourceFactory implements DynamicTableSourceFactory {private static final S…

Flink 窗口算子知识点扫盲
文章目录(一)窗口算子(Window)的由来(二)Window的分类(1)按照time和count分类(2)按照slide和size分类(3)time、count与 slide和size组合(三&#…
《Flink入门与实战》简介
《Flink入门与实战》,ApacheFlink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态的计算,广泛应用于大数据相关的实际业务场景中。本书是一本从零开始讲解Flink的入门教材,定价89元,配套示例源码、PPT课…

Flink 程序Sink(数据输出)操作(1)控制台
sink是flink程序三大逻辑结构之一(source(数据源),transform(数据处理),sink(数据输出)),主要功能就是负责把flink处理后的数据输出到外部系统中。
在…
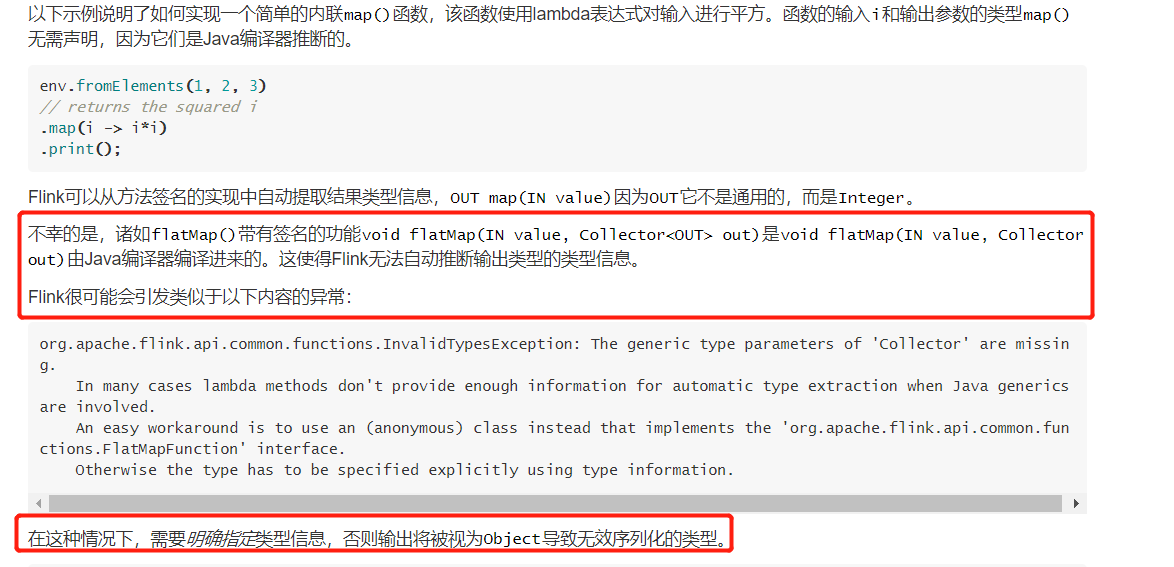
Flink程序中Tuple类型使用+ 算子程序Lambda方式正确使用姿势
文章目录(一)Tuple(1)说明(2)Tuple的使用元组使用姿势1元组使用姿势2Flink计算程序中Tuple使用姿势(二)算子程序Lambda表达式的使用(1)之前算子使用姿势&…

Flink1.12 DataStream(java)常用算子示例
文章目录前言Map算子FlatMap算子Filter算子KeyBy算子Max、Min、Sum、Reduce算子maxminsumreduceUnion算子Connect算子CoProcessFunction、CoFlatMap、CoMapProcess 算子Side Outputs算子(原 split、select)Window算子CoGroup算子算子链式调用总结&#x…
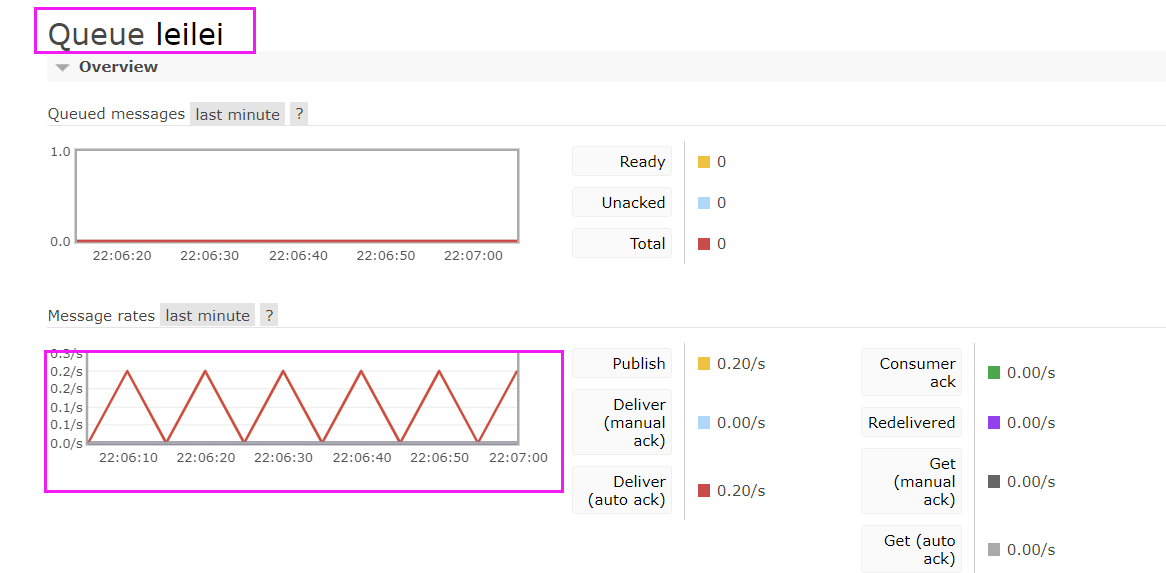
Flink程序加载数据源(4)从RabbitMQ中加载数据源
文章目录(1)自定义数据源说明(2)RabbitMQ中加载数据源(1)添加依赖(2)自定义RabbitMQ数据源(3)RabbitMQ连接器配置(4)加载自定义Rabbit…

Flink程序加载数据源(2)Scoket流
文章目录服务端客户端(代码端)flink 读取scoket数据程序何时终止计算?flink可以从scoket流中加载数据源
首先,我们需要先获取执行环境(必需),
StreamExecutionEnvironment env StreamExecuti…
Flink程序加载数据源(1)集合与文件
文章目录Flink程序加载数据源(1)集合与文件(1)从集合加载数据源(2)从文件中加载数据Flink程序加载数据源(1)集合与文件
flink可以从集合以及文件中读取数据源
下面进行代码演示
首…

【大数据】Flink 详解(五):核心篇 Ⅳ
Flink 详解(五):核心篇 Ⅳ 45、Flink 广播机制了解吗? 从图中可以理解 广播 就是一个公共的共享变量,广播变量存于 TaskManager 的内存中,所以广播变量不应该太大,将一个数据集广播后࿰…

Flink1.12 流批一体Hello-world
文章目录(1)核心依赖(2)流批一体测试环境说明:java: 1.8
flink: 1.12.2
编译器:IDEA MAVEN项目
要开发flink程序,首先,我们需要引入依赖,必要依赖POM.xml文件如下
(1…
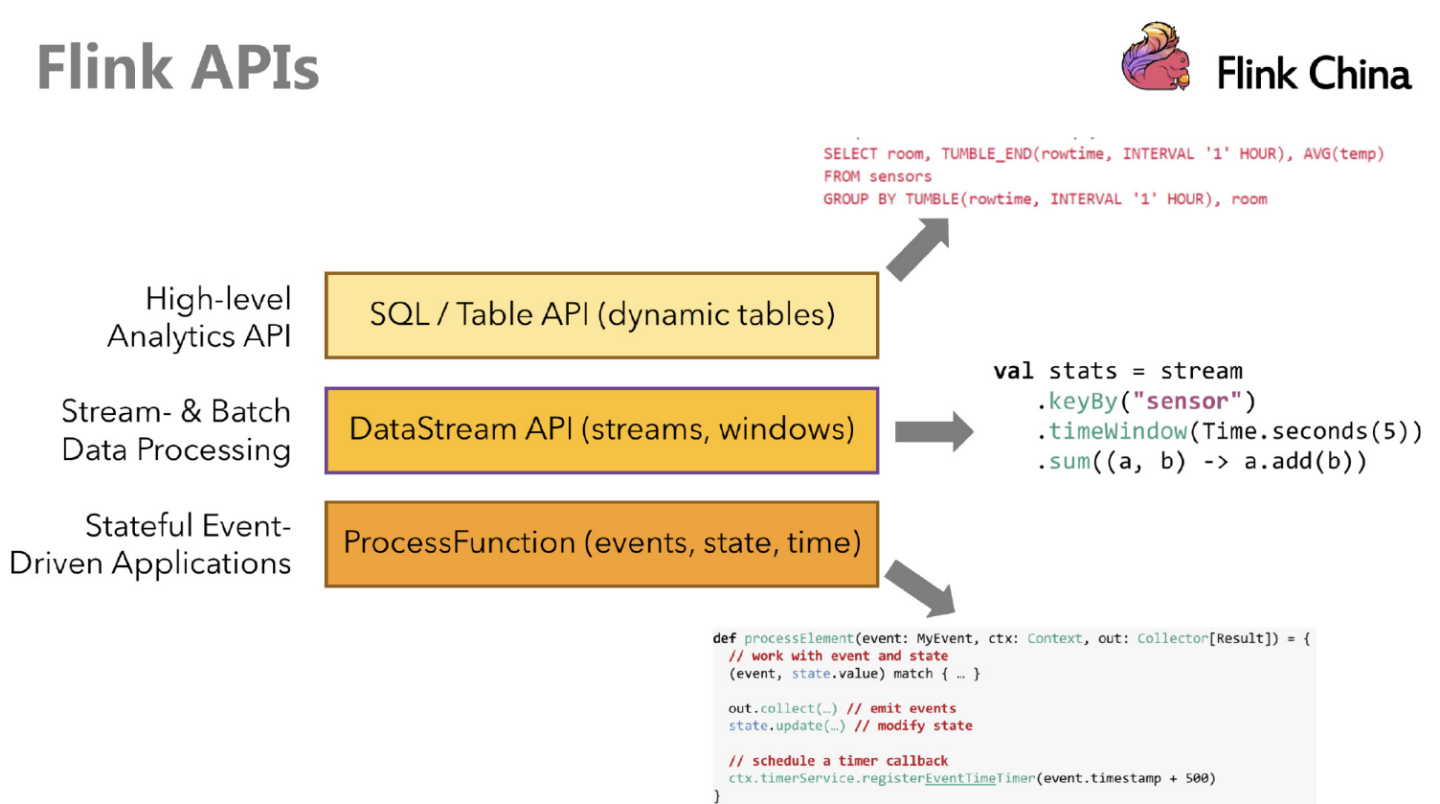
flink流批一体相关概念
文章目录(1)数据时效性(2)流处理与批处理(3)流处理与批处理对比(4)流批一体API(DataStream)(1)数据时效性
日常工作中,…

Flink、Yarn架构,以Flink on Yarn部署原理详解
Flink、Yarn架构,以Flink on Yarn部署原理详解
Flink 架构概览
Apache Flink是一个开源的分布式流处理框架,它可以处理实时数据流和批处理数据。Flink的架构原理是其实现的基础,架构原理可以分为以下四个部分:JobManager、TaskM…

Apache Hudi初探(二)(与flink的结合)--flink写hudi的操作(JobManager端的提交操作)
背景
在Apache Hudi初探(一)(与flink的结合)中,我们提到了Pipelines.hoodieStreamWrite 写hudi文件,这个操作真正写hudi是在Pipelines.hoodieStreamWrite方法下的transform(opName("stream_write", conf), TypeInformation.of(Object.class), operatorFa…
flink1.12 单机安装
文章目录Local本地模式下载上传至服务器并解压启动Flink本地“集群”查看启动后进程页面访问测试flinkLocal本地模式
运行流程:
Flink程序由JobClient进行提交JobClient将作业提交给JobManagerJobManager负责协调资源分配和作业执行。资源分配完成后,任…
Flink技术灵活使用总结(二)广播变量、广播流的使用
目录
广播变量基础知识
广播变量使用示例
1.广播变量的应用
2.广播流的应用 广播变量基础知识 Flink可以将数据广播到TaskManager上就可以供TaskManager中的SubTask/task去使用,数据存储到

怎样系统规划大数据学习之路?
大数据的领域非常广泛,往往使想要开始学习大数据及相关技术的人望而生畏。大数据技术的种类众多,这同样使得初学者难以选择从何处下手。
这正是我想要撰写本文的原因。本文将为你开始学习大数据的征程以及在大数据产业领域找到工作指明道路,…
大数据入门必读好书推荐
身处于一个大数据时代,大数据无疑是近期最时髦的词汇了。
不管是云计算、社交网络,还是物联网、移动互联网和智慧城市,都要与大数据搭上联系。 随着云计算、移动互联网和物联网等新一代信息技术的创新和应用普及。学习大数据,除了…
Hive 终于等来了 Flink
等疫情过去了,我们一起看春暖花开。 Apache Spark 什么时候开始支持集成 Hive 功能?
笔者相信只要使用过 Spark 的读者,应该都会说这是很久以前的事情了。
那 Apache Flink 什么时候支持与 Hive 的集成呢?
读者可能有些疑惑&am…
flink滚动日志的配置
flink滚动日志的配置
flink 1.11.0之前版本的配置
################################################################################# This affects logging for both user code and Flink
log4j.rootLoggerINFO, RFA# Uncomment this if you want to _only_ change Flink…
解密大数据领域岗位职业发展路径
我们迎来了一个新的时代,这就是大数据的时代。 —经济学家 詹姆斯莫里斯 行业背景 国家信息中心《2017中国大数据产业发展报告》对我国大数据产业发展的人才、政策、投融资、创新创业、产业发展、区域潜力、机构和人物影响力等多个维度进行了全面分析。结果显示&am…
日均处理万亿条数据,爱奇艺实时计算平台设计
1.爱奇艺 Flink 服务现状
爱奇艺从 2012 年开始开展大数据业务,一开始只有二十几个节点,主要是 MapReduce、Hive 等离线计算任务。到 2014 年左右上线了 Storm、Spark 实时计算服务,并随后发布了基于 Spark 的实时计算平台 Europa。2017 年开…
Flink入门(四)——编程模型
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性、高吞吐、低延迟等优势,本文简述flink的编程模型。
数据集类型: 无穷数据集:无穷的持续集成的数据集合 有界数据集:有限不会改…
从Storm到Flink:大数据处理的开源系统及编程模型
开源系统及编程模型
基于流计算的基本模型,当前已有各式各样的分布式流处理系统被开发出来。本节将对当前开源分布式流处理系统中三个最典型的代表性的系统:Apache Storm,Spark Streaming,Apache Flink以及它们的编程模型进行详细…
Flink并行度与slot之间的关系
简介 Flink运行时主要角色有两个:JobManager和TaskManager,无论是standalone集群,flink on yarn都是要启动这两个角色。JobManager主要是负责接受客户端的job,调度job,协调checkpoint等。TaskManager执行具…
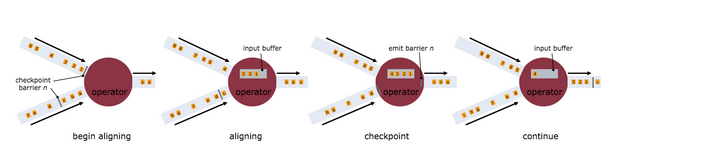
Flink中CheckPoint详细
Flink提供了Exactly once特性,是依赖于带有barrier的分布式快照可部分重发的数据源功能实现的。而分布式快照中,就保存了operator的状态信息。 Flink的失败恢复依赖于 检查点机制 可部分重发的数据源。 检查点机制机制:checkpoint定期触…
flink KeyedStream的reduce操作
序
本文主要研究一下flink KeyedStream的reduce操作
实例 Testpublic void testWordCount() throws Exception {// Checking input parameters
// final ParameterTool params ParameterTool.fromArgs(args);// set up the execution environmentfinal StreamExecuti…
三十五:自定义消息事件
上一课时中讲了 CEP 的基本原理并且用官网的案例介绍了 CEP 的简单应用。在 Flink CEP 中存在多个比较晦涩的概念,如果你对于这些概念理解有困难,我们可以把:创建系列 Pattern,然后利用 NFACompiler 将 Pattern 进行拆分并且创建出 NFA,NFA 包含了 Pattern 中的各个状态和…
二十六:Flink Redis Sink 实现
“Flink 常用的 Source 和 Connector”中提过 Flink 提供了比较丰富的用来连接第三方的连接器,可以在官网中找到 Flink 支持的各种各样的连接器。 此外,Flink 还会基于 Apache Bahir 发布一些 Connector,其中就有我们非常熟悉的 Redis。很多人在 Flink 项目中访问 Redis 的方…
二十三:Flink消费Kafka数据开发
我们提过在实时计算的场景下,绝大多数的数据源都是消息系统,而 Kafka 从众多的消息中间件中脱颖而出,主要是因为高吞吐、低延迟的特点;同时也讲了 Flink 作为生产者像 Kafka 写入数据的方式和代码实现。这一课时我们将从以下几个方面介绍 Flink 消费 Kafka 中的数据方式和源…
⑥Flink集群安装部署和HA配置-实战
这一课时将讲解 Flink 常见的部署模式:本地模式、Standalone 模式和 Flink On Yarn 模式,然后分别讲解三种模式的使用场景和部署中常见的问题,最后将讲解在生产环境中 Flink 集群的高可用配置。
Flink 常见的部署模式
环境准备
在绝大多数情况下,我们的 Flink 都是运行在…

写Flink Spark遇到的问题
OOM:调小核数,增加每个核的内存
调用map函数显示No implicits found for parameter evidence
解决:要在这段前面加上隐式转换,就是注释掉的那个
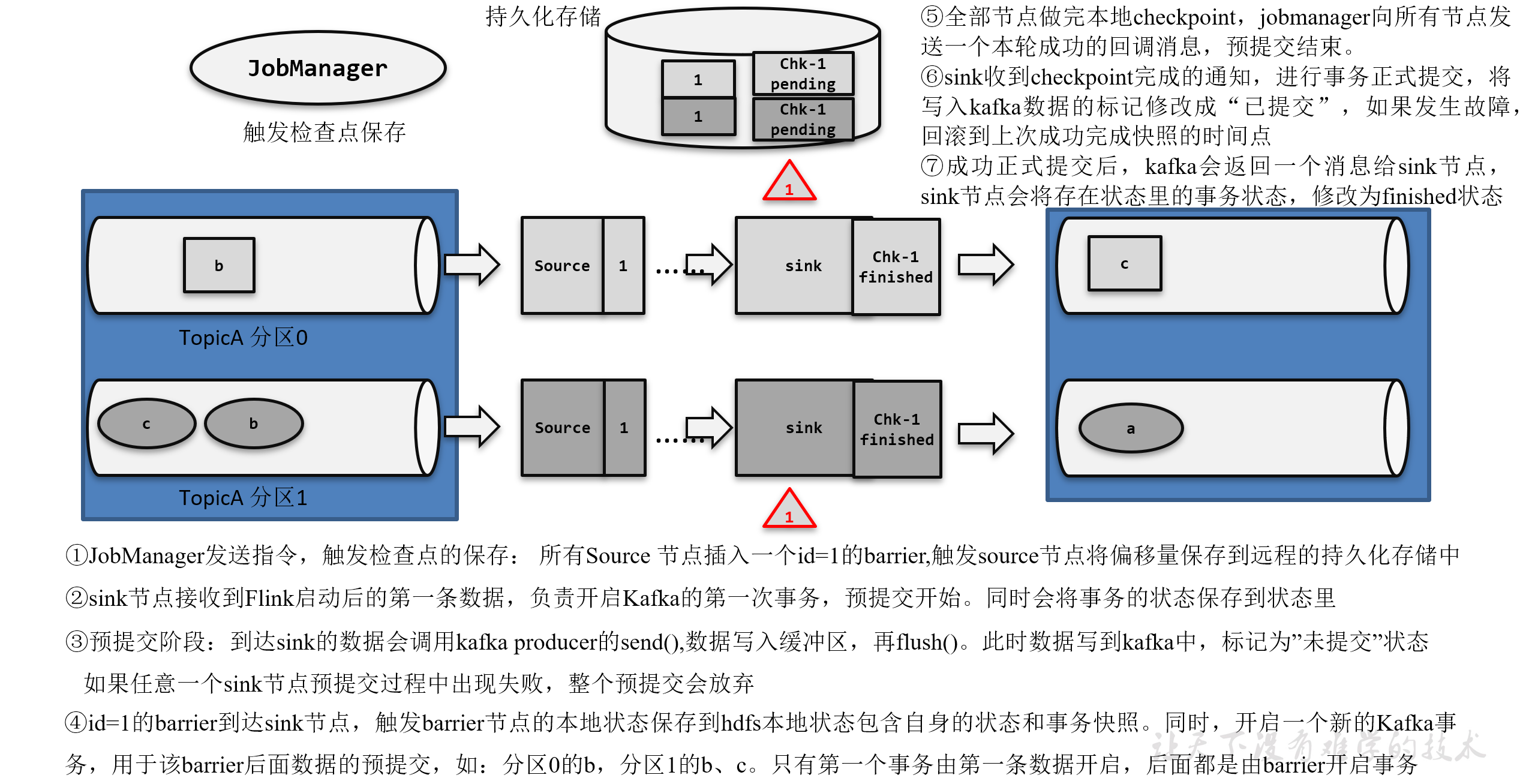
《Flink学习笔记》——第十章 容错机制
10.1 检查点(Checkpoint) 为了故障恢复,我们需要把之前某个时间点的所有状态保存下来,这份“存档”就是“检查点” 遇到故障重启的时候,我们可以从检查点中“读档”,恢复出之前的状态,这样就可以…
如何处理 Flink 作业频繁重启问题?
分析&回答
Flink 实现了多种重启策略
固定延迟重启策略(Fixed Delay Restart Strategy)故障率重启策略(Failure Rate Restart Strategy)没有重启策略(No Restart Strategy)Fallback重启策略ÿ…
Windows下安装Canal,Kafka,Flink,Spark
Canal安装使用 canal 1.1.1版本之后,server端可以通过简单的配置就能将订阅到的数据投递到kafka中 https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.deployer-1.1.5.tar.gz 解压即可(遇到了一些问题,改用低版本) 1.0.24下载使用:下载1.0.24的(Relea…
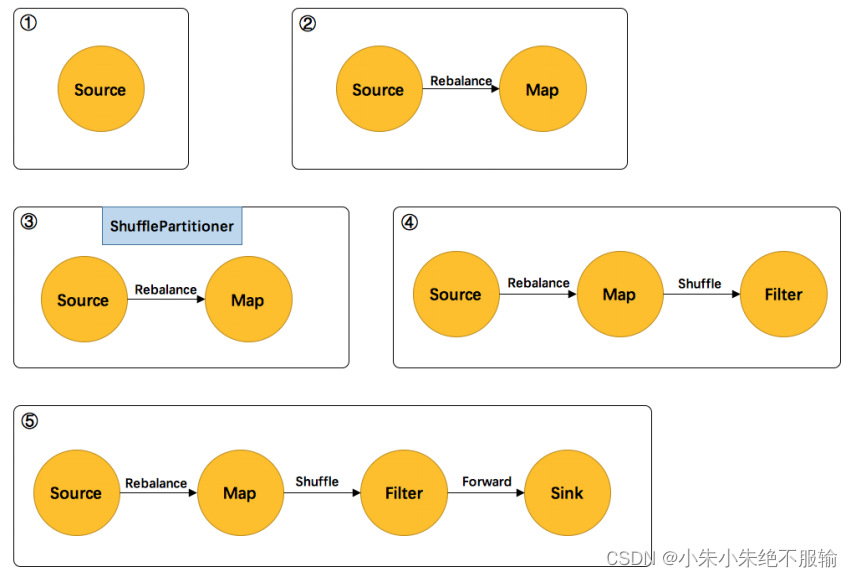
Flink内核源码(三)任务调度机制
最近在学习了尚硅谷的Flink内核源码解析,内容很多,因此想要整理学习一下。Flink的版本是1.12.0。
第三章就来从源码层面学习一下Flink的任务调度机制。主要分为两部分,一部分是图的详细转换过程,另一部分是任务调度执行。
问题整…
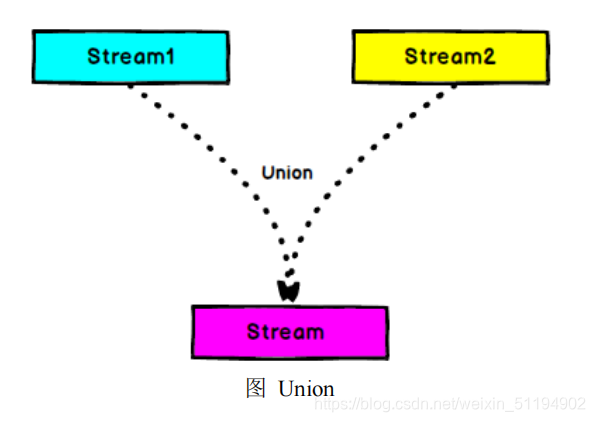
Flink的常用算子以及实例
1.map
特性:接收一个数据,经过处理之后,就返回一个数据 1.1. 源码分析
我们来看看map的源码 map需要接收一个MapFunction<T,R>的对象,其中泛型T表示传入的数据类型,R表示经过处理之后输出的数据类型我们继续往…
iceberg系列之 hadoop catalog 小文件合并实战
背景 flink1.15 hadoop3.0pom文件 <?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://mave…
Flink分流,合流,状态,checkpoint和精准一次笔记
第8章 分流 1.使用侧输出流
2.合流 2.1 union :使用 ProcessFunction 处理合流后的数据 2.2 Connect : 两条流的格式可以不一样, map操作使用CoMapFunction,process 传入:CoProcessFunction 2.2 BroadcastConnectedSt…
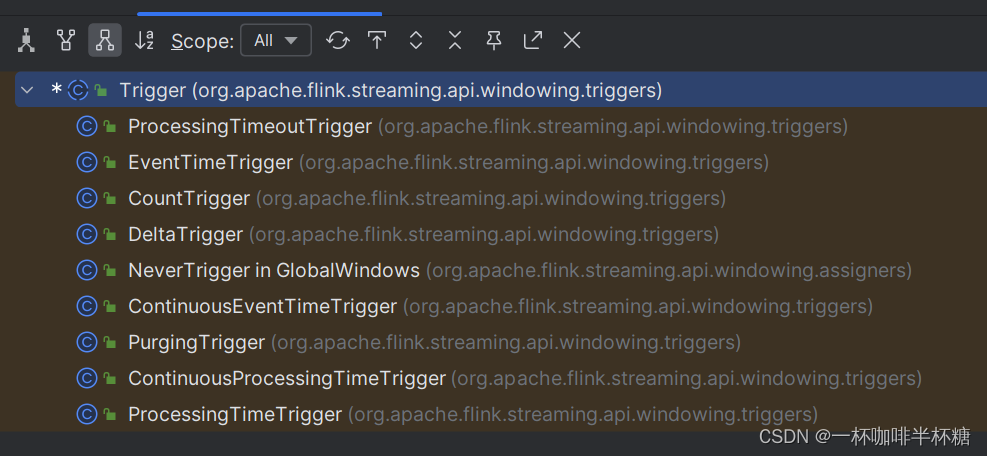
【Flink】Flink窗口触发器
数据进入到窗口的时候,窗口是否触发后续的计算由窗口触发器决定,每种类型的窗口都有对应的窗口触发机制。WindowAssigner 默认的 Trigger通常可解决大多数的情况。我们通常使用方式如下,调用trigger()方法把我们想执行触发器传递进去: SingleOutputStreamOperator<Produ…
0.flink学习资料
论文:
(1)google dataflow model
下载链接:p1792-Akidau.pdf (vldb.org)
Akidau T, Bradshaw R, Chambers C, et al. The dataflow model: a practical approach to balancing correctness, latency, and cost in massive-scal…
Flink主要知识点联系和全面总结
目录
1.Flink集群有哪些角色?各自有什么作用?
2.Flink TaskManager的内存管理
3.Flink 资源管理中 Slot、Task 和SubTask的概念

Flink 基本使用与公司级别使用经验总结
文章目录介绍流计算与批计算特性适用场景基本流程与程序写法DataStream 的主要转换操作KeyedStream 的理解stream 类型流转全图WaterMark 概念有界乱序事件下的 Watermark窗口计算多流合并操作Flink 类型系统理解 Flink 中的计算资源(task,jobmanage&…
Flink结合canal同步到Hbase
企业运维的数据库最常见的是mysql;但是mysql有个缺陷:当数据量达到千万条的时候,mysql的相关操作会变的非常迟缓;
如果这个时候有需求需要实时展示数据;对于mysql来说是一种灾难;而且对于mysql来说&#x…

Flink写入数据到ClickHouse
文章目录 1.ClickHouse建表1.ClickHouse依赖2.Bean实体类3.ClickHouse业务写入逻辑4.测试写入类5.发送数据 1.ClickHouse建表
ClickHouse中建表
CREATE TABLE default.test_write
(id UInt16,name String,age UInt16
) ENGINE TinyLog();1.ClickHouse依赖
Flink开发相关…
Flink动态ClickhouseSink+自动建表
通过自定义注解的形式,对JdbcSink进行封装,支持自动建表、自动拼接insert语句 主类
package cn.chinaunicom.sdsi.flink.security.sink;import cn.chinaunicom.sdsi.flink.security.anno.SecurityField;
import cn.chinaunicom.sdsi.flink.security.ann…
解决给Flink添加jdbc输出时的报错java.lang.VerifyError: Illegal type at constant pool entry
背景
今天在学习Flink的JDBC输出时,报了以下错误
java.lang.VerifyError: Illegal type at constant pool entry
解决方法
在富函数子类的invoke()和close()函数里,不要调用父类的空方法,也就是去掉super.invoke(value)和super.close()即…

Win10下flink任务的提交运行和取消
背景
最近开始抽空学习flink,这是一个实时流计算的框架
项目打包
先把任务项目打成jar包,在pom.xml文件里加入如下代码,添加打包插件 <plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plu…

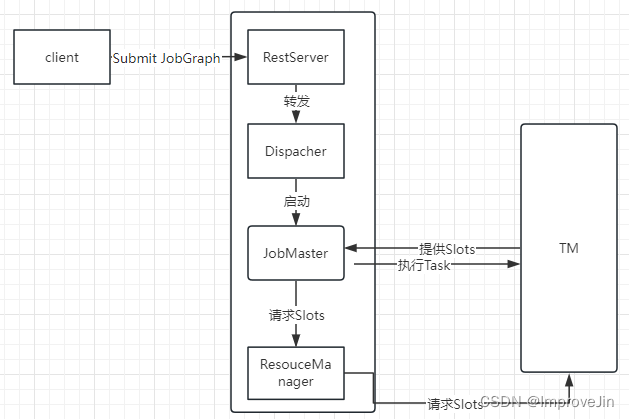
Flink源码之JobMaster启动流程
Flink中Graph转换流程如下: Flink Job提交时各种类型Graph转换流程中,JobGraph是Client端形成StreamGraph后经过Operator Chain优化后形成的,然后提交给JobManager的Restserver,最终转发给JobManager的Dispatcher处理。
Completa…
大数据-玩转数据-Flink RedisSink
一、添加Redis Connector依赖
具体版本根据实际情况确定
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-redis_2.11</artifactId><version>1.1.5</version>
</dependency>二、启动redis
参…


解密Flink的状态管理:探索流处理框架的数据保留之道,释放流处理的无限潜能!
水善利万物而不争,处众人之所恶,故几于道💦 文章目录 一、什么是状态二、应用场景三、Flink中状态的分类四、算子状态1. 列表状态(List State)2. 广播状态(Broadcast State) 五、键控状态1. Val…
Flink-----Standalone会话模式作业提交流程
1.Flink的Slot特点: 均分隔离内存,不隔离CPU可以共享:同一个job中,不同算子的子任务才可以共享同一个slot,同时在运行的前提是,属于同一个slot共享组,默认都是“default”2.Slot的数量 与 并行度 的关系 slot 是一种静态的概念,表示最大的并发上线并行度是个动态的概念…
关于flink-sql-connector-phoenix的重写逻辑
目录
重写意义
代码结构
调用链路
POM文件配置
代码解析
一、PhoenixJdbcDynamicTableFactory

flinksql实时统计程序背压延迟优化
问题:
flinkcdcflinksql做实时读取sls日志和实时统计业务指标,今天发现程序背压了,业务延迟了6个小时。解决办法:
1、资源优化
作业并发大时:在作业的高级配置的资源配置中,增加JobManager的资源…
大数据-玩转数据-Flink定时器
一、说明
基于处理时间或者事件时间处理过一个元素之后, 注册一个定时器, 然后指定的时间执行. Context和OnTimerContext所持有的TimerService对象拥有以下方法: currentProcessingTime(): Long 返回当前处理时间 currentWatermark(): Long 返回当前watermark的时间戳 registe…
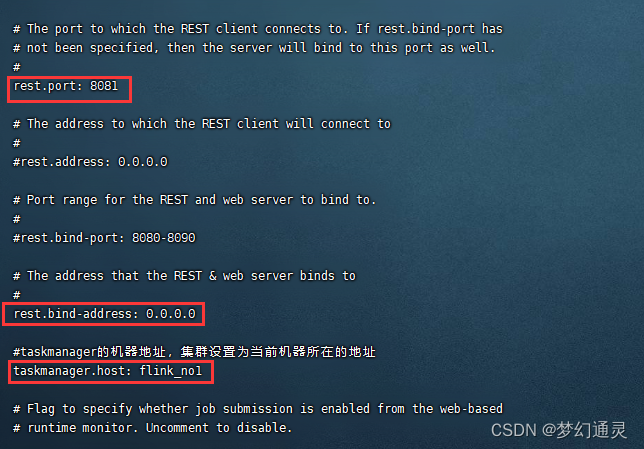
Flink的Standalone部署实战
在Flink是通用的框架,以混合和匹配的方式支持部署不同场景,而Standalone单机部署方便快速部署,记录本地部署过程,方便备查。
环境要求
1)JDK1.8及以上 2)flink-1.14.3 3)CentOS7
Flink相关信…
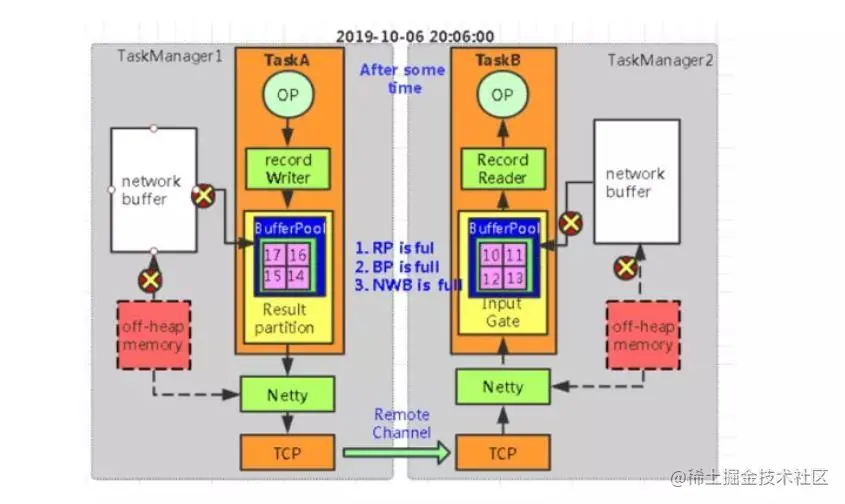
Flink 如何处理反压?
分析&回答
什么是反压(backpressure)
反压通常是从某个节点传导至数据源并降低数据源(比如 Kafka consumer)的摄入速率。反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而…
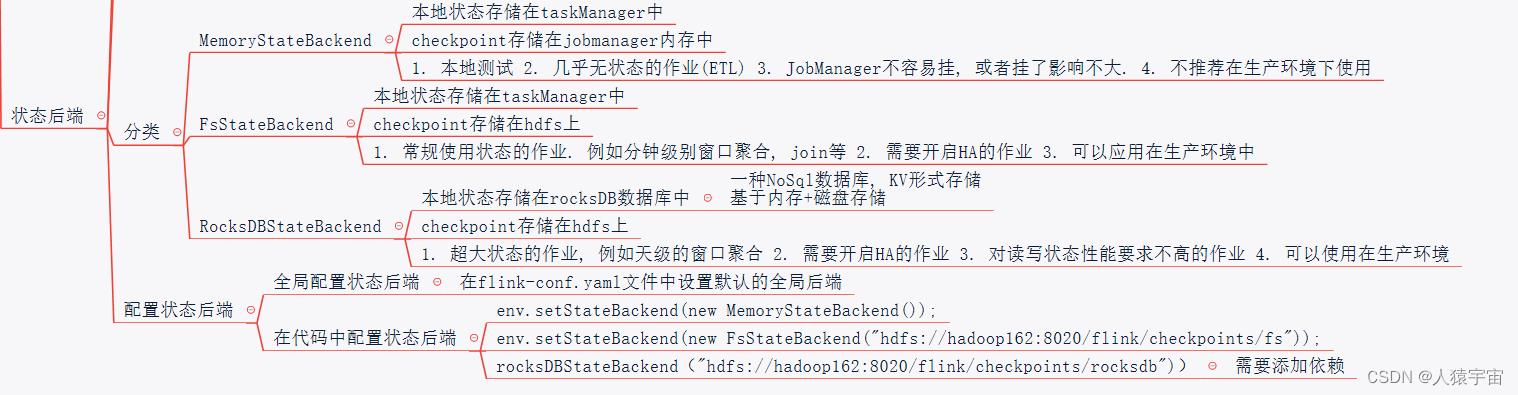
大数据-玩转数据-Flink状态编程(上)
一、Flink状态编程
有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。 SparkStreaming在状态管理这块做的不好, 很多时候需要借助于外部存储(例如Redis)来手动管理状态, 增加了编…
怎么理解flink的异步检查点机制
背景
flink的checkpoint监控页面那里有两个指标Sync Duration 和Async Duration,一个是开始进行同步checkpoint所需的时间,一个是异步checkpoint过程所需的时间,你是否也有过疑惑,是否只是同步过程中的时间才会阻塞正常的数据处理…
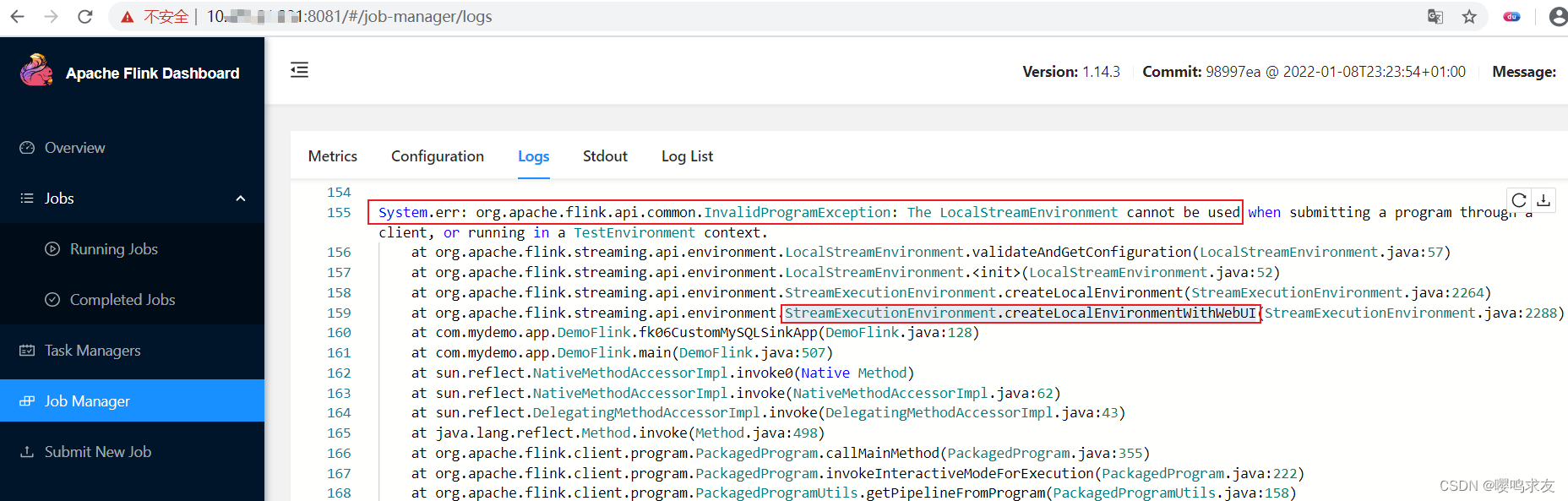
Flink提交jar出现错误RestHandlerException: No jobs included in application.
今天打包一个flink的maven工程为jar,通过flink webUI提交,发现居然报错。 如上图所示,提示错误为:
Server Response Message:
org.apache.flink.runtime.rest.handler.RestHandlerException: No jobs included in application. …
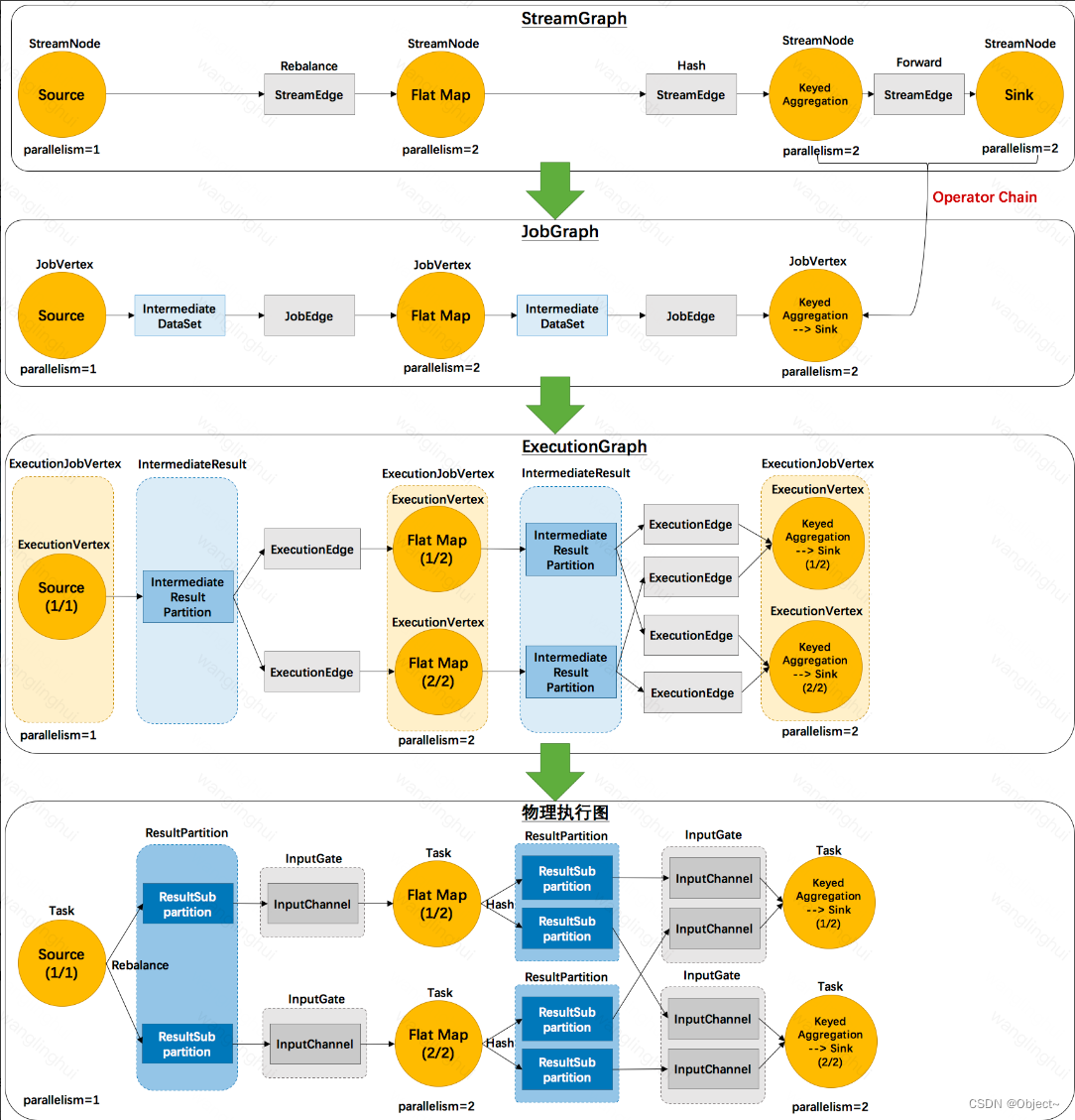
1.flink快速入门
前言
下图表示的是一个简单的flink-job的计算图,这种图被称为DAG(有向无环图),表示的这个任务的计算逻辑,无论是spark、hive、还是flink都会把用户的计算逻辑转换为这样的DAG,数据的计算按照DAG触发,理论上只要构建出…
大数据-玩转数据-Flink营销对账
一、说明
在电商网站中,订单的支付作为直接与营销收入挂钩的一环,在业务流程中非常重要。对于订单而言,为了正确控制业务流程,也为了增加用户的支付意愿,网站一般会设置一个支付失效时间,超过一段时间不支…
Flink的Standalone集群部署
在上篇进行单机的Standalone部署-Flink的Standalone部署实战,本篇介绍Flink的Standalone集群部署。 Flink集群为主从架构,主是JobManager,从为TaskManager,支持一主多从。 本次搭建环境为3台机器,信息如下表所示。
IP…
Flink Table API/SQL 多分支sink
背景
在某个场景中,需要从Kafka中获取数据,经过转换处理后,需要同时sink到多个输出源中(kafka、mysql、hologres)等。两次调用execute, 阿里云Flink vvr引擎报错:
public static void main(String[] args) {final StreamExecuti…

flink checkpoint时exact-one模式和atleastone模式的区别
背景:
flink在开启checkpoint的时候有两种模式可以选择,exact-one和atleastone模式,那么这两种模式有什么区别呢?
exact-one和atleastone模式的区别
先说结论:exact-one可以完全做到状态的一致性,而atle…
对比flink cdc和canal获取mysql binlog优缺点
Flink CDC和Canal都是用于获取MySQL binlog的工具,但是有以下几点优缺点对比:
Flink CDC是一个基于Flink的库,可以直接在Flink中使用,无需额外的组件或服务,而Canal是一个独立的服务,需要单独部署和运行&a…
flink cdc初始全量速度很慢原因和优化点
link cdc初始全量速度很慢的原因之一是,它需要先读取所有的数据,然后再写入到目标端,这样可以保证数据的一致性和顺序。但是这样也会导致数据的延迟和资源的浪费。flink cdc初始全量速度很慢的原因之二是,它使用了Debezium作为捕获…

206.Flink(一):flink概述,flink集群搭建,flink中执行任务,单节点、yarn运行模式,三种部署模式的具体实现
一、Flink概述
1.基本描述
Flink官网地址:Apache Flink — Stateful Computations over Data Streams | Apache Flink
Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。 2.有界流和无界流 无界流(流): 有定义流的开始,没有定义结束。会无休止…
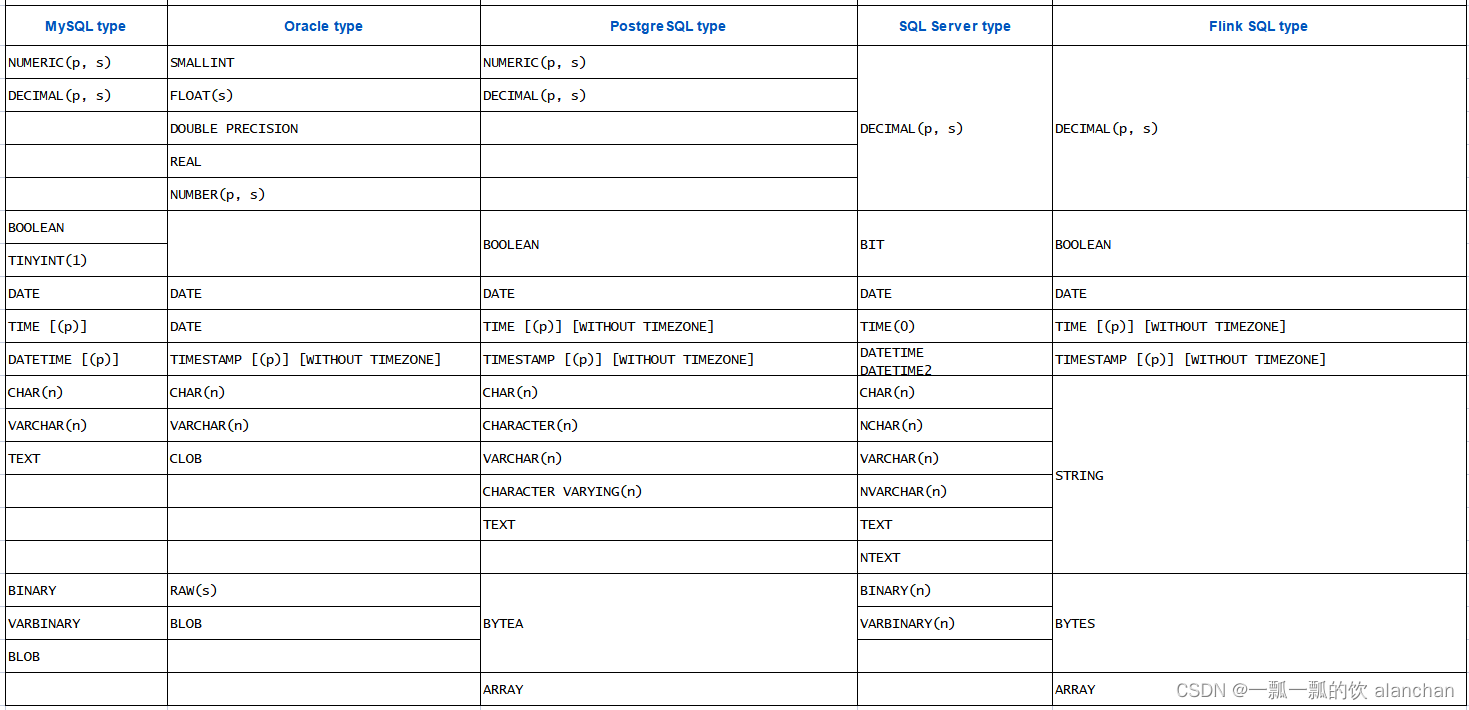
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
Flink安装与使用
1.安装准备工作
下载flink
Apache Flink: 下载 解压 [dodahost166 bigdata]$ tar -zxvf flink-1.12.0-bin-scala_2.11.tgz
2.Flinnk的standalone模式安装 2.1修改配置文件并启动
修改,好像使用默认的就可以了
[dodahost166 conf]$ more flink-conf.yaml
启动 …
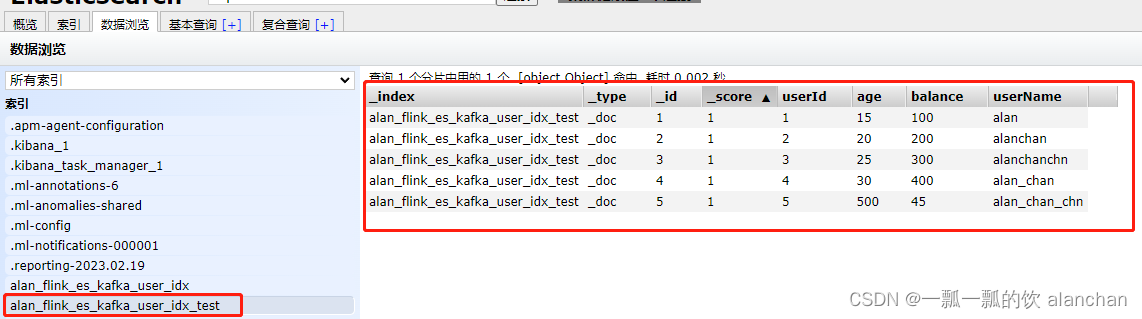
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
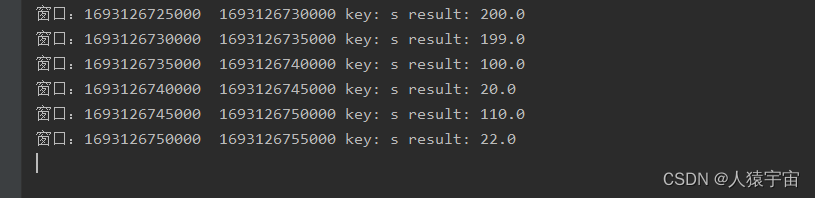
大数据-玩转数据-Flink窗口函数
一、Flink窗口函数
前面指定了窗口的分配器, 接着我们需要来指定如何计算, 这事由window function来负责. 一旦窗口关闭, window function 去计算处理窗口中的每个元素. window function 可以是ReduceFunction,AggregateFunction,or ProcessWindowFunction中的任意一种. Reduc…
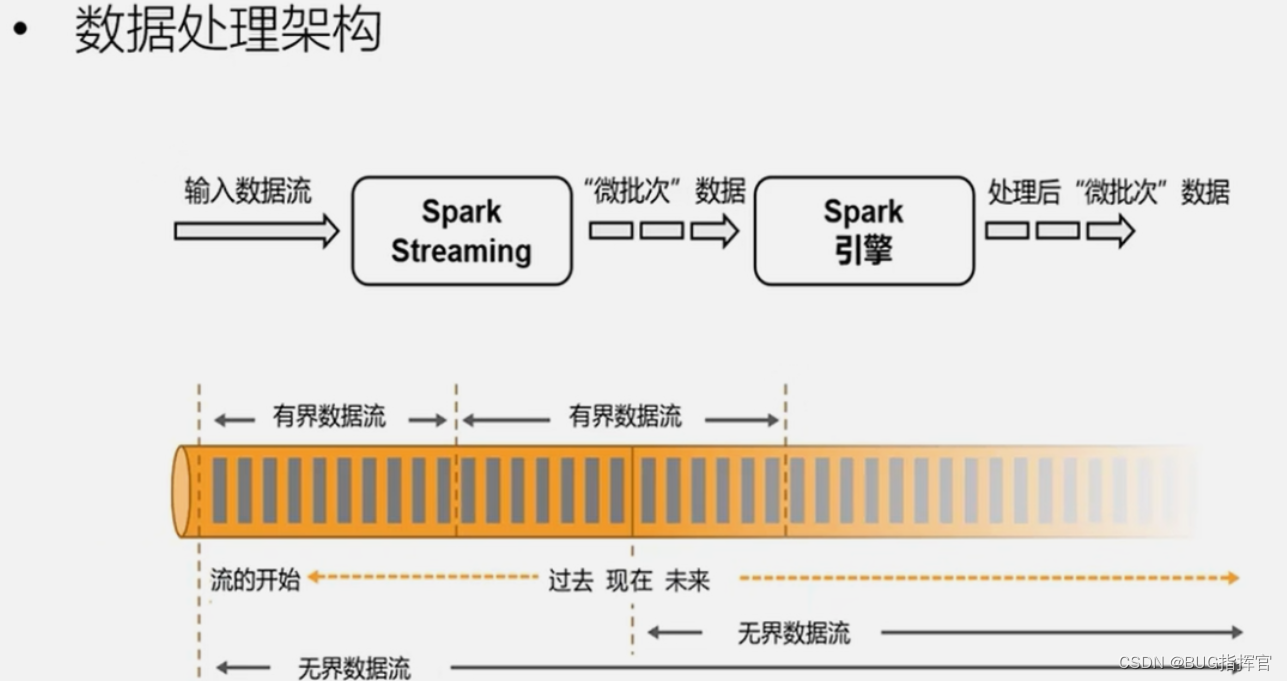
大数据Flink实时计算技术
1、架构 2、应用场景 Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。在启用高可用选项的情况下,它不存在单点失效问题。事实证明&#…
《Flink学习笔记》——第三章 Flink的部署模式
不同的应用场景,有时候对集群资源的分配和占用有不同的需求。所以Flink为各种场景提供了不同的部署模式。 3.1 部署模式(作业角度/通用分类)
根据集群的生命周期、资源的分配方式、main方法到底在哪里执行——客户端还是Client还是JobManage…
flink on yarn with kerberos 边缘提交
flink on yarn 带kerberos 远程提交 实现
flink kerberos 配置 先使用ugi进行一次认证正常提交
import com.google.common.io.Files;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.FileUtils;
import org.apache.flink.client.cli.CliFrontend;
import o…
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

美团 Flink 资源调度优化实践
摘要:本文整理自美团数据平台计算引擎组工程师冯斐,在 Flink Forward Asia 2022 生产实践专场的分享。本篇内容主要分为四个部分: 相关背景和问题解决思路分析资源调度优化实践后续规划 点击查看原文视频 & 演讲PPT 一、相关背景和问题 在…
flinkcdc同步完全量数据就不同步增量数据了
flinkcdc同步完全量数据就不同步增量数据了
使用flinkcdc同步mysql数据,使用的是全量采集模型 startupOptions(StartupOptions.earliest()) 全量阶段同步完成之后,发现并不开始同步增量数据,原因有以下两个:
原因1: …
对比Flink、Storm、Spark Streaming 的反压机制
分析&回答
Flink 反压机制
Flink 如何处理反压?
Storm 反压机制 Storm反压机制 Storm 在每一个 Bolt 都会有一个监测反压的线程(Backpressure Thread),这个线程一但检测到 Bolt 里的接收队列(recv queue)出现了…

说说FLINK细粒度滑动窗口如何处理
分析&回答
Flink的窗口机制是其底层核心之一,也是高效流处理的关键。Flink窗口分配的基类是WindowAssigner抽象类,下面的类图示出了Flink能够提供的所有窗口类型。 Flink窗口分为滚动(tumbling)、滑动(sliding&am…

说说Flink运行模式
分析&回答
1.开发者模式 在idea中运行Flink程序的方式就是开发模式。
2.local-cluster模式 Flink中的Local-cluster(本地集群)模式,单节点运行,主要用于测试, 学习。
3.Standalone模式 独立集群模式,由Flink自身提供计算资源。
4.Yarn模式
把Fl…
Apache Hudi初探(三)(与flink的结合)--flink写hudi的操作(真正的写数据)
背景
在之前的文章中Apache Hudi初探(二)(与flink的结合)–flink写hudi的操作(JobManager端的提交操作) 有说到写hudi数据会涉及到写hudi真实数据以及写hudi元数据,这篇文章来说一下具体的实现
写hudi真实数据
这里的操作就是在HoodieFlinkWriteClient.upsert方法:
public …
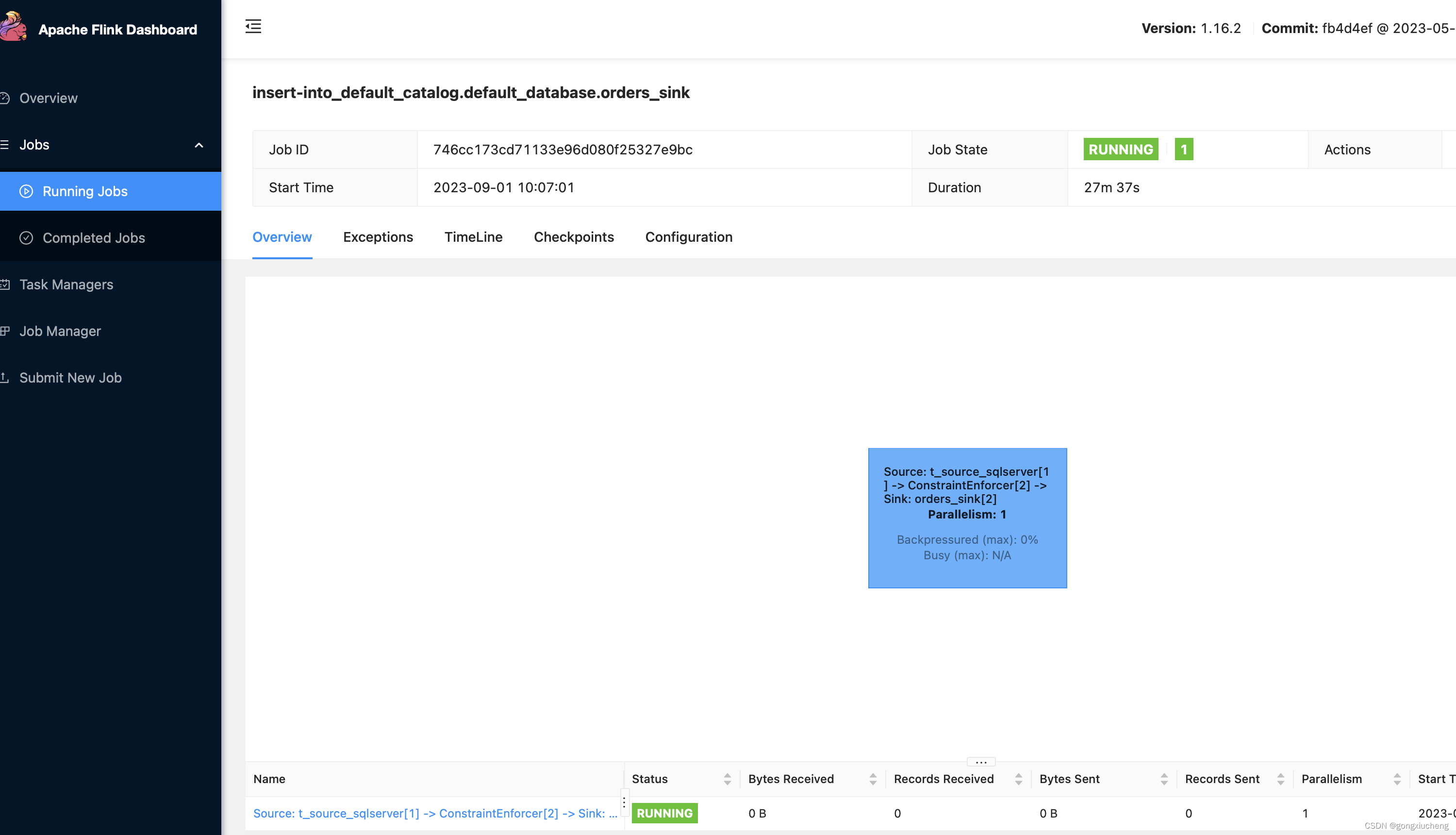
使用flink sqlserver cdc 同步数据到StarRocks
前沿: flink cdc功能越发强大,支持的数据源也越多,本篇介绍使用flink cdc实现:
sqlserver-》(using flink cdc)-〉flink -》(using flink starrocks connector)-〉starrocks整个流程…
Flink-----Yarn应用模式作业提交流程
Yarn应用模式作业提交流程
在Yarn当中又分为Session,PerJob,Application,建议和推荐使用独立集群的,其中就包含PerJob 和Application,但是1.17版本的Flink已将PerJob标记为过时,并且Application可以解决PerJob的一些痛点,减轻客户端的一些压力,所以需要重点了解Yarn应…
Flink 流式读写文件、文件夹
文章目录 一、flink 流式读取文件夹、文件二、flink 写入文件系统——StreamFileSink三、查看完整代码 一、flink 流式读取文件夹、文件
Apache Flink针对文件系统实现了一个可重置的source连接器,将文件看作流来读取数据。如下面的例子所示: StreamExe…
AppenderLoggingException:
ERROR An exception occurred processing Appender MainAppenderorg.apache.logging.log4j.core.appender.AppenderLoggingException:java.lang0utOfMemoryError: Metaspace
chat回答
该错误是由于 Java 的 Metaspace(元空间)耗尽导致的 OutOfMemoryEr…
【跟小嘉学 Apache Flink】二、Flink 快速上手
系列文章目录
【跟小嘉学 Apache Flink】一、Apache Flink 介绍 【跟小嘉学 Apache Flink】二、Flink 快速上手 文章目录 系列文章目录[TOC](文章目录) 一、创建工程1.1、创建 Maven 工程1.2、log4j 配置 二、批处理单词统计(DataSet API)2.1、创建 Bat…

Flink CDC-SQL Server CDC配置及DataStream API实现代码...可实现监控采集一个数据库的多个表
文章目录 SQL Server CDC配置第一步:启用指定数据库的CDC功能第二步:创建数据库角色第三步:创建文件组&文件第四步:启用指定表的CDC功能 SQLServer CDC DataStream API实现1. 定义SqlServerSource2. 数据处理3. Sink到MySQL 参…
flink k8s sink到kafka报错 Failed to get metadata for topics
可能出现的3种报错
-- 报错1
Failed to get metadata for topics [...].
org.apache.kafka.common.errors.TimeoutException: Call-- 报错2
Caused by: org.apache.kafka.common.errors.TimeoutException: Timed out waiting to send the call. Call: fetchMetadata
Heartbe…

【Flink】关于jvm元空间溢出,mysql binlog冲突的问题解决
问题一:7张表是同一个mysql中的,我们进行增量同步时分别用不同的flink任务读取,造成mysql server-id冲突问题,如下: Caused by: io.debezium.DebeziumException: A slave with the same server_uuid/server_id as this…
基于 Flink CDC 构建 MySQL 和 Postgres 的 Streaming ETL
官方网址:https://ververica.github.io/flink-cdc-connectors/release-2.3/content/%E5%BF%AB%E9%80%9F%E4%B8%8A%E6%89%8B/mysql-postgres-tutorial-zh.html官方教程有些坑,经过自己实测,记录个笔记。
服务器环境:
VM虚拟机&am…

大数据Flink(七十三):SQL的滚动窗口(TUMBLE)
文章目录
SQL的滚动窗口(TUMBLE) SQL的滚动窗口(TUMBLE)
滚动窗口定义:滚动窗口将每个元素指定给指定窗口大小的窗口。滚动窗口具有固定大小,且不重叠。例如,指定一个大小为 5 分钟的滚动窗口。在这种情况下,Flink 将每隔 5 分钟开启一个新的窗口,其中每一条数都会划…
使用IntelliJ IDEA本地启动调试Flink流计算工程的2个异常解决
记录:471
场景:使用IntelliJ IDEA本地启动调试Flink流计算时,报错一:加载DataStream报错java.lang.ClassNotFoundException。报错二:No ExecutorFactory found to execute the application。
版本:JDK 1.…
macos13 arm芯片(m2) 搭建hbase docker容器 并用flink通过自定义richSinkFunction写入数据到hbase
搭建hbase docker容器
下载镜像 https://hub.docker.com/r/satoshiyamamoto/hbase/tags 点击run 使用镜像新建容器 填写容器名和 容器与宿主机的端口映射 测试 通过宿主机访问容器内的hbase webUI
http://localhost:60010/master-status
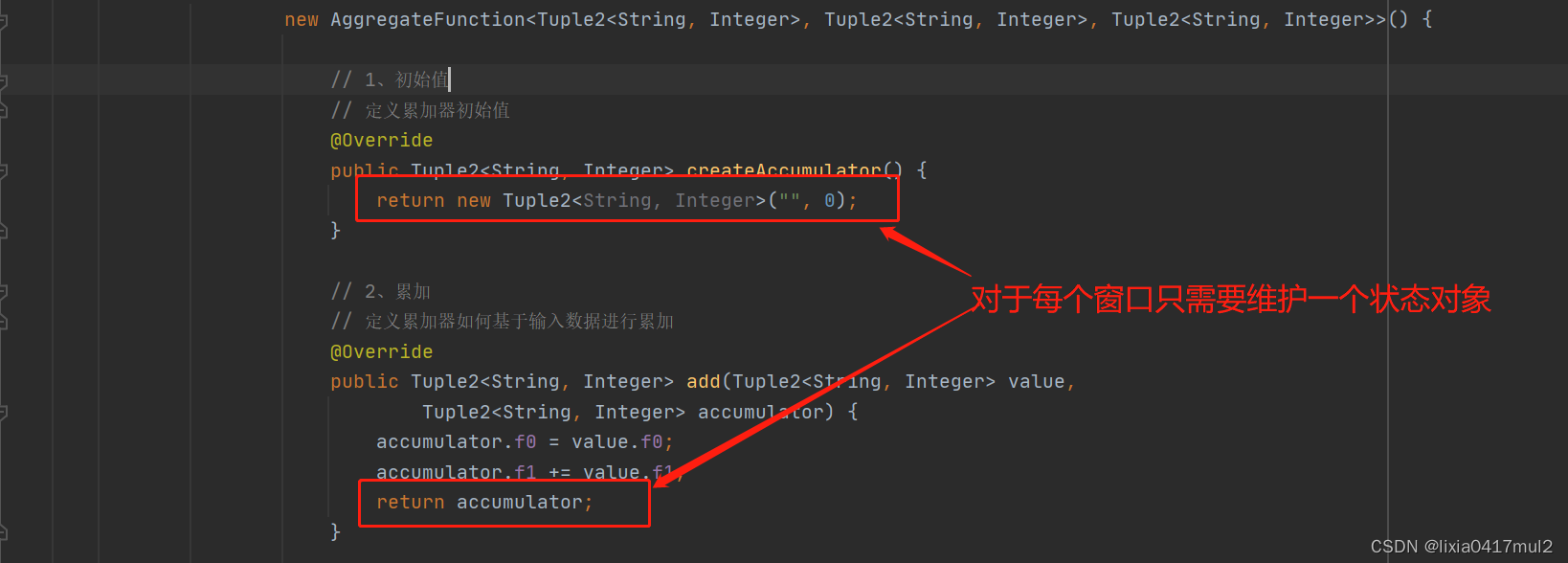
AggregateFunction结合自定义触发器实现点击率计算
背景:
接上一篇文章,ProcessWindowFunction 结合自定义触发器会有状态过大的问题,本文就使用AggregateFunction结合自定义触发器来实现,这样就不会导致状态过大的问题了
AggregateFunction结合自定义触发器实现 flink对于每个窗…
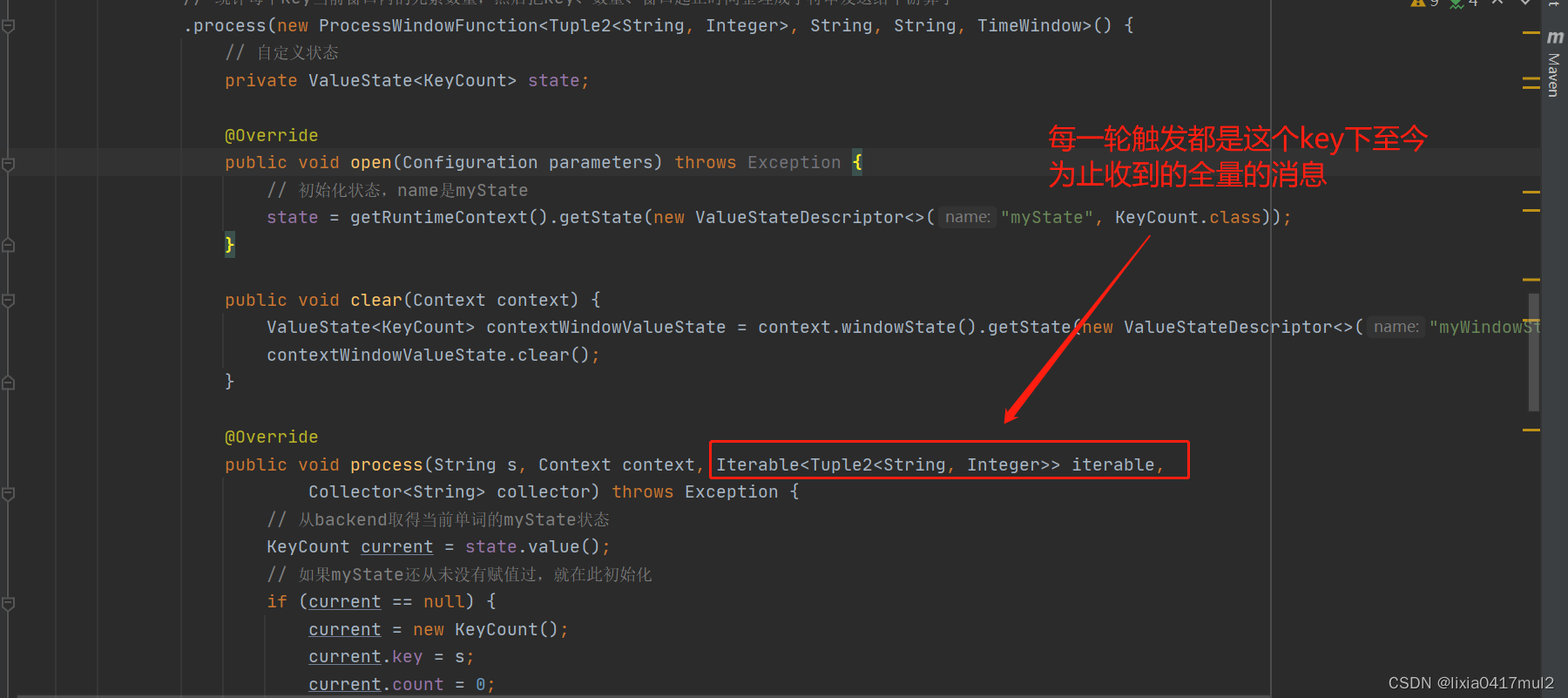
ProcessWindowFunction 结合自定义触发器的陷阱
背景:
flink中常见的需求如下:统计某个页面一天内的点击率,每10秒输出一次,我们如果采用ProcessWindowFunction 结合自定义触发器如何实现呢?如果这样实现问题是什么呢?
ProcessWindowFunction 结合自定义触发器实现…

44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例--网上有些说法好像是错误的
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
FlinkCDC 菜鸟教程
系列文章目录
背景篇
环境篇 准备一台已经安装了 Docker 的 Linux 或者 MacOS 电脑。准备教程所需要的组件版本对应关系安装环境检查
工具篇
flinkkibana
概念篇
Docker 介 绍Docker Compose 介 绍Kibana介 绍
实践篇
演示: Mysql CDC 导入 Elasticsearch
启动服务准备…
FlinkCDC 菜鸟教程-文章目录
系列文章目录
背景篇
环境篇 准备一台已经安装了 Docker 的 Linux 或者 MacOS 电脑。准备教程所需要的组件版本对应关系安装环境检查
工具篇
flinkkibana
概念篇
Docker 介 绍Docker Compose 介 绍Kibana介 绍
实践篇
演示: Mysql CDC 导入 Elasticsearch
启动服务准备…
Flink报错处理-1
在 flink job 运行一段时间后,观察日志发现出现了如下的 warn日志:
The operator name {} exceeded the {} characters length limit and was truncated
完整的 warn 日志如下: The operator name TriggerWindow(GlobalWindows(), ListStat…

【大数据】基于 Flink CDC 高效构建入湖通道
基于 Flink CDC 高效构建入湖通道 1.Flink CDC 核心技术解析2.CDC 数据入湖入仓的挑战2.1 CDC 数据入湖架构2.2 CDC 数据 ETL 架构 3.基于 Flink CDC 的入湖入仓方案3.1 Flink CDC 入湖入仓架构3.2 Flink CDC ETL 分析3.3 存储友好的写入设计3.4 Flink CDC 实现异构数据源集成3…

flink的物理DataFlow图及Slot处理槽任务分配
背景
在flink中,有几个比较重要的概念,逻辑DataFlow图,物理DataFlow图以及处理槽执行任务,本文就来讲解下这几个概念
概念详解
假设有以下代码:数据源和统计单词算子的并行度是2,数据汇算子的并行度是1&…

flink 端到端一致性
背景
我们经常会混淆flink提供的状态一致性保证和数据端到端一致性保证的关系,总以为他们表达的是同一个意思,事实上,他们不是一个含义,flink只能保证其维护的内部状态的一致性,而数据端到端的一致性需要数据源&#…
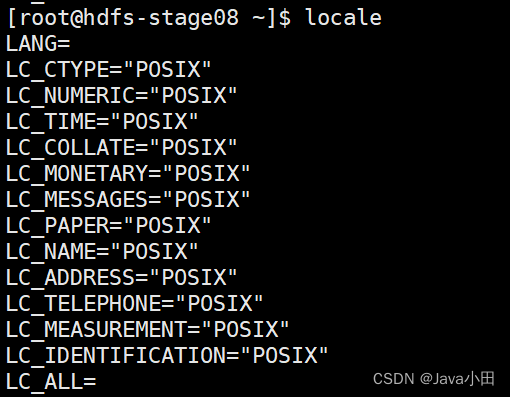
flink on yarn任务中文乱码问题解决记录
开发反馈预生产部分部分flink任务出现中文乱码的问题
找到乱码的flink任务所在的节点,登录服务器,执行locale命令: 发现是locale没有设置好,使用vim编辑文本,写入中文都直接乱码
对比其他几台机器,发现主…
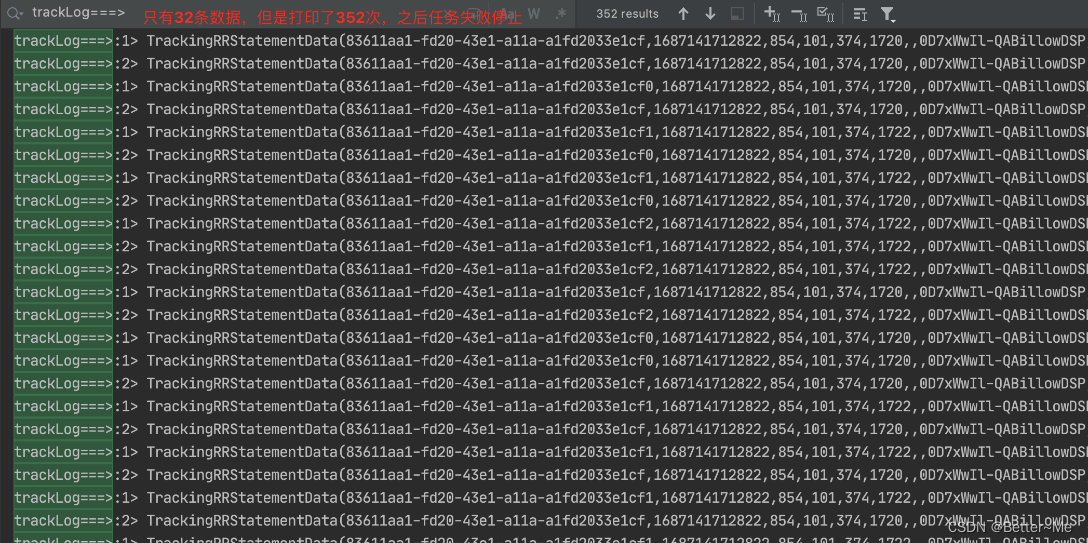
Idea本地跑flink任务时,总是重复消费kafka的数据(kafka->mysql)
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Idea中执行任务时,没法看到JobManager的错误,以至于我以为是什么特殊的原因导致任务总是反复消费。在close方法中,增加日志,发现jdbc连接被关闭了。 重新…
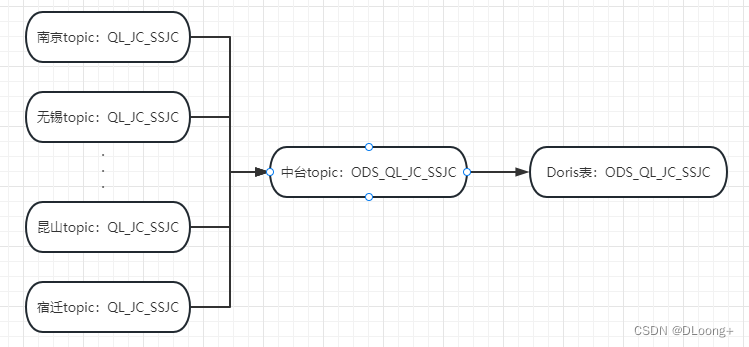
Flink实现kafka到kafka、kafka到doris的精准一次消费
1 流程图 2 Flink来源表建模
--来源-城市topic
CREATE TABLE NJ_QL_JC_SSJC_SOURCE (
record string
) WITH (connector = kafka,topic = QL_JC_SSJC,properties.bootstrap.servers = 172.*.*.*:9092,properties.group.id = QL_JC_SSJC_NJ_QL_JC_SSJC_SOURCE,scan.startup.mo…
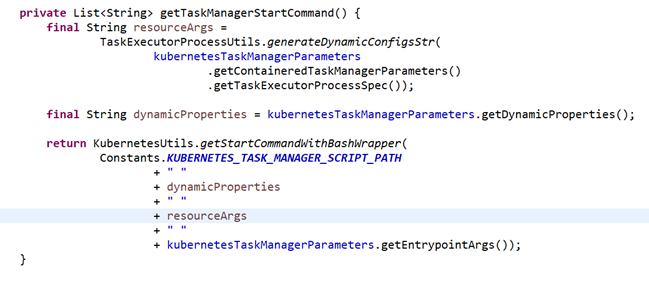
弹性资源组件elastic-resource设计(二)-集群
简介 弹性资源组件提供动态资源能力,是分布式系统关键基础设施,分布式datax,分布式索引,事件引擎都需要集群和资源的弹性资源能力,提高伸缩性和作业处理能力。 本文介绍弹性资源组件的设计,包括架构设计和详…
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

Hudi第三章:集成Flink
系列文章目录
Hudi第一章:编译安装 Hudi第二章:集成Spark Hudi第二章:集成Spark(二) Hudi第三章:集成Flink 文章目录 系列文章目录前言一、环境准备1.上传并解压2.修改配置文件3.拷贝jar包4.启动sql-client1.启动hadoop2.启动ses…
【Flink实战系列】Hash collision on user-specified ID “Kafka Source”
Hash collision on user-specified ID “Kafka Source”
在使用 fromSource 构建 Kafka Source 的时候,遇到下面的报错,下面就走进源码,分析一下原因。
Exception in thread "main" java.lang.IllegalArgumentException: Hash collision on user-specified ID &…
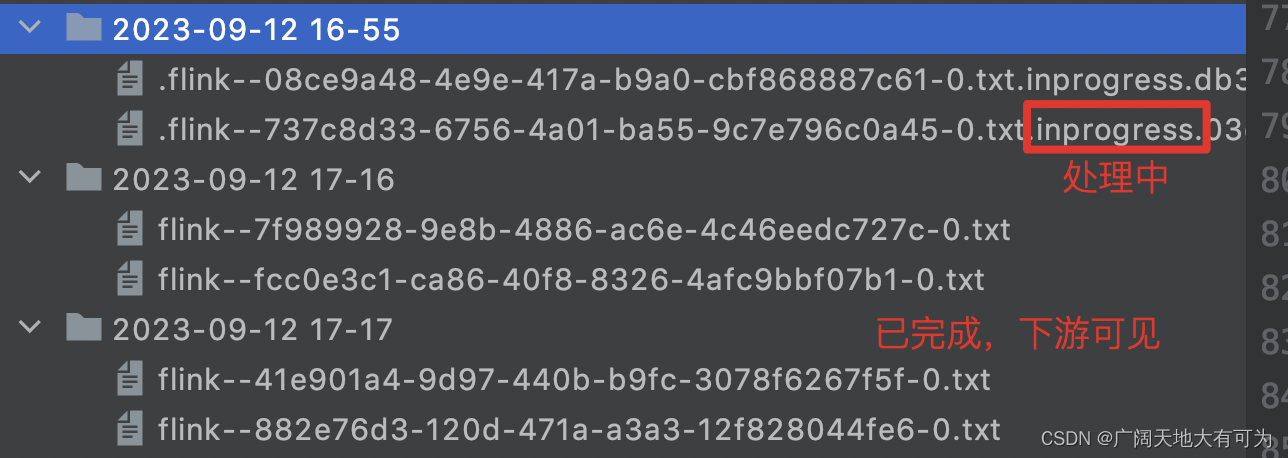
6.1、Flink数据写入到文件
1、前言
Flink API 提供了FileSink连接器,来帮助我们将数据写出到文件系统中去
版本说明:java1.8、flink1.17
官网链接:官网 2、Format Types - 指定文件格式
FileSink 支持 Row-encoded 、Bulk-encoded 两种格式写入文件系统 Row-encode…
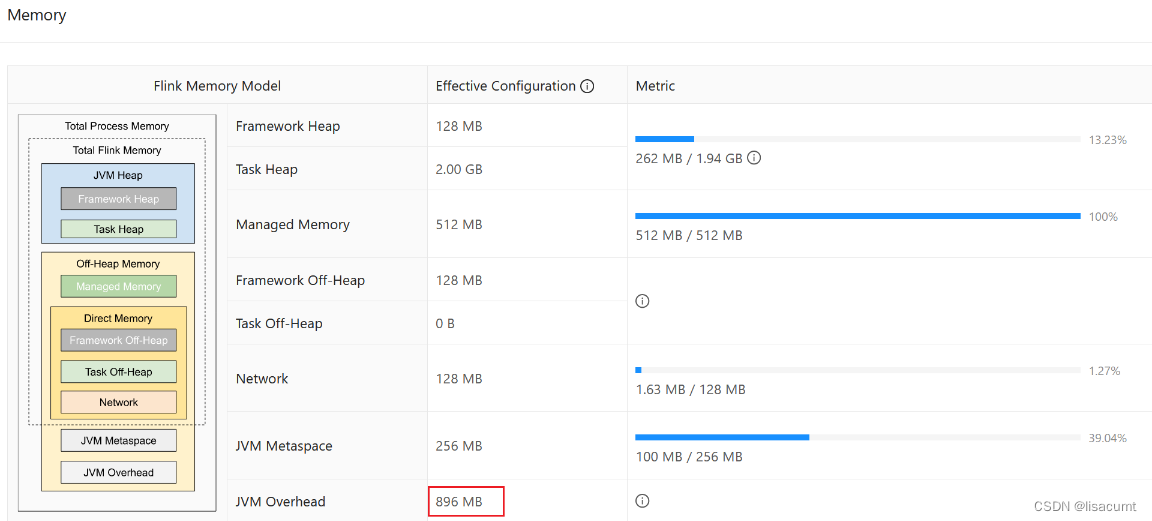
Flink TaskManger 内存计算实战
Flink TaskManager内存计算图 计算实例
案例一、假设Task Process内存4GB。
taskmanager.memory.process.size4096m 先排减JVM内存。
JVM Metaspace 固定内存 256mJVM Overhead 固定比例 process * 0.1 4096 * 0.1 410m 得到 Total Flink Memory 4096-256-410 3430m
计…
测试 Apache Flink SQL 代码
测试 Apache Flink SQL 代码是确保应用程序顺利运行并提供预期结果的关键步骤。 Flink SQL 应用程序用于广泛的数据处理任务,从复杂的分析到简单的 SQL 作业。全面的测试流程可以帮助您在开发过程的早期发现潜在问题,并确保您的应用程序按预期工作。 这篇…

flink集群与资源@k8s源码分析-资源III 声明式资源管理
1 资源
资源分析分3部分,资源请求,资源提供,声明式资源管理,本文是第三部分声明式资源管理
2 检查资源需求/检查资源声明
检查资源需求/检查资源声明是flink声明式资源管理的核心方法
上面的资源场景分为两类,提出资源需求和提供资源, 检查资源请求/检查资源声明是交…
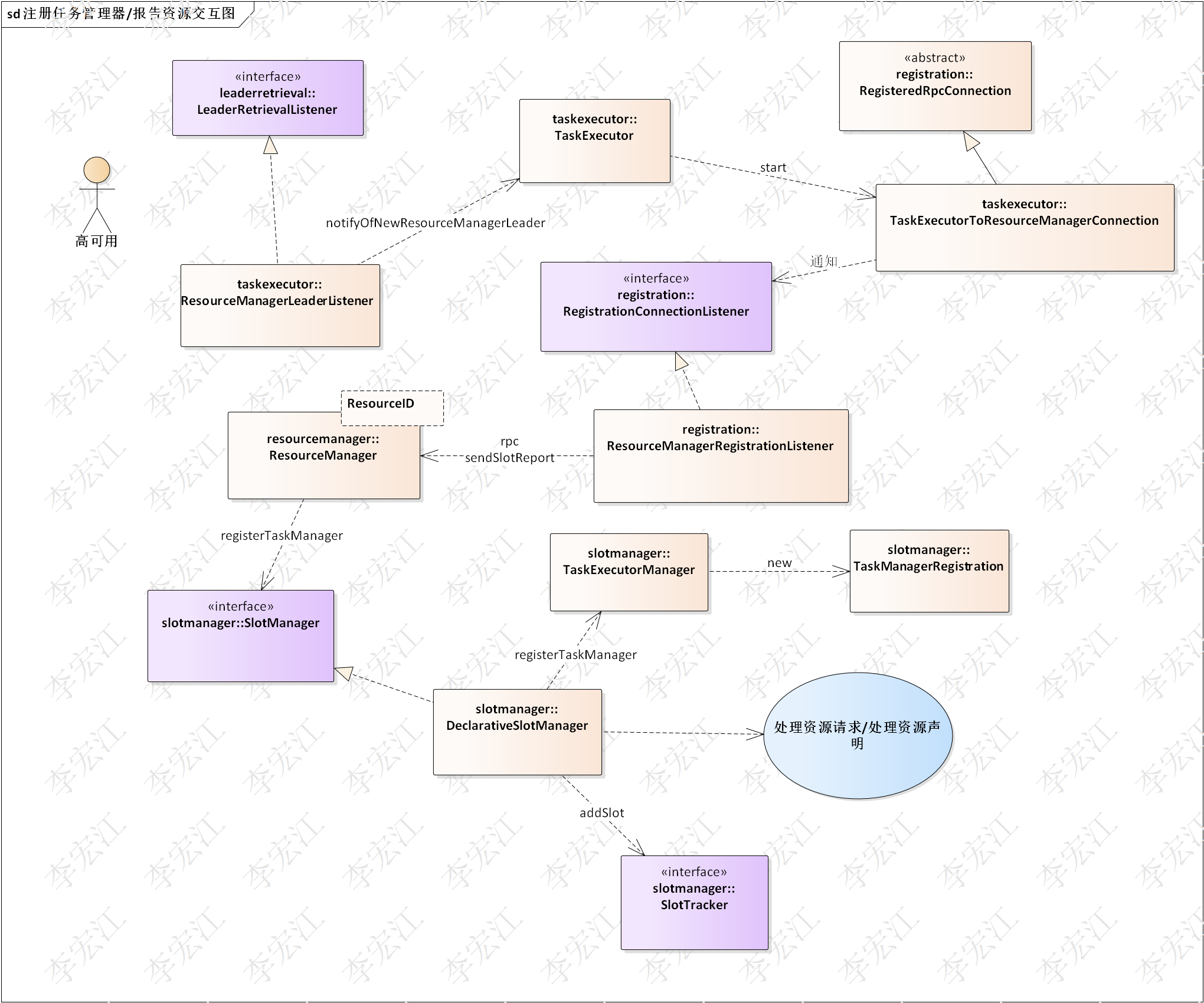
flink集群与资源@k8s源码分析-资源II 资源提供
1 资源
资源分析分3部分,资源请求,资源提供,声明式资源管理,本文是第二部分资源提供
2 注册任务管理器/报告资源
任务管理器启动后注册到资源管理器,报告自身资源,资源通过这个方式新增的 1. 任务管理器启动,同时启动高可用组件,触发 ResourceManagerLeaderListener…
flink以增量+全量的方式更新广播状态
背景
flink在实现本地内存和db同步配置表信息时,想要做到类似于增量(保证实时性) 全量(保证和DB数据一致)的效果,那么我们如何通过flink的广播状态外部定时器定时全量同步的方式来实现呢?
实现增量全量的效果
package wikiedits.schedule…
JNA封装C/C++动态库在flink内使用记录
概述
因为公司业务需求,需要将一部分原本已经用C/C写好的程序封装到flink内部使用。
操作系统
CentOS 7使用的技术和工具
flink 1.17.1
JDK 19.0.2
JNA 5.12.1
maven 3.9.4技术实现
利用JNA将C/C的程序封装到JAR包里面,然后结合flink依赖࿰…
Flink--4、DateStream API(执行环境、源算子、基本转换算子)
星光下的赶路人star的个人主页 注意力的集中,意象的孤立绝缘,便是美感的态度的最大特点 文章目录 1、DataStream API1.1 执行环境(Execution Environment)1.1.1 创建执行环境 1.2 执行模式(Execution Mode)…
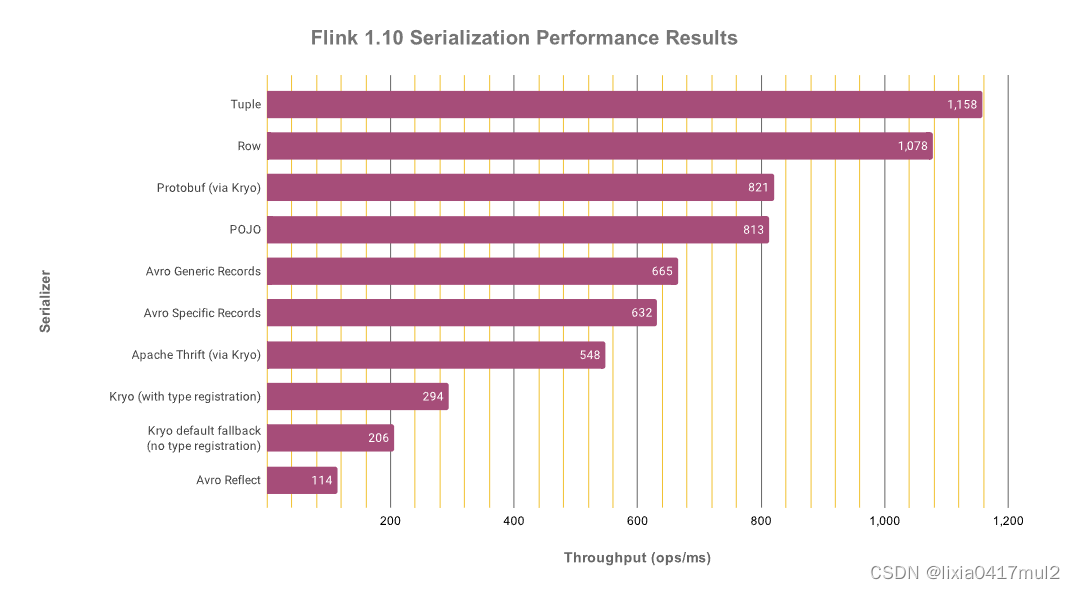
flink中不同序列化器性能对比
背景
flink有多种序列化方式,包括flink内置的以及fallback到kryo的,那么他们之间有多大的性能差距呢,本文就从https://flink.apache.org/2020/04/15/flink-serialization-tuning-vol.-1-choosing-your-serializer-if-you-can/这篇文章里摘录…
flink使用kryo支持自定义的序列化器
背景
这里所说的序列化器不是指实现TypeSerializer的状态序列化器,而是指flink在使用KryoSerializer序列化器时遇到kryo无法序列化的类型时,通过往kryo中注册某个序列化器类来让kryo可以序列化某个类的实例,所以这里严格意义上应该是说&…
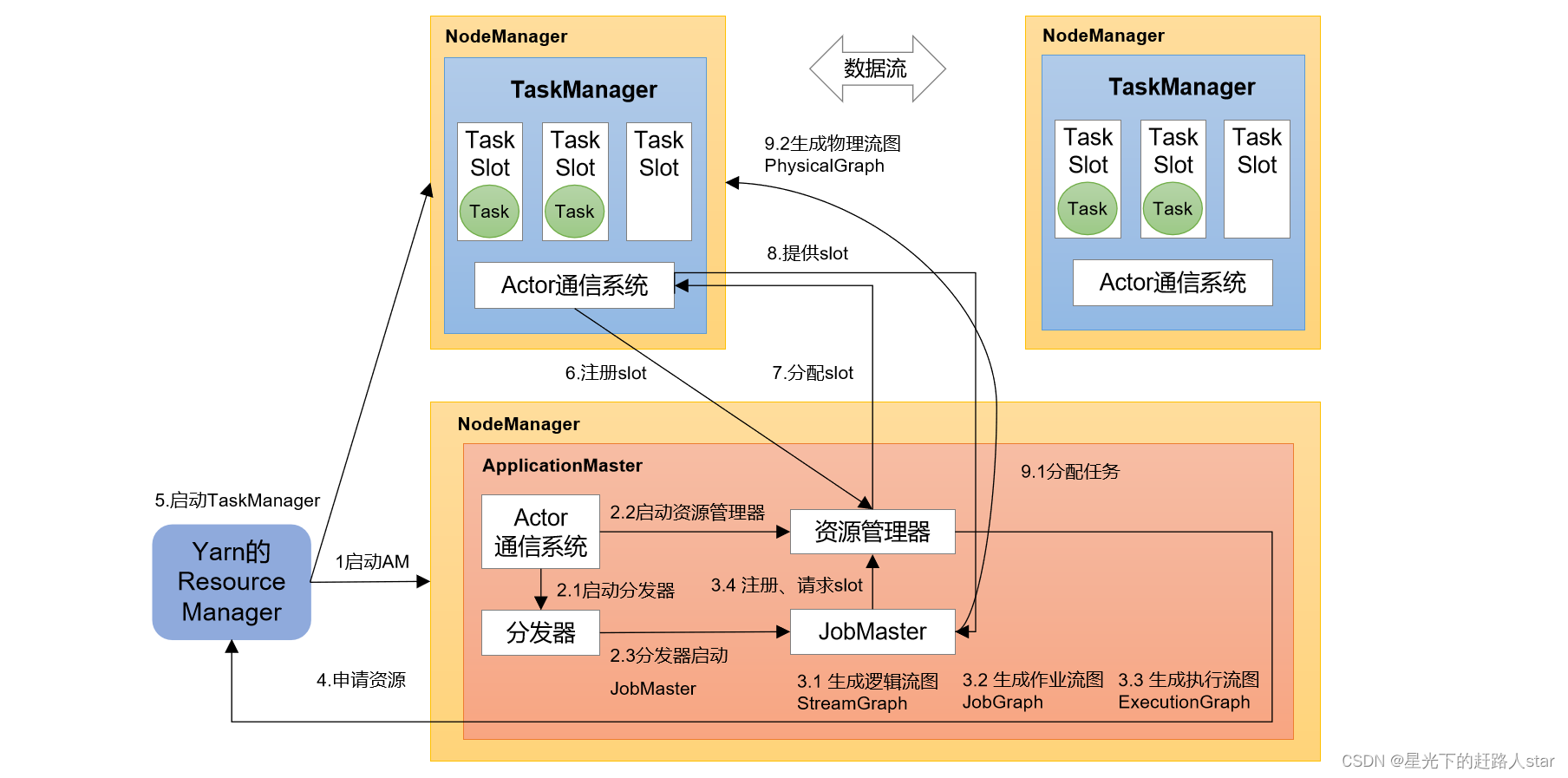
Fink--3、Flink运行时架构(并行度、算子链、任务槽、作业提交流程)
1、系统架构(以Standalone会话模式为例) 1、作业管理器(JobManager) JobManager是一个Flink集群中任务管理和调度的核心,是控制应用执行的主进程。也就是说,每个应用都应该被唯一的JobManager所控制执行。 …
Flink1.12.7 Standalone版本安装
官网下载版本:https://archive.apache.org/dist/flink/flink-1.12.7/flink-1.12.7-bin-scala_2.12.tgz
可以从首页找到Downloads | Apache Flink,一直往下拉 安装:下载后直接解压即可
添加全局参数:
#vi /etc/profile
FLINK_HO…

Flink的部署模式:Local模式、Standalone模式、Flink On Yarn模式
Flink常见的部署模式 Flink部署、执行模式Flink的部署模式Flink的执行模式 Local本地模式下载安装启动、停止Flink提交测试任务停止作业 Standalone独立模式会话模式单作业模式应用模式 YARN运行模式会话模式启动Hadoop集群申请一个YARN会话查看Yarn、Flink提交作业查看、测试作…
Flink CDC MySQL同步MySQL错误记录
1、启动 Flink SQL
[appuserwhtpjfscpt01 flink-1.17.1]$ bin/sql-client.sh2、新建源表
问题1:Encountered “(” 处理方法:去掉int(11),改为int
Flink SQL> CREATE TABLE t_user (
> uid int(11) NOT NULL AUTO_INCREMENT COMME…
Flink--6、输出算子(连接到外部系统、文件、kafka、MySQL、自定义Sink)
星光下的赶路人star的个人主页 世间真正温煦的春色,都熨帖着大地,潜伏在深谷 文章目录 1、输出算子(Sink)1.1 连接到外部系统1.2 输出到文件1.3 输出到Kafka1.4 输出到MySQL(JDBC)1.4 自定义Sink输出 1、输…
hadoop.ipc:Client
org.apache.hadoop.ipc:Client []- Failed to connect towgqccbsun07/172.29.100.147:8032:server:retries get failed due to exceeded maximum allowed retries number:参考YARN 切换ResourceManager(Failed to connect to server:8032 retries get failed due to…
flink生成水位线记录方式--基于特殊记录的水位线生成器
背景
在flink基于事件的时间处理中,水位线记录的生成是一个很重要的环节,本文就来记录下几种水位线记录的生成方式的其中一种:基于特殊记录的水位线生成器
基于特殊记录的水位线生成器
我们发送的事件中,如果带有某条特殊记录的…

Flink中序列化RoaringBitmap不同方式的对比
背景
在flink中,我们有时候会使用到RoaringBitmap进行统计计数等操作,而当使用RoaringBitmap时,这就涉及到了最重要的问题,如何序列化?序列化的目的是为了进行网络通信或者状态序列化的目的,本文的重点是比…
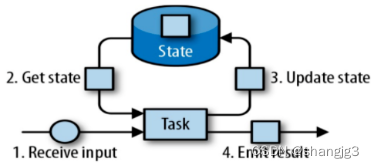
Flink状态管理与检查点机制
1.状态分类 相对于其他流计算框架,Flink 一个比较重要的特性就是其支持有状态计算。即你可以将中间的计算结果进行保存,并提供给后续的计算使用: 具体而言,Flink 又将状态 (State) 分为 Keyed State 与 Operator State: 1.1 算子状态 算子状态 (Operator State):顾名思义…
Flink Data Transformation
1.Transformations 分类 Flink 的 Transformations 操作主要用于将一个和多个 DataStream 按需转换成新的 DataStream。它主要分为以下三类: DataStream Transformations:进行数据流相关转换操作; Physical partitioning:物理分区。Flink 提供的底层 API ,允许用户定义数据…
Hudi SQL DDL
本文介绍Hudi在 Spark 和 Flink 中使用SQL创建和更改表的支持。 1.Spark SQL 创建hudi表 1.1 创建非分区表 使用标准CREATE TABLE语法创建表,该语法支持分区和传递表属性。 CREATE TABLE [IF NOT EXISTS] [db_name.]table_name[(col_name data_type [COMMENT col_comment], ..…
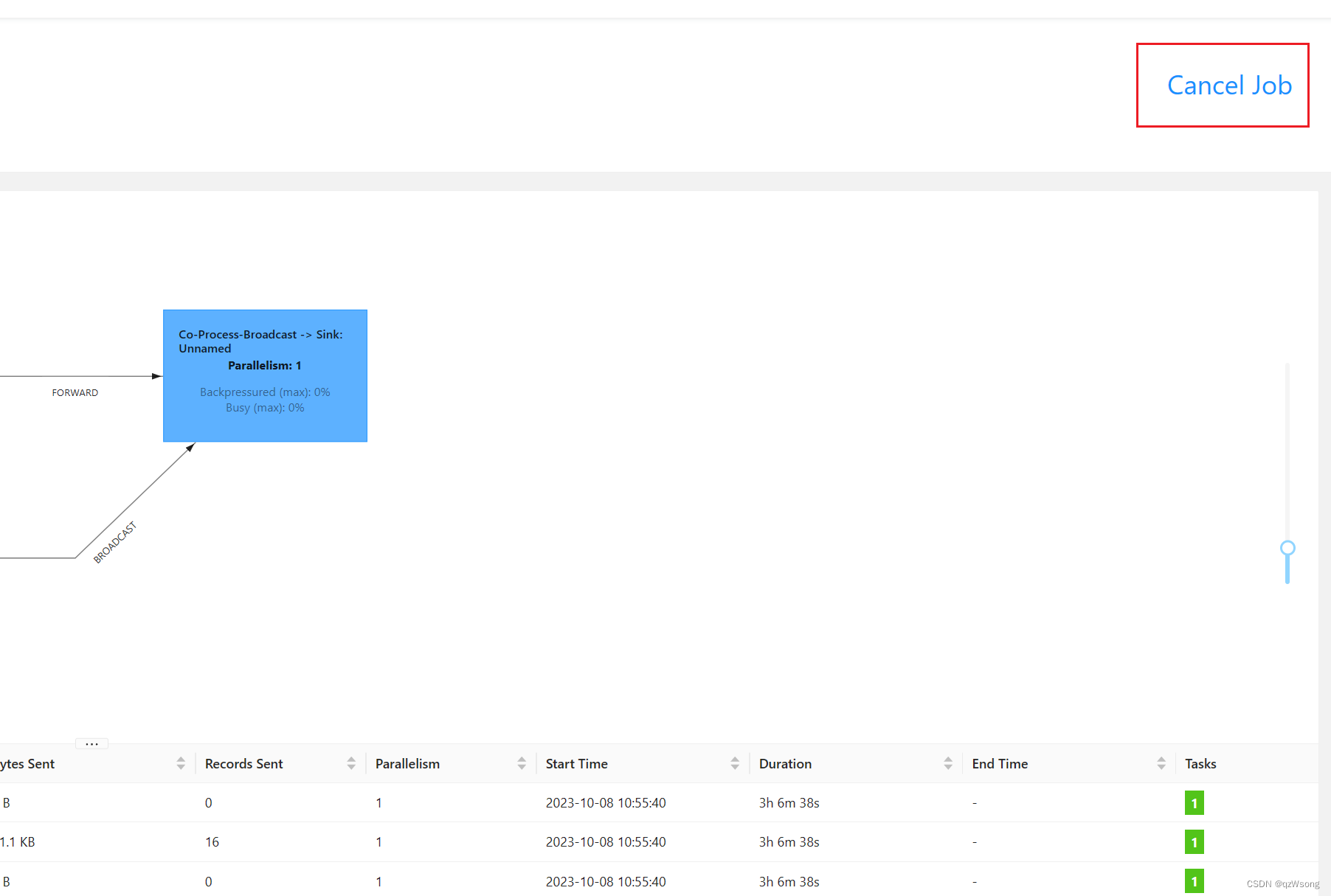
关于flink重新提交任务,重复消费kafka的坑
异常现象1
按照以下方式设置backend目录和checkpoint目录,fsbackend目录有数据,checkpoint目录没数据
env.getCheckpointConfig().setCheckpointStorage(PropUtils.getValueStr(Constant.ENV_FLINK_CHECKPOINT_PATH));
env.setStateBackend(new FsStat…
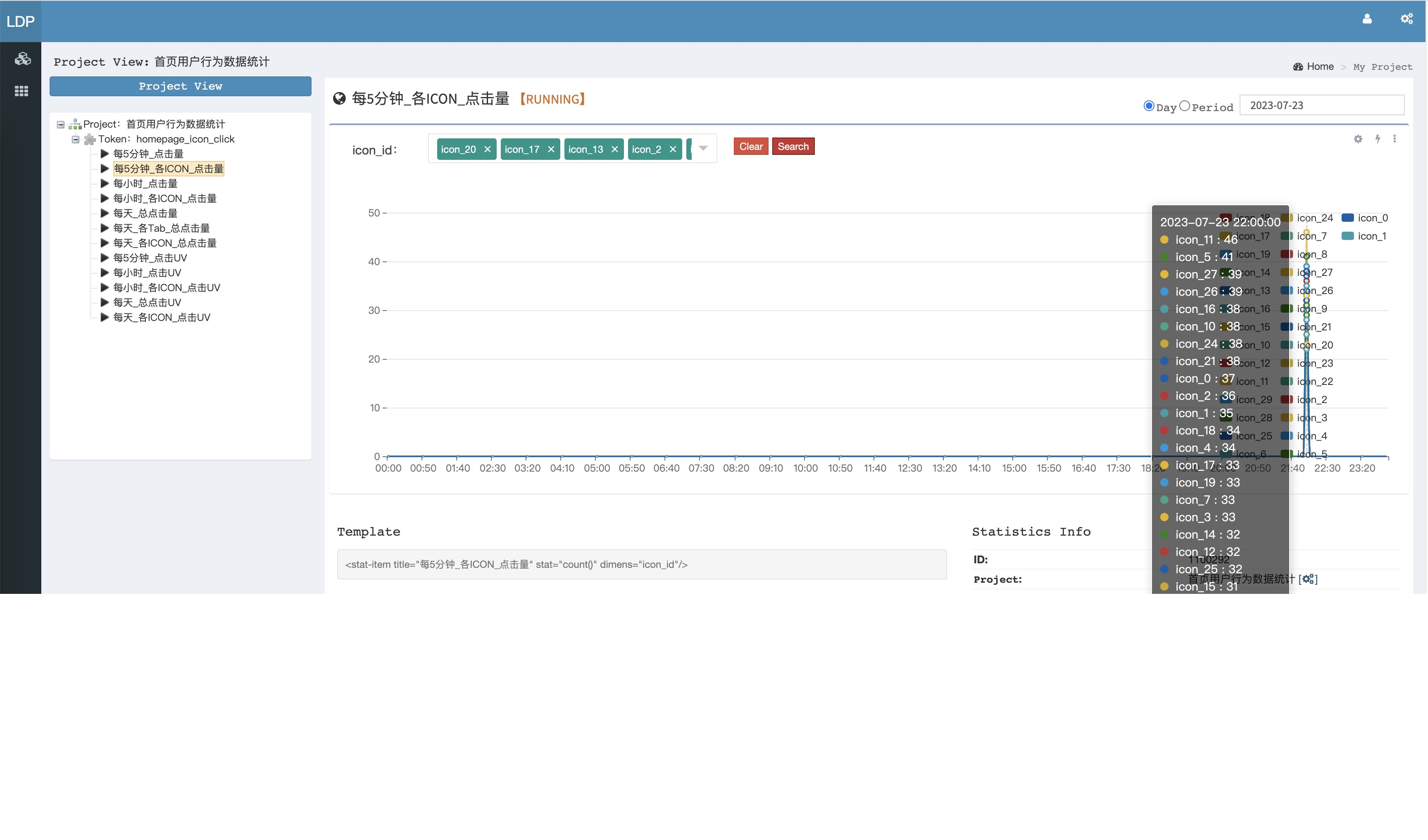
XL-LightHouse 与 Flink 和 ClickHouse 流式大数据统计系统
一个Flink任务只能并行处理一个或少数几个数据流,而XL-LightHouse一个任务可以并行处理数万个、几十万个数据流;
一个Flink任务只能实现一个或少数几个数据指标,而XL-LightHouse单个任务就能支撑大批量、数以万计的数据指标。 1、XL-LightHo…
Flink---12、状态后端(HashMapStateBackend/RocksDB)、如何选择正确的状态后端
星光下的赶路人star的个人主页 大鹏一日同风起,扶摇直上九万里 文章目录 1、状态后端(State Backends)1.1 状态后端的分类(HashMapStateBackend/RocksDB)1.2 如何选择正确的状态后端1.3 状态后端的配置 1、状态后端&am…
Flink---11、状态管理(按键分区状态(值状态、列表状态、Map状态、归约状态、聚合状态)算子状态(列表状态、广播状态))
星光下的赶路人star的个人主页 这世上唯一扛得住岁月摧残的就是才华 文章目录 1、状态管理1.1 Flink中的状态1.1.1 概述1.1.2 状态的分类 1.2 按键分区状态(Keyed State)1.2.1 值状态(ValueState)1.2.2 列表状态(ListS…
修炼k8s+flink+hdfs+dlink(五:安装dockers,cri-docker,harbor仓库,k8s)
一:安装docker。(所有服务器都要安装)
安装必要的一些系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2添加软件源信息
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/cent…

Flink开发环境搭建与提交运行Flink应用程序
Flink开发环境搭建与提交运行Flink应用程序 Flink概述环境 Flink程序开发项目构建添加依赖安装Netcat实现经典的词频统计批处理示例流处理示例 Flink Web UI 命令行提交作业编写Flink程序打包上传Jar提交作业查看任务测试 Web UI提交作业提交作业测试 Flink
概述 Apache Flink…
大数据面试题:Spark和Flink的区别
面试题来源:
《大数据面试题 V4.0》
大数据面试题V3.0,523道题,679页,46w字
可回答:1)Spark Streaming和Flink的区别
问过的一些公司:杰创智能科技(2022.11),阿里蚂蚁(2022.11)&…
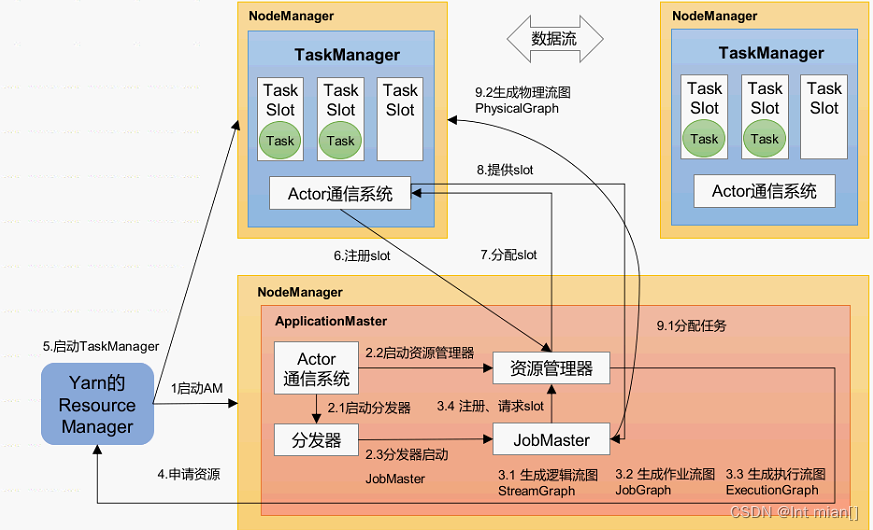
尚硅谷Flink(一)
目录
☄️前置工作
fenfa脚本
🌋概述
☄️Flink是什么
☄️特点(多nb)
☄️应用场景(不用看)
☄️分层API
🌋配环境
☄️wordcount
☄️WcDemoUnboundStreaming
🌋集群部署
☄️集…
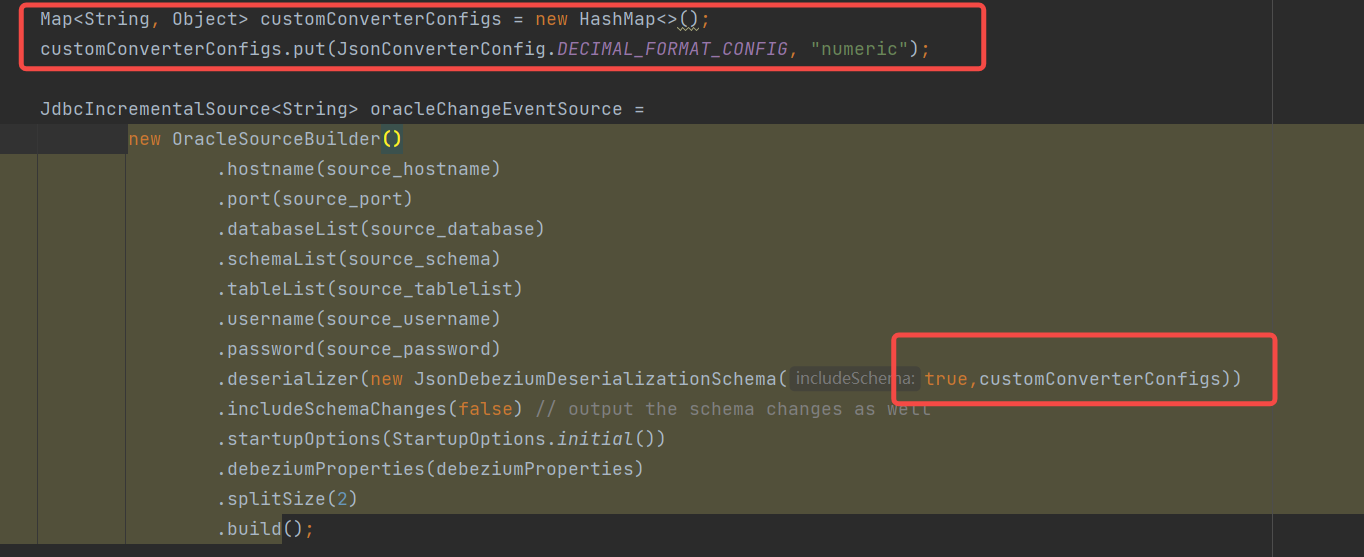
flinkcdc踩坑指南
文章目录 前言一、常见问题1.No suitable driver found for jdbc:oracle:thin:10.101.37.167:8888/orclpdb2.The db history topic or its content is fully or partially missing. Please check database history topic configuration and re-execute the snapshot3.com.verve…
Flink之窗口指派API模板
flink中窗口指派主要分为两类NoKeyed Windows和Keyed Windows,这里就结合这两类阐述窗口指派API
NoKeyed Windows NoKeyed Windows同时又分为两类Porcessing Time和Event Time,即处理时间语义和事件时间语义. 事件时间语义// 事件时间语义-滚动窗口
source.windowAll(Tumbling…
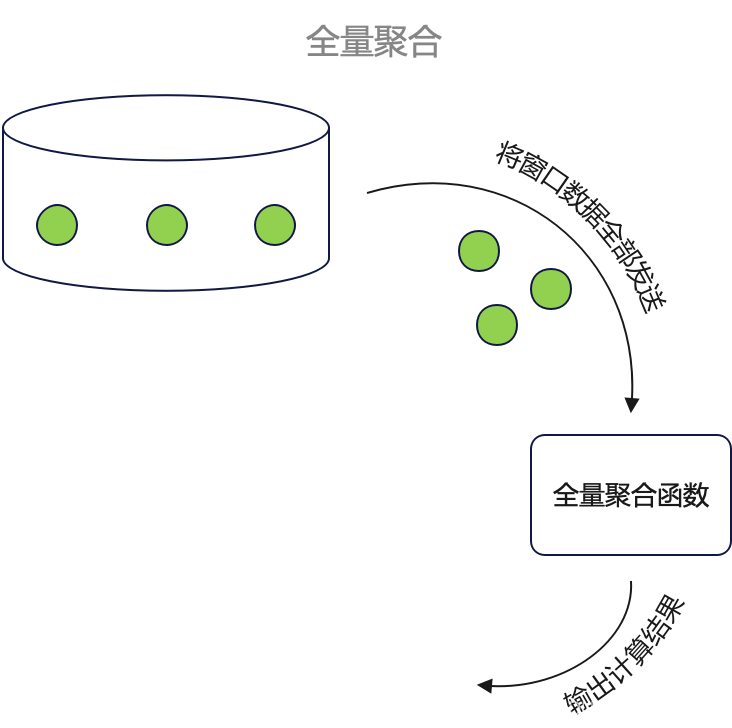
Flink之窗口聚合算子
1.窗口聚合算子
在Flink中窗口聚合算子主要分类两类
滚动聚合算子(增量聚合)全窗口聚合算子(全量聚合)
1.1 滚动聚合算子
滚动聚合算子一次只处理一条数据,通过算子中的累加器对聚合结果进行更新,当窗口触发时再从累加器中取结果数据,一般使用算子如下:
aggregatemaxmaxBy…
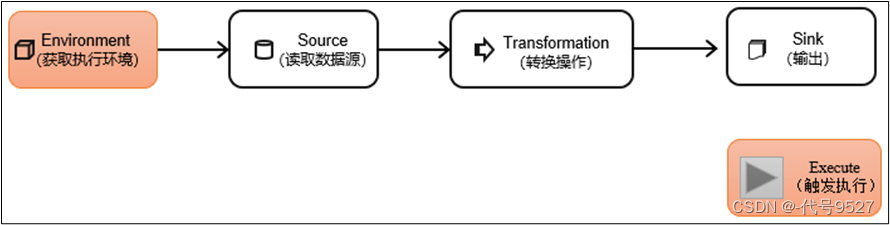
【API篇】一、执行环境API
文章目录 0、认识1、创建执行环境2、执行模式3、触发程序执行4、关于executeAsync方法 0、认识
DataStream API是Flink的核心层API。一个Flink程序,其实就是对数据源DataStream的各种转换。具体来说,代码基本上都由以下几部分构成: 后面章节…
尚硅谷Flink(二)DStream API
目录 🌠不会点 🪐DataStream API 编辑 🌠 执行环境 创建执行环境 执行模式 触发程序执行 🌠源算子 准备基础类型 从集合中读取数据 从文件读取数据 从 Socket 读取数据 从 Kafka 读取数据 (没学过) …

Flink测试利器之DataGen初探 | 京东云技术团队
什么是 Flinksql
Flink SQL 是基于 Apache Calcite 的 SQL 解析器和优化器构建的,支持ANSI SQL 标准,允许使用标准的 SQL 语句来处理流式和批处理数据。通过 Flink SQL,可以以声明式的方式描述数据处理逻辑,而无需编写显式的代码…
kafka、zookeeper、flink测试环境、docker
1、kafka环境单点
根据官网版本说明(3.6.0)发布,zookeeper依旧在使用状态,预期在4.0.0大版本的时候彻底抛弃zookeeper使用KRaft(Apache Kafka)官方并给出了zk迁移KR的文档
2、使用docker启动单点kafka 1、首先将kafka启动命令,存储为.servi…

分布式内存计算Spark环境部署与分布式内存计算Flink环境部署
目录
分布式内存计算Spark环境部署
1. 简介
2. 安装
2.1【node1执行】下载并解压
2.2【node1执行】修改配置文件名称
2.3【node1执行】修改配置文件,spark-env.sh
2.4 【node1执行】修改配置文件,slaves
2.5【node1执行】分发
2.6【node2、no…
【API篇】五、Flink分流合流API
文章目录 1、filter算子实现分流2、分流:使用侧输出流3、合流:union4、合流:connect5、connect案例 分流,很形象的一个词,就像一条大河,遇到岸边有分叉的,而形成了主流和测流。对于数据流也一样…
Flink学习之旅:(二)构建Flink demo工程并提交到集群执行
1.创建Maven工程 在idea中创建一个 名为 MyFlinkFirst 工程
2.配置pom.xml <properties><flink.version>1.13.0</flink.version><java.version>1.8</java.version><scala.binary.version>2.12</scala.binary.version><slf4j.ver…
Flink学习之旅:(一)Flink部署安装
1.本地搭建
1.1.下载Flink 进入Flink官网,点击Downloads 往下滑动就可以看到 Flink 的所有版本了,看自己需要什么版本点击下载即可。 1.2.上传解压 上传至服务器,进行解压
tar -zxvf flink-1.17.1-bin-scala_2.12.tgz -C ../module/
1.3.启…

Flink学习笔记(三):Flink四种执行图
文章目录 1、Graph 的概念2、Graph 的演变过程2.1、StreamGraph (数据流图)2.2、JobGraph (作业图)2.3、ExecutionGraph (执行图)2.4、Physical Graph (物理图) 1、Graph 的概念 Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -&g…
flink1.15 异步维表Join 用于外部数据访问的异步 I/O scala版本
官方文档 Asynchronous I/O for External Data Access
异步 I/O | Apache Flink
核心问题
问什么有官方文档,我还要写个博客,因为scala Future这块有坑.
1 为什么我的算子显示反压100%
2 为什么我的任务不报错,也没有输出
3 Future对象我该怎么构建,有哪些注意事项. pom …
Flink学习---15、FlinkCDC(CDC介绍、案例实操)
星光下的赶路人star的个人主页 未来总是藏在迷雾中让人胆怯,但当你踏入其中,便会云开雾散 文章目录 1、CDC简介1.1 什么是CDC1.2 CDC的种类1.3 Flink-CDC 2、FlinkCDC案例实操2.1 开启MySQL Binlog并重启MySQL2.2 FlinkSQL方式的应用2.2.1 导入依赖2.2.2…
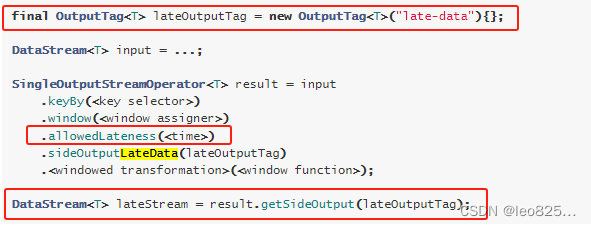
Flink学习笔记(四):Flink 四大基石之 Window 和 Time
文章目录 1、 概述2、 Flink 的 Window 和 Time2.1、Window API2.1.1、WindowAssigner2.1.2、Trigger2.1.3、Evictor 2.2、窗口类型2.2.1、Tumbling Windows2.2.2、Sliding Windows2.2.3、Session Windows2.2.4、Global Windows 2.3、Time 时间语义2.4、乱序和延迟数据处理2.5、…

【API篇】七、Flink窗口
文章目录 1、窗口2、分类3、窗口API概览4、窗口分配器 在批处理统计中,可以等待一批数据都到齐后,统一处理。但是在无界流的实时处理统计中,是来一条就得处理一条,那么如何统计最近一段时间内的数据呢? ⇒ 窗口的概念&…
Flink-CEP基于web日志检测暴力破解和异地登陆行为代码示例
Flink-CEP基于web日志检测暴力破解和异地登陆行为Demo
代码示例
(1)主程序代码
import Beans.EventPOJO;
import Beans.WaringMsgPOJO;
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternSelectFunction;
import org.apache.fli…
尚硅谷大数据项目《在线教育之实时数仓》笔记003
视频地址:尚硅谷大数据项目《在线教育之实时数仓》_哔哩哔哩_bilibili 目录
第7章 数仓开发之ODS层
P015
第8章 数仓开发之DIM层
P016
P017
P018
P019
01、node001节点Linux命令
02、KafkaUtil.java
03、DimSinkApp.java
P020
P021
P022
P023 第7章 数…

【API篇】十一、Flink水位线传递与迟到数据处理
文章目录 1、水位线传递2、水位线设置空闲等待3、迟到数据处理:窗口允许迟到4、迟到数据处理:侧流输出5、问 1、水位线传递
上游task处理完水位线,时钟改变后,要把数据和当前水位线继续往下游算子的task发送。当一个任务接收到多…
【flink sql table api】时间属性的指定与使用注意事项
文章目录 一. 时间属性介绍二. Table api指定时间属性三. 处理时间的指定1. 在创建表的 DDL 中定义2. 在 DataStream 到 Table 转换时定义3. 使用 TableSource 定义 四. 事件时间的指定1. 在 DDL 中定义2. 在 DataStream 到 Table 转换时定义3. 使用 TableSource 定义 五. 小结…
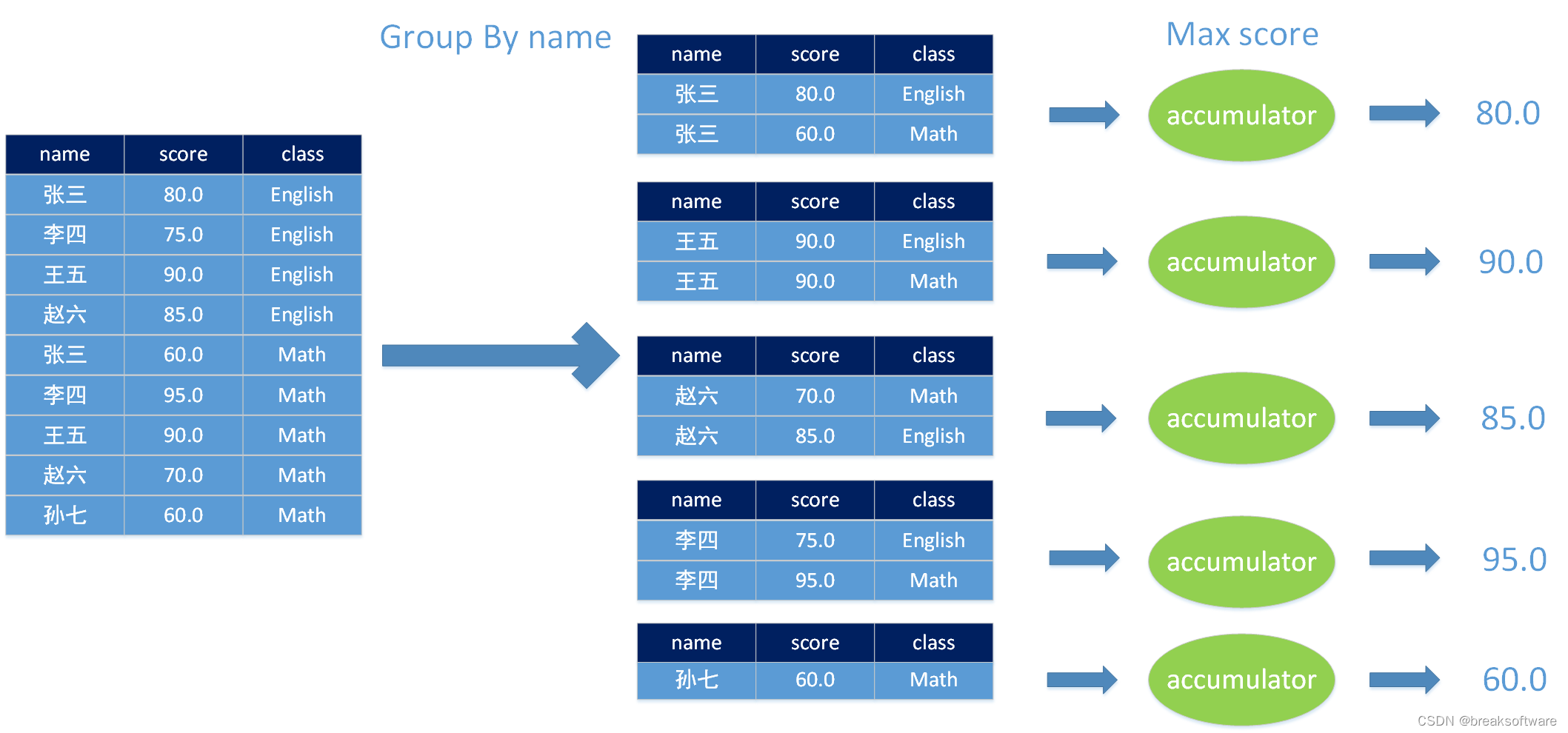
0基础学习PyFlink——用户自定义函数之UDAF
大纲 UDAF入参并非表中一行(Row)的集合计算每个人考了几门课计算每门课有几个人考试计算每个人的平均分计算每课的平均分计算每个人的最高分和最低分 入参是表中一行(Row)的集合计算每个人的最高分、最低分以及所属的课程计算每课…
Flink on yarn 加载失败plugins失效问题解决
Flink on yarn 加载失败plugins失效问题解决
flink版本:1.13.6
1. 问题
flink 任务运行在yarn集群,plugins加载失效,导致通过扩展资源获取任务参数失效
2. 问题定位 yarn容器的jar包及插件信息,jar包是正常上传 源码定位 加载plugins入口,TaskMana…

【Apache Flink】实现有状态函数
文章目录 在RuntimeContext 中声明键值分区状态通过ListCheckPonitend 接口实现算子列表状态使用CheckpointedFunction接口接收检查点完成通知参考文档 在RuntimeContext 中声明键值分区状态
Flink为键值分区状态(Keyed State)提供了几种不同的原语&…

0基础学习PyFlink——用户自定义函数之UDTAF
大纲 UDTAFTableAggregateFunction的实现累加器定义创建累加 返回类型计算 完整代码 在前面几篇文章中,我们分别介绍了UDF、UDTF和UDAF这三种用户自定义函数。本节我们将介绍最后一种函数:UDTAF——用户自定义表值聚合函数。
UDTAF
UDTAF函数即具备了…

2.flink编码第一步(maven工程创建)
概述 万里第一步,要进行flink代码开发,第一步先整个 flink 代码工程 flink相关文章链接 flink官方文档
两种方式 一种命令行 mvn 创建,另一种直接在 idea 中创建一个工程,使用 mvn 的一些配置 mvn命令行创建
mvn 创建flink工程&…
linux 上flink单机安装详解
目录
一 准备安装包
二 解压
三 配置环境变量
四 验证是否部署成功 一 准备安装包 官网地址:
Downloads | Apache Flink 百度网盘资源:
链接: https://pan.baidu.com/s/15aXmF3JLxnOlPiDxId637Q?pwdsqsx 提取码: sqsx 这里准备的版本是flink1.13…
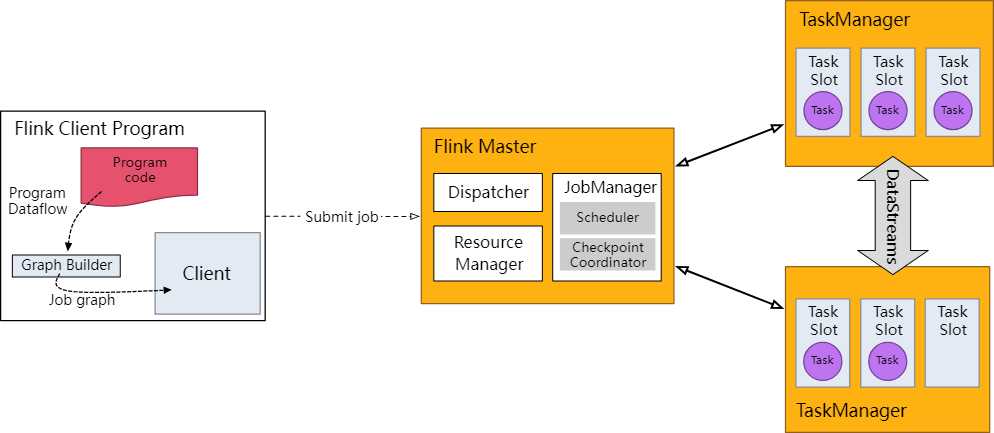
【Apache Flink】Flink DataStream API的基本使用
Flink DataStream API的基本使用 文章目录 前言1. 基本使用方法2. 核心示例代码3. 完成工程代码pom.xmlWordCountExample测试验证 4. Stream 执行环境5. 参考文档 前言
Flink DataStream API主要用于处理无界和有界数据流 。 无界数据流是一个持续生成数据的数据源࿰…
尚硅谷大数据项目《在线教育之实时数仓》笔记005
视频地址:尚硅谷大数据项目《在线教育之实时数仓》_哔哩哔哩_bilibili 目录
第9章 数仓开发之DWD层
P031
P032
P033
P034
P035
P036
P037
P038
P039
P040 第9章 数仓开发之DWD层
P031 DWD层设计要点: (1)DWD层的设计依…
17、Flink 之Table API: Table API 支持的操作(1)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
快速灵敏的 Flink1
一、flink单机安装
1、解压
tar -zxvf ./flink-1.13.2-bin-scala_2.12.tgz -C /opt/soft/
2、改名字
mv ./flink-1.13.2/ ./flink1132
3、profile配置
#FLINK
export FLINK_HOME/opt/soft/flink1132
export PATH$FLINK_HOME/bin:$PATH
4、查看版本
flink --version
5、…
flink job同时使用BroadcastProcessFunction和KeyedBroadcastProcessFunction例子
背景:
广播状态可以用于规则表或者配置表的实时更新,本文就是用一个欺诈检测的flink作业作为例子看一下BroadcastProcessFunction和KeyedBroadcastProcessFunction的使用
BroadcastProcessFunction和KeyedBroadcastProcessFunction的使用
1.首先看主流…
【API篇】二、源算子API
文章目录 0、demo数据1、源算子Source2、从集合中读取数据3、从文件中读取4、从Socket读取5、从Kafka读取6、从数据生成器读取数据7、Flink支持的数据类型8、Flink的类型提示(Type Hints) 0、demo数据
准备一个实体类WaterSensor:
Data
All…
Flink之源算子Data Source
源算子Data Source 概述内置Data Source基于集合构建基于文件构建基于Socket构建 自定义Data SourceSourceFunctionRichSourceFunction 常见连接器第三方系统连接器File Source连接器DataGen Source连接器Kafka Source连接器RabbitMQ Source连接器MongoDB Source连接器 概述 Fl…
18、Flink的SQL 支持的操作和语法
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

Flink SQL Window TopN 详解
Window TopN 定义(⽀持 Streaming): Window TopN 是特殊的 TopN,返回结果是每⼀个窗⼝内的 N 个最⼩值或者最⼤值。
应⽤场景: TopN 会出现中间结果,出现回撤数据,Window TopN 不会出现回撤数据…
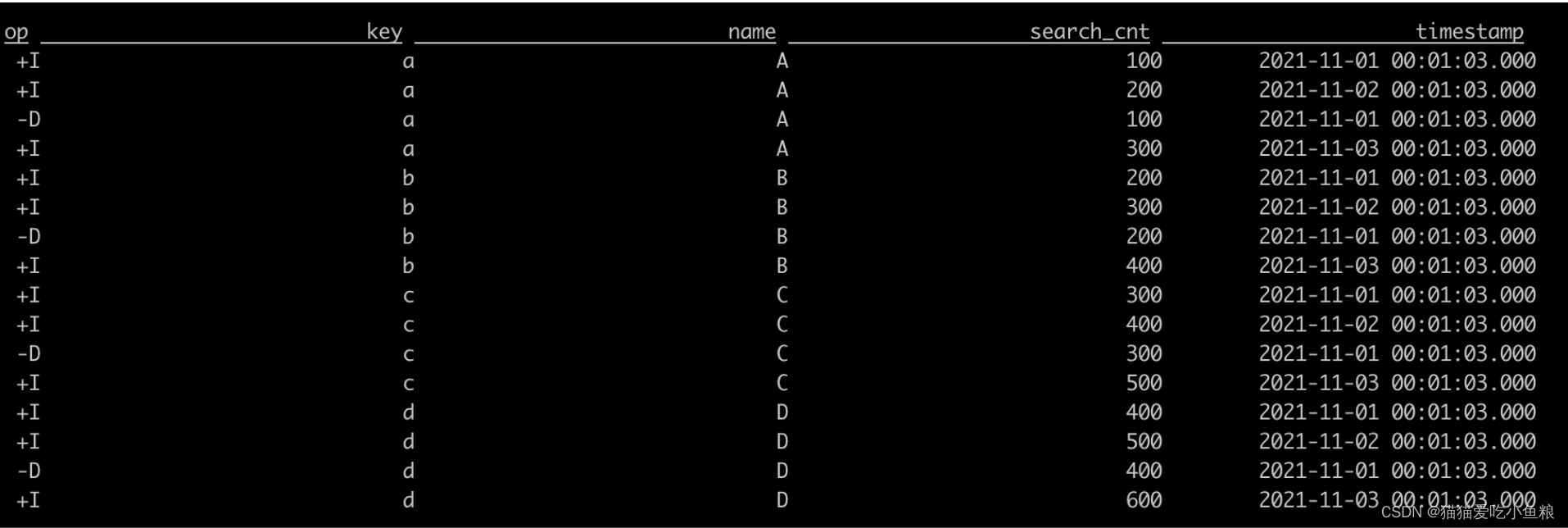
Flink SQL TopN语句详解
TopN 定义(⽀持 Batch\Streaming): TopN 对应离线数仓的 row_number(),使⽤ row_number() 对某⼀个分组的数据进⾏排序。
应⽤场景: 根据 某个排序 条件,计算 某个分组 下的排⾏榜数据。
SQL 语法标准&am…
flink状态和检查点
检查点和状态后端的区别 检查点 就是某个时间点下的所有算子的状态快照。这个时间点就是等所有任务将“同一个数据”处理完毕的时候。 状态后端:是一个管理状态的组件,还负责将本地状态(检查点)持久化到远程文件存储系统中。
分…
Kafka与Flink的整合 -- sink、source
1、首先导入依赖: <dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.15.2</version></dependency>
2、 source:Flink从Kafka中读取数据
p…
flink测试map转换函数和process函数
背景
在flink中,我们需要对我们写的map转换函数,process处理函数进行单元测试,测试的内容包括查看函数的输出结果是否符合以及函数内的状态是否正确更新,本文就记录几个测试过程中的要点
flink中测试函数
首先我们根据我们要测…
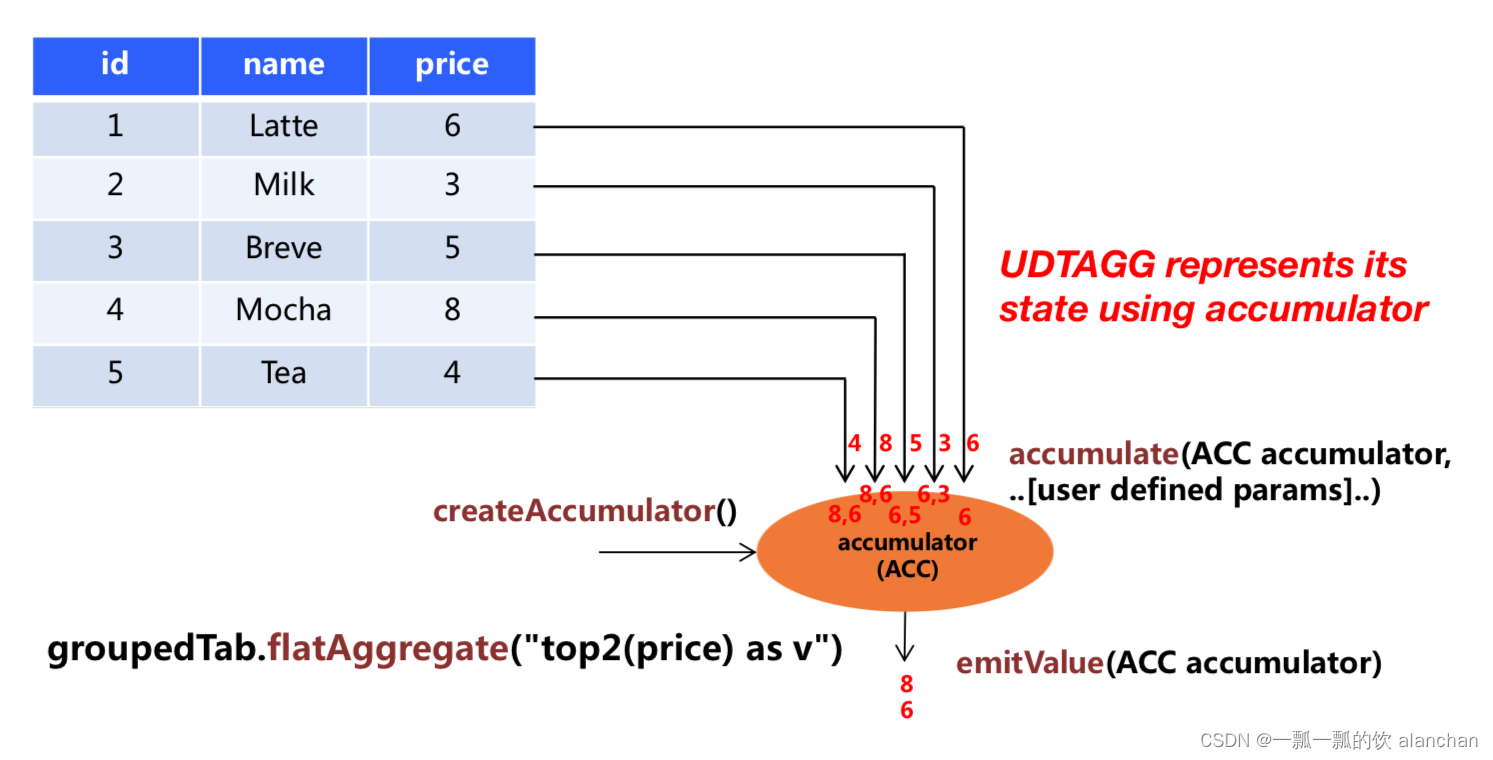
19、Flink 的Table API 和 SQL 中的自定义函数及示例(3)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
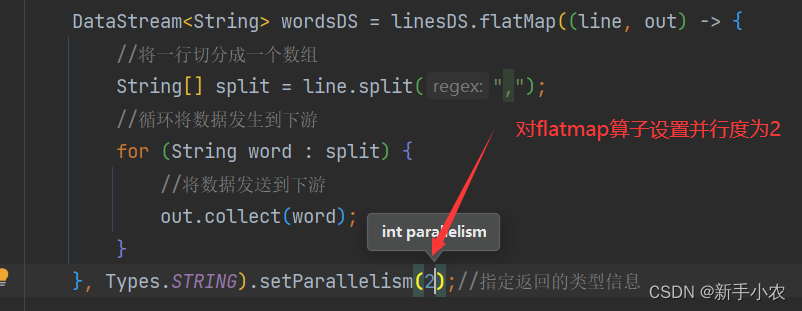
Flink -- 并行度
1、并行度: 对于一个Flink任务是有Source、Transformation和Sink等任务组成,一个任务由多个并行实例来执行,一个任务的并行实例数目被称为该任务的并行度。 2、TaskManager和Solt
Flink是一个分布式流处理框架,它基于TaskManager…
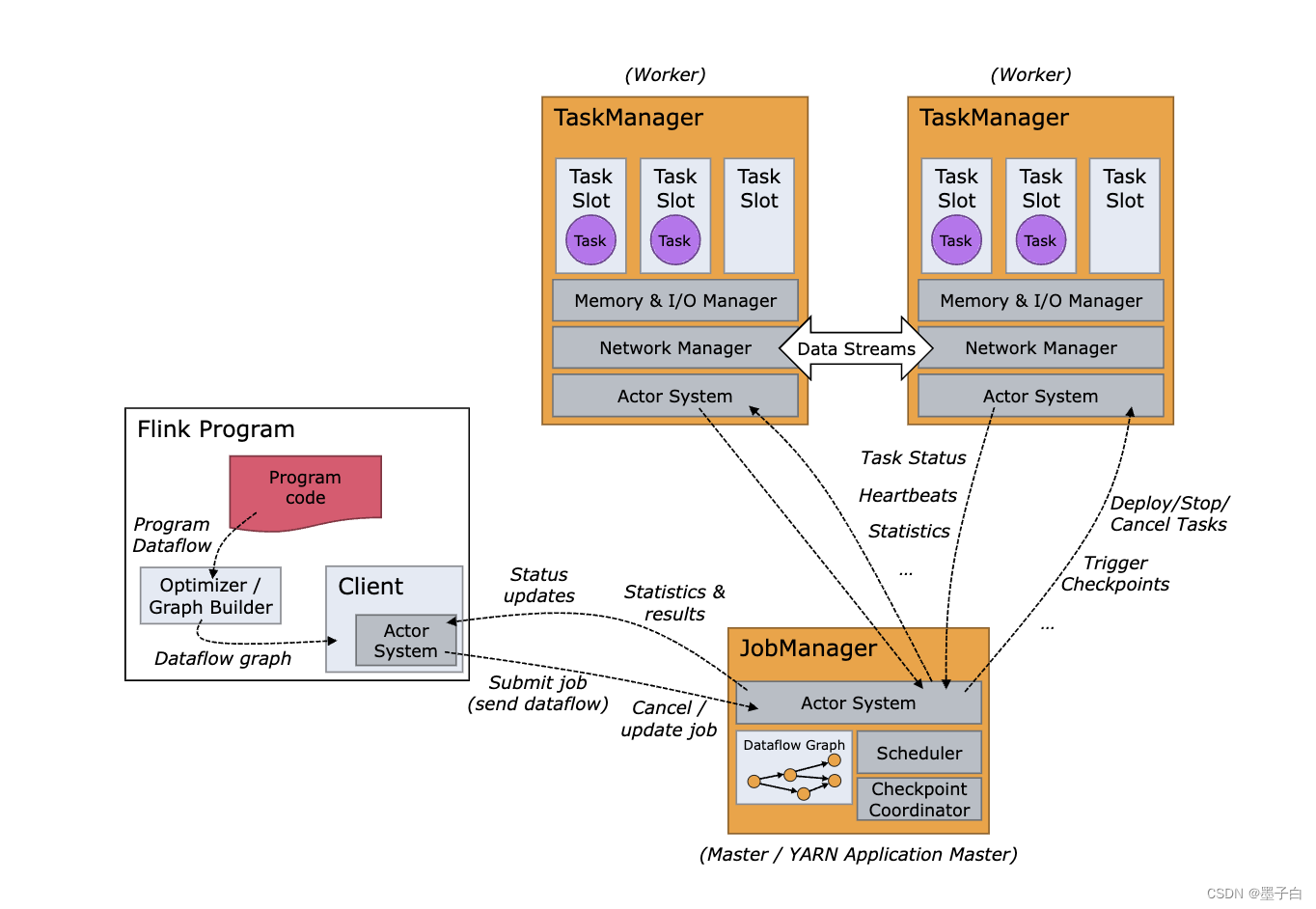
Flink的API分层、架构与组件原理、并行度、任务执行计划
Flink的API分层 Apache Flink的API分为四个层次,每个层次都提供不同的抽象和功能,以满足不同场景下的数据处理需求。下面是这四个层次的具体介绍: CEP API:Flink API 最底层的抽象为有状态实时流处理。其抽象实现是Process Functi…
19、Flink 的Table API 和 SQL 中的自定义函数及示例(4)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
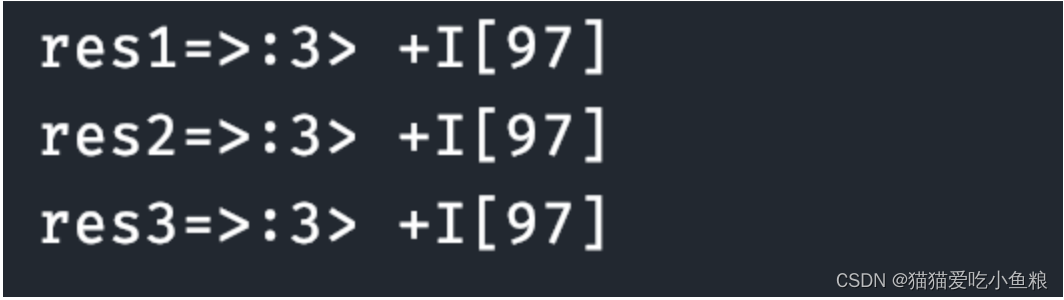
Flink SQL自定义标量函数(Scalar Function)
使用场景: 标量函数即 UDF,⽤于进⼀条数据出⼀条数据的场景。
开发流程:
实现 org.apache.flink.table.functions.ScalarFunction 接⼝实现⼀个或者多个⾃定义的 eval 函数,名称必须叫做 eval,eval ⽅法签名必须是 p…
SpringData、SparkStreaming和Flink集成Elasticsearch
本文代码链接:https://download.csdn.net/download/shangjg03/88522188 1 Spring Data框架集成 1.1 Spring Data框架介绍 Spring Data是一个用于简化数据库、非关系型数据库、索引库访问,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快…
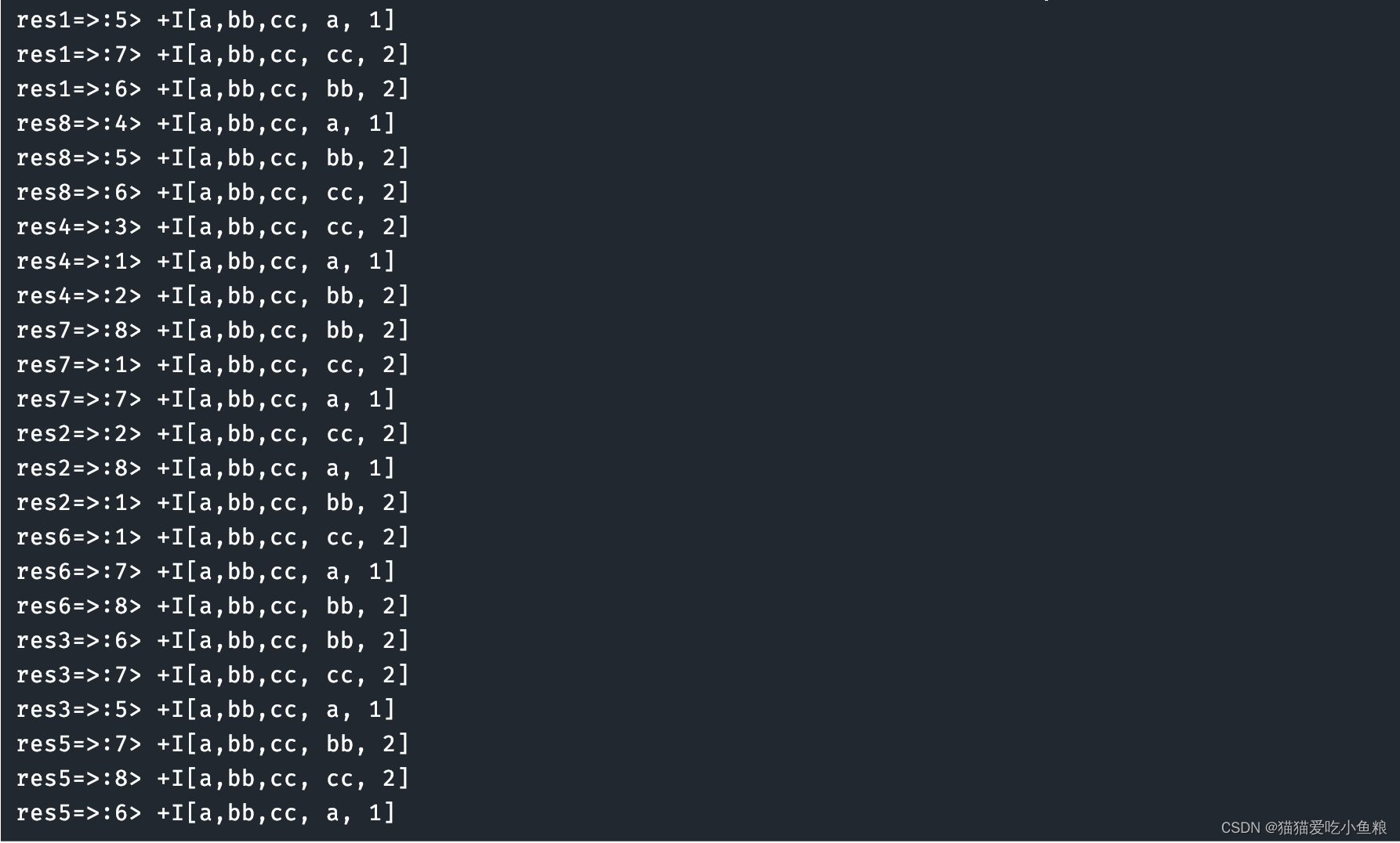
Flink SQL自定义表值函数(Table Function)
使用场景: 表值函数即 UDTF,⽤于进⼀条数据,出多条数据的场景。
开发流程:
实现 org.apache.flink.table.functions.TableFunction 接⼝实现⼀个或者多个⾃定义的 eval 函数,名称必须叫做 eval,eval ⽅法…
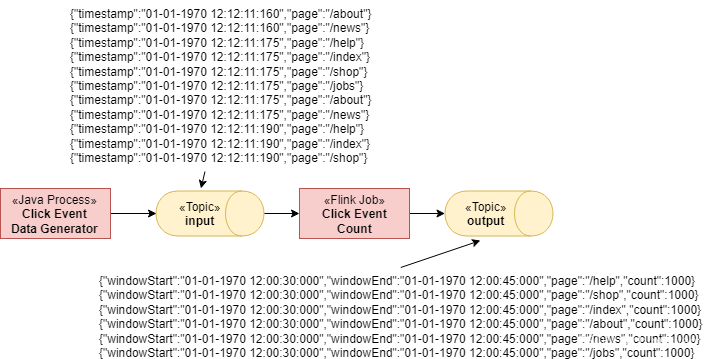
Flink 基础 -- 尝试Flink
官网
文档 v1.18.0
下载
数据流上的状态计算(Stateful Computations over Data Streams)
Apache Flink是一个框架和分布式处理引擎,用于无界和有界数据流的有状态计算。Flink被设计成可以在所有常见的集群环境中运行,以内存中的速度和任何规模执行计…

Flink SQL --命令行的使用(02)
1、窗口函数:
1、创建表:
-- 创建kafka 表
CREATE TABLE bid (bidtime TIMESTAMP(3),price DECIMAL(10, 2) ,item STRING,WATERMARK FOR bidtime AS bidtime
) WITH (connector kafka,topic bid, -- 数据的topicproperties.bootstrap.servers m…
Flink Table API和Flink SQL处理Row类型字段案例
从数据源获取Row类型数据流并使用Flink Table API和Flink SQL进行处理。
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironmen…
flink对状态ttl进行单元测试
背景
在处理键值分区状态时,使用ttl设置过期时间是我们经常使用的,但是任何代码的修改都需要首先进行单元测试,本文就使用单元测试来验证一下状态ttl的设置是否正确
测试状态ttl超时的单元测试
首先看一下处理函数:
// 处理函…
尚硅谷大数据项目《在线教育之实时数仓》笔记006
视频地址:尚硅谷大数据项目《在线教育之实时数仓》_哔哩哔哩_bilibili 目录
第9章 数仓开发之DWD层
P041
P042
P043
P044
P045
P046
P047
P048
P049
P050
P051
P052 第9章 数仓开发之DWD层
P041 9.3 流量域用户跳出事务事实表 P042 DwdTrafficUserJum…
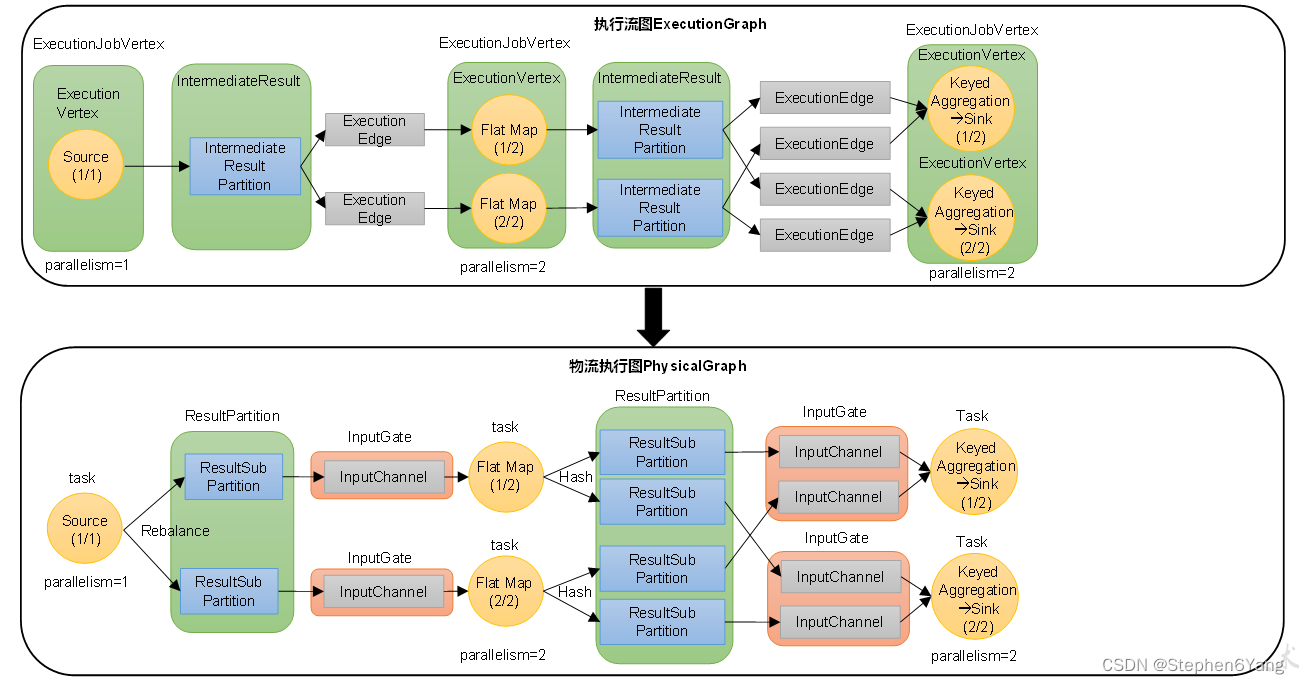
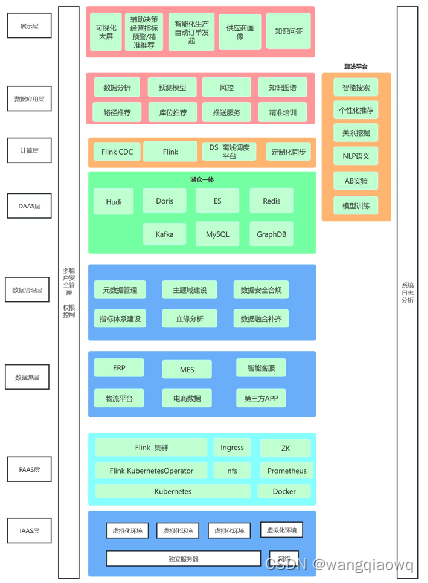
大数据平台架构及规划
梳理了数据平台及未来规划,具体如下:
整体架构: 当前建设进展: 部署架构 部署架构2: Flink 实时计算平台架构
版本1: 版本2: 离线平台架构: 未来规划:
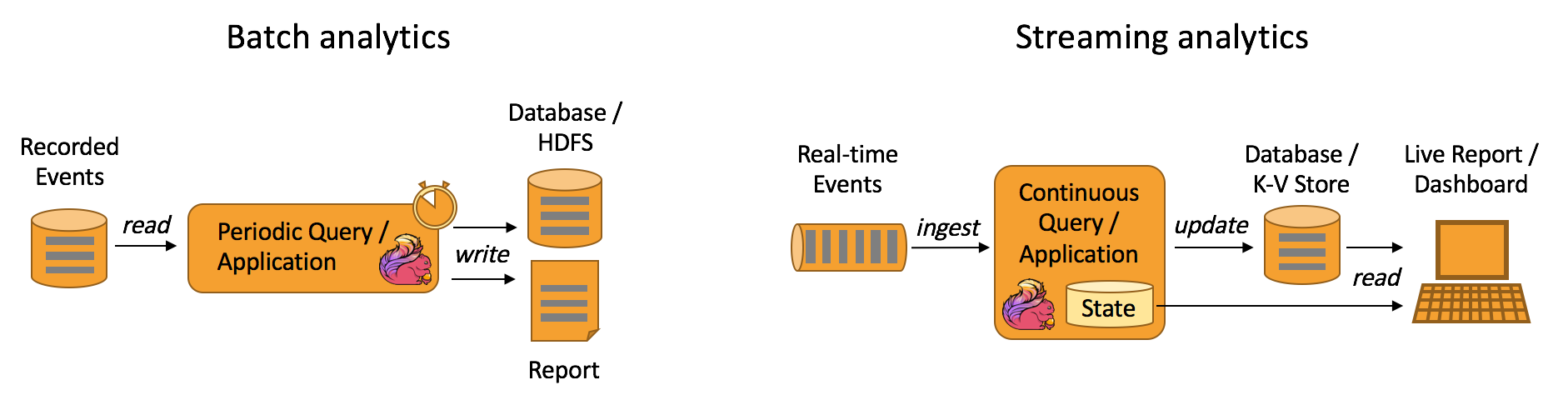
【Apache Flink】流式分析的多种应用场景
文章目录 0. 前言1. 数据处理架构的演进2. 传统数据处理架构3. 事务型处理4. 分析型处理用于数据分析的传统数据仓架构 状态化流处理5. 事件驱动型应用什么是事件驱动型应用? 6. 数据管道什么是数据管道?Flink 如何支持数据管道应用?典型的数…
Flink SQL 常用作业sql
目录 flink sql常用配置kafka source to mysql sink窗口函数 开窗datagen 自动生成数据表tumble 滚动窗口hop 滑动窗口cumulate 累积窗口 grouping sets 多维分析over 函数TopN flink sql常用配置
设置输出结果格式
SET sql-client.execution.result-modetableau;kafka source…

Apache Flink 1.12.0 on Yarn(3.1.1) 所遇到的問題
Apache Flink 1.12.0 on Yarn(3.1.1) 所遇到的問題
新搭建的FLINK集群出现的问题汇总
1.新搭建的Flink集群和Hadoop集群无法正常启动Flink任务 查看这个提交任务的日志无法发现有用的错误信息。
进一步查看yarn日志:
发现只有JobManager的错误日志出现了如下的…
源码解析FlinkKafkaConsumer支持punctuated水位线发送
背景
FlinkKafkaConsumer支持当收到某个kafka分区中的某条记录时发送水位线,比如这条特殊的记录代表一个完整记录的结束等,本文就来解析下发送punctuated水位线的源码
punctuated 水位线发送源码解析
1.首先KafkaFetcher中的runFetchLoop方法
public…
Flink源码解析二之执行计划⽣成
JobManager Leader 选举
首先flink会依据配置获取RecoveryMode,RecoveryMode一共两两种:STANDALONE和ZOOKEEPER。 如果用户配置的是STANDALONE,会直接去配置中获取JobManager的地址如果用户配置的是ZOOKEEPER,flink会首先尝试连接zookeeper,利用zookeeper的leadder选举服务发现…
Flink源码解析八之任务调度和负载均衡
源码概览 jobmanager scheduler:这部分与 Flink 的任务调度有关。 CoLocationConstraint:这是一个约束类,用于确保某些算子的不同子任务在同一个 TaskManager 上运行。这通常用于状态共享或算子链的情况。CoLocationGroup & CoLocationGroupImpl:这些与 CoLocationCon…
flink的起源、概念、特点、应用
flink的起源 Flink的起源可以追溯到2010年,当时它作为一个研究项目开始。该项目最初由德国柏林工业大学(Berlin Institute of Technology)的一群研究人员发起,包括Matei Zaharia、Kostas Tzoumas和Stephan Ewen等。 项目最初被称为…
48、Flink DataStream API 编程指南(2)- DataStream的source、transformation、sink、调试
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
Flink的部署模式和运行模式
集群角色
Flink提交作业和执行任务,需要几个关键组件: 客户端:代码由客户端获取并作转换,之后提交给Jobmanager Jobmanager就是Flink集群的管事人,对作业进行中央调度管理;当从客户端获取到转换过的作业后…
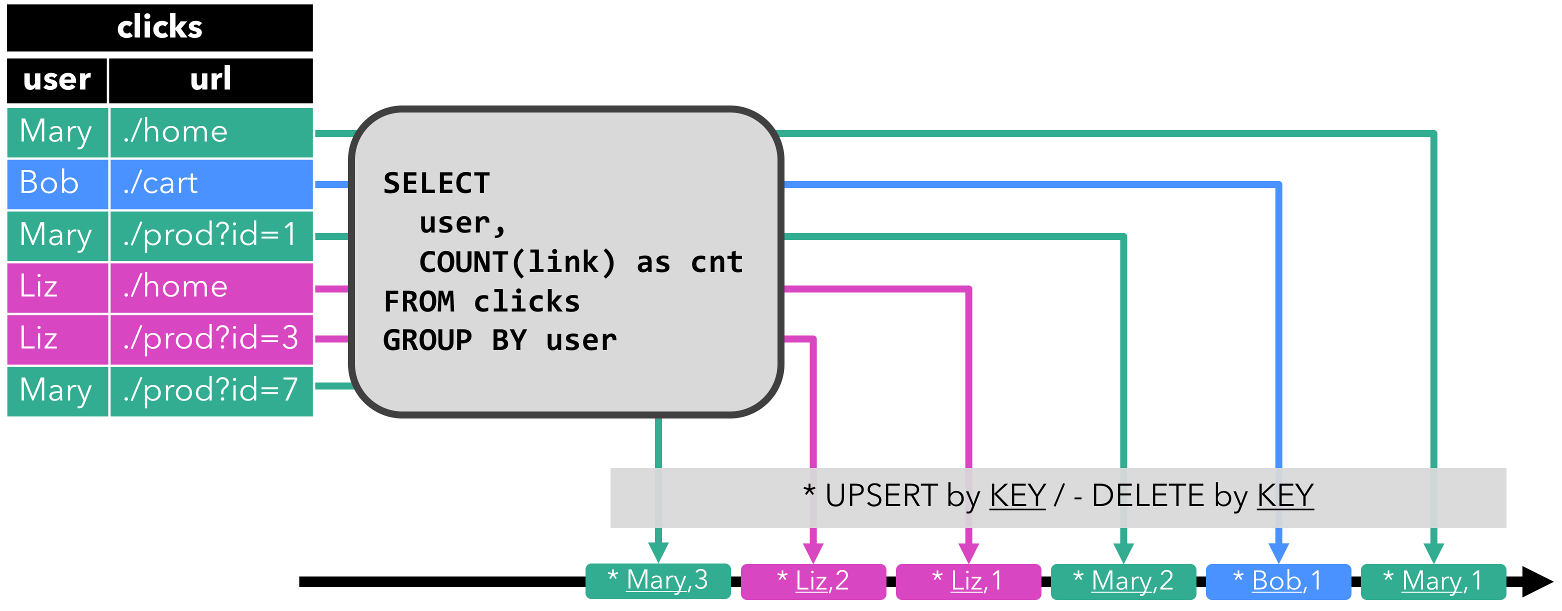
Flink之SQL客户端与DDL操作
SQL客户端与DDL操作 Flink SQLSQL客户端1.启动Flink2.启动Flink的SQL客户端3.HELP命令4.验证连接5.结果显示模式6.执行配置 数据库操作1.创建数据库2.查询数据库3.修改数据库4.删除数据库 表操作1.创建表表列属性表Watermark属性列PRIMARY KEY属性列PARTITIONED BY属性列WITH选…
【重点】Flink四大基石
1. Time(时间机制)
时间概念
处理时间:执行具体操作时的机器时间(例如 Java的 System.currentTimeMillis()) )事件时间:数据本身携带的时间,事件产生时的时间。摄入时间:数据进入 …
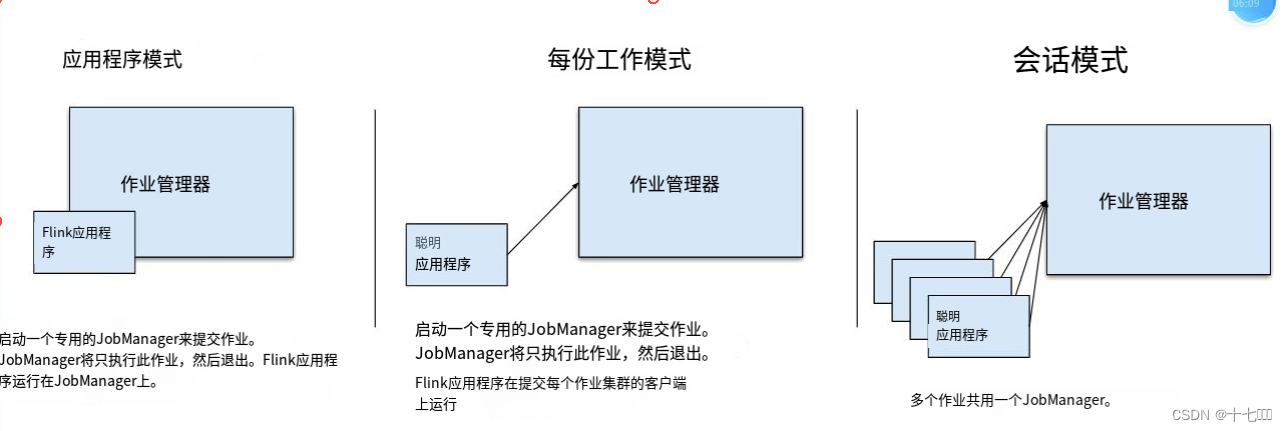
Flink入门(一)
整体框架
Flink概述Flink上手部署Flink架构DataStream API(算子)Flink中的时间和窗口:窗口就是范围处理函数:底层函数状态管理:容错机制:报错重启后能够从出错的位置继续执行FlinkSQL:功能逐步完善
基于数据流的有状…
【flink-sql实战】flink 主键声明与upsert功能实战
文章目录 一. flink 主键声明语法二. 物理表创建联合主键表三. flink sql使用 一. flink 主键声明语法
主键用作 Flink 优化的一种提示信息。主键限制表明一张表或视图的某个(些)列是唯一的并且不包含 Null 值。 主键声明的列都是非 nullable 的。因此主…
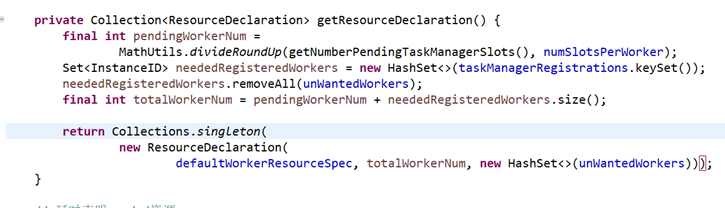
flink源码分析之功能组件(四)-slot管理组件II
简介 本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metrics&…
Flink之Java Table API的使用
Java Table API的使用 使用Java Table API开发添加依赖创建表环境创建表查询表输出表使用示例 表和流的转换流DataStream转换成表Table表Table转换成流DataStream示例数据类型 自定义函数UDF标量函数表函数聚合函数表聚合函数 API方法汇总基本方法列操作聚合操作Joins合并操作排…
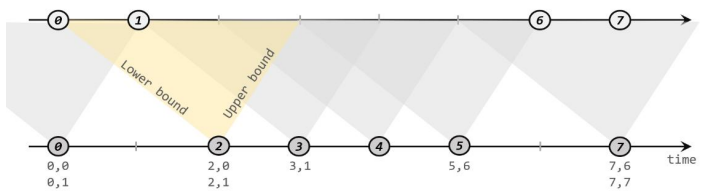
【入门Flink】- 10基于时间的双流联合(join)
统计固定时间内两条流数据的匹配情况,需要自定义来实现——可以用窗口(window)来表示。为了更方便地实现基于时间的合流操作,Flink 的 DataStrema API 提供了内置的 join 算子。 窗口联结(Window Join)
一…
flink安装与配置-脚本一键安装(超简单)
文章目录 前言使用shell脚本一键安装1. 复制脚本2. 增加执行权限3. 执行脚本4. 加载用户环境变量5. 浏览器访问 总结 前言
本文介绍了使用shell脚本一键安装和配置Apache Flink单机版的方法。通过复制并执行提供的安装脚本,可以自动下载、安装和配置Flink。脚本会检…
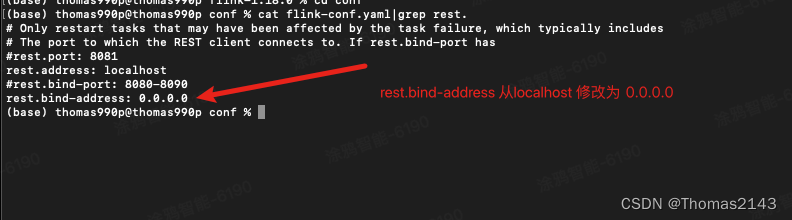
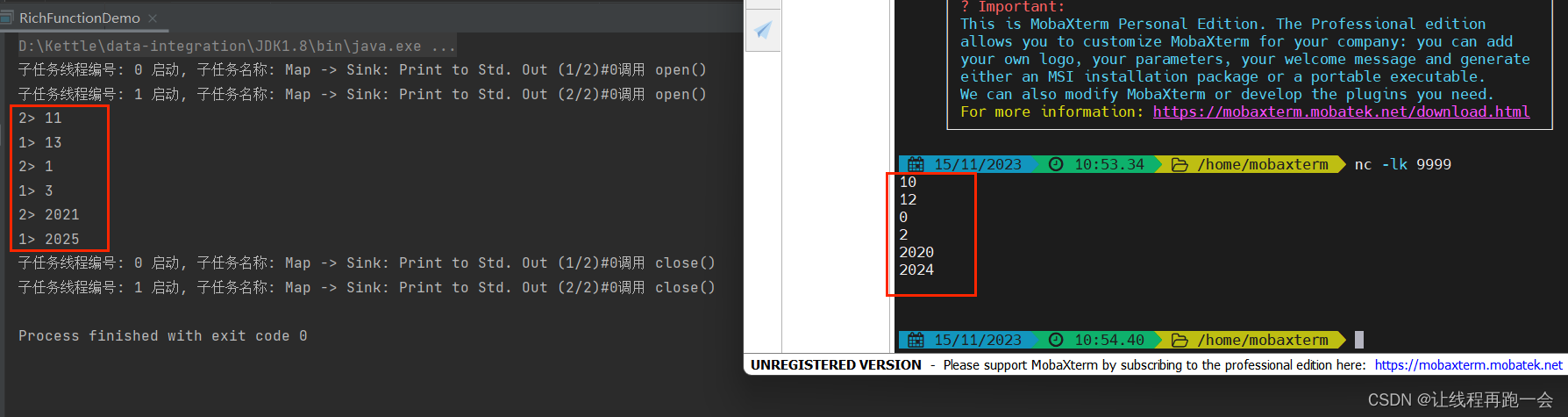
Flink(五)【DataStream 转换算子(上)】
前言 这节注定是一个大的章节,我预估一下得两三天,涉及到的一些东西不懂就重新学,比如 Lambda 表达式,我只知道 Scala 中很方便,但在 Java 中有点发怵了;一个接口能不能 new 来构造对象? 答案是可以的&…
【Flink】Flink任务缺失Jobmanager日志的问题排查
Flink任务缺失Jobmanager日志的问题排查
问题不是大问题,不是什么代码级别的高深问题,也没有影响任务运行,纯粹因为人员粗心导致,记录一下排查的过程。
问题描述
一个生产环境的奇怪问题,环境是flink1.15.0 on yarn…
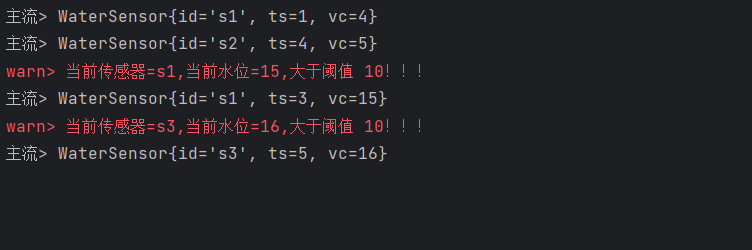
【入门Flink】- 11Flink实现动态TopN
基本处理函数(ProcessFunction)
stream.process(new MyProcessFunction())方法需要传入一个 ProcessFunction 作为参数,ProcessFunction 不是接口 , 而是一个抽象类 ,继承了AbstractRichFunction,所有的处…
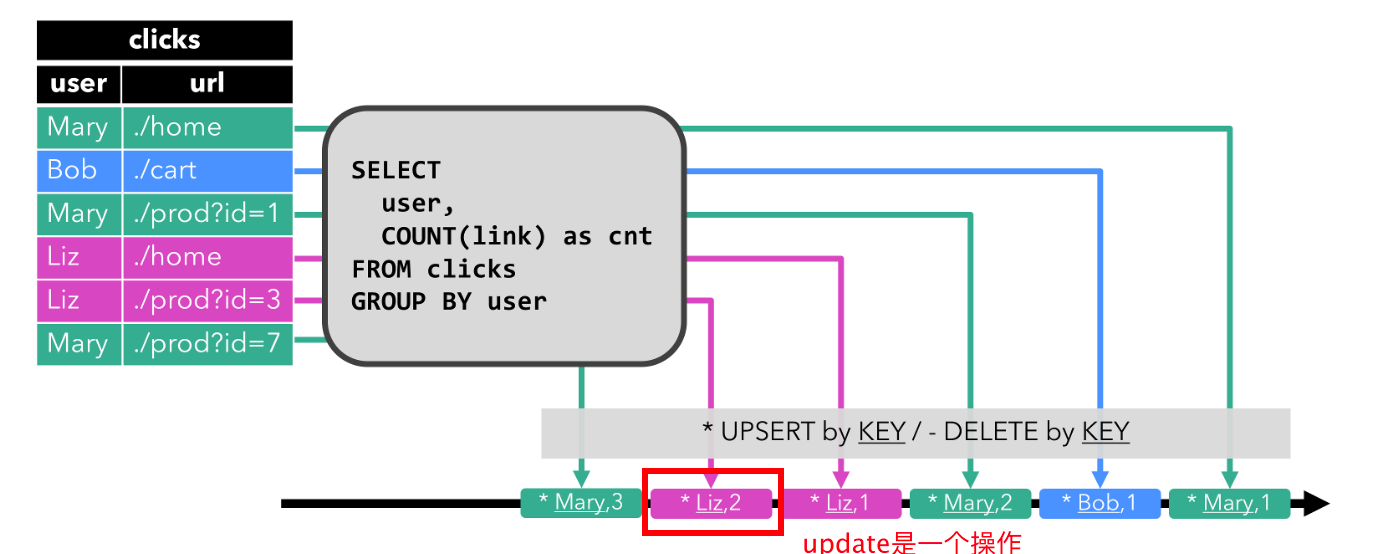
【flink理论】动态表:关系查询处理流的思路:连续查询、状态维护;表转换为流需要编码编码
文章目录 一. 使用关系查询处理流的讨论二. 动态表 & 连续查询(Continuous Query)三. 在流上定义表1. 连续查询2. 查询限制2.1. 维护状态2.2. 计算更新 四. 表到流的转换1. Append-only 流2. Retract 流3. Upsert 流 本文主要讨论了: 讨论通过关系查询处理无界流…
Flink之KeyedState
前面的文章中介绍过Operator State,这里介绍一下Keyed State. 在使用Operator State时必须要实现CheckpointFunction接口,而Keyed State则不需要,在使用keyBy(...)分组分组后,调用的函数必须是实现RichFuntion接口的函数才可以使用Keyed State.同样使用Keyed State也必须开启Ch…
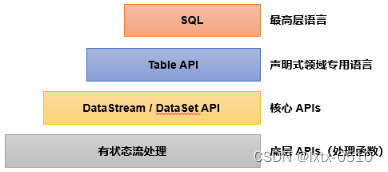
【Flink】Process Function
目录
1、ProcessFunction解析
1.1 抽象方法.processElement()
1.2 非抽象方法.onTimer()
2、Flink中8个不同的处理函数
2.1 ProcessFunction
2.2 KeyedProcessFunction
2.3 ProcessWindowFunction
2.4 ProcessAllWindowFunction
2.5 CoProcessFunction
2.6 ProcessJo…
GZ033 大数据应用开发赛题第10套
2023年全国职业院校技能大赛
赛题第10套 赛项名称: 大数据应用开发
英文名称: Big Data Application Development
赛项组别: 高等职业教育组
赛项编号: GZ033 …
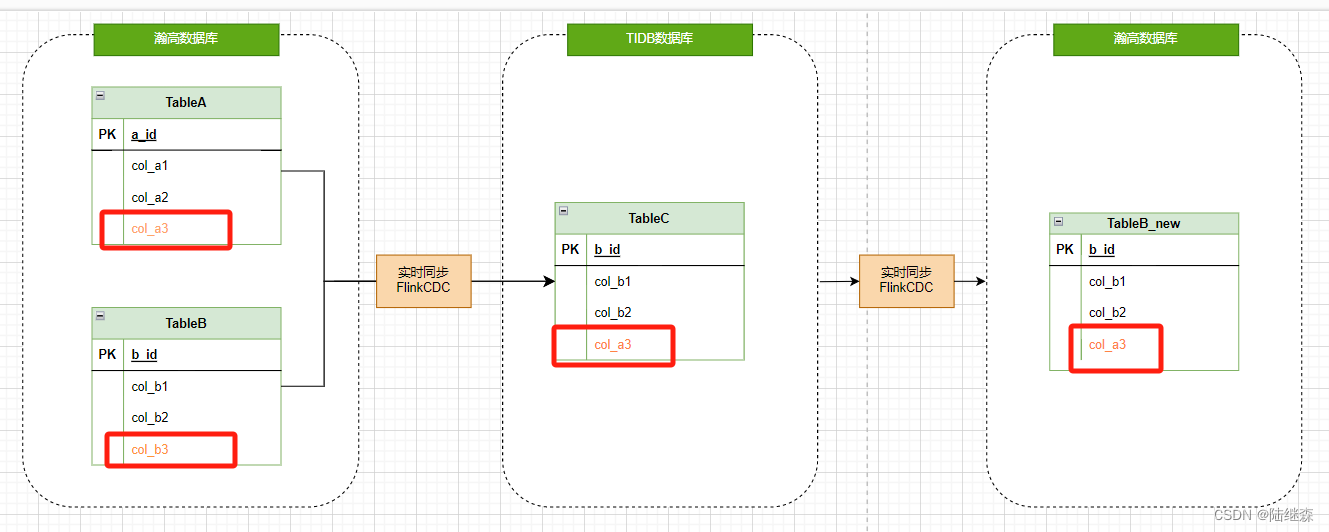
FlinkCDC实现主数据与各业务系统数据的一致性(瀚高、TIDB)
文章末尾附有flinkcdc对应瀚高数据库flink-cdc-connector代码下载地址
1、业务需求 目前项目有主数据系统和N个业务系统,为保障“一数一源”,各业务系统表涉及到主数据系统的字段都需用主数据系统表中的字段进行实时覆盖,这里以某个业务系统的一张表举例说明:业务系统表Ta…
flink的java.lang.IllegalStateException: Buffer pool is destroyed 异常
背景
最近flink的在线应用出现错误java.lang.IllegalStateException: Buffer pool is destroyed,本文记录下这个错误的原因
错误原因
详细的日志堆栈如下:
Caused by: java.lang.IllegalStateException: Buffer pool is destroyed.
at org.apache.flink.runtime…
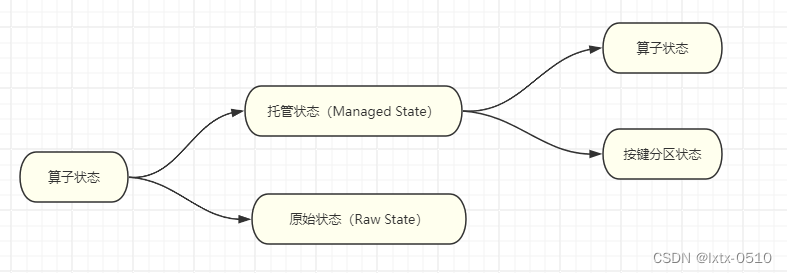
【Flink】状态管理
目录
1、状态概述
1.1 无状态算子
1.2 有状态算子
2、状态分类
编辑 2.1 算子状态
2.1.1 列表状态(ListState)
2.1.2 联合列表状态(UnionListState)
2.1.3 广播状态(BroadcastState)
2.2 按键分…

Flink 替换 Logstash 解决日志收集丢失问题
在某客户日志数据迁移到火山引擎使用 ELK 生态的案例中,由于客户反馈之前 Logstash 经常发生数据丢失和收集性能较差的使用痛点,我们尝试使用 Flink 替代了传统的 Logstash 来作为日志数据解析、转换以及写入 ElasticSearch 的组件,得到了该客…
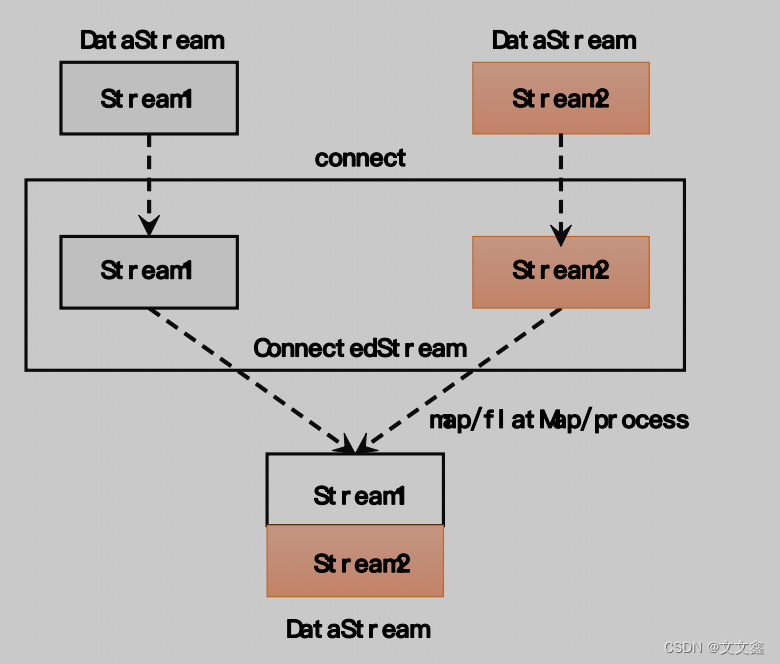
Flink Flink中的合流
一、Flink中的基本合流操作
在实际应用中,我们经常会遇到来源不同的多条流,需要将它们的数据进行联合处理。所以 Flink 中合流的操作会更加普遍,对应的 API 也更加丰富。
二、联合(Union)
最简单的合流操作…

Apache Flink(一):Apache Flink是什么?
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹…
flink源码分析之功能组件(四)-slotpool组件II
简介 本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metrics&…
flink源码分析之功能组件(四)-slotpool组件I
简介 本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metrics&…
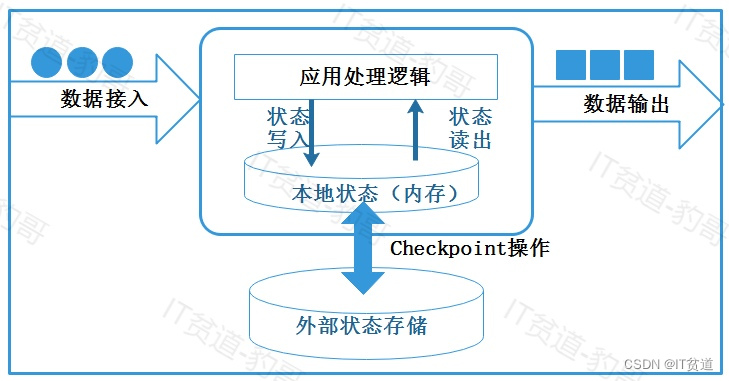
Apache Flink(二):数据架构演变
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹…
【Flink进阶】-- Flink kubernetes operator 快速入门与实战
1、课程目录 2、课程链接 https://edu.csdn.net/course/detail/38831
flink的集成测试
背景
日常测试中我们使用flink的TestHarness只能测试单个算子,很多情况下我们需要集成测试来测试真正的问题,所以在flink中进行集成测试还是非常有必要的,本文就来记录下如何在flink中进行集成测试
flink中进行集成测试
flink中进行集成测…

源码解析flink文件连接源TextInputFormat
背景:
kafka的文件系统数据源可以支持精准一次的一致性,本文就从源码看下如何TextInputFormat如何支持状态的精准一致性
TextInputFormat源码解析
首先flink会把输入的文件进行切分,分成多个数据块的形式,每个数据源算子任务会被分配以读取…
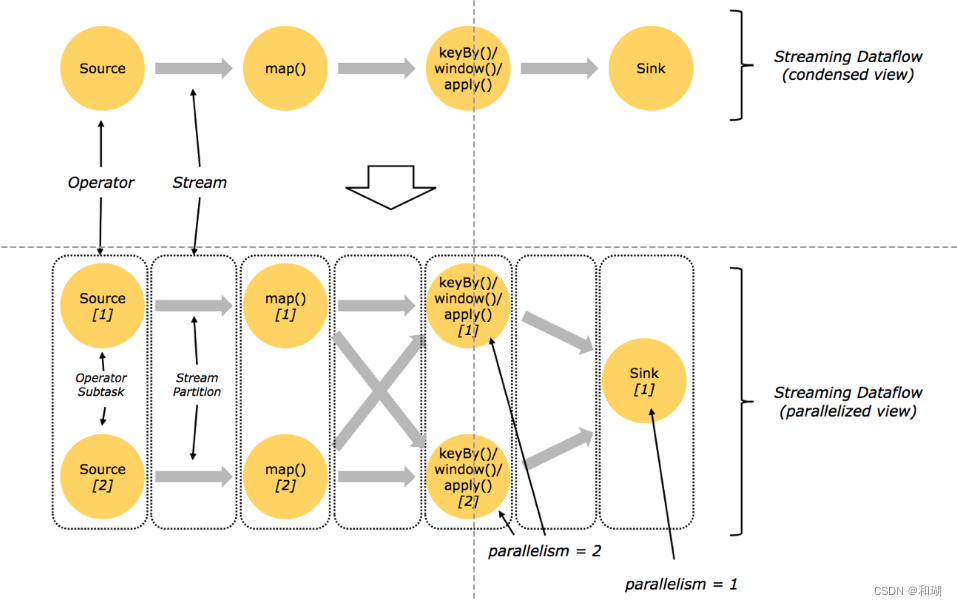
【Flink】Flink核心概念简述
目录 一、Flink 简介二、Flink 组件栈1. API & Libraries 层2. runtime层3. 物理部署层 三、Flink 集群架构四、Flink基本编程模型五、Flink 的优点 一、Flink 简介
Apache Flink 的前身是柏林理工大学一个研究性项目, 在 2014 被 Apache 孵化器所接受…
【flink番外篇】1、flink的23种常用算子介绍及详细示例(1)- map、flatmap和filter
Flink 系列文章
1、Flink 专栏等系列综合文章链接 文章目录 Flink 系列文章一、Flink的23种算子说明及示例1、maven依赖2、java bean3、map4、flatmap5、Filter 本文主要介绍Flink 的3种常用的operator(map、flatmap和filter)及以具体可运行示例进行说明…

flink中处理kafka分区的消息顺序
背景
kafka分区的消息是有序的,那么flink在消费kafka分区的时候消息的顺序是怎么样的呢?还能保持这个有序性吗,本文就来记录下
flink消费kafka分区的顺序性 从上图可知,flink的转换算子比如map,flatMap,f…
flink 1.13.2的pom.xml文件模板
flink 1.13.2的pom.xml文件模板
<?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven…
GZ033 大数据应用开发赛题第07套
2023年全国职业院校技能大赛 赛题第07套 赛项名称: 大数据应用开发 英文名称: Big Data Application Development 赛项组别: 高等职业教育组 赛项编号: GZ033 …

kyuubi整合flink yarn session mode
目录 概述配置flink 配置kyuubi 配置kyuubi-defaults.confkyuubi-env.shhive 验证启动kyuubibeeline 连接使用hive catlogsql测试 结束 概述
flink 版本 1.17.1、kyuubi 1.8.0、hive 3.1.3、paimon 0.5
整合过程中,需要注意对应的版本。
注意以上版本
配置
ky…
Flink优化——数据倾斜(二)
目录
数据倾斜
判断是否存在数据倾斜
数据倾斜的解决
KeyBy之前发生数据倾斜
KeyBy之后发生的数据倾斜
聚合操作存在数据倾斜
窗口聚合操作存在数据倾斜 数据倾斜
判断是否存在数据倾斜
相同 Task 的多个 Subtask 中,个别 Subtask 接收到的数据量明显大于其…
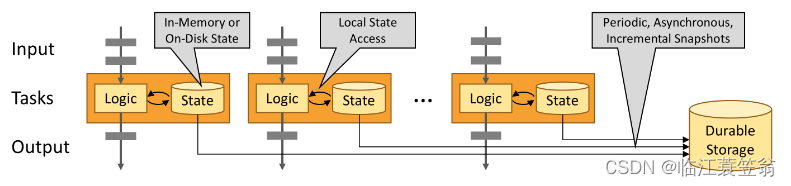
Flink-简介与基础
Flink-简介与基础 一、Flink起源二、Flink数据处理模式1.批处理2.流处理3.Flink流批一体处理 三、Flink架构1.Flink集群2.Flink Program3.JobManager4.TaskManager 四、Flink应用程序五、Flink高级特性1.时间流(Time)和窗口(Window࿰…
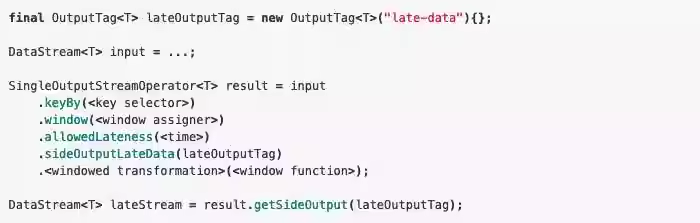
【Flink系列四】Window及Watermark
3.1、window
在 Flink 中 Window 可以将无限流切分成有限流,是处理有限流的核心组件,现在 Flink 中 Window 可以是时间驱动的(Time Window),也可以是数据驱动的(Count Window)。 Flink中的窗口…
【Flink on k8s】- 12 - Flink kubernetes operator 的高级特性
目录
1、自动伸缩
1.1 工作原理
1.2 Job 要求和限制
1.2.1 要求
1.2.2 限制
【flink番外篇】1、flink的23种常用算子介绍及详细示例(3)-window、distinct、join等
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…
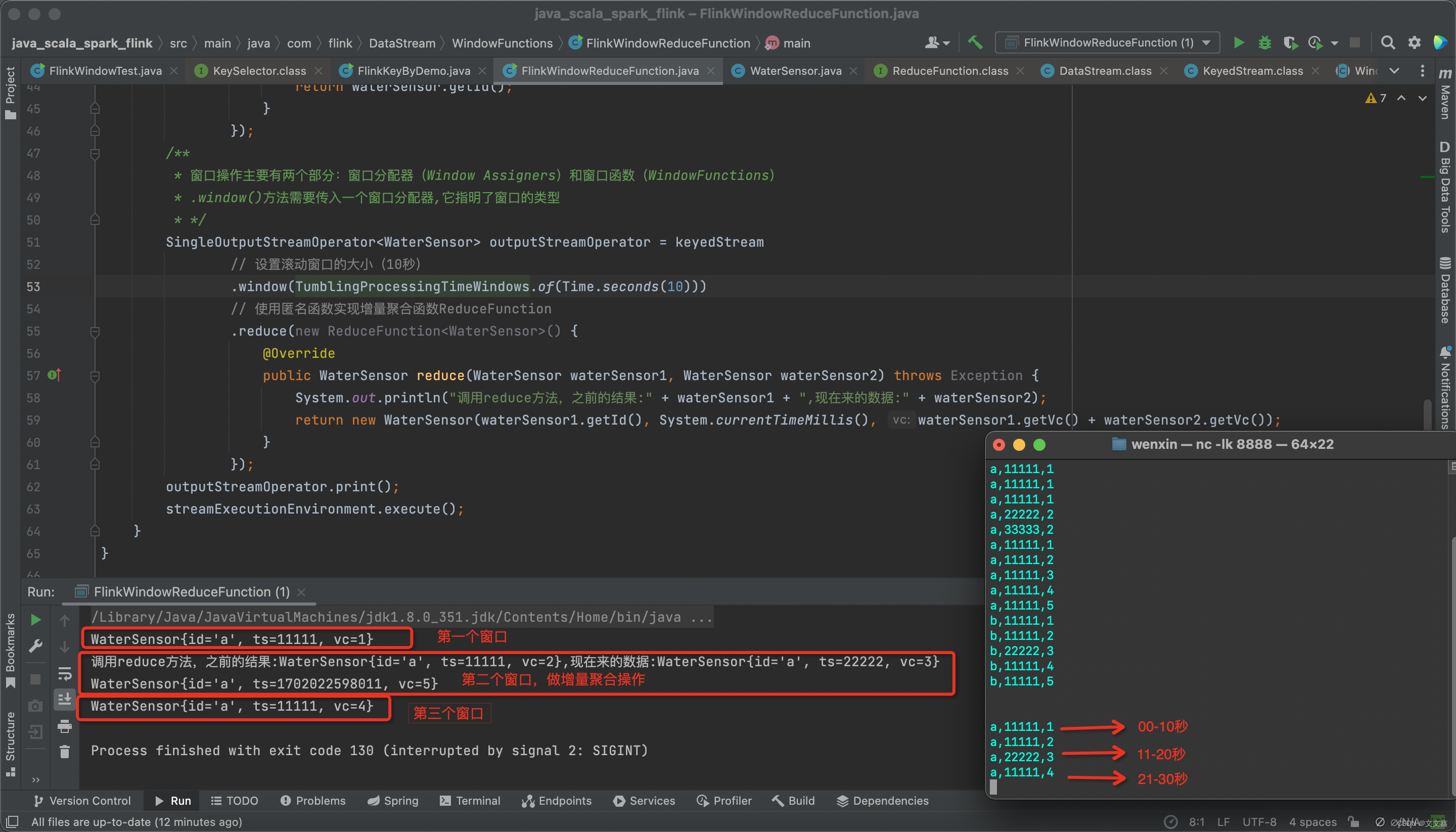
Flink Window中典型的增量聚合(ReduceFunction / AggregateFunction)
一、什么是增量聚合函数
在Flink Window中定义了窗口分配器,我们只是知道了数据属于哪个窗口,可以将数据收集起来了;至于收集起来到底要做什么,其实还完全没有头绪,这也就是窗口函数所需要做的事情。所以在窗口分配器…
flink-cdc同步mysql到doris建设数据仓储最佳实践
项目背景
当前需要搭建数据仓储,横向对比了多个数据库最终选定doris,正常的单表,多表数据同步已经完成开发。但是单全量表结构同步还是没有完成,发现flink有这个功能,现在进行使用
开始使用
废话不多说,…
轻松通关Flink第24讲:Flink 消费 Kafka 数据业务开发
在上一课时中我们提过在实时计算的场景下,绝大多数的数据源都是消息系统,而 Kafka 从众多的消息中间件中脱颖而出,主要是因为高吞吐、低延迟的特点;同时也讲了 Flink 作为生产者像 Kafka 写入数据的方式和代码实现。这一课时我们将…
编译 Flink代码
构建环境
JDK1.8以上和Maven 3.3.x可以构建Flink,但是不能正确地遮盖某些依赖项。Maven 3.2.5会正确创建库。所以这里使用为了减少问题选择 Maven3.2.5版本进行构建。要构建单元测试,请使用Java 8以上,以防止使用PowerMock运行器的单元测试失…

Apache Flink(十一):Flink集群部署-Standalone集群部署
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录
1. 节点划分

Flink反压如何查看和优化
我们在使用Flink程序进行流式数据处理时,由于种种原因难免会遇到性能问题,如我们在使用Flink程序消费kafka数据,可能会遇到kafka数据有堆积的情况,并且随着时间的推移,数据堆积越来越多,这就表名消费处理数…

【Flink系列七】TableAPI和FlinkSQL初体验
Apache Flink 有两种关系型 API 来做流批统一处理:Table API 和 SQL
Table API 是用于 Scala 和 Java 语言的查询API,它可以用一种非常直观的方式来组合使用选取、过滤、join 等关系型算子。 Flink SQL 是基于 Apache Calcite 来实现的标准 SQL。无论输…
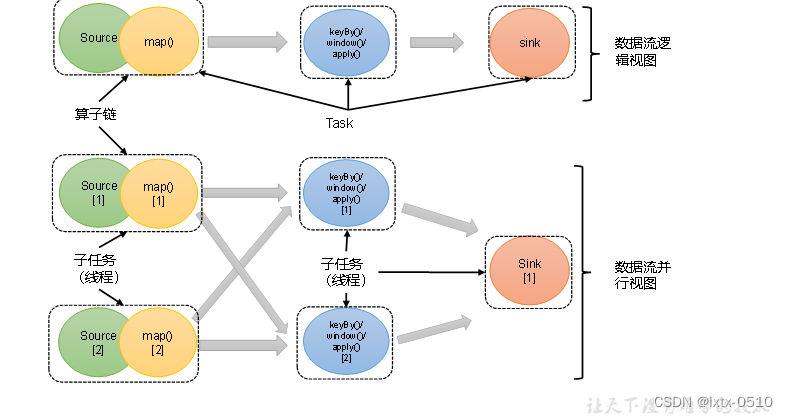
【Flink】核心概念:并行度与算子链
并行度(Parallelism)
当要处理的数据量非常大时,我们可以把一个算子操作,“复制”多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多个并行的“子任务”&#x…
《十堂课学习 Flink SQL》第三章:Flink SQL 环境搭建
本章内容包括安装和配置 Flink 环境;Flink 官方示例代码解读;使用 Flink SQL CLI 进行基本查询 以及 Flink SQL 连接外部数据源。所有内容均会以公开源码,希望能够帮助到大家。可以的话点个免费的赞吧 ~ 3.1 安装与配置 Flink 环境
3.1.1 ja…
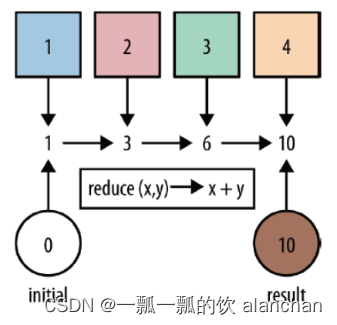
【flink番外篇】1、flink的23种常用算子介绍及详细示例(2)- keyby、reduce和Aggregations
Flink 系列文章
1、Flink 专栏等系列综合文章链接 文章目录 Flink 系列文章一、Flink的23种算子说明及示例6、KeyBy7、Reduce8、Aggregations 本文主要介绍Flink 的3种常用的operator(keyby、reduce和Aggregations)及以具体可运行示例进行说明. 如果需要…
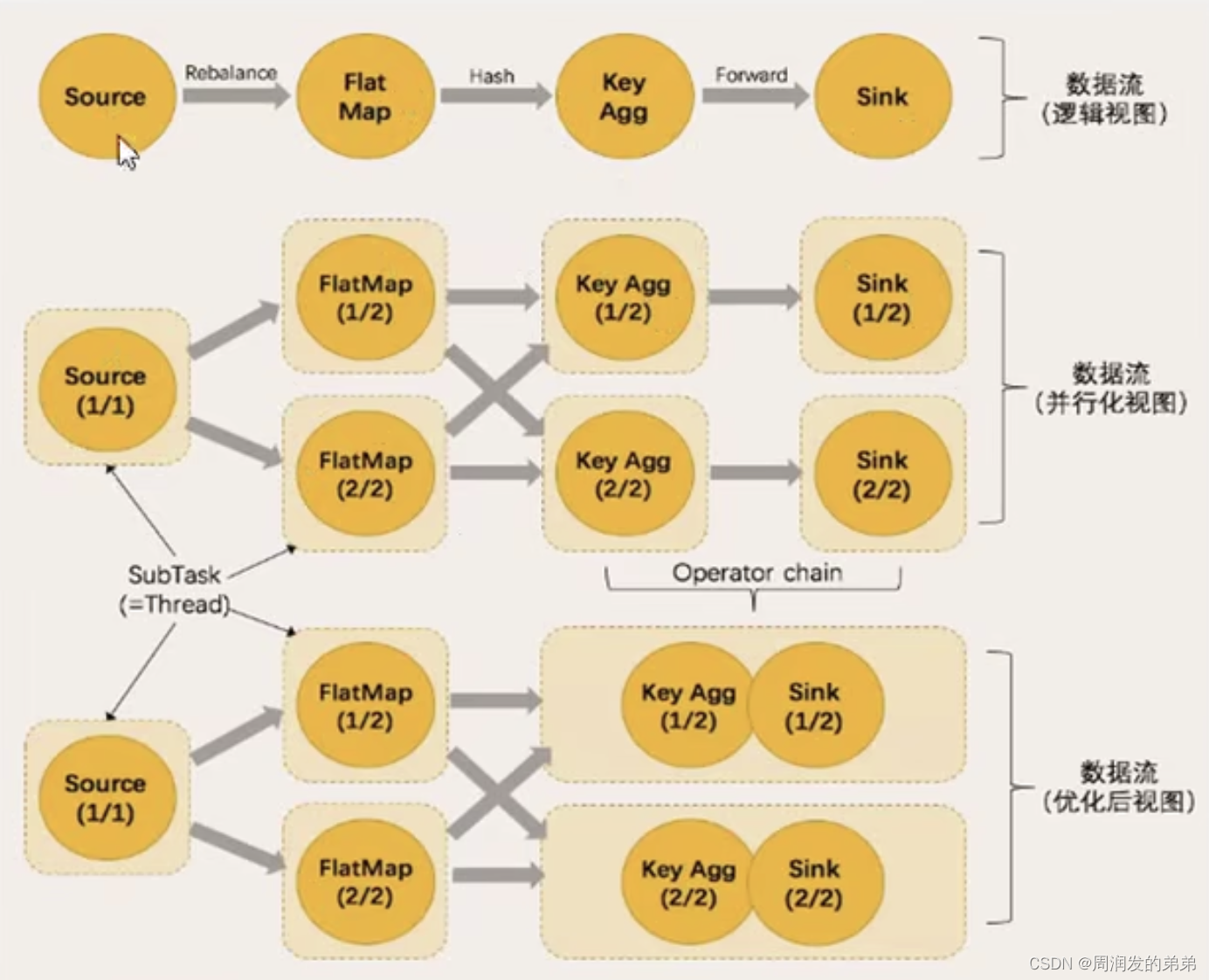
【Flink系列三】数据流图和任务链计算方式
上文介绍了如何计算并行度和slot的数量,本文介绍Flink代码提交后,如何生成计算的DAG数据流图。
程序和数据流图 所有的Flink程序都是由三部分组成的:Source、Transformation和Sink。Source负责读取数据源,Transformation利用各种…
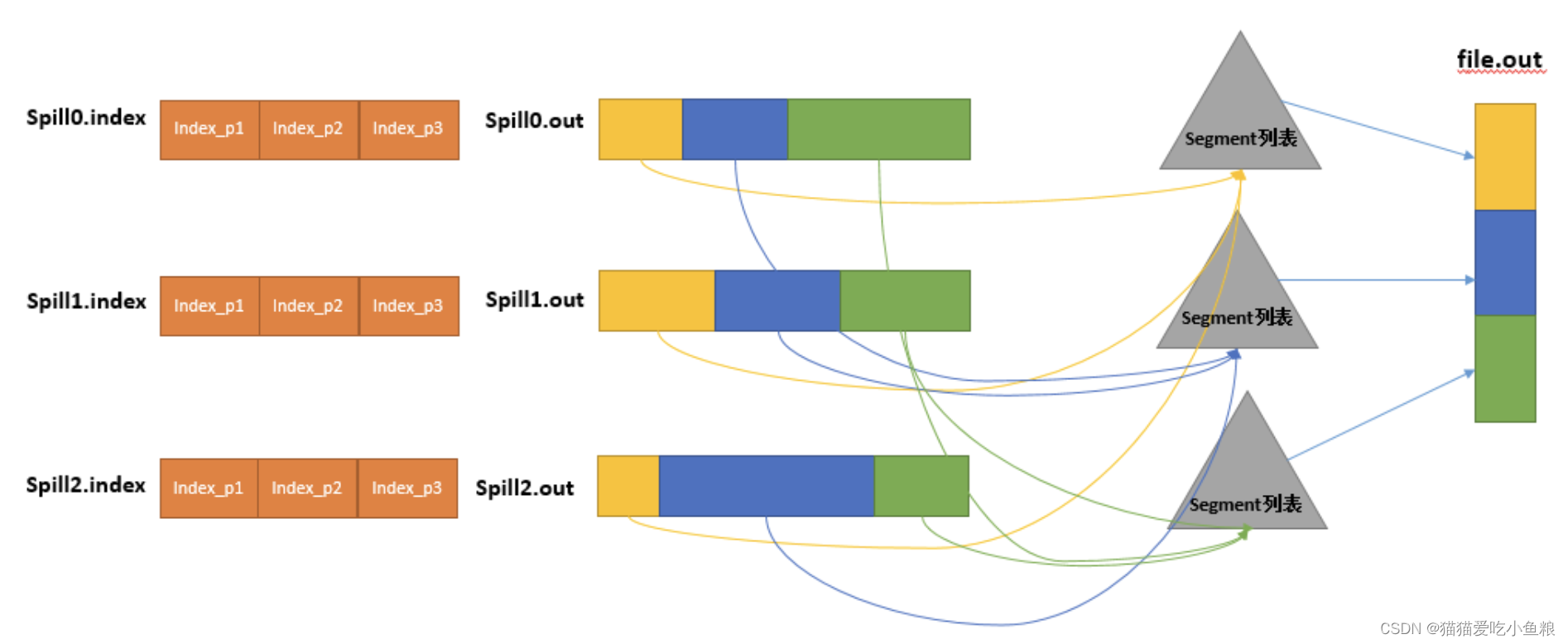
Flink Shuffle、Spark Shuffle、Mr Shuffle 对比
总结:
1、Flink ShufflePipelined Shuffle:上游 Subtask 所在 TaskManager 直接通过网络推给下游 Subtask 的 TaskManager;Blocking Shuffle:
Hash Shuffle-将数据按照下游每个消费者一个文件的形式组织;
Sort-Merge …
【Flink名称解释一】什么是cataLog
Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。 数据处理最关键的方面之一是管理元数据。 元数据可以是临时的,例如临时表、或者通过 TableEnvironment 注册的 UDF。 元数据也可以是持久化的&#x…
45、Flink 的指标体系介绍及验证(3)- 完整版
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
FLink开发遇到java 泛型报错
FLink 开发遇到java报错
/Library/jdk1.8.0_372.jdk/Contents/Home/bin/java -javaagent:/Applications/IntelliJ IDEA.app/Contents/lib/idea_rt.jar52448:/Applications/IntelliJ IDEA.app/Contents/bin -Dfile.encodingUTF-8 -classpath /Library/jdk1.8.0_372.jdk/Content…
flink源码分析 - 命令行参数解析-CommandLineParser
flink版本: flink-1.11.2
调用位置:
org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint#main 代码位置:
flink核心命令行解析器: org.apache.flink.runtime.entrypoint.parser.CommandLineParser
/** Licensed to the Apache Software Foundati…
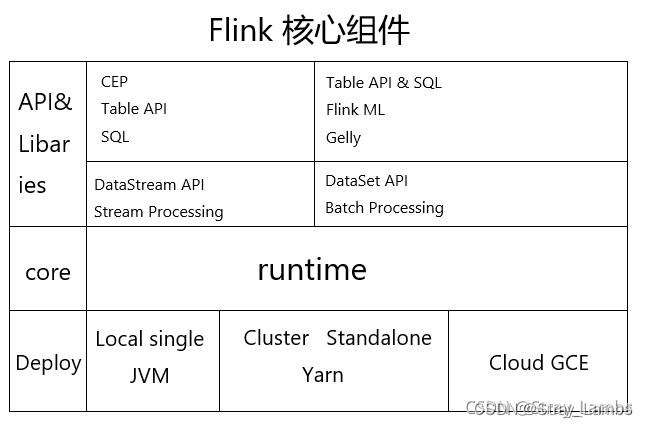
Flink面试题与详解
Flink面试题目合集
从牛客网上找到的一些面试题,如果还有其他的,欢迎大家补充。 1、能否详细描述下Apache Flink的架构组件和其工作原理?请介绍一下Flink on YARN部署模式的工作原理。
官网图: 由两个部分组成,JM&am…
【Flink SQL API体验数据湖格式之paimon】
前言
随着大数据技术的普及,数据仓库的部署方式也在发生着改变,之前在部署数据仓库项目时,首先想到的是选择国外哪家公司的产品,比如:数据存储会从Oracle、SqlServer中或者Mysql中选择,ETL工具会从Informa…

以csv为源 flink 创建paimon 临时表相关 join 操作
目录 概述配置关键配置测试启动 kyuubi执行配置中的命令 bug解决bug01bug02 结束 概述
目标:生产中有需要外部源数据做paimon的数据源,生成临时表,以使用与现有正式表做相关统计及 join 操作。
环境:各组件版本如下
kyuubi 1.8…
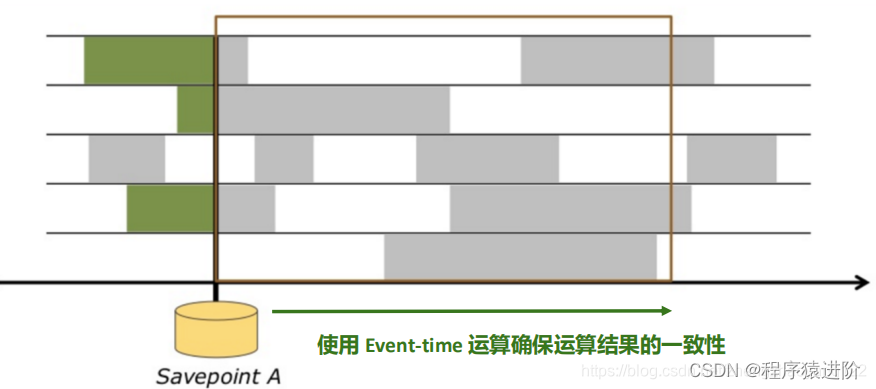
Flink 有状态流式处理
传统批次处理方法 【1】持续收取数据(kafka等),以window时间作为划分,划分一个一个的批次档案(按照时间或者大小等); 【2】周期性执行批次运算(Spark/Stom等);…
【CDP】CDP 集群通过Knox 访问Yarn Web UI,无法跳转到Flink Web UI 问题解决
一、前言
记录下在CDP 环境中,通过Knox 访问Yarn Web UI,无法跳转到Flink Web UI 的BUG 解决方法。
二、问题复现
登录 Knox Web UI 找到任一 Flink 任务 点击 ApplicationMaster 跳转 Flink WEB UI 出问题
内容空白,无法正常跳转到…
Flink之状态编程
状态
对人来说,状态是指当下的各种条件的具体情况就是状态;对于数据来说,状态就是当下需要维护的额外的数据。
算子
无状态算子:无状态算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果。有状态…

【源码解析】flink sql执行源码概述:flink sql执行过程中有哪些阶段,这些阶段的源码大概位置在哪里
文章目录 一. sql执行流程源码分析1. Sql语句解析成语法树阶段(SQL - > SqlNode)2. SqlNode 验证(SqlNode – >Operation)3. 语义分析(Operation - > RelNode)4. 优化阶段(RelNode - &…
Temporal table join requires an equality condition on fields of table
报错信息
org.apache.flink.table.api.TableException: Temporal table join requires an equality condition on fields of table *******************
发生地址
flinksql 维表关联
解决
关联条件必须等值关联 也就是必须是等号,并且 关联条件两边要确定数据类…

Flink CDC 1.0至3.0回忆录
Flink CDC 1.0至3.0回忆录 一、引言二、CDC概述三、Flink CDC 1.0:扬帆起航3.1 架构设计3.2 版本痛点 四、Flink CDC 2.0:成长突破4.1 DBlog 无锁算法4.2 FLIP-27 架构实现4.3 整体流程 五、Flink CDC 3.0:应运而生六、Flink CDC 的影响和价值…
【大数据】Hudi HMS Catalog 完全使用指南
Hudi HMS Catalog 完全使用指南 1.Hudi HMS Catalog 基本介绍2.在 Flink 中写入数据3.在 Flink SQL 中查看数据4.在 Spark 中查看数据5.在 Hive 中查看数据 1.Hudi HMS Catalog 基本介绍
功能亮点:当 Flink 和 Spark 同时接入 Hive Metastore(HMS&#…
Flink 日志总结
前言
总结一下 Flink 项目代码打印日志的配置。
目的
默认情况下不会打印Flink日志信息,只会抛出缺少日志类警告,比如上篇文章中的 flink-hbase 代码就没有打印 Flink 日志信息。有些情况下我们需要从 Flink 日志中获取一下信息,对于我们学习 Flink 或者解决问题都有帮助…
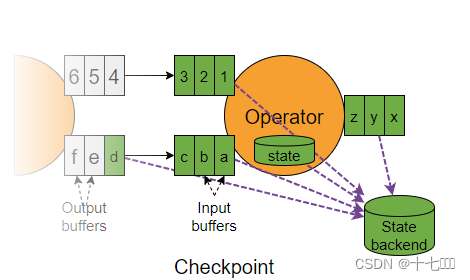
Flink的容错机制
容错机制
容错:指出错后不影响数据的继续处理,并且恢复到出错前的状态。 检查点:用存档读档的方式,将之前的某个时间点的所有状态保存下来,故障恢复继续处理的结果应该和发送故障前完全一致,这就是所谓的检…
【Flink on k8s】- 15 - 将 flink on yarn 迁移到 flink on k8s
目录
1、集群现状
2、与 Flink on yarn 对比
2.1 Flink on yarn 的一些痛点
2.2 Flink on k8s 的一些优点
Flink 输出至 Redis
【1】引入第三方Bahir提供的Flink-redis相关依赖包
<!-- https://mvnrepository.com/artifact/org.apache.bahir/flink-connector-redis -->
<dependency><groupId>org.apache.bahir</groupId><artifactId>flink-connector-redis_2.11</arti…
【Flink-Kafka-To-RocketMQ】使用 Flink 自定义 Sink 消费 Kafka 数据写入 RocketMQ
【Flink-Kafka-To-RocketMQ】使用 Flink 自定义 Sink 消费 Kafka 数据写入 RocketMQ 1)准备环境2)代码实现2.1.主程序2.2.conf2.2.1.ConfigTools 2.3.utils2.3.1.DBConn2.3.2.CommonUtils 2.4.function2.4.1.MqSinkFunction 2.5.resources2.5.1.appconfi…
Flink-状态后端
状态后端是一个“开箱即用”的组件,可以在不改变应用程序逻辑的情况下独立配置。 Flink中提供了两类不同的状态后端,一种是“哈希表状态后端”(HashMapStateBackend),另一种是“内嵌RocksDB状态后端”(Embe…
Flink 数据类型 TypeInformation信息
Flink流应用程序处理的是以数据对象表示的事件流。所以在Flink内部,我么需要能够处理这些对象。它们需要被序列化和反序列化,以便通过网络传送它们;或者从状态后端、检查点和保存点读取它们。为了有效地做到这一点,Flink需要明确知…

掌握实时数据流:使用Apache Flink消费Kafka数据
导读:使用Flink实时消费Kafka数据的案例是探索实时数据处理领域的绝佳方式。不仅非常实用,而且对于理解现代数据架构和流处理技术具有重要意义。 理解Flink和Kafka
Apache Flink Apache Flink 是一个在有界数据流和无界数据流上进行有状态计算分布式处理…

Flink Has Become the De-facto Standard of Streaming Compute
摘要:本文整理自 Apache Flink 中文社区发起人、阿里巴巴开源大数据平台负责人王峰(莫问),在 Flink Forward Asia 2023 主会场的分享。Flink 从 2014 年诞生之后,已经发展了将近 10 年,尤其是最近这些年得到…
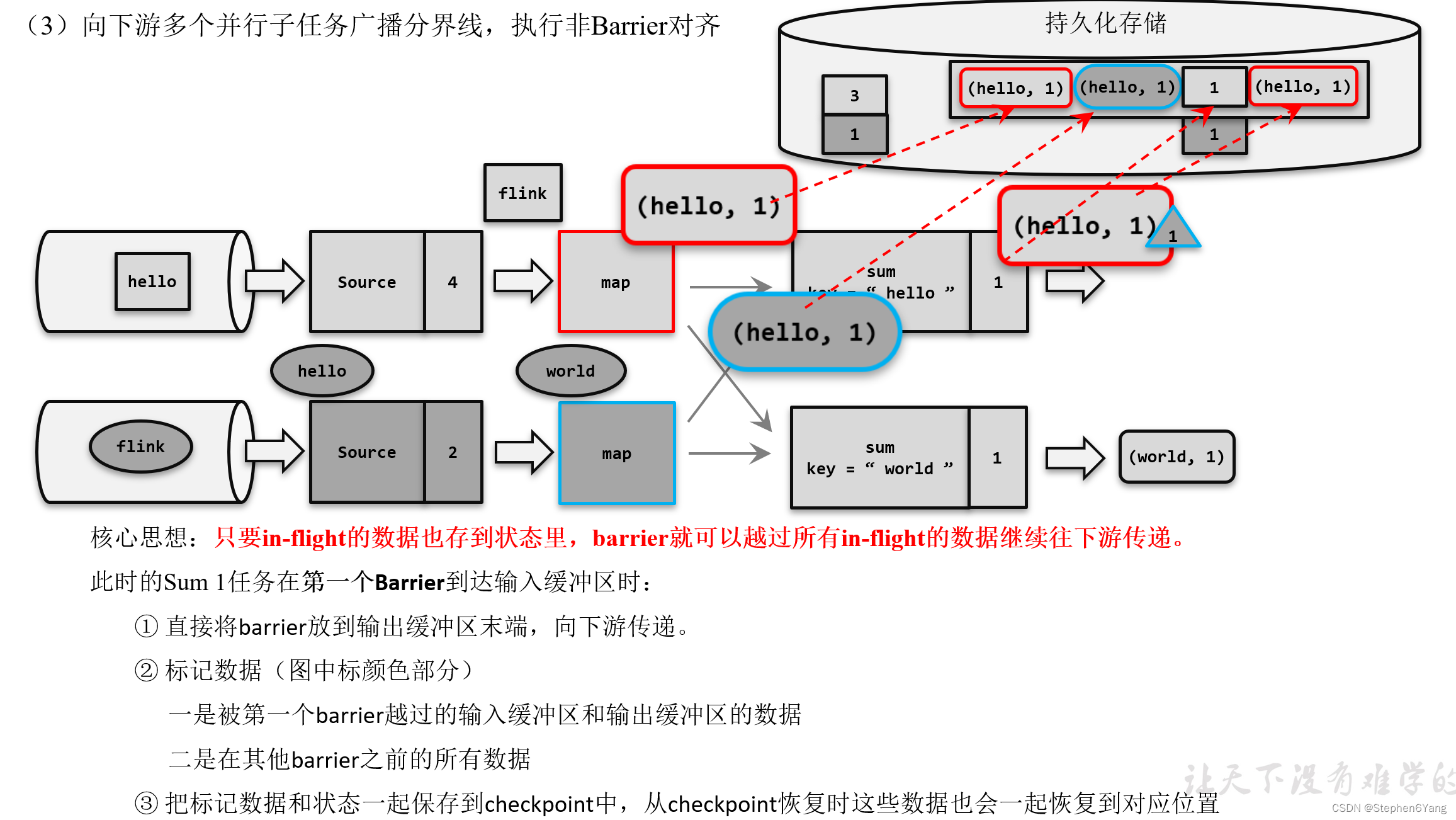
Flink-容错机制checkpoint
检查点的保存
周期性的触发保存
“随时存档”确实恢复起来方便,可是需要我们不停地做存档操作。如果每处理一条数据就进行检查点的保存,当大量数据同时到来时,就会耗费很多资源来频繁做检查点,数据处理的速度就会受到影响。所以…
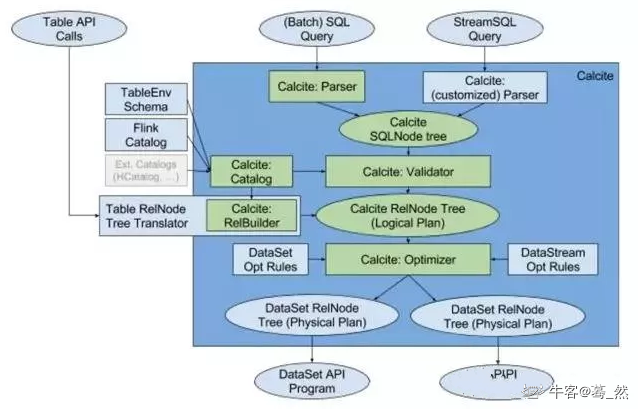
【大数据面试】Flink面试题附答案
目录
✅Flink介绍、特点、应用场景
✅Flink与Spark Streaming的区别
✅Flink有哪些部署模式
✅Flink架构
✅怎么设置并行度?
✅什么是算子链?
✅什么是任务槽(Task Slots)?
✅任务槽和并行度的关系
✅Flink作…
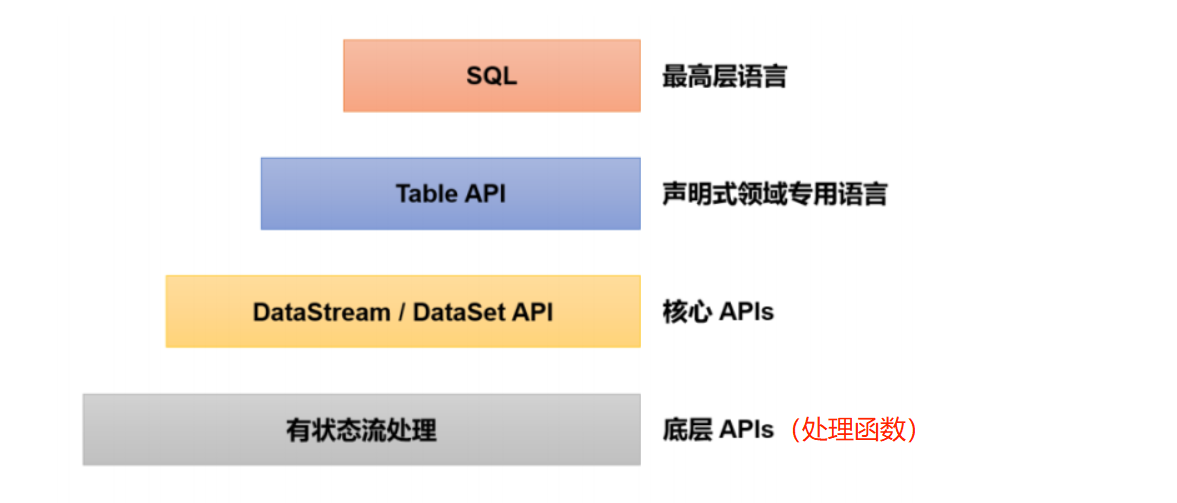
Flink(十)【处理函数】
前言 冬天学习成本太高了,每天冻得要死,自习室人满为患,确实是辛苦。学校基本的硬件条件差的一批(图书馆贼小贼偏僻、老教室暖气还没有地板热、空教室还得自己一个一个挨着找),个体无法改变环境只能顺应了&…
【Flink-Kafka-To-ClickHouse】使用 Flink 实现 Kafka 数据写入 ClickHouse
【Flink-Kafka-To-ClickHouse】使用 Flink 实现 Kafka 数据写入 ClickHouse 1)导入相关依赖2)代码实现2.1.resources2.1.1.appconfig.yml2.1.2.log4j.properties2.1.3.log4j2.xml2.1.4.flink_backup_local.yml 2.2.utils2.2.1.DBConn2.2.2.CommonUtils2.…

Flink 状态管理与容错机制(CheckPoint SavePoint)的关系
一、什么是状态
无状态计算的例子: 例如一个加法算子,第一次输入235那么以后我多次数据23的时候得到的结果都是5。得出的结论就是,相同的输入都会得到相同的结果,与次数无关。 有状态计算的例子: 访问量的统计&#x…
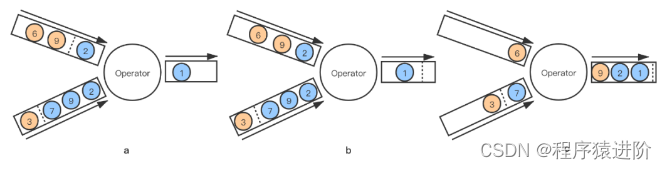
Checkpoint 执行机制原理解析
在介绍Checkpoint的执行机制前,我们需要了解一下state的存储,因为state是Checkpoint进行持久化备份的主要角色。Checkpoint作为Flink最基础也是最关键的容错机制,Checkpoint快照机制很好地保证了Flink应用从异常状态恢复后的数据准确性。同时…

Apache Flink(四):Flink 其他实时计算框架对比
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 根据前文描述我们知道Flink主要处…
![Flink 运行时[Runtime] 整体架构](https://img-blog.csdnimg.cn/direct/c3ba18c96bf14152aca1463de7a3b9d7.png)
Flink 运行时[Runtime] 整体架构
一、基本组件栈
在Flink整个软件架构体系中,同样遵循着分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富且友好的接口。从下图中可以看出整个Flink的架构体系基本上可以分为三层,由上往下依次是 …
FlinkSQL窗口实例分析
Windowing TVFs
Windowing table-valued functions (Windowing TVFs),即窗口表值函数 注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区,即存在:group by window_start,wind…
Flink 输出至 Elasticsearch
【1】引入pom.xml依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-elasticsearch6_2.12</artifactId><version>1.10.0</version>
</dependency>【2】ES6 Scala代码,自动导入的…
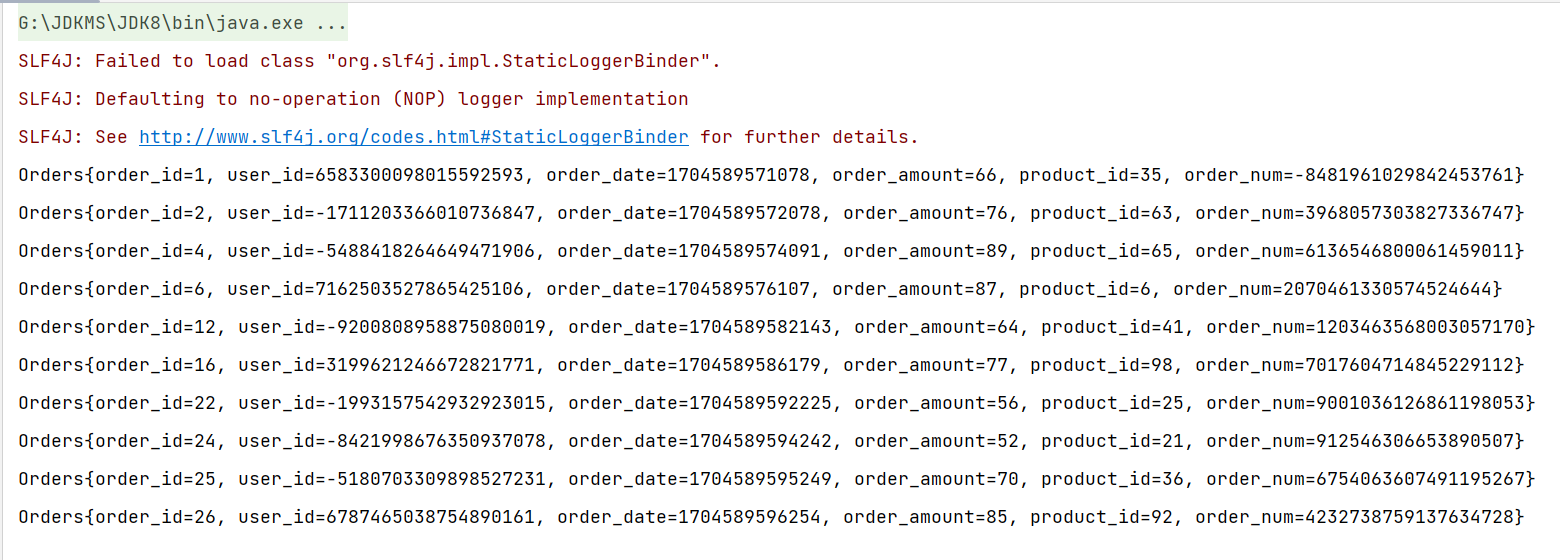
FlinkAPI开发之自定义函数UDF
案例用到的测试数据请参考文章: Flink自定义Source模拟数据流 原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048
概述
用户自定义函数(user-defined function,UDF),即用户可以根据…
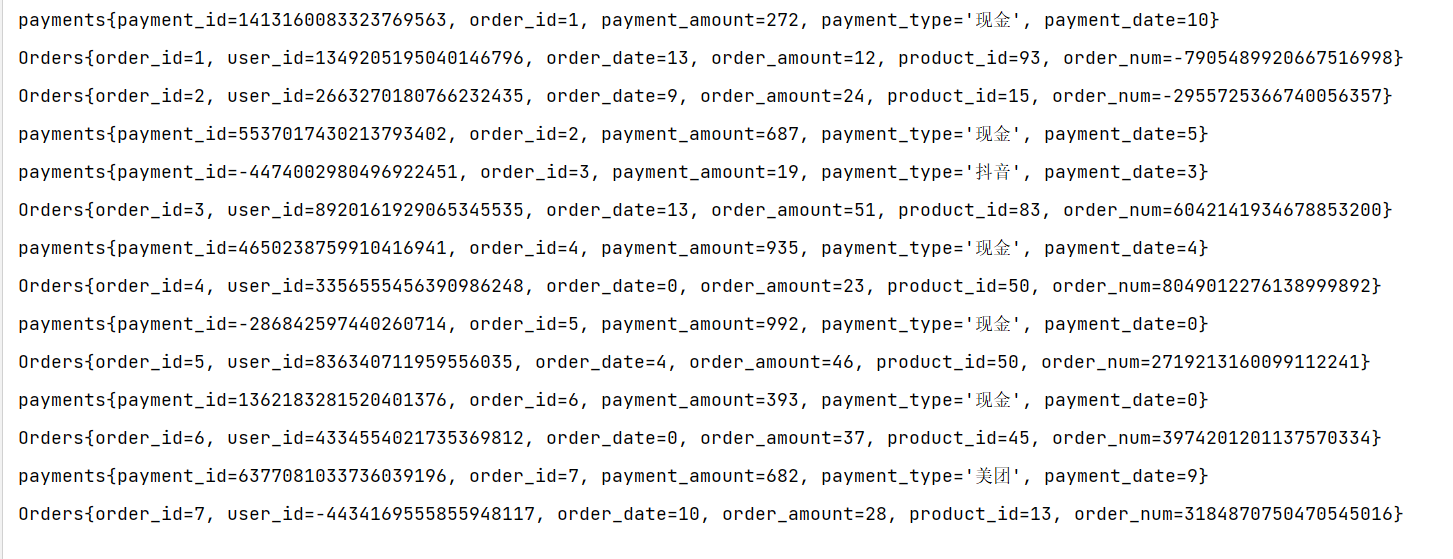
Flink自定义Source模拟数据流
maven依赖
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.…
Flink实时电商数仓(八)
用户域登录各窗口汇总表
主要任务:从kafka页面日志主题读取数据,统计 七日回流用户:之前活跃的用户,有一段时间不活跃了,之后又开始活跃,称为回流用户当日独立用户数:同一个用户当天重复登录&a…
Flink实时电商数仓(九)
用户注册汇总表
需求分析
统计各窗口的注册用户数,写入Doris
思路分析
读取kafka用户注册主题数据转换数据结构 string -> JSONObject->javaBean使用user_info表中的数据代表用户注册设置水位线开窗聚合写入Doris
具体实现
创建用户注册统计类继承BaseA…
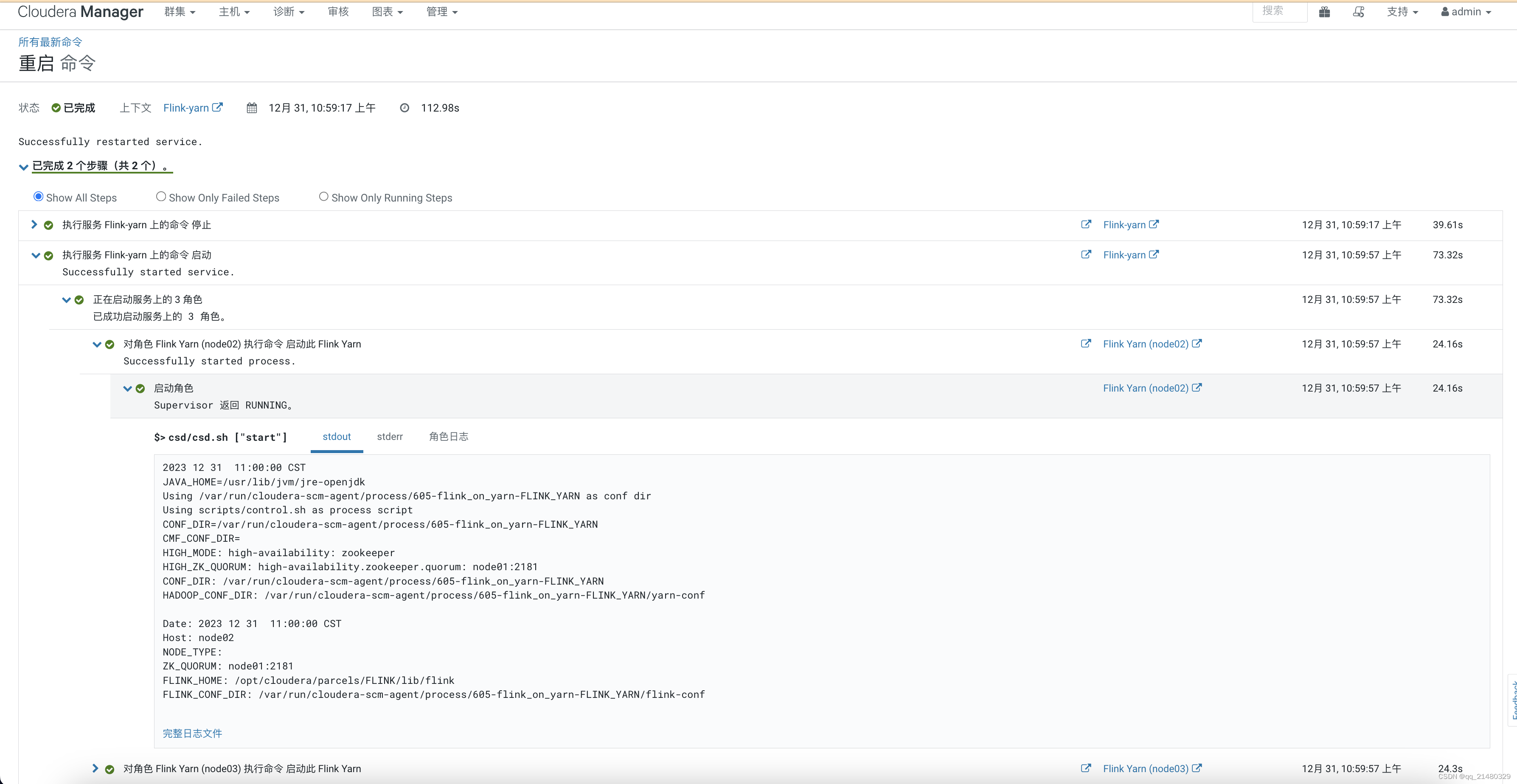
CDH 6.3.2集成flink 1.18 zookeeper版本不匹配Flink-yarn启动失败
CDH 6.3.2集成flink 1.18 zookeeper版本不匹配Flink-yarn不能正常启动,而在CHD Web页面,flink日志报错提示不明确,不能定位具体错误。CM WEB启动失败错误日志如下图所示: CM查看完成错误日志
[31/Dec/2023 10:45:09 0000] 26000…
Flink学习-处理函数
简介
处理函数是Flink底层的函数,工作中通常用来做一些更复杂的业务处理,处理函数分好几种,主要包括基本处理函数,keyed处理函数,window处理函数。
Flink提供了8种不同处理函数:
ProcessFunction&#x…
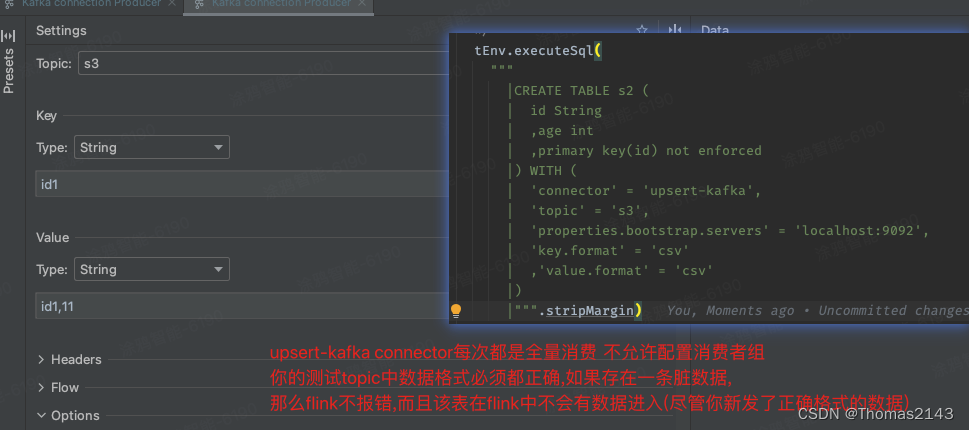
为什么我的flink upsert-kafka 没有数据输出
我写了测试数据到kafka 为什么upsert-kafka 没有数据打印? 测试代码
package com.yy.state.OperatorStateTTLimport org.apache.flink.configuration.{Configuration, RestOptions}
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flin…

PiflowX组件-WriteToUpsertKafka
WriteToUpsertKafka组件
组件说明
以upsert方式往Kafka topic中写数据。
计算引擎
flink
有界性
Streaming Upsert Mode
组件分组
kafka
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子kafka_h…
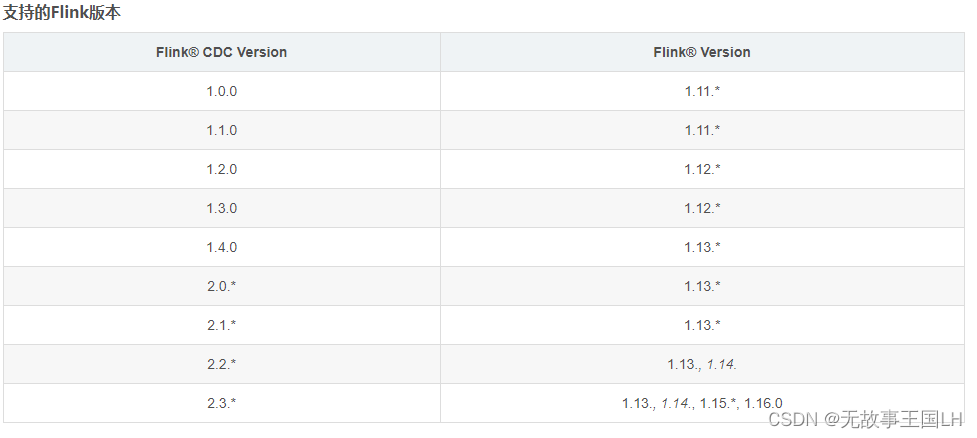
Flink CDC使用
Flink 环境准备
Flink 版本对应的CDC版本 两个jar包上传到flink bin目录下
flink-sql-connector-mysql-cdc
mysql-connector-java
重启Flink集群

深入理解 Flink(一)Flink 架构设计原理
大数据分布式计算引擎设计实现剖析
MapReduce
MapReduce 执行引擎解析 MapReduce 的组件设计实现图 Spark
执行引擎解析 Spark 相比于 RM 的真正优势的地方在哪里:(Simple、Fast、Scalable、Unified)
DAG 引擎中间计算结果可以进行内存持…

PiflowX组件-JDBCWrite
JDBCWrite组件
组件说明
使用JDBC驱动向任意类型的关系型数据库写入数据。
计算引擎
flink
有界性
Sink: Batch
Sink: Streaming Append & Upsert Mode
组件分组
Jdbc
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默…
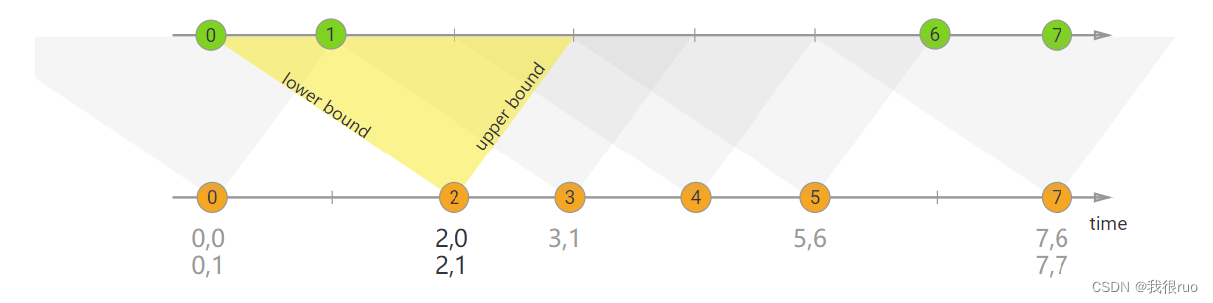
深入理解 Flink(四)Flink Time+WaterMark+Window 深入分析
Flink Window 常见需求背景
需求描述
每隔 5 秒,计算最近 10 秒单词出现的次数 —— 滑动窗口 每隔 5 秒,计算最近 5 秒单词出现的次数 —— 滚动窗口
关于 Flink time 种类 TimeCharacteristic ProcessingTimeIngestionTimeEventTime
WindowAssign…
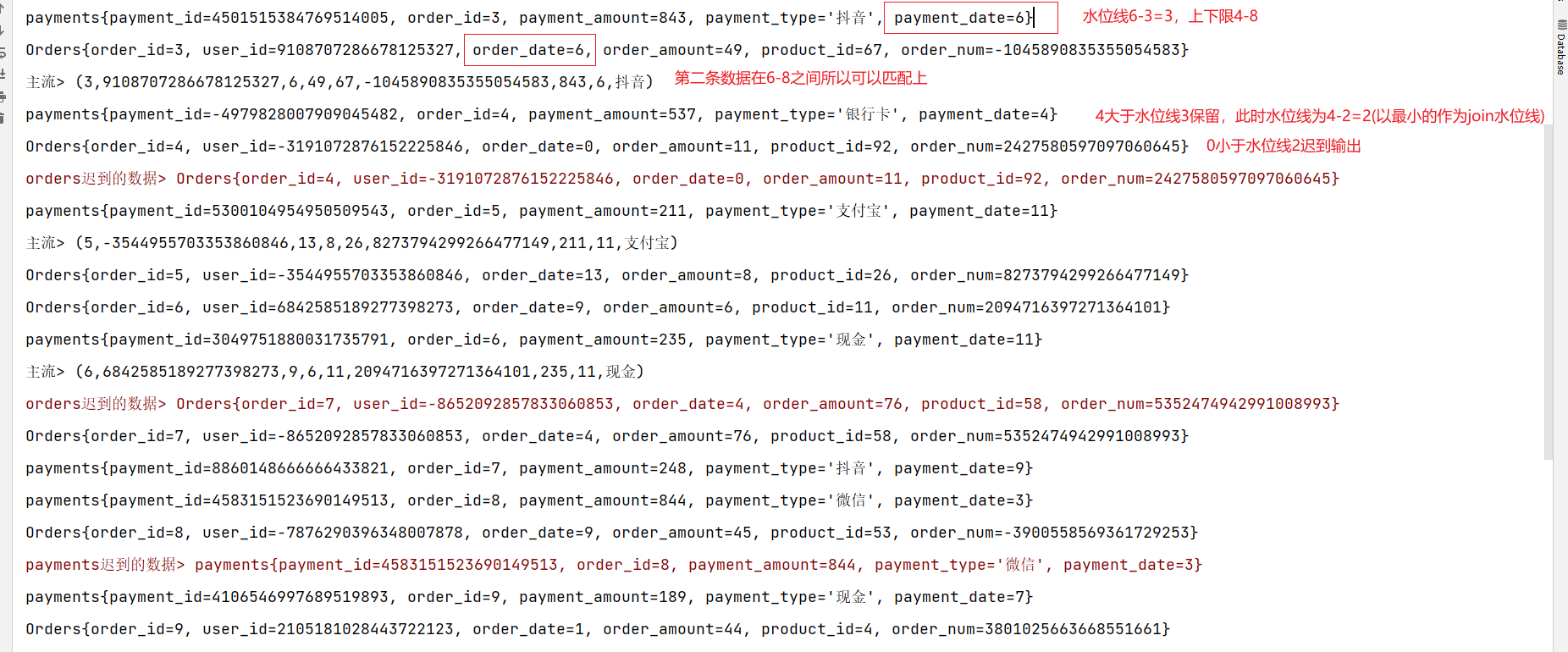
FlinkAPI开发之数据合流
案例用到的测试数据请参考文章: Flink自定义Source模拟数据流 原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048
概述
在实际应用中,我们经常会遇到来源不同的多条流,需要将它们的数据进行联合处理。所以…
自定义Flink SourceFunction定时读取数据库
文章目录 前言一、自定义Flink SourceFunction定时读取数据库二、java代码实现总结 前言
Source 是Flink获取数据输入的地方,可以用StreamExecutionEnvironment.addSource(sourceFunction) 将一个 source 关联到你的程序。Flink 自带了许多预先实现的 source funct…

基于Hologres+Flink的曹操出行实时数仓建设作者:林震|曹操出行实时计算负责人
作者:林震|曹操出行实时计算负责人
曹操出行业务背景介绍
曹操出行创立于2015年5月21日,是吉利控股集团布局“新能源汽车共享生态”的战略性投资业务,以“科技重塑绿色共享出行”为使命,将全球领先的互联网、车联网、…
【flink番外篇】13、Broadcast State 模式示例(完整版)
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…
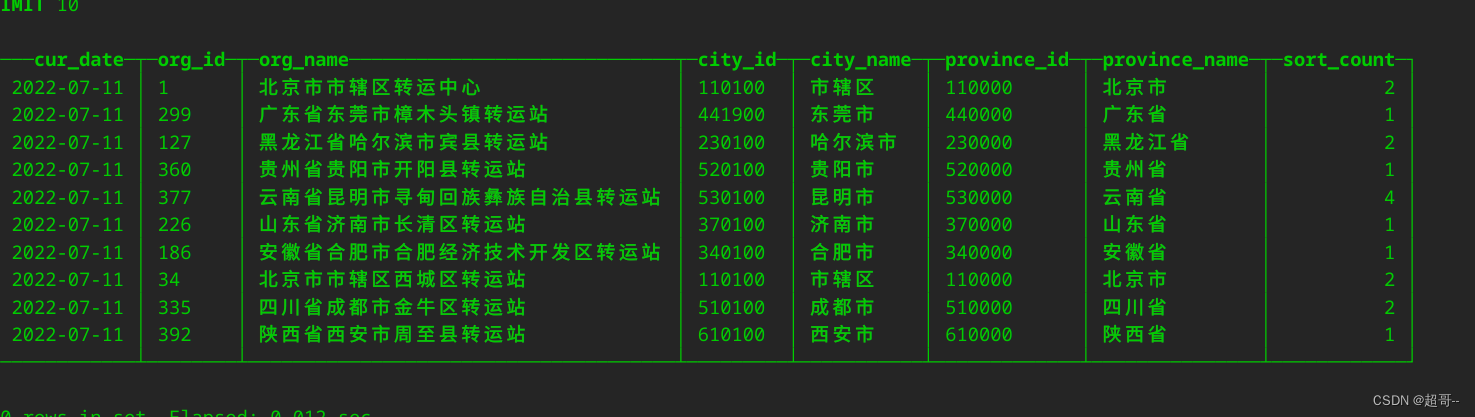
物流实时数仓:数仓搭建(DWS)一
系列文章目录
物流实时数仓:采集通道搭建 物流实时数仓:数仓搭建 物流实时数仓:数仓搭建(DIM) 物流实时数仓:数仓搭建(DWD)一 物流实时数仓:数仓搭建(DWD&am…

【大数据】Flink 详解(十):SQL 篇 Ⅲ
《Flink 详解》系列(已完结),共包含以下 10 10 10 篇文章:
【大数据】Flink 详解(一):基础篇【大数据】Flink 详解(二):核心篇 Ⅰ【大数据】Flink 详解&…
flink1.14.5使用CDH6.3.2的yarn提交作业
使用CDH6.3.2安装了hadoop集群,但是CDH不支持flink的安装,网上有CDH集成flink的文章,大都比较麻烦;但其实我们只需要把flink的作业提交到yarn集群即可,接下来以CDH yarn为基础,flink on yarn模式的配置步骤…
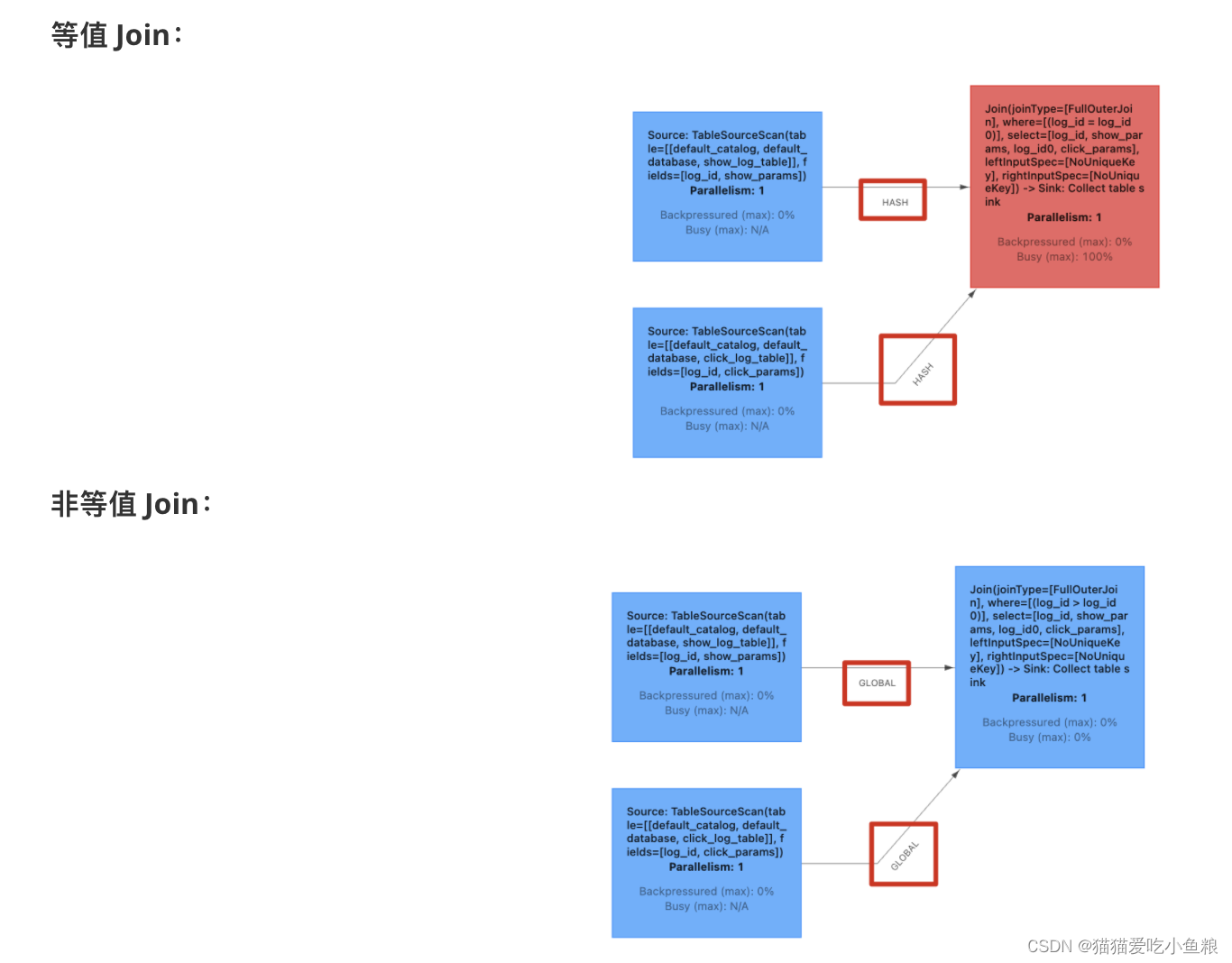
Flink 维表关联方案
Flink 维表关联方案
1、Flink DataStream 关联维表
1)概述
1.分类
实时数据库查找关联(Per-Record Reference Data Lookup)
预加载维表关联(Pre-Loading of Reference Data)
维表变更日志关联(Refere…
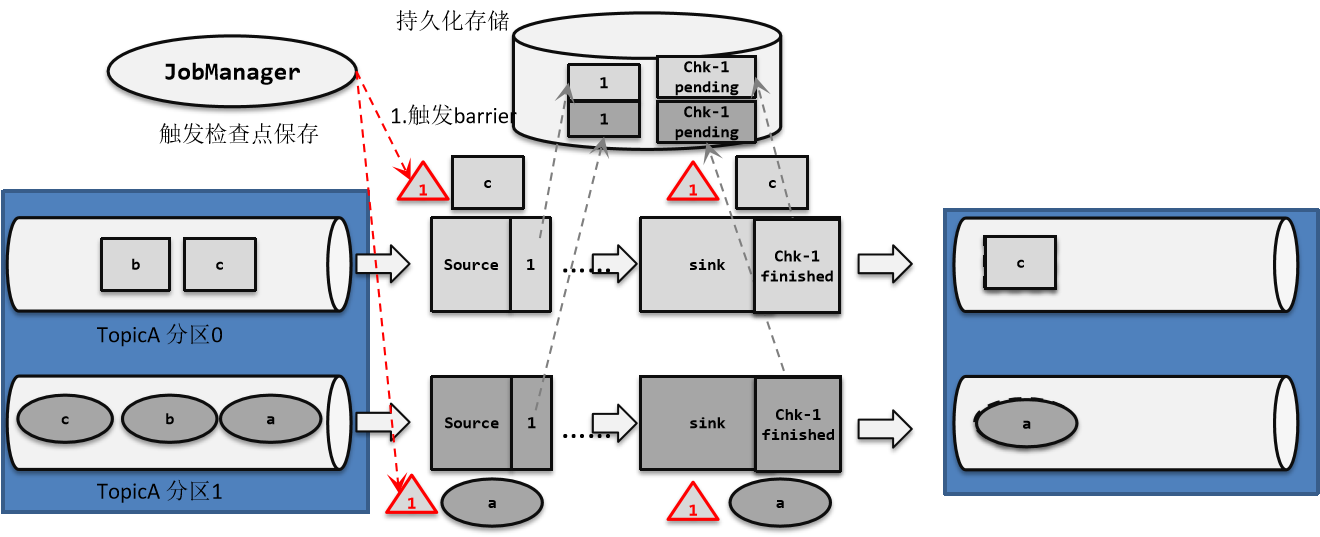
Flink1.17 基础知识
Flink1.17 基础知识
来源:B站尚硅谷 目录 Flink1.17 基础知识Flink 概述Flink 是什么Flink特点Flink vs SparkStreamingFlink的应用场景Flink分层API Flink快速上手创建项目WordCount代码编写批处理流处理 Flink部署集群角色部署模式会话模式(Session …
Flink检查点(checkpoint)、 保存点(savepoint)的区别和联系
一、Flink checkpoint
Checkpoint是Flink实现容错机制最核心的功能,能够根据配置周期性的基于Stream中各个Operator的状态来生成Snapshot,从而将这些状态数据定期持久存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择的从这些Snapshot进行恢复,从而修正因为…
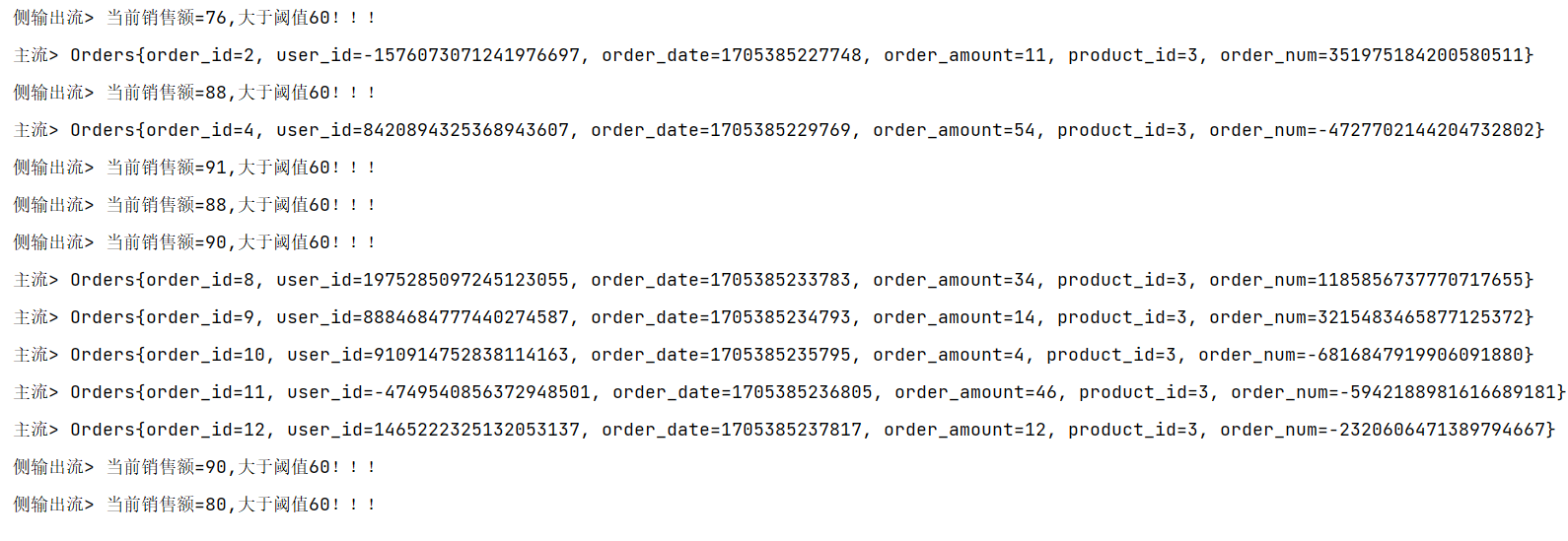
FlinkAPI开发之处理函数
案例用到的测试数据请参考文章: Flink自定义Source模拟数据流 原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048
概述
之前所介绍的流处理API,无论是基本的转换、聚合,还是更为复杂的窗口操作,…
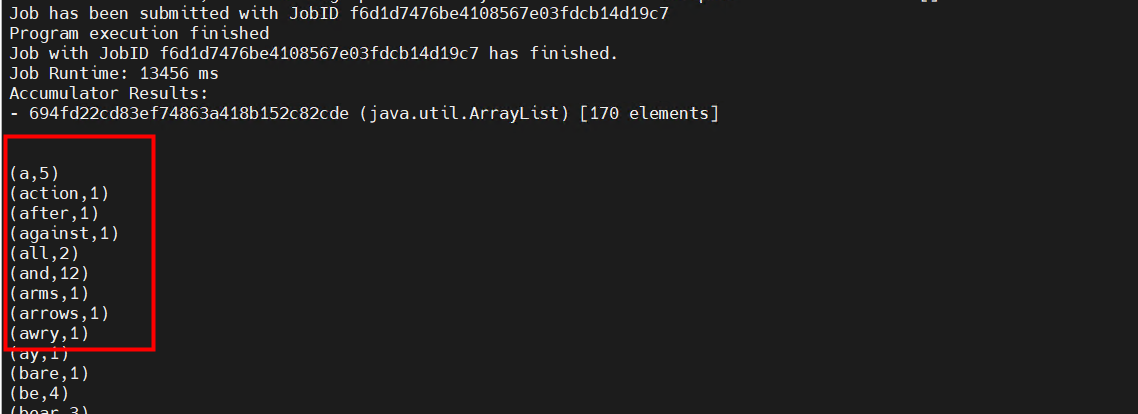
【DataSophon】大数据服务组件之Flink升级
🦄 个人主页——🎐开着拖拉机回家_Linux,大数据运维-CSDN博客 🎐✨🍁 🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁&am…
【动态读取配置文件】ParameterTool读取带环境的配置信息
不同环境Flink配置信息是不同的,为了区分不同环境的配置文件,使用ParameterTool工具读取带有环境的配置文件信息 区分环境的配置文件 三个配置文件:
flink.properties:决定那个配置文件生效
flink-dev.properties:测…
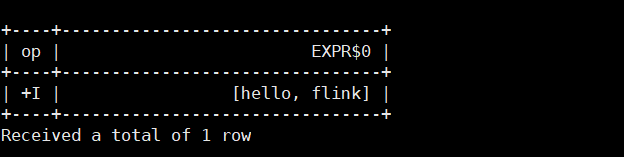
Flink(十四)【Flink SQL(中)查询】
前言 接着上次写剩下的查询继续学习。
Flink SQL 查询
环境准备:
# 1. 先启动 hadoop
myhadoop start
# 2. 不需要启动 flink 只启动yarn-session即可
/opt/module/flink-1.17.0/bin/yarn-session.sh -d
# 3. 启动 flink sql 的环境 sql-client
./sql-client.sh …
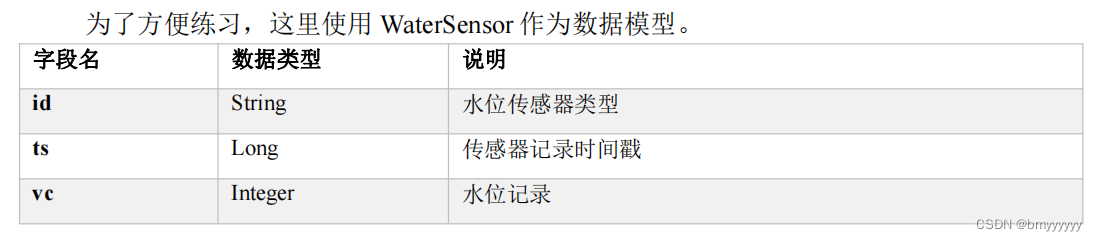
【Flink-1.17-教程】-【四】Flink DataStream API(1)源算子(Source)
【Flink-1.17-教程】-【四】Flink DataStream API(1)源算子(Source) 1)执行环境(Execution Environment)1.1.创建执行环境1.2.执行模式(Execution Mode)1.3.触发程序执行…
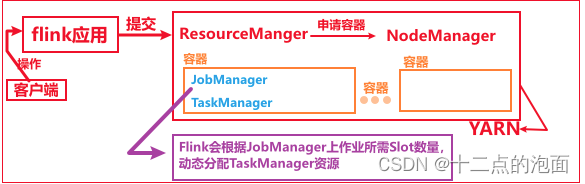
大数据学习之Flink,了解Flink的多种部署模式
目录
一、部署模式
1. 部署模式分类:
1.1 会话模式(Session Mode):
优点:
缺点:
1.2 单作业模式(Per-Job Mode):
优点:
缺点:
1.3…
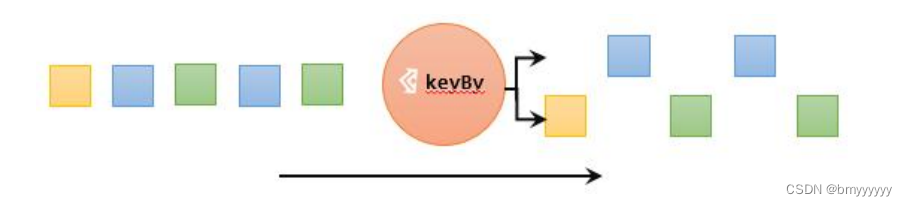
【Flink-1.17-教程】-【四】Flink DataStream API(2)转换算子(Transformation)【基本转换算子、聚合算子】
【Flink-1.17-教程】-【四】Flink DataStream API(2)转换算子(Transformation)【基本转换算子、聚合算子】 1)基本转换算子(map / filter / flatMap)1.1.映射(map)1.2.过…
【Flink-1.17-教程】-【四】Flink DataStream API(3)转换算子(Transformation)【用户自定义函数(UDF)】
【Flink-1.17-教程】-【四】Flink DataStream API(3)转换算子(Transformation)【用户自定义函数(UDF)】 1)函数类(Function Classes)2)富函数类(R…
大数据学习之Flink、比较不同框架的容错机制
第一章、Flink的容错机制
第二章、Flink核心组件和工作原理
第三章、Flink的恢复策略
第四章、Flink容错机制的注意事项
第五章、Flink的容错机制与其他框架的容错机制相比较 目录
第五章、Flink的容错机制与其他框架的容错机制相比较
Ⅰ、Flink的容错机制与其他框架的容…
实战Flink Java api消费kafka实时数据落盘HDFS
文章目录 1 需求分析2 实验过程2.1 启动服务程序2.2 启动kafka生产 3 Java API 开发3.1 依赖3.2 代码部分 4 实验验证STEP1STEP2STEP3 5 时间窗口 1 需求分析
在Java api中,使用flink本地模式,消费kafka主题,并直接将数据存入hdfs中。
flin…

flink-java使用介绍,flink,java
1、环境准备
文档:https://nightlies.apache.org/flink/flink-docs-release-1.18/zh/ 仓库:https://github.com/apache/flink 下载:https://flink.apache.org/zh/downloads/ 下载指定版本:https://archive.apache.org/dist/flink…
记一次Flink通过Kafka写入MySQL的过程
一、前言 总体思路:source -->transform -->sink ,即从source获取相应的数据来源,然后进行数据转换,将数据从比较乱的格式,转换成我们需要的格式,转换处理后,然后进行sink功能,也就是将数…

大数据学习之Flink算子、了解DataStream API(基础篇一)
DataStream API (基础篇) 注: 本文只涉及DataStream 原因:随着大数据和流式计算需求的增长,处理实时数据流变得越来越重要。因此,DataStream由于其处理实时数据流的特性和能力,逐渐替代了DataSe…
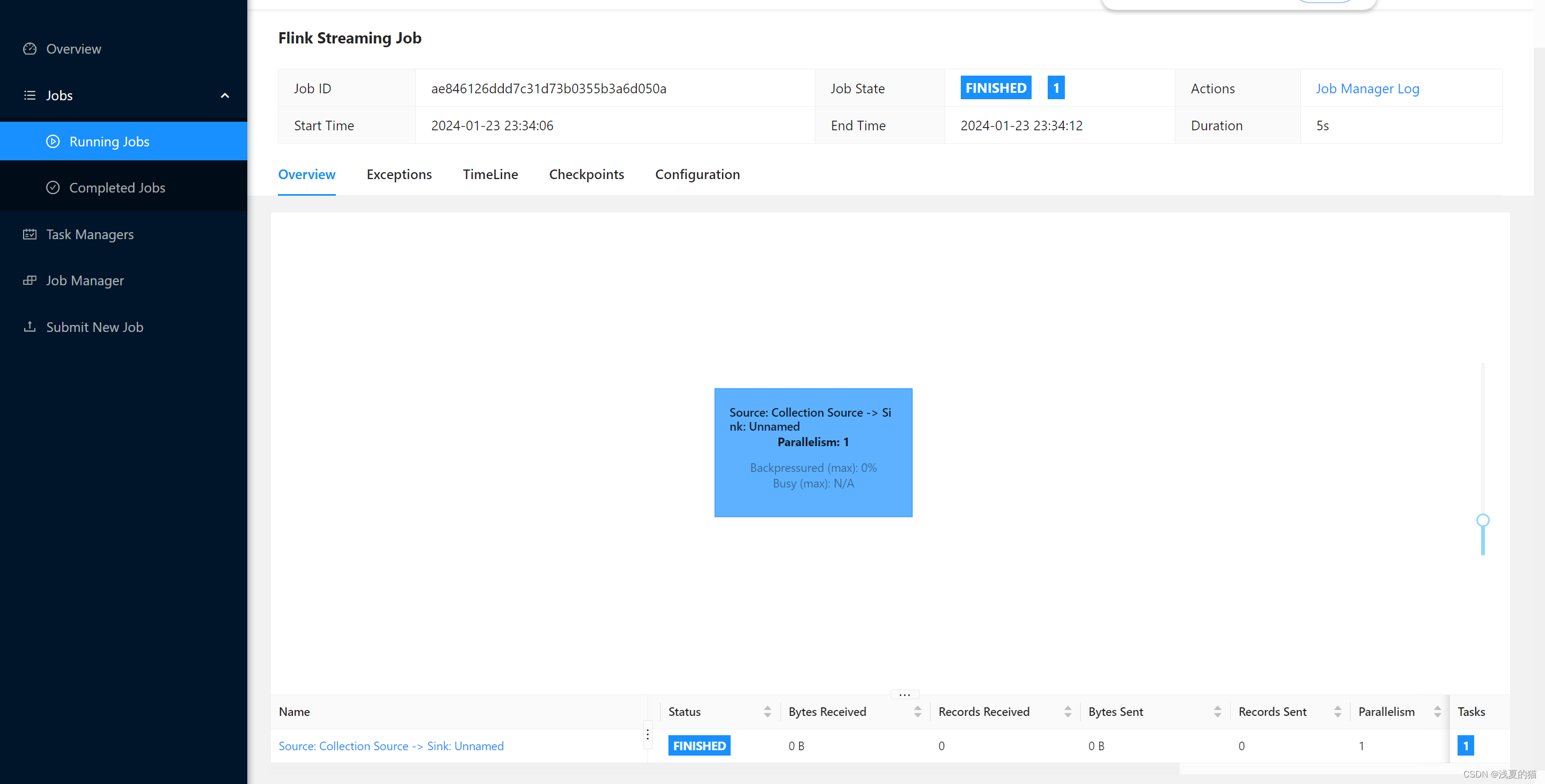
【极数系列】Flink项目入门搭建(03)
【极数系列】Flink项目入门搭建(03)
引言
gitee地址:https://gitee.com/shawsongyue/aurora.git 源码直接下载可运行,模块:aurora_flink Flink 版本:1.18.0 Jdk 版本:11
1.创建mavenx项目 2.…
flink内存管理(三):MemorySegment内存使用场景:托管内存与网络内存
文章目录 一.ManagedMemory(算子)内存的申请与使用1. tm内存申请与使用大致流程2. 创建MemoryManager实例3. 算子使用通过MemoryManager使用内存4. ManagedMemory内存空间申请流程 二.NetworkBuffer内存申请与使用1. NetworkBuffer构造器 在Flink内存模型…
数据中台的护城河,基于Flink实时构建数据仓
hello宝子们...我们是艾斯视觉擅长ui设计和前端开发10年经验!希望我的分享能帮助到您!如需帮助可以评论关注私信我们一起探讨!致敬感谢感恩! 数据中台的护城河:基于Flink实时构建数据仓
在数字化时代,数据…
Flink问题解决及性能调优-【Flink不同并行度引起sink2es报错问题】
最近需求,仅想提高sink2es的qps,所以仅调节了sink2es的并行度,但在调节不同算子并行度时遇到一些问题,找出问题的根本原因解决问题,并分析整理。
实例代码
--SET table.exec.state.ttl86400s; --24 hour,默认: 0 ms
…

37、Flink 的CDC 格式:debezium部署以及mysql示例(完整版)
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…
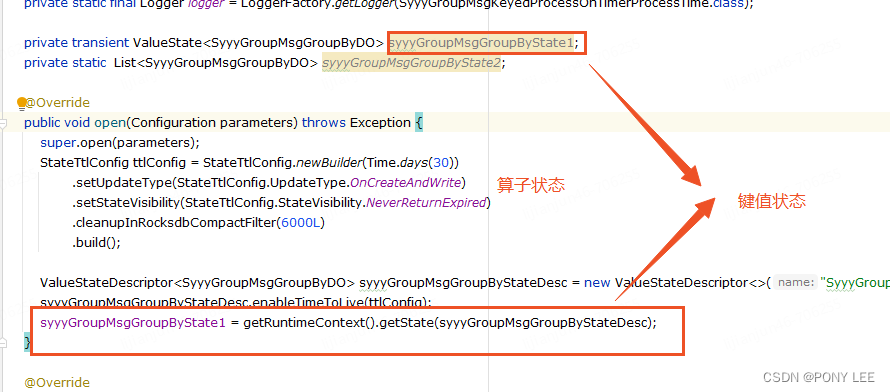
Flink问题解决及性能调优-【Flink根据不同场景状态后端使用调优】
Flink 实时groupby聚合场景操作时,由于使用的是rocksdb状态后端,发现CPU的高负载卡在rocksdb的读写上,导致上游算子背压特别大。通过调优使用hashmap状态后端代替rocksdb状态后端,使吞吐量有了质的飞跃(20倍的性能提升…

flink-start源码
jobSubmit
testCse
final StreamExecutionEnvironment env new StreamExecutionEnvironment(configuration);
//将算子添加进transformArrayList中env.fromCollection(Collections.singletonList(42)).addSink(new DiscardingSink<>());return env.execute();StreamEx…
【flink番外篇】9、Flink Table API 支持的操作示例(2)-完整版
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…
Flink运行架构以及容错机制
Flink运行架构以及容错机制 1. Flink的角色区分1.1 JM1.2 TM1.3 SLOT 2. Flink-Cluster模式的任务提交流程2.1 Flink On Yarn的任务提交流程2.1.1 yarn相关概念2.1.2 运行模式2.1.2.1 Session-Cluster模式2.1.2.2 PreJob-Cluster模式2.1.2.3 Application模式 2.1.3 任务提交流程…

【大数据】Flink 架构(二):数据传输
《Flink 架构》系列(已完结),共包含以下 6 篇文章:
Flink 架构(一):系统架构Flink 架构(二):数据传输Flink 架构(三):事件…
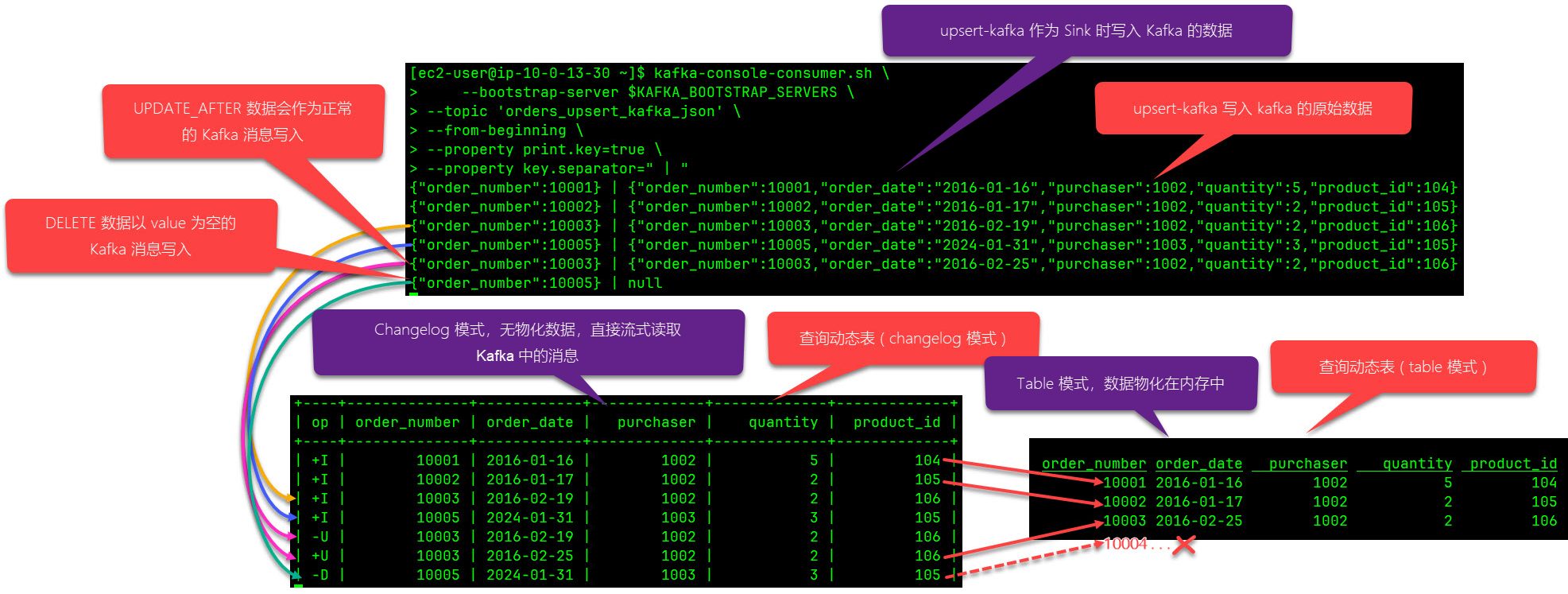
透彻理解实时数仓的支撑技术:Upsert Kafka 和 Flink 动态表(Dynamic Table)
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…

Flink入门之Flink程序开发步骤(java语言)
文章目录(0)开发程序所需依赖(1)获取执行环境(2)加载/创建数据源(3)数据转换处理(4)处理后数据放置/输出(5)执行计算程序(…
大数据常见端口汇总-hadoop、hbase、hive、spark、kafka、zookeeper等(持续更新)
常见端口汇总:
Hadoop: 50070:HDFS WEB UI端口 8020 : 高可用的HDFS RPC端口 9000 : 非高可用的HDFS RPC端口 8088 : Yarn 的WEB UI 接口 8485 : JournalNode 的RPC端口 8019 :…
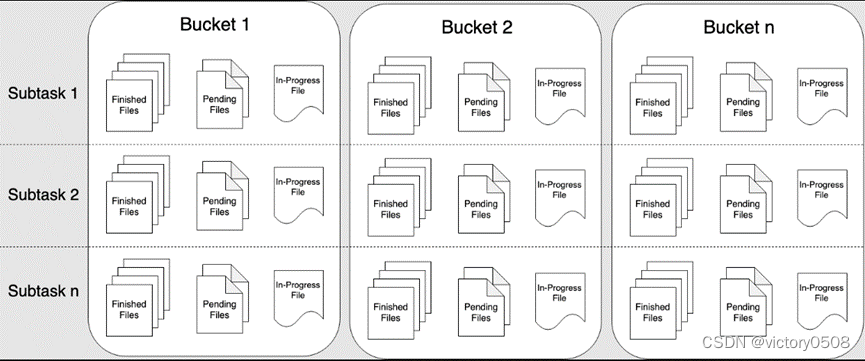
Flink流批一体计算(18):PyFlink DataStream API之计算和Sink
目录 1. 在上节数据流上执行转换操作,或者使用 sink 将数据写入外部系统。
2. File Sink
File Sink
Format Types
Row-encoded Formats
Bulk-encoded Formats
桶分配
滚动策略
3. 如何输出结果
Print
集合数据到客户端,execute_and_collect…
【Flink实战】Flink中的分流
Flink中的分流
在Flink中将数据流切分为多个子数据流,子数据流称为”旁路输出数据流“。 #mermaid-svg-bnbf0HOpEUsgi9nh {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-bnbf0HOpEUsgi9nh .error-icon{…

自定义Flink时间窗口
需求说明
Flink提供的常用简单窗口有:TumblingEventTimeWindows,TumblingProcessingTimeWindows,SlidingEventTimeWindows,SlidingProcessingTimeWindows等。对于初学者来说,这些窗口并不能满足特定的需求,例如:当接收到活动告警后,延迟一分钟,这一分钟内如果有对应清…
Flink集群常见的监控指标
为确保能够全面、实时地监控Flink集群的运行状态和性能指标。以下是监控方案的主要组成部分:
Flink集群概览:通过访问Flink的JobManager页面,您可以获取集群的总体信息,包括TaskManager的数量、任务槽位数量、运行中的作业以及已…
[实战-04]FlinkSql 如何实现数据去重?
摘要
很多时候flink消费上游kafka的数据是有重复的,因此有时候我们想数据在落盘之前进行去重,这在实际开发中具有广泛的应用场景,此处不说详细代码,只粘贴相应的flinksql
代码
--********************************************…

大数据Flink(七十四):SQL的滑动窗口(HOP)
文章目录
SQL的滑动窗口(HOP) SQL的滑动窗口(HOP)
滑动窗口定义:滑动窗口也是将元素指定给固定长度的窗口。与滚动窗口功能一样,也有窗口大小的概念。不一样的地方在于,滑动窗口有另一个参数控制窗口计算的频率(滑动窗口滑动的步长)。因此,如果滑动的步长小于窗口大…
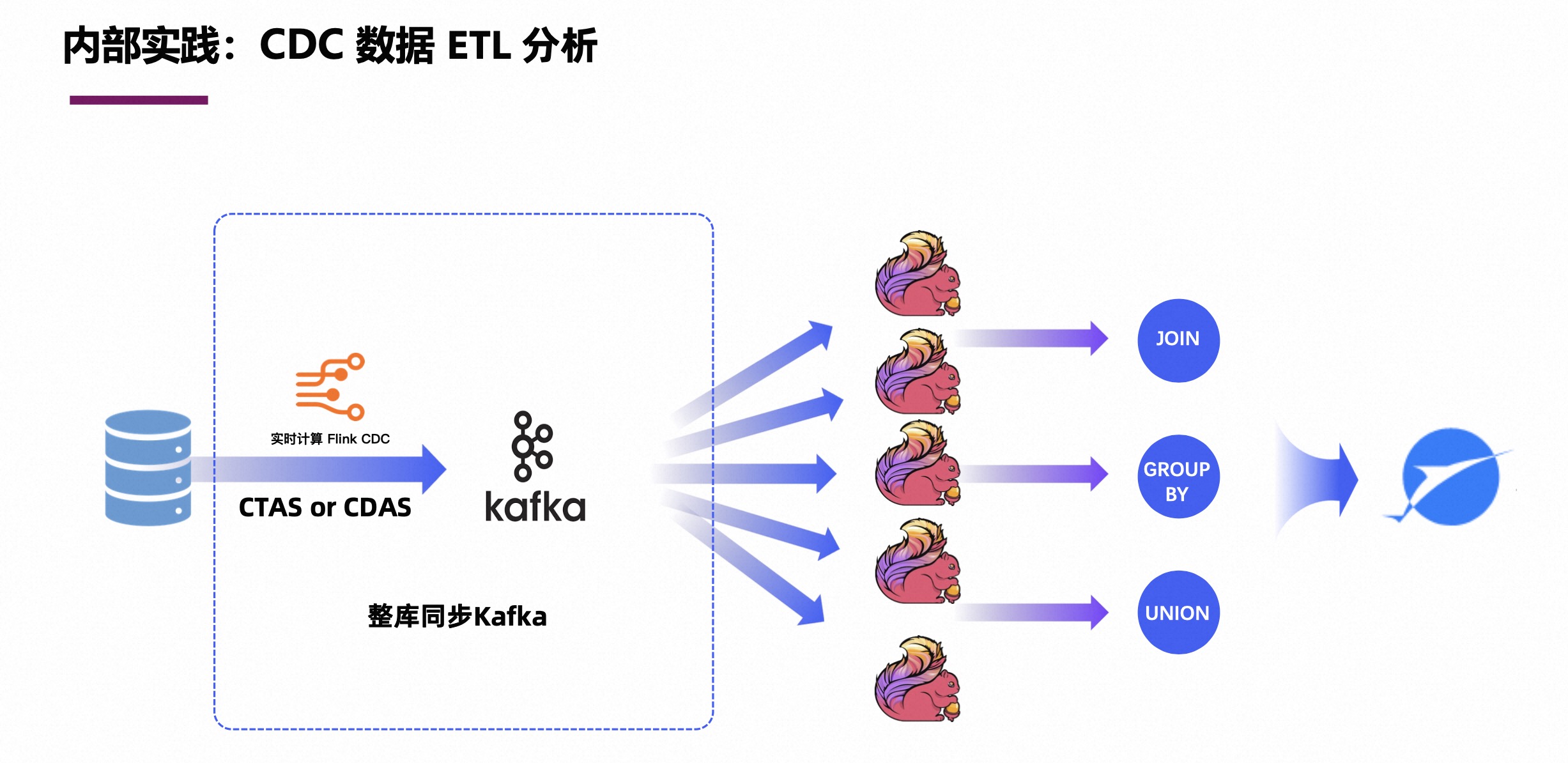
基于 Flink CDC 高效构建入湖通道
本文整理自阿里云 Flink 数据通道负责人、Flink CDC 开源社区负责人, Apache Flink PMC Member & Committer 徐榜江(雪尽),在 Streaming Lakehouse Meetup 的分享。内容主要分为四个部分: Flink CDC 核心技术解析数…
Flink state,checkpoint详解
目录
目录
背景 (1)介绍,实现方式分类
(2) 使用Manage State,Flink自动实现state保存和恢复
(3) 自定义state 自行实现实现checkpoint接口
借鉴文章 背景 Flink相对于Storm和Sp…
Flink Table API 使用详解
Table API是流处理和批处理通用的关系型API,Table API可以基于流输入或者批输入来运行而不需要进行任何修改。Table API是SQL语言的超集并专门为Apache Flink设计的,Table API是Scala 和Java语言集成式的API。与常规SQL语言中将查询指定为字符串不同&…

mac电脑安装flink其他版本(历史版本)简单有效
1.安装brew这里不介绍安装方式
2.安装最新版本的flink(brew默认就会直接安装最新版的软件)
brew install apache-flink
3.安装成功后检查版本信息
fink --version
4.如果这个版本太新,而想安装历史版本,看下面的套路
5.查看…
阿里云 Flink 原理分析与应用:深入探索 MongoDB Schema Inference
本文整理自阿里云 Flink 团队归源老师关于阿里云 Flink 原理分析与应用:深入探索 MongoDB Schema Inference 的研究,内容主要分为以下四部分: MongoDB 简介社区MongoDB CDC 核心特性MongoDB CDC 在阿里云 Flink 实时计算产品的实践总结 一、M…
flink中的重启策略
背景
在flink宣布作业失败的时候往往会进行重试,本文就来记录下flink中的几种重启策略
flink失败重启策略
1.固定延时重启 这种重启策略会重启固定的次数,每两次重启之间会间隔固定的时间间隔,如果失败次数达到了配置的次数限制࿰…

【大数据】Flink 架构(三):事件时间处理
《Flink 架构》系列(已完结),共包含以下 6 篇文章:
Flink 架构(一):系统架构Flink 架构(二):数据传输Flink 架构(三):事件…
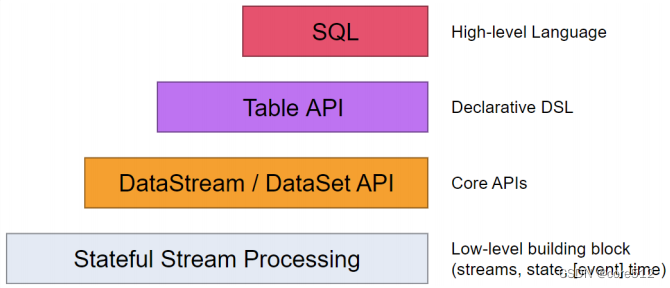
Flink实战三_TableAPISQL
接上文:Flink实战二_DataStream API 1、Table API和SQL是什么?
接下来理解下Flink的整个客户端API体系,Flink为流式/批量处理应用程序提供了不同级别的抽象: 这四层API是一个依次向上支撑的关系。
Flink API 最底层的抽象就是有…

Flink版本更新汇总(1.14-1.18)
0、汇总
1.14.0
1.有界流支持 Checkpoint;
2.批执行模式支持 DataStream 和 Table/SQL 混合应用;
3.新增 Hybrid Source 功能;
4.新增 缓冲区去膨胀 功能;
5.新增 细粒度资源管理 功能;
6.新增 DataStream 的 Pulsar …

【极数系列】Flink集成DataSource读取集合数据(07)
文章目录 01 引言02 简介概述03 基于集合读取数据3.1 集合创建数据流3.2 迭代器创建数据流3.3 给定对象创建数据流3.4 迭代并行器创建数据流3.5 基于时间间隔创建数据流3.6 自定义数据流 04 源码实战demo4.1 pom.xml依赖4.2 创建集合数据流作业4.3 运行结果日志 01 引言
源码地…
FlinkOnYarn 监控 flink任务
Flink任务一般为实时不断运行的任务,如果没有任务监控, 任务异常时无法第一时间处理会比较麻烦。 这里通过调用API接口方式来获取参数,实现任务监控。 Flink任务监控(基于API接口编写shell脚本) 一 flink-on-yarn 模式 二 编写she…
flink分别使用FilterMap和ProcessFunction实现去重逻辑
背景
在日常的工作中,对数据去重是一件很常见的操作,比如我们只需要保留重复记录的第一条,而忽略掉后续重复的记录,达到去重的效果,本文就使用flink的FilterMap和ProcessFunction来实现去重逻辑
FilterMap和ProcessF…
Apache Flink文件上传漏洞(CVE-2020-17518)漏洞代码分析
漏洞复现参考如下文章
Apache Flink文件上传漏洞(CVE-2020-17518)漏洞复现分析_文件上传漏洞复现cve-CSDN博客
分析代码的话,首先找到漏洞修复的邮件
漏洞详情,可以看到漏洞概要,影响的版本,漏洞描述以及…
Flink 添加 / 部署 Jar 包的若干注意事项
Flink 添加 / 部署 Jar 包可根据 Jar 包的声明周期、作用范围选择不同的附属方式,从实际应用上来看,可以分成以下几种场景:
普遍使用的框架或基础设施级别的 Jar 包,例如 Kafka、Hive、Hudi 等 Connector 的Jar 包,应…
PiflowX-DorisRead组件
DorisRead组件
组件说明
从Doris存储读取数据。
计算引擎
flink
有界性
目前Doris Source是有界流,不支持CDC方式读取。
组件分组
Doris
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述…
Flink实战四_TableAPISQL
接上文:Flink实战三_时间语义 1、Table API和SQL是什么?
接下来理解下Flink的整个客户端API体系,Flink为流式/批量处理应用程序提供了不同级别的抽象: 这四层API是一个依次向上支撑的关系。
Flink API 最底层的抽象就是有状态实…
Flink数据实时写入HBase
main
object MyHbaseSinkTest {def main(args: Array[String]): Unit {//环境val env StreamExecutionEnvironment.getExecutionEnvironment/*** 获取基础参数*/val bootstrapserversnew Contant.BOOTSTRAP_SERVERS_NEWimport org.apache.flink.api.scala._/*** 定义kafka-…
![Flink 1.18.1 部署与配置[CentOS7]](https://img-blog.csdnimg.cn/direct/e06e1abfbca04bbf9c19452edeb41f08.png)
Flink 1.18.1 部署与配置[CentOS7]
静态IP设置
# 修改网卡配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33# 修改文件内容
TYPEEthernet
PROXY_METHODnone
BROWSER_ONLYno
BOOTPROTOstatic
IPADDR192.168.18.128
NETMASK255.255.255.0
GATEWAY192.168.18.2
DEFROUTEyes
IPV4_FAILURE_FATALno
IPV6INIT…
【flink番外篇】15、Flink维表实战之6种实现方式-通过广播将维表数据传递到下游
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…
Flink(十三)【Flink SQL(上)SqlClient、DDL、查询】
前言 最近在假期实训,但是实在水的不行,三天要学完SSM,实在一言难尽,浪费那时间干什么呢。SSM 之前学了一半,等后面忙完了,再去好好重学一遍,毕竟这玩意真是面试必会的东西。 今天开始学习 Flin…
flink operator 拉取阿里云私有镜像(其他私有类似)
创建 k8s secret
kubectl --namespace flink create secret docker-registry aliyun-docker-registry --docker-serverregistry.cn-shenzhen.aliyuncs.com --docker-usernameops_acr1060896234 --docker-passwordpasswd --docker-emailDOCKER_EMAIL注意命名空间指定你使用的 我…
PiflowX组件-OracleCdc
OracleCdc组件
组件说明
Oracle CDC连接器允许从Oracle数据库读取快照数据和增量数据。
计算引擎
flink
组件分组
cdc
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子hostnameHostname“”无是Or…
大数据学习之Flink,Flink的安装部署
Flink部署
一、了解它的关键组件 客户端(Client) 作业管理器(JobManager) 任务管理器(TaskManager)
我们的代码,实际上是由客户端获取并做转换,之后提交给 JobManger 的。所以 …
大数据学习之Flink算子、了解(Source)源算子(基础篇二)
Source源算子(基础篇二) 目录
Source源算子(基础篇二)
二、源算子(source)
1. 准备工作
2.从集合中读取数据
可以使用代码中的fromCollection()方法直接读取列表
也可以使用代码中的fromElements()方…
Spring SpEL在Flink中的应用-与Filter结合实现数据动态分流
文章目录 前言一、POM依赖二、主函数代码示例三、FilterFunction实现总结 前言
SpEL表达式与Flink fiter结合可以实现基于表达式的灵活动态过滤。有关SpEL表达式的使用请参考Spring SpEL在Flink中的应用-SpEL详解。 可以将过滤规则放入数据库,根据不同的数据设置不…
![[Flink03] Flink安装](https://img-blog.csdnimg.cn/img_convert/3bc059e0490c0289ab0fa93eb4313fe3.png)
[Flink03] Flink安装
本文介绍Flink的安装步骤,主要是Flink的独立部署模式,它不依赖其他平台。文中内容分为4块:前置准备、Flink本地模式搭建、Flink Standalone搭建、Flink Standalong HA搭建。
演示使用的Flink版本是1.15.4,官方文档地址࿱…
[Flink03] Flink安装
本文介绍Flink的安装步骤,主要是Flink的独立部署模式,它不依赖其他平台。文中内容分为4块:前置准备、Flink本地模式搭建、Flink Standalone搭建、Flink Standalong HA搭建。
演示使用的Flink版本是1.15.4,官方文档地址࿱…
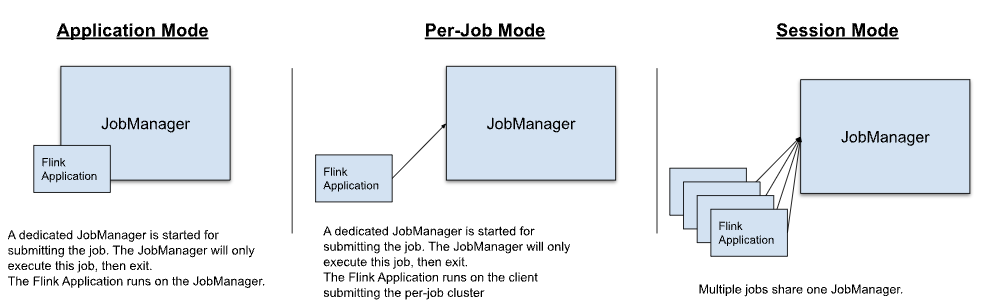
Docker中部署flink集群的两种方式
文章目录 一、概述二、准备工作三、方式一四、方式二1、准备配置文件2、执行 docker 命令 一、概述
本文将通过 2 种方式在 docker 中部署 flink standalone 集群,集群中共有 4 个节点,分别是 1 个 jobManager 节点和 3 个 taskManager 节点。方式一能快…
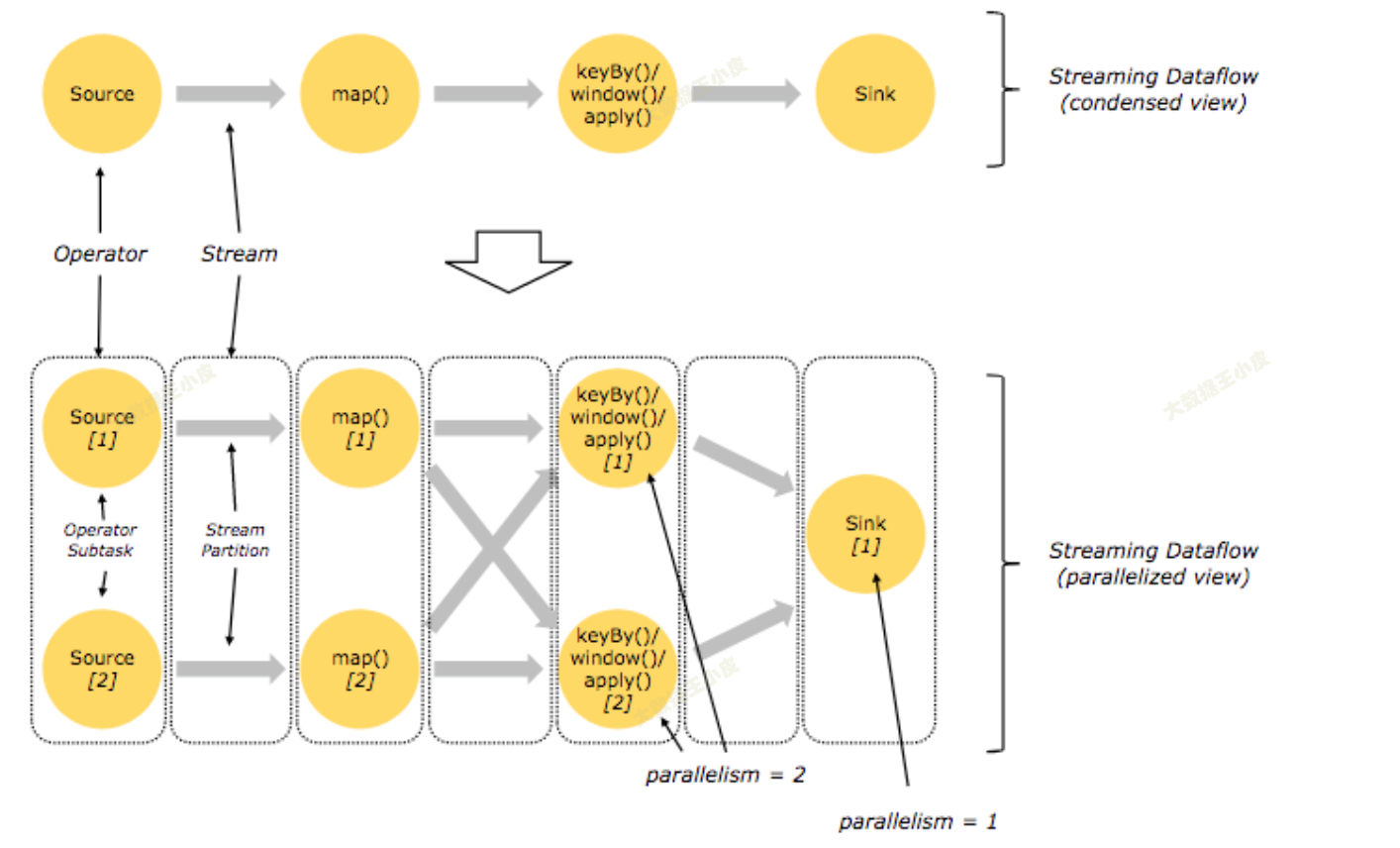
【Flink入门修炼】1-4 Flink 核心概念与架构
前面几篇文章带大家了解了 Flink 是什么、能做什么,本篇将带大家了解 Flink 究竟是如何完成这些的,Flink 本身架构是什么样的,让大家先对 Flink 有整体认知,便于后期理解。
一、Flink 组件栈
Flink是一个分层架构的系统…

生产环境下,应用模式部署flink任务,通过hdfs提交
前言 通过通过yarn.provided.lib.dirs配置选项指定位置,将flink的依赖上传到hdfs文件管理系统 1. 实践 (1)生产集群为cdh集群,从cm上下载配置文件,设置环境
export HADOOP_CONF_DIR/home/conf/auth
export HADOOP_CL…
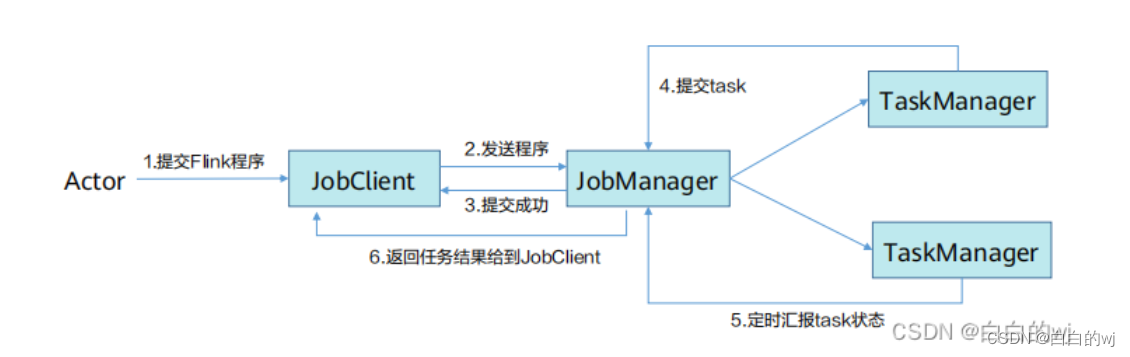
2024.2.19 阿里云Flink
一 、Flink基本介绍
Spark底层是微批处理 , Flink底层则是实时流计算
流式计算特点: 数据是源源不断产生,两大问题,乱序和延迟
Stateful:有状态
Flink的三个部分
Source:Transactions , logs ,iot ,clicks Transformation: 事件驱动 , ETL , 批处理 Sink : 输出 HDFS ,Kaf…
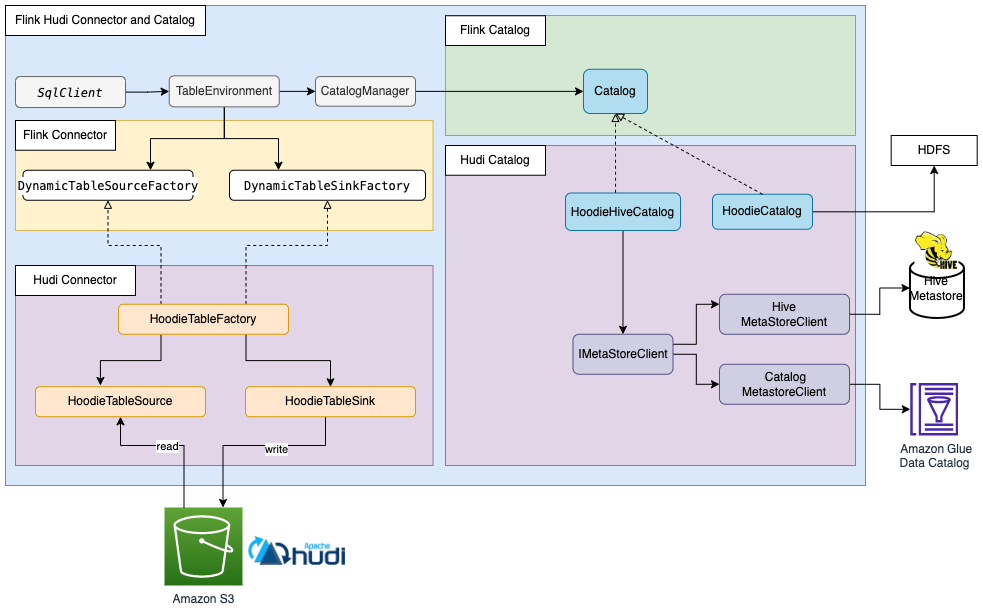
Flink Catalog 解读与同步 Hudi 表元数据的最佳实践
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…

calcite在flink中的二次开发,介绍解析器与优化器
calcite 在flink中的二次开发 1 CodeGen2 flink 语法扩展2.1 在进行 Rule 规则匹配时,放开对 Distinct 的限制2.2下面附上一个 利用codegen来生成所需类的例子: 3 flink使用calcite 生成解析器FlinkSqlParserImpl3.1 FlinkSqlParserImpl 的生成3.1.1 fli…
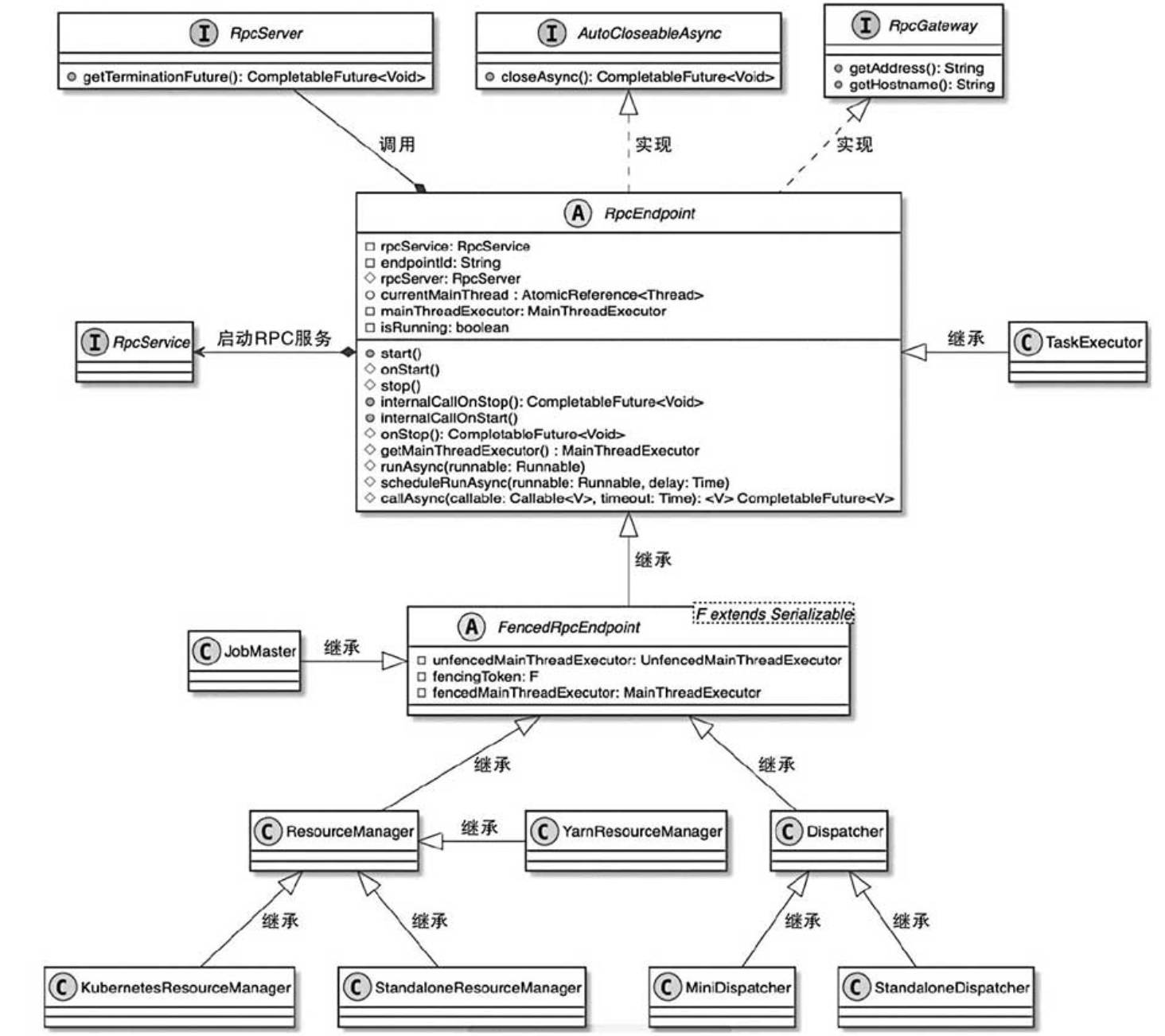
【Flink网络通讯(一)】Flink RPC框架的整体设计
文章目录 1. Akka基本概念与Actor模型2. Akka相关demo2.1. 创建Akka系统2.2. 根据path获取Actor并与之通讯 3. Flink RPC框架与Akka的关系4.运行时RPC整体架构设计5. RpcEndpoint的设计与实现 我们从整体的角度看一下Flink RPC通信框架的设计与实现,了解其底层Akka通…

【Flink】FlinkSQL读取hive数据(批量)
一、简介:
Hive在整个数仓中扮演了非常重要的一环,我们可以使用FlinkSQL实现对hive数据的读取,方便后续的操作,本次例子为Flink1.13.6版本
二、依赖jar包准备:
官网地址如下:
Overview | Apache Flink
1、我们需要准备相关的jar包到Flink安装目录的lib目录下,我们需…
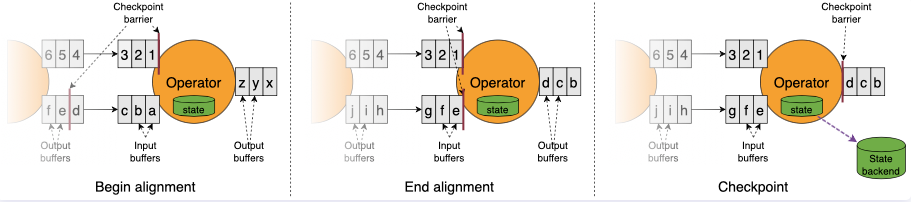
Flink理论—容错之状态后端(State Backends)
Flink理论—容错之状态后端(State Backends)
Flink 使用流重放和 检查点的组合来实现容错。检查点标记每个输入流中的特定点以及每个运算符的相应状态。通过恢复运算符的状态并从检查点点重放记录,可以从检查点恢复流数据流,同时保持一致性
容错机制不…
【Flink】FlinkSQL实现数据从Hive到MySQL
简介 未来Flink通用化,代码可能就会转换为sql进行执行,大数据开发工程师研发Flink会基于各个公司的大数据平台或者通用的大数据平台,去提交FlinkSQL实现任务,学习FlinkSQL势在必行。 本博客在sql-client(Flink自带的sql执行器)中模拟大数据平台的sql编辑器执行FlinkSQL,使…
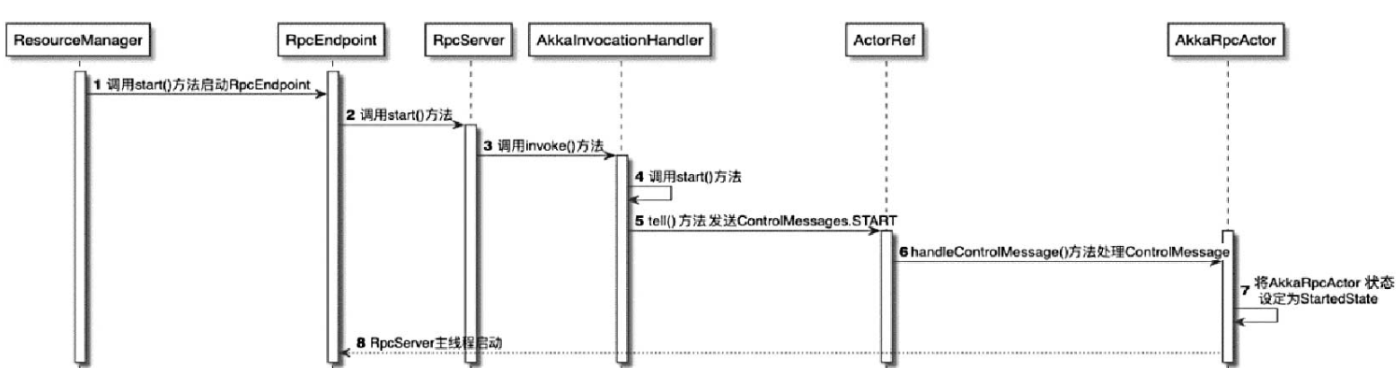
【Flink集群RPC通讯机制(二)】创建AkkaRpcService、启动RPC服务、实现相互通信
文章目录 零. RpcService服务概述1. AkkaRpcService的创建和初始化2.通过AkkaRpcService初始化RpcServer3. ResourceManager中RPC服务的启动4. 实现相互通讯能力 零. RpcService服务概述
RpcService负责创建和启动Flink集群环境中RpcEndpoint组件的RpcServer,且Rpc…

flink 任务提交流程源码解析
flinkjob 提交流程 任务启动流程图1客户端的工作内容1.1解析命令1.2 执行用户代码 2集群工作内容2.2启动JobManager和 ResourceManager2.3 申请资源 启动 taskmanager 3分配任务3.1 资源计算3.2 分发任务 4 Task 任务调度执行图5 任务提交过程总结 任务启动流程图 可以先简单看…
![[ 2024春节 Flink打卡 ] -- 优化(draft)](https://img-blog.csdnimg.cn/direct/ee8f7f0edc074642b3899acdacfc8e9e.png)
[ 2024春节 Flink打卡 ] -- 优化(draft)
2024,游子未归乡。工作需要,flink coding。觉知此事要躬行,未休,特记
资源配置调优内存设置 TaskManager内存模型
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/config/
TaskManager 内存模型…
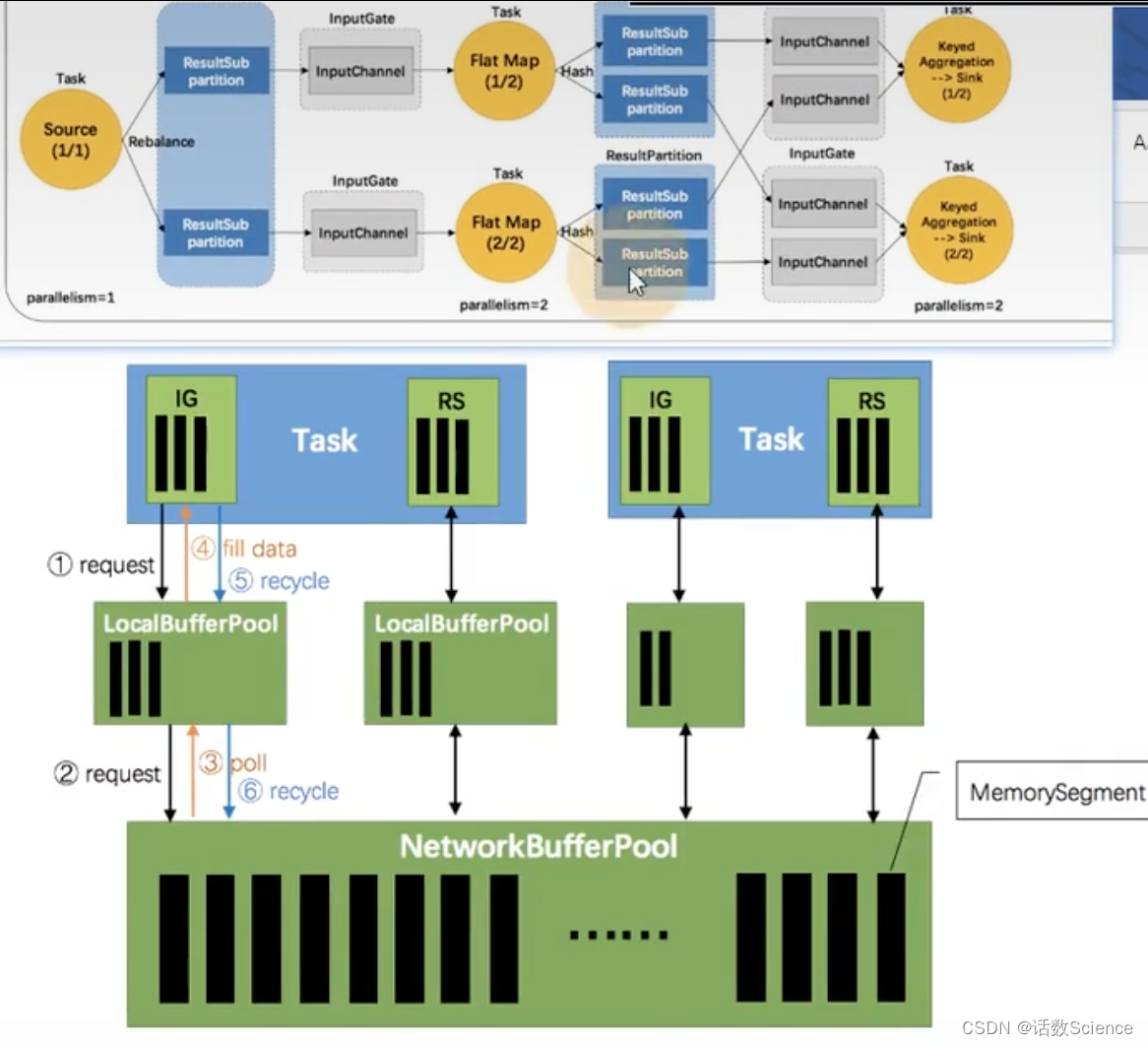
【Flink经济】Flink 内存管理
面临的问题 目前, 大数据计算引擎主要用 Java 或是基于 JVM 的编程语言实现的,例如 Apache Hadoop、 Apache Spark、 Apache Drill、 Apache Flink 等。 Java 语言的好处在于程序员不需要太关注底层内存资源的管理,但同样会面临一个问题&…
问题:Spark SQL 读不到 Flink 写入 Hudi 表的新数据,打开新 Session 才可见
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…

一种基于动态水位值的Flink调度优化算法(flink1.5以前),等同于实现flink的Credit-based反压原理
优化flink反压 说明1 flink反压介绍1.1 介绍1.2 大数据系统反压现状1.4 flink task与task之间的反压1.5 netty水位机制作用分析 2 反压优化算法3 重点! 但是 可但是 flink1.5以后的反压过程。4 flink反压问题的查找瓶颈办法 说明
首先说明,偶然看了个论…
Flink启动Yarn Session报错:Couldn‘t deploy Yarn session cluster
Flink版本:1.1.3
启动Yarn Session的语句:bin/yarn-session.sh -nm test -d
报错截图如下: 仅通过ERROR信息只能知道是yarn session集群未能正常启动,因此继续向下查找:
找到报错信息的Caused by部分: 报…
SeaTunnel 、DataX 、Sqoop、Flume、Flink CDC 对比
对比 对比项Apache SeaTunnelDataXApache SqoopApache FlumeFlink CDC部署难度容易容易中等,依赖于 Hadoop 生态系统容易中等,依赖于 Hadoop 生态系统运行模式分布式,也支持单机单机本身不是分布式框架,依赖 Hadoop MR 实现分布式分布式,也支持单机分布式,也支持单机健壮…
Flink 流式读取 Debezium CDC 数据写入 Hudi 表无法处理 -D / Delete 消息
问题场景是:使用 Kafka Connect 的 Debezium MySQL Source Connector 将 MySQL 的 CDC 数据 (Avro 格式)接入到 Kafka 之后,通过 Flink 读取并解析这些 CDC 数据,然后以流式方式写入到 Hudi 表中,测试中发现…
【大数据面试题】001 Flink 的 Checkpoint 原理
一步一个脚印,一天一道大数据面试题。
Flink 是大数据实时处理计算框架。实时框架对检查点,错误恢复的功能要比离线的更复杂,所以一起来了解 Flink 的 Checkpoint 机制吧。
Checkpoint 机制
触发 Checkpoint 通过设置时间或数据量阈值来触…
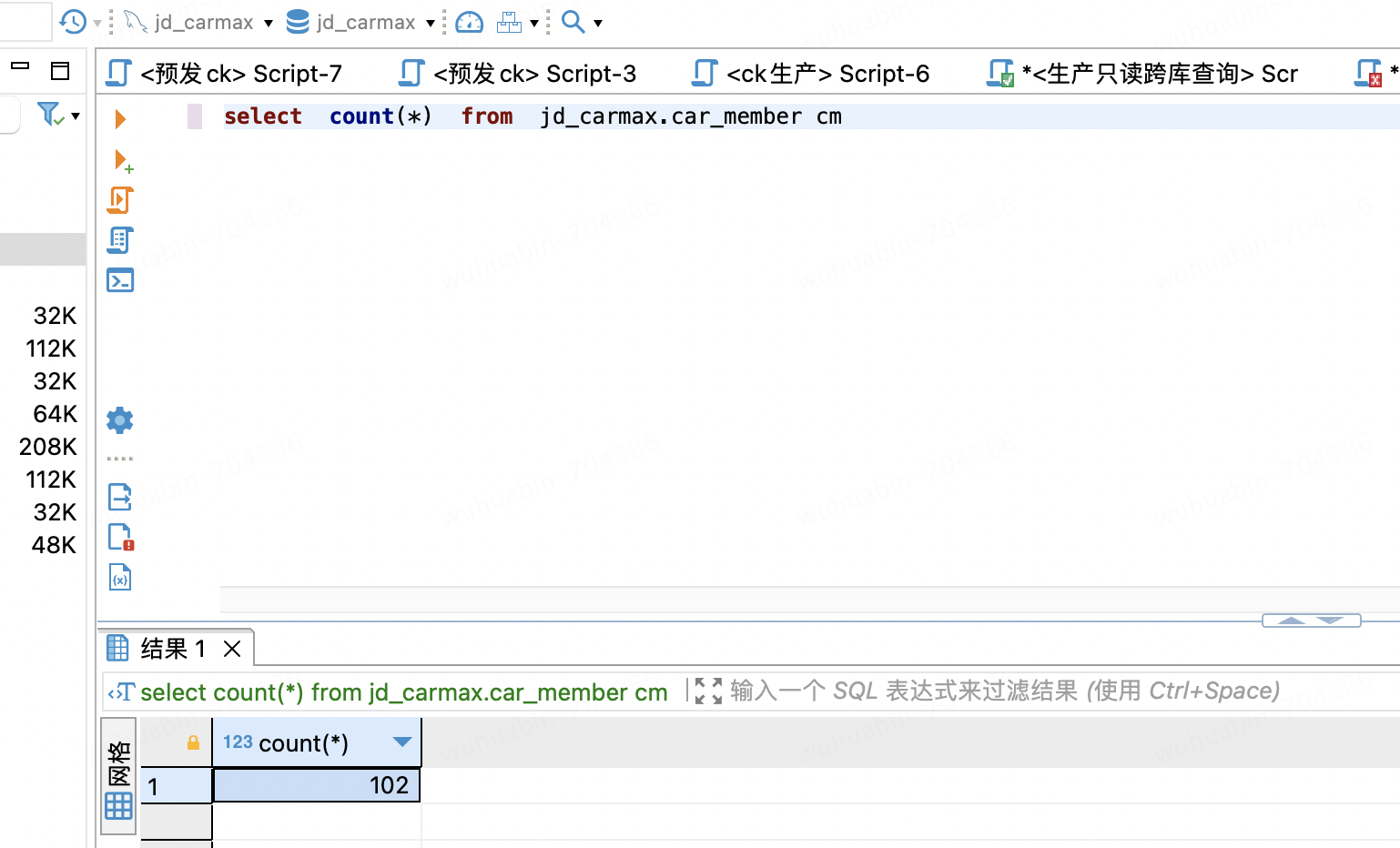
streampark+flink一键整库或多表同步mysql到doris实战
streamparkflink一键整库或多表同步mysql到doris实战,此应用一旦推广起来,那么数据实时异构时,不仅可以减少对数据库的查询压力,还可以减少数据同步时的至少50%的成本,还可以减少30%的存储成本;
streampar…
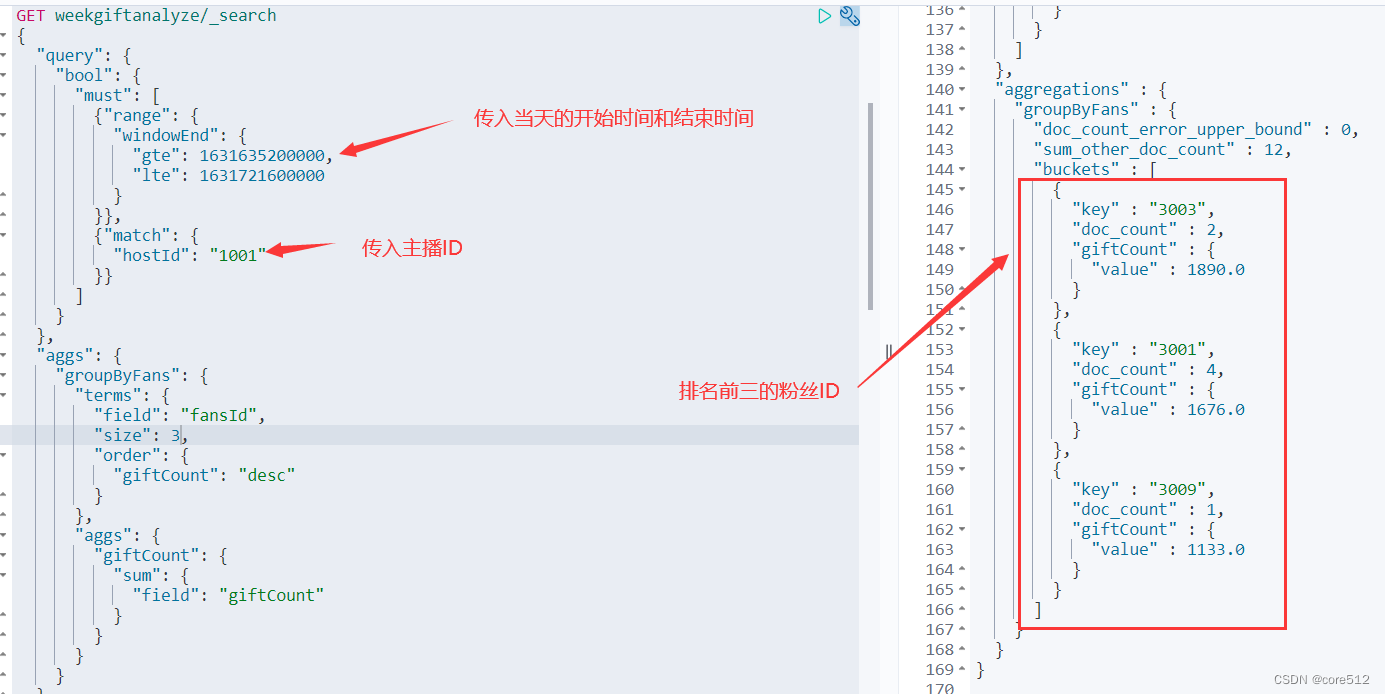
Flink实战五_直播礼物统计
接上文:Flink实战四_TableAPI&SQL 1、需求背景
现在网络直播平台非常火爆,在斗鱼这样的网络直播间,经常可以看到这样的总榜排名,体现了主播的人气值。
人气值计算规则:用户发送1条弹幕互动,赠送1个荧…
Fink CDC数据同步(四)Mysql数据同步到Kafka
依赖项
将下列依赖包放在flink/lib
flink-sql-connector-kafka-1.16.2
创建映射表
创建MySQL映射表
CREATE TABLE if not exists mysql_user (id int,name STRING,birth STRING,gender STRING,PRIMARY KEY (id) NOT ENFORCED
) WITH (connector mysql-cdc,hostn…
seatunnel数据集成(三)多表同步
seatunnel数据集成(一)简介与安装seatunnel数据集成(二)数据同步seatunnel数据集成(三)多表同步seatunnel数据集成(四)连接器使用 seatunnel除了单表之间的数据同步之外,…
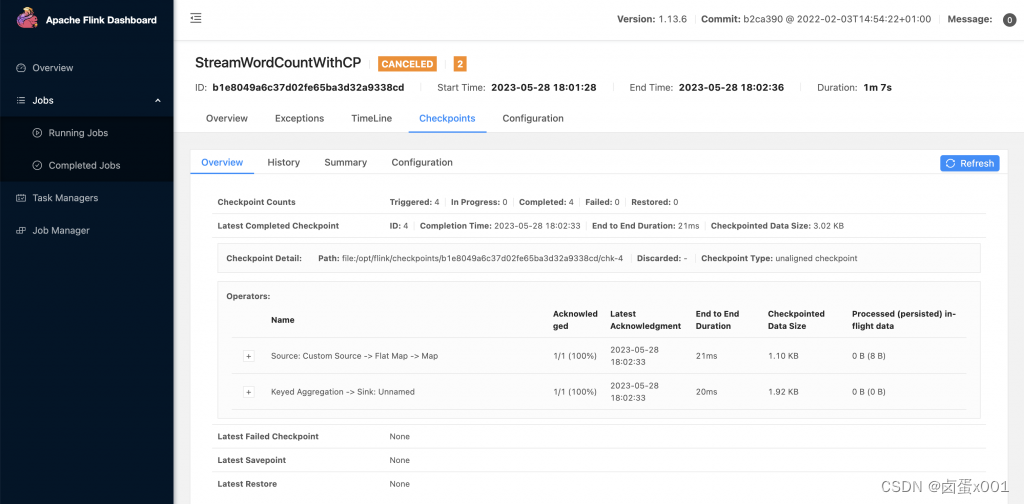
Flink on k8s之historyServer
1.Flink HistoryServer用途 HistoryServer可以在Flink 作业终止运行(Flink集群关闭)之后,还可以查询已完成作业的统计信息。此外,它对外提供了 REST API,它接受 HTTP 请求并使用 JSON 数据进行响应。Flink 任务停止后&…
【Flink】SQL-CLIENT中出现 Could not find any factory for identifier ‘kafka‘
在Flink的sql-client客户端中执行sql代码时出现如下错误,版本Flink1.13.6 [ERROR] Could not execute SQL statement. Reason: org.apache.flink.table.api.ValidationException: Could not find any factory for identifier kafka that implements org.apache.flink.table.fa…
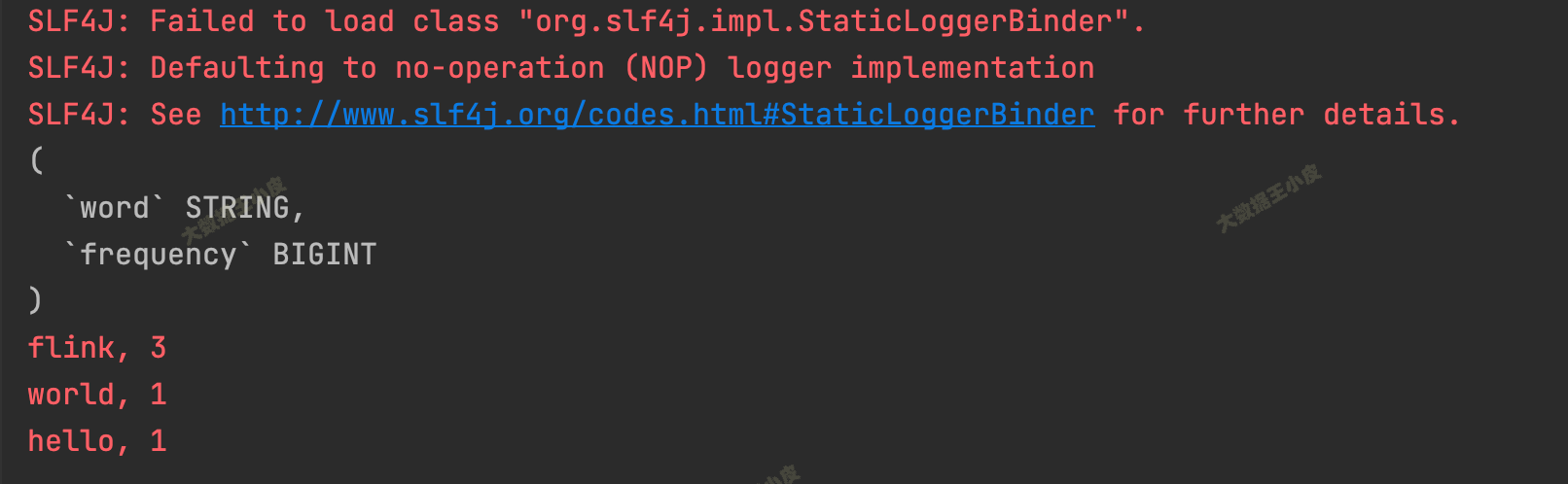
【Flink入门修炼】1-3 Flink WordCount 入门实现
本篇文章将带大家运行 Flink 最简单的程序 WordCount。先实践后理论,对其基本输入输出、编程代码有初步了解,后续篇章再对 Flink 的各种概念和架构进行介绍。 下面将从创建项目开始,介绍如何创建出一个 Flink 项目;然后从 DataStr…
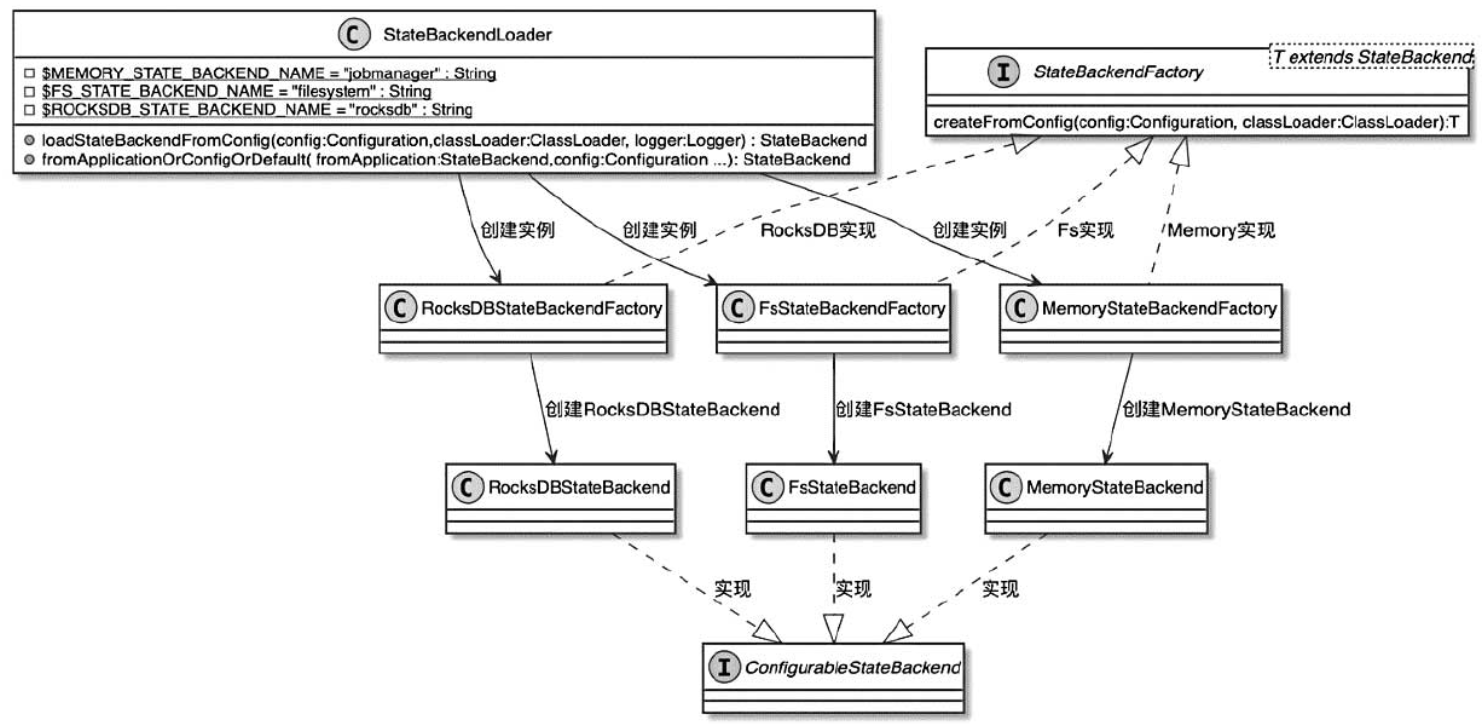
【flink状态管理(三)】StateBackend的整体设计、StateBackend创建说明
文章目录 一. 状态后端概述二. StateBackend的整体设计1. 核心功能2. StateBackend的UML3. 小结 三. StateBackend的加载与初始化1. StateBackend创建概述2. StateBackend创建过程 一. 状态后端概述
StateBackend作为状态存储后端,提供了创建和获取KeyedStateBacke…
【天衍系列 03】深入理解Flink的Watermark:实时流处理的时间概念与乱序处理
文章目录 01 基本概念02 工作原理03 优势与劣势04 核心组件05 Watermark 生成器 使用06 应用场景07 注意事项08 案例分析8.1 窗口统计数据不准8.2 水印是如何解决延迟与乱序问题?8.3 详细分析 09 项目实战demo9.1 pom依赖9.2 log4j2.properties配置9.3 Watermark水印…
【大数据面试题】007 谈一谈 Flink 背压
一步一个脚印,一天一道面试题(有些难点的面试题不一定每天都能发,但每天都会写)
什么是背压 Backpressure
在流式处理框架中,如果下游的处理速度,比上游的输入数据小,就会导致程序处理慢&…

Flink Task退出流程与Failover机制
这里写目录标题 1 TaskExecutor端Task退出逻辑2 JobMaster端failover流程2.1 Task Execute State Handle2.2 Job Failover2.2.1 Task Failure Handle2.2.2 Restart Task2.2.3 Cancel Task:2.2.4 Start Task 3 Task失败的自动重启策略 1 TaskExecutor端Task退出逻辑 …

Flink ML 的新特性解析与应用
摘要:本文整理自阿里巴巴算法专家赵伟波,在 Flink Forward Asia 2023 AI特征工程专场的分享。本篇内容主要分为以下四部分: Flink ML 概况在线学习的设计与应用在线推理的设计与应用特征工程算法与应用 一、Flink ML 概况 Flink ML 是 Apache…
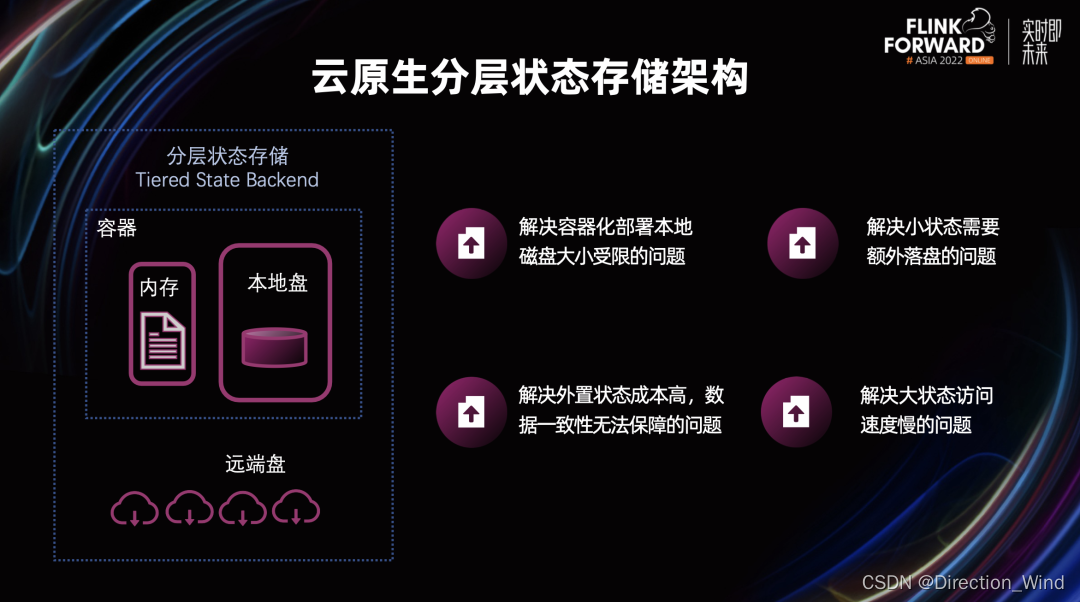
Flink checkpoint操作流程详解与报错调试方法汇总,增量checkpoint原理及版本更新变化,作业恢复和扩缩容原理与优化
Flink checkpoint操作流程详解与报错调试方法汇总,增量checkpoint原理及版本更新变化,作业恢复和扩缩容原理与优化 flink checkpint出错类型flink 重启策略Checkpint 流程简介增量Checkpoint实现原理MemoryStateBackend 原理FsStateBackend原理RocksDBSt…

Flink join详解(含两类API及coGroup、connect详解)
Flink SQL支持对动态表进行复杂而灵活的连接操作。 为了处理不同的场景,需要多种查询语义,因此有几种不同类型的 Join。
默认情况下,joins 的顺序是没有优化的。表的 join 顺序是在 FROM 从句指定的。可以通过把更新频率最低的表放在第一个、…
【Flink精讲】Flink 内存管理
面临的问题 目前, 大数据计算引擎主要用 Java 或是基于 JVM 的编程语言实现的,例如 Apache Hadoop、 Apache Spark、 Apache Drill、 Apache Flink 等。 Java 语言的好处在于程序员不需要太关注底层内存资源的管理,但同样会面临一个问题&…
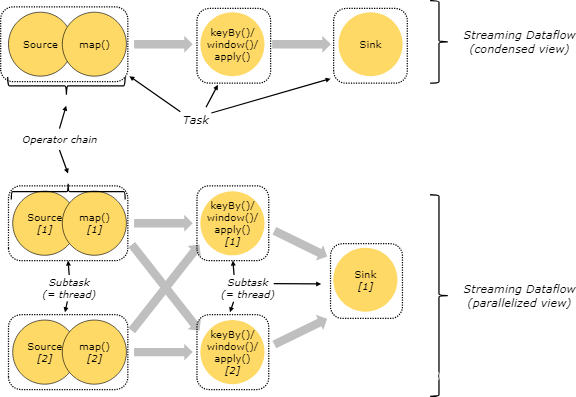
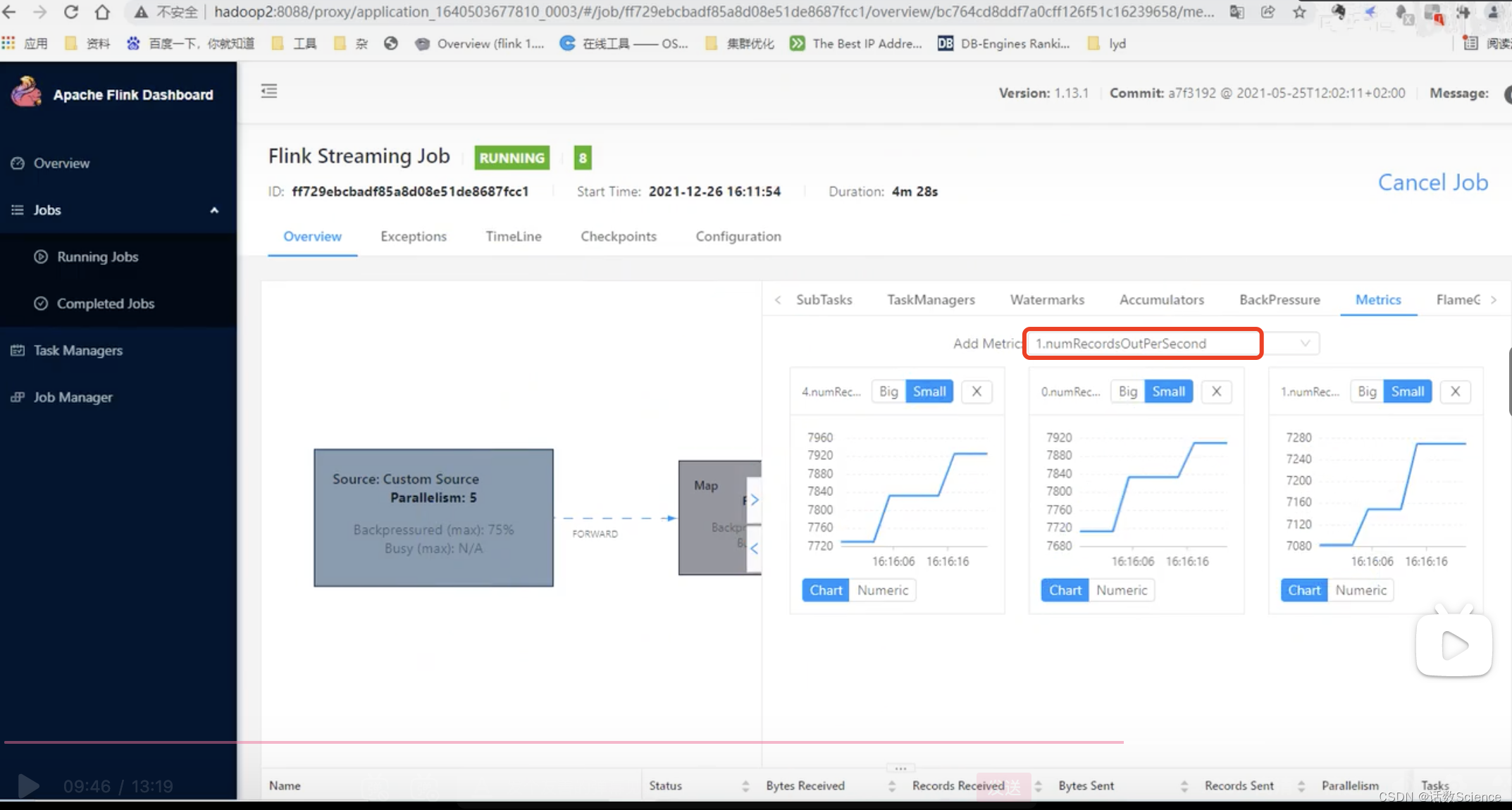
【Flink精讲】Flink性能调优:CPU核数与并行度
常见问题
举个例子
提交任务命令: bin/flink run \ -t yarn-per-job \ -d \ -p 5 \ 指定并行度 -Dyarn.application.queuetest \ 指定 yarn 队列 -Djobmanager.memory.process.size2048mb \ JM2~4G 足够 -Dtaskmanager.memory.process.size4096mb \ 单个 TM2~8G 足…

【大数据】Flink SQL 语法篇(四):Group 聚合
Flink SQL 语法篇(四):Group 聚合 1.基础概念2.窗口聚合和 Group 聚合3.SQL 语义4.Group 聚合支持 Grouping sets、Rollup、Cube 1.基础概念
Group 聚合定义(支持 Batch / Streaming 任务):Flink 也支持 G…
【大数据】Flink SQL 语法篇(四):Group 聚合、Over 聚合
Flink SQL 语法篇(四):Group 聚合、Over 聚合 1.Group 聚合1.1 基础概念1.2 窗口聚合和 Group 聚合1.3 SQL 语义1.4 Group 聚合支持 Grouping sets、Rollup、Cube 2.Over 聚合2.1 时间区间聚合2.2 行数聚合 1.Group 聚合
1.1 基础概念
Grou…
Flink 1.11.0 版本介绍
Flink 1.11.0 发布于 2020 年,引入下面的新特性: 为了缓解 backpressure 下的 checkpointing 性能问题引入 unaligned checkpoints统一 Watermark Generator接口引入 Data Source API为 kubernates 引入新的部署模式:application modeUnaligned Checkpoints
触发一次 check…
测试环境搭建整套大数据系统(七:集群搭建kafka(2.13)+flink(1.14)+dinky+hudi)
一:搭建kafka。
1. 三台机器执行以下命令。
cd /opt
wget wget https://dlcdn.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgz
tar zxvf kafka_2.13-3.6.1.tgz
cd kafka_2.13-3.6.1/config
vim server.properties修改以下俩内容 1.三台机器分别给予各自的broker_id…
jdk21本地执行flink出现不兼容问题
环境说明:换电脑尝尝鲜,jdk,flink都是最新的,千辛万苦把之前的项目编译通过,跑一下之前的flink项目发现启动失败,啥都不说了上异常
Exception in thread "main" java.lang.IllegalAccessError: …
flink类加载器原理与隔离(flink jar包冲突)
flink类加载器原理与隔离 Java 类加载器解决类冲突基本思想什么是 Classpath?Jar 包中的类什么时候被加载?哪些行为会触发类的加载?什么是双亲委派机制?如何打破双亲委派机制? Flink 类加载隔离的方案Flink是如何避免类泄露的?Flink 卸载用户代码中动态加载的类Flink 卸载…
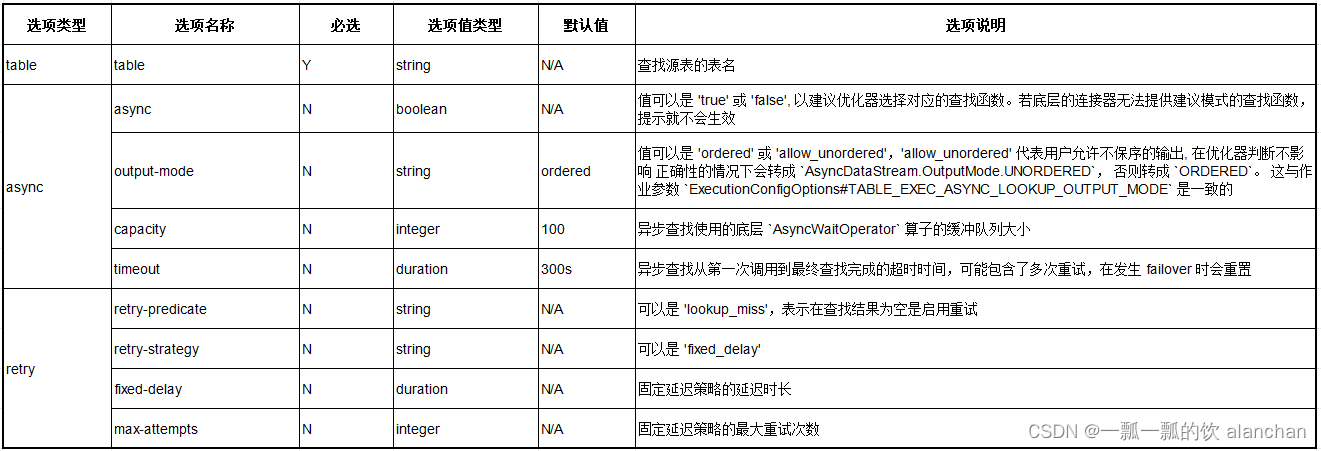
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2-1)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
用 flink 插件chunjun实现全量+增量同步-达梦数据库到postgresql
用 flink 插件chunjun实现全量增量同步,这里以达梦数据库同步到postgresql数据库为例。
纯钧下载地址:纯钧
纯钧是一款稳定、易用、高效、批流一体的数据集成框架,目前基于实时计算引擎Flink实现多种异构数据源之间的数据同步与计算&#x…
【Flink实战】玩转Flink里面核心的Source Operator实战
🚀 作者 :“大数据小禅” 🚀 文章简介 :【Flink实战】玩转Flink里面核心的Source Operator实战 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 目录导航 Flink 的API层级介绍Source Operator速览Flin…
FlinkException
org.apache.flink.util.FlinkException:Could not stop with a savepoint job
问题描述
------------------------------------------------------------The program finished with the following exception:org.apache.flink.util.FlinkException: Could not stop with a s…
Flink的自定义状态序列化器
背景
flink的状态序列化器不仅仅用于检查点的数据传输序列化,而且还用于TaskManager进程间的网络传输,最主要是flink的状态序列化器非常容易引起混淆,我们经常区分不出所谓的自定义状态序列化器是给一个全新类型定义一个完全的序列化程序还是…
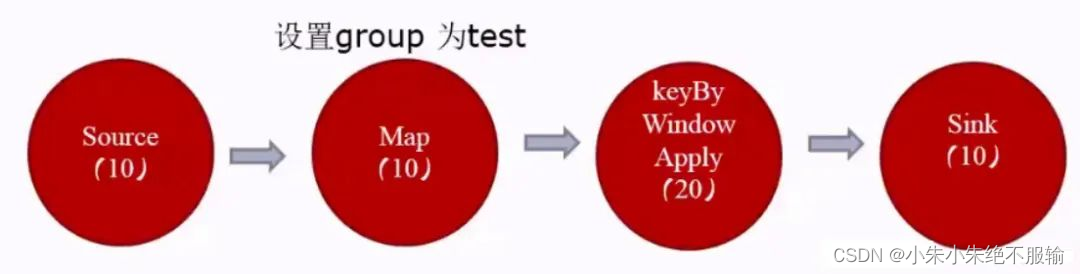
Flink内核源码(五)控制任务调度:作业链与处理槽共享组
第五章就来从源码层面学习一下Flink的控制任务调度——作业链与处理槽共享组。
问题整理: 1. 什么是任务链?作业链怎么操作? 2. 什么是槽共享组?slot共享机制是怎么实现的? 3. 如何通过调整默认行为以及控制作业链与…
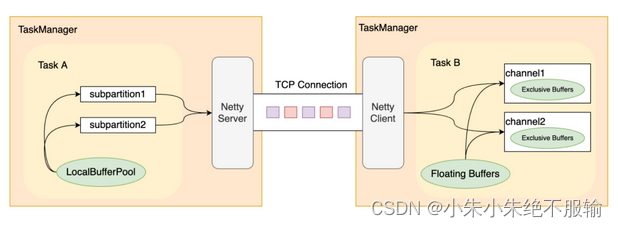
Flink内核源码(四)内存管理
最近在学习了尚硅谷的Flink内核源码解析,内容很多,因此想要整理学习一下。Flink的版本是1.12.0。
第四章就来从源码层面学习一下Flink的内存管理机制。
问题整理:
1. JVM内存管理有什么不足? 2. Flink的内存管理机制是怎样的&a…
Flink读取kafka数据报错
报错如下:
D:\software_install\java\bin\java.exe "-javaagent:C:\Program Files\JetBrains\IntelliJ IDEA 2021.2.3\lib\idea_rt.jar58672:C:\Program Files\JetBrains\IntelliJ IDEA 2021.2.3\bin" -Dfile.encodingUTF-8 -classpath D:\software_inst…

别再乱用 Prometheus 联邦了,分享一个 Prometheus 高可用新方案
前言我看到很多人会这样使用联邦:联邦 prometheus 收集多个采集器的数据实在看不下下去了,很多小白还在乱用prometheus的联邦其实很多人是想实现 prometheus 数据的可用性,数据分片保存,有个统一的查询地方(小白中的联邦 promethe…

可以节能的能耗数据监测管理系统
现如今,软件企业很难涉及到底层的设施,节能公司很少做云端产品,做服务的节能公司更少,很少有司掌握能源应用技术,且对能耗数据管理的产业链清晰的知晓,并且一直都在进一步的实践与创新。
项目介绍…
Flink RoaringBitmap去重
1、RoaringBitmap的依赖 <!-- 去重大哥-->
<dependency><groupId>org.roaringbitmap</groupId><artifactId>RoaringBitmap</artifactId><version>0.9.21</version>
</dependency>
2、Demo去重
package com.gwm.driver…
实时指标-1日留存率
2个DWD层 登录→kafka注册→kafka1个DWS 弄2条流,从kafka读取数据将昨日注册数据存到状态中,TTL为2天,存到map状态中,key为注册日期,value为set,存储注册的uid将登录流和注册流进行连接来一条登录数据&…
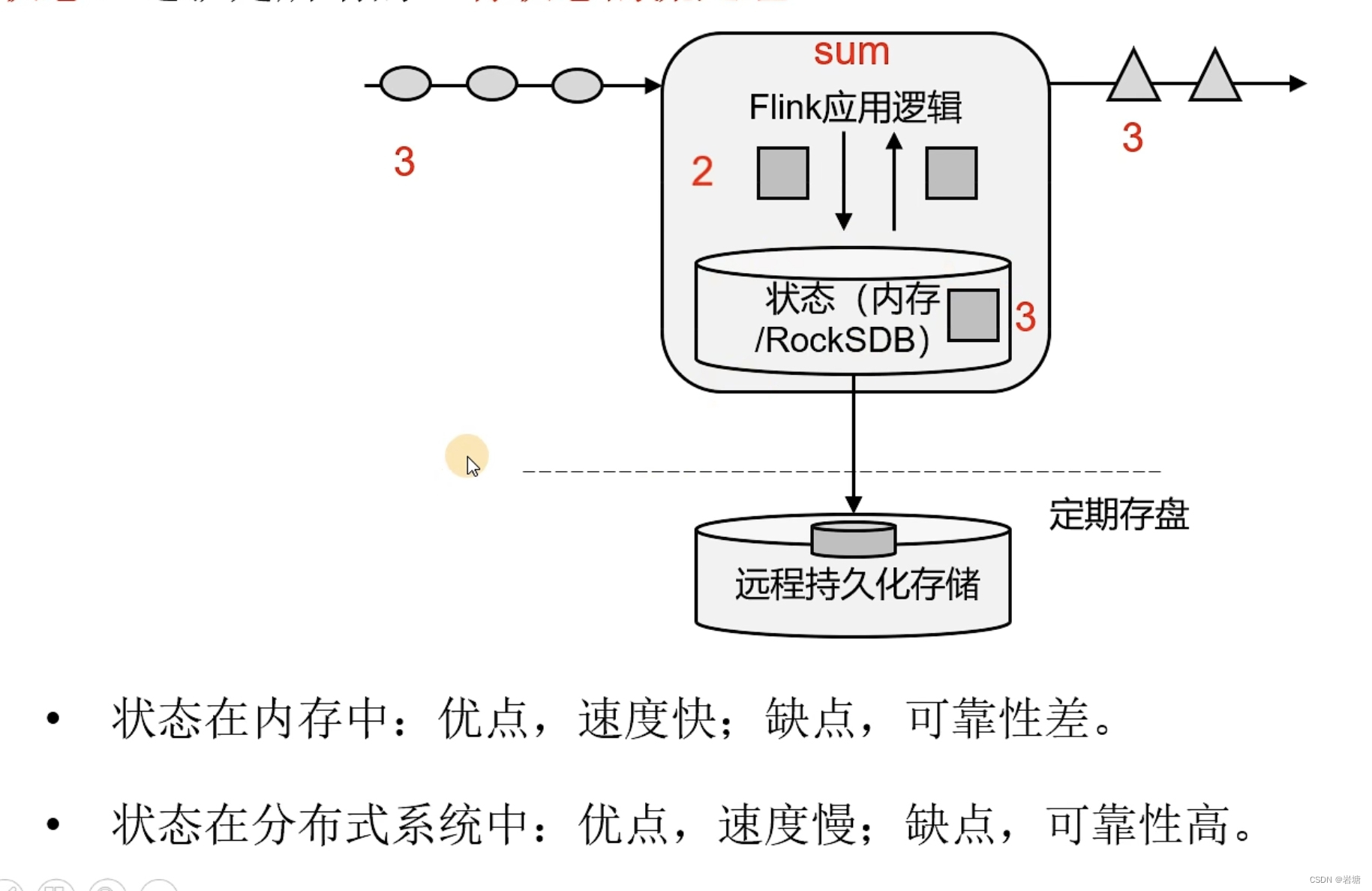
【Flink、java】
事件驱动型应用
核心目标:数据流上的有状态计算
Apache Flink是一个框架和分布式处理引擎,用于对无界或有界数据流进行有状态计算。
运行逻辑 状态
把流处理需要的额外数据保存成一个“状态”,然后针对这条数据进行处理,并且更新状态。这就是所谓的“…

Flink安装及简单使用
目录 转载处(个人用最新1.17.1测试)
依赖环境
安装包下载地址
Flink本地模式搭建
安装
启动集群
查看WebUI
停止集群
Flink Standalone搭建
安装
修改flink-conf.yaml配置文件
修改workers文件
复制Flink安装文件到其他服务器
启动集群
查…
Apache Hudi初探(五)(与flink的结合)--Flink 中hudi clean操作
背景
本文主要是具体说说Flink中的clean操作的实现
杂说闲谈
在flink中主要是CleanFunction函数: Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);this.writeClient FlinkWriteClients.createWriteClient(conf,…

CDH 6.3.2升级Flink到1.17.1版本
CDH:6.3.2 原来的Flink:1.12 要升级的Flink:1.17.1 操作系统:CentOS Linux 7
一、Flink1.17编译 build.sh文件:
#!/bin/bash
set -x
set -e
set -vFLINK_URLsed /^FLINK_URL/!d;s/.*// flink-parcel.properties
FLI…
208.Flink(三):窗口的使用,处理函数的使用
目录
一、窗口
1.窗口的概念
2.窗口的分类
(1)按照驱动类型分
(2)按照窗口分配数据的规则分类
3.窗口api概览
(1)按键分区(Keyed)和非按键分区(Non-Keyed)
*1)按键分区窗口(Keyed Windows)
*2)非按键分区(Non-Keyed Windows)
(2)代码中窗口API的调…
Flink 内存模型
Jobmanage内存模型
1G 1C 的配置 上图不够直观,用户大脑无法第一反应出内存构成。 Total Process Memory = JVM堆内存 + JVM堆外内存(堆外内存+ JVM元空间 +JVM自身运行内存)
Total Flink Memory = JVM堆内存 + 堆外内存
参数控制:
Total Process Memory 对应 jobmanag…

【时区】Flink JDBC 和CDC时间字段时区 测试及时间基准
关联文章: 各种时间类型和timezone关系浅析
一、测试目的和值
1. 测试一般的数据库不含time zone的类型的时区。
mysql timestamp(3) 类型postgres timestamp(3) 类型sqlserver datetime2(3) 类型oracle类型 TIMESTAMP(3) 类型 在以下测试之中均为ts字段
2.测试CDC中元数据…
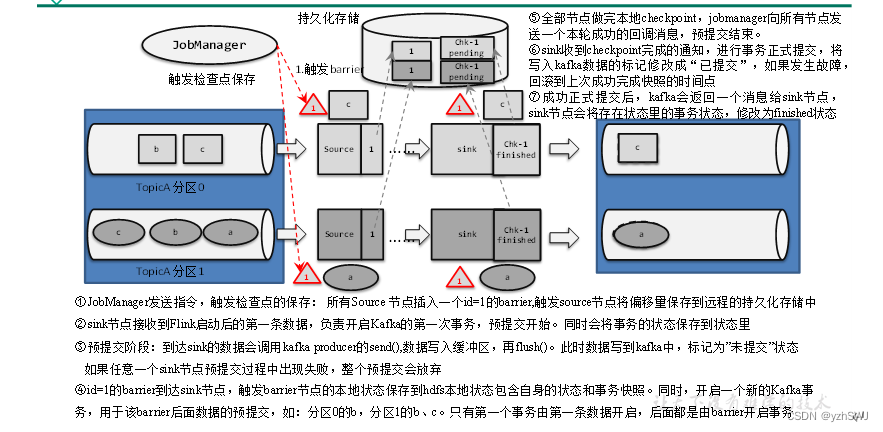
修炼k8s+flink+hdfs+dlink(一:安装hdfs)
一:安装jdk,并配置环境变量。
在对应的所有的节点上进行安装。
mkdir /opt/app/java
cd /opt/app/java
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24http%3A%2F%2Fwww.oracle.com%
2F; oraclelicenseaccept-securebackup…
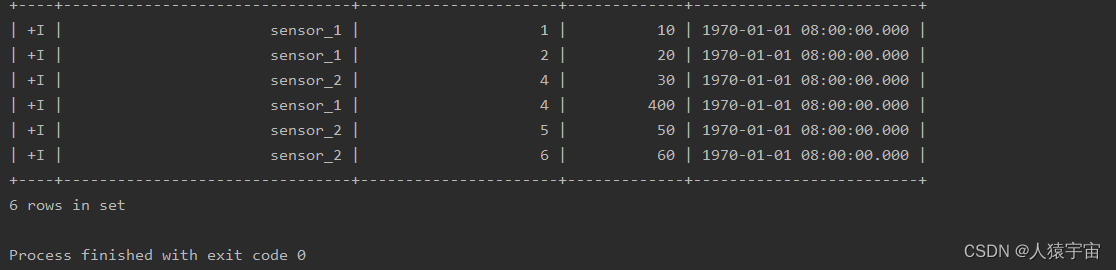
玩转数据-大数据-Flink SQL 中的时间属性
一、说明
时间属性是大数据中的一个重要方面,像窗口(在 Table API 和 SQL )这种基于时间的操作,需要有时间信息。我们可以通过时间属性来更加灵活高效地处理数据,下面我们通过处理时间和事件时间来探讨一下Flink SQL …
flink生成水位线记录方式--周期性水位线生成器
背景
在flink基于事件的时间处理中,水位线记录的生成是一个很重要的环节,本文就来记录下几种水位线记录的生成方式的其中一种:周期性水位线生成器
周期性水位线生成器
1.1 BoundedOutOfOrdernessTimeStampExtractor 他会接收一个表示最大延…
Flink读取数据的5种方式(文件,Socket,Kafka,MySQL,自定义数据源)
Flink读取数据的5种方式 从文件中读取数据从Socket中读取数据从Kafka中读取数据从MySQL中读取数据从自定义数据源读取数据 从文件中读取数据
这是最简单的数据读取方式。当需要进行功能测试时,可以将数据保存在文件中,读取后验证流处理的逻辑是否符合预…
什么是API网关,解释API网关的作用和特点?解释什么是数据流处理,如Apache Flink和Spark Streaming的应用?
1、什么是API网关,解释API网关的作用和特点?
API网关是一种在分布式系统中的组件,用于管理不同系统之间的通信和交互。API网关的作用是在不同系统之间提供统一的接口和协议,从而简化系统之间的集成和互操作性。
API网关的特点包…
flinkcdc数据采集代码FlinkAPI
1. flinkcdc数据采集代码:
背景
使用flinkcdc采集mysql数据到kafka,经过长达两个月的各种调试,终于把调试后的版本给写出来了,进行的全量加增量的数据采集,并写了一个窗口,每隔10min中更新一次每张表同步…
19、Flink 的Table API 和 SQL 中的自定义函数及示例(2)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
Flink之Watermark
1.乱序问题
流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因࿰…
Flink TableSQL的底层原理和企业应用
目录
1.动态表
2.持续查询(Continuous Query)
3.表的查询
3.1Table API的调用
3.1.1将DataStream转换成表
209.Flink(四):状态,按键分区,算子状态,状态后端。容错机制,检查点,保存点。状态一致性。flink与kafka整合
一、状态
1.概述
算子任务可以分为有状态、无状态两种。 无状态:filter,map这种,每次都是独立事件有状态:sum这种,每次处理数据需要额外一个状态值来辅助。这个额外的值就叫“状态”2.状态的分类
(1)托管状态(Managed State)和原始状态(Raw State)
托管状态就是由…
广播状态实现注意事项
背景:
日常我们事件流总要关联上其他的静态数据来组成一条完整的记录,例如事件流规则表来组合出一条完整的记录流,这个时候规则表就要设置成广播状态的形式来支持快速流操作
技术实现
// 广播处理函数new KeyedBroadcastProcessFunction&l…
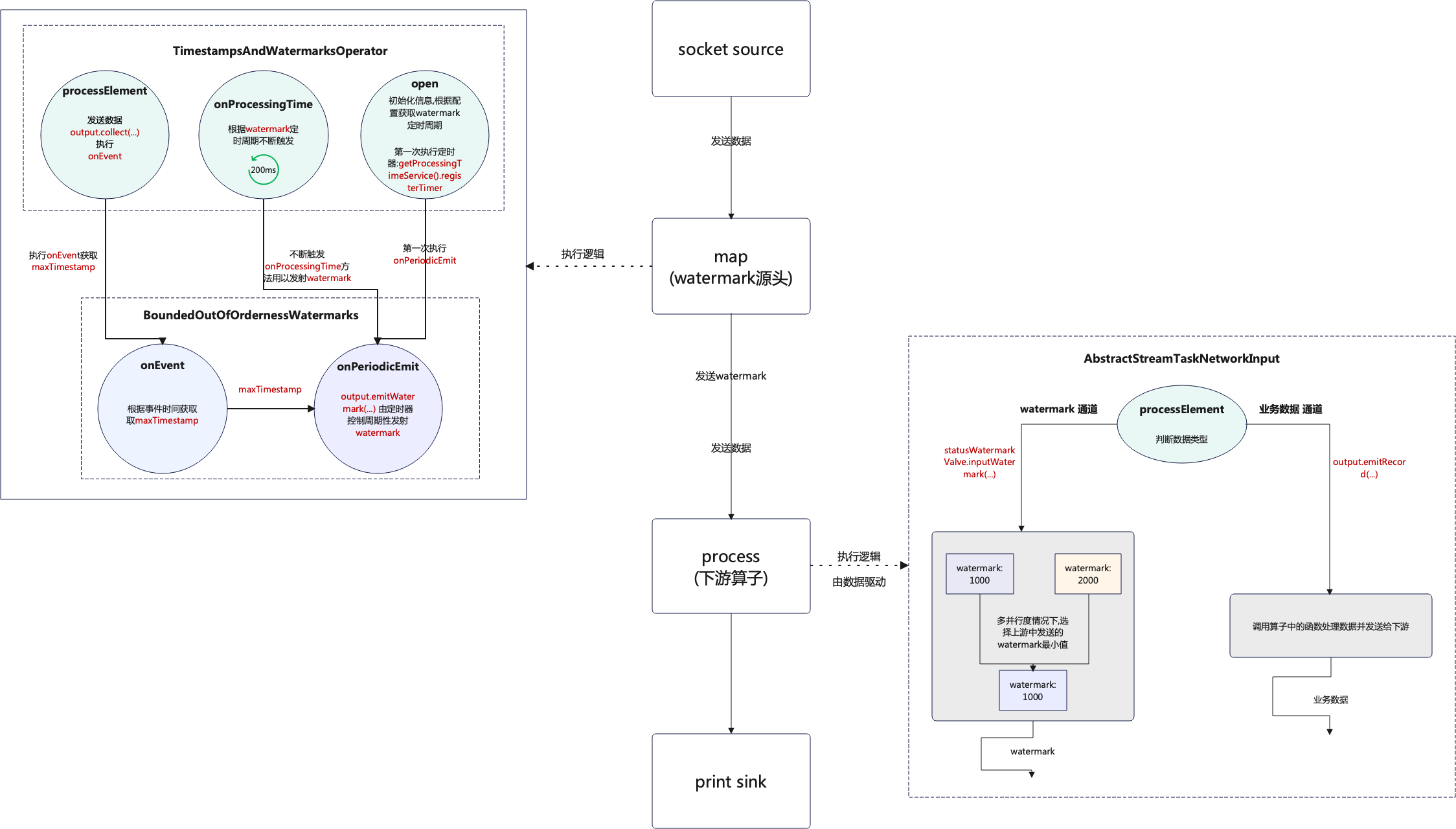
Flink之Watermark源码解析
1. WaterMark源码分析 在Flink官网中介绍watermark和数据是异步处理的,通过分析源码得知这个说法不够准确或者说不够详细,这个异步处理要分为两种情况: watermark源头watermark下游 这两种情况的处理方式并不相同,在watermark的源头确实是异步处理的,但是在下游只是做的判断,这…
flink中使用外部定时器实现定时刷新
背景:
我们经常会使用到比如数据库中的配置表信息,而我们不希望每次都去查询db,那么我们就想定时把db配置表的数据定时加载到flink的本地内存中,那么如何实现呢?
外部定时器定时加载实现
1.在open函数中进行定时器的…
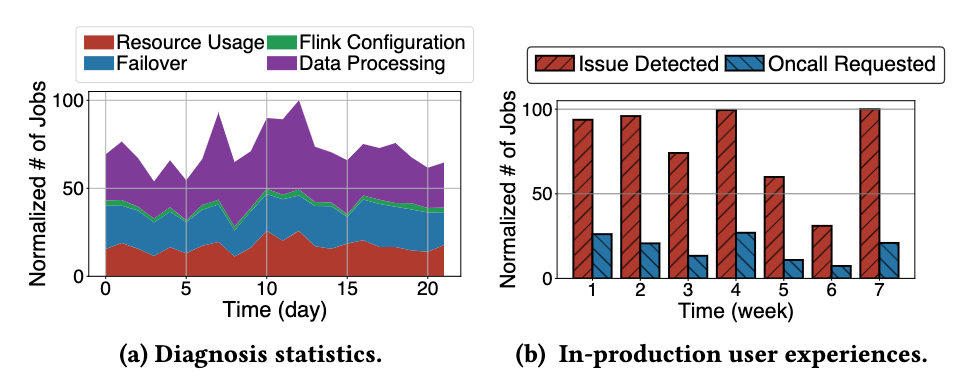
数据库顶会 VLDB 2023 论文解读:字节跳动如何解决超大规模流式任务运维难题
本文解读了新加坡国立大学马天白教授团队、字节跳动基础架构-计算-流式计算团队联合发表在国际数据库与数据管理顶级会议 VLDB 2023 上的论文“StreamOps: Cloud-Native Runtime Management for Streaming Services in ByteDance”,介绍字节跳动内部基于数万 Flink …

1. Flink简述
Flink与Spark Streaming对比
数据模型和处理模型
Spark 的数据模型是 RDD,很多时候 RDD 可以实现为分布式共享内存或者完全虚拟化(即有的中间结果 RDD 当下游处理完全在本地时可以直接优化省略掉)。这样可以省掉很多不必要的 I/O。
…

修炼k8s+flink+hdfs+dlink(四:k8s(二)组件)
一:控制平面组件。
控制平面组件会为集群做出全局决策,比如资源的调度。 以及检测和响应集群事件,例如当不满足部署的 replicas 字段时, 要启动新的 pod)。
1. kube-apiserver。
该组件负责公开了 Kubernetes API&a…

flink的网络缓冲区
背景
在flink的taskmanager进行数据交互的过程中,网络缓冲区是一个可以提升网络交换速度的设计,此外,flink还通过网络缓冲区实现其基于信用值credit的流量控制,以便尽可能的处理数据倾斜问题
网络缓冲区
在flink中每个taskmana…
大数据flink篇之三-flink运行环境安装(一)单机Standalone安装
一、安装包下载地址 https://archive.apache.org/dist/flink/flink-1.15.0/ 二、安装配置流程 前提基础:Centos环境(建议7以上) 安装命令: 解压:tar -zxvf flink-xxxx.tar.gz 修改配置conf/flink-conf.yaml࿱…
flink1.15 savepoint 超时报错 java.util.concurrent.TimeoutException
savepoint命令
flink savepoint e04813d4e7480c526912eb4d32bba510 hdfs://flink/flink/migration/savepoint56650 -Dyarn.application.id=application_1683808492336_1222报错内容
org.apache.flink.util.FlinkException: Triggering a savepoint for the job e04813d4e7480…
Flink自定义sink并支持insert overwrite 功能
前言
自定义flink sink,批模式下,有insert overwrite 需求或需要启动任务或任务完成后时,只执行一次某些操作时,则可参考此文章
分析
待补充
步骤
待补充

【Flink实战】新老用户分析:按照操作系统维度进行新老用户的分析
🚀 作者 :“大数据小禅” 🚀 文章简介 :新老用户分析:按照操作系统维度进行新老用户的分析 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 目录导航 同类产品参考日志的数据格式需求&…

大数据Flink(九十四):DML:TopN 子句
文章目录
DML:TopN 子句 DML:TopN 子句
TopN 定义(支持 Batch\Streaming):TopN 其实就是对应到离线数仓中的 row_number(),可以使用 row_number() 对某一个分组的数据进行排序
应用场景
Flink--7、窗口(窗口的概念、分类、API、分配器、窗口函数)、触发器、移除器
星光下的赶路人star的个人主页 内心的平静始于不再让他人掌控你的感情 文章目录 0、前言1、窗口(Window)1.1 窗口的概念1.2 窗口的分类1.3 窗口API概览1.4 窗口分配器(Window Assigner)1.4.1 时间窗口1.4.2 计数窗口 1.5 窗口函数…

# Flink的状态
1.什么是时状态(state)? 有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。 例如以下状态都需要使用流处理的状态功能:
数据流中的数据有重复,…
Flink---10、处理函数(基本处理函数、按键分区处理函数、窗口处理函数、应用案例TopN、侧输出流)
星光下的赶路人star的个人主页 我的敌手就是我自己,我要他美好到能使我满意的程度 文章目录 1、处理函数1.1 基本处理函数(ProcessFunction)1.1.1 处理函数的功能和使用1.1.2 ProcessFunction解析1.1.3 处理函数的分类 1.2 按键分区处理函数&…

Flink学习笔记(二):Flink内存模型
文章目录 1、配置总内存2、JobManager 内存模型3、TaskManager 内存模型4、图形化展示5、实际案例计算内存分配 1、配置总内存
Flink JVM 进程的进程总内存(Total Process Memory)包含了由 Flink 应用使用的内存(Flink 总内存)以…
Flink -- 状态与容错
1、Stateful Operations 有状态算子:
有状态计算,使用到前面的数据,常见的有状态的算子:例如sum、reduce,因为它们在计算的时候都是用到了前面的计算的结果
总结来说,有状态计算并不是独立存在的…
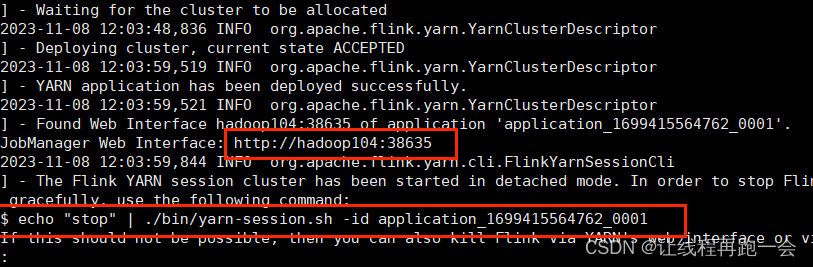
Flink(二)【Flink 部署模式】
前言 今天是Flink学习的第二天,我的心情异常的复杂哈哈哈(苦笑),学习上还是比较顺利的,感情上我并不擅长,所以心情波动大在所难免。害,至少还有学习让我不被各种糟糕琐碎的日常生活里的人和事所…
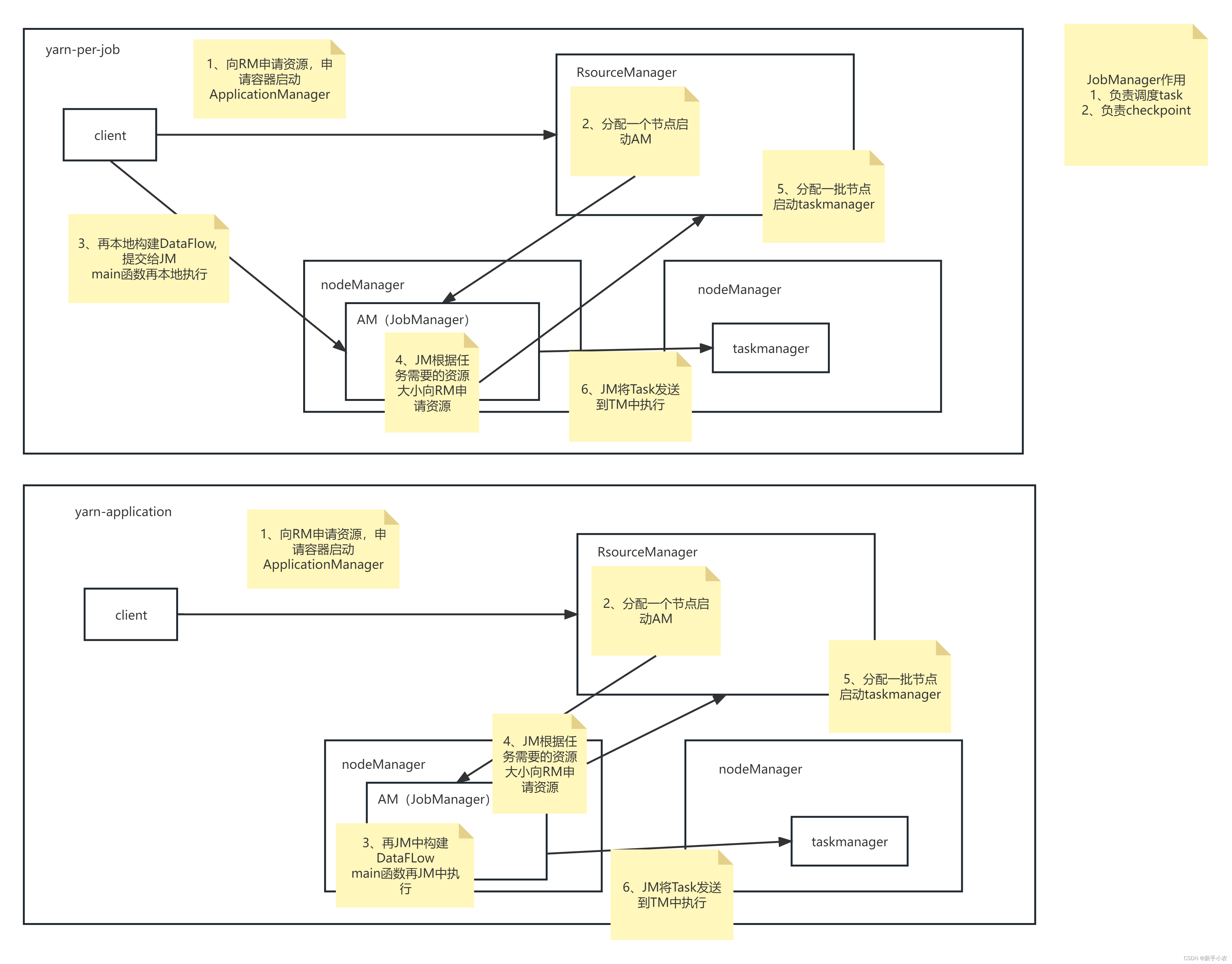
Flink ON Yarn 模式 --- per job mode 与application mode的区别
1、per job mode: 对于yarn-per-job模式调度的过程: 1、资源调度: 1、因为是yarn模式,所以客户端会向ResourceManager申请资源,申请容器负责来启动ApplicationManager 2、此时ResourceManager接受到客户端的请求&#…
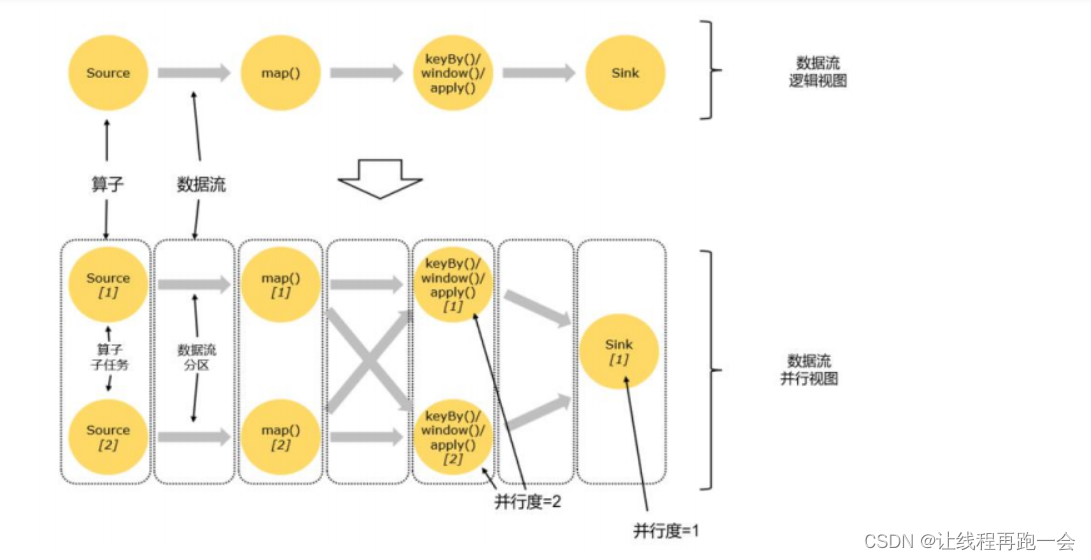
Flink(三)【运行时架构】
前言 今天学习 Flink 的一些原理性的东西,比较偏概念,但是十分重要。有人觉得上来框框敲代码才能学到东西,那是狗屁不通的道理(虽然我以前也这么认为)。个人认为,学习 JavaEE那些框架,你上来就敲…
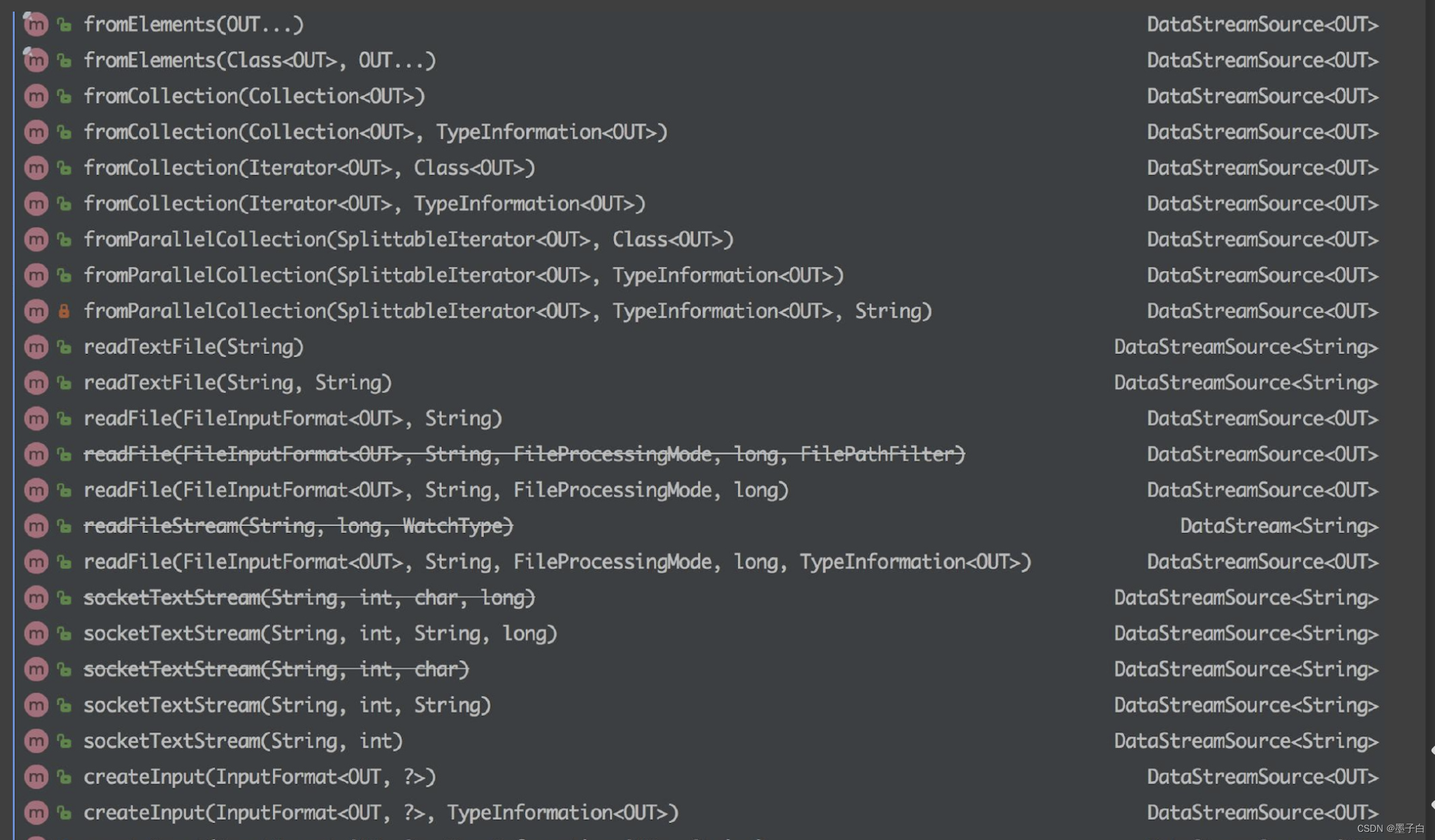
Flink—— Data Source 介绍
Data Source 简介 Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来ÿ…
Flink之Catalog
Catalog Catalog概述Catalog分类 GenericInMemoryCatalogJdbcCatalog下载JAR包及使用重启操作创建Catalog查看与使用Catalog自动初始化catalog HiveCatalog下载JAR包及使用重启操作hive metastore服务创建Catalog查看与使用CatalogFlink与Hive中操作自动初始化catalog 用户自定…
Flink(四)【DataStream API - Source算子】
前言 今天开始学习 DataStream 的 API ,这一块是 Flink 的核心部分,我们不去学习 DataSet 的 API 了,因为从 Flink 12 开始已经实现了流批一体, DataSet 已然是被抛弃了。忘记提了,从这里开始,我开始换用 F…
Flink SQL --Flink 整合 hive
1、整合
# 1、将依赖包上传到flink的lib目录下
flink-sql-connector-hive-3.1.2_2.12-1.15.2.jar# 2、重启flink集群
yarn application -list
yarn application -kill application_1699579932721_0003
yarn-session.sh -d# 3、重新进入sql命令行
sql-client.sh
2、Hive cata…
Flink SQL处理回撤流(Retract Stream)案例
Flink SQL支持处理回撤流(Retract Stream),下面是一个使用Flink SQL消费回撤流的案例:
假设有一个数据流,包含用户的姓名和年龄,希望计算每个姓名的年龄总和。
以下是示例代码:
// 创建流执行…
Flink和Kafka连接时的精确一次保证
Flink写入Kafka两阶段提交
端到端的 exactly-once(精准一次) kafka -> Flink -> kafka 1)输入端
输入数据源端的 Kafka 可以对数据进行持久化保存,并可以重置偏移量(offset)
2)Flink内…
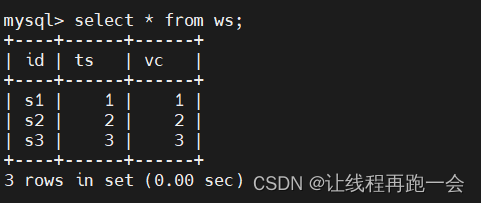
Flink(七)【输出算子(Sink)】
前言 今天是我写博客的第 200 篇,恍惚间两年过去了,现在已经是大三的学长了。仍然记得两年前第一次写博客的时候,当时学的应该是 Java 语言,菜的一批,写了就删,怕被人看到丢脸。当时就想着自己一年之后&…

Flink(林子雨慕课课程)
文章目录 12.Flink12.1 Flink简介12.2 为什么要选择Flink12.3 Flink应用场景12.4 Flink技术栈、体系架构和编程模型12.5 Flink的安装和编程实战 12.Flink
12.1 Flink简介 企业的处理架构已经由传统数据处理架构和大数据Lamda架构向流处理架构演变 Flink实现了Goole Dataflow…
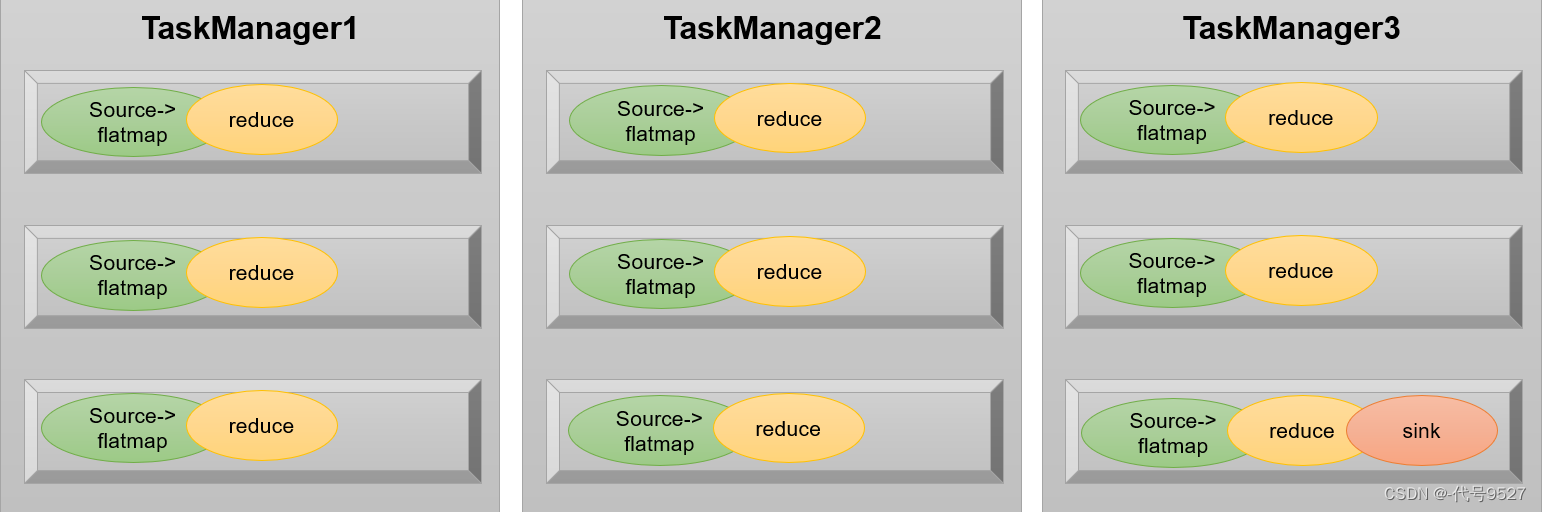
【基础篇】七、Flink核心概念
文章目录 1、并行度2、并行度的设置3、算子链4、禁用算子链5、任务槽6、任务槽和并行度的关系 1、并行度
要处理的数据量很多时,可以把一个算子的操作(比如前面demo里的flatMap、sum),"复制"多份到多个节点,…
Flink之窗口触发机制及自定义Trigger的使用
1 窗口触发机制 窗口计算的触发机制都是由Trigger类决定的,Flink中为各类内置的WindowsAssigner都设计了对应的默认Trigger. 层次结构如下: Trigger ProcessingTimeoutTriggerEventTimeTriggerCountTriggerDeltaTriggerNeverTrigger in GlobalWindowsContinuousEventTimeTrigge…
浅谈大数据之Flink-2
1.5 流处理基础概念
在某些场景下,流处理打破了批处理的一些局限。Flink作为一款以流处理见长的大数据引擎,相比其他流处理引擎具有众多优势。本节将对流处理的一些基本概念进行细化,这些概念是入门流处理的必备基础,至此你将正式进入数据流的世界。
1.5.1 延迟和吞吐 …
尚硅谷Flink(完)FlinkSQL
🧙FlinkSQL🏂🤺
Table API 和 SQL 是最上层的 API,在 Flink 中这两种 API 被集成在一起,SQL 执行的对象也是Flink 中的表(Table),所以我们一般会认为它们是一体的。
SQL API 是基于…
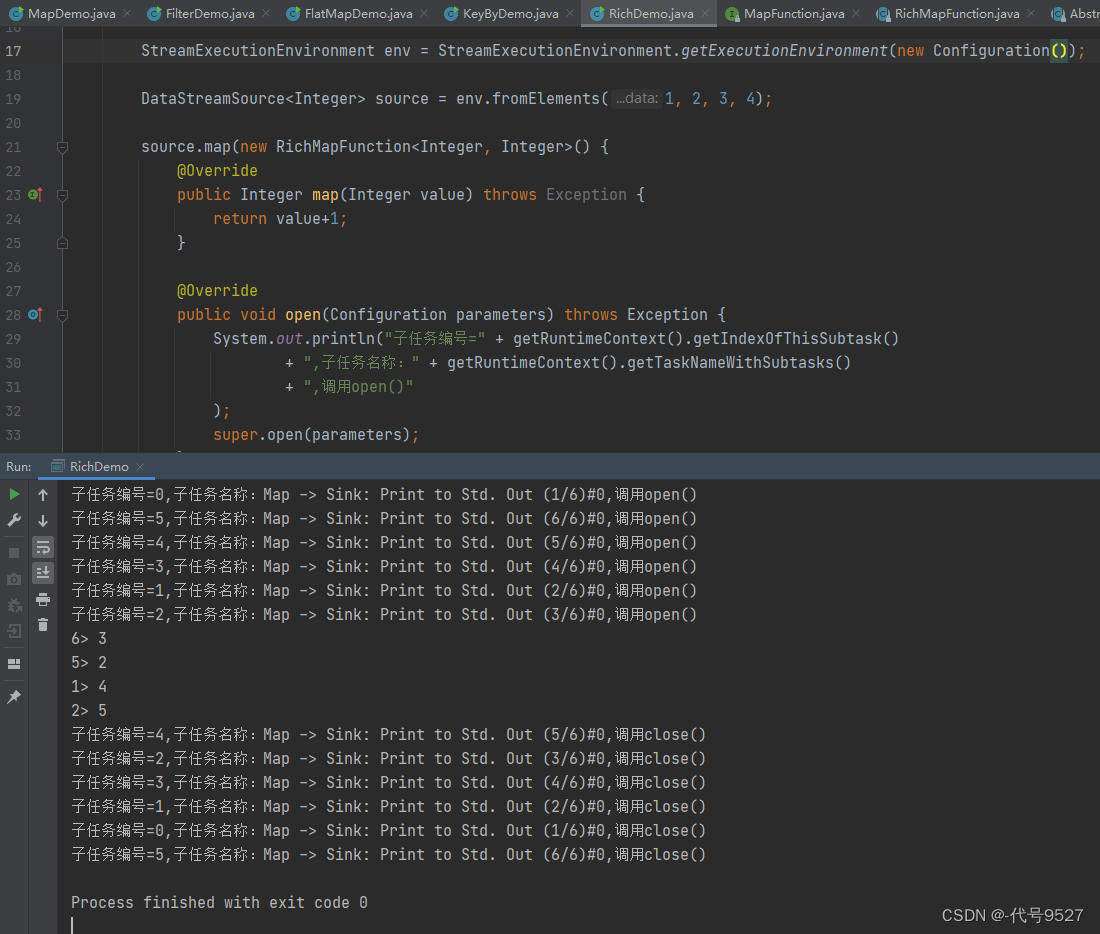
【API篇】三、转换算子API(上)
文章目录 0、demo数据1、基本转换算子:映射map2、基本转换算子:过滤filter3、基本转换算子:扁平映射flatMap4、聚合算子:按键分区keyBy5、聚合算子:简单聚合sum/min/max/minBy/maxBy6、聚合算子:归约聚合re…

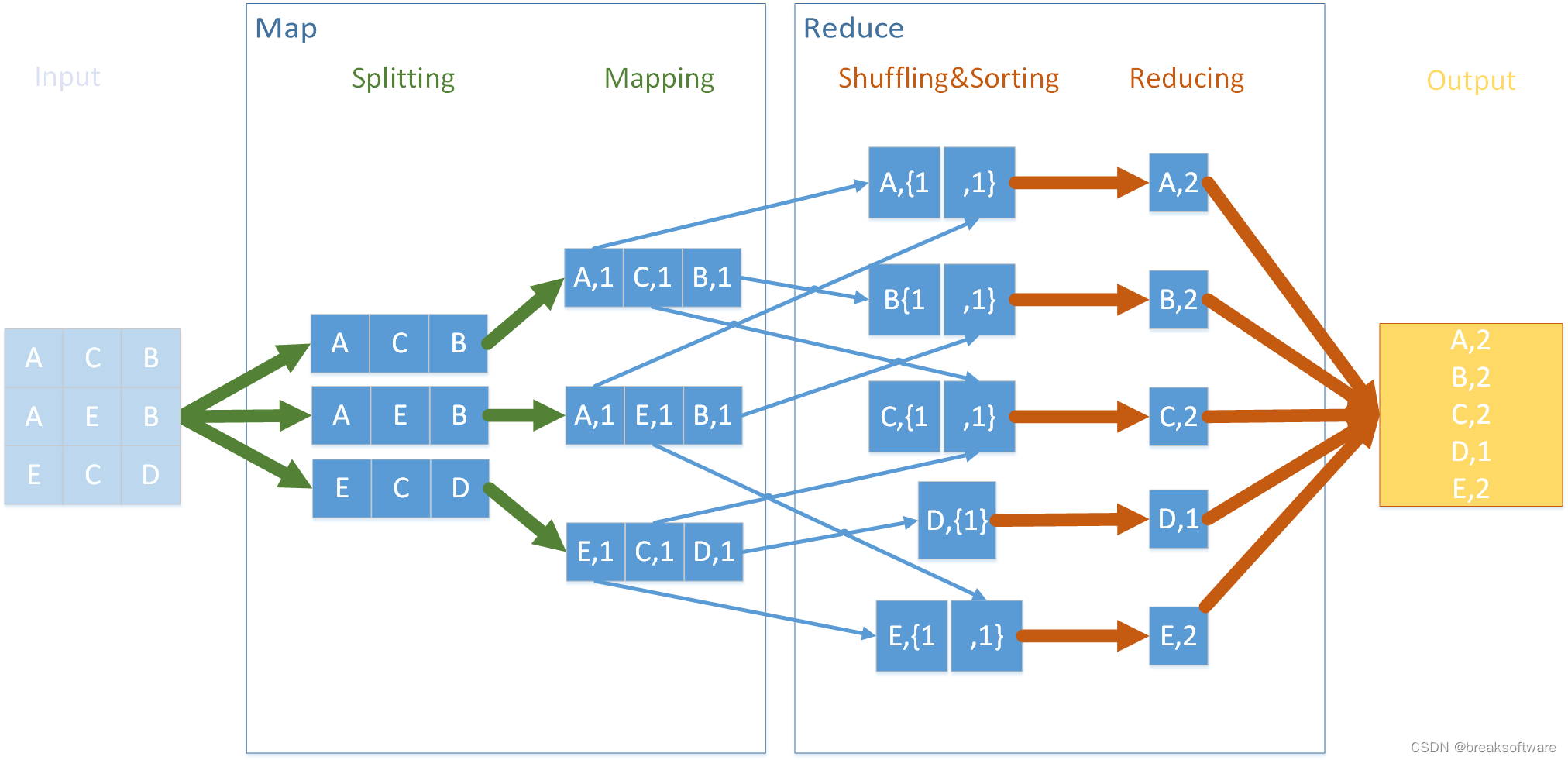
0基础学习PyFlink——模拟Hadoop流程
学习大数据还是绕不开始祖级别的技术hadoop。我们不用了解其太多,只要理解其大体流程,然后用python代码模拟主要流程来熟悉其思想。 还是以单词统计为例,如果使用hadoop流程实现,则如下图。
为什么要搞这么复杂呢? 顾…
Flink之输出算子Redis Sink
Redis Sink Redis Sinkjedis实现添加依赖自定义Redis Sink使用Sink验证 开源 Redis Connector添加依赖自定义Redis SinkRedisCommandString数据类型示例Hash数据类型示例 使用SinkRedisStringSinkRedisHashSink 验证 Redis Sink 在新版Flink的文档中,并没有发现Redi…

大数据Flink(一百零一):SQL 表值函数(Table Function)
文章目录
SQL 表值函数(Table Function) SQL 表值函数(Table Function)
Python UDTF,即 Python TableFunction,针对每一条输入数据,Python UDTF 可以产生 0 条、1 条或者多条输出数据,此外,一条输出数据可以包含多个列。比如以下示例,定义了一个名字为 split 的Pyt…
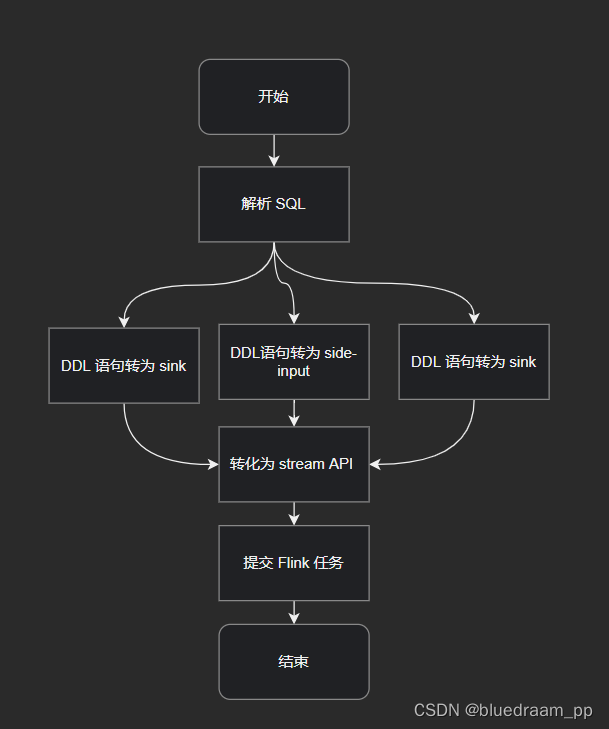
袋鼠云的FlinkSQL插件开发
袋鼠云是什么
袋鼠云是一家大数据产品供应商。他开发了一个产品叫做 flinkStreamSQL。这东西是以 Flink 为基础开发的使用 SQL 来写流式计算逻辑的产品。
FlinkStreamSQL 的开源地址
什么是插件
这里所说的插件是可以理解为自定义的语法。例如下面的 SQL:
sele…
Flink 维表关联
1、实时查询维表
实时查询维表是指用户在 Flink 算子中直接访问外部数据库,比如用 MySQL 来进行关联,这种方式是同步方式,数据保证是最新的。但是,当我们的流计算数据过大,会对外 部系统带来巨大的访问压力࿰…
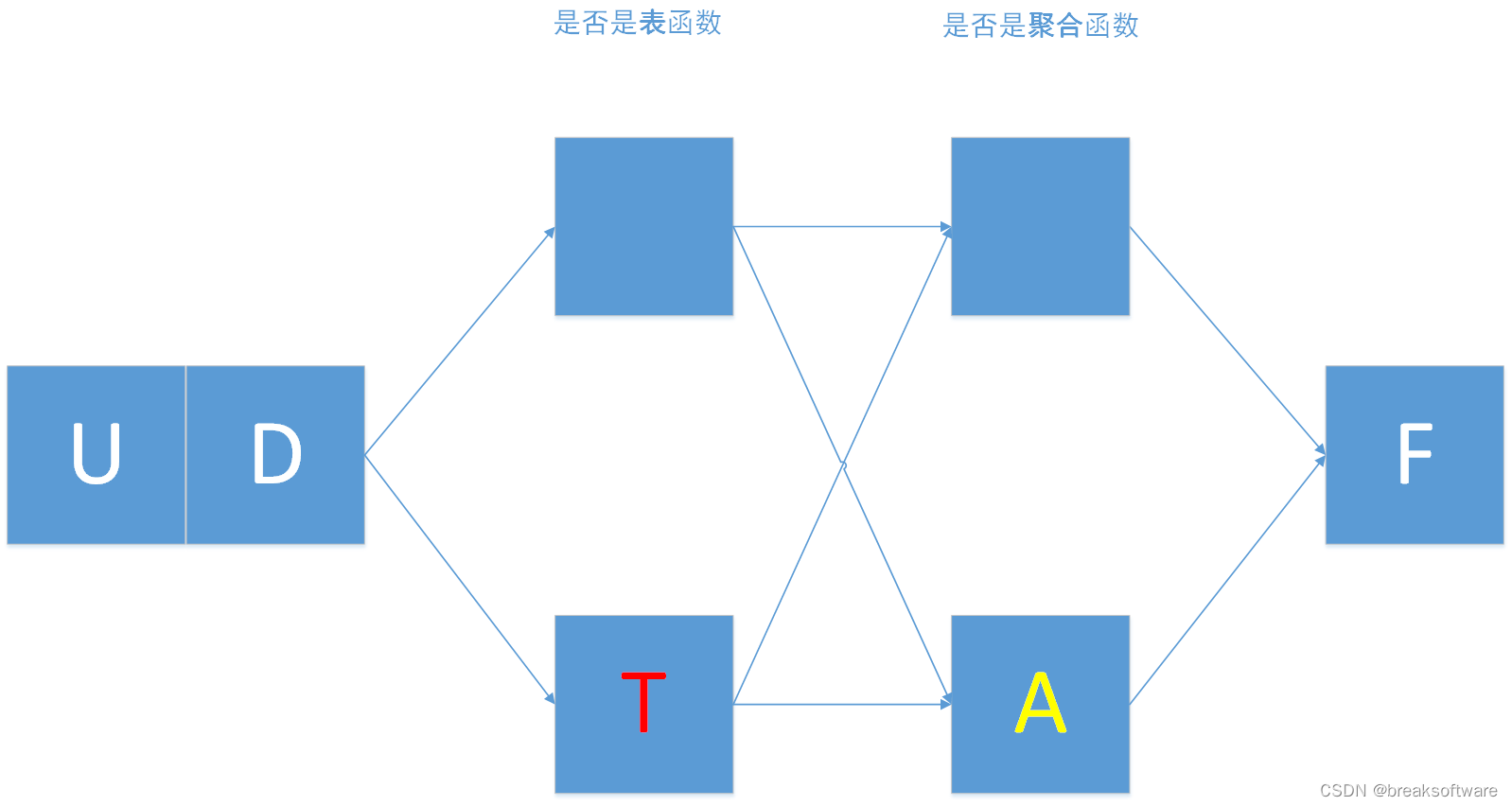
0基础学习PyFlink——用户自定义函数之UDF
大纲 标量函数入参并非表中一行(Row)入参是表中一行(Row)alias PyFlink中关于用户定义方法有: UDF:用户自定义函数。UDTF:用户自定义表值函数。UDAF:用户自定义聚合函数。UDTAF&…

Flink Hive Catalog操作案例
在此对Flink读写Hive表操作进行逐步记录,需要指出的是,其中操作Hive分区表和非分区表的DDL有所不同,以下分别记录。
基础环境
Hive-3.1.3 Flink-1.17.1
基本操作与准备
1、上传依赖jar包到flink/lib目录下
cp flink-sql-connector-hive-…

Flink CDC 2.0 主要是借鉴 DBLog 算法
DBLog 算法原理 DBLog 这个算法的原理分成两个部分,第一部分是分 chunk,第二部分是读 chunk。分 chunk 就是把一张表分为多个 chunk(桶/片)。我可以把这些 chunk 分发给不同的并发的 task 去做。例如:有 reader1 和 re…

0基础学习PyFlink——时间滚动窗口(Tumbling Time Windows)
大纲 mapreduce完整代码参考资料 在《0基础学习PyFlink——个数滚动窗口(Tumbling Count Windows)》一文中,我们发现如果窗口内元素个数没有达到窗口大小时,计算个数的函数是不会被调用的。如下图中红色部分 那么有没有办法让上图中(B,2&…

0基础学习PyFlink——时间滑动窗口(Sliding Time Windows)
在《0基础学习PyFlink——时间滚动窗口(Tumbling Time Windows)》我们介绍了不会有重复数据的时间滚动窗口。本节我们将介绍存在重复计算数据的时间滑动窗口。 关于滑动窗口,可以先看下《0基础学习PyFlink——个数滑动窗口(Sliding Count Windows&#x…
FlinkCDC系列:数据同步对部分字段的处理,只更新部分字段
在flinkCDC源数据配置中,只对表中的部分字段关注,通过监控部分字段进行数据更新或者不更新,对数据进行同步。主要通过以下两个参数:
column.exclude.list
默认: 空字符串
一个可选的、以逗号分隔的正则表达式列表,与…

flink的安装与使用(ubuntu)
组件版本 虚拟机:ubuntu-20.04.6-live-server-amd64.iso
flink:flink-1.18.0-bin-scala_2.12.tgz
jdk:jdk-8u291-linux-x64.tar flink 下载 1、官网:https://flink.apache.org/downloads/
2、清华镜像:https://mirr…

Flink SQL Over 聚合详解
Over 聚合定义(⽀持 Batch\Streaming):**特殊的滑动窗⼝聚合函数,拿 Over 聚合 与 窗⼝聚合 做对⽐。
窗⼝聚合:不在 group by 中的字段,不能直接在 select 中拿到
Over 聚合:能够保留原始字段…
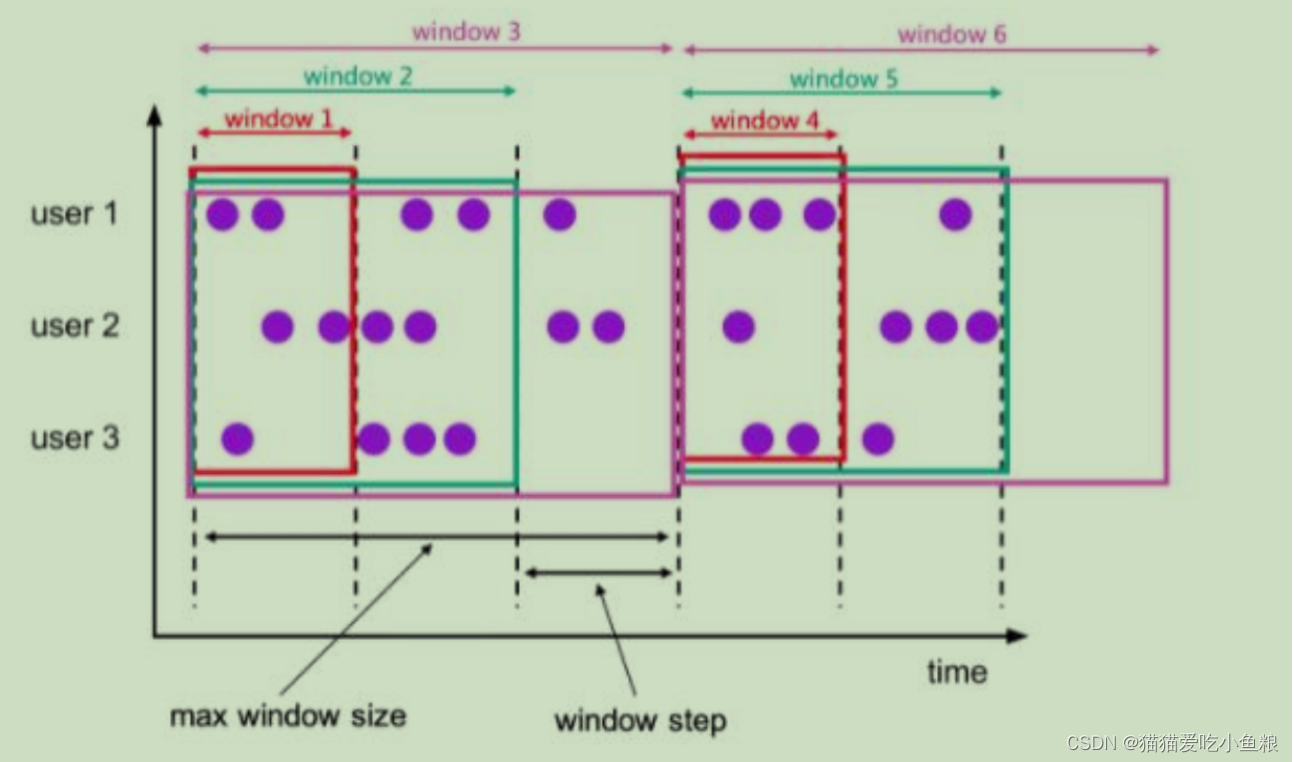
Flink SQL时间属性和窗口介绍
(1)概述
时间属性(time attributes),其实就是每个表模式结构(schema)的一部分。它可以在创建表的 DDL 里直接定义为一个字段,也可以在 DataStream 转换成表时定义。
一旦定义了时间…

大数据技能竞赛(需要提供相关答疑私信)
全国职业院校技能大赛模拟题 (平台搭建,离线数据清洗,实时数据分析,可视化,综合分析) 大数据平台搭建 大数据技术与应用技能竞赛题目解析及代码分析实验 Hadoop完全分布式安装配置/伪分布式安装配置 Spark、…
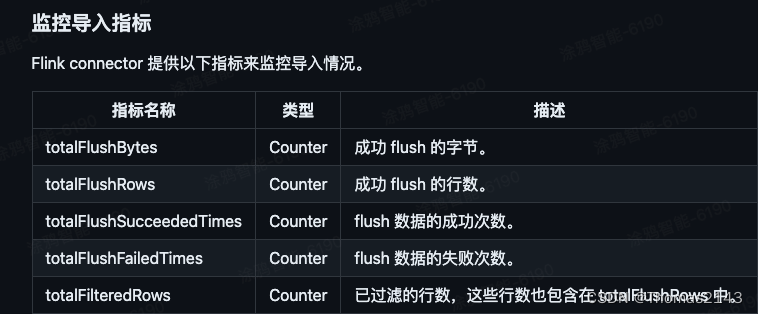
flink 查看写入starrocks的数据量 总行数
针对该connector: https://github.com/StarRocks/docs.zh-cn/blob/main/loading/Flink-connector-starrocks.md

快速灵敏的Flink2
flink基础知识
TumblingEventTimeWindows 滚动开窗 package org.apache.flink.streaming.api.windowing.assigners;import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.api.common.ExecutionConfig;
import org.apache.flink.api.common.typeutils.…

31、Flink的SQL Gateway介绍及示例
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
Flink--Data Source 介绍
Data Source 简介 Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来ÿ…
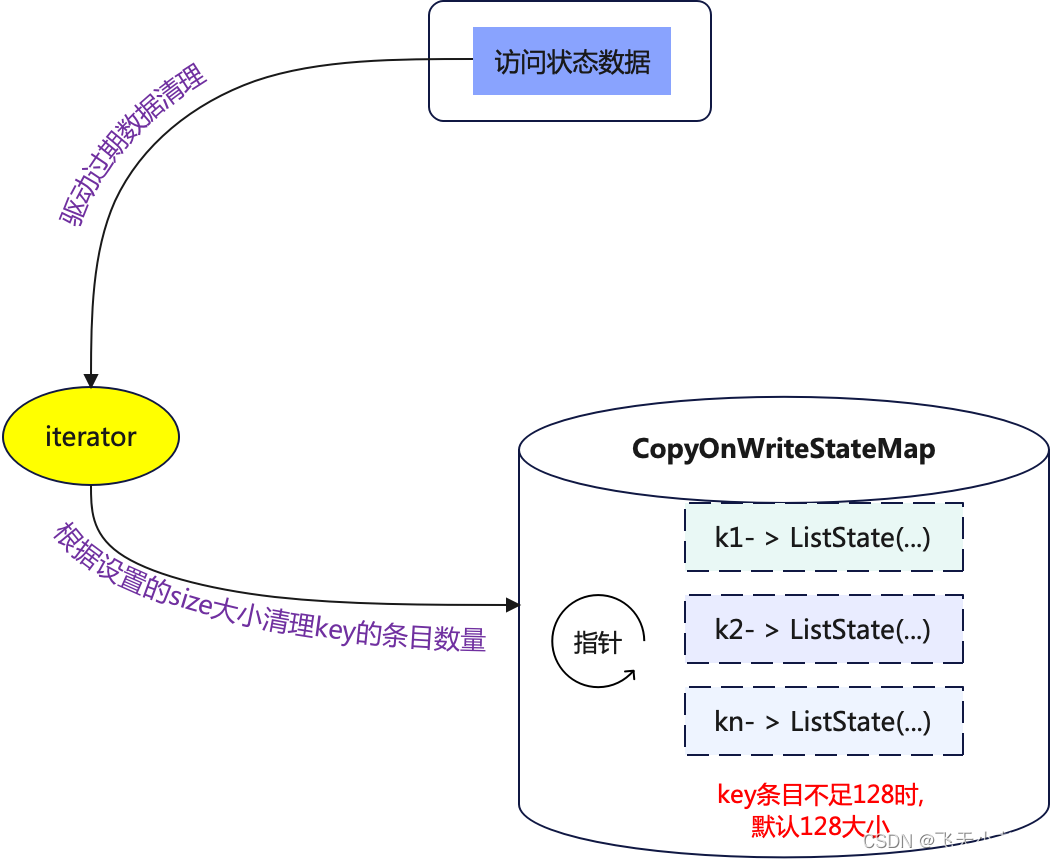
Flink之状态TTL机制内容详解
1 状态TTL机制 状态的 TTL机制就是Flink提供的自动化删除状态中的过期数据,配置 TTL的 API可以做到对状态中的数据进行冷热数据分离,将热数据一直保存在状态存储器中,将冷数据进行定期删除. 1.1 API简介
TTL常用API如下:
API注解setTtl(Time.seconds(…))配置过期时长,当状态…
Flink-时间窗口
在流数据处理应用中,一个很重要、也很常见的操作就是窗口计算。所谓的“窗口”,一 般就是划定的一段时间范围,也就是“时间窗”;对在这范围内的数据进行处理,就是所谓的 窗口计算。所以窗口和时间往往是分不开的。
时…

flink的AggregateFunction,merge方法作用范围
背景
AggregateFunction接口是我们经常用的窗口聚合函数,其中有一个merge方法,我们一般情况下也是实现了的,但是你知道吗,其实这个方法只有在你使用会话窗口需要进行窗口合并的时候才需要实现
AggregateFunction.merge方法调用时…
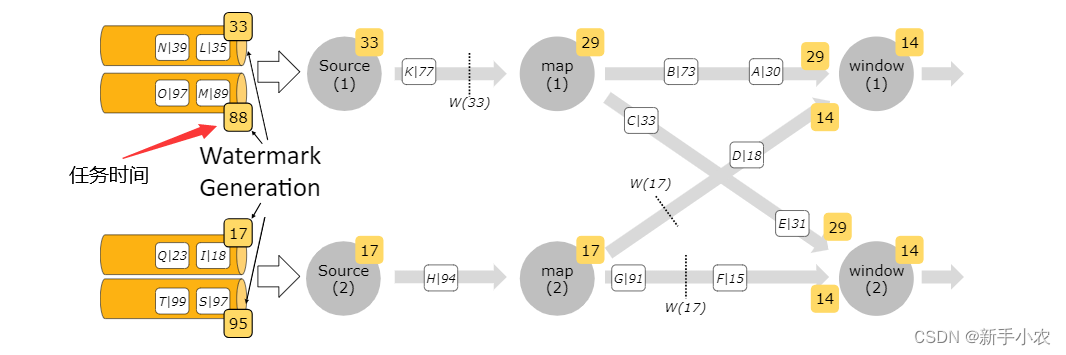
Flink -- 事件时间 Watermark
1、事件时间: 指的是数据产生的时间或是说是数据发生的时间。
在Flink中有三种时间分别是: Event Time:事件时间,数据产生的时间,可以反应数据真实发生的时间 Infestion Time:事件接收时间 Processing Tim…

Flink之状态管理
Flink状态管理 状态概述状态分类 键控、按键分区状态概述值状态 ValueState列表状态 ListStateMap状态 MapState归约状态 ReducingState聚合状态 Aggregating State 算子状态概述列表状态 ListState联合列表状态 UnionListState广播状态 Broadcast State 状态有效期 (TTL)概述S…
Flink -- window(窗口)
1、窗口主要分成三大种: 1、Time Window (时间窗口):固定时间触发一次窗口 a、SlidingEventTimeWindows: 滑动的事件时间窗口
public class Demo1TImeWindow {public static void main(String[] args) throws Exception {/*** 时…
Flink源码解析零之重要名词的理解
名词解释
1)StreamGraph
根据用户通过 Stream API 编写的代码生成的最初的图。
(1)StreamNode
用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
(2)StreamEdge
表示连接两个StreamNode的边。
2)JobGraph
StreamGraph经过优化后生成了 J…
flink源码分析之功能组件(四)-slot管理组件I
简介 本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metrics&…
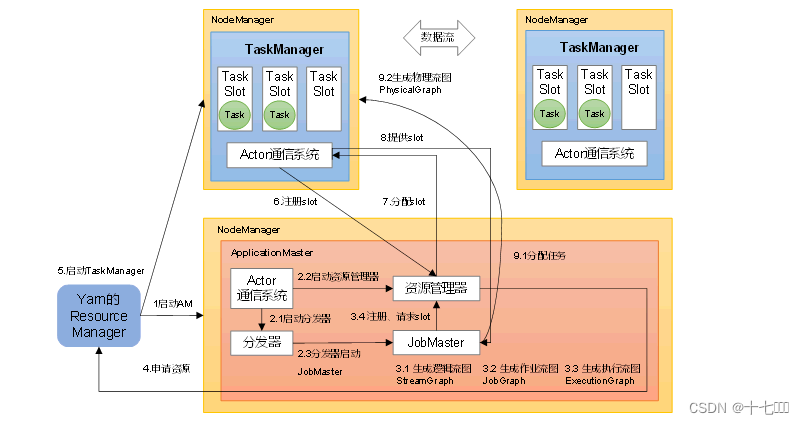
Flink入门之核心概念(三)
任务槽 TaskSlots: 任务槽,是TaskManager提供的用于执行Task的资源(CPU 内存) TaskManager提供的TaskSlots的个数:主要由Taskmanager所在机器的CPU核心数来决定,不能超过CPU的最大核心数 1.可以在flink/conf/flink-c…
Flinksql bug :Illegal mixing of types in CASE or COALESCE statement
报错信息
org.apache.flink.table.api.ValidationException: SQL validation failed. From line 66, column 23 to line 68, column 46: Illegal mixing of types in CASE or COALESCE statement org.apache.calcite.runtime.CalciteContextException: From line 66, column 2…
Flink基础之DataStream API
流的合并
union联合:被unioin的流中的数据类型必须一致connect连接:合并的两条流的数据类型可以不一致 connec后,得到的是ConnectedStreams合并后需要根据数据流是否经过keyby分区 coConnect: 将两条数据流合并为同一数据类型keyedConnect …
Flink优化——资源优化(一)
目录
资源配置优化
内存设置 (1CPU 配置 4G 内存)
并行度设置
最优并行度计算
Source 端并行度的配置
Transform 端并行度的配置
Keyby 之前的算子
Keyby 之后的算子 (KeyGroup 最小值为128)
Sink 端并行度的配置
Rocks…
【Flink系列二】如何计算Job并行度及slots数量
接上文的问题
并行的任务,需要占用多少slot ?一个流处理程序,需要包含多少个任务
首先明确一下概念
slot:TM上分配资源的最小单元,它代表的是资源(比如1G内存,而非线程的概念,好多…

合纵连横 – 以 Flink 和 Amazon MSK 构建 Amazon DocumentDB 之间的实时数据同步
在大数据时代,实时数据同步已经有很多地方应用,包括从在线数据库构建实时数据仓库,跨区域数据复制。行业落地场景众多,例如,电商 GMV 数据实时统计,用户行为分析,广告投放效果实时追踪ÿ…
flink state原理,TTL,状态后端,数据倾斜一文全
flink state原理 1. 状态、状态后端、Checkpoint 三者之间的区别及关系?2 算子状态与键控状态的区别2.1 算子状态2.2 键控状态2.3 算子状态api2.4 键控状态api 3 HashMapStateBackend 状态后端4 EmBeddedRocksDbStateBackend 状态后端5 状态数据结构介绍5.1 算子状态…
【Flink集群RPC通讯机制(四)】集群组件(tm、jm与rm)之间的RPC通信
文章目录 1. 集群内部通讯方法概述2. TaskManager向ResourceManager注册RPC服务3. JobMaster向ResourceManager申请Slot计算资源 现在我们已经知道Flink中RPC通信框架的底层设计与实现,接下来通过具体的实例了解集群运行时中组件如何基于RPC通信框架构建相互之间的调…
Flink SQL Client 安装各类 Connector、组件的方法汇总(持续更新中....)
一般来说,在 Flink SQL Client 中使用各种 Connector 只需要该 Connector 及其依赖 Jar 包部署到 ${FLINK_HOME}/lib 下即可。但是对于某些特定的平台,如果 AWS EMR、Cloudera CDP 等产品会有所不同,主要是它们中的某些 Jar 包可能被改写过&a…

Flink CEP(基本概念)
Flink CEP 在Flink的学习过程中,我们已经掌握了从基本原理和核心层的DataStream API到底层的处理函数,再到应用层的Table API和SQL的各种手段,可以应对实际应用开发的各种需求。然而,在实际应用中,还有一类更为复…
Flink 集成和使用 Hive Metastore
1. AWS EMR 的 Flink 使用 Hive Metastore 想在 Flink 中使用 Hive Metastore 其实只需要将 Flink Hive Connector 以及 Hive Metastore 有关的 Jar 包部署到 ${FLINK_HOME}/lib 下即可,稍后我们会介绍一下具体做法。但是,如果是 AWS EMR,会有…
flink sql 实战实例 及延伸问题:聚合/数据倾斜/DAU/Hive流批一体 等
flink sql 实战实例 及延伸问题 Flink SQL 计算用户分布Flink SQL 计算 DAU多topic 数据更新mysql topic接入mysql引入 upsert-kafka-connector 以1.14.4版本为例 数据倾斜问题:让你使用用户心跳日志(20s 上报一次)计算同时在线用户、DAU 指标…
flink-cdc使用小结
原理:
同步原理:其实就是伪装成一个mysql 的从库会拉取主库的binlog日志读取数据,相当于mysql 的主从复制。然而flink的数据处理方式是流处理,实时收集清洗数据。相关联的checkpoint,其实就是一个容错恢复快照&#x…
Flink CDC 3.0 表结构变更时导致webUI接口无反应原因
Flink CDC 3.0 表结构变更时导致webUI接口无反应!
原因:因为deliverCoordinationRequestToCoordinator和requestJob都是SchedulerNG中方法,该类的线程模型是单线程执行,所以在deliverCoordinationRequestToCoordinator执行表结构…
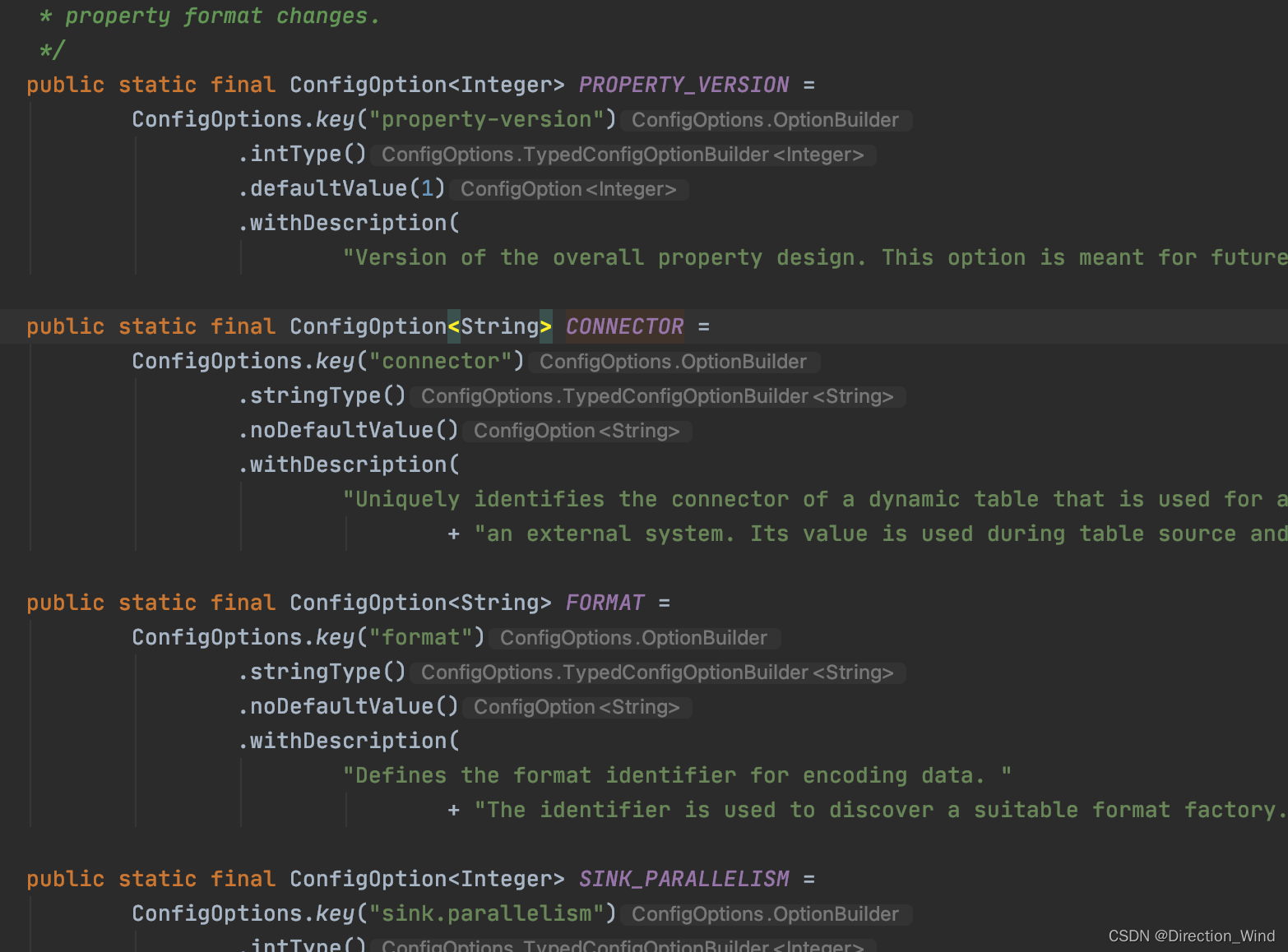
深入理解flinksql执行流程,calcite与catalog相关概念,扩展解析器实现语法的扩展
深入理解Flink Sql执行流程 1 Flink SQL 解析引擎1.1SQL解析器1.2Calcite处理流程1.2.1 SQL 解析阶段(SQL–>SqlNode)1.2.2 SqlNode 验证(SqlNode–>SqlNode)1.2.3 语义分析(SqlNode–>RelNode/RexNode&#…
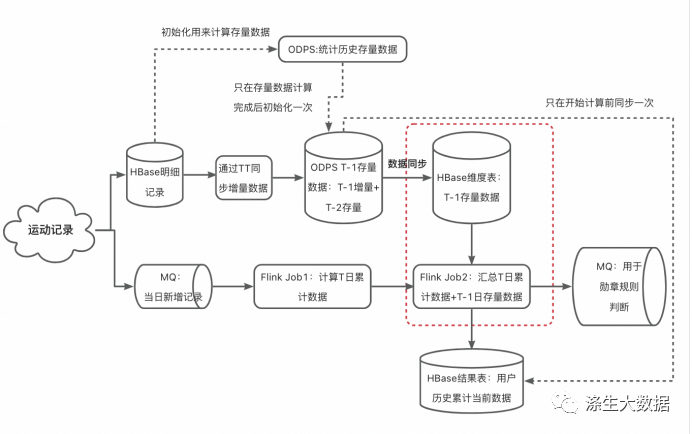
涤生大数据实战:基于Flink+ODPS历史累计计算项目分析与优化(上)
涤生大数据实战:基于FlinkODPS历史累计计算项目分析与优化(一)
1.前置知识
ODPS(Open Data Platform and Service)是阿里云自研的一体化大数据计算平台和数据仓库产品,在集团内部离线作为离线数据处理和存…
Flink从入门到实践(三):数据实时采集 - Flink MySQL CDC
文章目录 系列文章索引一、概述1、版本匹配2、导包 二、编码实现1、基本使用2、更多配置3、自定义序列化器4、Flink SQL方式 三、踩坑1、The MySQL server has a timezone offset (0 seconds ahead of UTC) which does not match the configured timezone Asia/Shanghai. 参考资…
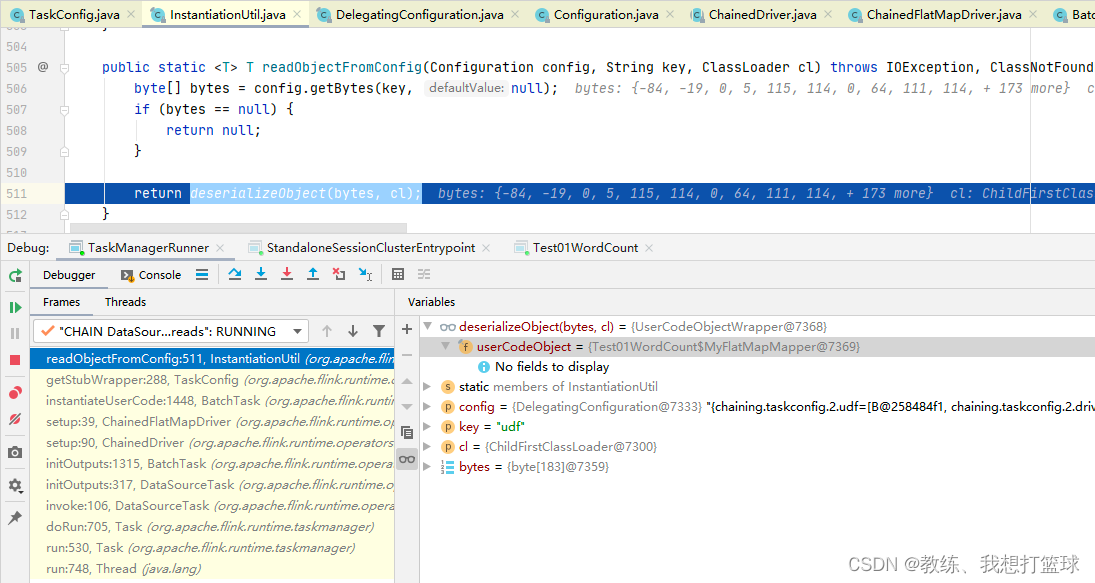
06 flink 的各个角色的交互
前言
这里主要是 涉及到 flink 中各个角色的交互
TaskManager 和 ResourceManager 的交互
JobMaster 和 ResourceManager 的交互
等等流程 TaskManager 和 ResourceManager 的交互
主要是 包含了几个部分, 如下, 几个菜单
TaskManager向 ResourceManager 注册
Resou…
【Flink状态管理(六)】Checkpoint的触发方式(1)通过CheckpointCoordinator触发算子的Checkpoint操作
文章目录 一. 启动CheckpointCoordinator二. 开启CheckpointScheduler线程三. 触发Checkpoint1. Checkpoint执行前的工作2. 创建PendingCheckpoint3. Checkpoint的触发与执行 四. Task节点的Checkpoint操作1. 触发准备2. 调用TaskExecutor执行Checkpoint操作 五. 在StreamTask中…
flink: 通过Sink将数据写入MySQL
一、依赖添加 <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.30</version></dependency><dependency><groupId>org.apache.flink</groupId><artifac…
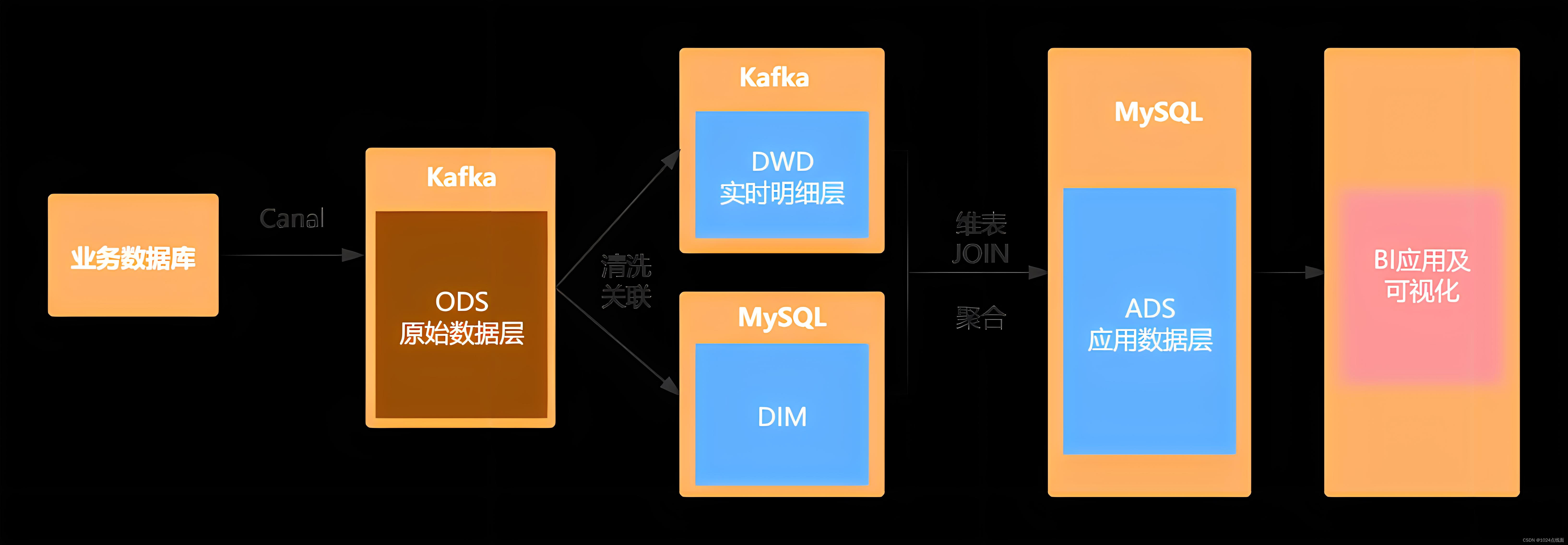
大数据组件之Flink:实时流处理的王者
导言
在大数据的世界里,实时流处理已成为许多业务场景中的核心需求。而Apache Flink,作为一款开源的流处理框架,凭借其高效、可靠和灵活的特性,已经在实时计算领域一枝独秀了。 简介
Apache Flink是一个用于无界和有界数据流的开…
PiflowX-TopN组件
TopN组件
组件说明
按列排序的N个最小值或最大值。
有界性
batch streaming
计算引擎
flink
组件分组
common
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子column_listcolumn_list“*”无否查…
外卖平台订餐流程架构的实践
当我们想要在外卖平台上订餐时,背后其实涉及到复杂的技术架构和流程设计。本文将就外卖平台订餐流程的架构进行介绍,并探讨其中涉及的关键技术和流程。
## 第一步:用户端体验
用户通过手机应用或网页访问外卖平台,浏览菜单、选择…
【大数据面试题】014 Flink CDC 用过吗,请简要描述
一步一个脚印,一天一道面试题。 完成比完美更重要,明天更新完!
Flink CDC 的诞生背景
Flink CDC 的全称是 Change Data Capture(变更数据捕获) 每一项技术的诞生都是为了解决某个问题,某个痛点。而 Flink…
Flinkcdc通过catalog同步mysql数据到hologres的ods中
Flinkcdc通过catalog同步mysql数据到hologres的ods中大致分为以下几步: 配置Flink CDC 的MySQL catalog:CREATE CATALOG mysqlsource
WITH (type = mysql,hostname = xxxx,port = xxxx,username = xxxx<
Apache Paimon 使用 MySQL CDC 获取数据
Paimon支持使用(CDC)同步来自不同数据库的更改,此功能需要Flink及其CDC连接器。
准备 CDC Bundled Jar 依赖
flink-sql-connector-mysql-cdc-*.jar同步表
在Flink DataStream中或通过flink run使用MySqlSyncTableAction,可以将…
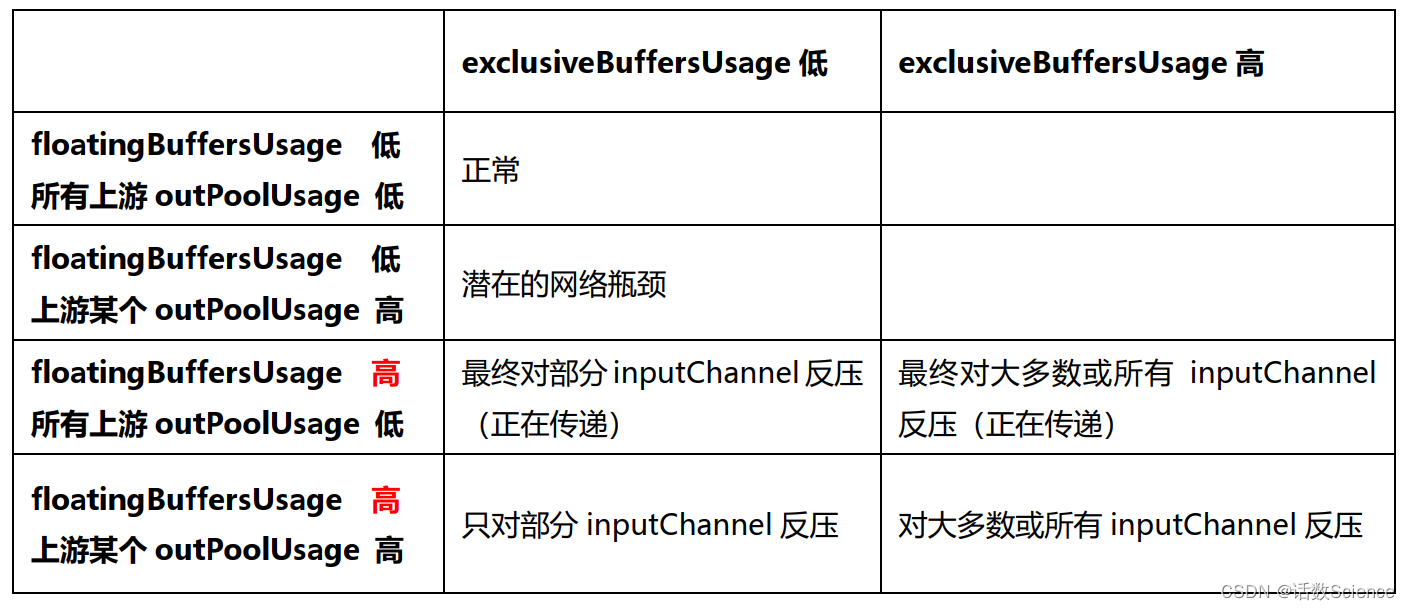
【Flink精讲】Flink反压调优
Flink 网络流控及反压的介绍:
Apache Flink学习网
反压的理解 简单来说, Flink 拓扑中每个节点(Task)间的数据都以阻塞队列的方式传输,下游来不及消费导致队列被占满后,上游的生产也会被阻塞,…
【实战-08】 flink自定义Map中的变量的行为
场景
自定义Map或者别的算子的时候,有时候需要定义一些类变量,在flink内部高并发的情况下需要正确理解这些变量的行为
代码
package com.pg.function;import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common…

Flink Sql 自定义实现 kudu connector
Flink Sql 自定义实现 kudu connector 原理实现 众所周知啊,flinksql 中与其他的存储做数据的传输连接的时候,是需要有独特的连接器的,mysql redis es hbase kudu ,不同的存储他们自己使用的协议与操作都不一样,所以需…
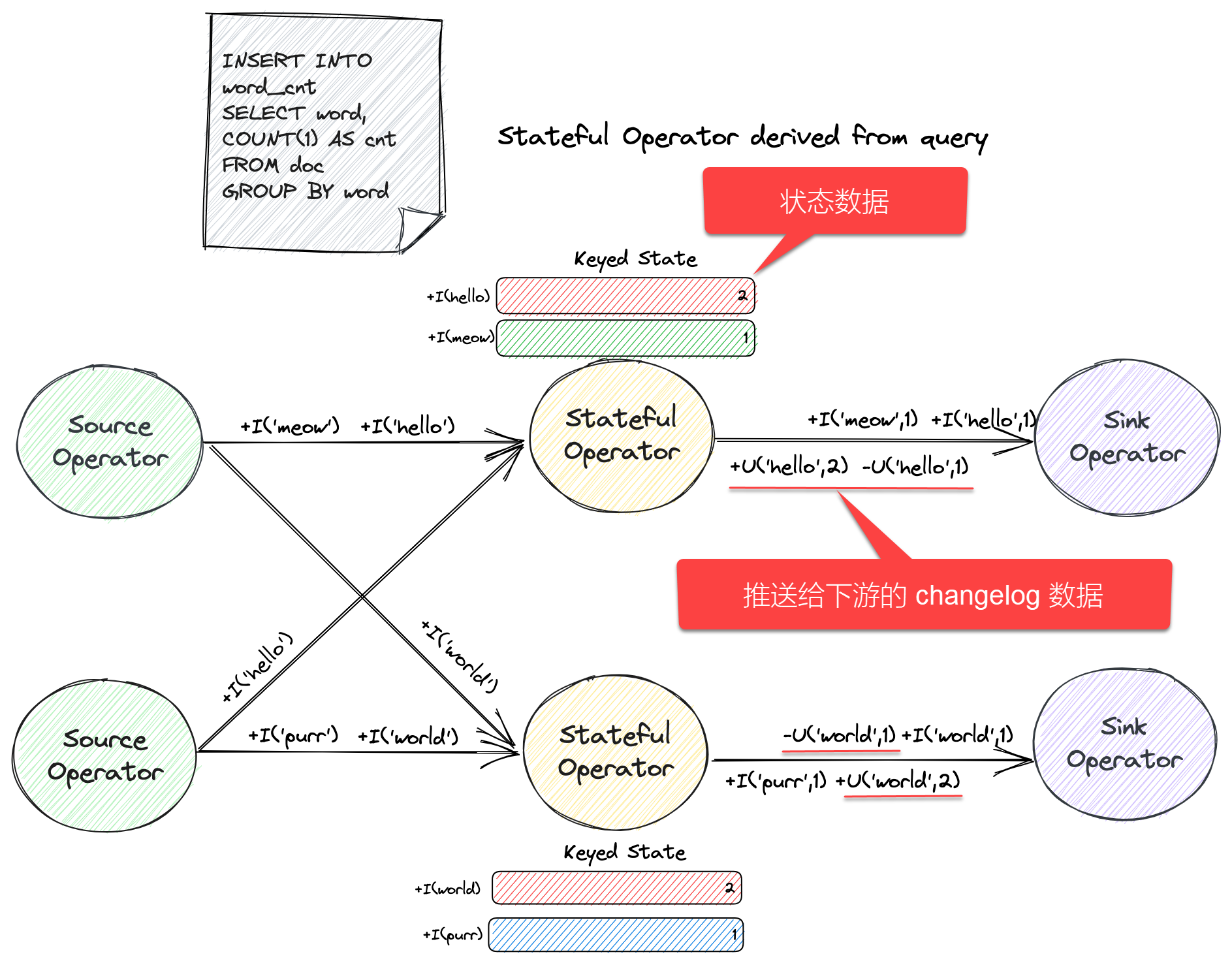
Flink SQL 中的流式概念:状态算子
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
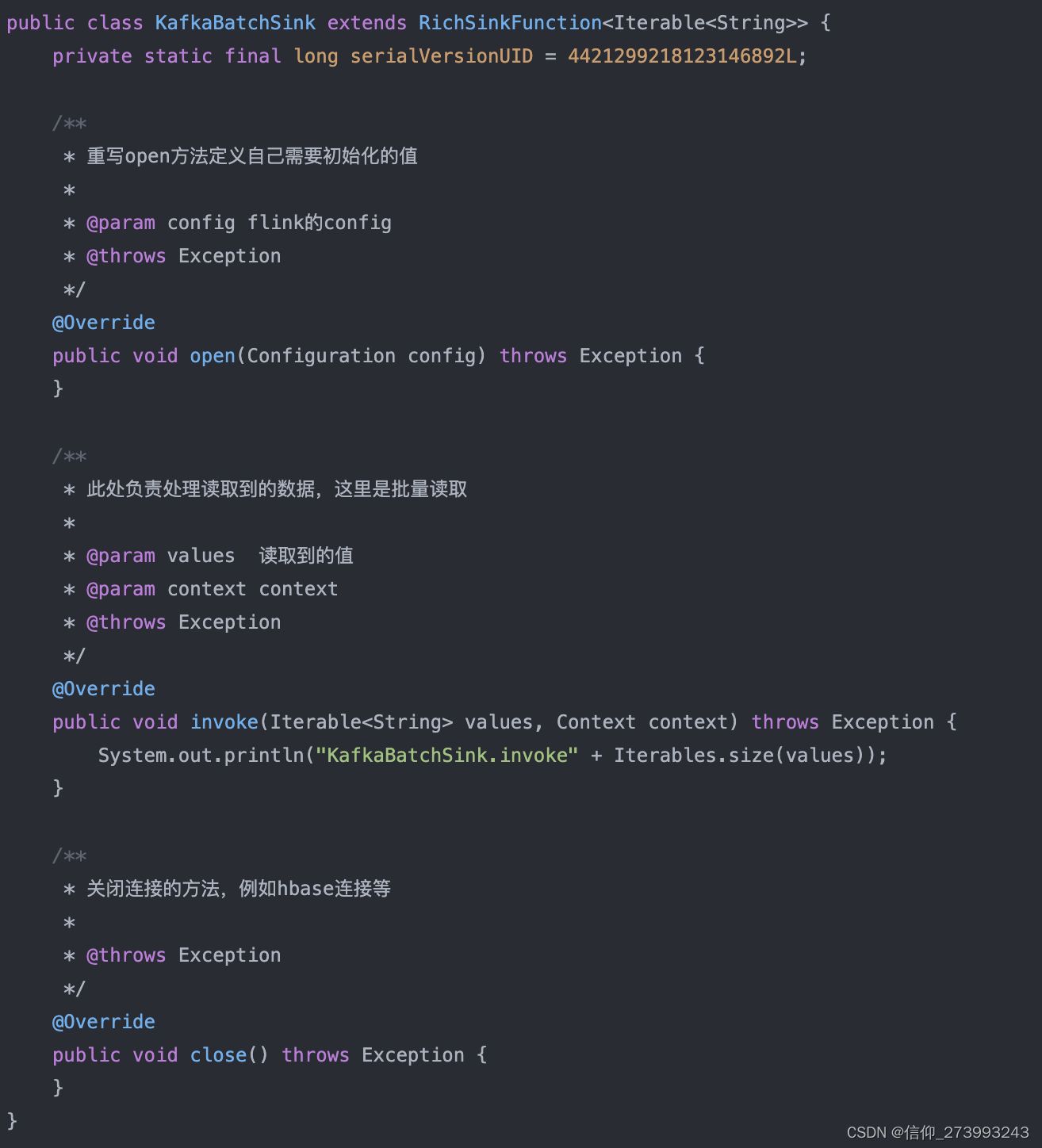
Flink+Kafka消费
引入jar
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.8.0</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactI…
大数据学习之Flink、Flink容错机制的注意事项
第一章、Flink的容错机制
第二章、Flink核心组件和工作原理
第三章、Flink的恢复策略
第四章、Flink容错机制的注意事项
第五章、Flink的容错机制与其他框架的容错机制相比较 目录
第四章、Flink容错机制的注意事项
Ⅰ、注意事项
1. Checkpoint的稳定性:
2.…
Flink系列之:SQL提示
Flink系列之:SQL提示 一、动态表选项二、语法三、例子四、查询提示五、句法六、加入提示七、播送八、随机散列九、随机合并十、嵌套循环十一、LOOKUP十二、进一步说明十三、故障排除十四、连接提示中的冲突案例十五、什么是查询块 SQL 提示可以与 SQL 语句一起使用来…
Flink cdc3.0同步实例(动态变更表结构、分库分表同步)
文章目录 前言准备flink环境docker构建mysql、doris环境数据准备 通过 FlinkCDC cli 提交任务整库同步同步变更路由变更路由表结构不一致无法同步 结尾 前言
最近Flink CDC 3.0发布, 不仅提供基础的数据同步能力。schema 变更自动同步、整库同步、分库分表等增强功…
flink sql1.18.0连接SASL_PLAINTEXT认证的kafka3.3.1
阅读此文默认读者对docker、docker-compose有一定了解。
环境
docker-compose运行了一个jobmanager、一个taskmanager和一个sql-client。
如下:
version: "2.2"
services:jobmanager:image: flink:1.18.0-scala_2.12container_name: jobmanagerports:…
【FLink消费Kafka之FlinkConsumer到KafkaSource的转变】
前言
上篇介绍了flink的入门程序wordcount,在项目开发过程中,最常接触的还是跟各种源头系统打交道,其中消费接收kafka中的数据是最常见的情况,而flink在1.15版本后连接kafka的依赖包发生了变化,之前的flink版本使用的…
Flink 客户端操作命令及可视化工具
Flink提供了丰富的客户端操作来提交任务和与任务进行交互。下面主要从Flink命令行、Scala Shell、SQL Client、Restful API和 Web五个方面进行整理。
在Flink安装目录的bin目录下可以看到flink,start-scala-shell.sh和sql-client.sh等文件,这些都是客户…
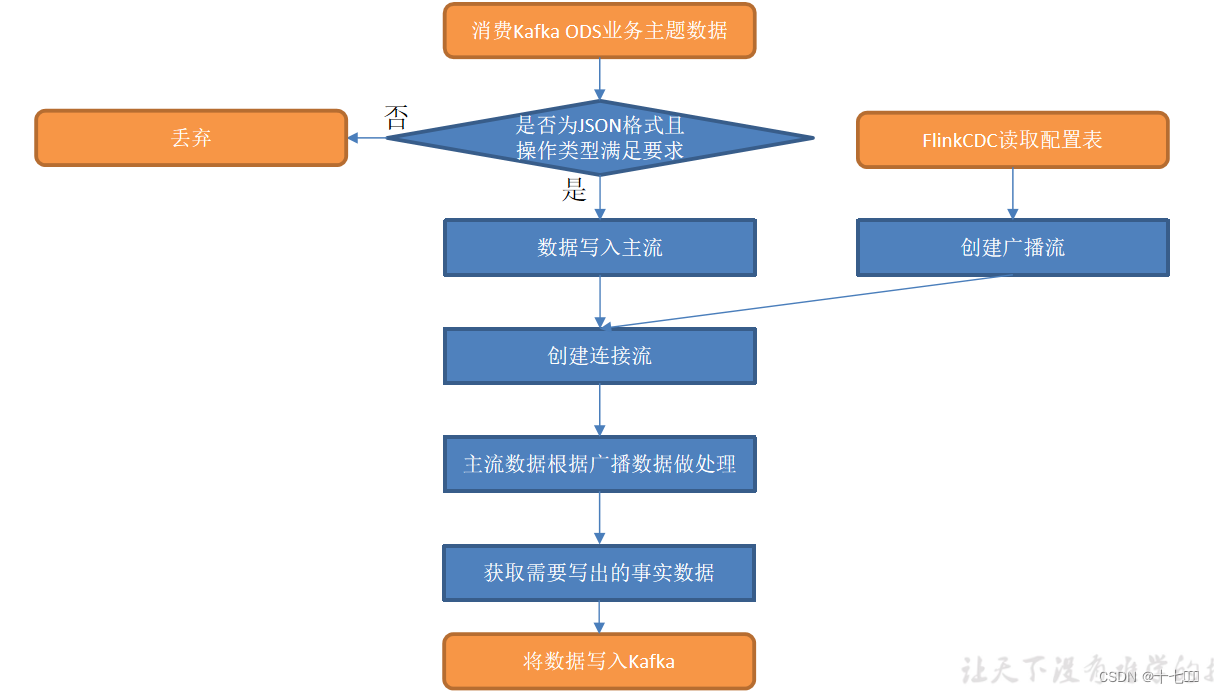
Flink电商实时数仓(六)
交易域支付成功事务事实表
从topic_db业务数据中筛选支付成功的数据从dwd_trade_order_detail主题中读取订单事实数据、LookUp字典表关联三张表形成支付成功宽表写入 Kafka 支付成功主题
执行步骤
设置ttl,通过Interval join实现左右流的状态管理获取下单明细数据…
【Flink-Kafka-To-Mysql】使用 Flink 实现 Kafka 数据写入 Mysql(根据对应操作类型进行增、删、改操作)
【Flink-Kafka-To-Mysql】使用 Flink 实现 Kafka 数据写入 Mysql(根据对应操作类型进行增、删、改操作) 1)导入依赖2)resources2.1.appconfig.yml2.2.application.properties2.3.log4j.properties2.4.log4j2.xml 3)uti…

Flink实时电商数仓之Doris框架(七)
Doris框架
大规模并行处理的分析型数据库产品。使用场景:一般先将原始数据经过清洗过滤转换后,再导入doris中使用。主要实现的功能有:
实时看板 面向企业内部分析师和管理者的报表面向用户或者客户的高并发报表分析 即席查询统一数仓构建&a…
Flink-1.17集群部署
1、部署
1.1、修改flink-conf.yaml
1.1.1、flink-17
jobmanager.rpc.address: boshi-122
jobmanager.rpc.port: 6123
# 设置jobmanager总内存
jobmanager.memory.process.size: 2048m
# 设置taskmanager的运行总内存
taskmanager.memory.process.size: 4096mb
# 设置用户代码…

Next Station of Flink CDC
摘要:本文整理自阿里云智能 Flink SQL、Flink CDC 负责人伍翀(花名:云邪),在 Flink Forward Asia 2023 主会场的分享。Flink CDC 是一款基于 Flink 打造一系列数据库的连接器。本次分享主要介绍 Flink CDC 开源社区在过…
相比于其他流处理技术,Flink的优点在哪?
Apache Flink 是一个开源的流处理框架,用于在高吞吐量和低延迟的情况下进行大规模数据流的处理。Flink 以其在流处理领域的性能而闻名,相比于其他流处理技术,Flink 提供了一些独特的特性和优化,使其在某些情况下更快。以下是 Flin…

Flink1.17实战教程(第二篇:DataStream API)
系列文章目录
Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…
flink中值得监控的几个指标
背景
为了维持flink的正常运行,对flink的日常监控就变得很重要,本文我们就来看一下flink中要监控的几个重要的指标
重要的监控指标
1.算子的处理速度的指标:numRecordsInPerSecond/numRecordsOutPerSecond,这有助于你了解到算子的是否正在…
flink的三个state backend的选择
flink的三个状态
MemoryStateBackend 默认,小状态,本地调试使用FsStateBackend 大状态,长窗口,高可用场景RocksDBStateBackend 超大状态,长窗口,高可用场景,可增量checkpoint
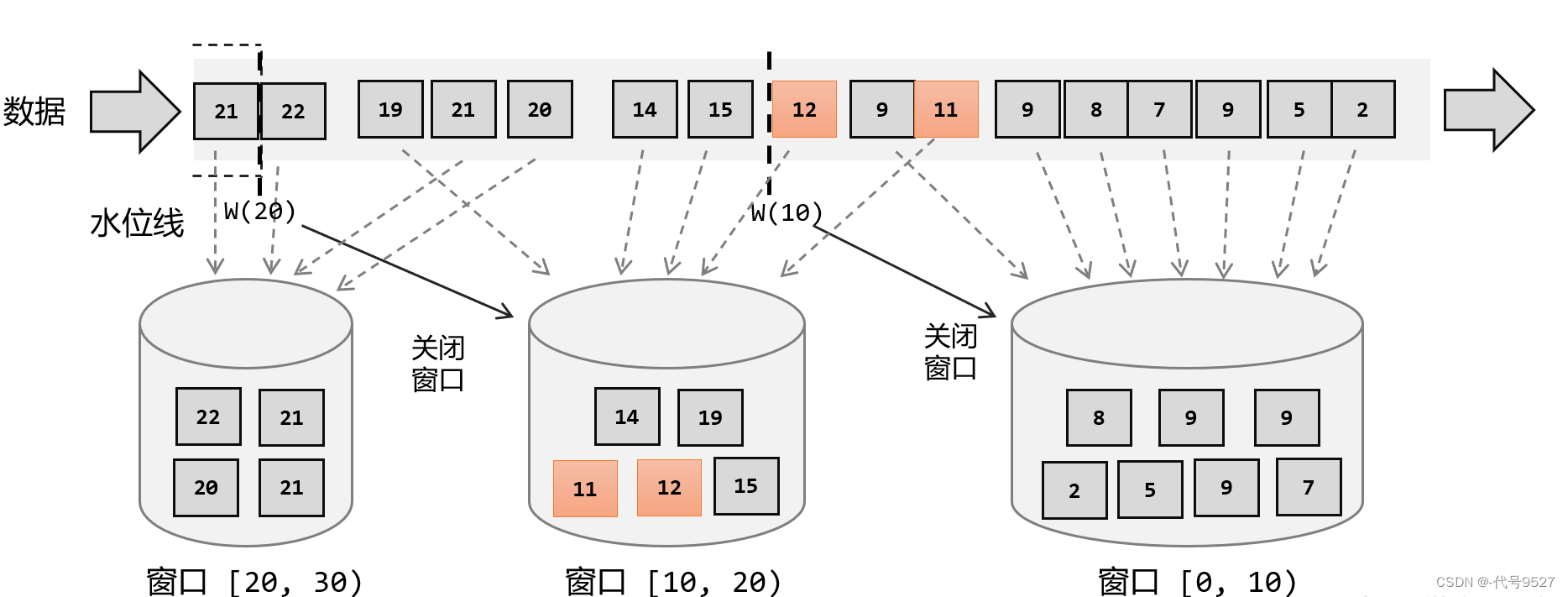
【API篇】九、Flink的水位线
文章目录 1、Flink时间语义2、事件时间和窗口3、水位线4、水位线和窗口的工作原理 1、Flink时间语义
事件时间处理时间
举个例子就是,一条数据在23:59:59产生,在00:00:01被处理,前者为事件时间,后者为处理时间。 从Flink1.12版本…

flink generic log-based incremental checkpoints 设计
背景
flink 在1.15版本后开始提供generic log-based incremental checkpoints的检查点方案,目的在于减少checkpoint的耗时,尽量缩短端到端的数据处理延迟,本文就来看下这种新类型的checkpoint的设计
generic log-based incremental checkpo…
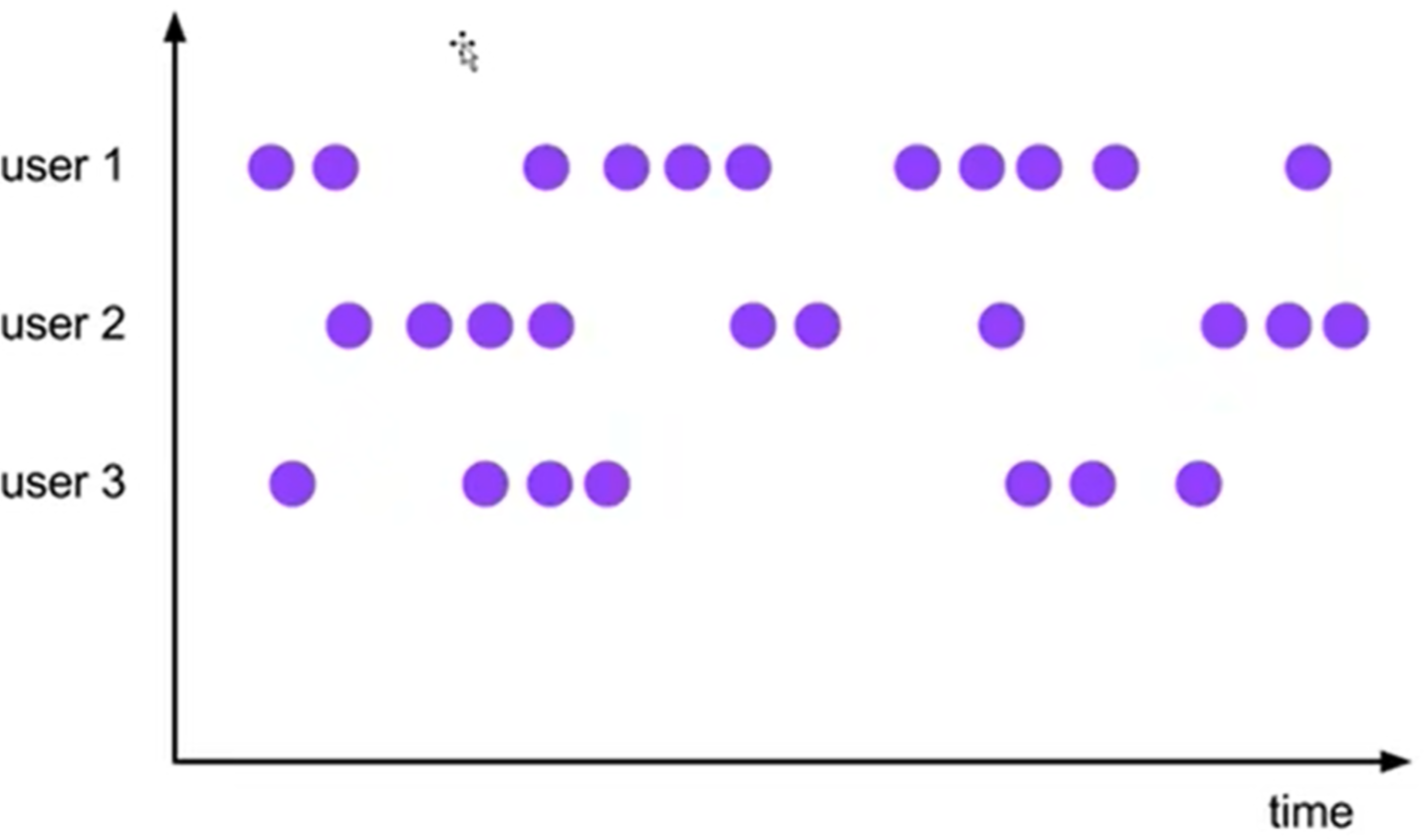
Flink学习-时间和窗口
在流数据处理应用中,一个很重要、也很常见的操作就是窗口计算。所谓的“窗口”,一 般就是划定的一段时间范围,也就是“时间窗”;对在这范围内的数据进行处理,就是所谓的 窗口计算。所以窗口和时间往往是分不开的。
时…
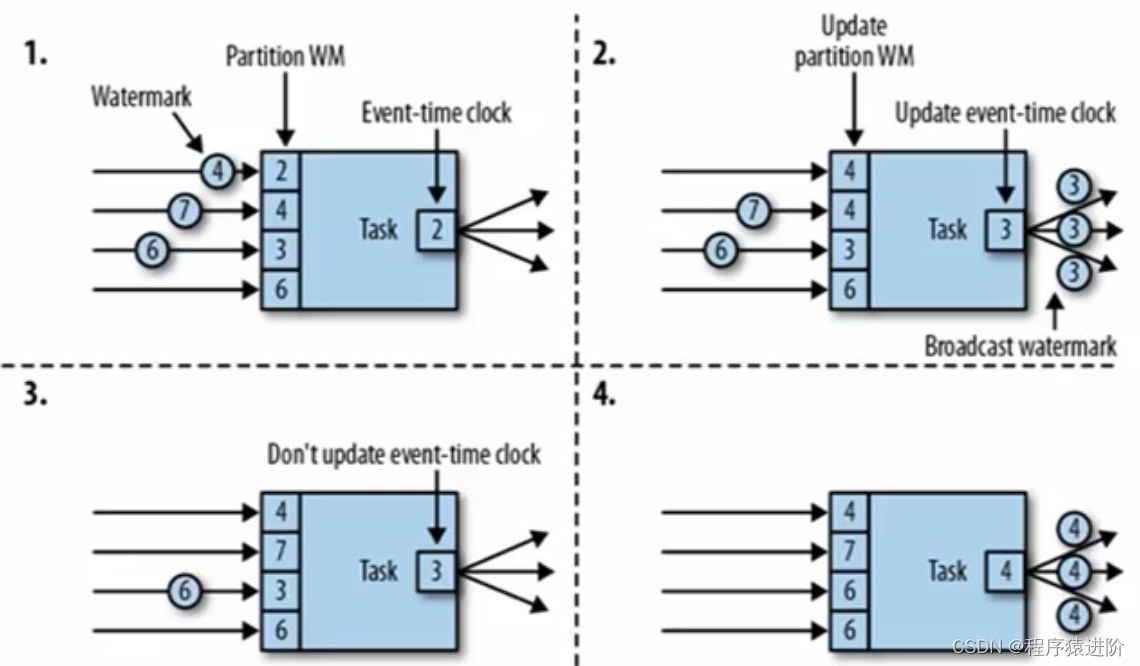
Flink Watermark和时间语义
Flink 中的时间语义 时间语义: EventTime:事件创建时间;Ingestion Time:数据进入Flink的时间;Processing Time:执行操作算子的本地系统时间,与机器无关。不同的时间语义有不同的应用场合&#x…
Flink 任务指标监控
目录
状态监控指标
JobManager 指标
TaskManager 指标
Job 指标
资源监控指标
数据流监控指标
任务监控指标
网络监控指标
容错监控指标
数据源监控指标
数据存储监控指标
JobManager 指标
TaskManager 指标
Job 指标 当使用 Apache Flink 进行流处理任务时&…
flink消费kafka限制消费速率
flink版本1.14 别的版本类似
需要速率限制的情况
1.任务异常在停止的时间内大量数据挤压
2.新任务上线需要铺底数据,消费几天前的数据
在不增加内存和并行度的情况下,如果任务启动可能会造成oom,这时需要进行速率限制。
前提
漏桶算法(Leaky Bucket Algorithm): 原…
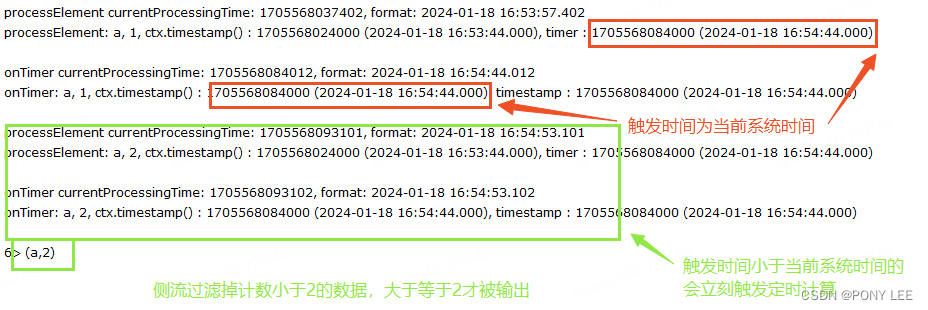
Flink的KeyedProcessFunction基于Event Time和Process Time的定时器用法实例分析
FLink处理函数简介
在Flink底层,我们可以不定义任何具体的算子(比如 map,filter,或者 window),而只是提炼出一个统一的【处理】(process)操作——它是所有转换算子的一个概括性的表…
Flink旁路输出OutputTag
文章目录 前言代码示例1.流复制2.条件分流3.迟到数据分流 前言
除了由 DataStream 操作产生的主要流之外,还可以产生任意数量的旁路输出结果流。结果流中的数据类型不必与主要流中的数据类型相匹配,并且不同旁路输出的类型也可以不同。当你需要拆分数据…
flinkcdc 原理 + 实践
使用环境 Flink 1.14.2 flink cdc 2.2.0 提示:flinkcdc 2.2版本之后才支持flink 1.14.*, flinkcdc 2.2版本之前不支持 mysql低版本5.6的 cdc. CDC1.*版本痛点 单并发。 为了保证一致性,一般通过全量 增量进行获取数据。 在全量阶段会进行加锁操…

Flink动态分区裁剪
1 原理
1.1 静态分区裁剪与动态分区裁剪 静态分区裁剪的原理跟谓词下推是一致的,只是适用的是分区表,通过将where条件中的分区条件下推到数据源达到减少分区扫描的目的 动态分区裁剪应用于Join场景,这种场景下,分区条件在joi…

Flink1.15 DataSream 连接器 —— FileSystem源码阅读及代码示例
接上篇《Flink1.15 DataSream 连接器 —— FileSystem》 文章目录代码全景UML 图File Source去除掉Deprecated被弃用类去掉工具类、参数配置类等File Sink去除掉Deprecated被弃用类去掉工具类、参数配置类等File Table代码示例结语代码全景 从上图中可以看到src和sink …
【Flink精讲】Flink单机安装步骤
Flink单机安装步骤
获取Flink安装包:Index of /flink
解压缩:tar -zxvf flink-1.17.2-bin-scala_2.12.tgz
修改配置文件:conf/flink-conf.yaml
启动命令:./bin/start-cluster.sh
终止命令:./bin/stop-cluster.s…
【大数据】Flink SQL 语法篇(十):EXPLAIN、USE、LOAD、SET、SQL Hints
《Flink SQL 语法篇》系列,共包含以下 10 篇文章:
Flink SQL 语法篇(一):CREATEFlink SQL 语法篇(二):WITH、SELECT & WHERE、SELECT DISTINCTFlink SQL 语法篇(三&…

Apache Flink连载(三十五):Flink基于Kubernetes部署(5)-Kubernetes 集群搭建-1
🏡 个人主页:IT贫道-CSDN博客 🚩 私聊博主:私聊博主加WX好友,获取更多资料哦~ 🔔 博主个人B栈地址:豹哥教你学编程的个人空间-豹哥教你学编程个人主页-哔哩哔哩视频 目录
编辑
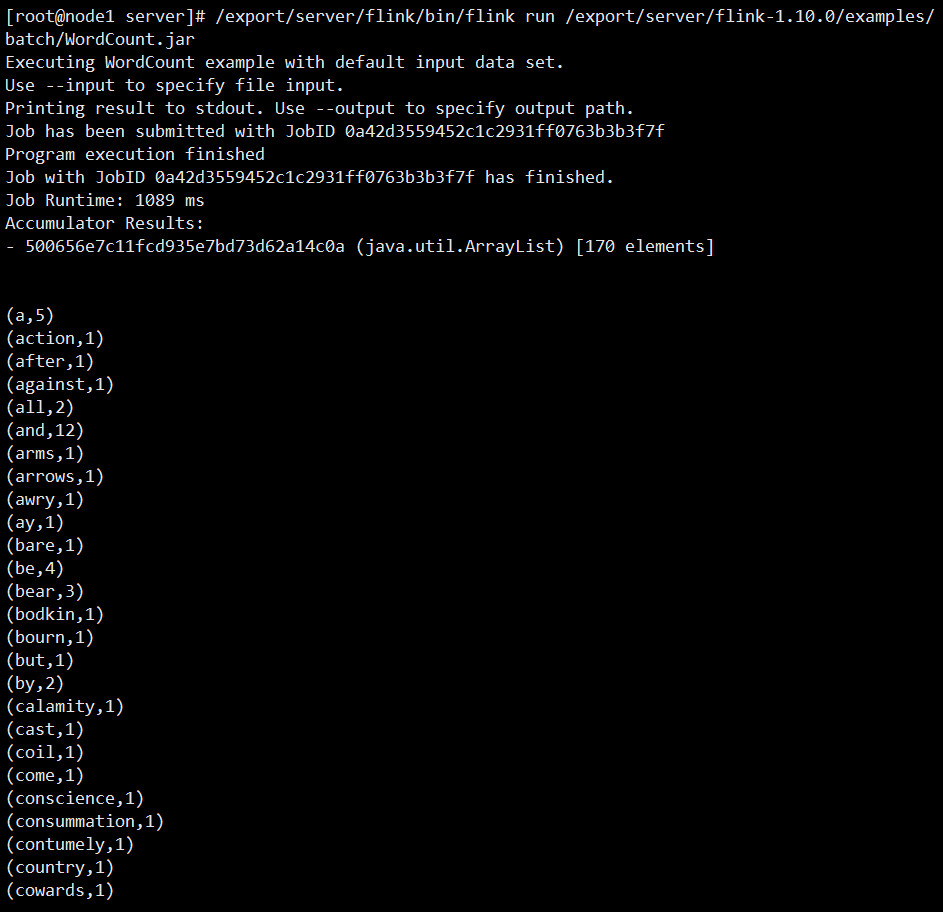
17-Linux部署Flink环境
Linux部署Flink环境
注意
本小节的操作,基于:大数据集群(Hadoop生态)安装部署环节中所构建的Hadoop集群
如果没有Hadoop集群,请参阅前置内容,部署好环境。 参考文章 14-Linux部署Hadoop集群:…
Flink实时数仓同步:切片表实战详解
一、背景
在大数据领域,初始阶段业务数据通常被存储于关系型数据库,如MySQL。然而,为满足日常分析和报表等需求,大数据平台采用多种同步方式,以适应这些业务数据的不同存储需求。
一项常见需求是,业务使用…
flink实战--Flink任务资源自动化优化
背景 在生产环境Flink任务资源是用户在实时平台端进行配置,用户本身对于实时任务具体配置多少资源经验较少,所以存在用户资源配置较多,但实际使用不到的情形。比如一个 Flink 任务实际上 4 个并发能够满足业务处理需求,结果用户配置了 16 个并发,这种情况会导致实时计算资…
如何构建基于Flink+Hologres的实时数仓
构建基于Flink和Hologres的实时数仓可以通过以下几个步骤来实现: 了解核心组件:需要对Flink和Hologres的核心能力有所了解。Flink是一个强大的流式计算引擎,支持对海量实时数据的高效处理。而Hologres是一站式实时数据仓库引擎,支持海量数据实时写入、更新和分析,兼容Post…
[2024年]-flink面试真题(二)
[2024年]-flink面试真题(一)
[2024年]-flink面试真题(三)
1(北京)什么是flink的两阶段提交?
2 (北京)flink on yarn的模式有哪几种 , 有什么特点?
3 (北京)谈谈工作中使用了哪几种窗口计算 .
4&…
flink重温笔记(十四): flink 高级特性和新特性(3)——数据类型及 Avro 序列化
Flink学习笔记 前言:今天是学习 flink 的第 14 天啦!学习了 flink 高级特性和新特性之数据类型及 avro 序列化,主要是解决大数据领域数据规范化写入和规范化读取的问题,avro 数据结构可以节约存储空间,本文中结合企业真…
[AIGC] Flink中的时间语义:精确处理数据
在处理实时数据流时,一个核心的概念就是时间。Apache Flink提供了强大的时间语义支持,能够处理复杂的时间相关问题。本文介绍Flink中的时间语义以及其在实时数据处理中的重要性。
时间语义简介
在Flink中,有三种基本的时间语义:…
Flink StreamTask启动和执行源码分析
文章目录 前言StreamTask 部署启动Task 线程启动StreamTask 初始化StreamTask 执行 前言
Flink的StreamTask的启动和执行是一个复杂的过程,涉及多个关键步骤。以下是StreamTask启动和执行的主要流程:
初始化:StreamTask的初始化阶段涉及多个…

Flink K8S Operator 离线安装
一 推送镜像
docker pull quay.io/jetstack/cert-manager-cainjector:v1.8.2
docker tag quay.io/jetstack/cert-manager-cainjector:v1.8.2 10.177.85.101:8000/flink/cert-manager-cainjector:v1.8.2
docker push 10.177.85.101:8000/flink/cert-manager-cainjector:v1.8.2d…
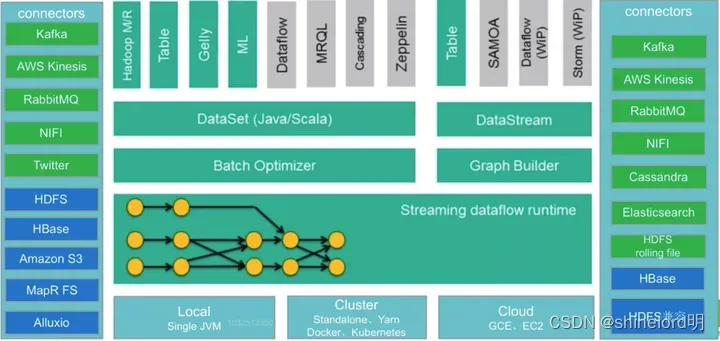
Flink技术简介与入门实践
架构简介 Flink 是一个分布式流处理和批处理计算框架,具有高性能、容错性和灵活性。下面是 Flink 的架构概述: JobManager:JobManager 是 Flink 集群的主节点,负责接收和处理用户提交的作业。JobManager 的主要职责包括࿱…
Flink中遇到的问题
目录
1、提交flink 批处理任务时遇到的问题
2、flink定时任务,mysql连接超时问题
3、yarn 增加并行任务数量配置
4、flink checkpoint 恢复失败
5、flink程序在hadoop集群跑了一段时间莫名挂掉 1、提交flink 批处理任务时遇到的问题
问题描述:
…
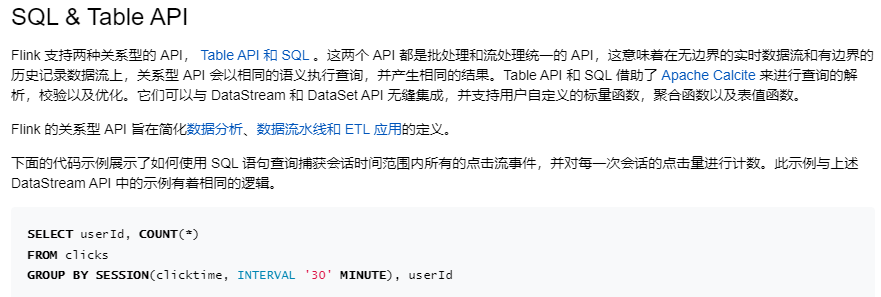
Flink高手之路1一Flink的简介
文章目录一、Flink简介1. Fink的引入2.Flink简介3.支持的编程语言4.Flink的特性5.Flink四大基石6.批处理和流处理二、Flink的架构1.Flink的角色2.编程模型一、Flink简介
1. Fink的引入
大数据的计算引擎,发展过程有四个阶段
第一代:Hadoop的MapReduce…

【Flink SQL】Flink SQL 基础概念(三):SQL 动态表 连续查询
《Flink SQL 基础概念》系列,共包含以下 5 篇文章:
Flink SQL 基础概念(一):SQL & Table 运行环境、基本概念及常用 APIFlink SQL 基础概念(二):数据类型Flink SQL 基础概念&am…
为什么说新一代流处理器Flink是第三代流处理器(论点:发展历史、区别、适用场景)
Flink 被认为是第三代流处理器,这是因为 Flink 在设计时参考了前两代流处理器的经验教训并引入了一些新的技术和思想,从而使得 Flink 具有更高的性能和更广泛的应用场景。下面我带大家了解一下流处理器从第一代到第三代的发展历史。 对于有状态的流处理&…
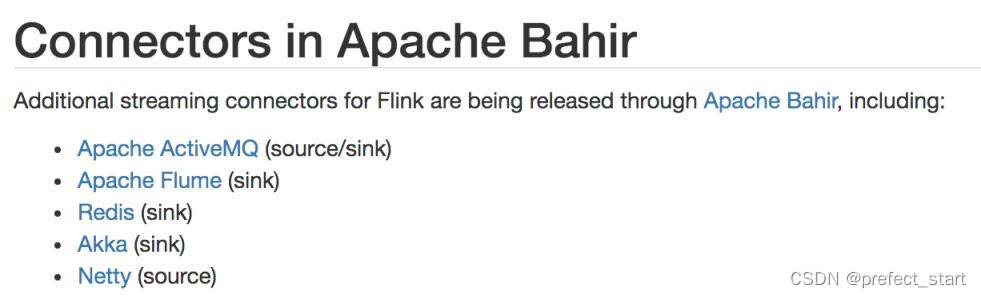
Flink从入门到精通系列(四)
5、DataStream API(基础篇)
Flink 有非常灵活的分层 API 设计,其中的核心层就是 DataStream/DataSet API。由于新版本已经实现了流批一体,DataSet API 将被弃用,官方推荐统一使用 DataStream API 处理流数据和批数据。…

Hudi集成Flink-写入方式
文章目录一、CDC 入湖1.1、[开启binlog](https://blog.csdn.net/wuxintdrh/article/details/130142601)1.2、创建测试表1.2.1、创建mysql表1.2.2、将 binlog 日志 写入 kafka1、使用 mysql-cdc 监听 binlog2、kafka 作为 sink表3、写入sink 表1.2.3、将 kakfa 数据写入hudi1、k…

flink任务处理下线流水数据,数据遗漏不全(三)
flink任务处理下线流水数据,数据遗漏不全(二)
居然还是重量,做一个判断,如果是NaN 就直接获取原始的数据的重量 测试后面会不会出现这个情况! 发现chunjun的代码运行不到5h以后,如果网络不稳…

CDH6.3.2大数据集群生产环境安装(九)之部署flink1.13.2客户端
添加flink用户(可选,这里是因为公司需要这个参数所以才添加;所有节点都添加上,省事) 29.1. 添加 useradd flink部署flink客户端 选择一个集群节点作为客户端部署节点,这里选择zcpt-prd-bigdata-worker-01节点 30.1. 上传资源 flink-1.13.2-bin-scala_2.12.tgz 30.2. 解压…
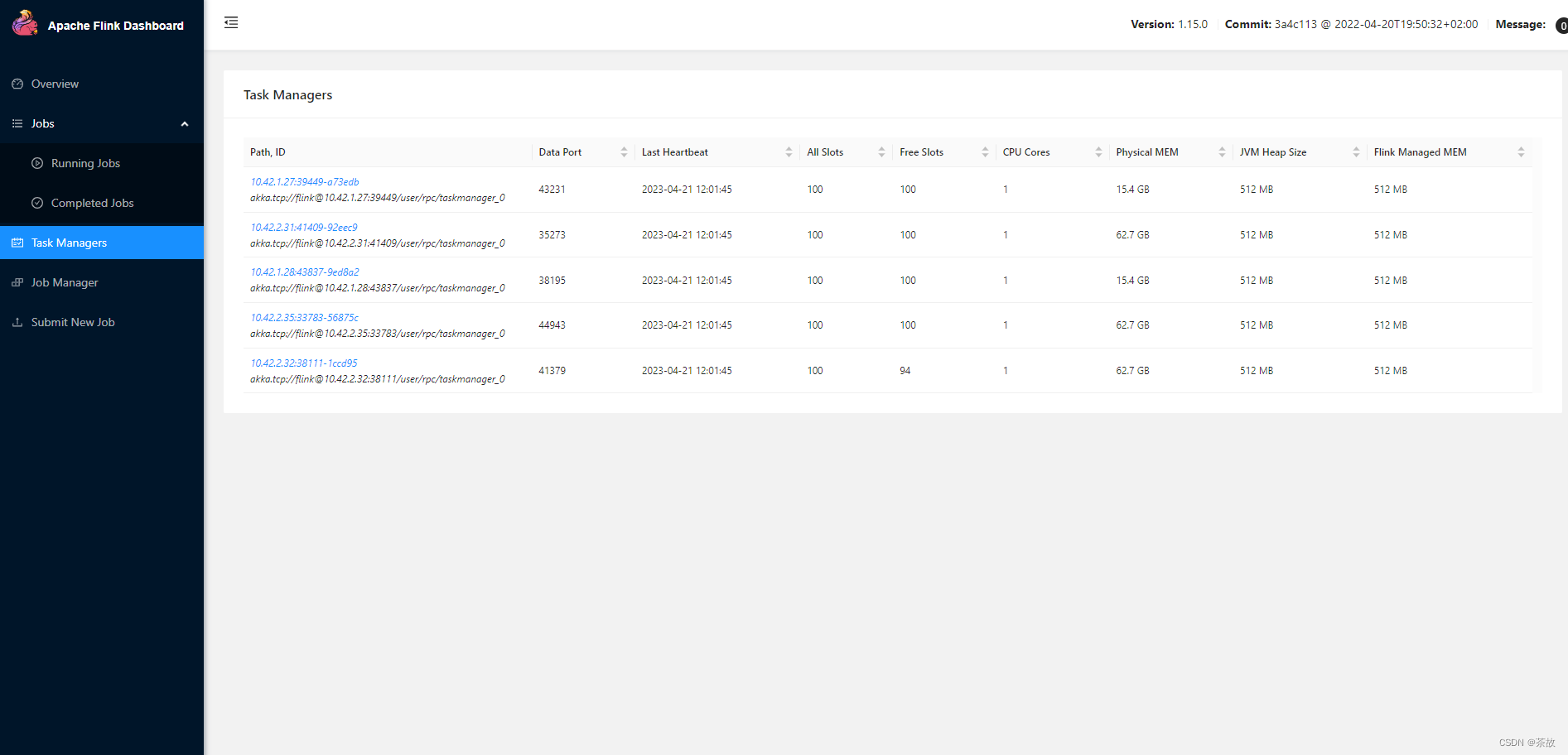
rancher部署flink集群
rancher版本:v2.6.8
k8s版本:v1.22.13rke2r1
flink集群版本:1.15.0
flink安装模式:session cluster
写在前面:因为参照官网的说明安装过程中出现了很多问题,特记录于此,避免后续重复踩坑 目…
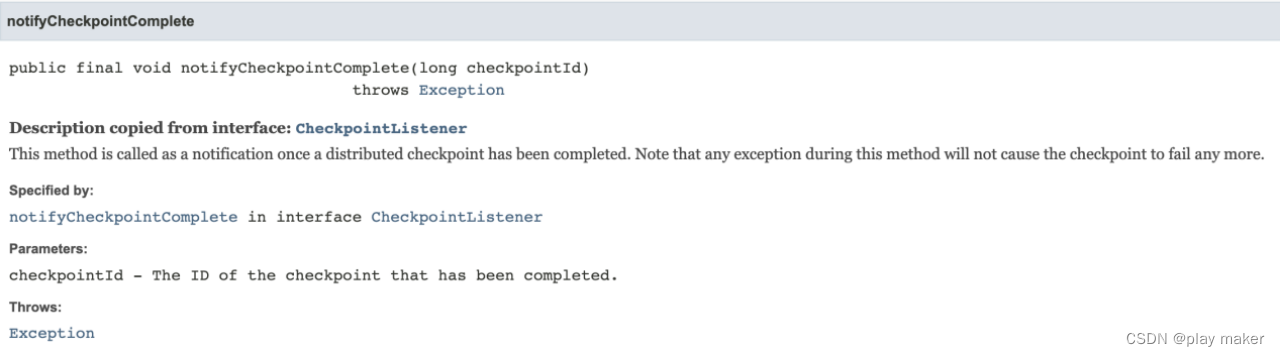
Flink+Kafka、Pulsar实现端到端的exactly-once语义
End-to-End Exactly-Once Processing in Apache Flink with Apache Kafka
2017年12月Apache Flink社区发布了1.4版本。该版本正式引入了一个里程碑式的功能:两阶段提交Sink,即TwoPhaseCommitSinkFunction。该SinkFunction提取并封装了两阶段提交协议中的…
【大数据面试题】010 Flink有哪些算子
一步一个脚印,一天一道大数据面试题 这几天生病了,每天只睡2到4小时,吃药恢复了,就先来点简单的题
Flink 有哪些算子 这是一个挺简单的题,不过有时一问我,我还真只结结巴巴说出 map,flatmap 。…
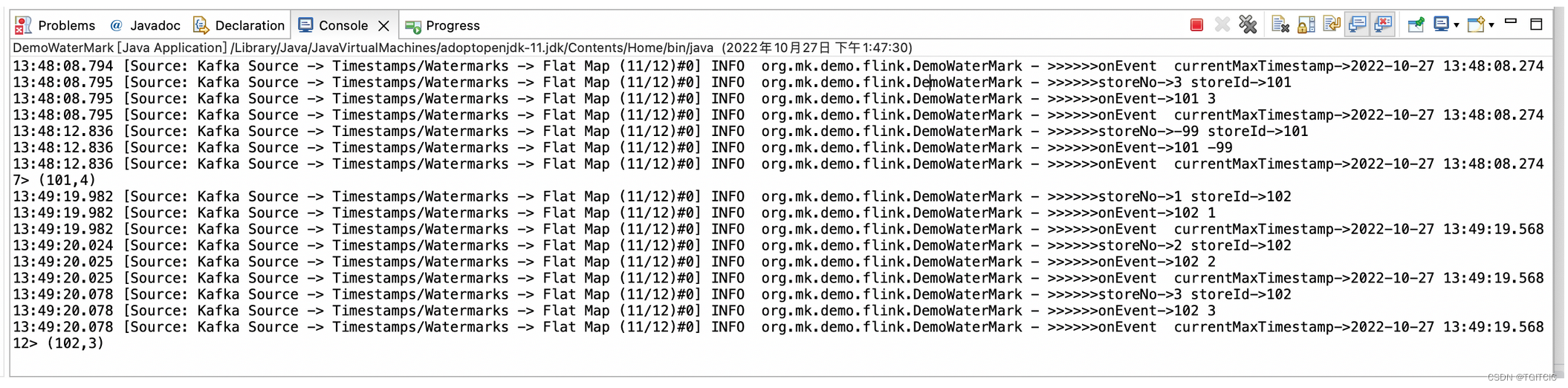
FLINK 基于1.15.2的Java开发-Watermark是怎么解决延迟数据唯一正确的生产级解决方案-目前市面上的例子都有问题
至此篇,已经完成高级生产应用,至此只剩“码需求”了。
开篇
Watermark这一块国内中文相关资料没有一篇是写完整或者写对的。源于:官网的watermark理论是对的,中文相关博客的代码和公式是错的。
很有可能是写第一篇Watermark中文…
Flink1.15源码解析--启动脚本----start-cluster.sh
文章目录一、 start-cluster.sh1.1、config.sh1.2、jobmanager.sh1.3、taskmanager.sh1.4、flink-daemon.sh1.4.1、根据传入的ENTRYPOINT参数确定入口类1.4.2、将入口类作为参数启动jar返回[Flink1.15源码解析-总目录](https://blog.csdn.net/wuxintdrh/article/details/127796…
![[flink]系统架构](https://img-blog.csdnimg.cn/img_convert/fb19de7f3e4a4950922b0382dbcc6b1b.png)
[flink]系统架构
https://www.bilibili.com/video/BV1zr4y157XV?p21&vd_source51f694f71c083955be7443b1d75165e0看到4:12,继续他说一句,记一句。一 、系统架构1、客户端将程序转换成数据流图(作业图),将提交给jobManager:程序在客户端进行转…
Flink 1.16 idea intellij中运行web ui
在pom.xml文件中添加flink-runtime-web依赖<dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web</artifactId><version>1.16.1</version><scope>provided</scope></dependency>在初始…
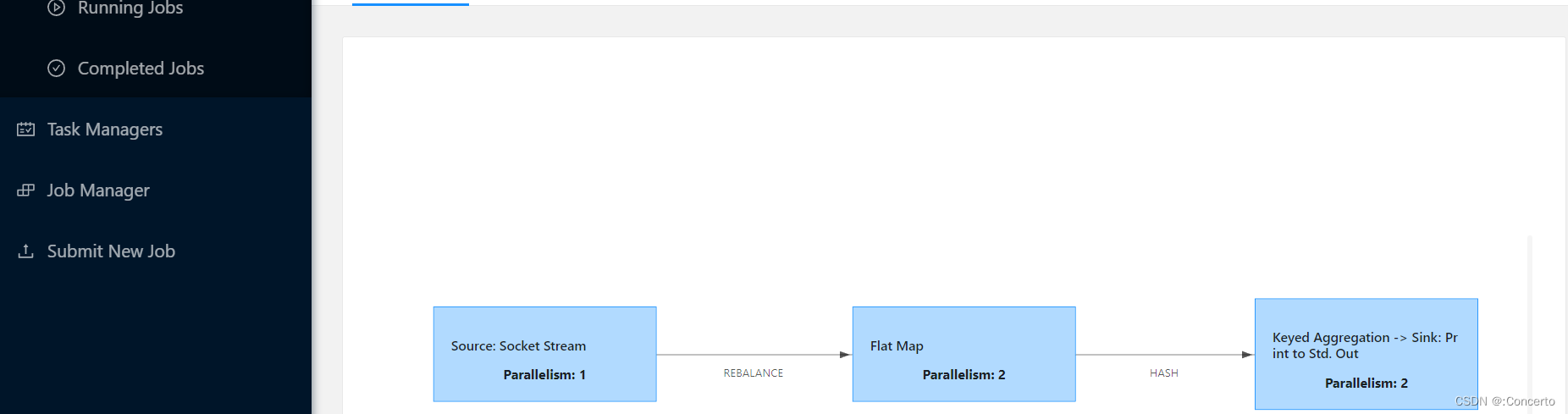
Flink-经典案例WordCount快速上手以及安装部署
2 Flink快速上手
2.1 批处理api
经典案例WordCount
public class BatchWordCount {public static void main(String[] args) throws Exception {//1.创建一个执行环境ExecutionEnvironment env ExecutionEnvironment.getExecutionEnvironment();//2.从文件中读取数据//得到…
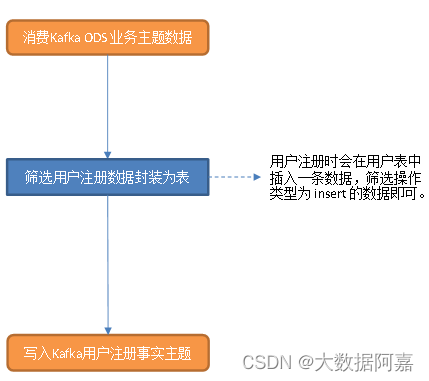
数仓开发之DWD层(四)
目录 十一:工具域优惠券领取事务事实表
11.1 主要任务:
11.2 思路分析:
11.3 图解:
十二:工具域优惠券使用(下单)事务事实表
12.1 主要任务:
12.2 思路分析:
12.3…
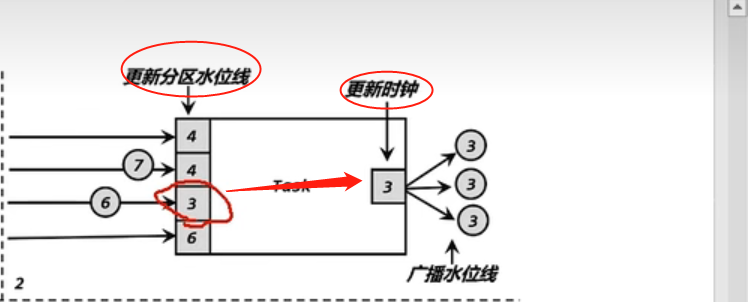
Flink-水位线的设置以及传递
6.2 水位线
6.2.1 概述
分类
有序流 无序流 判断的时间延迟
延迟时间判定
6.2.2 水位线的设置
分析 DataStream下的assignTimstampsAndWatermarks方法,返回SingleOutputStreamOperator本质还是个算子,传入的参数是WatermarkStrategy的生成策略 但…
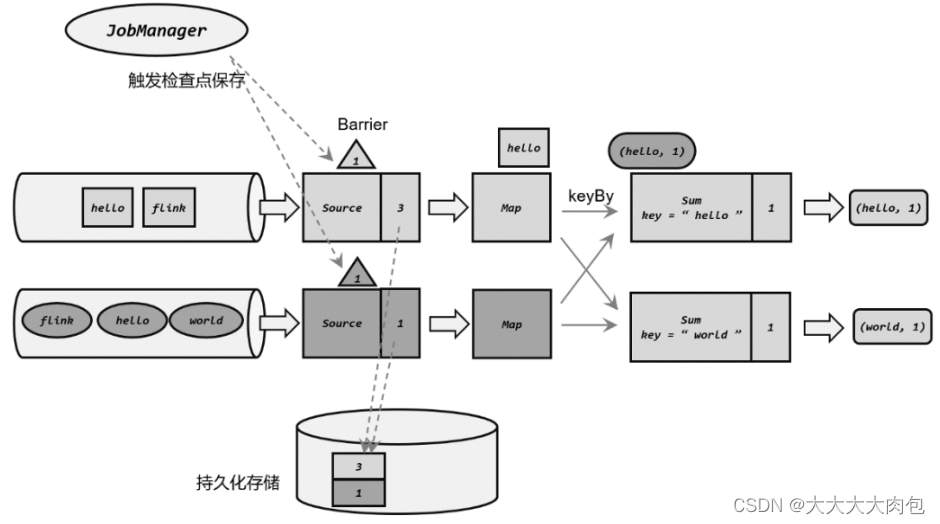
Flink的检查点和保存点
在分布式架构中,当某个节点出现故障,其他节点基本不受影响。这时只需要重启应用,恢复之前某个时间点的状态继续处理就可以了。这一切看似简单,可是在实时流处理中,我们不仅需要保证故障后能够重启继续运行,…

实时即未来,大数据项目车联网之创建Flink实时计算子工程【二】
文章目录写在前面车联网项目全新升级创建Flink实时计算子工程1 在原工程下创建实时分析子模块2 导入实时分析子模块pom依赖3 配置实时分析子模块资源文件写在前面
车联网项目全新升级
更全 8-》21篇 更细 -》 图文并茂、部分代码首次披露 更新 -》Flink车联网项目贴近企业开发…
Flink系列之Flink集群搭建
title: Flink系列 二、Flink集群搭建
2.1 Flink的Standalone模式集群安装
1、上传解压重命名
[roothadoop10 software]# tar -zxvf flink-1.14.3-bin-scala_2.12.tgz
[roothadoop10 software]# mv flink-1.14.3 flink2、进入到解压之后的目录里面修改配置文件flink-conf.yam…
殿堂级Flink源码极精课程预售
一、为什么我们要读源码? 1、让个人技术快速成长: 优秀的开源框架,底层的源码设计思想也非常优秀,同时还有含有大量的设计模式和并发编程技术,优秀的解决方案,熟读源码对猿们技术提升有很大帮助
2、新技术学习能力: Java开源码框架的源码熟读后,若出现…
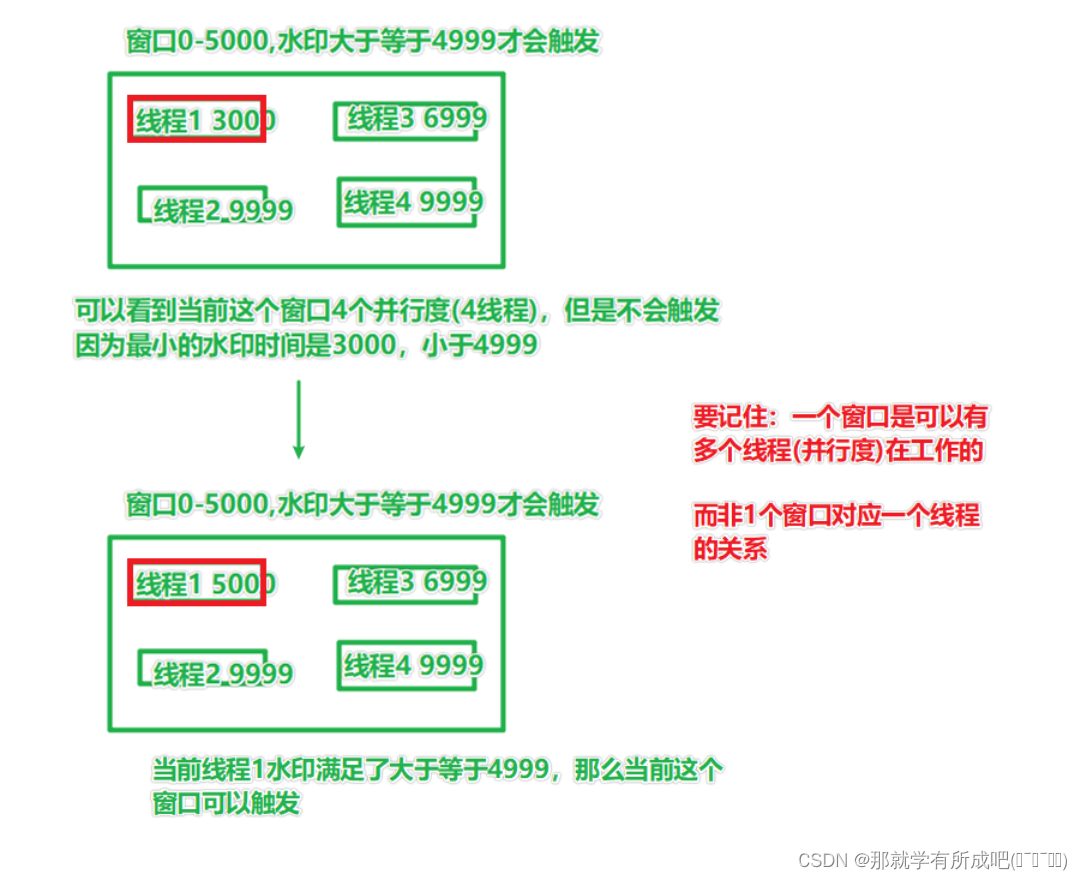
flink重温笔记(九):Flink 高级 API 开发——flink 四大基石之WaterMark(Time为核心)
Flink学习笔记 前言:今天是学习 flink 的第 9 天啦!学习了 flink 四大基石之 Time的应用—> Watermark(水印,也称水位线),主要是解决数据由于网络延迟问题,出现数据乱序或者迟到数据现象&…

在Docker跑通Flink分布式版本的WordCount
前言
前文我们介绍了,使用Docker快速部署Flink分布式集群,这一把我们研究一下怎么自己撸一个WordCount上去跑起来。
官网例子的问题
大家发现我的风格或多或少是因为引导大家怎么去入门到熟悉的过程,所以我希望传递给大家一些学习的办法。我是比较大家直接看官网…
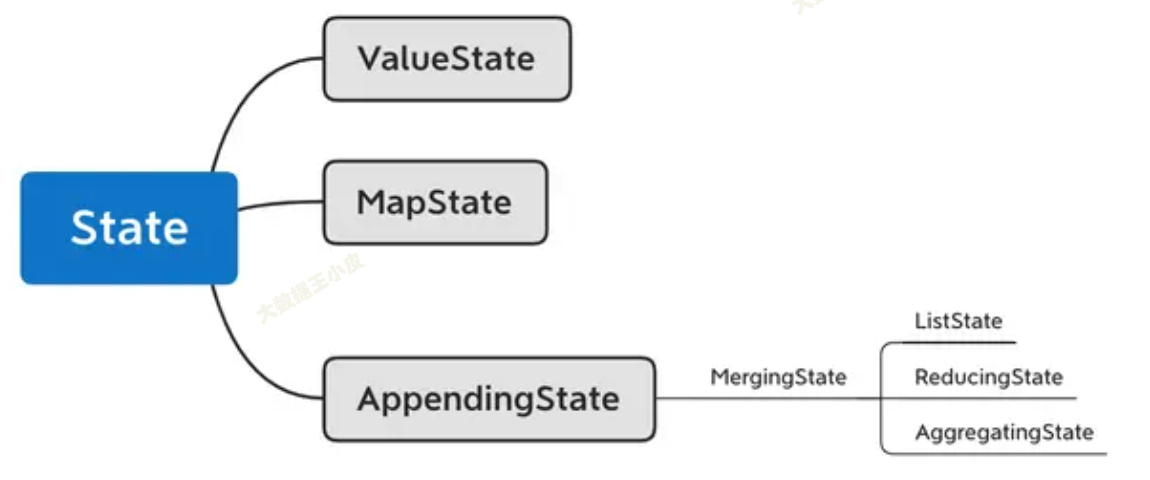
【Flink入门修炼】2-2 Flink State 状态
什么是状态?状态有什么作用?如果你来设计,对于一个流式服务,如何根据不断输入的数据计算呢?又如何做故障恢复呢?
一、为什么要管理状态
流计算不像批计算,数据是持续流入的,而不是…

【Flink】检查点算法实现原理之检查点分界线
一 检查点的实现算法
一种简单的想法(同步的思想) 暂停应用保存状态到检查点再重新恢复应用(Spark Streaming) Flink 的改进实现(异步的思想) 基于 Chandy-Lamport 算法的分布式快照算法将检查点的保存和数…
Flink 大数据 学习详情
参考视频: 尚硅谷大数据Flink1.17实战教程从入门到精通_哔哩哔哩_bilibili
核心目标: 数据流上的有状态的计算 具体说明: Apache Flink是一个 框架 和 分布式处理引擎,用于对 无界(eg:kafka) 和…
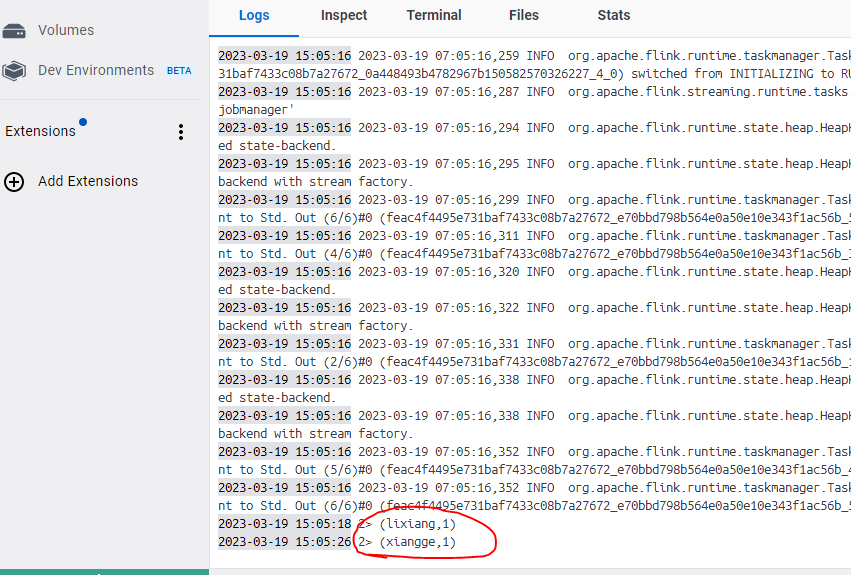
DockerDesktop搭建Flink集群:命令行提交jar包
一般提交任务都是在WEBUI中,可是如果想用命令行提交该怎么办?尤其我这个是DockerDesktop,又该怎么弄呢?和正常的Docker一样吗?是的,一样的。我先将需要提交的jar包放进jobmanager的容器中:Ubunt…
flink sql 如何upsert 到一张hologres表中
Flink Table 的三种 Sink 模式
作为计算引擎 Flink 应用的计算结果总要以某种方式输出,比如调试阶段的打印到控制台或者生产阶段的写到数据库。而对于本来就需要在 Flink 内存保存中间及最终计算结果的应用来说,比如进行聚合统计的应用,输出…
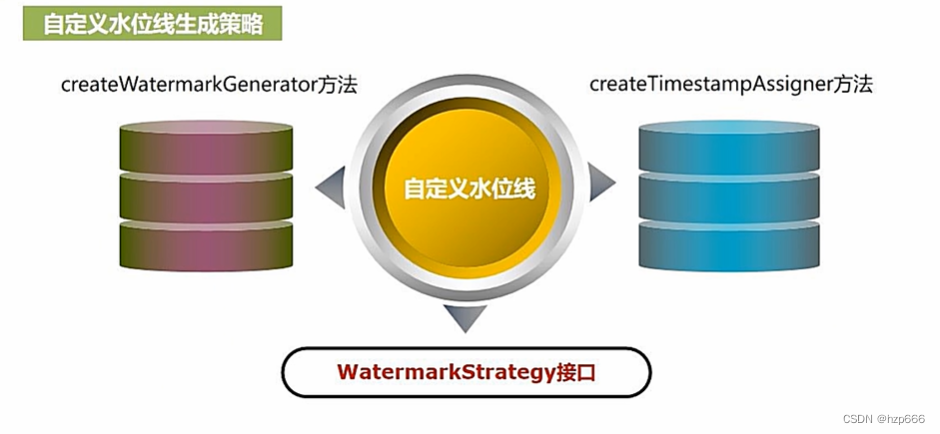
Flink学习28:水位线
1.前言
flink有3种时间,主要是事件时间和处理时间。 水位线主要解决,数据乱序到达或者延迟到达的问题 2.水位线原理 即只有当水位线,越过窗口的结束时间,才会触发窗口计算。
窗口计算需要同时满足两个条件:
1.水位线…
Flink / Scala - 19.Side Outputs 侧输出流简介与使用
目录
一.引言
二.Side Outputs 简介
1.定义 OutputTag
2.通过 Context 输出
3.获取 Side Outputs
三.Side Outputs 实战

flink学习之水位线
什么是水位线
在事件时间语义下,我们不依赖系统时间,而是基于数据自带的时间戳去定义了一个时钟, 用来表示当前时间的进展。于是每个并行子任务都会有一个自己的逻辑时钟,它的前进是靠数 据的时间戳来驱动的。 我们可以把时钟也以…

Flink处理函数(3)—— 窗口处理函数
窗口处理函数包括:ProcessWindowFunction 和 ProcessAllWindowFunction
基础用法
stream.keyBy( t -> t.f0 ).window( TumblingEventTimeWindows.of(Time.seconds(10)) ).process(new MyProcessWindowFunction())
这里的MyProcessWindowFunction就是ProcessWi…
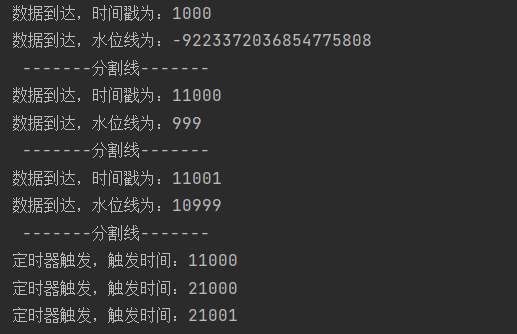
Flink处理函数(2)—— 按键分区处理函数
按键分区处理函数(KeyedProcessFunction):先进行分区,然后定义处理操作
1.定时器(Timer)和定时服务(TimerService)
定时器(timers)是处理函数中进行时间相关…

flink结合Yarn进行部署
1. 什么是Yarn模式部署Flink
独立(Standalone)模式由 Flink 自身提供资源,无需其他框架,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但我们知道,Flink 是大数据计算框架,不是资…
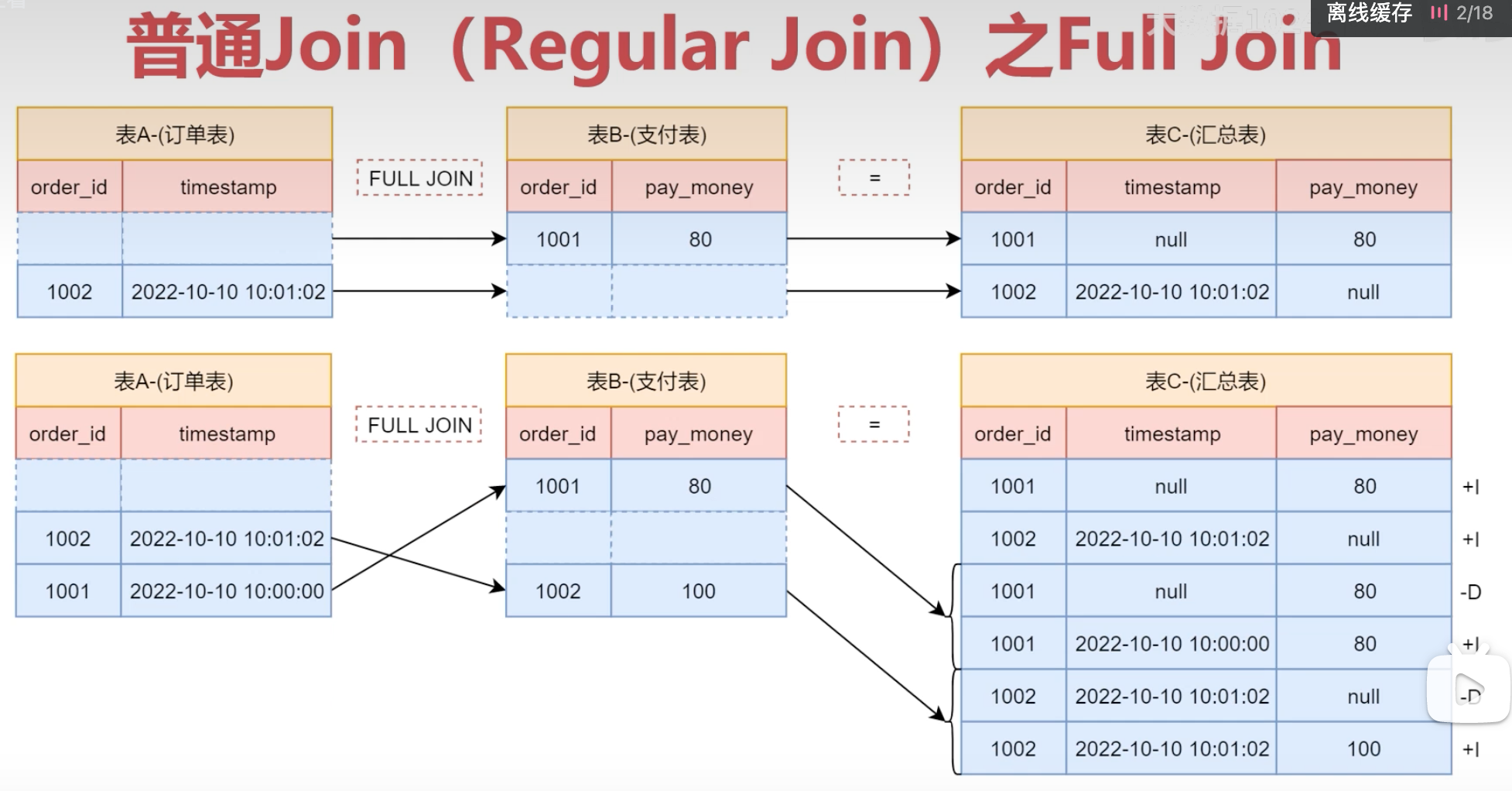
【Flink精讲】双流Join之Regular Join(即普通Join)
Regular Join
普通Join
通过条件关联两条实时数据流:动态表Join动态表支持Inner Join、Left Join、Right Join、Full Join。 1. Inner Join(Join):只有两边数据流都关联上才输出[L,R] 2. Left Join(Left Outer Join):只要左流有数据即输出[…

PiflowX组件 - Filter
Filter组件
组件说明
数据过滤。
计算引擎
flink
组件分组
common
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子conditioncondition“”无是过滤条件。age > 50 or age < 20
Filter示例…

【大数据】基于 Flink CDC 构建 MySQL 和 Postgres 的 Streaming ETL
基于 Flink CDC 构建 MySQL 和 Postgres 的 Streaming ETL 1.准备阶段1.1 准备教程所需要的组件1.2 下载 Flink 和所需要的依赖包1.3 准备数据1.3.1 在 MySQL 数据库中准备数据1.3.2 在 Postgres 数据库中准备数据 2.启动 Flink 集群和 Flink SQL CLI3.在 Flink SQL CLI 中使用…
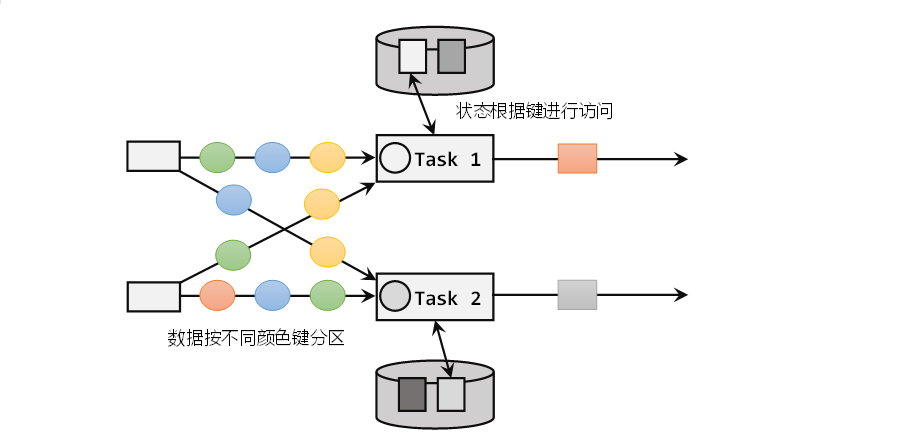
Flink中的状态管理
一.Flink中的状态
1.1 概述
在Flink中,算子任务可以分为有状态和无状态两种状态。
无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果。例如Map、Filter、FlatMap都是属于无状态算子。
而有状态的算子任务,就…

流式湖仓增强,Hologres + Flink 构建企业级实时数仓
流式湖仓增强,Hologres + Flink 构建企业级实时数仓 一、Hologres+Flink,阿里云上众多客户实时数仓的首选 随着大数据从规模化走向实时化,实时数据的需求覆盖互联网、交通、传媒、金融、政府等各个领域。实时计算在企业大数据平台的比重也在不断提高,部分行业已经达到了 50…
Flink集成Hive之Hive Catalog
流程流程:
Flink消费Kafka,逻辑处理后将实时流转换为表视图,利用HiveCataLog创建Hive表,将实时流 表insert进Hive,注意分区时间字段需要为 yyyy-MM-dd形式,否则抛出异常:java.time.format.DateTimeParseException: Text 20240111 could not be parsed 写入到hive分区表
strea…
FlinkCDC的分析和应用代码
前言:原本想讲如何基于Flink实现定制化计算引擎的开发,并以FlinkCDC为例介绍;发现这两个在表达上不知以谁为主,所以先分析FlinkCDC的应用场景和技术实现原理,下一篇再去分析Flink能在哪些方面,做定制化计算…
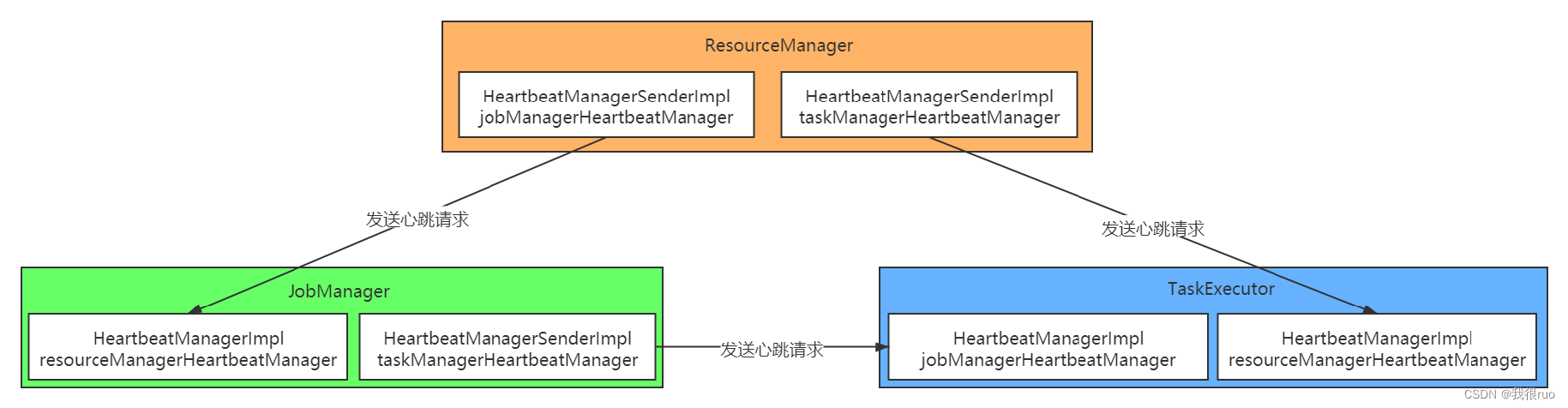
深入理解 Flink(五)Flink Standalone 集群启动源码剖析
前言
Flink 集群的逻辑概念: JobManager(StandaloneSessionClusterEntrypoint) TaskManager(TaskManagerRunner) Flink 集群的物理概念: ResourceManager(管理集群所有资源,管理集群所有从节点) TaskExecutor(管理从节点资源,接…

【大数据】深入浅出 Apache Flink:架构、案例和优势
深入浅出 Apache Flink:架构、案例和优势 1.现代大数据架构1.1 什么是批处理?1.2 什么是流处理? 2.Apache Flink 项目2.1 处理无界和有界数据流2.2 有界数据流2.3 无界流 3.Apache Flink 架构和关键组件3.1 Flink 架构3.2 Flink 生态3.2.1 Da…
flink源码分析 - flink命令启动分析
flink版本: flink-1.12.1
源码位置: flink-dist/src/main/flink-bin/bin/flink flink命令源码:
#!/usr/bin/env bash
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
#…
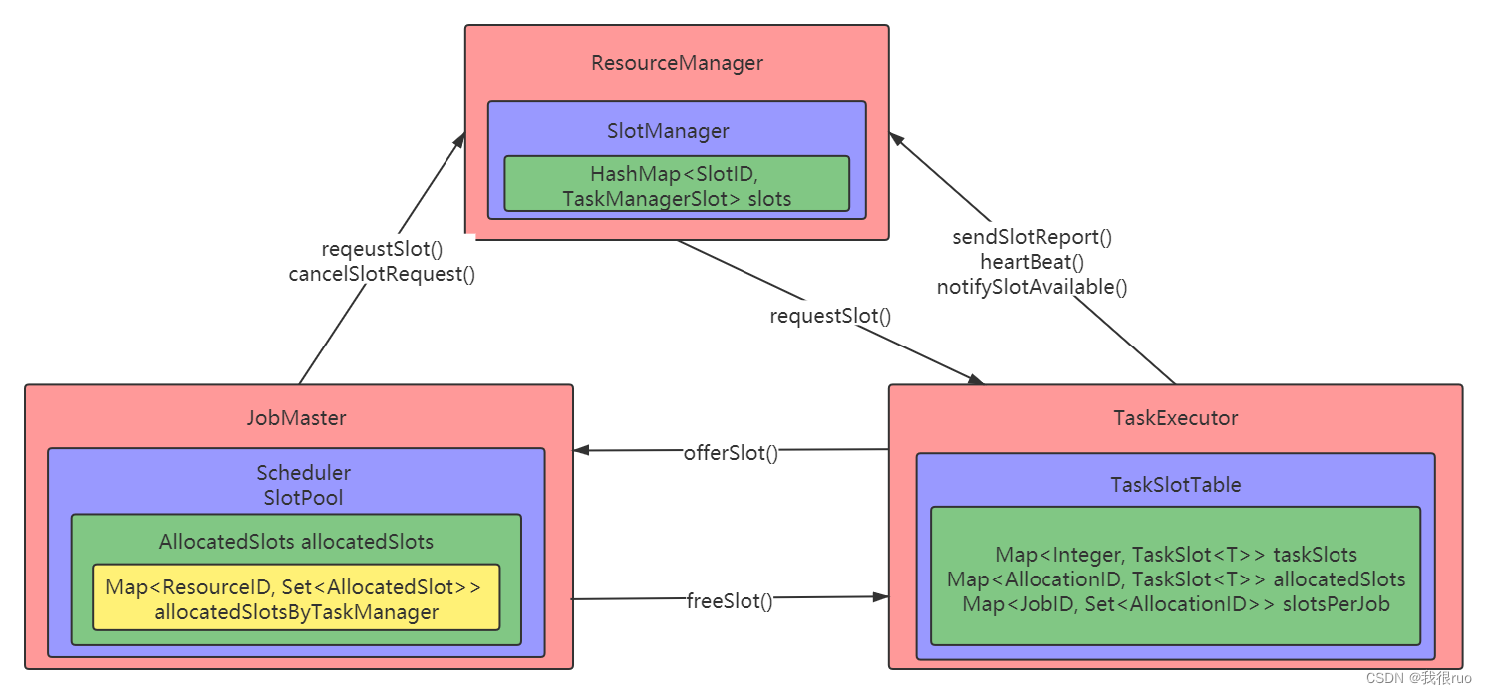
深入理解 Flink(七)Flink Slot 管理详解
1.JobMaster 注册成功之后开始调度
JobMaster 中封装了一个 DefaultScheduler,在 DefaultScheduler.startSchedulingInternal() 方法中生成 ExecutionGraph 以执行调度。
2.Flink 的资源管理机制
资源调度的大体流程如下:
a.TaskExecutor 注册
Reg…
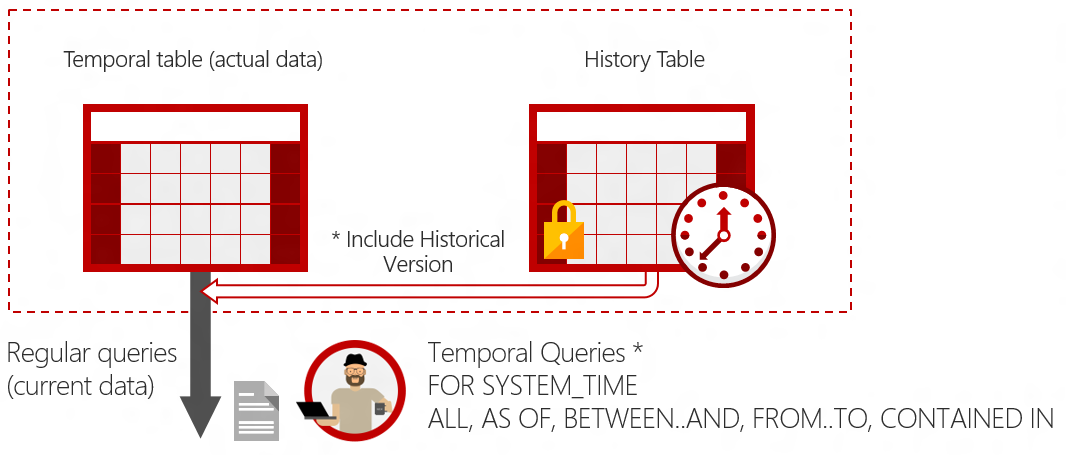
Flink-SQL——时态表(Temporal Table)
时态表(Temporal Table) 文章目录 时态表(Temporal Table)数据库时态表的实现逻辑时态表的实现原理时态表的查询实现时态表的意义 Flink中的时态表设计初衷产品价格的例子——时态表汇率的例子——普通表 声明版本表声明版本视图声明普通表 一个完整的例子测试数据代码实现测试…

【大数据】Flink 详解(八):SQL 篇 Ⅰ
《Flink 详解》系列(已完结),共包含以下 10 10 10 篇文章:
【大数据】Flink 详解(一):基础篇【大数据】Flink 详解(二):核心篇 Ⅰ【大数据】Flink 详解&…
Flink State 状态管理
文章目录 前言一、状态分类二、keyed代码示例ListStateMapState 总结 前言
状态在Flink中叫做State,用来保存中间计算结果或者缓存数据。要做到比较好的状态管理,需要考虑以下几点内容:
状态数据的存储和访问 在Task内部,如何高…
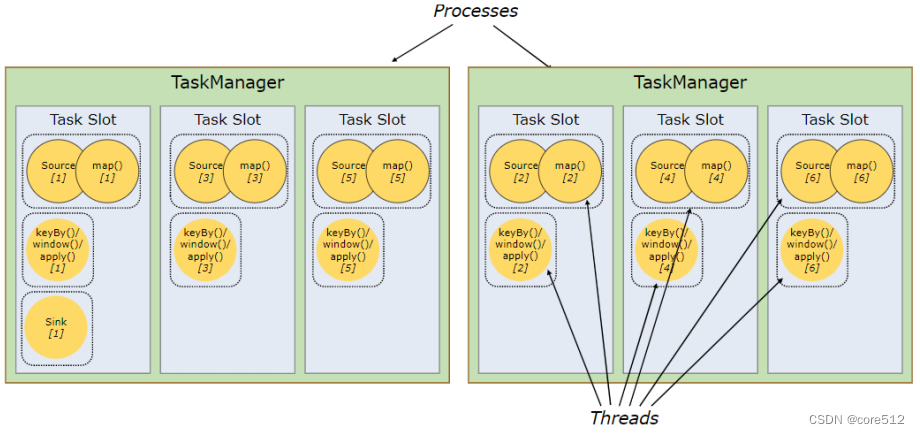
Flink实战之运行架构
本文章:重点是分析清楚运行架构以及并行度与slot的分配 1、JobManager和TaskManager
Flink中的节点可以分为JobManager和TaskManager。
JobManager处理器也称为Master,用于协调分布式任务执行。他们用来调度task进行具体的任务。TaskManager处理器也称…
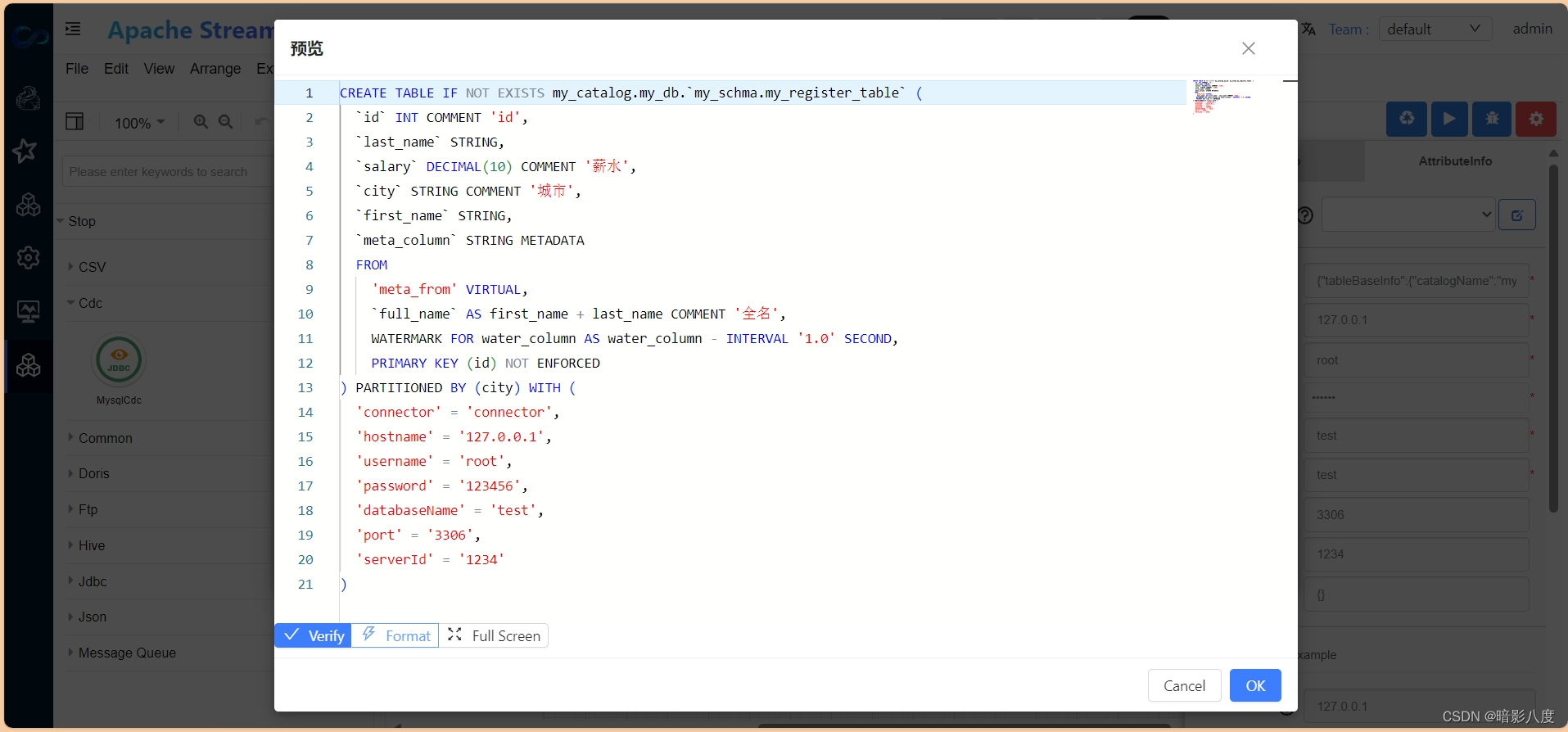
PiflowX如何快速开发flink程序
PiflowX如何快速开发flink程序
参考资料
Flink最锋利的武器:Flink SQL入门和实战 | 附完整实现代码-腾讯云开发者社区-腾讯云 (tencent.com)
Flink SQL 背景
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标…

【大数据】Flink 测试利器:DataGen
Flink 测试利器:DataGen 1.什么是 FlinkSQL ?2.什么是 Connector ?3.DataGen Connector3.1 Demo3.2 支持的类型3.3 连接器属性 4.DataGen 使用案例4.1 场景一:生成一亿条数据到 Hive 表4.2 场景二:持续每秒生产 10 万条…
Flink天级别窗口聚合的时区问题
flink处理天级别的开窗出现时区的问题时区的问题是,在处理数据的时候我们是东八区,要对当前要处理的时间加上8小时,才是符合我们预期的。flink这个没考虑时区问题。1.时间纪元所谓的”时间纪元”就是1970年1月1日0时0分0秒,指的是…
Hudi(22):Hudi集成Flink之常见问题汇总
目录
相关文章链接
问题一:存储一直看不到数据
问题二:数据有重复
问题三:Merge On Read 写只有 log 文件 相关文章链接 Hudi文章汇总
问题一:存储一直看不到数据
如果是 streaming 写,请确保开启 checkpoint&a…

【Flink】详解JobGraph
概述
JobGraph 是 StreamGraph 优化后的产物,客户端会将优化后的 JobGraph 发送给 JM。接下来的文章涉及到一些前置知识点,没有看前几期的小伙伴最好看一下前几期:
【Flink】详解StreamGraph【Flink】浅谈Flink架构和调度【Flink】详解Flin…
flink实战--FlinkSQl实时写入hudi表元数据自动同步到hive
简介 为了实现hive, trino等组件实时查询hudi表的数据,可以通过使用Hive sync。在Flink操作表的时候,自动同步Hive的元数据。Hive metastore通过目录结构的来维护元数据,数据的更新是通过覆盖来保证事务。但是数据湖是通过追踪文件来管理元数据,一个目录中可以包含多个版本…
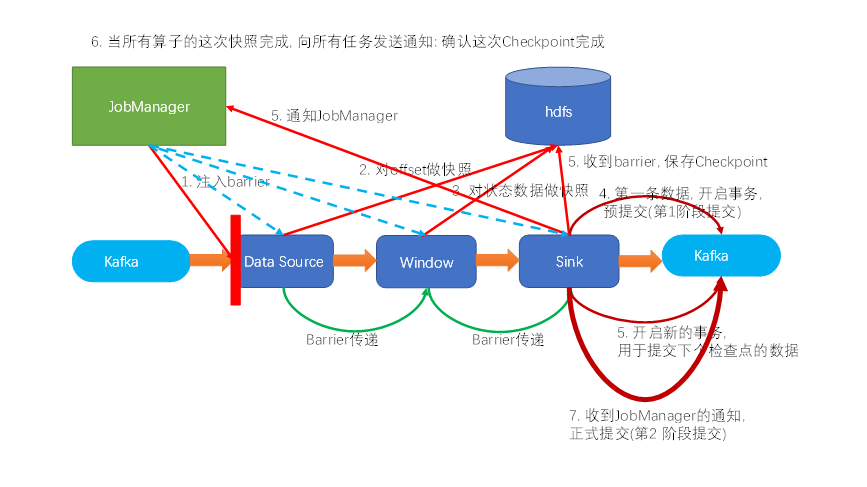
Flink容错机制介绍
Flink容错机制介绍 1.状态一致性
一致性实际上是"正确性级别"的另一种说法,是在成功处理故障并恢复之后得到的结果。
1-1.一致性级别
在流处理中,一致性可以分为3个级别
最多一次 - at-most-once 故障发生之后,计数结果可能…
Flink流计算处理-旁路输出
使用Flink做流数据处理时,除了主流数据输出,还自定义侧流输出即旁路输出,以实现灵活的数据拆分。
定义旁路输出标签
首先需要定义一个OutputTag,代码如下:
// 这需要是一个匿名的内部类,以便我们分析类型…
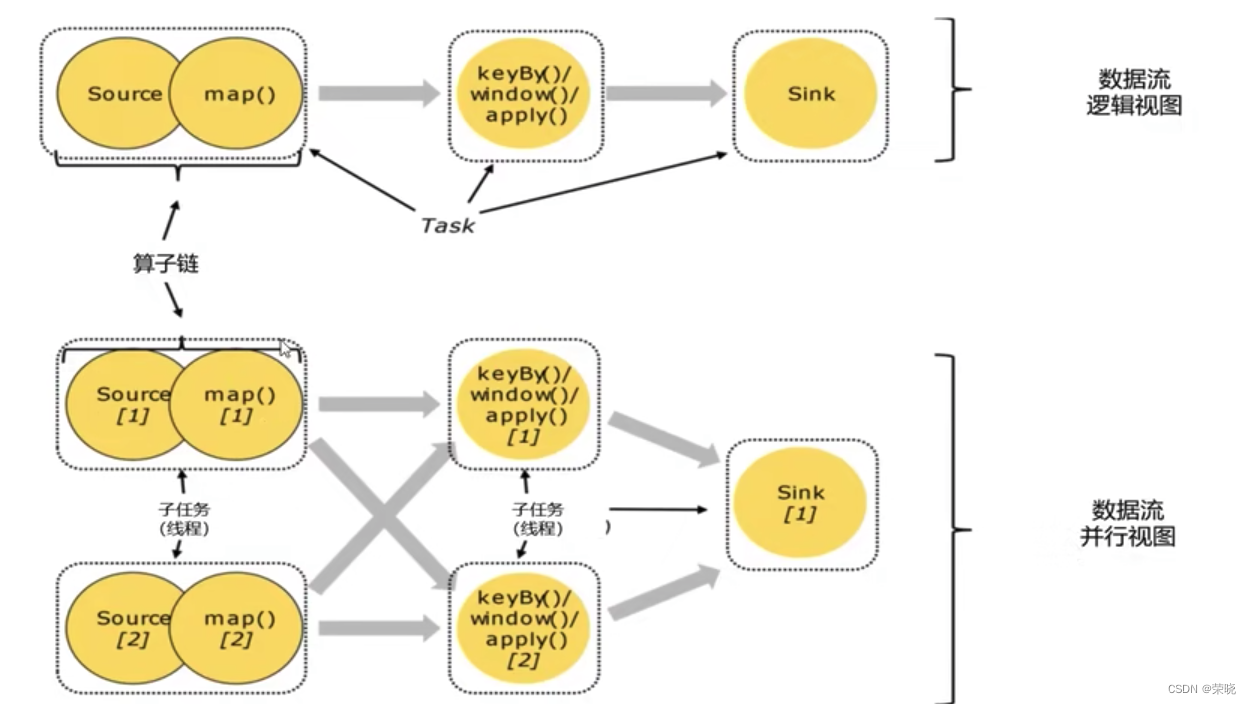
flink笔记:022-26系统架构
其实客户端并不是处理系统的一部分,它只负责作业的 提交。具体来说,就是调用程序的 main 方法,将代码转换成“数据流图”(Dataflow Graph), 并最终生成作业图(JobGraph),…
【flink】 各种join类型对比
表定义 动态表(dynamic table):动态表是流的另一种表达方式,动态表作为一个逻辑的抽象概念,使我们更容易理解flink中将streaming发展到table这个层次的设计,本质都是对无边界、持续变更数据的表示形式,所以动态表与流之…
![[Flink]部署模式(看pdf上的放上面)](https://img-blog.csdnimg.cn/img_convert/c678d04caffc4f4d808fd0867bb8e4c6.png)
[Flink]部署模式(看pdf上的放上面)
运行一个wordcountval dataStream: DataStream[String] environment.socketTextStream("hadoop1", 7777)
//流式数据不能进行groupBy,流式数据要来一条处理一次.0表示第一个元素,1表示第二个元素
//keyBy(0)根据第一个元素进行分组
val out: DataStream[(String, In…
Apache Pulsar的Connector连接器使用
目录1. 背景2. 介绍3. Pulsar Flink Connector3.1 Flink读取Pulsar消息3.1 Flink发送消息到Pulsar1. 背景
虽然可以使用produce和consume的API进行消息的发送和消费,但Pulsar提供了一种更简便的方式,用来同步其它系统的数据到Pulsar的topic,…
Flink1.14 Standalone独立集群模式安装
一、下载
在Flink 官网下载Flink 1.14,完整的安装包名是:flink-1.14.4-bin-scala_2.11.tgz。
二、master 配置
解压安装包,编辑conf/flink-conf.yaml文件:
vim conf/flink-conf.yaml jobmanager.rpc.address: 172.21.0.XX
tas…
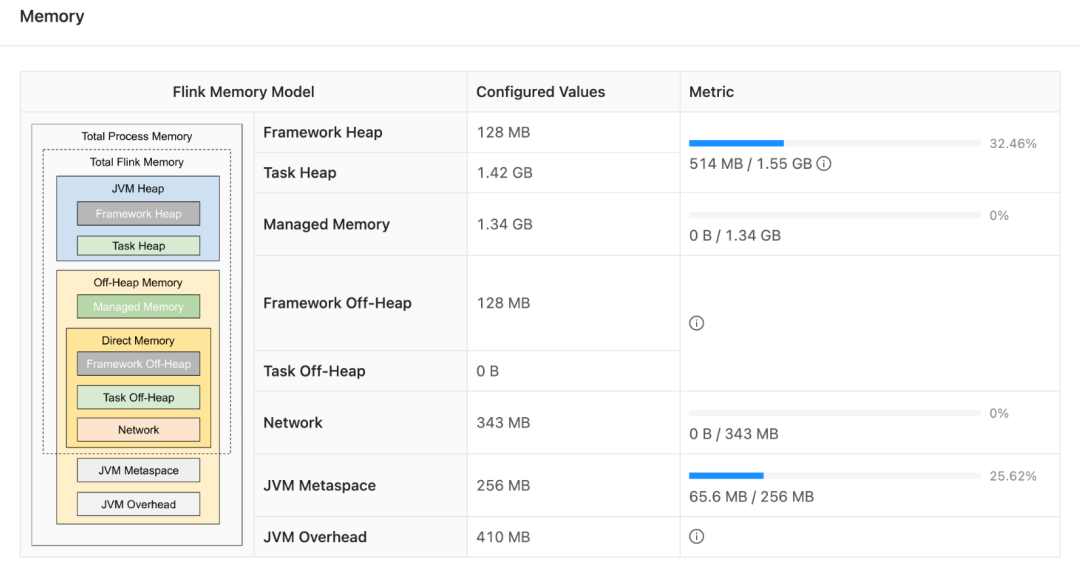
Flink处理大型离线任务稳定性与性能调优探索
Apache Flink作为分布式处理引擎,用于对无界和有界数据流进行状态计算。其中实时任务用于处理无界数据流,离线任务用于处理有界数据。通过本文你将掌握让大型离线任务运行稳定的能力,同时能够通过分析离线任务运行特点,降低任务运…
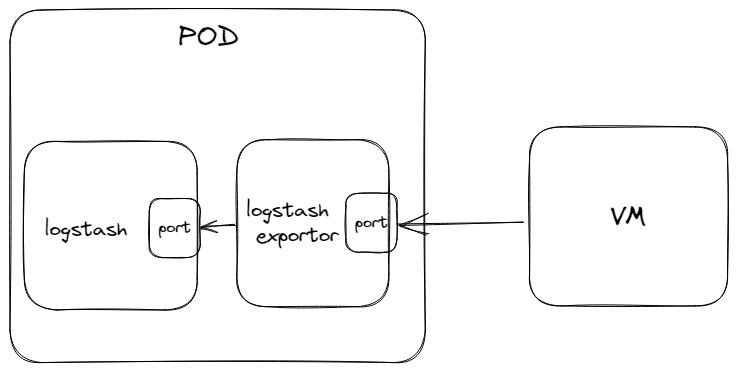
django后端服务、logstash和flink接入VictoriaMetrics指标监控
0.简介
通过指标监控可以设置对应的告警,快速发现问题,并通过相应的指标定位问题。
背景:使用的 VictoriaMetrics(简称 VM) 作为监控的解决方案,需要将 django 服务、logstash 和 flink 引擎接入进来,VM 可以实时的获…
Flink-CountWindow/CountWindowAll
在这里我们已经知道这两者之间的区别,本文将用代码和控制台打印的方式演示二者
CountWindow
CountWindow是基于key的窗口,所以必须在keyBy方法之后才能调用,再演示之前,我们先建立两个类
public class WordOnce {/***表示输入的…
Flink State 状态后端分析
flink状态实现分析
state * State* |* -------------------InternalKvState* | |* MergingState |* | |* …

数据湖架构Hudi(五)Hudi集成Flink案例详解
五、Hudi集成Flink案例详解
5.1 hudi集成flink
flink的下载地址:
https://archive.apache.org/dist/flink/
HudiSupported Flink version0.12.x1.15.x、1.14.x、1.13.x0.11.x1.14.x、1.13.x0.10.x1.13.x0.9.01.12.2
将上述编译好的安装包拷贝到flink下的jars目录…
Flink SQL join类型
Flink提供了多种流式join操作,我们可以根据实际情况选择最适合自己的类型。下面开始介绍不同的join类型。
Regular Joins(常规join)
Regular Joins是最通用的join类型,和传统数据库的 JOIN 语法完全一致。对于输入表的任何更新&…
FlinkRay使用场景
目录 1. 特点1.1 Apache Flink:1.2 Ray:2. 考虑因素:2.1 社区和生态系统支持:2.2 可靠性和容错性:2.3 运维和管理:2.4 技术团队的熟悉度:2.5 商业支持和可扩展性:3. 对比分析3.1 稳定性和可靠性:3.2 企业的运维角度:3.3 团队熟悉度:3.4 商业支持:3.5 可扩展性:4. 选择…
Flink1.14新特性介绍及尝鲜
一、Flink简介
l官网:Apache Flink: Stateful Computations over Data Streams
lApache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。 版本定位:专注于质量改进和维护的版本 发版时间:2021年9月3…
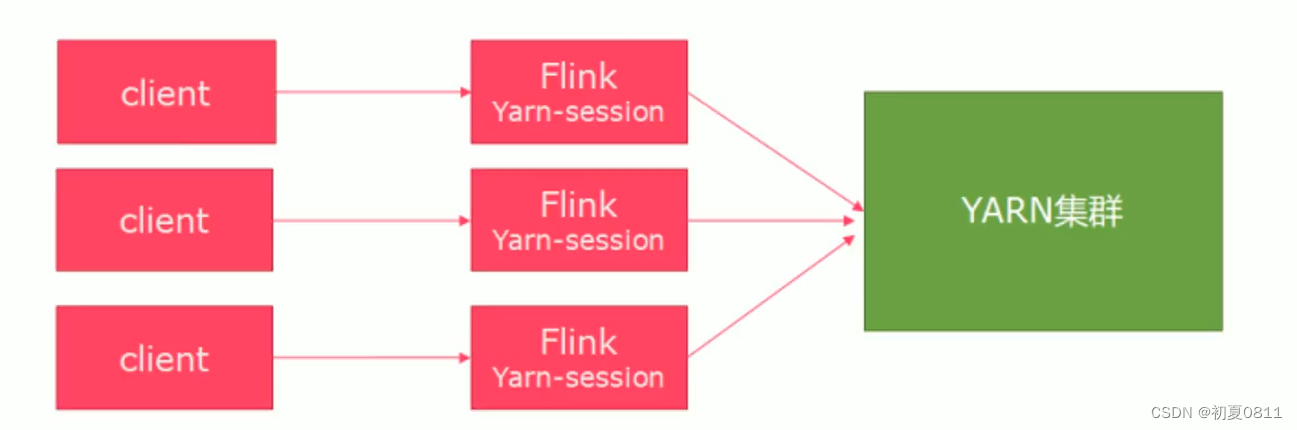
flink-on-yarn两种提交模式及其区别
一、session模式
在yarn上启动一个flink集群,并重复使用该集群,后续提交的任务都是提交给该集群,资源会一直被占用,除非手动关闭。 特点:需要事先申请资源,启动JobManager和TaskManager。 优点:…
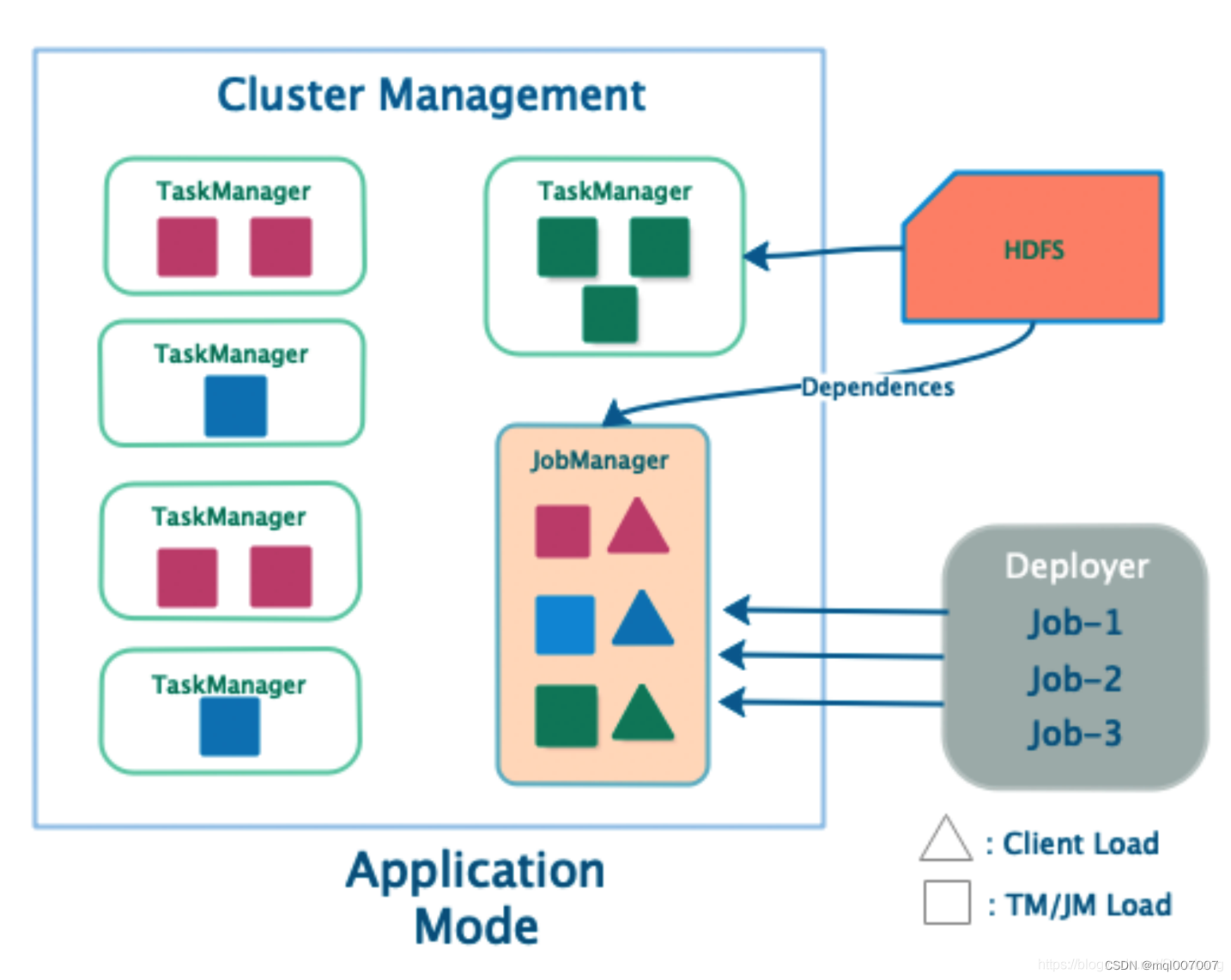
大数据系列——Flink理论
概述 Flink是一个对有界和无界数据流进行有状态计算的分布式处理引擎和框架,既可以处理有界的批量数据集,也可以处理无界的实时流数据,为批处理和流处理提供了统一编程模型,其代码主要由 Java 实现,部分代码由 Scala实…
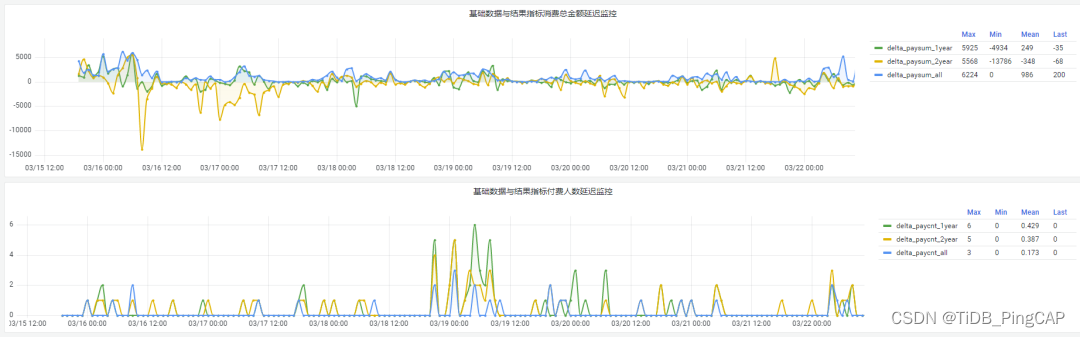
基于 TiDB + Flink 实现的滑动窗口实时累计指标算法
作者:李文杰
前言
在不少的支付分析场景里,大部分累计值指标可以通过 Tn 的方式计算得到 。随着行业大环境由增量市场转为存量市场,产品的运营要求更加精细化、更快速反应,这对各项数据指标的实时性要求已经越来越高。产品如果能…
解析创建KeyedState流程源码
由于在(StreamTask反射)beforeInvoke的“状态初始化”阶段已经把StateInitializationContext(保存了可以创建xxxState的xxxStateStore)交给了StreamOperator的自定义RichFunction,并且AbstractStreamOperator也已经通过…
Hudi的Index类型
Hudi 的索引是 hoodiekey 到文件组(File Group)或者文件 ID(File ID)的映射,hoodiekey 由 recordkey 和 partitionpath 两部分组成。
定义在文件 HoodieIndex.java 中。
分一下几种:
类型说明SIMPLE简单…
公司大数据CDH技术选型升级为EMR集群的技术调研
大数据技术栈现状
大数据技术整体设计图 当前大数据各组件版本
ZooKeeper 3.4.5 Spark 2.4.0 Hue 4.3.0 Hive 2.1.1 Hbase 2.1.4 Hadoop 3.0.0 Kafka 2.2.1 Phoenix 5.0.0-cdh6.2.0 Dolphinscheduler 3.0.0 Yarn 3.0.0-cdh6.3.2 Logstash 7.7.0 Kibana 7.7.0 Elasticsearch 7…
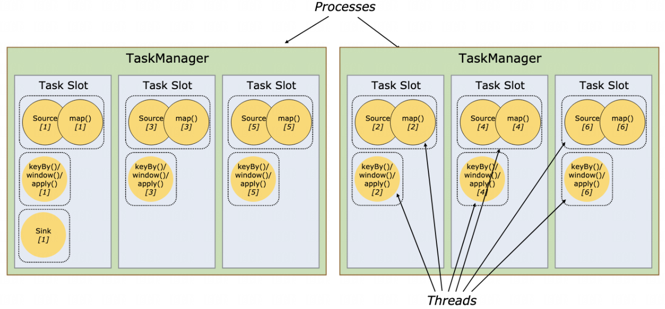
Flink基础介绍-2 架构
Flink基础介绍-1 概述 二、Flink架构2.1 Flink的设计架构2.2 Flink的运行架构2.3 Flink的系统架构 二、Flink架构
2.1 Flink的设计架构
Flink是一个分层的架构系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件,Flink的分层体…
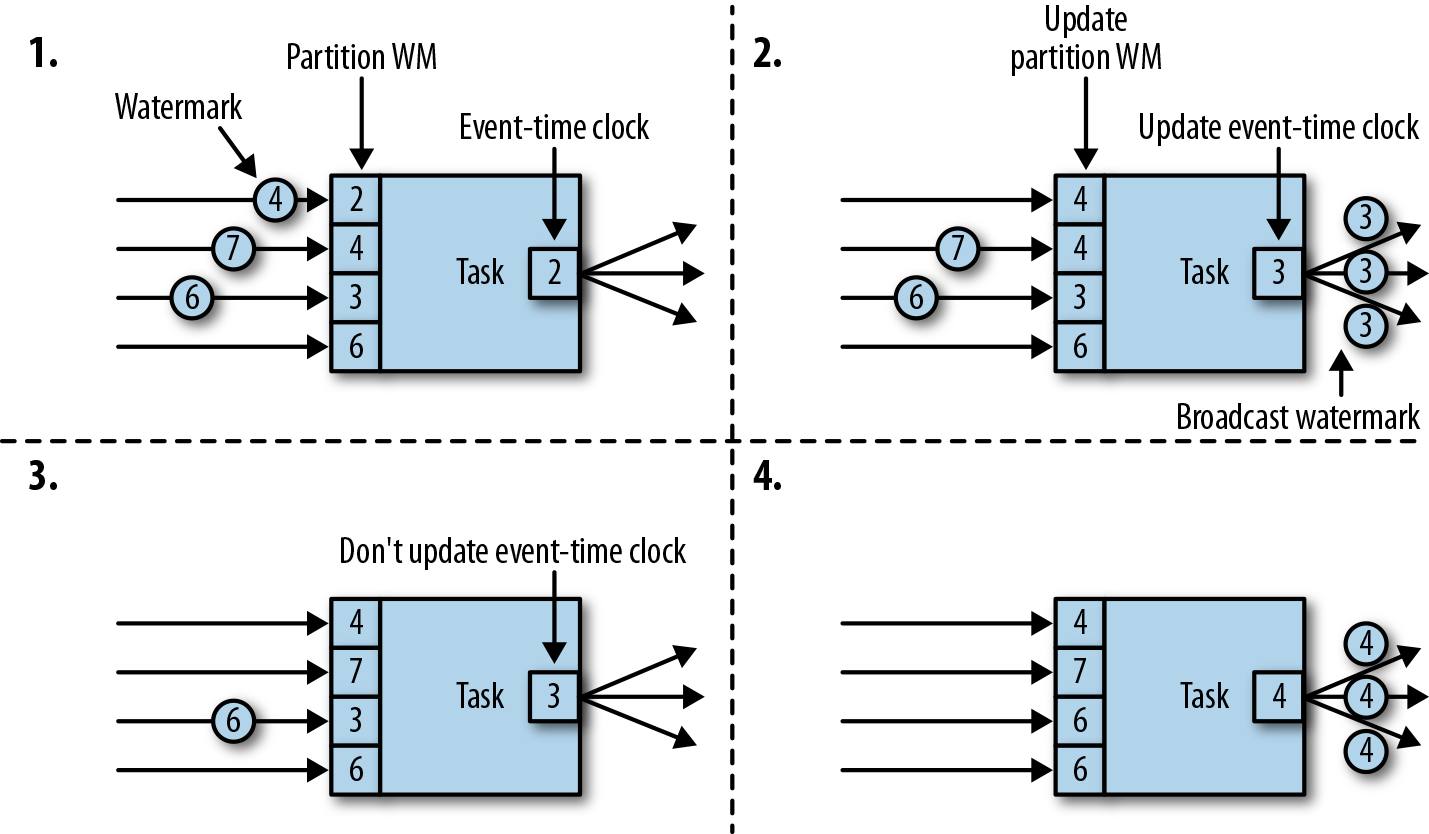
Flink Watermark 源码分析
随着 flink 的快速发展与 API 的迭代导致新老版本差别巨大遂重拾 flink,在回顾到时间语义时对 watermark 有了不一样的理解。 一、如何生成
在 flink 1.12(第一次学习的版本)时 watermark 生成策略还有两种: punctuated 和 periodic,在 1.17 中 punctua…
Flink 侧流输出源码解析
Flink 的 side output 为我们提供了侧流(分流)输出的功能,根据条件可以把一条流分为多个不同的流,之后做不同的处理逻辑,下面就来看下侧流输出相关的源码。先来看下面的一个 Demo,一个流被分成了 3 个流&am…
源码解析Checkpoint后续收尾流程
当StreamTask中的Runnable任务中的OperatorSnapshotFutures执行完成后,就要将ACK消息发送给TaskStateManager。
/*** 整个Checkpoint操作完成后,发送ACK消息给TaskStateManager。*/
private void reportCompletedSnapshotStates(TaskStateSnapshot ackn…

Hudi系列25: Flink SQL使用checkpoint恢复job异常
文章目录 一. 通过Flink SQL将MySQL数据写入Hudi二. 模拟Flink任务异常2.1 手工停止job2.2 指定checkpoint来恢复数据2.3 整个yarn-session上的任务恢复 三. 模拟源端异常3.1 手工关闭源端 MySQL 服务3.2 FLink任务查看 FAQ:1. checkpoint未写入数据2. checkpoint 失败3. 手工取…
【Flink实战系列】Flink 消费多个 topic 的数据根据不同 topic 数据做不同的处理逻辑
Flink 消费多个 topic 的数据根据不同 topic 数据做不同的处理逻辑
需求
有的时候我们需要消费同一个 kafka 集群的多个 topic 数据,然后可能会根据不同 topic 的数据做不同的处理逻辑.可能还需要获取到 topic 的元数据信息比如 offset ,timestamp 等.
分析
其实对于这个需…

Flink 1.13.0 反压监控的优化
Flink 1.13.0 版本增加了很多新特征,具体可以参考前面一篇文章,在 Flink 1.13.0 版本之前,我们通常是通过 UI 上面的 BackPressure 或者 Metrics 里面的 inPoolUsage ,outPoolUsage 指标去分析反压出现的位置.在 Flink 1.13.0 版本中对反压监控新增了瓶颈检测,能够帮助我们快速…
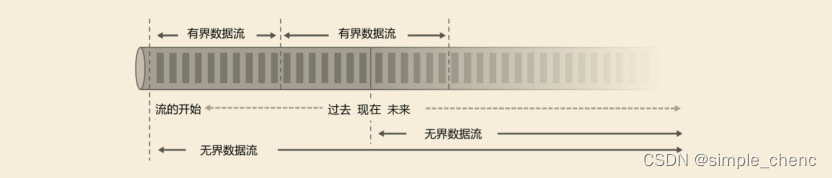
Flink学习--第一章 初识Flink
Flink是Apache基金会旗下的一个开源大数据处理框架,如今已被很多人认为是大数据实时处理的方向和未来,许多公司也都在招聘和储备掌握Flink技术的人才。 1.1 Flink的源起和设计理念 Flink起源于一个叫作Stratosphere的项目,它是由3所地处柏林的…

Flink 实时计算DIM层实现方案
1 概述
DIM层设计要点: (1)DIM层的设计依据是维度建模理论,该层存储维度模型的维度表。 (2)DIM层的数据存储在 HBase 表中DIM 层表是用于维度关联的,要通过主键去获取相关维度信息,…
Flink的数据处理模型
Flink是一个流式处理和批处理的开源框架,它提供了强大的数据处理能力和灵活的编程模型。Flink的数据处理模型基于流式计算的概念,可以实现高效的数据流处理和实时分析。下面介绍Flink的数据处理模型及其核心概念。
1. 流式处理模型
Flink的核心思想是将…

小米基于 Flink 的实时数仓建设实践
摘要:本文整理自小米软件开发工程师周超,在 Flink Forward Asia 2022 平台建设专场的分享。本篇内容主要分为四个部分: 1. 小米数仓架构演变 2. FlinkIceberg 架构升级实践 3. 流批一体实时数仓探索 4. 未来展望 Tips:点击「阅读原…
Flink高手之路2-Flink集群的搭建
文章目录Flink高手之路2-Flink集群的搭建一、Flink的安装模式1.本地local模式2.独立集群模式standalone3.高可用的独立集群模式standalone HA4.基于yarn模式Flink on yarn二、基础环境三、Flink的local模式安装1. 下载安装包2. 上传服务器3.解压4. 配置环境变量5. 使环境变量起…
【Flink实战系列】Flink+kafka+redis 实时计算 wordcount
上一篇中我们在本地跑了一个wordcount,今天我们写一个流式的计算wordcount,读取kafka的数据进行实时的计算,把结果写入redis中;
pom文件如下:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.11</artifactId><…
【Flink实战系列】Flink 集群的搭建 Standalone 模式教程
今天我们来说一下flink,大家可能对flink还不是特别的熟悉,其实它是一个很早的项目,只是在2016年的时候才被大家所注意到,现在已经被很多公司所使用,作为一个后起之秀,或者说流计算的新贵,为什么它能得到大家的认可呢,Flink把批处理当作流处理中的一种特殊情况.在Flink中,所有的…
【flink sql】kafka连接器
Kafka 连接器提供从 Kafka topic 中消费和写入数据的能力。
前面已经介绍了flink sql创建表的语法及说明:【flink sql】创建表
这篇博客聊聊怎么通过flink sql连接kafka
创建kafka表示例
CREATE TABLE KafkaTable (user_id BIGINT,item_id BIGINT,behavior STRI…
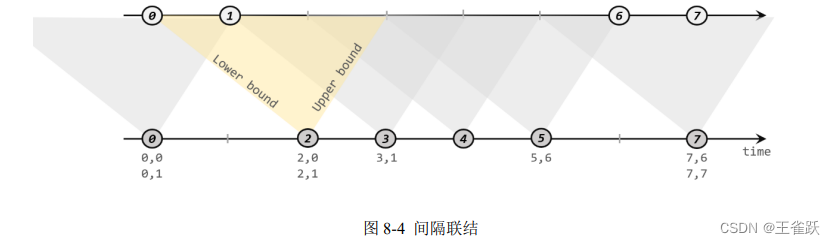
Flink 中的多流转换-第八章
借鉴《尚硅谷Flink1.13版本笔记.pdf》中第七章 多流转换可分为“分流”和“合流”两大类。
目前分流操作一般是通过侧输出流(side output)来实现,而合流的算子比较丰富,根据不同的需求可调用 union()、connect()、join() 等接口进…
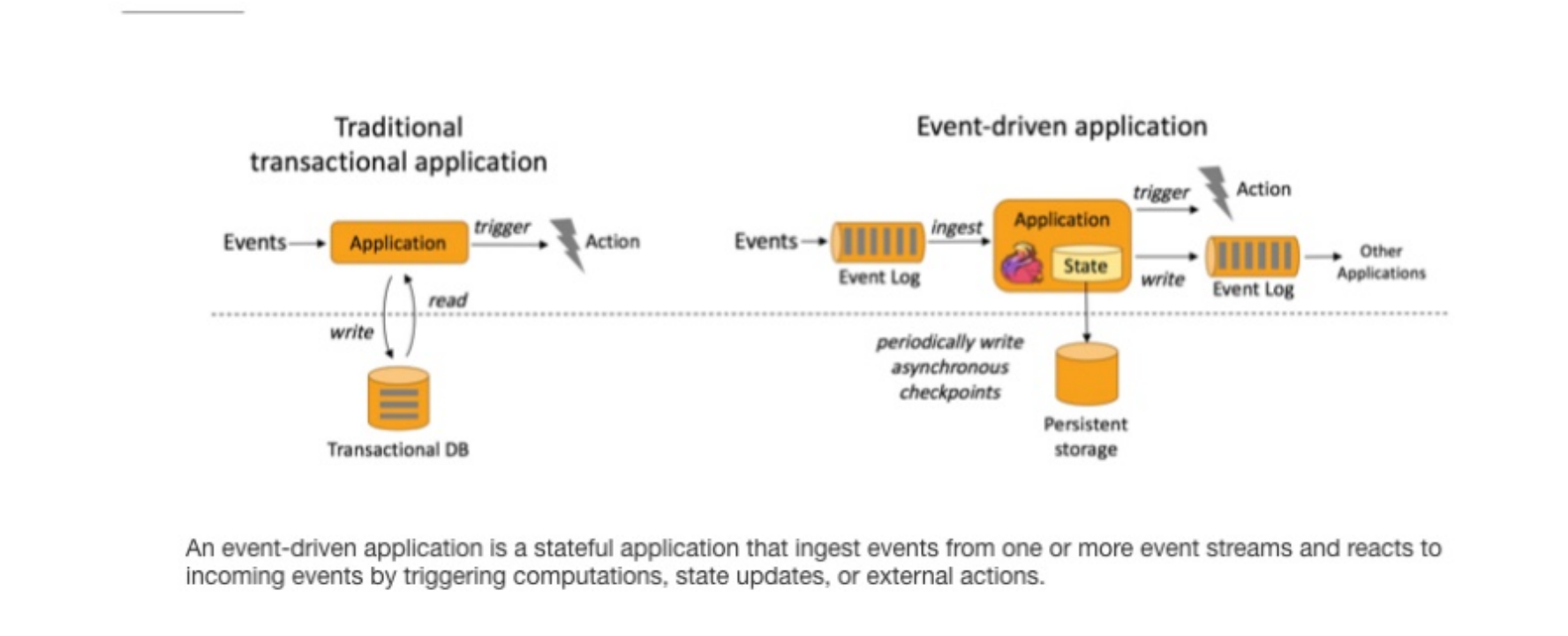
【Apache-Flink零基础入门】「入门到精通系列」手把手+零基础带你玩转大数据流式处理引擎Flink(基础概念解析)
手把手零基础带你玩转大数据流式处理引擎Flink 前言介绍Apache Flink 的定义、架构及原理Flink应用服务Streams有限数据流和无限数据流的区别 StateTimeAPI Flink架构体系 Flink操作处理Flink 的应用场景Flink 的应用场景:Data Pipeline实时数仓搜索引擎推荐 Flink …

Apache Flink 1.17
Apache Flink 1.17 1. Flink 1.17 Overview2. Flink 1.17 Overall Story3. Flink 1.17 Key Features4. Summary5. Q&A 1. Flink 1.17 Overview Flink 1.17 版本完成了 7 个 FLIP,累计贡献者 170,解决 600Issue 以及 1100Commits,整体来看…
Apache Hudi初探(一)(与flink的结合)
背景
和Spark的使用方式不同,flink结合hudi的方式,是以SPI的方式,所以不需要像使用Spark的方式一样,Spark的方式如下:
spark.sql.extensionsorg.apache.spark.sql.hudi.HoodieSparkSessionExtension
spark.sql.catalog.spark_ca…
Flink主要有两种基础类型的状态:operator state。
Flink主要有两种基础类型的状态:keyed state 和operator state。 Operator State 对于Operator State(或者non-keyed state),每个operator state绑定到一个并行operator实例上。在Flink中,Kafka Connector是一个使用Operator State的很好的例…
flinkSQL count中加case when
场景: 当想统计字段等于某个值count时,而且不想用where, 因为where是全局的,当只统计一个字段等于某个值的总数没问题,当一个字段分别等于某两个值的总数就有问题,所以就可以在 count中加case when 例子:
SELECT count(case when…
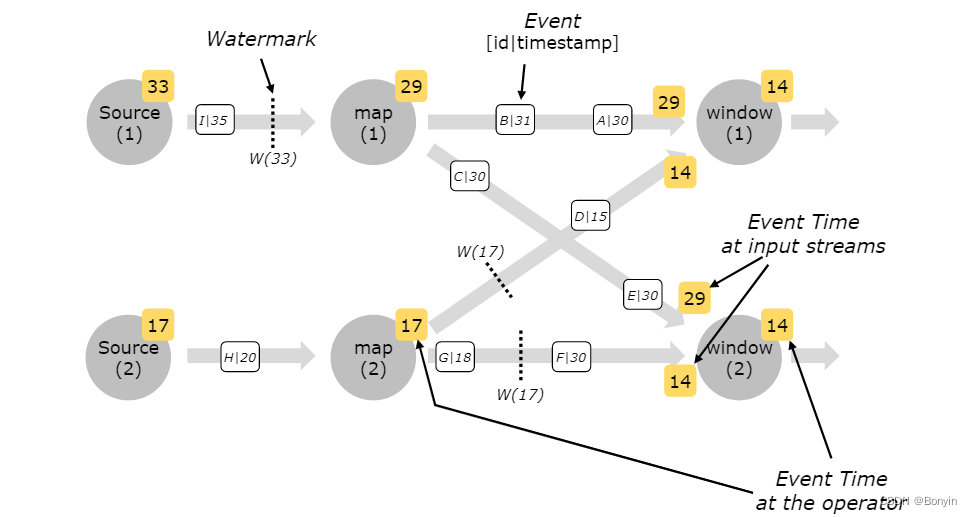
FLink 里面的时间语义说明
本文说明一下flink的时间语义 处理时间(processTIme)
执行相关操作的机器系统时间。 如果flink的流式处理程序是基于processtime。那么代码中所有的操作都是将基于运算符的机器系统时钟时间。每小时的processTime window包括在系统时钟指示完整一个小时…
【iot】初识 边缘-网关-EMQX-Influxdb 全套流程 对比 边缘-网关-MQTT broker-Flink-influxdb
场景:
目前接手一个物联网项目,目前基本整理出了如下2套解决方案
图一:是我新调研的架构(基于EMQX架) 图二:是我们之前的架构(基于非EMQX产品Flink架构) 我始终相信,少…
Flink MySQL CDC connector 使用注意事项
注意事项 表要有主键 库名和表名不能有点号
是个 BUG,估计后续会修复。
表名不能有大写
也是个 BUG,估计后续会修复。
如果表名含有大写的字母,查询时日志可看到如下信息:
java.util.concurrent.ExecutionException: java.…
使用Flink MySQL cdc分别sink到ES、Kafka、Hudi
环境说明 [flink-1.13.1-bin-scala_2.11.tgz](https://archive.apache.org/dist/flink/flink-1.13.1/flink-1.13.1-bin-scala_2.11.tgz)[hadoop-2.7.3.tar.gz](https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz)[flink-cdc-connectors](https:…

编译flink1.6源码并打包成CDH6.3.2的parcel
说明:scala :2.12,maven:3.6.1, java:1.8,macOS 1、指定scala,maven的环境变量
sudo vi ~/.bash_profile
export PATH$PATH:$M2_HOME/bin:/Users/admin/Documents/softwares/scala-2.12.17/bin2、克隆flink代码
git clone https…

Flink用户自定义连接器(Table API Connectors)学习总结
文章目录 前言背景官网文档概述元数据解析器运行时的实现 自定义扩展点工厂类Source扩展Sink和编码与解码 自定义flink-http-connectorSQL示例具体代码pom依赖HttpTableFactoryHttpTableSourceHttpSourceFunctionHttpClientUtil 最后参考资料 前言
结合官网文档和自定义实现一…
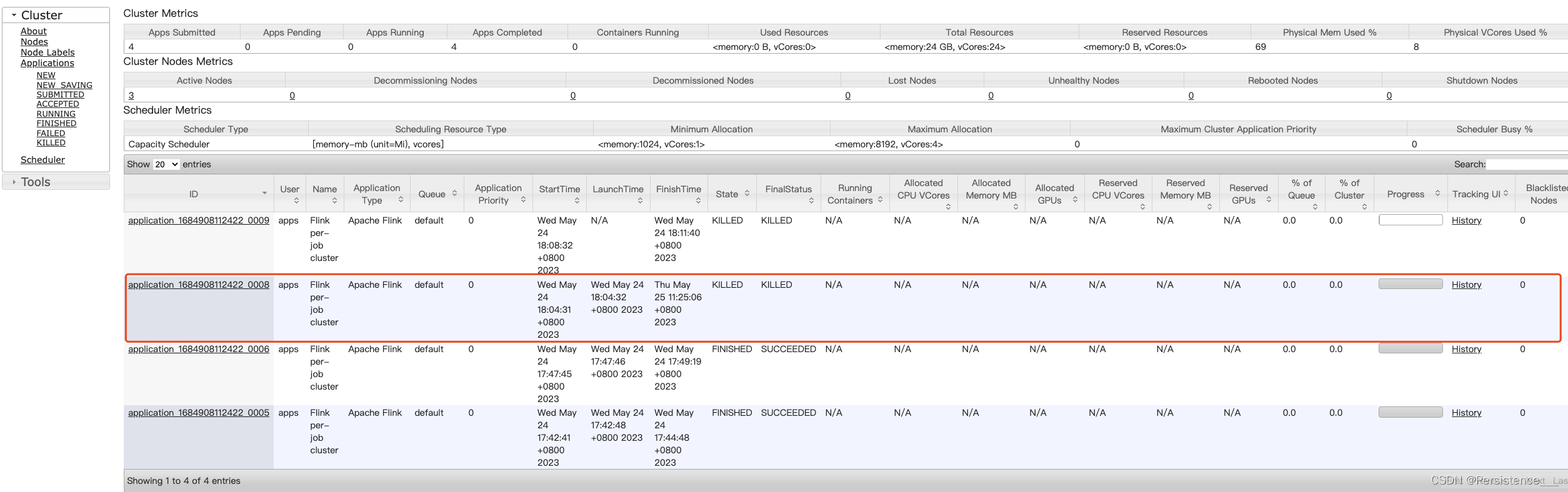
Flink+hadoop部署及Demo
Hadoop集群高可用部署
下载hadoop包地址
https://dlcdn.apache.org/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz 上传并解压到3台服务器 配置3台主机的hosts和免密登录
1.修改.bash_profile
vi .bash_profile
# HADOOP_HOME
export HADOOP_HOME/apps/svr/hadoop-3.2.…
flink写mysql报错Could not retrieve transation read-only status server
事务隔离级别前提下还是报错
SET GLOBAL tx_isolationREAD-COMMITTED; show global variables like wait timeout;
发现mysql是8小时。如果flnk超过8小时没有发送数据,invoke将会导致
mysql主动断开连接,而java侧并无感知。
解决问题,在使…
各大数据组件数据倾斜的原因和解决办法
1 背景
在处理大规模数据时,数据倾斜是一个常见的问题。数据倾斜指的是在分布式环境中处理数据时,某些节点上的任务会比其他节点更加繁重,这可能导致性能下降、资源浪费等问题。数据倾斜可能会出现在不同层次的数据处理过程中,例…
【Flink实战系列】Flink 实时计算热门商品 TopN
1,需求
每隔5分钟输出最近一小时内点击量最多的前N个商品 这是一个很常见的需求,其实跟实时的pv,uv差不多,可能会比pv,uv复杂一点,由于Flink窗口功能的强大,也让这个需求变的相对简单了,当然用Flink SQL也可以实现.
2,实现步骤 抽取出业务时间戳,告诉Flink框架基于事件时间做…
Flink的状态管理
Flink作为一种流处理框架,具备处理连续流数据的能力。在处理流数据的过程中,状态管理是非常重要的,它用于维护和跟踪数据流的中间结果和状态信息。本篇博客将介绍Flink中的状态管理机制。
1. 状态概述
状态是指在流处理过程中需要保持的数据…
Flink中aggregate[AggregateFunction]的使用及讲解
Flink的aggregate()方法一般是通过实现AggregateFunction接口对数据流进行聚合计算的场景。例如,在使用 Flink 的DataStream API时,用户经常需要对输入数据进行分组操作,并按照一组 key对数据进行汇总、运算或聚合计算。对于这些场景…
使用布隆过滤器的flink十亿级数据实时过滤实践一
1项目背景
1.1 需求
实时推荐项目需求如下:根据用户实时行为(如关注,播放,收藏)推荐该UP主(关注的up主,播放视频发布up主,收藏up主)或其相似UP主的作品,UP主及相似UP主下的作品是提前离线召回…
flink笔记3 DataStream 外部命令提交参数
1.编写代码
package org.tysf.yximport org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, createTypeInformation}object StreamWordCount {def main(args: Array[String]): Unit {//创建执行环境val env StreamExecutionEnvironment.getExecutionEnviro…
Flink中max和maxBy的区别及使用
在Flink中max算子和maxBy算子都是用来求取最大值的,下面将结合代码介绍一下它俩的相同点和不同点 相同点 都是滚动聚合都会根据代码的逻辑更新状态中记录的聚合值,并输出 不同点 max算子只会更新最大值的字段,maxBy算子会更新整条数据,下面就结合代码看和结果看一下相同点及区…
Flink中reduce算子的使用
在Flink中reduce算子可以帮助我们实现很多计算需求,如最大值、最小值、求和等等,根据实际业务需求编写相关逻辑即可,下面将结合代码看一下reduce算子如何使用. 测试数据 李淳风,男,风水大师,5000
李逵,男,健身教练,4500
袁天罡,男,风水大师,7000
张三丰,男,武术指导,6500
孙二娘…
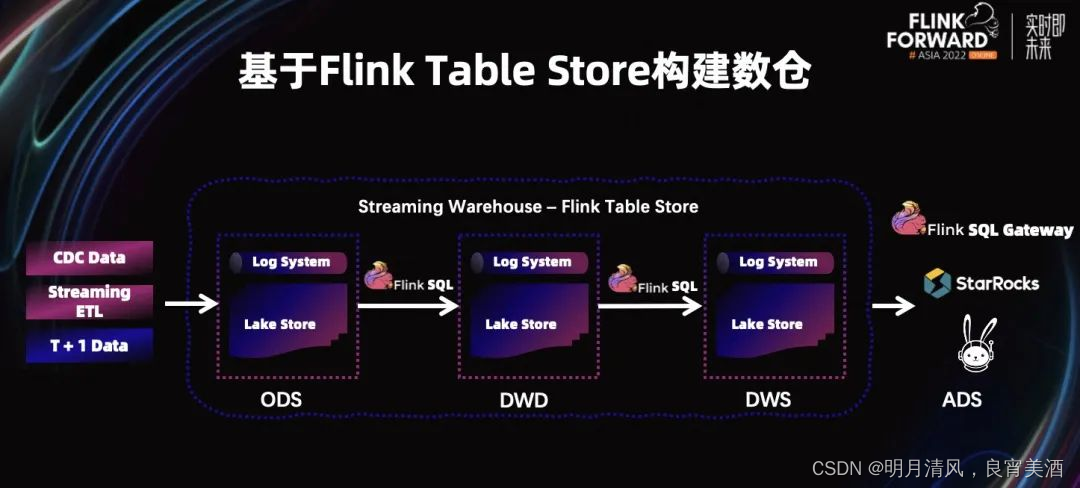
中原银行 OLAP 架构实时化演进
中原银行 OLAP 架构实时化演进 1. OLAP 实时化建设背景2. OLAP 全链路实时化3. OLAP 实时化探索4. 未来探索方向 中原银行成立于 2014 年,是河南省唯一的省级法人银行,2017 年在香港联交所主板上市,2022 年 5 月经中国银保监会批准正式吸收合…
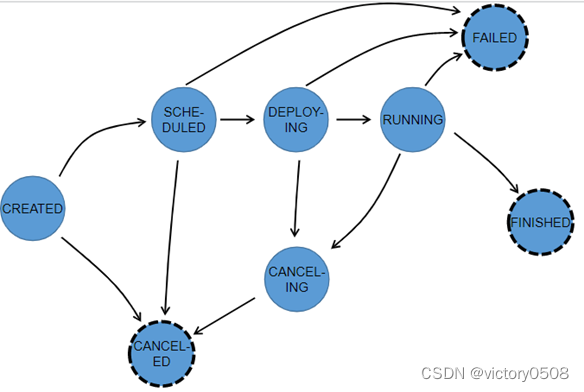
Flink流批一体计算(3):FLink作业调度
架构
所有的分布式计算引擎都需要有集群的资源管理器,例如:可以把MapReduce、Spark程序运行在YARN集群中、或者是Mesos中。Flink也是一个分布式计算引擎,要运行Flink程序,也需要一个资源管理器。而学习每一种分布式计算引擎&…
初探Flink的Java实现流处理和批处理
端午假期,夏日炎炎,温度连续40度以上,在家学习Flink相关知识,记录下来,方便备查。 开发工具:IntelliJ Idea Flink版本:1.13.0 本次主要用Flink实现批处理(DataSet API) 和…

基于Flink实时数仓——维表关联代码实现(4.2优化:异步查询)
在 Flink 流处理过程中,经常需要和外部系统进行交互,用维度表补全事实表中的字段。 例如:
在电商场景中,需要一个商品的 skuid去关联商品的一些属性,例如商品所属行业、 商品的生产厂家、生产厂家的一些情况ÿ…

基于Flink实时数仓——DWS 层与 DWM 层的设计(3.1)
设计思路 在之前通过分流等手段,把数据分拆成了独立的 Kafka Topic。那么接下来如何处 理数据,就要思考一下到底要通过实时计算出哪些指标项。 因为实时计算与离线不同,实时计算的开发和运维成本都是非常高的,要结合实际情况 考虑…
FlinkCDC中的DataStream与FlinkSQL对比、FlinkCDC与Maxwell与Canal对比
DataStream:
优点:多库多表缺点:需要自定义反序列化器(灵活)
FlinkSQL:
优点:不需要自定义反序列化器缺点:单表查询
FlinkCDCMaxwellCanalSQL与数据条数关系SQL影响几条出现几条…
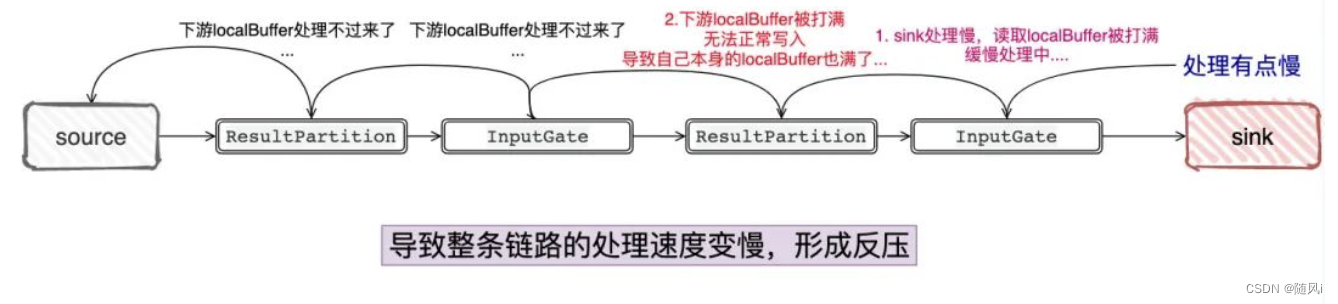
Flink基础概念及常识
1.flink入门
官方定义:Apache Flink是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算,Flink能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
简言之,Flink是一个分布式的计…

Flink / Scala 实战- 4.BroadCast 广播流数据先到再处理 Source 数据
一.引言
Flink 支持增加 DataStream KeyBy 之后 conncet BroadCastStream 形成 BroadConnectedStream,广播流内数据一般为不间断更新的上下文信息,在本例中,需要针对数据流中的用户信息,基于用于信息 + 广播流内的物料库实现推荐逻辑,针对 BroadConnectedStream 流,需要…
flink datastream api实现数据实时写入hudi
Apache Hudi(发音为“hoodie”)是下一代流数据湖平台。 Apache Hudi 将核心仓库和数据库功能直接引入数据湖。 Hudi 提供表、事务、高效的更新插入/删除、高级索引、流式摄取服务、数据集群/压缩优化和并发性,同时将您的数据保持为开源文件格…
Flink的TopN
1.为什么定时器的时间设置为,窗口的end值1ms就可以呢?
因为定时器是下游,水位线是取的多个上游的最小的, 水位线是跟在数据后面的,所以当定时器的时间到达时,上游一定计算完成了,并且数据已经在…
flink 如何分析及处理反压
在 Apache Flink 中,反压(Backpressure)是指当数据源产生的数据速度超过处理程序的处理能力时,处理程序需要向数据源发送信号来减慢数据产生的速度,以避免数据积压和系统崩溃。
Flink 提供了一些机制来分析和处理反压…
Flink Word Count Stream Demo
Flink流处理Word Count示例代码
主体代码:
public class WordCountStreamText {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env StreamExecutionEnvironment.getExecutionEnvironment();env.fromElements(WORDS).fla…
Flink Word Count Batch Demo
Flink Word Count 批处理代码样例
public class WordCountBatch {public static void main(String[] args) throws Exception {ExecutionEnvironment env ExecutionEnvironment.getExecutionEnvironment();env.readTextFile("Java/src/main/resources/flink/word_count_…
【Flink 实战系列】Flink SQL 使用 filesystem connector 同步 Kafka 数据到 HDFS(parquet 格式 + snappy 压缩)
Flink SQL 同步 Kafka 数据到 HDFS(parquet + snappy)
在上一篇文章中,我们用 datastream API 实现了从 Kafka 读取数据写到 HDFS 并且用 snappy 压缩,今天这篇文章我们来实现一个 Flink SQL 版本的,为了方便我直接采用 sql-client 提交任务的方式来演示。
添加 jar 包 …
【Flink 源码系列】Flink Collector Output 接口源码解析
0在 Flink 中 Collector 接口主要用于 operator 发送(输出)元素,Output 接口是对 Collector 接口的扩展,增加了发送 WaterMark 的功能,在 Flink 里面只要涉及到数据的传递都必须实现这两个接口,下面就来梳理…
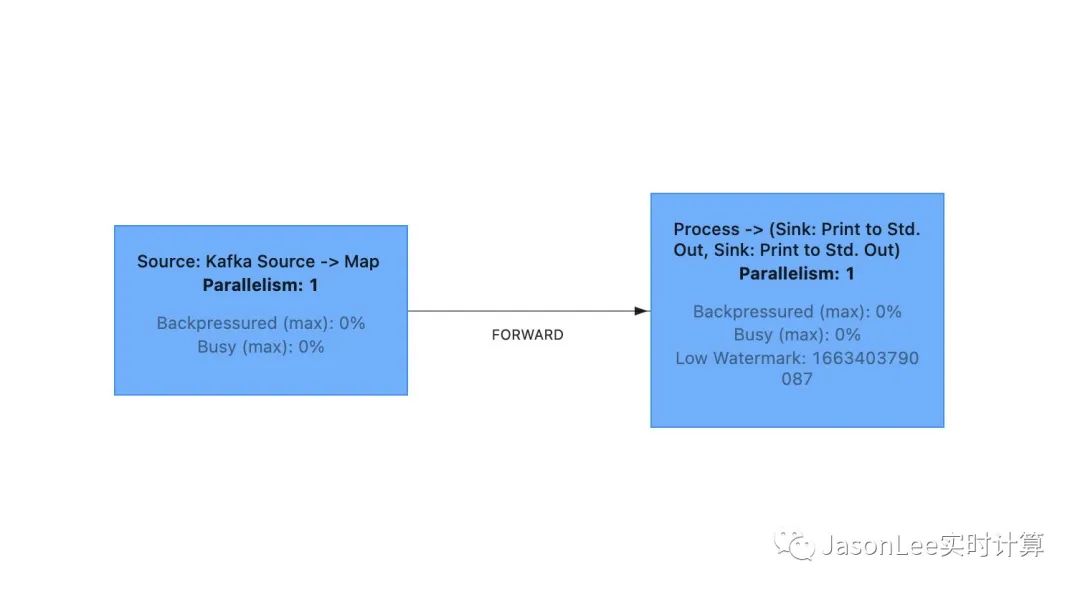
Flink Collector Output 接口源码解析
0在 Flink 中 Collector 接口主要用于 operator 发送(输出)元素,Output 接口是对 Collector 接口的扩展,增加了发送 WaterMark 的功能,在 Flink 里面只要涉及到数据的传递都必须实现这两个接口,下面就来梳理…
【Flink 监控系列】Flink 自定义 kafka metrics reporter 上报 metrics 到 kafka
Flink 自定义 kafka metrics reporter 上报 metrics 到 kafka
对于一个 Flink 任务来说,通常情况下,我们有三种方式查看 metrics: 直接在 Flink Web UI 上面查看。通过 Flink 提供的 Metric Reporters 上报到外部系统,最终在 Grafana 上面展示。通过 Flink Rest API 接口查…
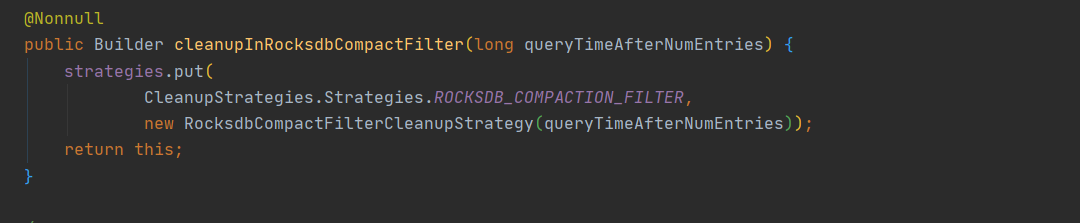
Flink-State-TTL 状态过期时间设置
为什么需要TTL
状态不需要一次存储状态有效期有时间限制,超过时间需要重置状态(业务上)
TTL设置
StateTtlConfig ttlConfig StateTtlConfig// 状态有效时间.newBuilder(Time.seconds(10))//设置状态更新类型.setUpdateType(StateTtlConfi…

Flink-KeyedState-MapState结合Window使用
文章目录(一)MapState使用步骤(二)MapState验证(三)完整DEMO(一)MapState使用步骤
映射状态(MapState<K, V>),将状态表示为一组Key-Value键…

Flink窗口-计数窗口(CountWindow)
文章目录Flink窗口-CountWindow使用(一)数量窗口的本质(二)数量窗口的使用(1)调用Window API(2)Window触发时执行计算逻辑① 匿名内部类方式② 自定义WindowFunction③ 示例演示Flin…

Flink第四章:水位线和窗口
系列文章目录
Flink第一章:环境搭建 Flink第二章:基本操作. Flink第三章:基本操作(二) Flink第四章:水位线和窗口 文章目录 系列文章目录前言一、水位线二、窗口二、实际案例1.自定义聚合函数2.全窗口函数3.水位线窗口4.统计用户点击数据5.处理迟到数据 总结 前言
这次博客记…
【Flink实战系列】Could not initialize class org.apache.hadoop.security.UserGroupInformation
java.lang.NoClassDefFoundError: Could not initialize class
背景说明
在 Flink 读取 hive 数据写到 kafka 的任务中,提交任务在客户端报错:
java.lang.NoClassDefFoundError: Could not initialize class org.apache.hadoop.security.UserGroupInformationat org.apach…
【Flink实战系列】Flink异步IO访问mysql和redis
流计算系统中经常需要与外部系统进行交互,比如需要查询外部数据库以关联上用户的额外信息。通常,我们的实现方式是向数据库发送用户a的查询请求(例如在MapFunction中),然后等待结果返回,在这之前,我们无法发送用户b的查询请求。这是一种同步访问的模式,为了提高性能阿里向…
【Flink实战系列】Flink 如何实现多个 sink 输出
在实际的生产环境中,我们的Flink任务可能需要同时写入多个存储,也就说会有多个sink,当然Flink是支持多个Sink,而且多个sink之间是并行的关系,互相也没有影响,具体的实现代码如下:
package flink.tableimport java.sql.Timestamp
import java.util.TimeZone
import flink.util.…
Flink Transformation中map、filter、flatMap算子详细介绍
本文将对Flink Transformation中各算子进行详细介绍,并使用大量例子展示具体使用方法。Transformation各算子可以对Flink数据流进行处理和转化,是Flink流处理非常核心的API。如之前文章所述,多个Transformation算子共同组成一个数据流图。
[…
Hive Spark Flink 调优
Hive(from -> on -> join -> where -> group by -> having -> select -> order by -> limit)Spark(Master,Driver,TaskManager)Flink语法优化 1. 列裁剪(只选择需要的列…
【Flink实战系列】Flink如何提交任务到远程的集群
Flink可以直接从本地提交任务到远程的集群,这样就不用每次打包上传到集群然后再启动任务,会减少很多时间,下面就来看看具体是怎么实现的? spark在本地提交到远程的yarn集群上可以看这篇文章 https://mp.weixin.qq.com/s/Rwz5uAI-TfnTBpppsMTfBg
Flink提供了远程提交的环境cr…
Flink 的状态清除演进之路
直接看我的公众号
https://mp.weixin.qq.com/s?__bizMzg3MDE0MjUzMA&mid2247483742&idx1&sn44f26e1772a2a2dd83312183fa7aef67&chksmce930673f9e48f65a2ba16f1fc31bd6e540cfc0e9203f423029fc2f0aff20459d68eaab53645&token1703187184&langzh_CN#rd
…

Flink第九章:Flink CEP
系列文章目录
Flink第一章:环境搭建 Flink第二章:基本操作. Flink第三章:基本操作(二) Flink第四章:水位线和窗口 Flink第五章:处理函数 Flink第六章:多流操作 Flink第七章:状态编程 Flink第八章:FlinkSQL Flink第九章:Flink CEP 文章目录 系列文章目录前言一、简单案例1.Logi…
零基础入门大数据之spark中rdd部分算子详解
零基础入门大数据之spark中rdd部分算子详解先前文章介绍过一些spark相关知识,本文继续补充一些基础算子,主要包括: 1. parallelize
2. aggregate
3. cache
4. cartesian
5. distinct
6. filter
7. keyBy
我们知道,spark中一…
【第2章】分析一下 Flink中的流执行模式和批执行模式
目录
1、什么是有界流、无界流
2、什么是批执行模式、流执行模式
3、怎样选择执行模式?
4、怎样配置执行模式? 1、什么是有界流、无界流
有界流: 数据流定义了开始位置和结束位置,对一个计算任务而言,在计算前所有…

非科班转行大数据开发--最详细的学习路线
大数据开发学习之路分为三个阶段
主要是根据面试重点,分成阶段性学习。 第一阶段:Java部分 Java基础、JVM、并发、数据库、缓存、设计模式、计算机网络、操作系统、Linux第二阶段:大数据框架 MapReduce、YARN、HDFS、HBase、Hive、Zookeeper…
【Flink】DataStream API使用之转换算子(Transformation)
转换算子(Transformation) 数据源读入数据之后,就是各种转换算子的操作,将一个或者多个DataSream转换为新的DataSteam,并且Flink可以针对一条流进行转换处理,也可以进行分流或者河流等多流转换操作…
Flink SQL中窗口和水印触发机制
下面是一个使用窗口的例子,按说明写入了2条数据,各个窗口的开始和结束时间规则,以及水印的使用,代码如下:
-- 第一条数据09:00:25,第二条数据09:01:10
CREATE TEMPORARY TABLE kafka_test_report (my_id V…
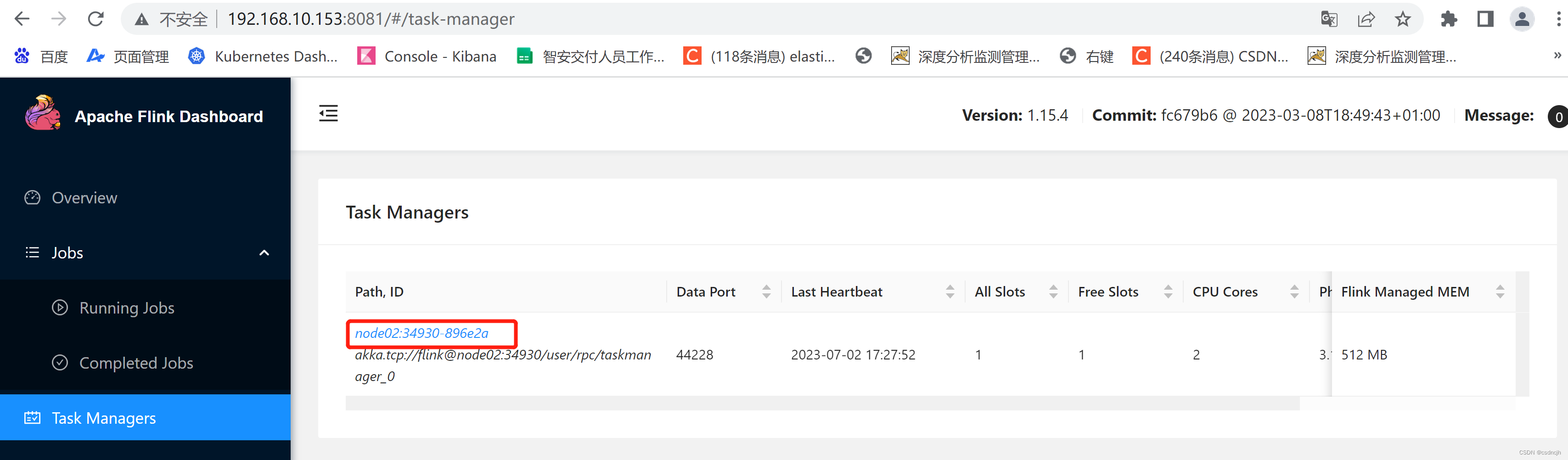
Flink集群部署总结
集群部署方式
Flink有两种部署方式,Standalone和Flink on Yarn集群部署方式。 Flink集群架构
Flink分布式架构是常见的主从结构,由JobManager和TaskManager组成。JobManager是大脑,负责接收、协调、分发Task到各个TaskManager,也…
Iceberg从入门到精通系列之十二:Flink DataStream 使用FLIP-27方式读取Iceberg表
Iceberg从入门到精通系列之十二:Flink DataStream 使用FLIP-27方式读取Iceberg表 一、读取iceberg表转化为二元组二、batch方式和streaming方式区别三、batch方式读取Iceberg表四、streaming方式读取Iceberg表 一、读取iceberg表转化为二元组
4> (6&…
![flink笔记12 [Table API和SQL] 创建表环境、创建表](https://img-blog.csdnimg.cn/20210511132257985.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzYzMTk5Nw==,size_16,color_FFFFFF,t_70)
flink笔记12 [Table API和SQL] 创建表环境、创建表
Table API和SQL(一)
1.创建表环境
2.在catalog中创建表 1.创建表环境
TableEnvironment 是 Table API 和 SQL 的核心概念。它负责:
在内部的 catalog 中注册 Table注册外部的 catalog执行 SQL 查询将 DataStream 或 DataSet 转换成 Table持有对 ExecutionEnvironment 或 St…
二十五:Flink聚合函数和累加器使用
提到了 Flink 所支持的窗口和时间类型,并且在第 25 课时中详细讲解了如何设置时间戳提取器和水印发射器。
实际的业务中,我们在使用窗口的过程中一定是基于窗口进行的聚合计算。例如,计算窗口内的 UV、PV 等,那么 Flink 支持哪些基于窗口的聚合函数?累加器又该如何实现呢…
⑦Flink窗口、时间和水印
我们在之前的课时中反复提到过窗口和时间的概念,Flink 框架中支持事件时间、摄入时间和处理时间三种。而当我们在流式计算环境中数据从 Source 产生,再到转换和输出,这个过程由于网络和反压的原因会导致消息乱序。因此,需要有一个机制来解决这个问题,这个特别的机制就是“…
flink笔记11 Flink Table API和SQL的简单实例
Apache Flink有两个关系应用编程接口——the Table API and SQL ,用于统一的流和批处理
The Table API and SQL 相互无缝集成,与Flink的DataStream API无缝集成
1.Table API & SQL简介
Table API是流处理和批处理通用的关系型API,Tabl…

快手 Flink 的稳定性和功能性扩展
摘要:本文整理自快手技术专家刘建刚,在 Flink Forward Asia 2022 生产实践专场的分享。本篇内容主要分为四个部分: 1. 快手 Flink 平台 2. 稳定性保障和智能运维 3. 复杂场景下的功能扩展 4. 批处理的定制优化 Tips:点击「阅读原文…

flink笔记4 flink在local模式下两种提交job的方法
目录
1.网页
1.1自己的流处理程序
1.2将自己的程序打包
1.3开启虚拟机,启动flink
1.4网页提交jar
2.命令行
2.1启动flink 同上
2.2提交job
2.3取消job 1.网页
1.1自己的流处理程序
import org.apache.flink.api.java.utils.ParameterTool
import org.…
flink笔记1 使用Scala实现WordCount程序(批处理和流处理)
WordCount程序 1.批处理(DataSet API)实现
1.1代码讲解
1.2附完整代码
2.流处理实现
2.1代码讲解
2.2附完整代码 1.批处理(DataSet API)实现
1.1代码讲解
1.创建执行环境(Obtain an execution environment)
val env ExecutionEnvironment.getEx…
【Flink学习】flink-training浅析
文章目录官网练习数据集说明Schema of Taxi Ride Events 乘坐出租车事件的结构项目工程commonride-cleansingRideCleansingSolutionhourly-tipsHourlyTipsSolutionrides-and-faresRidesAndFaresSolutionlong-ride-alertsLongRidesSolution官网练习
数据集说明
纽约市出租车和…

【Flink学习】入门教程之DataStream API 简介
文章目录DataStream API 简介Java tuples 和 POJOsTuplesPOJOsScala tuples 和 case classes一个完整的示例Stream execution environment 流执行环境Basic stream sources 基本的 stream sourceBasic stream sinks 基本的 stream sinkDebuggingHands-on 实践DataStream API 简…

Flink自主内存管理——JVM堆上内存和堆外内存的问题
系列文章目录 文章目录系列文章目录前言一、JVM内存管理在大数据场景下的问题1.有效数据密度低2.垃圾回收1.OOM问题影响稳定性1.缓存未命中问题二、自主内存管理堆上内存的问题堆外内存的不足之处前言 Java语言的好处是不用考虑底层,JVM可以对代码进行深度优化&…

基于Flink实时数仓——DWS层-关键词主题表FlinkSQL(9)
需求分析与思路:
关键词主题这个主要是为了大屏展示中的字符云的展示效果,用于感性的让大屏观看者感知目前的用户都更关心的那些商品和关键词。 关键词的展示也是一种维度聚合的结果,根据聚合的大小来决定关键词的大小。 关键词的第一重要来…
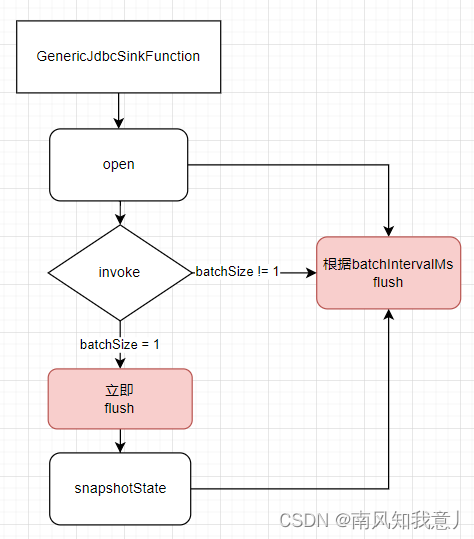
Flink JdbcSink.sink源码解析及常见问题
文章目录 源码入口我们看下flush方法干了什么flush方法至此走完了,但是什么时机写入的数据呐?补充总结: 常见问题1. 为什么会出现JdbcSink.sink方法插入Mysql无数据的情况?2. JdbcSink.sink写Phoenix无数据问题 参考 基于Flink 1.…
大数据--spark生态5--sparkStreaming
目录
一:流数据特征
二:流数据的数据价值
三:流计算系统的标准
四:流处理系统与传统的数据处理系统区别
五:数据处理分类
六:streaming的特点
七:DStream转换
八:Flink优势 …
Flink / Scala - 9.DataStream Broadcast State 模式示例详解
一.引言
上一篇文章 Flink / Scala - DataSet 应用 Broadcast Variables 介绍了 DataSet 场景下 Broadcast 的使用,本文将介绍 DataStream 中的 Broadcast 应用场景,与 DataSet 类似,Broadcast 的值是所有 task 公用的,Broadcast State 是为 DataStreaming 所有 task 定制…
Flink / Scala - 8.DataSet 应用 Broadcast Variables
一.引言
除了操作的常规输入之外,广播变量 Broadcast Value 允许使一个数据集对操作的所有并行实例可用,即适合 task 都需要公用的变量,就像是 spark 中各个 executor 都需要访问的公共变量一样。这对于辅助数据集或依赖于数据的参数化非常有用。然后,该数据集将作为一个集…
Flink / Scala - 3.DataSource 之 DataStream 获取数据总结
一.引言
DataStream API 得名于特殊的 DataStream 类,该类用于表示 Flink 程序中的数据集合。你可以认为 它们是可以包含重复项的不可变数据集合。这些数据可以是有界(有限)的,也可以是无界(无限)的,但用于处理它们的API是相同的。
DataStream 在用法上类似于常规的 J…

Flink / Scala - 7.DataSet DataStream Sink 输出数据详解
一.引言
Flink 的数据处理主要分三步,第一步 Source 为数据源,分为 DataSet 和 DataStreaming ,后一步为 Transformation 负责处理和转换数据,针对不同的 DataSource,Transformation 可能会存在差异,最后一步是 sink 负责将结果输出。前面介绍了 DataSet 的 Source 和 T…
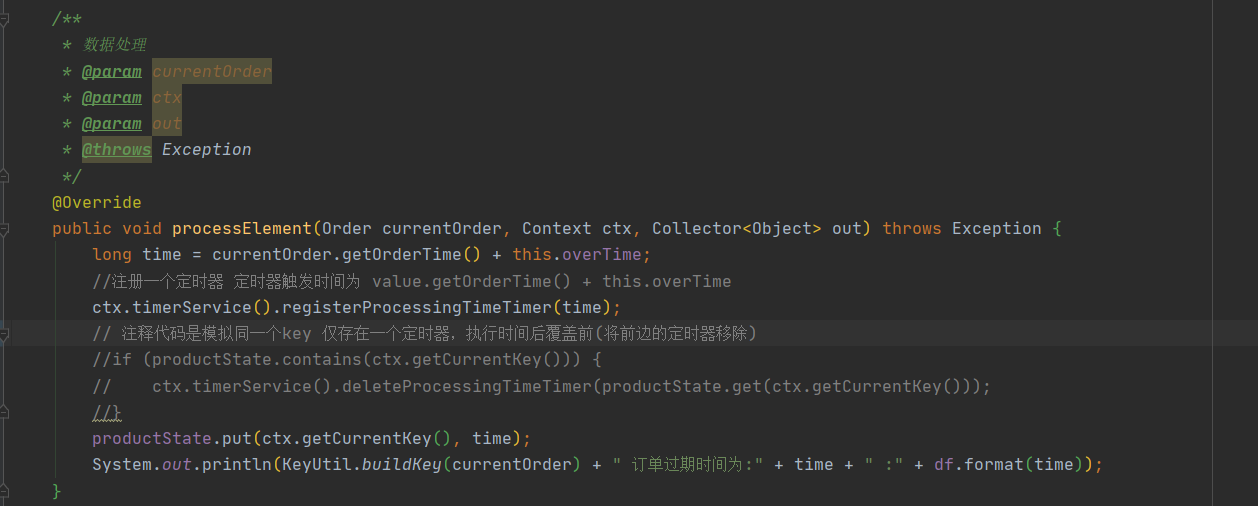
Flink程序 Timer实现定时操作
Flink程序中 Timer实现定时操作
有时候,我们在计算任务中需要使用到定时器来帮助我们处理业务,例如 订单的自动结算?自动好评? 定时收集?等等…
但需要注意的 我们无法为计算任务灵活的配置CRON表达式,仅仅只能指定触发的时刻。…
Flink本地开发(例如在IDEA/Eclipse中)模式启动WEB-UI
文章目录前言一、添加依赖二、代码中启用本地WEB-UI三、IDEA运行Flink JOB;本地WEB-UI查看查看Task详情注意点:前言
我们在IDE中编写Flink代码,我们希望在IEDA中运行程序便能够查看到Web-UI,从而快速的了解Flink程序的运行情况&a…

Flink TaskSlot与并行度
文章目录一、Flink的Task、SubTask二、算子链三、什么情况下算子可以组合为算子链?四、算子链操作五、并行度六、TaskSlot与并行度的联系七、槽位共享八、并行度设置注意事项九、并行度设置十、并行度优先级十一、并行度Parallelism与任务槽TaskSlot总结十二、Local…

Flink JobManger、TaskManger、TaskSlots、Client作用
文章目录JobMangerTaskManagerTaskSlotsClient上图,是我们Flink-WEB-UI 一部分截图
Flink 系统主要由两个组件组成,分别为 JobManager 和 TaskManager,Flink 架构遵循了 Master - Slave 架构设计原则,JobManager 为 Master 节点&…
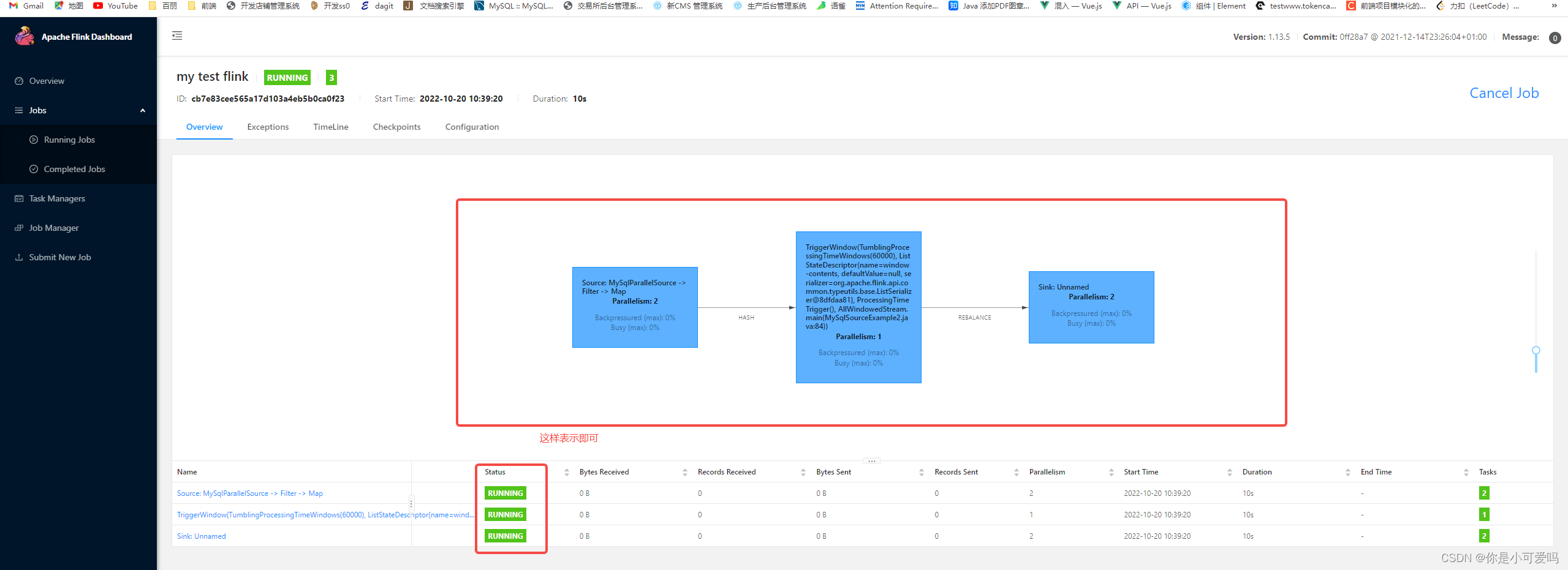
Java 实现mysql 同步 flink cdc 做数据收集 demo
**
准备环境
**
java 8mysqlflink1.3.5flink cdc 2.2.1
数据库 创建 2张测试表格 student、和 student1
CREATE TABLE student (id int(11) NOT NULL AUTO_INCREMENT,name varchar(25) COLLATE utf8mb4_bin NOT NULL,age int(4) NOT NULL,ctime datetime DEFAULT NULL,mti…

flink笔记14 动态表(Dynamic Tables)
动态表 概念
在流上定义表
连续查询
更新和追加查询
表到流的转换 概念
动态表 是 Flink 的支持流数据的 Table API 和 SQL 的核心概念。
与表示批处理数据的静态表不同,动态表是随时间变化的。可以像查询静态批处理表一样查询它们。查询动态表将生成一个连续…
![flink笔记10 [实验]体验ProcessingTime和指定EventTime下的区别](https://img-blog.csdnimg.cn/20210526171822408.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzYzMTk5Nw==,size_16,color_FFFFFF,t_70)
flink笔记10 [实验]体验ProcessingTime和指定EventTime下的区别
体验ProcessingTime和指定EventTime下的区别 实验数据
实验代码
实验结果
实验分析 实验数据
sensor_1,1619492107,36.2
sensor_1,1619492108,36.0
sensor_1,1619492109,36.5
sensor_1,1619492110,34.3
sensor_1,1619492111,34.3
sensor_1,1619492112,34.3
sensor_1,161949…
![flink笔记13 [Table API和SQL] 查询表、输出表、查看执行计划](https://img-blog.csdnimg.cn/20210513153817608.png)
flink笔记13 [Table API和SQL] 查询表、输出表、查看执行计划
查询表、输出表、查看执行计划 1.查询表
2.输出表
3.查看执行计划 1.查询表
Flink给我们提供了两种查询方式:Table API和 Flink SQL
查询表具体操作有很多,可以参考官方文档:Table API & SQL
完整实例:
(1)Table API查询…

如何读取,写入和修改 Flink 应用程序的状态
如何读取,写入和修改 Flink 应用程序的状态
本文主要介绍 Flink 的状态管理,非常实用。
过去无论是在生产中使用,还是调研 Apache Flink,总会遇到一个问题:如何访问和更新 Flink 保存点(savepoint&#x…
Flink DataStream之从集合/文件读数据
从集合中读数据方式一
package test01;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.…
大数据开发实战系列之Spark电商平台
源于企业级电商网站的大数据统计分析平台,该平台以 Spark 框架为核心,对电商网站的日志进行离线和实时分析。
该大数据分析平台对电商网站的各种用户行为(访问行为、购物行为、广告点击行为等)进行分析,根据平台统计出…

20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

Flink源码之JobManager启动流程
从启动命令flink-daemon.sh中可以看出StandaloneSession入口类为org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint, 从该类的main方法会进入ClusterEntrypoint::runCluster中, 该方法中会创建出主要服务和组件。
StandaloneSessionClusterEntrypoint:…
Flink-间隔联结
间隔联结只支持事件时间间隔联结如果遇到迟到数据,则会关联不上,比如来了一个5秒的数据,它可以关联前2秒的数据,后3秒的数据,就是可以关联3秒到8秒的数据,然后又来了一个6秒的数据,可以关联4秒到…
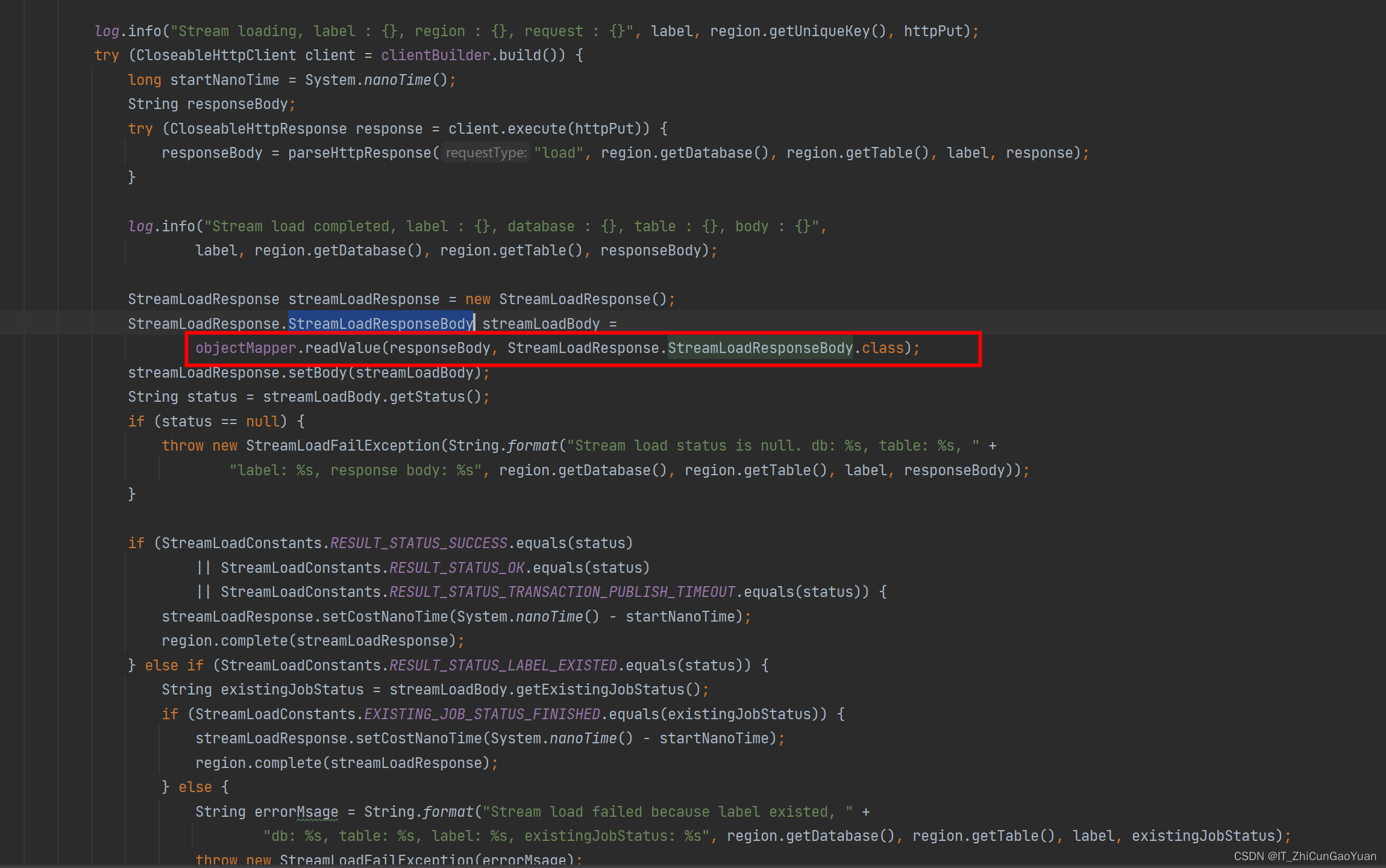
flinksql sink to sr often fail because of nullpoint
flinksql or DS sink to starrocks often fail because of nullpoint flink sql 和 flink ds sink starrocks 经常报NullpointException重新编译代码 并上传到flink 集群 验证,有效 flink sql 和 flink ds sink starrocks 经常报NullpointException
使用flink-sta…

【大数据】Flink 详解(二):核心篇 Ⅱ
Flink 详解(二):核心篇 Ⅱ 22、刚才提到 State,那你简单说一下什么是 State。 在 Flink 中,状态 被称作 state,是用来保存中间的计算结果或者缓存数据。根据状态是否需要保存中间结果,分为 无状…
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

Flink-Window详细讲解-countWindow
一.countWindow和countWindowall区别
1.countWindow:
如果您使用 countWindow(5),这意味着您将数据流划分成多个大小为 5 的窗口。划分后的窗口如下:
窗口 1: [1, 2, 3, 4, 5]窗口 2: [6, 7, 8, 9, 10]
当每个窗口中的元素数量达到 5 时&…
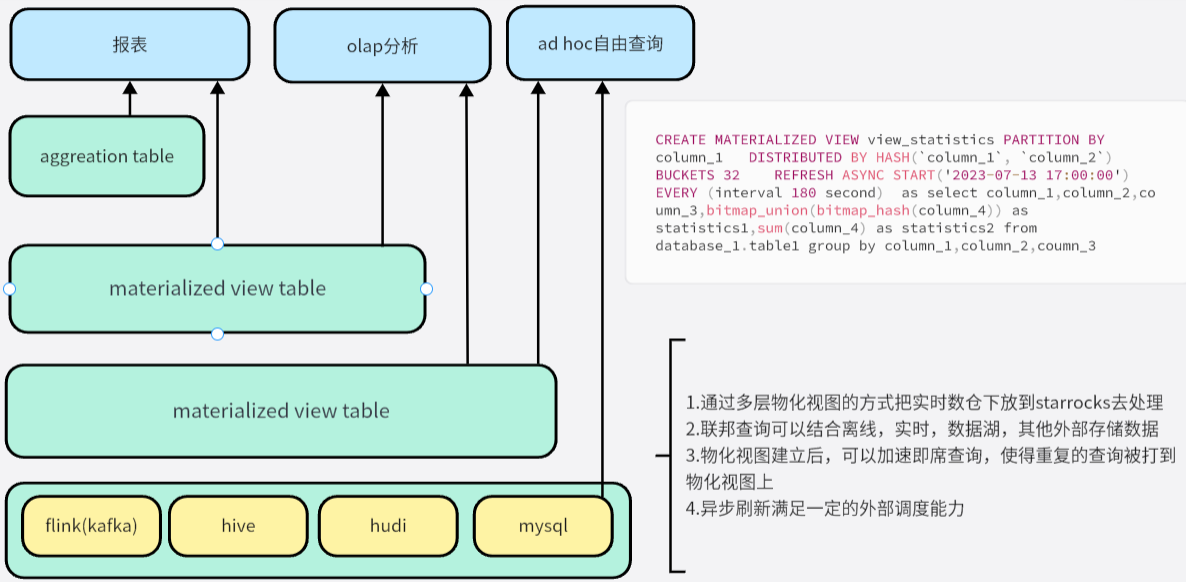
芒果 TV 基于 Flink 的实时数仓建设实践
公司简介:芒果 TV 作为湖南广电旗下互联网视频平台,在“一云多屏,多元一体”的战略指导下,通过内容自制,培植核心竞争力,从独播、独特走向独创,并通过市场化运作完成 A 轮、B 轮融资,…

Flink窗口分类简介及示例代码
水善利万物而不争,处众人之所恶,故几于道💦 文章目录 1. 流式计算2. 窗口3. 窗口的分类◆ 基于时间的窗口(时间驱动)1) 滚动窗口(Tumbling Windows)2) 滑动窗口(Sliding Windows&…
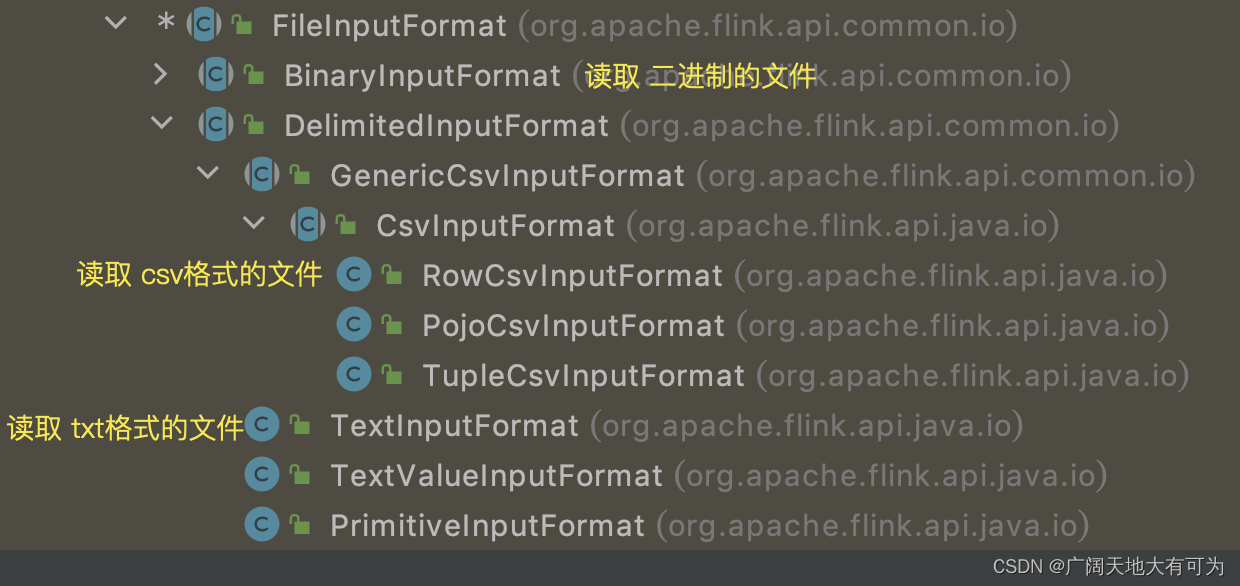
4.2、Flink任务怎样读取文件中的数据
目录
1、前言
2、readTextFile(已过时,不推荐使用)
3、readFile(已过时,不推荐使用)
4、fromSource(FileSource) 推荐使用 1、前言
思考: 读取文件时可以设置哪些规则呢? 1. 文件的格式(tx…
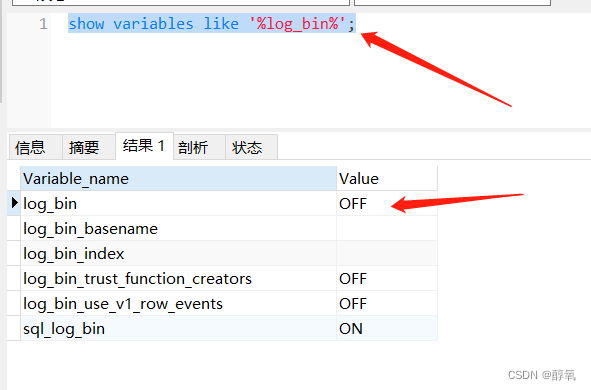
【flinkCDC】Cannot read the binlog filename and position via ‘SHOW MASTER STATUS‘
执行flinkCDC同步时候报错了: 2023-08-10 14:50:48
java.lang.RuntimeException: One or more fetchers have encountered exceptionat org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:261)at o…

OceanBase X Flink 基于原生分布式数据库构建实时计算解决方案
摘要:本文整理自 OceanBase 架构师周跃跃,在 Flink Forward Asia 2022 实时湖仓专场的分享。本篇内容主要分为四个部分: 分布式数据库 OceanBase 关键技术解读 生态对接以及典型应用场景 OceanBase X Flink 在游戏行业实践 未来展望 点击…
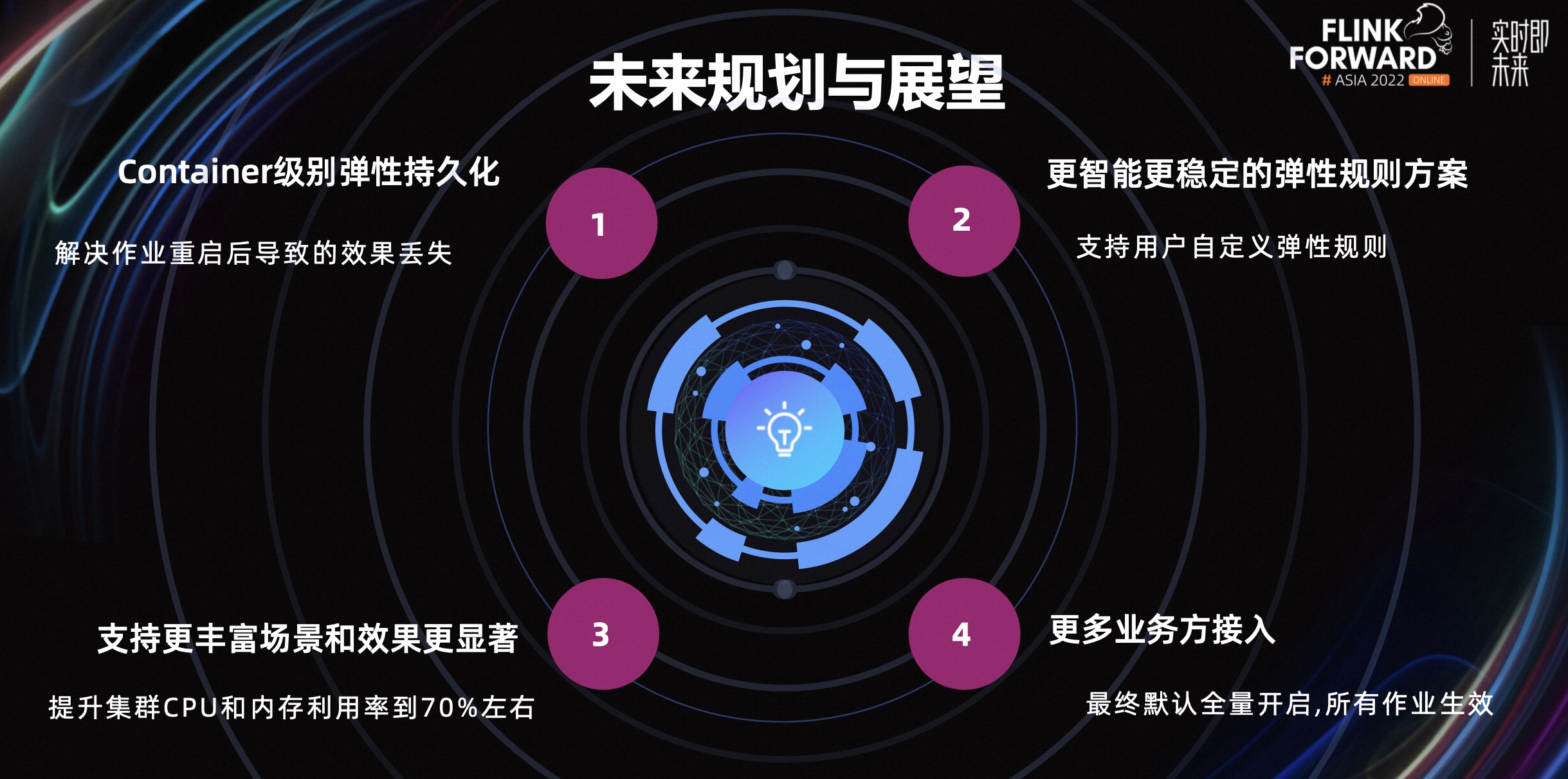
小米基于 Flink 的实时计算资源治理实践
摘要:本文整理自小米高级软件工程师张蛟,在 Flink Forward Asia 2022 生产实践专场的分享。本篇内容主要分为四个部分: 发展现状与规模框架层治理实践平台层治理实践未来规划与展望 点击查看原文视频 & 演讲PPT 一、发展现状与规模 如上图…
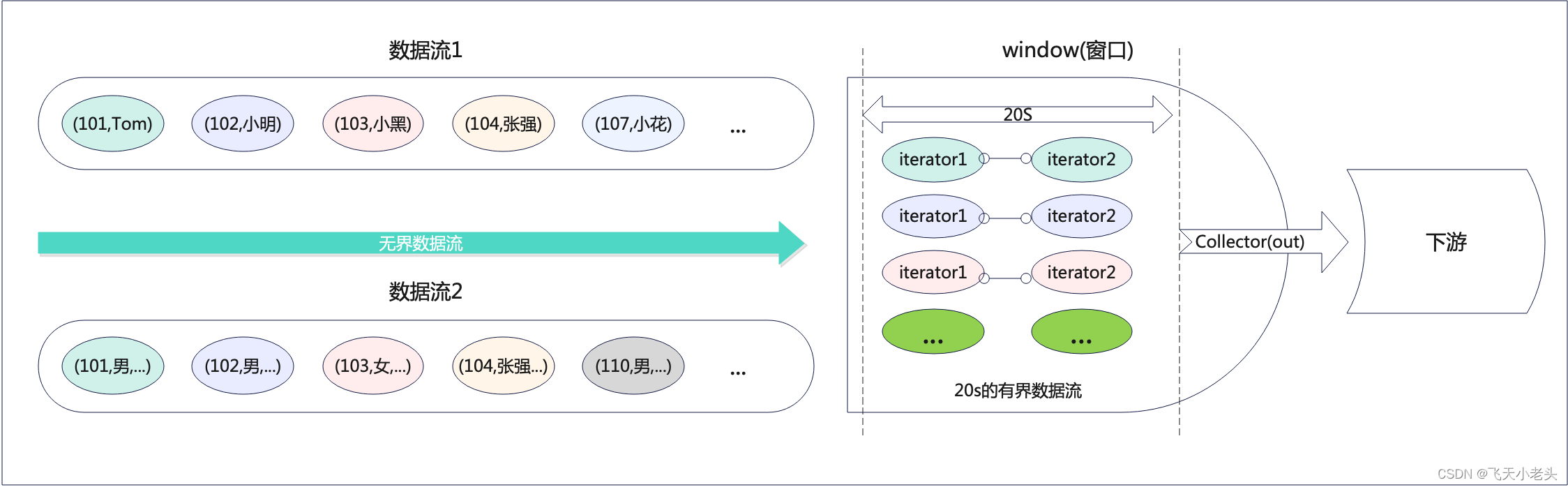
Flink多流处理之coGroup(协同分组)
这篇文章主要介绍协同分组coGroup的使用,先讲解API代码模板,后面会结图解介绍coGroup是如何将流中数据进行分组的.
1 API介绍
数据源# 左流数据
➜ ~ nc -lk 6666
101,Tom
102,小明
103,小黑
104,张强
105,Ken
106,GG小日子
107,小花
108,赵宣艺
109,明亮# 右流数据
➜ ~ n…
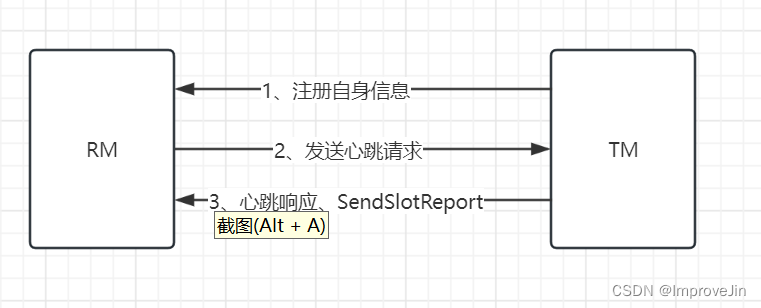
Flink源码之TaskManager启动流程
从启动命令flink-daemon.sh可以看出TaskManger入口类为org.apache.flink.runtime.taskexecutor.TaskManagerRunner
TaskManagerRunner::main
TaskManagerRunner::runTaskManagerProcessSecurely
TaskManagerRunner::runTaskManager //构造TaskManagerRunner并调用start()方法
…

史上最全Flink面试题,高薪必备,大数据面试宝典
说在前面
本文《尼恩 大数据 面试宝典》 是 《尼恩Java面试宝典》姊妹篇。
这里特别说明一下:《尼恩Java面试宝典》41个专题 PDF 自首次发布以来, 已经汇集了 好几千题,大量的大厂面试干货、正货 ,足足4800多页,帮助…

SparkStreaming,Flink,Storm三大实时框架对比分析
对比分析
如果对延迟要求不高的情况下,建议使用Spark Streaming,丰富的高级API,使用简单,天然对接Spark生态栈中的其他组件,吞吐量大,部署简单,UI界面也做的更加智能,社区活跃度较高…
具备哪些条件学习大数据开发更容易?
1. 数学知识
数学知识是数据分析师的基础知识。
对于初级数据分析师,了解一些描述统计相关的基础内容,有一定的公式计算能力即可,了解常用统计模型算法则是加分。
对于高级数据分析师,统计模型相关知识是必备能力,线…
日均百亿级日志处理:微博基于Flink的实时计算平台建设
本文作者简介
吕永卫,微博广告资深数据开发工程师,实时数据项目组负责人。
黄鹏,微博广告实时数据开发工程师,负责法拉第实验平台数据开发、实时数据关联平台、实时算法特征数据计算、实时数据仓库、实时数据清洗组件开发工作。…
flink1.15 regular join之left join 测试代码
目的: 通过测试代码查看join的效果
package com.yy.flinkSqlJoinimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.{Schema, Table, TableResult}
import org.apache.flink.table.api.bridge.scala.StreamTableEnv…

Flink / Scala - 4.DataSet Transformations 常用转换函数详解
一.引言
上一篇文章讲到了 Flink 如何获取数据生成 DataSet,这篇文章主要讨论 DataSet 后续支持的 Transform 转换函数。相较于 Spark,Flink 提供了更多的 API 和更灵活的写法与实现。 Tips :
下述示例均以该 env 为基础实现 import org.apache.flink.api.scala.Execution…

Flink 常考面试题
这里写目录标题Flink 与 Storm 的对比WaterMark 的理解主要作用是:用来解决乱序,延迟事件。因为对于 late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发 window 去进行计算了。这…
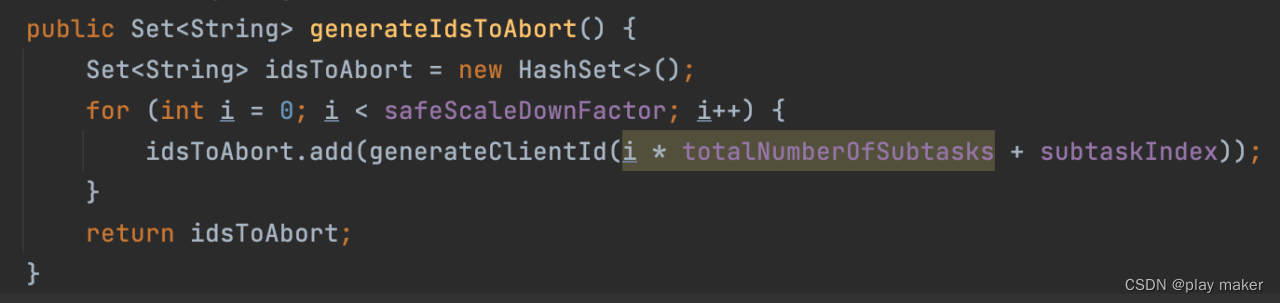
Flink+Pulsar、Kafka问题分析及方案 -- 事务阻塞
Pulsar、Kafka的事务设计
Pulsar跟Kafka在设计事务功能时,在消费者读取消息的顺序方面,都采用了类似的设计。 比如说,先创建txn1,然后创建txn2,这两个事务生产消息到同一个topic/partition里,但是txn2比tx…

flink无法消费kafka消息的一次问题记录
flink无法消费kafka的消息,本地开发时也没有错误信息打印,后来排查到注掉addsink()后就可以消费到消息; 继续排查发现是写入hbase的配置中,由于地址无法连通导致的。
简单批处理、流处理【Flink学习笔记一】
目录
Flink 处理数据的流程:
环境准备
目的:
批处理
流处理 Flink 处理数据的流程:
1、获取执行环境;
2、加载/创建初始数据;
3、指定数据相关的转换;
4、指定计算结果的存储位置;
5、触发…

Flink 六脉神剑秘诀
Flink是什么?
Flink是一款实时计算框架,能够实现ms级别甚至更低的延时计算(流式处理 -- 有状态的计算处理),不少同学肯定会提及spark streaming(可认为是批处理,类似Hive -- 无状态计算;这几个框架只能做…

大数据之路--Flink学习
Flink这块学习资料比较少,近期都在学习中,之后完善做一个总结,希望对自己和大家的学习有帮助,错误或者不足支持,恳请批评指正,谢谢!
计算框架
目前在学习大数据这块,随着计算成本的…

Flink内核源码(八)Flink Checkpoint
Flink中Checkpoint是使Flink 能从故障恢复的一种内部机制。检查点是 Flink 应用状态的一个一致性副本,在发生故障时,Flink 通过从检查点加载应用程序状态来恢复。
核心思想:是在 input source 端插入 barrier,控制 barrier 的同步…

Flink事件时间处理和水印
最近找到这个对事件时间处理和水印说的比较好的文章,所以转载一下,供大家分享,原文连接:https://blog.csdn.net/a6822342/article/details/78064815 http://vishnuviswanath.com/flink_eventtime.html 本文用途纯粹是为了分享…
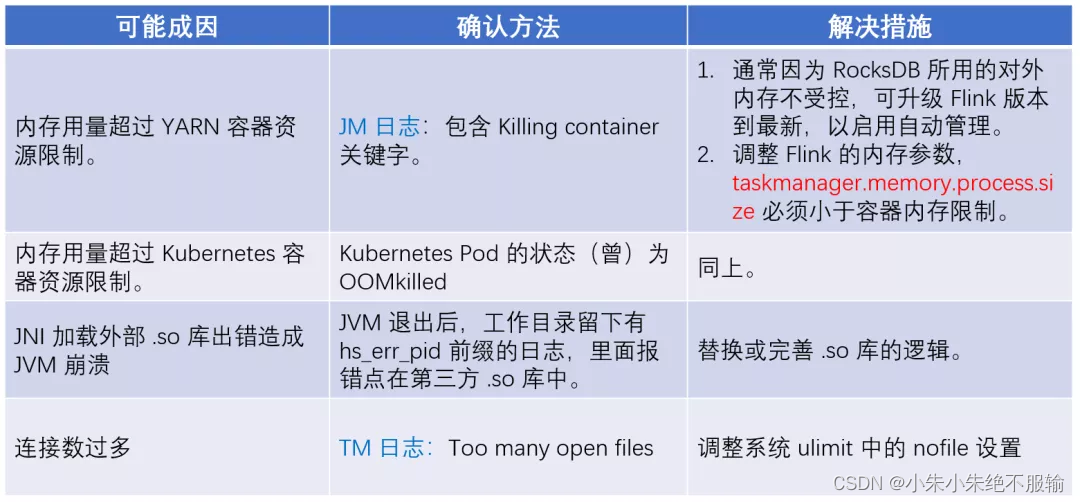
Flink生产环境经典问题汇总
Flink生产环境中遇到的各种问题的汇总。 文章目录1. 如何规划生产中的集群大小?2. Flink CheckPoint问题如何排查?3. 反压问题如何排查?4. 客户端常见问题4.1 应用提交控制台异常信息4.2 用户应用和框架 JAR 包版本冲突问题4.3 Flink 应用资源…
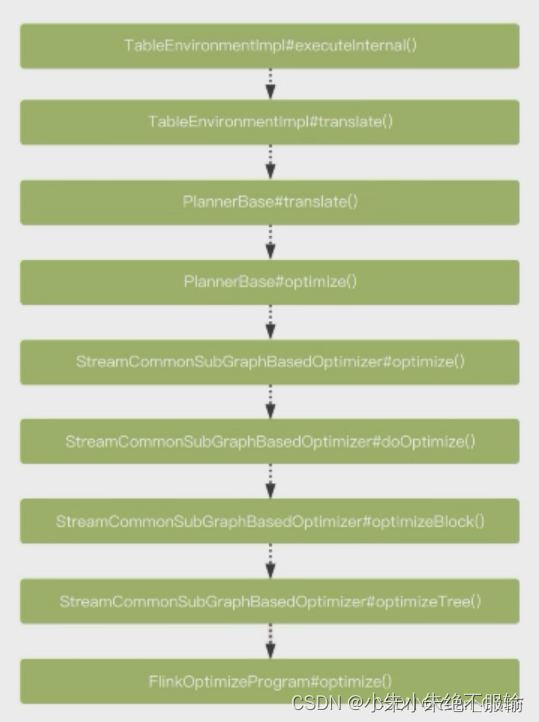
Flink内核源码(七)Flink SQL提交流程
第七章就来学习一下Flink SQL的解析提交流程。
问题整理:
1. Flink中的Calcite是什么? 2. Flink SQL的提交流程是怎样的?
1. Calcite
Apache Calcite是一个动态数据管理框架 ,它具备很多典型数据库管理系统的功能,…


Flink筛选重要配置参数
1.简单介绍一下flink背景
随着科技的发展,大数据框架处理海量数据越来越流行。有状态流计算将会逐步成为企业作为构建数据平台的架构模式,而目前从社区来看,能够满足的只有Apache Flink。Flink通过实现Goolge Dataflow流式计算模型实现了高吞…
hibench运行flink程序第三步run.sh出错(提交job失败)
在hibench上运行flink程序,提交job失败
hibench上做flink实验时,在新的服务器上重新配置环境后,在成功运行Hibench的前两步genSeedDataset.sh和dataGen.sh后,运行run.sh,正常提交,但生成metrics全部为0。 分析原因&am…

kafka自动清理日志
Kafka日志的清除
Kafka将消息存储在磁盘里,随着程序的运行,Kafka会产生大量的消息日志,进而占据大部分磁盘空间,当磁盘空间满时还会导致Kafka自动宕机,因此Kafka的日志删除是非常有必要的。
1. Kafka的日志清除策略 …

Flink--window数据倾斜
1.window数据倾斜
对于集群系统,一般缓存是分布式的,即不同节点负责一定范围的缓存数据。我们把缓存数据分散度不够,导致大量的缓存数据集中到了一台或几台服务节点上,称为数据倾斜。一般来说,数据倾斜是由于负载均衡…

kafka自动宕机原因分析和解决
Kafka自动宕机问题
本博客主要解决的是在运行flink程序时,Kafka在启动几秒后出现自动宕机的问题,从运行程序的情况下,主要有两个方面的问题和解决措施。
1.log日志所在内存满
在运行flink程序时,Kafka产生数据会生成两个日志目…
flink在Hibench下的配置和运行
Hibench简单介绍
HiBench是一个大数据基准套件,它在速度、吞吐量和系统资源利用率方面帮助评估不同的大数据框架。它包含一组Hadoop、Spark和流工作负载,包括Sort, WordCount, TeraSort, Sleep, SQL, PageRank, Nutch indexing, Bayes, Kmeans, NWeight…

Kafka 消息过期策略(时间相关参数)
Kafka 消息过期策略(时间相关参数) 标记delete时效 (CDH配置项)log.retention.ms (Kafka offset配置)retention.ms
标记delete的真删底层文件 delete.delay.ms log.segmetn.delete
背景:在不需要重启kafka的情况下&a…

flink sql常用函数
1. flink sql 时间函数 时间戳单位为秒 timeintervalunit时间单位:SECOND,MINUTE,HOUR,DAY,WEEK,MONTH,QUARTER,或YEAR。select REPLACE(hello world, world, flink) returns "…
大数据-玩转数据-Flink App市场推广统计
一、说明
电商网站中已经有越来越多的用户来自移动端,相比起传统浏览器的登录方式,手机APP成为了更多用户访问电商网站的首选。对于电商企业来说,一般会通过各种不同的渠道对自己的APP进行市场推广,而这些渠道的统计数据…
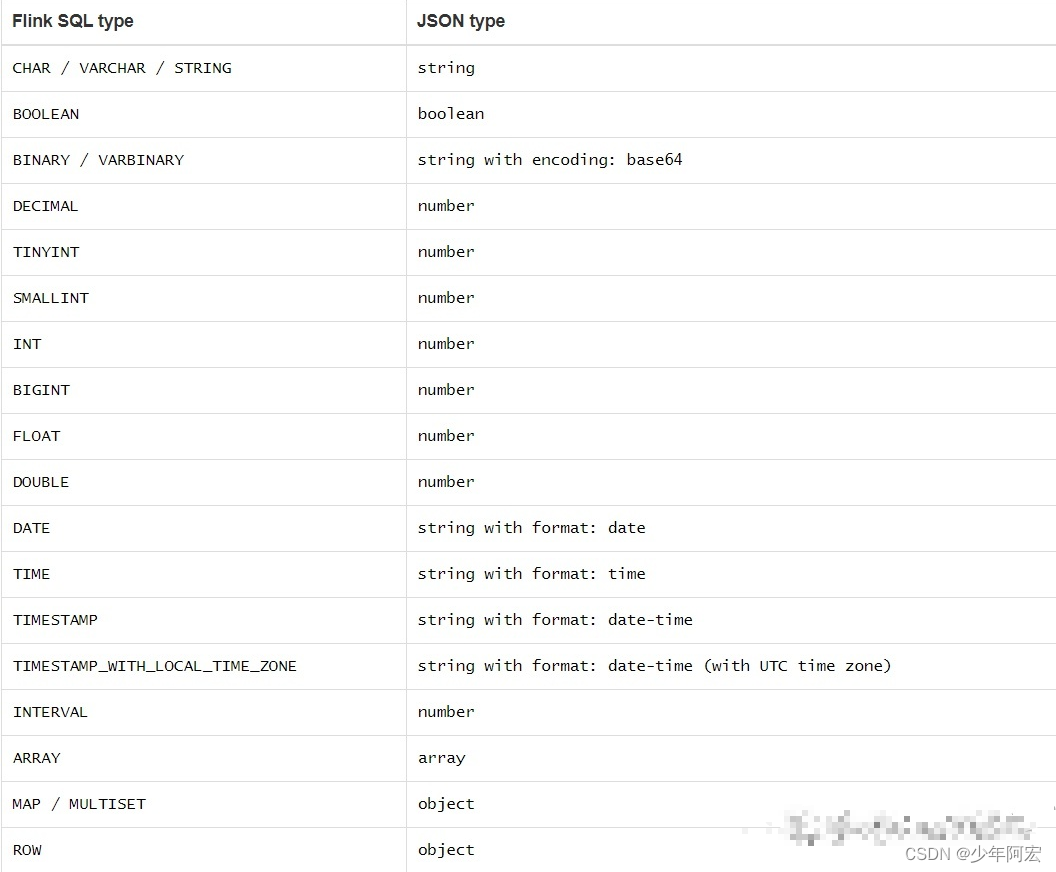
flink sql checkpoint 调优配置
- execution.checkpointing.interval: 检查点之间的时间间隔(以毫秒为单位)。在此间隔内,系统将生成新的检查点
SET execution.checkpointing.interval 6000;
- execution.checkpointing.tolerable-failed-checkpoints: 允许的连续失败检查…

记录几个Hudi Flink使用问题及解决方法
前言
如题,记录几个Hudi Flink使用问题,学习和使用Hudi Flink有一段时间,虽然目前用的还不够深入,但是目前也遇到了几个问题,现在将遇到的这几个问题以及解决方式记录一下
版本
Flink 1.15.4Hudi 0.13.0
流写
流写…
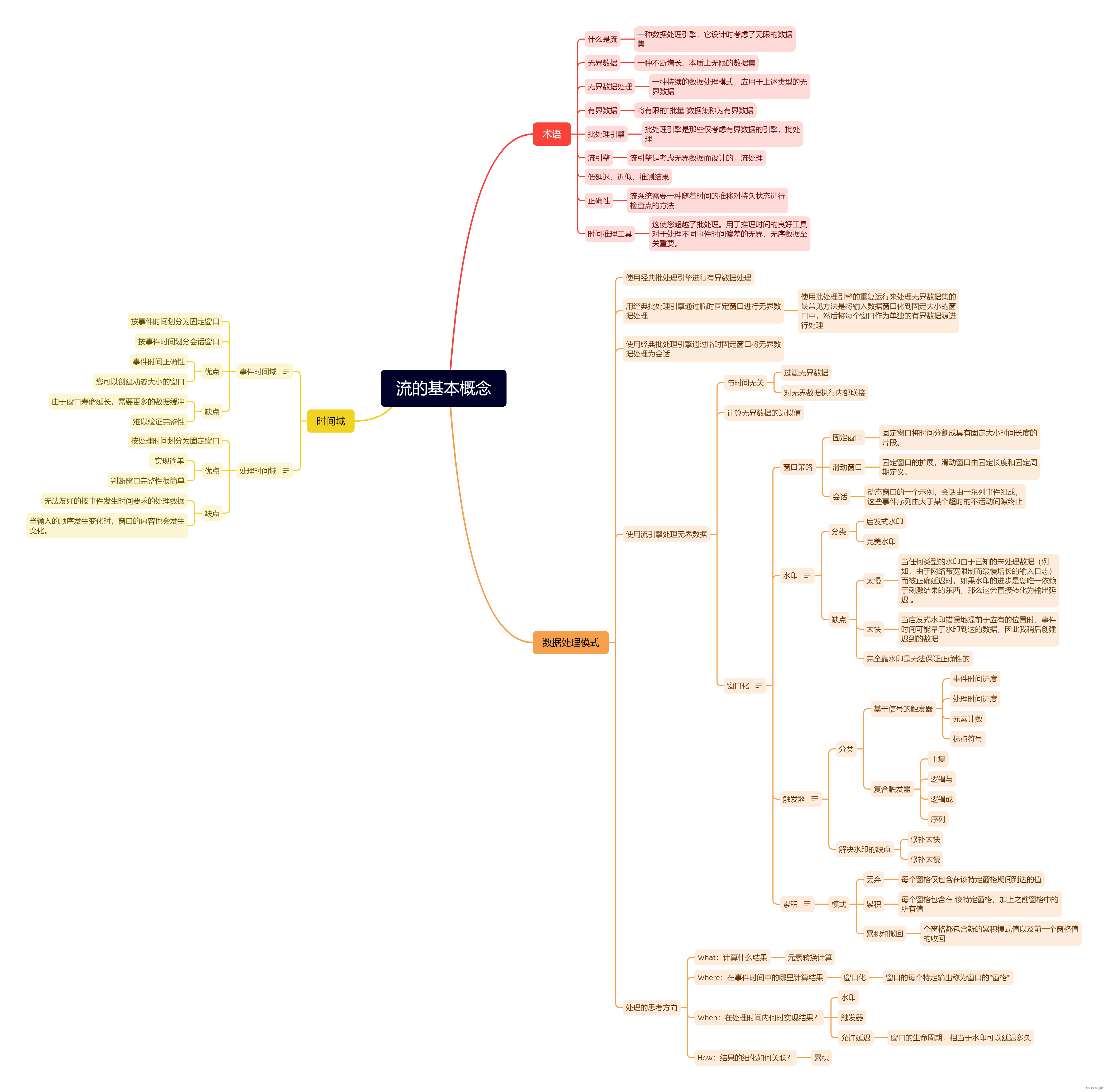

Flink零基础学习(四)RunTime总览以及核心组件简单介绍
用户的任务会以job方式提交给集群,runtime负责整个作业的调度,支持各种作业方式。
简单的一个作业表单 实际上作业是: 这里就是逻辑图(JobVertex)和执行图(ExecutionVertex)的区别,虚线圈表示的是一个Operator chain(要求并发度一…

Flink源码之Checkpoint执行流程
Checkpoint完整流程如上图所示:
JobMaster的CheckpointCoordinator向所有SourceTask发送RPC触发一次CheckPointSourceTask向下游广播CheckpointBarrierSouceTask完成状态快照后向JobMaster发送快照结果非SouceTask在Barrier对齐后完成状态快照向JobMaster发送快照结…
docker-compose.yml flink metrics pushgateway
这里写目录标题1. docker-compose.yml flink metrics pushgateway1.1. 说明1.2. 扩展说明1.2.1. PrometheusPushGateway 方式(推荐)1.2.2. Prometheus 方式1.3. tree1.4. docker-compose.yml1.5. restart_flink.sh1. docker-compose.yml flink metrics p…

Flink零基础学习(一)理解和搭建demo
网上关于Flink介绍的文章很多,可以自行百度,向来喜欢研究技术解决实际问题,主要谈我是怎么入坑的
学java出身没怎么接触大数据,也分不清楚Hadoop和Spark的业务场景好坏之分,只是在工作中遇到GPS异常数据处理时&#x…
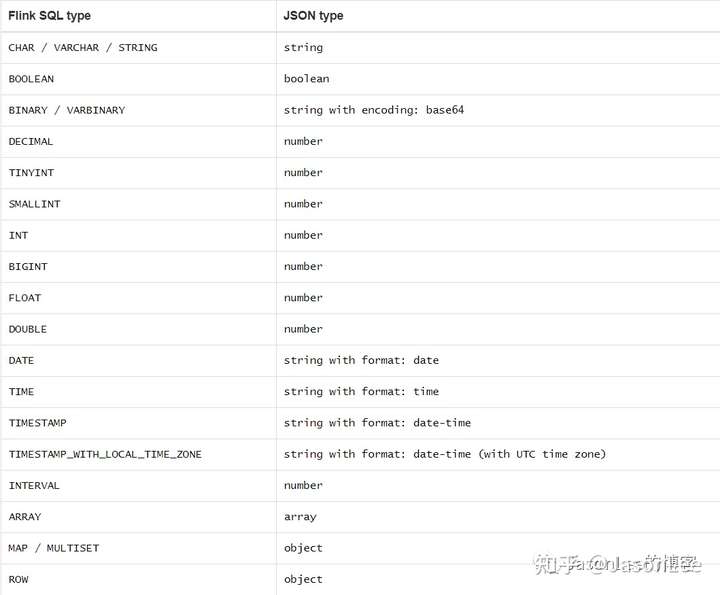
Flink SQL 如何解析嵌套的 JSON 数据<转载>
在日常的开发中,最常用的数据格式是 JSON ,并且有的时候 JSON 的格式是非常复杂的(嵌套的格式),那在 Flink SQL 中进行解析的时候也会相当麻烦一点,下面将会演示如何在 DDL 里面定义 Map、Array、Row 类型的数据,以及在 SQL 里面如何获里面的值数据格式如下:以下数据完全是自己…
大数据领域现状flink,storm,sparkstreaming,sql引擎
Hadoop 生态组件竞争激烈,Spark 优势明显,MapReduce 已进入维护模式 曾有开发人员表示,Hadoop 主要是被 MapReduce 拖累了,其实 HDFS 和 YARN 都还不错。堵俊平( 腾讯云专家研究员)则认为 MapReduce 拖累 H…
flink 使用savepoint
Flink通过Savepoint功能可以做到程序升级后,继续从升级前的那个点开始执行计算,保证数据不中断。 Flink中Checkpoint用于保存状态,是自动执行的,会过期,Savepoint是指向Checkpoint的指针,需要手动执行&…
idea本地启动项目带webUI的flink执行环境
//创建一个带webui的env执行环境 便于开发Configuration configuration new Configuration();configuration.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true);configuration.setInteger(RestOptions.PORT, 8989);StreamExecutionEnvironment env StreamExecutionEn…
idea配置flink web ui
为了方便flink本地开发配置了 webui flink本地运行,访问webui方法: 添加依赖:flink-runtime-web 一定要添加这个依赖,否则访问页面是会报{“errors”:[“Not found.”]} <dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-we…

flink 容错机制
Apache Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态。该机制确保即使出现故障,程序的状态最终也会反映来自数据流的每条记录(只有一次)。 从容错和消息处理的语义上(at least once, exactly once),Flink引入了state和checkpoi…
Flink DataSet Sink 写入 Kafka
借鉴这篇博客,由于flink没有提供将DataSet写入kafka的API,所以自己写了一个。通过实现org.apache.flink.api.common.io.OutputFormat接口,参照JDBCOutputFormat,加入了自定义分区器。
Github
KafkaOutputFormat.java
package c…
flink on yarn调优配置 slot、parallelsm、cpu
1、Flink参数配置 jobmanger.rpc.address:jobmanger的地址 jobmanger.rpc.port:jobmanger的端口 jobmanager.heap.mb:jobmanager的堆内存大小。不建议配的太大,1-2G足够。 taskmanager.heap.mb:taskmanager的堆内存大小…
flink常见的八种分区方式
BroadcastPartitioner:广播分区器,将数据发往下游的所有节点 CustomPartitionerWrapper:自定义分区器,可以自定义分区的规则 ForwardPartitioner:转发分区器,将数据转发给在本地运行下游的operater Shuffle…
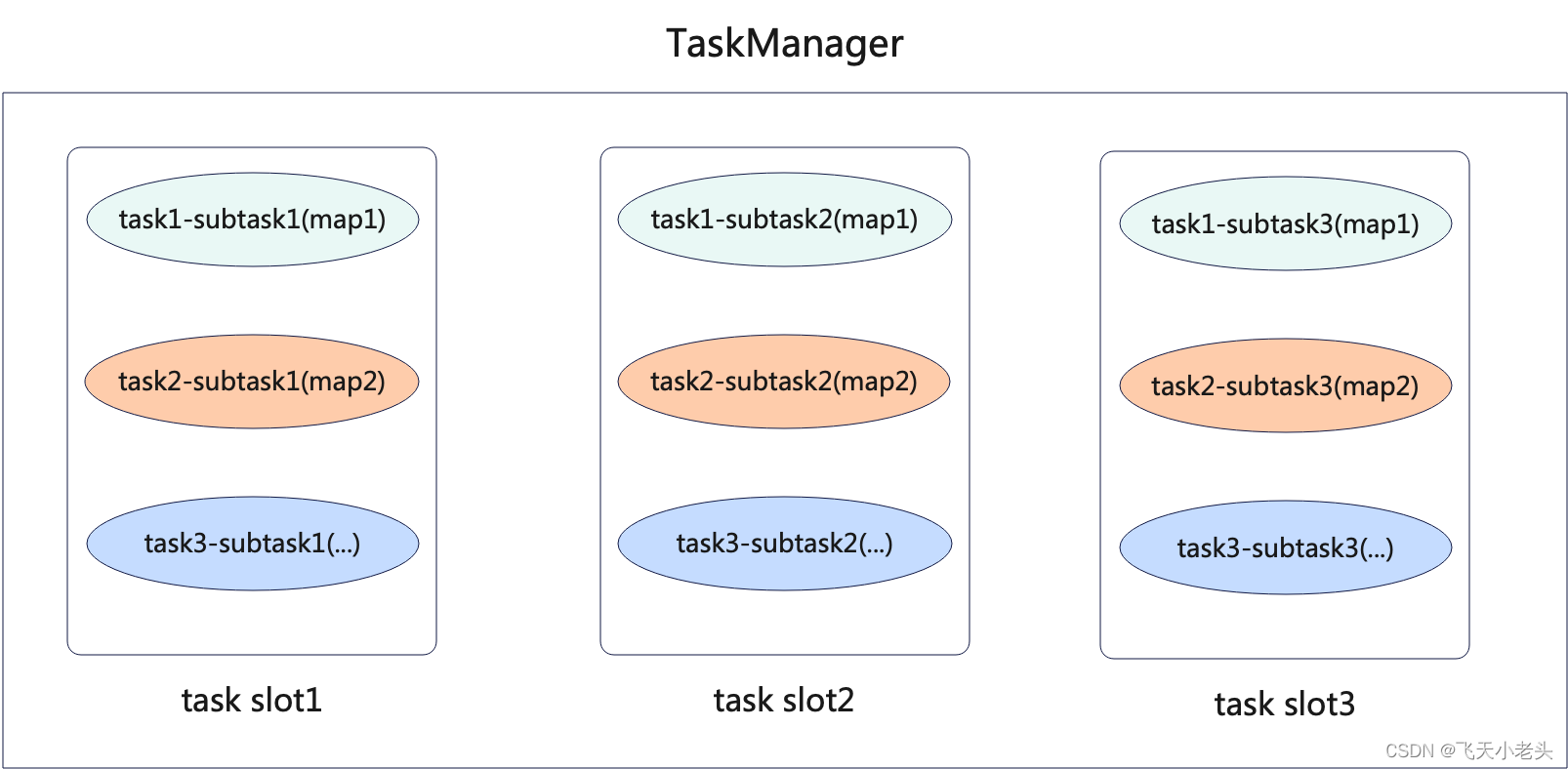
Flink之Task解析
Flink之Task解析 对Flink的Task进行解析前,我们首先要清楚几个角色TaskManager、Slot、Task、Subtask、TaskChain分别是什么
角色注释TaskManager在Flink中TaskManager就是一个管理task的进程,每个节点只有一个TaskManagerSlotSlot就是TaskManager中的槽位,一个TaskManager中可…
Flink源码之State创建流程
StreamOperatorStateHandler
在StreamTask启动初始化时通过StreamTaskStateInitializerImpl::streamOperatorStateContext会为每个StreamOperator 创建keyedStatedBackend和operatorStateBackend,在AbstractStreamOperator中有个StreamOperatorStateHandler成员变量…
看一眼常见数据处理的产品
Hadoop vs Spark
Hadoop 是一个分布式存储和计算框架,而 Spark 是一个基于内存的分布式计算框架。Hadoop 在存储大数据方面表现出色,而 Spark 在计算和处理大数据方面表现更快。另外,Hadoop 使用 MapReduce 处理数据,而 Spark 使…
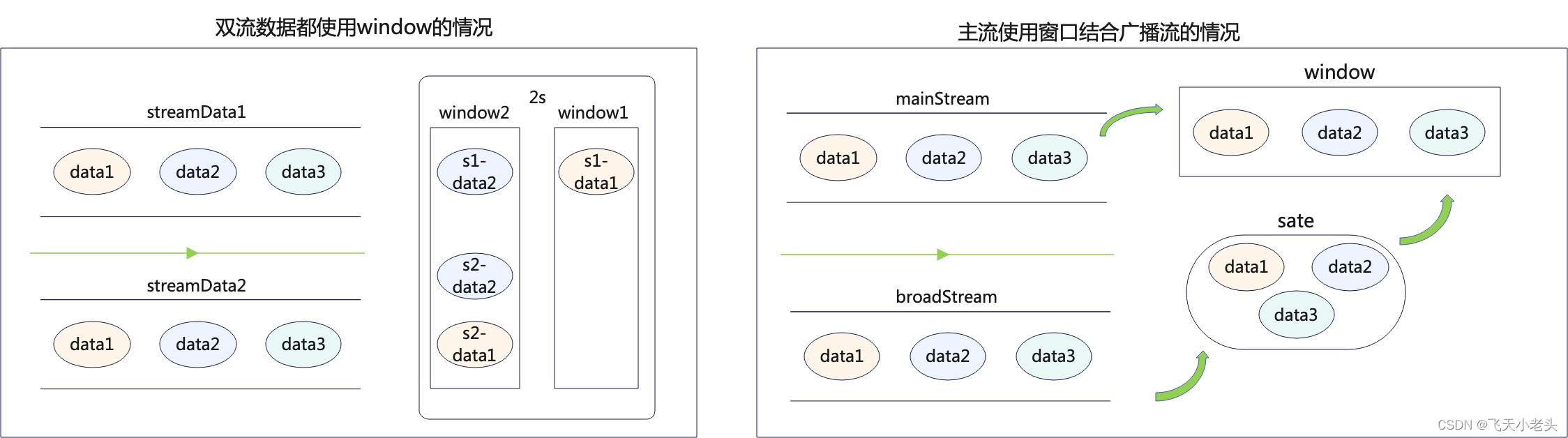
Flink多流处理之Broadcast(广播变量)
写过Spark批处理的应该都知道,有一个广播变量broadcast这样的一个算子,可以优化我们计算的过程,有效的提高效率;同样在Flink中也有broadcast,简单来说和Spark中的类似,但是有所区别,首先Spark中的broadcast是静态的数据,而Flink中的broadcast是动态的,也就是源源不断的数据流.在…
Flink CDC 与 Kafka 集成:State Snapshot 还是 Changelog?Kafka 还是 Upsert Kafka?
我们知道,尽管 Flink CDC 可以越过 Kafka,将关系型数据库中的数据表直接“映射”成数据湖上的一张表(例如 Hudi 等), 但从整体架构上考虑,维护一个 Kafka 集群作为数据接入的统一管道是非常必要的,这会带来很多收益。
在 Flink CDC 之前,以 Debezium + Kafka Connect …
【极数系列】Flink集成KafkaSink 实时输出数据(11)
文章目录 01 引言02 连接器依赖2.1 kafka连接器依赖2.2 base基础依赖 03 使用方法04 序列化器05 指标监控06 项目源码实战6.1 包结构6.2 pom.xml依赖6.3 配置文件6.4 创建sink作业 01 引言
KafkaSink 可将数据流写入一个或多个 Kafka topic
实战源码地址,一键下载可用…
Flink流式数据倾斜
1. 流式数据倾斜
流式处理的数据倾斜和 Spark 的离线或者微批处理都是某一个 SubTask 数据过多这种数据不均匀导致的,但是因为流式处理的特性其中又有些许不同 2. 如何解决
2.1 窗口有界流倾斜 窗口操作类似Spark的微批处理,直接两阶段聚合的方式来解决…
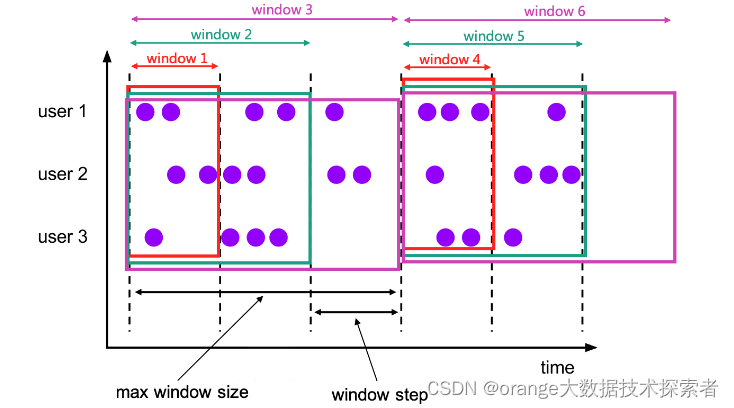
FlinkSql 窗口函数
Windowing TVF
以前用的是Grouped Window Functions(分组窗口函数),但是分组窗口函数只支持窗口聚合
现在FlinkSql统一都是用的是Windowing TVFs(窗口表值函数),Windowing TVFs更符合 SQL 标准且更加强大…
【大数据面试题】004 Flink状态后端是什么
一步一个脚印,一天一道大数据面试题。
在实时处理中,状态管理是十分常用的。比如监控某些数据是否一直快速增长。那就需要记录到之前的状态,数值。
那作为最热门的实时处理框架,Flink对状态管理是有一套的。那就是状态后端&…
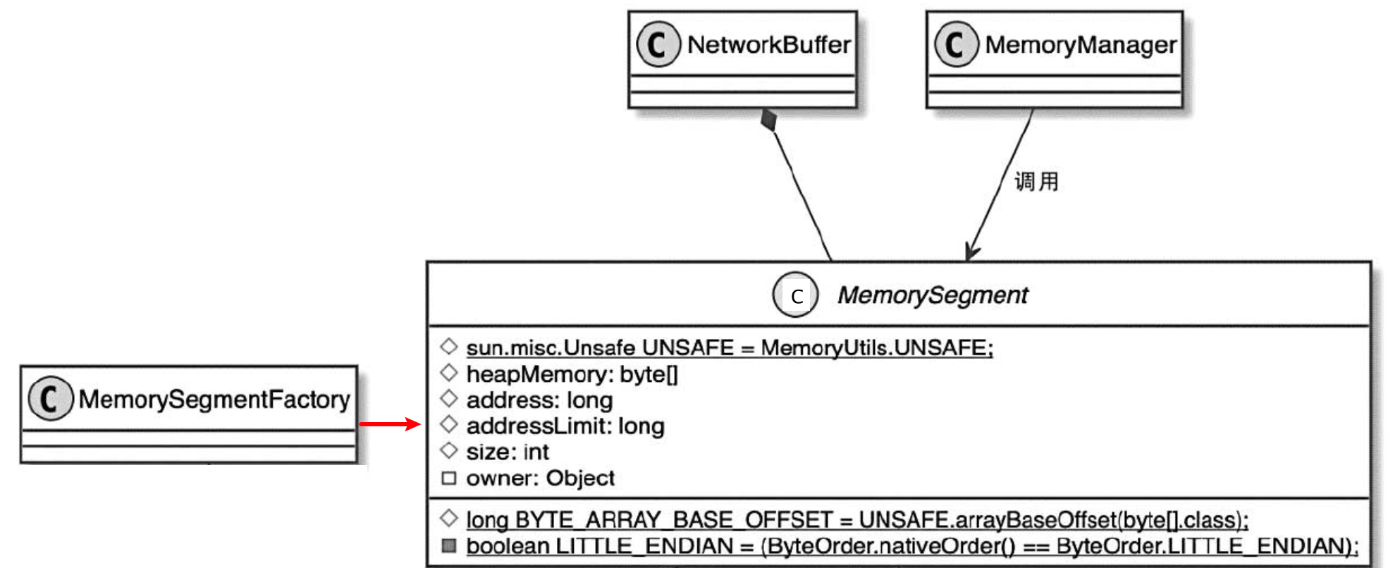
flink内存管理(二):MemorySegment的设计与实现:(1)架构、(2)管理堆内/外内存、(3)写入/读取内存、(4)垃圾清理器
文章目录 一. MemorySegment架构概览二. MemorySegment详解1.基于MemorySegment管理堆内存2.基于MemorySegment管理堆外内存3.基于Unsafe管理MemorySegment4.写入和读取内存数据5.创建MemoryCleaner垃圾清理器 在flink内存管理(一)中我们已经知道&#x…
Spring SpEL在Flink中的应用-SpEL详解
前言 Spring 表达式语言 Spring Expression Language(简称 SpEL )是一个支持运行时查询和操做对象图的表达式语言 。 语法相似于 EL 表达式 ,但提供了显式方法调用和基本字符串模板函数等额外特性。SpEL 在许多组件中都得到了广泛应用&#x…
大数据学习之Flink、搞懂Flink的恢复策略
第一章、Flink的容错机制
第二章、Flink核心组件和工作原理
第三章、Flink的恢复策略
第四章、Flink容错机制的注意事项
第五章、Flink的容错机制与其他框架的容错机制相比较 目录
第三章、Flink的恢复策略
Ⅰ、恢复策略
1. Checkpoint:
2. Savepoint&#…

flink-java使用介绍,flink,java,DataStream API,DataSet API,ETL,设置 jobname
1、环境准备
文档:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/ 仓库:https://github.com/apache/flink 下载:https://flink.apache.org/zh/downloads/ 下载指定版本:https://archive.apache.org/dist/flink…
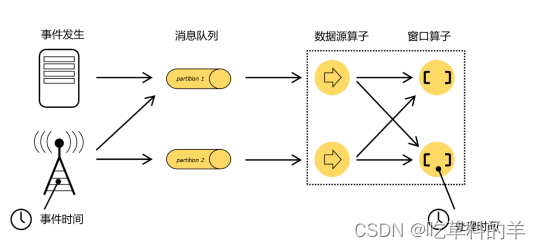
flink基础概念之什么是时间语义
什么是时间语义
Flink支持三种不同的时间语义,以便处理流式数据中的事件时间、处理时间和摄入时间。
1. 处理时间(Processing Time)
处理时间的概念非常简单,就是指执行处理操作的机器的系统时间。 在这种时间语义下处理窗口非…
【大数据】流处理基础概念(三):状态和一致性模型(任务故障、结果保障)
流处理基础概念(一):Dataflow 编程基础、并行流处理流处理基础概念(二):时间语义(处理时间、事件时间、水位线)流处理基础概念(三):状态和一致性模…
PiflowX-JdbcCatalog组件
JdbcCatalog组件
组件说明
通过JDBC协议将Flink连接到关系数据库,目前支持Postgres Catalog和MySQL Catalog。
计算引擎
flink
组件分组
Catalog
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子c…
Flink SQL TopN
Flink SQL 对于批处理(Batch)和流处理(streaming)模式的SQL,都支持 Top-N 查询。Top-N 查询可以根据指定列排序后获得前 N 个最小或最大值。并且该结果集还可用于进一步分析。Flink 使用 OVER 窗口子句和过滤条件的组合…
《Flink学习笔记》——第五章 DataStream API
一个Flink程序,其实就是对DataStream的各种转换,代码基本可以由以下几部分构成: 获取执行环境读取数据源定义对DataStream的转换操作输出触发程序执行 获取执行环境和触发程序执行都属于对执行环境的操作,那么其构成可以用下图表示…
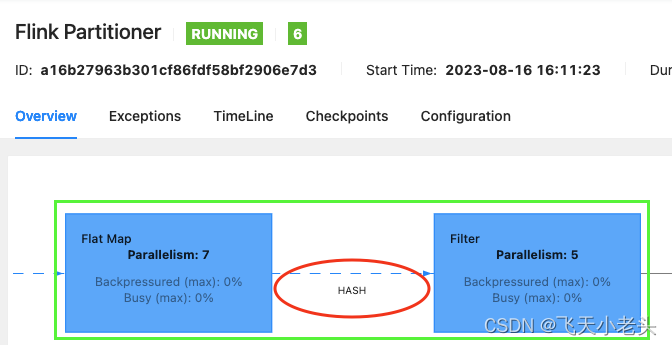
Flink之Partitioner(分区规则)
Flink之Partitioner(分区规则)
方法注释global()全部发往1个taskbroadcast()广播(前面的文章讲解过,这里不做阐述)forward()上下游并行度一致时一对一发送,和同一个算子连中算子的OneToOne是一回事shuffle()随机分配(只是随机,同Spark的shuffle不同)rebalance()轮询分配,默认机…
flinksql报错 Cannot determine simple type name “org“
flink版本 1.15
报错内容
2023-08-17 15:46:02
java.lang.RuntimeException: Could not instantiate generated class WatermarkGenerator$0at org.apache.flink.table.runtime.generated.GeneratedClass.newInstance(GeneratedClass.java:74)at org.apache.flink.table.runt…
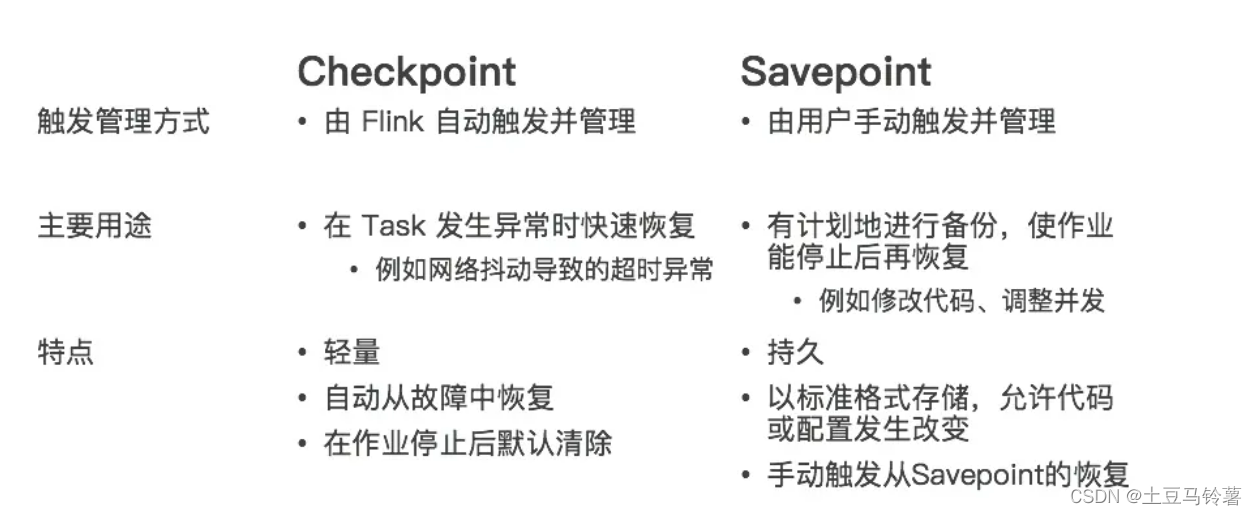
Flink状态和状态管理
1.什么是状态
官方定义:当前计算流程需要依赖到之前计算的结果,那么之前计算的结果就是状态。
这句话还是挺好理解的,状态不只存在于Flink,也存在生活的方方面面,比如看到一个认识的人,如何识别认识呢&am…
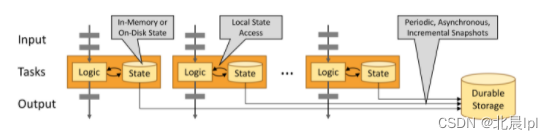
Flink学习笔记(一)
流处理
批处理应用于有界数据流的处理,流处理则应用于无界数据流的处理。 有界数据流:输入数据有明确的开始和结束。 无界数据流:输入数据没有明确的开始和结束,或者说数据是无限的,数据通常会随着时间变化而更新。 在…

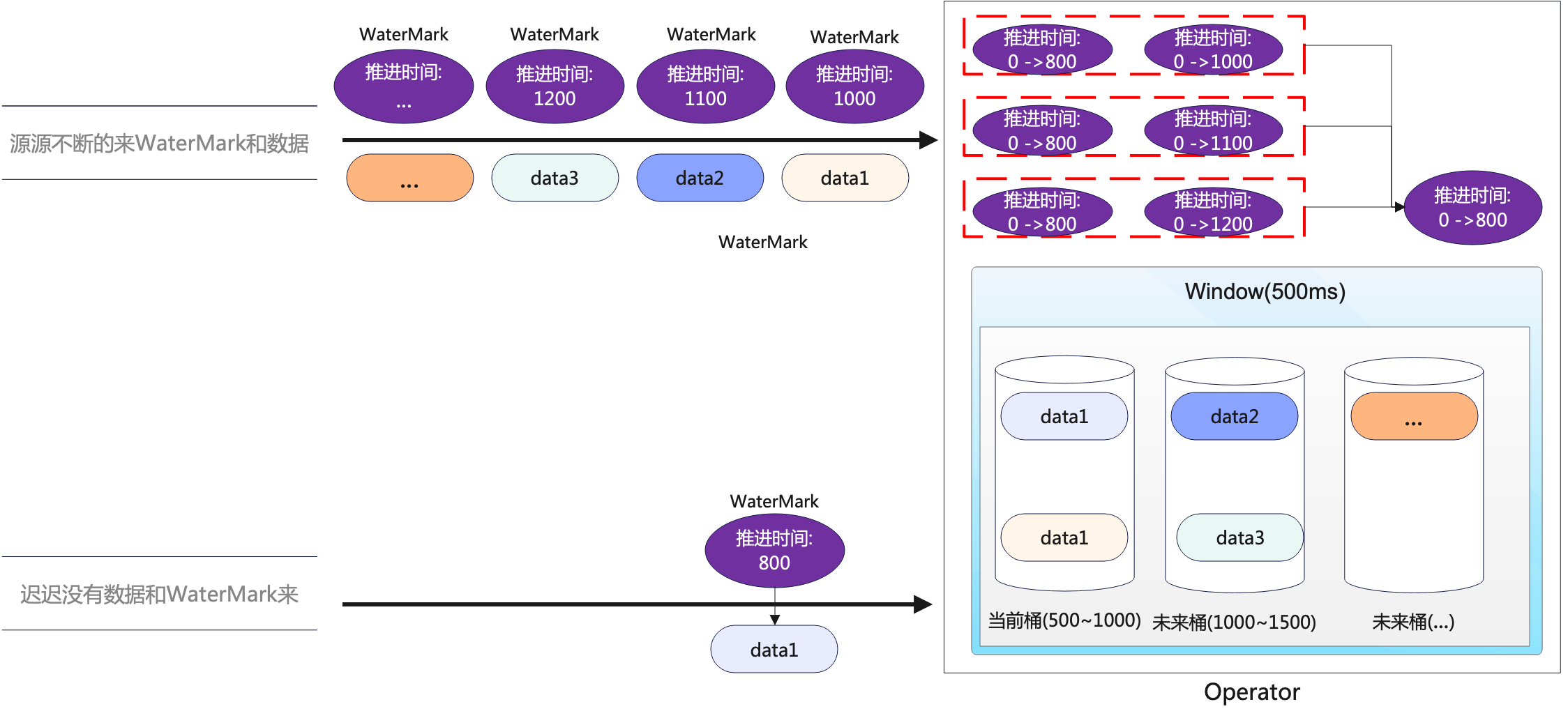
Flink之时间语义
Flink之时间语义
简介
Flink中时间语义可以说是最重要的一个概念了,这里就说一下关于时间语义的机制,我们下看一下下面的表格,简单了解一下
时间定义processing time处理时间,也就是现实世界的时间,或者说代码执行时,服务器的时间event time事件时间,就是事件数据中所带的时…
Flink流批一体计算(14):PyFlink Tabel API之SQL查询
举个例子
查询 source 表,同时执行计算
# 通过 Table API 创建一张表:
source_table table_env.from_path("datagen")
# 或者通过 SQL 查询语句创建一张表:
source_table table_env.sql_query("SELECT * FROM datagen&quo…
Flink流批一体计算(13):PyFlink Tabel API之SQL DDL
1. TableEnvironment
创建 TableEnvironment
from pyflink.table import Environmentsettings, TableEnvironment# create a streaming TableEnvironmentenv_settings Environmentsettings.in_streaming_mode()table_env TableEnvironment.create(env_settings)# or create…

大数据Flink学习圣经:一本书实现大数据Flink自由
学习目标:三栖合一架构师
本文是《大数据Flink学习圣经》 V1版本,是 《尼恩 大数据 面试宝典》姊妹篇。
这里特别说明一下:《尼恩 大数据 面试宝典》5个专题 PDF 自首次发布以来, 已经汇集了 好几百题,大量的大厂面试…
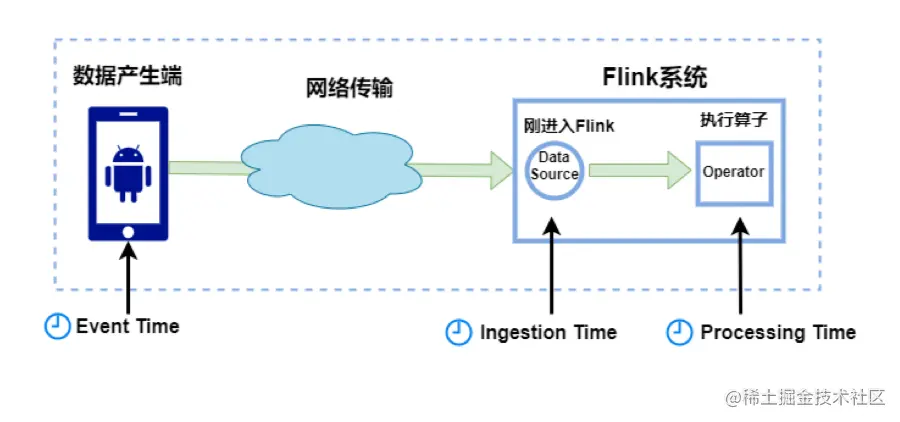
Watermark 是怎么生成和传递的?
分析&回答
Watermark 介绍
Watermark 本质是时间戳,与业务数据一样无差别地传递下去,目的是衡量事件时间的进度(通知 Flink 触发事件时间相关的操作,例如窗口)。
Watermark 是一个时间戳, 它表示小于该时间戳的…

38、Flink 的CDC 格式:canal部署以及示例
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…
Flink窗口类型功能汇总
Flink窗口类型功能汇总 Flink 中的 WindowAssigner 有多种实现类,每种实现类都有不同的作用。以下是一些常见的 WindowAssigner 实现类: TumblingEventTimeWindows: 将事件时间划分为固定大小的窗口。 SlidingEventTimeWindows: 将…

Flink Checkpoint 超时问题和解决办法
第一种、计算量大,CPU密集性,导致TM内线程一直在processElement,而没有时间做CP【过滤掉部分数据;增大并行度】
代表性作业为算法指标-用户偏好的计算,需要对用户在商城的曝光、点击、订单、出价、上下滑等所有事件进…
[AIGC大数据基础] Flink: 大数据流处理的未来
Flink 是一个分布式流处理引擎,它被广泛应用于大数据领域,具有高效、可扩展和容错的特性。它是由 Apache 软件基金会开发和维护的开源项目,并且在业界中受到了广泛认可和使用。 文章目录 什么是 FlinkFlink 的特点真正的流处理高性能和低延迟…
【大数据】Flink 中的事件时间处理
Flink 中的事件时间处理 1.时间戳2.水位线3.水位线传播和事件时间4.时间戳分配和水位线生成 在之前的博客中,我们强调了时间语义对于流处理应用的重要性并解释了 处理时间 和 事件时间 的差异。虽然处理时间是基于处理机器的本地时间,相对容易理解&#…
Flink 集成 Debezium Confluent Avro ( format=debezium-avro-confluent )
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,京东购书链接:https://item.jd.com/12677623.html,扫描左侧二维…

Flink实现数据写入MySQL
先准备一个文件里面数据有: a, 1547718199, 1000000
b, 1547718200, 1000000
c, 1547718201, 1000000
d, 1547718202, 1000000
e, 1547718203, 1000000
f, 1547718204, 1000000
g, 1547718205, 1000000
h, 1547718210, 1000000
i, 1547718210, 1000000
j, 154771821…
【极数系列】Linux环境搭建Flink1.18版本 (03)
文章目录 引言01 Linux部署JDK11版本1.下载Linux版本的JDK112.创建目录3.上传并解压4.配置环境变量5.刷新环境变量6.检查jdk安装是否成功 02 Linux部署Flink1.18.0版本1.下载Flink1.18.0版本包2.上传压缩包到服务器3.修改flink-config.yaml配置4.启动服务5.浏览器访问6.停止服务…
PiflowX组件-FileWrite
FileWrite组件
组件说明
往文件系统写入。
计算引擎
flink
组件分组
file
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子pathpath“”无是文件路径。hdfs://server1:8020/flink/test/text.txtfo…

flink cdc,standalone模式下,任务运行一段时间taskmanager挂掉
在使用flink cdc,配置任务运行,过了几天后,任务无故取消,超时,导致taskmanager挂掉,相关异常如下: 异常1: did not react to cancelling signal interrupting; it is stuck for 30 s…
【Flink】FlinkSQL实现数据从MySQL到MySQL
简介
我们在实际开发过程中可以使用Flink实现数据从MySQL传输到MySQL具体操作,本例子Flink版本1.13.6,具体操作如下:
创建mysql测试表
下面语句创建了mysql原表和目标表,并插入一条语句到mysql原表中 CREATE TABLE `mysql_source` ( `id` int(11) unsigned NOT NULL A…
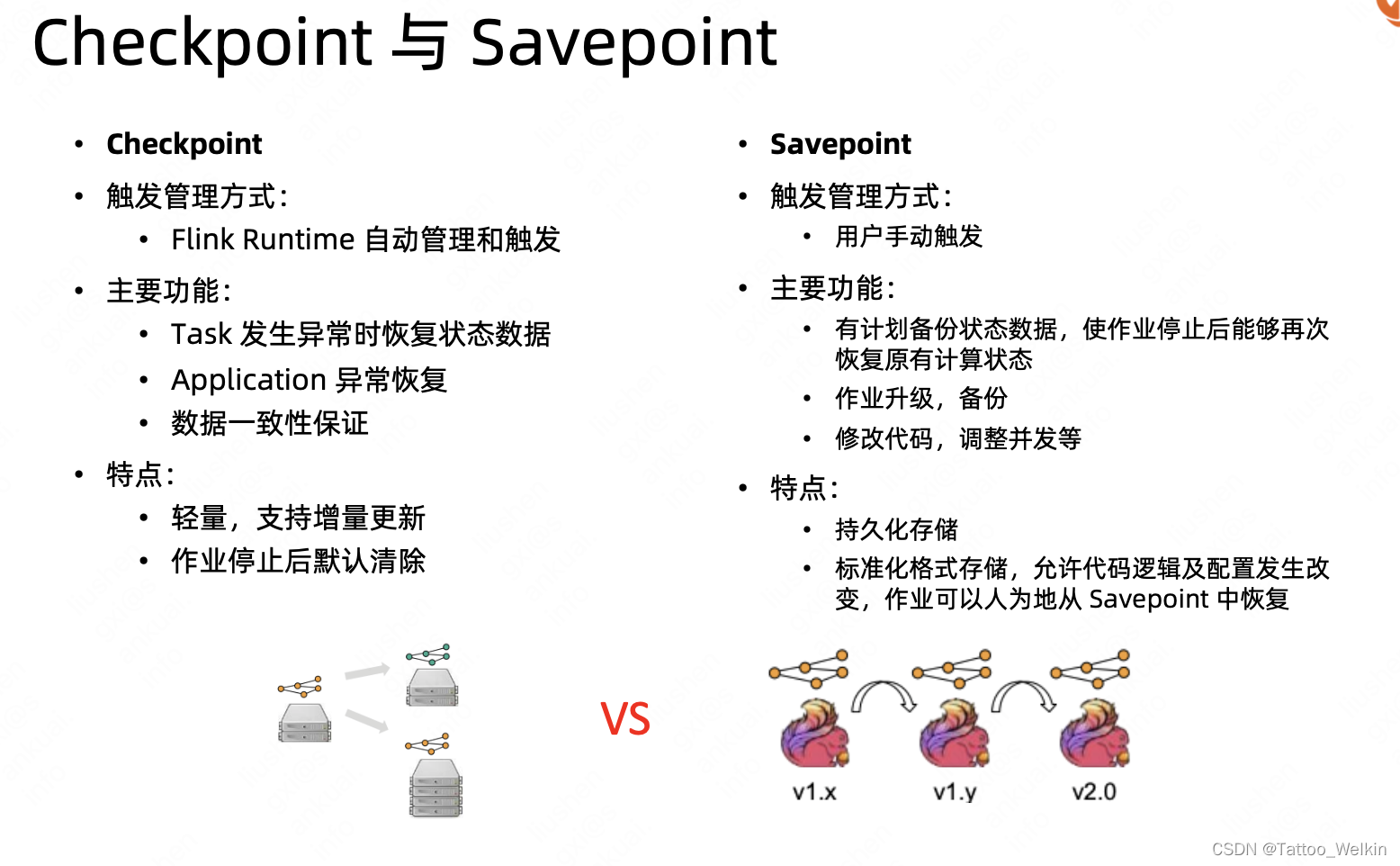
Flink 状态管理与容错
文章目录有状态计算使用外部存储会存在的问题?自己实现中间状态存储会存在的问题?以及如何解决?状态类型与应用状态应用场景CheckPoint 实现原理作用:其实就是持久化作用:其实就是持久化SavePoint 实现原理(…

如何深度融合 Flink 和 Kubernetes实现运维资源的统一管理?
Flink 是这两年大数据领域最火的开源分布式流处理框架,而 Flink 的核心架构以及执行流程拆解,自然而然就成了大数据工程师、架构师的必备技能。过去,一个优质的大数据岗位可能只需要你对 Spark 应用到炉火纯青。但现在,如果你没接…
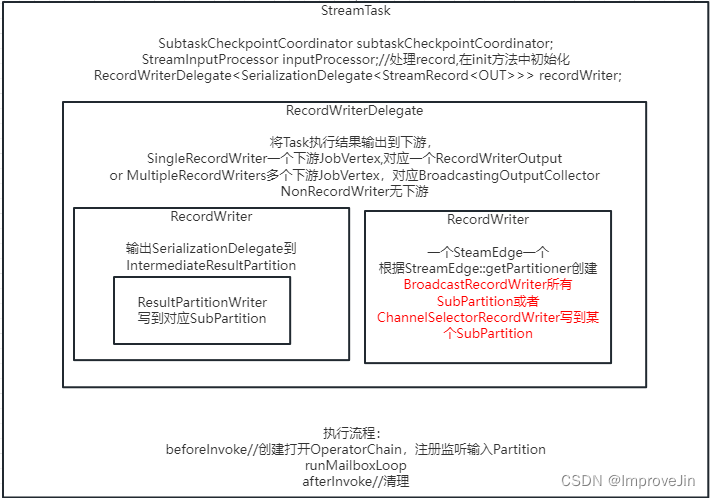
Flink源码之StreamTask启动流程
每个ExecutionVertex分配Slot后,JobMaster就会向Slot所在的TaskExecutor提交RPC请求执行Task,接口为TaskExecutorGateway::submitTask
CompletableFuture<Acknowledge> submitTask(TaskDeploymentDescriptor tdd, JobMasterId jobMasterId, RpcTi…
关于网络入侵检测领域使用Spark/Flink等计算框架做分布式
关于网络入侵检测领域使用Spark/Flink等计算框架做分布式 0、引言1 基于LightGBM的网络入侵检测研究2 基于互信息法的智能化运维系统入侵检测Spark实现3 基于Spark的车联网分布式组合深度学习入侵检测方法4 基于Flink的分布式在线集成学习框架研究5 基于Flink的分布式并行逻辑回…
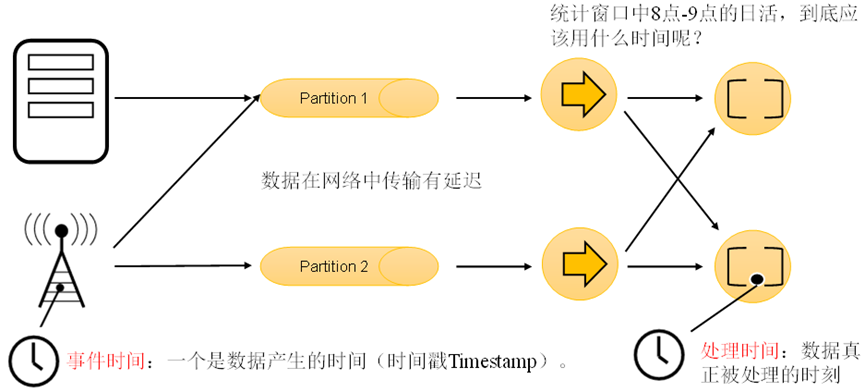
如何使用Spark/Flink等分布式计算引擎做网络入侵检测
如何使用Spark/Flink等分布式计算引擎做网络入侵检测 引言16 Distributed Abnormal Behavior Detection Approach Based on Deep Belief Network and Ensemble SVM Using Spark17 Spark configurations to optimize decision tree classification on UNSW-NB1518 A dynamic spa…
大数据-玩转数据-Flink网页埋点PV统计
一、说明
衡量网站流量一个最简单的指标,就是网站的页面浏览量(Page View,PV)。用户每次打开一个页面便记录1次PV,多次打开同一页面则浏览量累计。 一般来说,PV与来访者的数量成正比,但是PV并不…

07_Hudi案例实战、Flink CDC 实时数据采集、Presto、FineBI 报表可视化等
7.第七章 Hudi案例实战 7.1 案例架构 7.2 业务数据 7.2.1 客户信息表 7.2.2 客户意向表 7.2.3 客户线索表 7.2.4 线索申诉表 7.2.5 客户访问咨询记录表 7.3 Flink CDC 实时数据采集 7.3.1 开启MySQL binlog 7.3.2 环境准备 7.3.3 实时采集数据 7.3.3.1 客户信息表 7.3.3.2 客户…
【大数据】-- 本地部署 Flink kubernetes operator
目录 1.说明
1.1 版本
1.2 kubernetes 环境
1.3 参考
2.安装步骤
2.1 安装本地 kubernetes 环境
《Flink学习笔记》——第七章 处理函数
为了让代码有更强大的表现力和易用性,Flink 本身提供了多层 API
在更底层,我们可以不定义任何具体的算子(比如 map,filter,或者 window),而只是提炼出一个统一的“处理”(process&a…
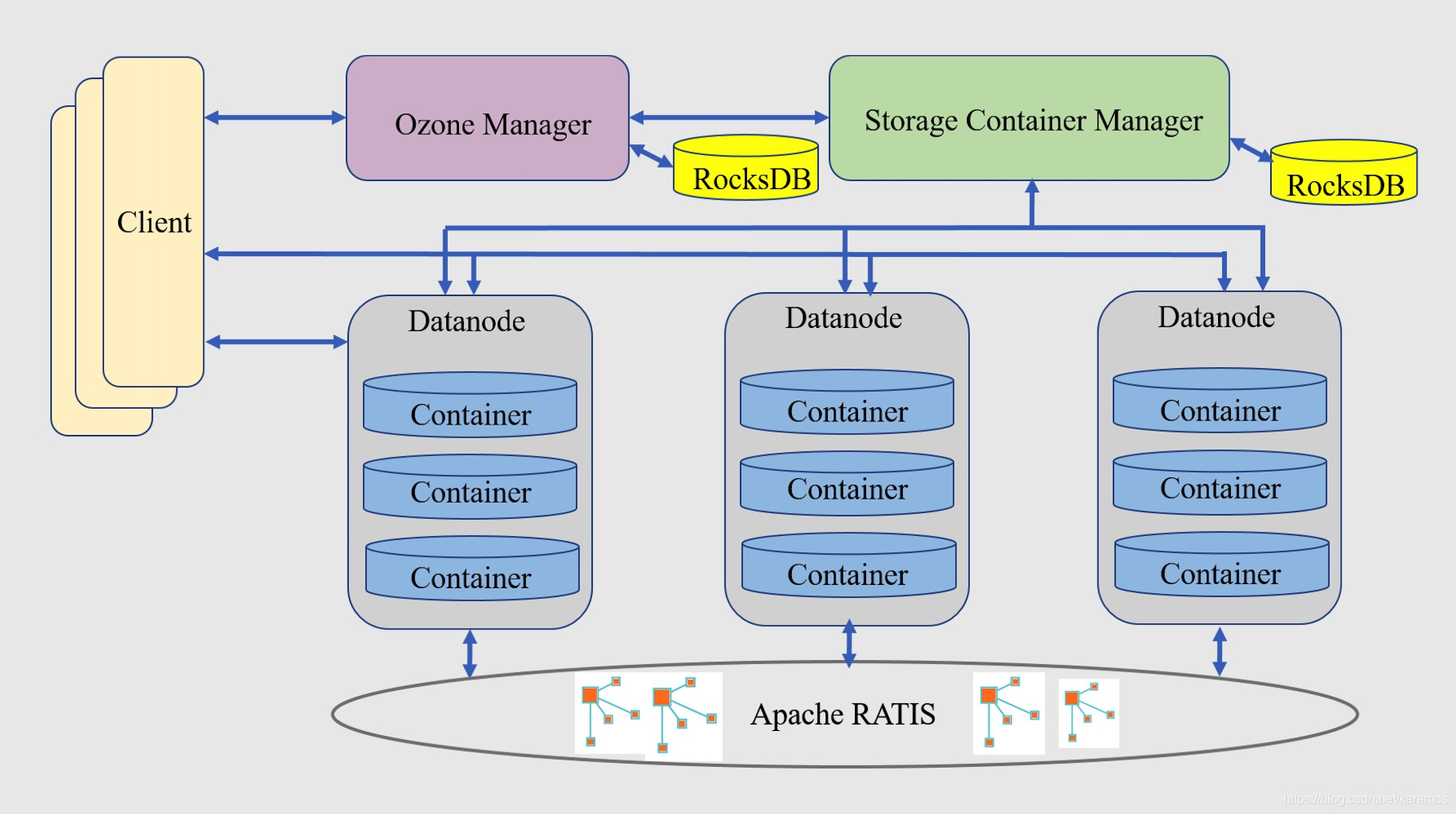
腾讯云大数据团队主导Apache社区新一代分布式存储系统Ozone 1.0.0发布
刚刚获悉,由腾讯云大数据团队主导的Ozone 1.0.0版本在Apache Hadoop社区正式发布。据了解,经过2年多的社区持续开发和内部1000节点的实际落地验证,Ozone 1.0.0已经具备了在大规模生产环境下实际部署的能力。
Ozone 是Apache Hadoop社区推出的…

《Flink学习笔记》——第六章 Flink的时间和窗口
6.1 时间语义
6.1.1 Flink中的时间语义 对于一台机器而言,时间就是系统时间。但是Flink是一个分布式处理系统,多台机器“各自为政”,没有统一的时钟,各自有各自的系统时间。而对于并行的子任务来说,在不同的节点&…
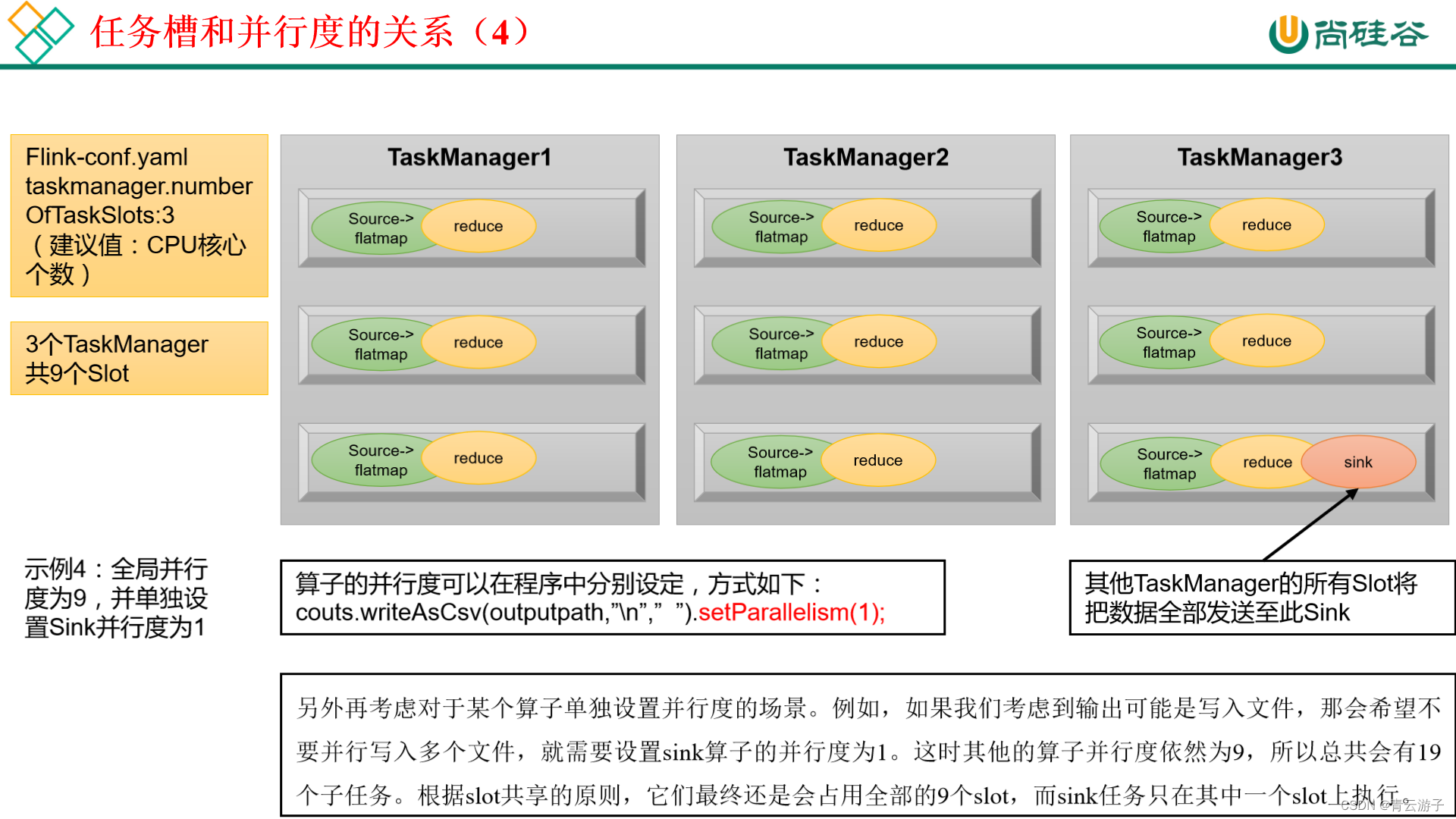
Flink-任务槽和并行度的关系
任务槽和并行度都跟程序的并行执行有关,但两者是完全不同的概念。简单来说任务槽是静态的概念,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置;而并行度是动态概念,也就是Task…
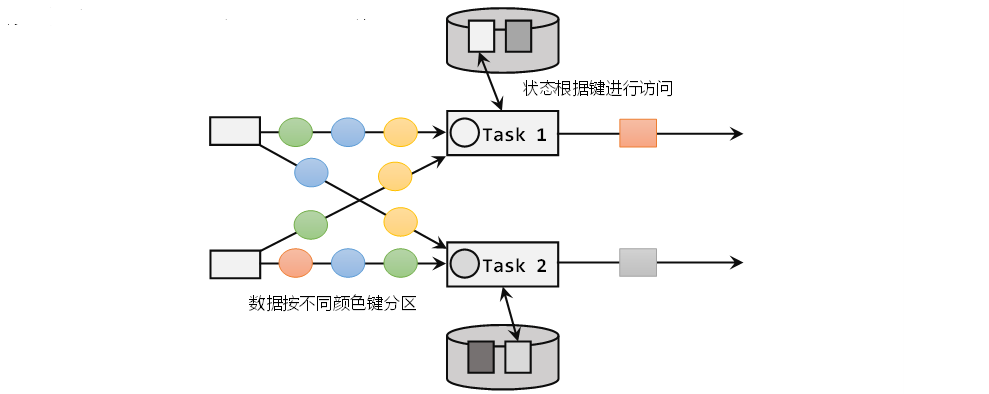
《Flink学习笔记》——第八章 状态管理
8.1 Flink中的状态
8.1.1 概述
在Flink中,算子任务可以分为无状态和有状态两种情况。
**无状态的算子:**每个事件不依赖其它数据,自己处理完就输出,也不需要依赖中间结果。例如:打印操作,每个数据只需要…

大数据-玩转数据-Flink 水印
一、Flink 中的水印
在Flink的流式操作中, 会涉及不同的时间概念:
1.1 处理时间
是指的执行操作的各个设备的时间,对于运行在处理时间上的流程序, 所有的基于时间的操作(比如时间窗口)都是使用的设备时钟。比如, 一个长度为1个小时的窗口将会包含设备…
FlinkSql 如何实现数据去重?
摘要
很多时候flink消费上游kafka的数据是有重复的,因此有时候我们想数据在落盘之前进行去重,这在实际开发中具有广泛的应用场景,此处不说详细代码,只粘贴相应的flinksql
代码
--********************************************…
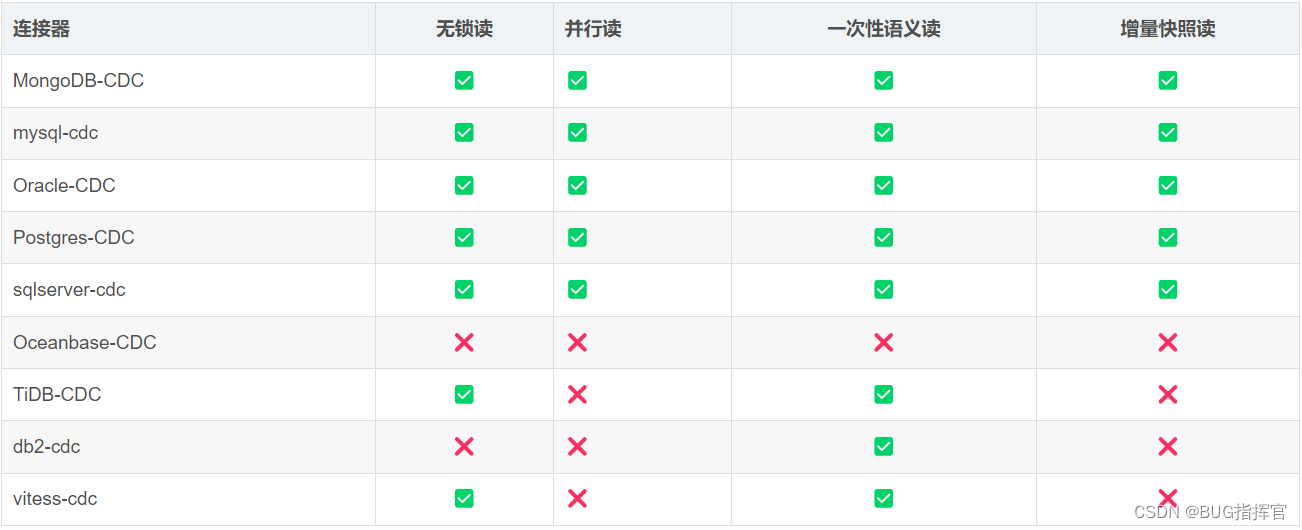
Flink CDC介绍
1.CDC概述 CDC(Change Data Capture)是一种用于捕获和处理数据源中的变化的技术。它允许实时地监视数据库或数据流中发生的数据变动,并将这些变动抽取出来,以便进行进一步的处理和分析。
传统上,数据源的变化通常通过…
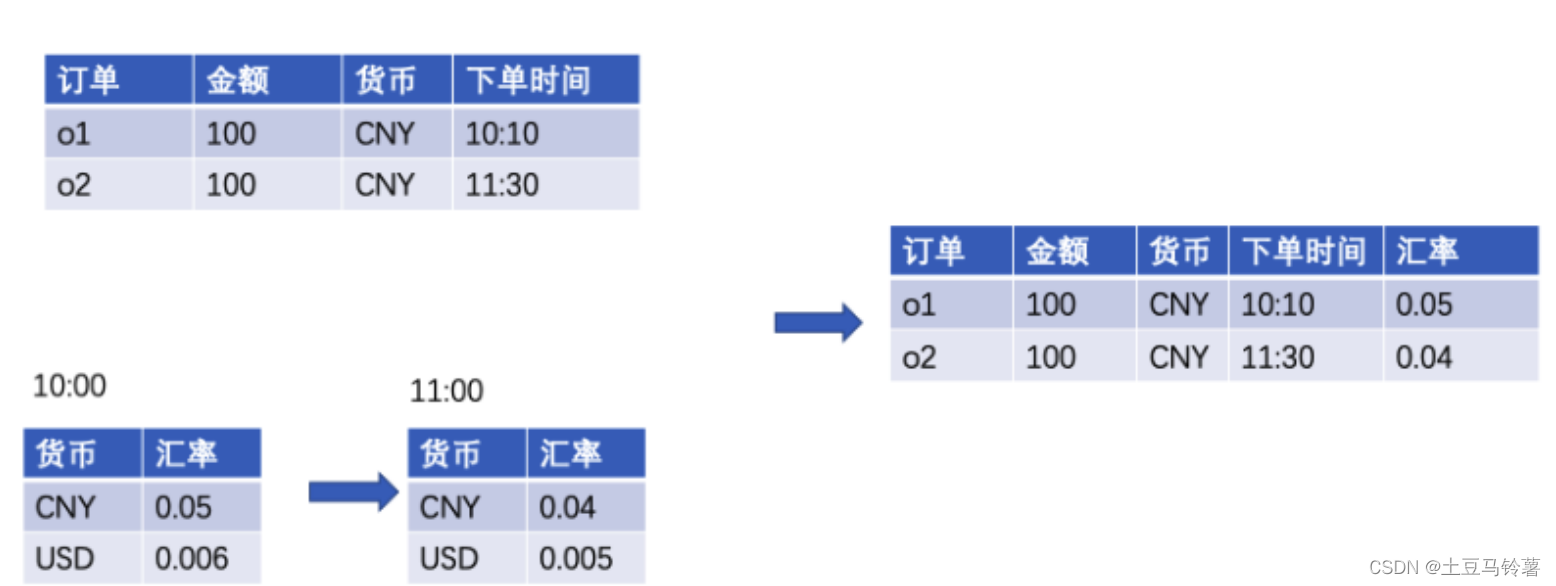
Flink SQL之Temporal Joins
1.Temporal Joins(时态JOIN)
时态表是一个随时间演变的表,在Flink中也称为动态表。
时态表中的行与一个或多个时态周期相关联,并且所有Flink表都是时态的(动态的)。时态表包含一个或多个版本化的表快照&a…
Flink 源算子之 DataGeneratorSource DataGenerator
目录
1、功能说明
2、API使用说明
3、代码示例 1、功能说明 从Flink1.1开始提供了DataGen连接器,它提供了Source类的实现(可并行的源算子),用来生成测试数据,在本地开发或者无法访问外部系统(如kafka)时,…
flink sql 13.2 读取与写入数据库的报错(踩坑)
flink sql读取与写入数据的报错(踩坑) flink sql sink mysql 没有数据写入或数据写入中文乱码或报useSSLflink sql source mysql 任务执行正常没有任何报错信息(构建 Flink LookUp 表 的踩坑历程) flink sql sink mysql 没有数据写…
Flink流批一体计算(9):Flink Python
目录 使用Python依赖
使用自定义的Python虚拟环境
方式一:在集群中的某个节点创建Python虚拟环境
方式二:在本地开发机创建Python虚拟环境
使用JAR包
使用数据文件 使用Python依赖
通过以下场景为您介绍如何使用Python依赖:
使用自定义…
flink维度表关联
分析&回答
根据我们业务对维表数据关联的时效性要求,有以下几种解决方案: 1、实时查询维表
实时查询维表是指用户在Flink 的Map算子中直接访问外部数据库,比如用 MySQL 来进行关联,这种方式是同步方式,数据保证是…

说说Flink中的State
分析&回答
基本类型划分
在Flink中,按照基本类型,对State做了以下两类的划分:
Keyed State,和Key有关的状态类型,它只能被基于KeyedStream之上的操作,方法所使用。我们可以从逻辑上理解这种状态是一…

性能提升3-4倍!贝壳基于Flink + OceanBase的实时维表服务
作者介绍:肖赞,贝壳找房(北京)科技有限公司 OLAP 平台负责人,基础研发线大数据平台部架构师。
贝壳找房是中国最大的居住服务平台。作为居住产业数字化服务平台,贝壳致力于推进居住服务的产业数字化、智能…
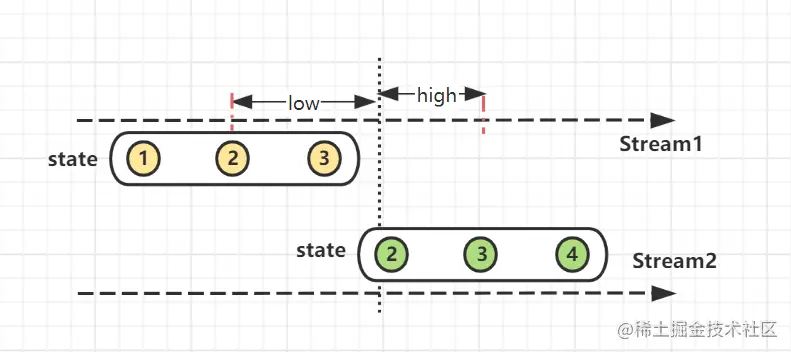
说说Flink双流join
分析&回答
Flink双流JOIN主要分为两大类
一类是基于原生State的Connect算子操作另一类是基于窗口的JOIN操作。其中基于窗口的JOIN可细分为window join和interval join两种。
基于原生State的Connect算子操作
实现原理:底层原理依赖Flink的State状态存储&…
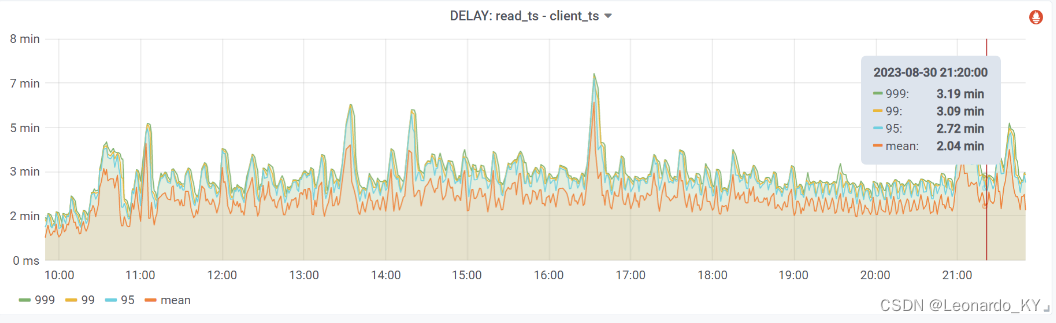
Flink+Paimon多流拼接性能优化实战
目录
(零)本文简介
(一)背景
(二)探索梳理过程
(三)源码改造
(四)修改效果
1、JOB状态
2、Level5的dataFile总大小
3、数据延迟
(五&…
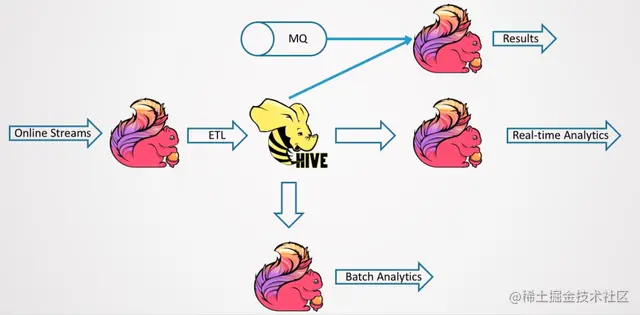
Flink SQL你用了吗?
分析&回答
Flink 1.1.0:第一次引入 SQL 模块,并且提供 TableAPI,当然,这时候的功能还非常有限。Flink 1.3.0:在 Streaming SQL 上支持了 Retractions,显著提高了 Streaming SQL 的易用性,使…
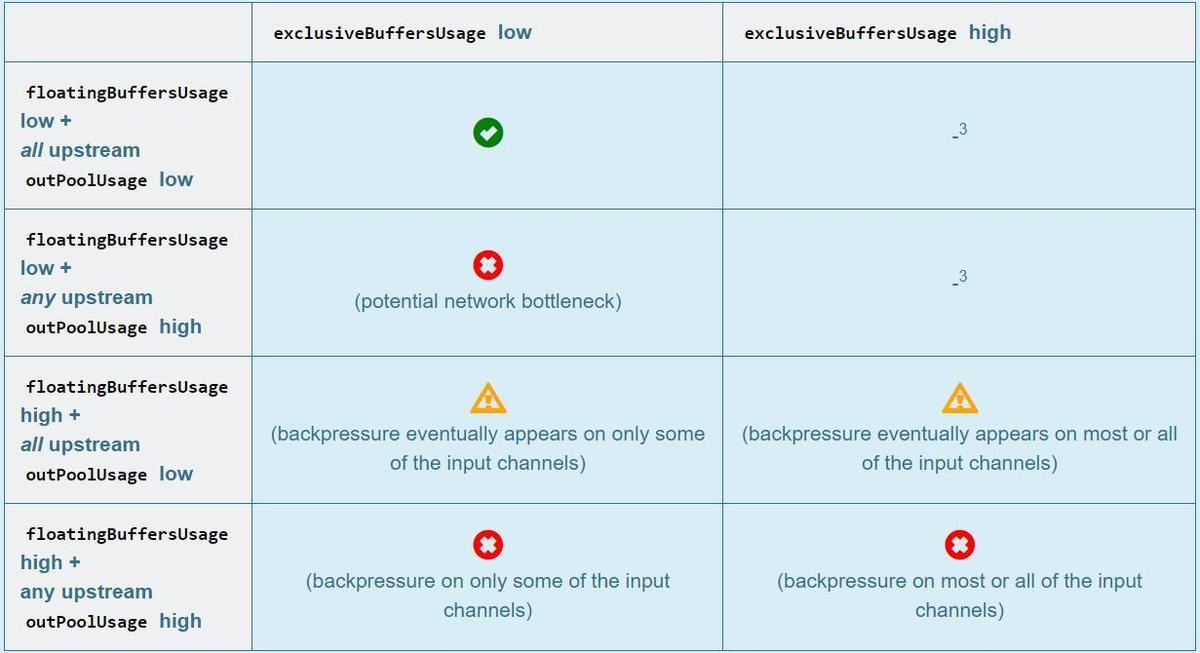
Flink 如何定位反压节点?
分析&回答
Flink Web UI 自带的反压监控 —— 直接方式
Flink Web UI 的反压监控提供了 Subtask 级别的反压监控。监控的原理是通过Thread.getStackTrace() 采集在 TaskManager 上正在运行的所有线程,收集在缓冲区请求中阻塞的线程数(意味着下游阻…
flink-对齐和不对齐,精准一次和至少一次
精准一次怎么保证?可以设置为以下2个 对齐 当有一个barrier比较快时,输入缓冲区阻塞,当另外一个barrier到来时,才进行备份,所以数据不会重复。优点:不会造成数据重复缺点:会造成数据积压&#x…
大数据-玩转数据-Flink 网站UV统计
一、说明
在实际应用中,我们往往会关注,到底有多少不同的用户访问了网站,所以另外一个统计流量的重要指标是网站的独立访客数(Unique Visitor,UV)。
二、数据准备
package com.lyh.flink06;import lombo…
基于Flink CDC实时同步PostgreSQL与Tidb【Flink SQL Client模式下亲测可行,详细教程】
文章目录 一、PostgreSQL作为数据来源(source),由flink读取1.postgre安装与配置2.flink安装与配置3.flink cdc postgre配置3.1 postgre配置(for flink cdc)3.2 flink cdc postgres的jar包下载 4.flink cdc postgre测试…
Flink1.17.1消费kafka3.5中的数据出现问题Failed to get metadata for topics [flink].
问题呈现 Failed to get metadata for topics [flink]. at org.apache.flink.connector.kafka.source.enumerator.subscriber.KafkaSubscriberUtils.getTopicMetadata(KafkaSubscriberUtils.java:47) at org.apache.flink.connector.kafka.source.enumerator.subscriber.TopicL…

【大数据】Flink 详解(二):核心篇 Ⅲ
Flink 详解(二):核心篇 Ⅲ 29、Flink 通过什么实现可靠的容错机制? Flink 使用 轻量级分布式快照,设计检查点(checkpoint)实现可靠容错。 30、什么是 Checkpoin 检查点? Checkpoint …
大数据-玩转数据-Flink 自定义Sink(Mysql)
一、说明
如果Flink没有提供给我们可以直接使用的连接器,那我们如果想将数据存储到我们自己的存储设备中,mysql 的安装使用请参考 mysql-玩转数据-centos7下mysql的安装 创建表
CREATE TABLE sensor (id int(10)
) ENGINEInnoDB DEFAULT CHARSETutf8二…
Flink CDC获取mysql 主从分库,分库分表的binlog
Flink CDC可以获取MySQL主从分库,分库分表的binlog,但是需要注意以下几点:
Flink CDC需要配置MySQL的binlog模式为row,以及开启GTID(全局事务标识符),以便正确地识别和处理binlog事件Flink CDC…

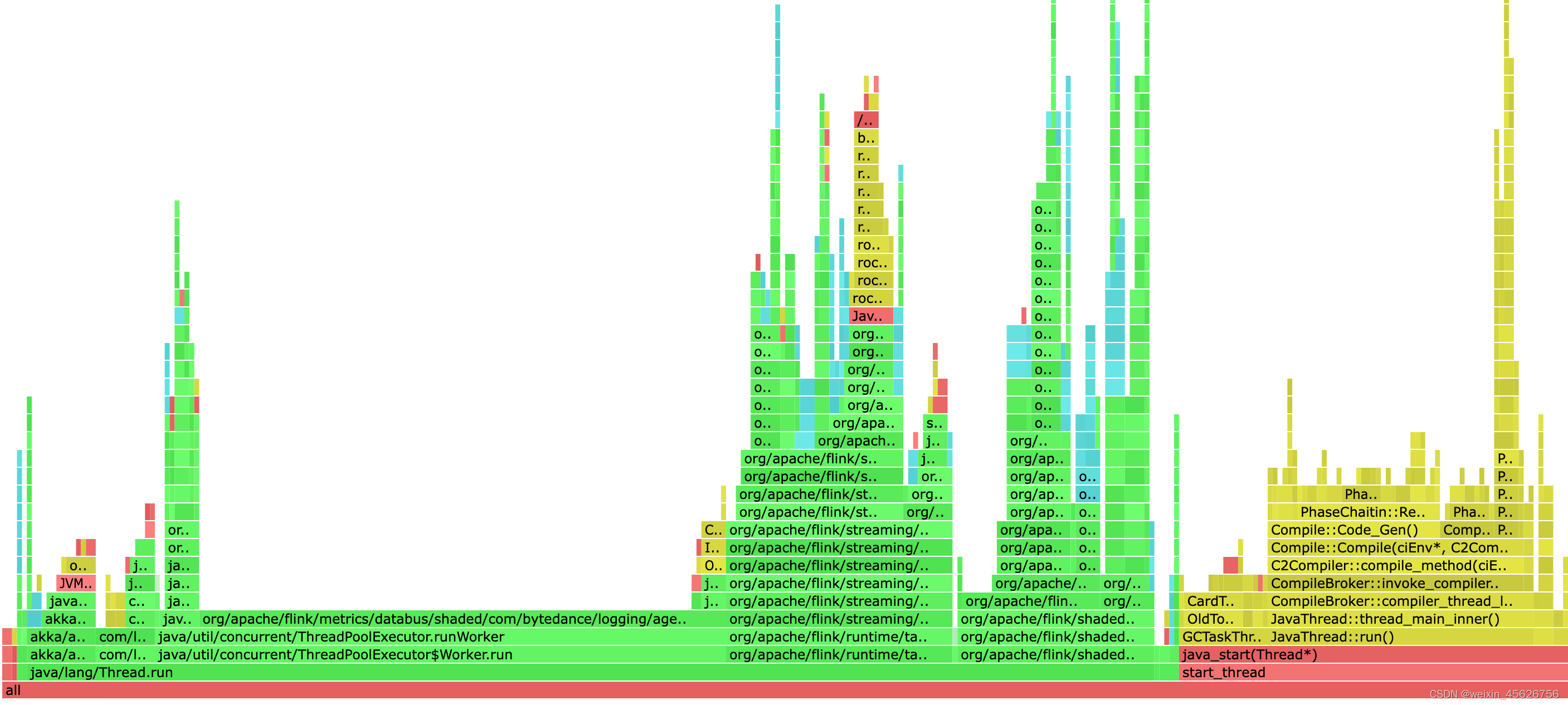

SmartNews 基于 Flink 的 Iceberg 实时数据湖实践
摘要:本文整理自 SmartNews 数据平台架构师 Apache Iceberg Contributor 戢清雨,在 Flink Forward Asia 2022 实时湖仓专场的分享。本篇内容主要分为五个部分: SmartNews 数据湖介绍基于 Icebergv1 格式的数据湖实践基于 Flink 实时更新的数据…
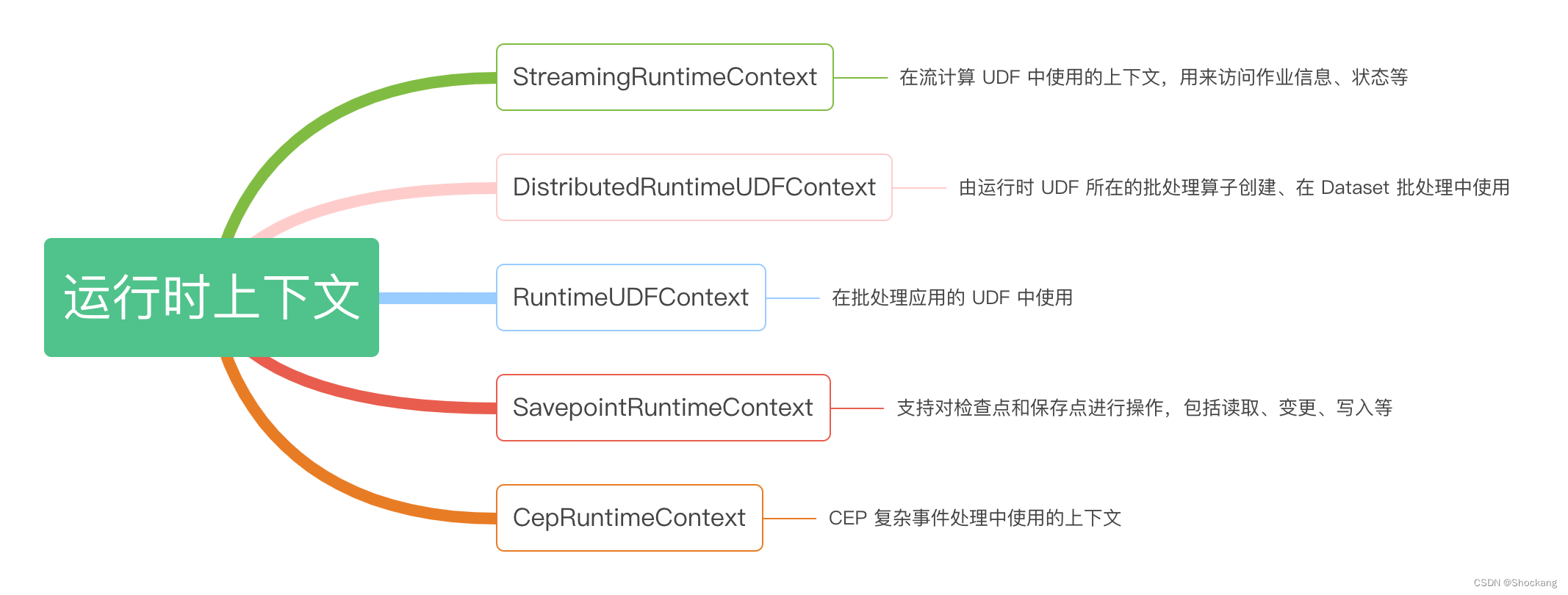
Flink 环境对象
前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见大数据技术体系 思维导图 总览
StreamExecutionEnvironment 是Flin…
Flink Table 数据类型 及Stream转Table实战 和 Flink假(模拟、mock)数据生成工具
列举的flink Table API的数据类型。并生成与这些类型匹配的数据。 同时比较了DataType或LoglicalType默认conversionClass与Flink Table API中规定的内部类型的conversionClass的异同。
一、添加maven pom依赖
用于生成假数据。 <dependency><groupId>net.datafa…

7.1、如何理解Flink中的时间语义
目录
1、如何理解Flink中的时间语义
2、实时计算时,应该如何选择时间语义?
3、时间语义与窗口的关系 1、如何理解Flink中的时间语义
flink作为流式计算引擎,提供了 两种时间语义 来对流式数据进行计算
事件时间(EventTime) : 事件产生的…

Flink1.17 笔记
main快捷键设置
wordcount
dataset API
package com.atguigu.wc;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.ap…
Flink流批一体计算(15):PyFlink Tabel API之SQL写入Sink
目录 举个例子
写入Sink的各种情况
1. 将结果数据收集到客户端
2. 将结果数据转换为Pandas DataFrame,并收集到客户端
3. 将结果写入到一张 Sink 表中
4. 将结果写入多张 Sink 表中 举个例子
将计算结果写入给 sink 表
#将Table API结果表数据写入sink表&…
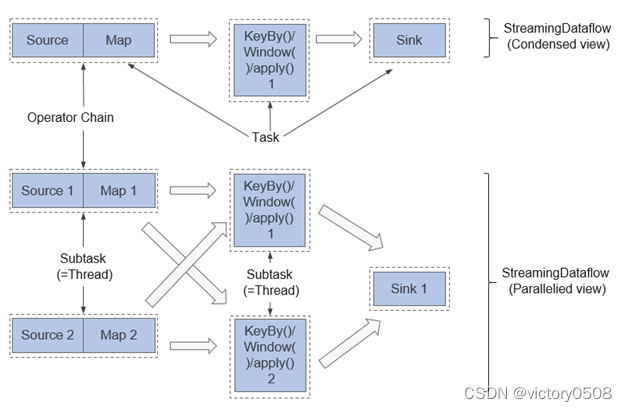
Flink流批一体计算(16):PyFlink DataStream API
目录 概述
Pipeline Dataflow
代码示例WorldCount.py
执行脚本WorldCount.py 概述
Apache Flink 提供了 DataStream API,用于构建健壮的、有状态的流式应用程序。它提供了对状态和时间细粒度控制,从而允许实现高级事件驱动系统。
用户实现的Flink程…

大数据-玩转数据-Flink时间滚动动窗口
一、说明
时间窗口包含一个开始时间戳(包括)和结束时间戳(不包括), 这两个时间戳一起限制了窗口的尺寸. 在代码中, Flink使用TimeWindow这个类来表示基于时间的窗口. 这个类提供了key查询开始时间戳和结束时间戳的方法, 还提供了针对给定的窗口获取它允许的最大时间戳的方法(m…

Flink_state 的优化与 remote_state 的探索
摘要:本文整理自 bilibili 资深开发工程师张杨,在 Flink Forward Asia 2022 核心技术专场的分享。本篇内容主要分为四个部分: 相关背景state 压缩优化Remote state 探索未来规划 点击查看原文视频 & 演讲PPT 一、相关背景 1.1 业务概况 从…
flink開啟歷史服務器
flink開啟歷史服務器
在flink-conf.yaml配置文件添加如下配置
# HistoryServer
#
# 指定由JobManager归档的作业信息所存放的目录,这里使用的是HDFS
jobmanager.archive.fs.dir: hdfs://mycluter:8020/flink/completed-jobs/
# History Server所绑定的ip
historys…

5小时玩转阿里云实时计算Flink实时湖仓之代码文档
文章目录 视频链接 bxg代码文档项目离线数据准备MySQL映射表流数据准备num.txtmakedata.log(空文件)start.shcreate-log.shinsert-data.sh 维表创建paimon_dim表mysql_to_paimon_dim任务 事实表ODS层ECS创建ods层kafka topickafka_ods表mysql_to_kafka_ods数据插入paimon_ods表…
Flink的简要概述
以下是Flink的各种架构的简要概述:
1. Flink概述:Apache Flink是一个开源的流处理和批处理框架,具有高性能、容错性和数据一致性保证。它支持事件驱动的流处理和批量处理,并提供了丰富的API和工具来处理实时数据流和大规模数据集…
Flink流批一体计算(17):PyFlink DataStream API之StreamExecutionEnvironment
目录 StreamExecutionEnvironment
Watermark
watermark策略简介
使用 Watermark 策略
内置水印生成器
处理空闲数据源
算子处理 Watermark 的方式
创建DataStream的方式
通过list对象创建
使用DataStream connectors创建
使用Table & SQL connectors…

美团2面:5个9高可用99.999%,如何实现?
说在前面
在40岁老架构师 尼恩的读者社区(50)中,最近有小伙伴拿到了一线互联网企业如网易、有赞、希音、百度、网易、滴滴的面试资格,遇到一几个很重要的面试题: 问题1:你们系统,高可用怎么实现? 问题2&am…
flink源码分析-获取最大可以打开的文件句柄
flink版本: flink-1.11.2
代码位置: org.apache.flink.runtime.util.EnvironmentInformation
调用位置: taskmanager启动类:
org.apache.flink.runtime.taskexecutor.TaskManagerRunner
long maxOpenFileHandles EnvironmentInformation.getOpenFileHandlesLimit();
…

大数据Flink(六十八):SQL Table 的基本概念及常用 API
文章目录
SQL & Table 的基本概念及常用 API
一、一个 Table API\SQL任务的代码结构
Flink实时计算中台Kubernates功能改造点
背景
平台为数据开发人员提供基本的实时作业的管理功能,其中包括jar、sql等作业的在线开发;因此中台需要提供一个统一的SDK支持平台能够实现flink jar作业的发布;绝大多数情况下企业可能会考虑Flink On Yarn的这个发布模式,但是伴随云原生的呼声越来越大,一些企业不希望部…
flink实现kafka、doris精准一次说明
前言说明:本文档只讨论数据源为kafka的情况实现kafka和doris的精准一次写入
flink的kafka连接器已经实现了自动提交偏移量到kafka,当flink中的数据写入成功后,flink会将这批次数据的offset提交到kafka,程序重启时,kafka中记录了当前groupId消费的offset位置,开始消费时将…

大数据组件-Flink环境搭建
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…
Flink---1、概述、快速上手
1、Flink概述
1.1 Flink是什么
Flink的官网主页地址:https://flink.apache.org/ Flink的核心目标是“数据流上有状态的计算”(Stateful Computations over Data Streams)。 具体说明:Apache Flink是一个“框架和分布式处理引擎”,用于对无界…
flink怎么会有这种问题
java.lang.NoSuchMehodError:org.apache.flink.configuration.coreoption.getParentFirstLOader
env.execute执行不了是什么鬼 我试图使用以下方法读取文件:
final ExecutionEnvironment env ExecutionEnvironment.getExecutionEnvironment(); DataSet line e…

Flink+Flink CDC版本升级的依赖问题总结
之前使用Flink1.13Flink CDC2.0同步MySQL数据,想测试一下最新的几个版本。但是各种依赖冲突的报错,经过一段时间的调试,终于解决,现在总结一下。
1、flink1.15前后jar包名称不一样
flink-streaming-java、flink-clients、flink-…
Flink动态更新维表
1.Lookup join 概念:Lookup join是针对于由作业流表触发,关联右侧维表来补全数据的场景 。
默认情况下,在流表有数据变更,都会触发维表查询(可以通过设置维表是否缓存,来减轻查询压力)…
26、Flink 的SQL之概览与入门示例
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

3. 自定义datasource
一、自定义DataSource
自定义DataSource有两大类:单线程的DataSource和多线程的DataSource 单线程:继承 SourceFunction 多线程:继承 ParallelSourceFunction,继承 RichParallelSourceFunction(可以有其他的很多操…
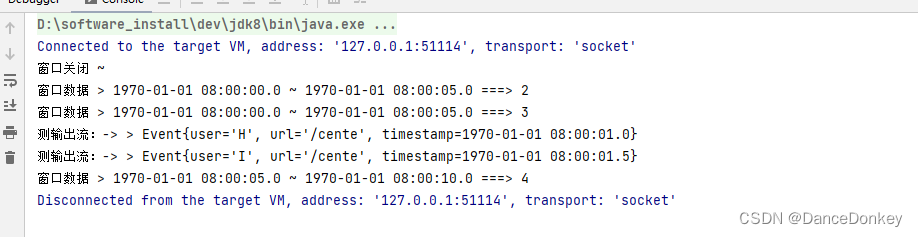
窗口延时、侧输出流数据处理
一 、 AllowedLateness API 延时关闭窗口
AllowedLateness 方法需要基于 WindowedStream 调用。AllowedLateness 需要设置一个延时时间,注意这个时间决定了窗口真正关闭的时间,而且是加上WaterMark的时间,例如 WaterMark的延时时间为2s&…
【云原生】Docker-compose部署flink
docker-compose 部署flink集群_docker-compose flink-CSDN博客 Apache Flink的数据流编程模型在有限和无限数据集上提供单次事件(event-at-a-time)处理。在基础层面,Flink程序由流和转换组成。 Apache Flink的API:有界或无界数据流…

Flink JobManager的高可用配置
背景
在flink执行中,jobManager是一个负责执行流式应用执行和检查点生成的组件,一旦发生故障,那么其负责的所有应用都会被取消,所以我们需要对JobManager配置高可用的模式
JobManager高可用配置
配置JobManager的高可用需要使用…
flink 1.14 编译
编译命令 mvn clean package -DskipTests -Dcheckstyle.skiptrue -Drat.skiptrue -T 8 指定 hadoop 版本 mvn clean install -DskipTests -Dhadoop.version2.7.3 -Dcheckstyle.skip -Drat.skiptrue -Dspotless.check.skiptrue -T 8 注意点
-DskipTests 与 -Dmaven.test.skiptr…

大数据-玩转数据-Flink状态后端(下)
一、状态后端
每传入一条数据,有状态的算子任务都会读取和更新状态。由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务(子任务)都会在本地维护其状态,以确保快速的状态访问。
状态的存储、访问以及维护,由一个…
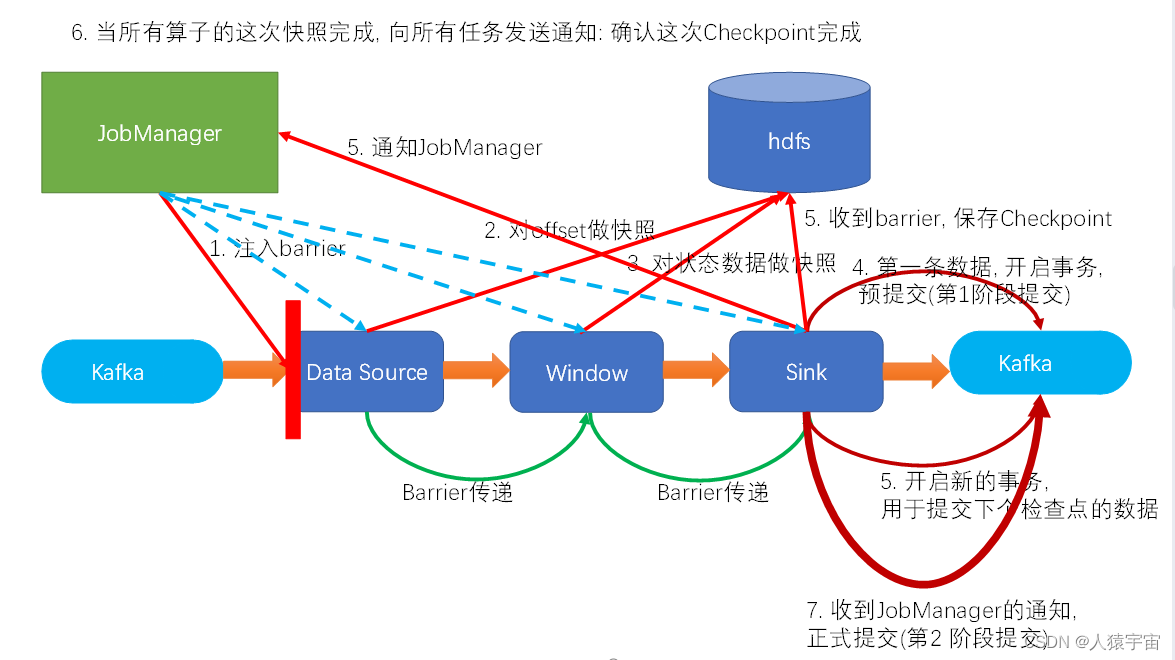
大数据-玩转数据-Flink 容错机制
一、概述
在分布式架构中,当某个节点出现故障,其他节点基本不受影响。在 Flink 中,有一套完整的容错机制,最重要就是检查点(checkpoint)。
二、检查点(Checkpoint)
在流处理中&am…

Flink DataStream 体系
前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见大数据技术体系 思维导图 正文
对 Flink 这种以流为核心的分布式计…
flink MemoryStateBackend 和 RocksDBStateBackend 切换导致任务出现bug
这两个stateBackend有什么区别
速度和大小的区别
RocksDBStateBackend 会多出序列化,反序列化 所以性能更差,但是他可以支撑很大的状态.
和任务代码相关,可能导致bug 测试不同状态后端(注意开启checkpoint),使用 map_dp.get(key).append(value) 的效果是否相同其中 value是…

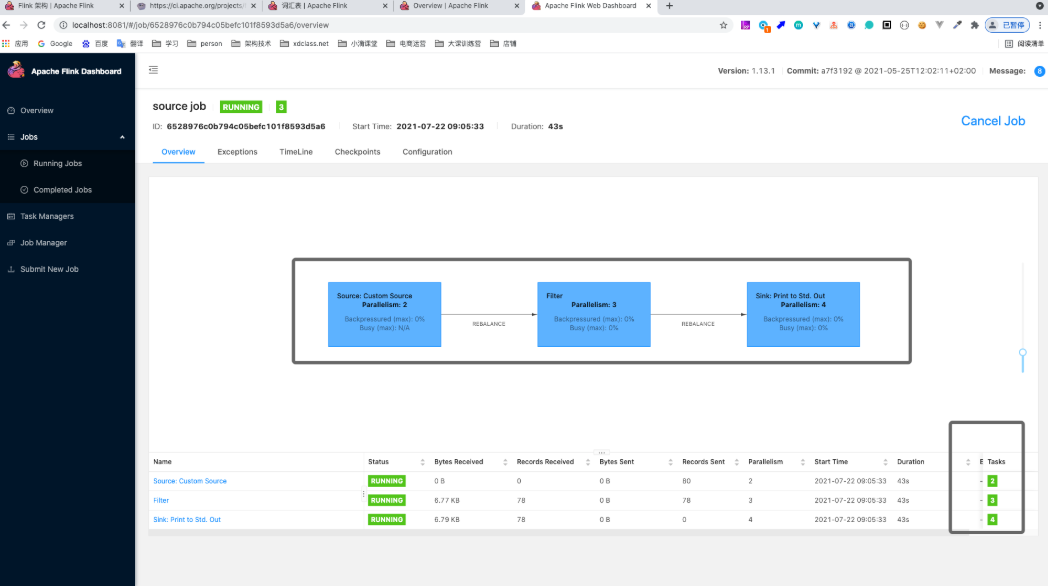
【Flink实战】Flink自定义的Source 数据源案例-并行度调整结合WebUI
🚀 作者 :“大数据小禅” 🚀 文章简介 :【Flink实战】玩转Flink里面核心的Source Operator实战 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 目录导航 什么是Flink的并行度Flink自定义的Source 数据…

6、如何将 Flink 中的数据写入到外部系统(文件、MySQL、Kafka)
目录
1、如何查询官网
2、Flink数据写入到文件
3、Flink数据写入到Kafka
4、Flink数据写入到MySQL 1、如何查询官网
官网链接:官网 2、Flink数据写入到文件
传送门:Flink数据写入到文件
3、Flink数据写入到Kafka
传送门:Flink数据写入…
flink连接kafka报:org.apache.kafka.common.errors.TimeoutException
测试flink1.12.7 连接kafka:
package org.test.flink;import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutio…
【Flink】 FlinkCDC读取Mysql( DataStream 方式)(带完整源码,直接可使用)
简介: FlinkCDC读取Mysql数据源,程序中使用了自定义反序列化器,完整的Flink结构,开箱即用。
本工程提供
1、项目源码及详细注释,简单修改即可用在实际生产代码
2、成功编译截图
3、自己编译过程中可能出现的问题
4、mysql建表语句及测试数据
5、修复FlinkCDC读取Mys…
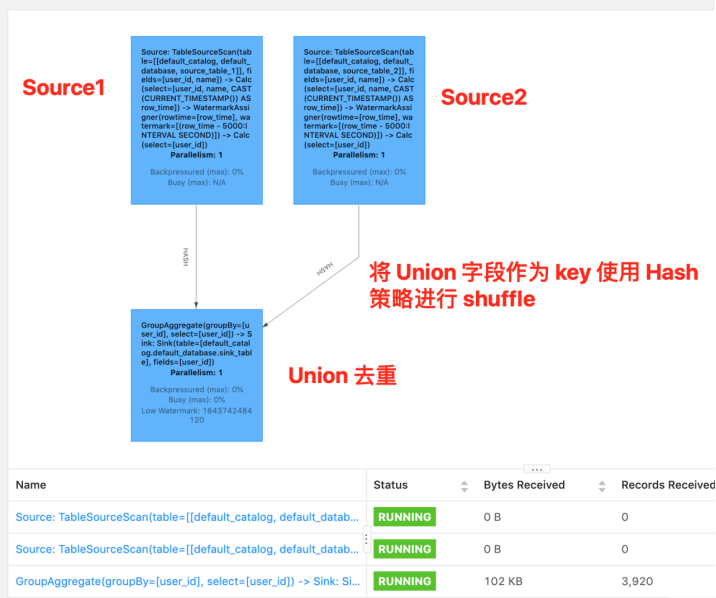

【Flink】FlinkCDC获取mysql数据时间类型差8小时时区解决方案
1、背景:
在我们使用FlinkCDC采集mysql数据的时候,日期类型是我们很常见的类型,但是FlinkCDC读取出来会和数据库的日期时间不一致,情况如下
FlinkCDC获取的数据中create_time字段1694597238000转换为时间戳2023-09-13 17:27:18 而数据库中原始数据如下,并没有到下午5点…

7.2、如何理解Flink中的水位线(Watermark)
目录
0、版本说明
1、什么是水位线?
2、水位线使用场景?
3、设计水位线主要为了解决什么问题?
4、怎样在flink中生成水位线?
4.1、自定义标记 Watermark 生成器
4.2、自定义周期性 Watermark 生成器
4.3、内置Watermark生…
org.apache.flink.table.api.TableException: Sink does not exists
FlinkSQL_1.12_用DDL实现Kafka到MySQL的数据传输_实现按照条件进行过滤写入MySQL_flink从kafka拉取数据并过滤数据写入mysql_旧城里的阳光的博客-CSDN博客
参考这篇文章,写了kafka到mysql的代码例子,因为自己改了表结构,运行下面代码&#x…

大数据Flink(八十七):DML:Joins之Regular Join
文章目录
DML:Joins之Regular Join DML:Joins之Regular Join
Flink 也支持了非常多的数据 Join 方式,主要包括以下三种: 动态表(流)与动态表(流)的 Join动态表(流)与外部维表(比如 Redis)的 Join动态表字段的列转行(一种特殊的 Join)细分 Flink SQL 支持的
【毕设选题】flink大数据淘宝用户行为数据实时分析与可视化
文章目录 0 前言1、环境准备1.1 flink 下载相关 jar 包1.2 生成 kafka 数据1.3 开发前的三个小 tip 2、flink-sql 客户端编写运行 sql2.1 创建 kafka 数据源表2.2 指标统计:每小时成交量2.2.1 创建 es 结果表, 存放每小时的成交量2.2.2 执行 sql &#x…
flink命令行提交jar包任务
1. 环境准备
1.1 flink环境准备
关于如何安装flink,这个写的非常详细,https://blog.csdn.net/qq_43699958/article/details/132826440 在flink的bin目录启动flink cluster
[rootlocalhost bin]# ./start-cluster.sh1.2 Linux环境准备
1.2.1 关闭linu…
Debezium实现mysql监听
pom:
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 ht…
【大数据面试题】002 Flink 如何实现 Exactly-Once 语义
一步一个脚印,一天一道大数据面试题。
在流式大数据处理框架中,Exactly-Once 语义对于确保每条数据精确地只被消费一次(避免重复读取和丢失读取)非常重要。下面将介绍 Flink 是如何实现 Exactly-Once 语义的。
尽管在程序正常运…
【nginx】starrocks通过nginx实现负载均衡、故障转移与flink运行SR实战
文章目录 一. 通过nginx实现starrocks负载均衡与故障转移1. 架构逻辑与nginx配置2. nginx相关知识:stream模块和http模块2.1. stream模块2.2. http模块 二. 使用flink 消费SR实战1. Expect: 100-continue 问题1.1. Expect: 100-continue的逻辑1.2. 问题分析与解决 2…
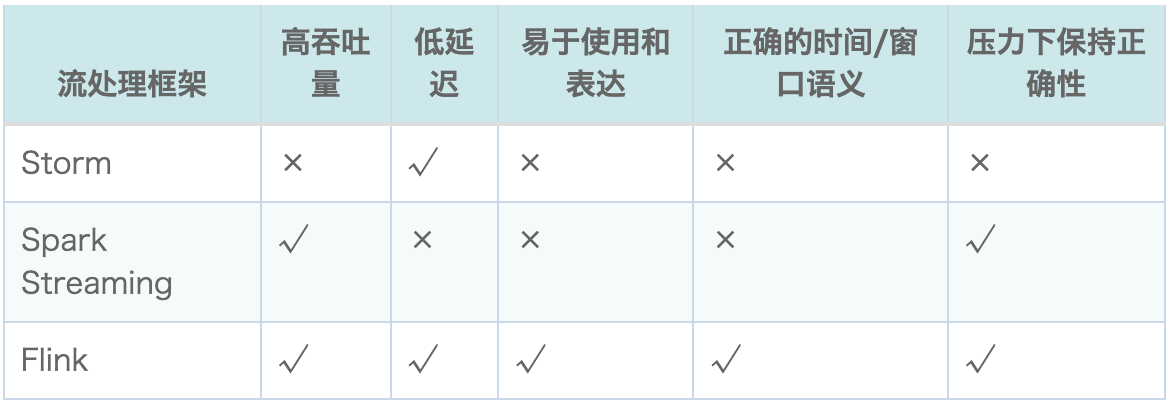
【Flink入门修炼】1-1 为什么要学习 Flink?
流处理和批处理是什么? 什么是 Flink? 为什么要学习 Flink? Flink 有什么特点,能做什么? 本文将为你解答以上问题。 一、批处理和流处理
早些年,大数据处理还主要为批处理,一般按天或小时定时处…
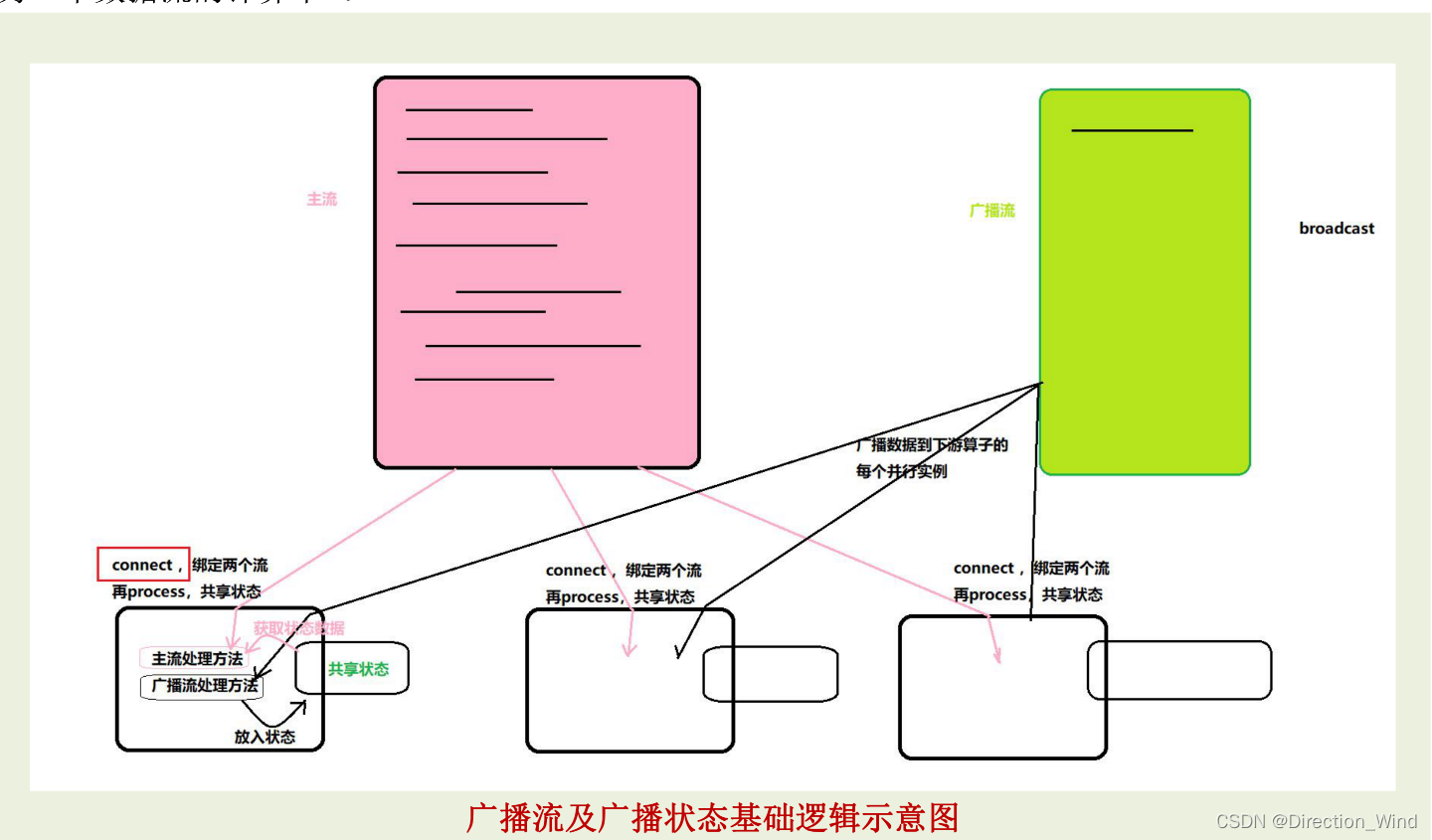
flink多流操作(connect cogroup union broadcast)
flink多流操作1 分流操作2 connect连接操作2.1 connect 连接(DataStream,DataStream→ConnectedStreams)2.2 coMap(ConnectedStreams → DataStream)2.3 coFlatMap(ConnectedStreams → DataStream)3 union操作3.1 uni…
基于apache paimon实时数仓全增量一体实时入湖
用例简介
Apache Paimon(以下简称 Paimon)作为支持实时更新的高性能湖存储,本用例展示了在千万数据规模下使用全量 增量一体化同步 MySQL 订单表到 Paimon明细表、下游计算聚合及持续消费更新的能力。整体流程如下图所示,其中 …
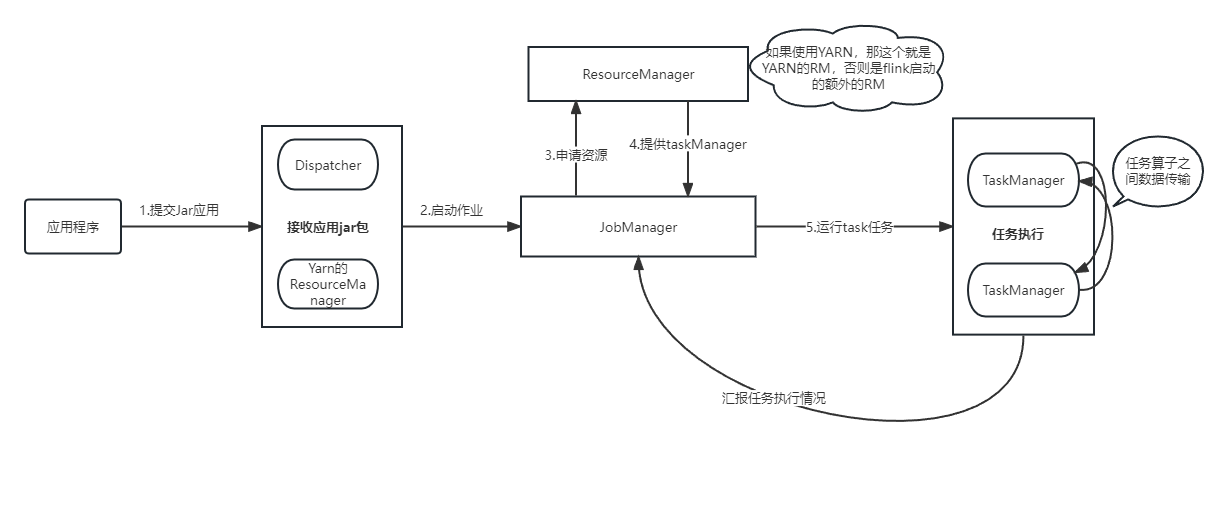
flink主要组件及高可用配置
背景
flink不论运行在哪种环境,例如Yarn,Mesos,Kebernute以及独立集群,每个应用都会包含重要的几个组件,本文就来讲述下flink的主要组件以及如何实现flink的高可用配置
flink主要组件 如图所示,flink主要…
在Flink中集成和使用Hudi
本文介绍在Flink 中集成和使用Hudi。介绍Flink如何将Streaming引入Hudi。在Hudi上使用Flink,并学习Flink读写Hudi的不同模式: Flink SQL客户端写入:Flink SQL客户端写入(读取)Hudi。 配置:对于全局配置,通过$FLINK_HOME/conf/FLINK-conf.yaml进行设置。对于每个作业配置…
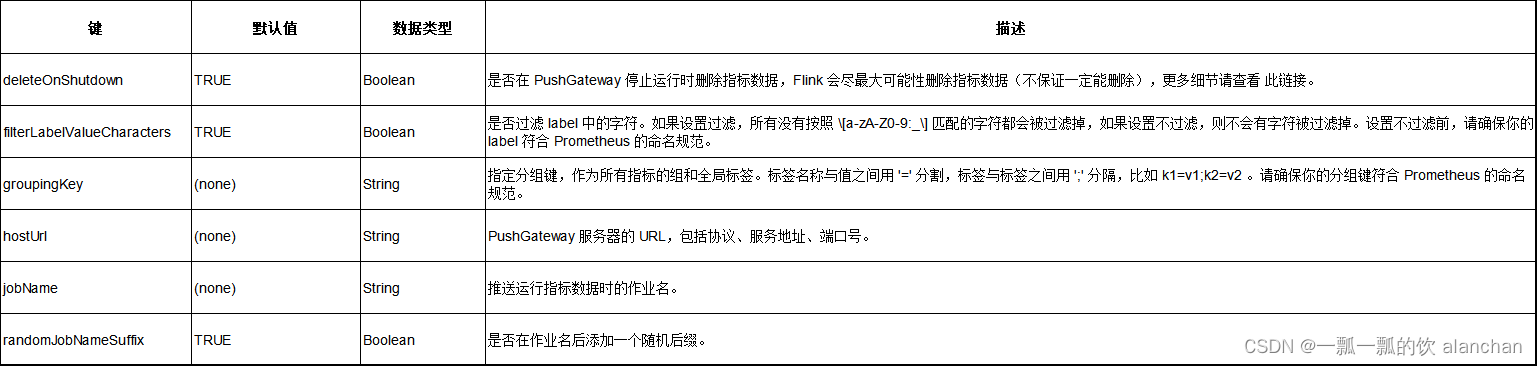
47、Flink 的指标报告介绍(graphite、influxdb、prometheus、statsd和datalog)及示例(jmx和slf4j示例)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
基于 Flink SQL 和 Paimon 构建流式湖仓新方案
目录
1. 数据分析架构演进
2. Apache Paimon
3. Flink + Paimon 流式湖仓
Consumer 机制
Changelog 生成编辑
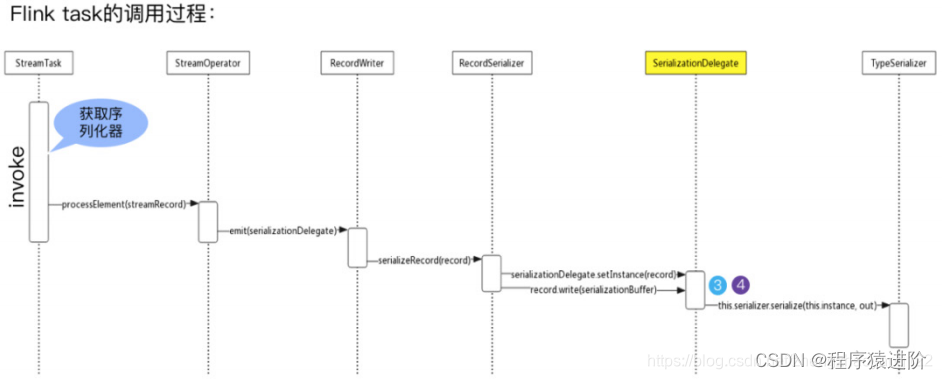
Flink 数据序列化
为 Flink 量身定制的序列化框架
大家都知道现在大数据生态非常火,大多数技术组件都是运行在JVM上的,Flink也是运行在JVM上,基于JVM的数据分析引擎都需要将大量的数据存储在内存中,这就不得不面临JVM的一些问题,比如Ja…

Flink大状态和Checkpoint调优
文章迁移,待整理
2. 状态和Checkpoint调优
2.1 大状态调优
我们生产大多数会使用 fsState ,memState程序挂了状态就丢了,应该没人会在生产使用,但是涉及到一些大状态,fsState效率很低,这时候会选择 roc…
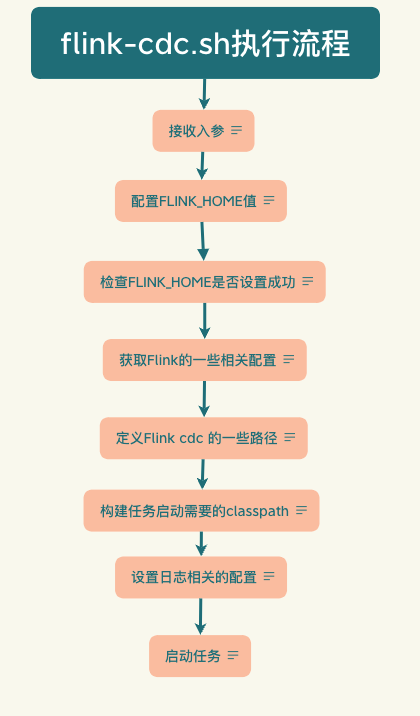
flinkcdc 3.0 源码学习之任务提交脚本flink-cdc.sh
大道至简,用简单的话来描述复杂的事,我是Antgeek,欢迎阅读. 在flink 3.0版本中,我们仅通过一个简单yaml文件就可以配置出一个复杂的数据同步任务, 然后再来一句 bash bin/flink-cdc.sh mysql-to-doris.yaml 就可以将任务提交, 本文就是来探索一下这个shell脚本,主要是研究如何通…
大数据-玩转数据-Flink页面广告点击量统计
一、应用场景
电商网站的市场营销商业指标中,除了自身的APP推广,还会考虑到页面上的广告投放(包括自己经营的产品和其它网站的广告)。所以广告相关的统计分析,也是市场营销的重要指标。 对于广告的统计,最…
Flink中的批和流
批处理的特点是有界、持久、大量,非常适合需要访问全部记录才能完成的计算工作,一般用于离线统计。 流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。 而在Flin…

大数据-玩转数据-Flink恶意登录监控
一、恶意登录
对于网站而言,用户登录并不是频繁的业务操作。如果一个用户短时间内频繁登录失败,就有可能是出现了程序的恶意攻击,比如密码暴力破解。 因此我们考虑,应该对用户的登录失败动作进行统计,具体来说&#x…
Flink RowData 与 Row 相互转化工具类
RowData与Row区别
(0)都代表了一条记录。都可以设置RowKind,和列数量Aritry。 (1)RowData 属于Table API,而Row属于Stream API (2)RowData 属于Table内部接口,对用户不友…

Flink——Flink检查点(checkpoint)、保存点(savepoint)的区别与联系
Flink checkpoint
Checkpoint是Flink实现容错机制最核心的功能,能够根据配置周期性地基于Stream中各个Operator的状态来生成Snapshot,从而将这些状态数据定期持久化存储下来,从而将这些状态数据定期持久化存储下来,当Flink程序一…
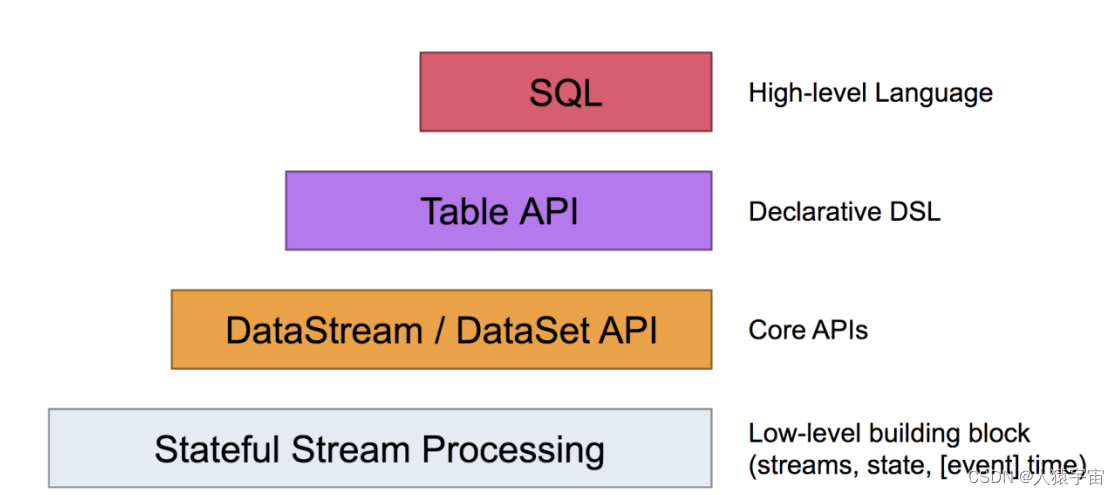
大数据-玩转数据-Flink SQL编程
一、概念 1.1 Apache Flink 两种关系型 API
Apache Flink 有两种关系型 API 来做流批统一处理:Table API 和 SQL。 Table API 是用于 Scala 和 Java 语言的查询API,它可以用一种非常直观的方式来组合使用选取、过滤、join 等关系型算子。
Flink SQL 是…
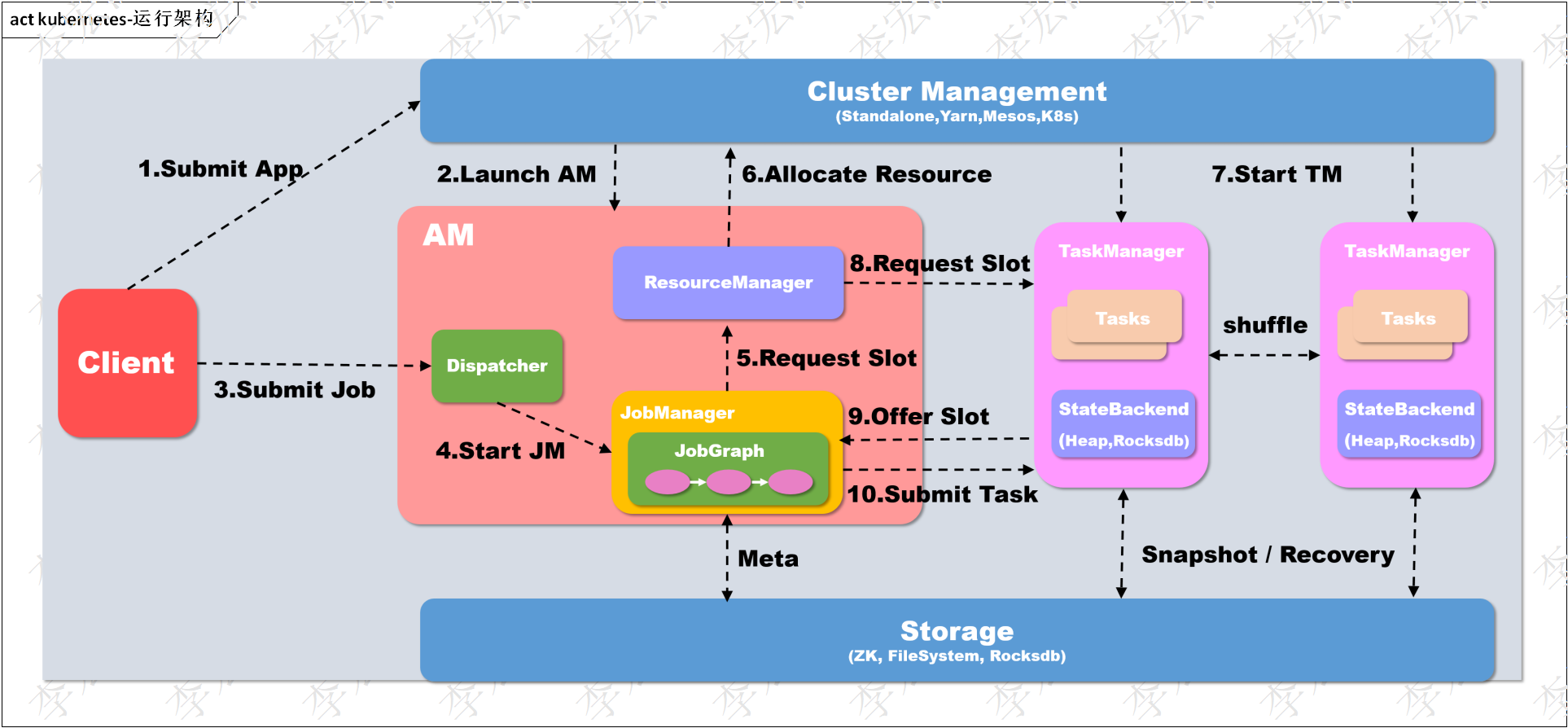
flink集群与资源@k8s源码分析-总述
1 简介
集群和资源模块提供动态资源能力,是分布式系统关键基础设施,分布式datax,分布式索引,事件引擎都需要集群和资源的弹性资源能力,提高伸缩性和作业处理能力。本文分析flink的集群和资源的k8s模块,深入了解其设计原理,为开发自有的集群和资源组件做技术准备, 同时涉…
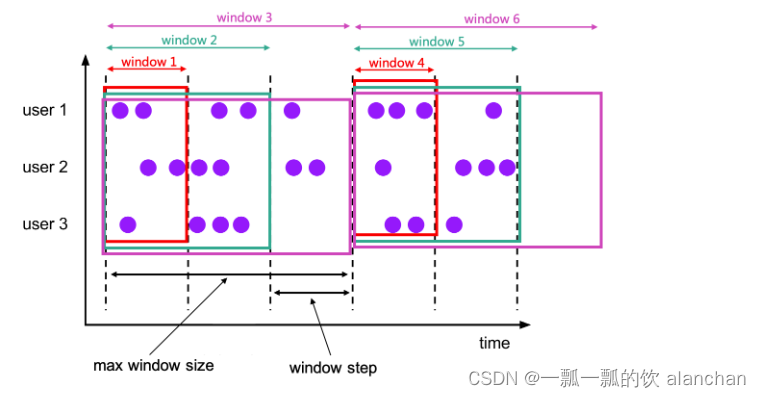
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
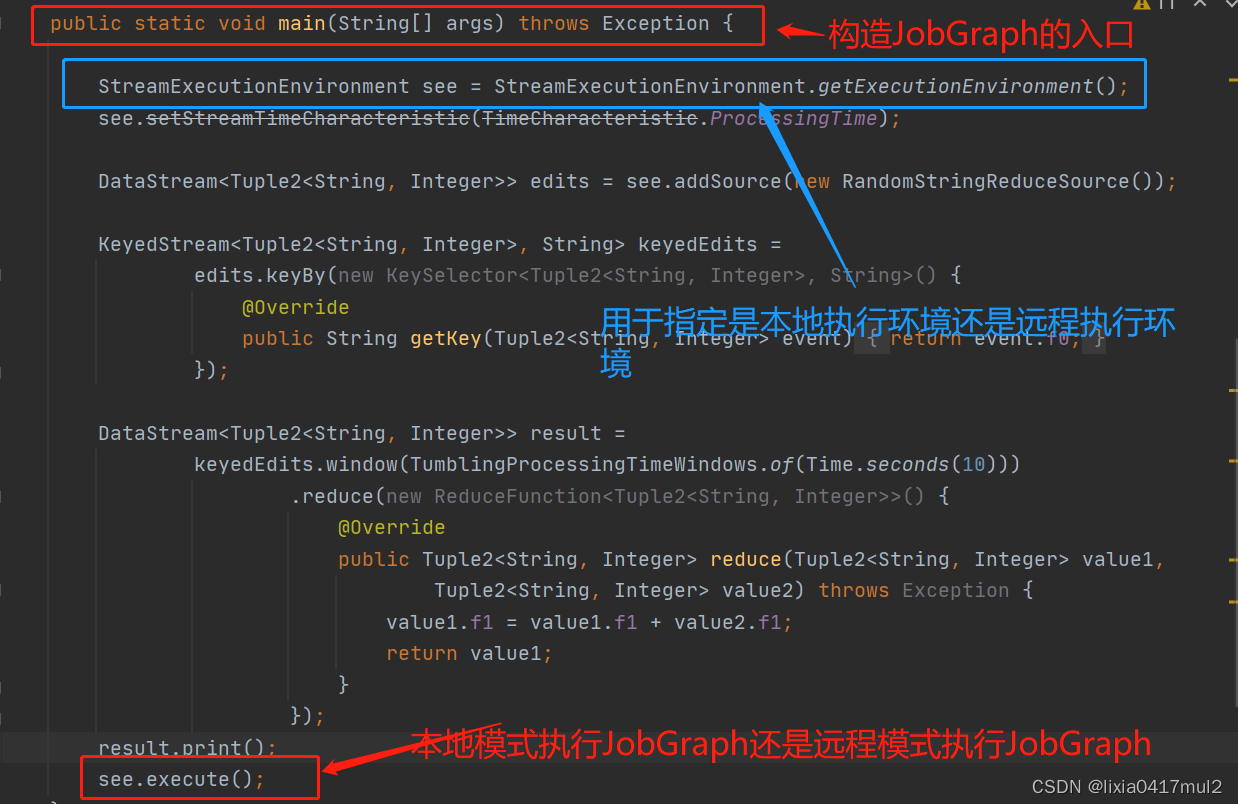
flink的main方法和execute方法的关系
背景:
执行flink时,我们几种执行模式,比如在IDE本地执行模式以及远程YARN执行的模式等,你是否有疑问,为什么他们可以共用相同的代码呢?其实这就涉及到main方法和execute方法的关系了
flink的main方法和ex…
flink中cpu消耗的大户-序列化和反序列化
背景
故事的起源来源于这样一篇关于序列化/反序列化优化的文章https://www.ververica.com/blog/a-journey-to-beating-flinks-sql-performance,当把传输的对象从String变成byte[]数组后,QPS直接提升了50%
flink的网络数据交换优化
在flink中对于每个算子之间的跨…
Flink-CDC 抽取SQLServer问题总结
Flink-CDC 抽取SQLServer问题总结
背景 flink-cdc 抽取数据到kafka 中,使用flink-sql进行开发,相关问题总结flink-cdc 配置SQLServer cdc参数
1.创建CDC 使用的角色, 并授权给其查询待采集数据数据库 -- a.创建角色
create role flink_role;-- b.授权…
大数据Flink(八十八):Interval Join(时间区间 Join)
文章目录
Interval Join(时间区间 Join) Interval Join(时间区间 Join)
Interval Join 定义(支持 Batch\Streaming):Interval Join 在离线的概念中是没有的。Interval Join 可以让一条流去 Jo…

flink集群与资源@k8s源码分析-运行时
1 运行时
运行时提供了Flink作业运行过程依赖的基础执行环境,包含Dispatcher、ResourceManager、JobManager和TaskManager等核心组件,本节分析资源相关运行时组件构建和启动。
flink没有使用spring,缺少ioc的构建过程相当复杂,所有依赖手动关联和置入,为了共享组件,fli…
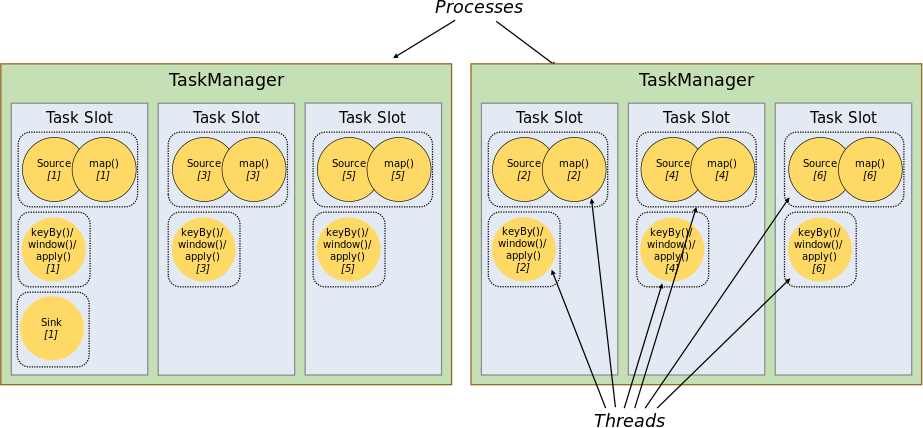
【大数据】Flink 详解(七):源码篇 Ⅱ
本系列包含:
【大数据】Flink 详解(一):基础篇【大数据】Flink 详解(二):核心篇 Ⅰ【大数据】Flink 详解(三):核心篇 Ⅱ【大数据】Flink 详解(四…
搭建Flink集群、集群HA高可用以及配置历史服务器
Flink集群搭建 Flink集群搭建集群规划下载并解压安装包修改集群配置分发安装目录启动集群访问Web UI Flink集群HA高可用概述集群规划配置flink配置master、workers配置ZK分发安装目录启动HA集群测试 Flink参数配置配置历史服务器概述配置启动、停止历史服务器提交一个Job任务查…
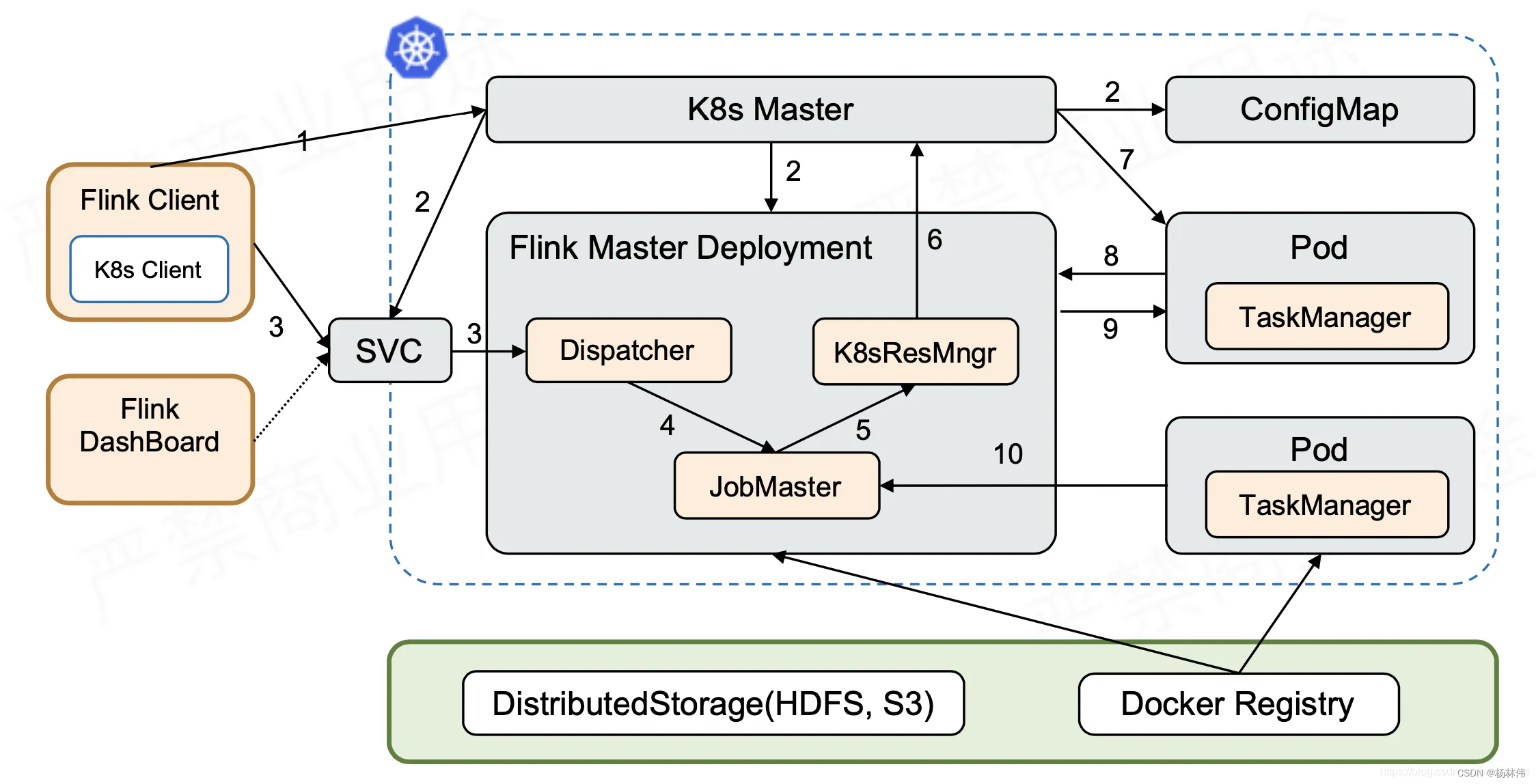
flink集群与资源@k8s源码分析-回顾
本章是分析系列最后一章,作为回顾,以运行架构图串联起所有分析场景
1 启动集群,部署集群(提交k8s),新建作业管理器组件
2 构建和启动flink master组件
3 提交作业,N/A
k8s 搭建基于session模式的flink集群
1.flink集群搭建
不废话直接上代码,都是基于官网的,在此记录一下 Kubernetes | Apache Flink
flink-configuration-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:name: flink-configlabels:app: flink
data:flink-conf.yaml: |jobmanager…
大数据面试题:Flink延迟数据是怎么解决的
最近朋友面试某猪的时候,被问到一个问题答得面试官不太满意,问的是前司数据延迟问题是怎么解决的,我稍作整理。
一、什么是延迟数据
大数据处理过程中 Join 的场景太多太多了,几乎所有公司的 APP 都会涉及到两条流数据之间的维度…

flink学习之广播流与合流操作demo
广播流是什么?
将一条数据广播到所有的节点。使用 dataStream.broadCast()
广播流使用场景?
一般用于动态加载配置项。比如lol,每天不断有人再投诉举报,客服根本忙不过来,腾讯内部做了一个判断,只有vip3…
flink cdc多种数据源安装、配置与验证
搜索 flink cdc多种数据源安装、配置与验证 文章目录 1. 前言2. 数据源安装与配置2.1 MySQL2.1.1 安装2.1.2 CDC 配置2.2 Postgresql2.2.1 安装2.2.2 CDC 配置2.3 Oracle2.3.1 安装2.3.2 CDC 配置2.4 SQLServer2.4.1 安装2.4.2 CDC 配置3. 验证3.1 Flink版本与CDC版本的对应关系…
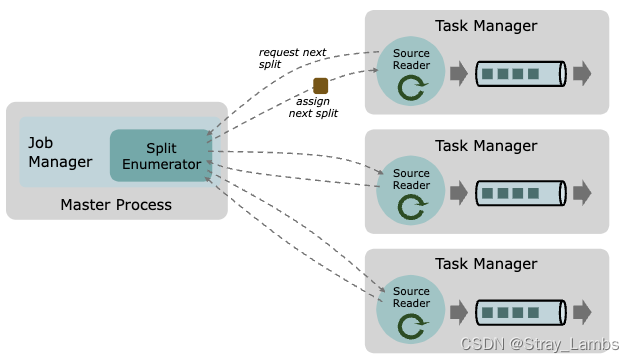
Flink1.14 Source概念入门讲解与源码解析
目录
Flink Source概念
Source
Source源码
getBoundedness()
createReader(SourceReaderContext readerContext)
createEnumerator(SplitEnumeratorContext enumContext)
SplitEnumerator restoreEnumerator(SplitEnumeratorContext enumContext, EnumChkT checkpoint) …

Flink Batch SQL Improvements on Lakehouse
本文整理自阿里云研发工程师刘大龙(风离),在 Streaming Lakehouse Meetup 的分享。内容主要分为三个部分: Flink Batch on Paimon 挑战Flink Batch 核心优化后续规划 点击查看原文视频 & 演讲PPT 一、Flink Batch on Paimon 挑…
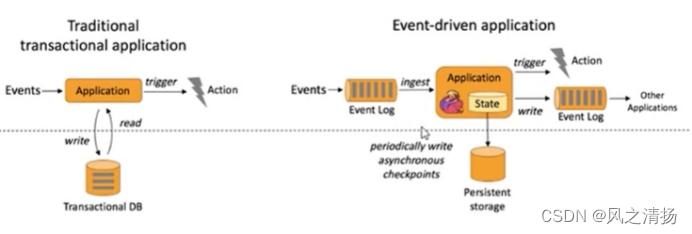
大数据flink篇之一-基础知识
一、起源
2010至2014年间,由柏林工业大学、柏林洪堡大学和哈索普拉特纳研究所联合发起名Stratosphere的研究项目。2014年4月,项目贡献给Apache基金会,成为孵化项目。更名为Flink2014年12月,成为基金会顶级项目2015年9月ÿ…
Flink-CDC——MySQL、SqlSqlServer、Oracle等数据库开启日志方法
文章目录
1. 前言
2. 数据源安装与配置
2.1 MySQL
2.1.1 安装
2.1.2 CDC 配置
2.2 Postgresql
2.2.1 安装
2.2.2 CDC 配置
2.3 Oracle
2.3.1 安装
2.3.2 CDC 配置
2.4 SQLServer
2.4.1 安装
2.4.2 CDC 配置
3. 验证
3.1 Flink版本与CDC版本的对应关系
3.2 下载…

大数据flink篇之二-基础实例wordcount
flink既支持批数据处理,也支持流数据处理。flink1.12版本后,批流进行了api统一。开发语言可以选择java和scala,这里选择java。下面以wordcount为例,讲解flink编程的流程。 开发前提:
ideamavenjdk 1.8
一、maven依赖…
flink 分区策略
背景
当使用DataStream操作流数据时,由于经过fliter操作后数据分布不均匀,或者由于下游的算子需要接收全部相同的数据,这样就有需要对数据进行分区操作,本文就介绍常见的几种分区策略
分区策略
1.使用DataStream.shuffle操作按…

大数据Flink(九十):Lookup Join(维表 Join)
文章目录
Lookup Join(维表 Join) Lookup Join(维表 Join)
Lookup Join 定义(支持 Batch\Streaming):Lookup Join 其实就是维表 Join,比如拿离线数仓来说,常常会有用户画像,设备画像等数据,而对应到实时数仓场景中,这种实时获取外部缓存的 Join 就叫做维表 Join。…
flink的序列化基准测试
背景:
flink提供了在本地环境使用jmh测试不同序列化方法的性能差异,本文就是基于这个https://github.com/apache/flink-benchmarks这个性能测试,总结几个结论,以便后面使用时避免掉坑
基准测试
我们本次运行的是SerializationF…

大数据Flink(八十九):Temporal Join(快照 Join)
文章目录
Temporal Join(快照 Join) Temporal Join(快照 Join)
Temporal Join 定义(支持 Batch\Streaming):Temporal Join 在离线的概念中其实是没有类似的 Join 概念的,但是离线中常常会维护一种表叫做 拉链快照表,使用一个明细表去 join 这个 拉链快照表 的 join …
修炼k8s+flink+hdfs+dlink(一:安装flink)
一:standalone的ha环境部署。
创建目录,上传安装包。
mkdir /opt/app/flink
上传安装包到本目录。
tar -zxvf flink-1.13.6-bin-scala_2.12.tgz配置参数。 在flink-conf.yaml中添加zookeeper配置
jobmanager.rpc.address: node01
high-availability: …
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
Flink on yarn 实战和源码分析
版本:1.13.6 目录
Flink on yarn 的3种模式的使用
yarn session 模式源码分析
yarn per-job模式源码分析
application模式源码分析 Flink on yarn 的3种模式的使用
Application Mode #
./bin/flink run-application -t yarn-application ./examples/streaming…
Flink-CDC——MySQL、SqlSqlServer、Oracle、达梦等数据库开启日志方法
目录
1. 前言
2. 数据源安装与配置
2.1 MySQL
2.1.1 安装
2.1.2 CDC 配置
2.2 Postgresql
2.2.1 安装
2.2.2 CDC 配置
2.3 Oracle
2.3.1 安装
2.3.2 CDC 配置
2.4 SQLServer
2.4.1 安装
2.4.2 CDC 配置
2.5达梦
2.4.1安装
2.4.2CDC配置
3. 验证
3.1 Flink版…

7、如何使用Flink中的窗口(Window算子)
目录
1、如何理解 Flink中的窗口(window)
2、Flink中窗口的类型
2.1 根据上游DataStream类型分类
2.2 根据驱动类型分类
2.3 根据进入到窗口数据的分发规则分类
3、怎样使用 Flink中的 Window算子
4、怎样使用 Flink中的 Window Assigners
4.1、…
flink sql 使用
1.准备工作 安装flink 1.16.2 将以下jar包放到/data/cmpt/flink-1.16.2/lib 目录下 antlr-runtime-3.5.2.jar
flink-connector-hive_2.12-1.16.2.jar
flink-connector-jdbc-1.16.2.jar
mysql-connector-java-6.0.6.jar
hive-exec-3.1.3.jar
libfb303-0.9.3.ja…
大数据-玩转数据-Flink Catalog
一、Catalog
Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。 数据处理最关键的方面之一是管理元数据。 元数据可以是临时的,例如临时表、或者通过 TableEnvironment 注册的 UDF。 元数据也可以是持…
flink选择slot
flink选择slot 在这个类里修改
package org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl;
findMatchingSlot(resourceProfile):找到满足要求的slot(负责从哪个taskmanager中获取slot)对应上图第8,9&…
大数据-玩转数据-Flink Sql 窗口
一、说明
时间语义,要配合窗口操作才能发挥作用。最主要的用途,当然就是开窗口然后根据时间段做计算了。Table API和SQL中,主要有两种窗口:分组窗口(Group Windows)和 含Over字句窗口(Over Win…

大数据Flink(九十五):DML:Window TopN
文章目录
DML:Window TopN DML:Window TopN
Window TopN 定义(支持 Streaming):Window TopN 是一种特殊的 TopN,它的返回结果是每一个窗口内的 N 个最小值或者最大值。
应用场景

大数据-玩转数据-双流JOIN
一、双流JOIN
在Flink中, 支持两种方式的流的Join: Window Join和Interval Join
二、Window Join
窗口join会join具有相同的key并且处于同一个窗口中的两个流的元素. 注意: 1.所有的窗口join都是 inner join, 意味着a流中的元素如果在b流中没有对应的, 则a流中这个元素就不会…
大数据-玩转数据-Flink 海量数据实时去重
一、海量数据实时去重说明
借助redis的Set,需要频繁连接Redis,如果数据量过大, 对redis的内存也是一种压力;使用Flink的MapState,如果数据量过大, 状态后端最好选择 RocksDBStateBackend; 使用布隆过滤器,…
从ContinuousEventTimeTrigger/ContinuousProcessingTimeTrigger代码看如何实现一个自定义的触发器
背景
当我们想要实现提前触发计算的触发器时,我们可以使用ContinuousEventTimeTrigger/ContinuousProcessingTimeTrigger作为触发器达到比如几分钟触发一次计算并发送计算结果的类,我们本文就从代码角度解析下实现自定义触发器的一些注意事项
Continuo…
Flink--9、双流联结(窗口联结、间隔联结)
星光下的赶路人star的个人主页 我还有改变的可能性,一想起这点,我就心潮澎湃 文章目录 1、基于时间的合流——双流联结(Join)1.1 窗口联结(Window Join)1.2 间隔联结(Interval Join)…
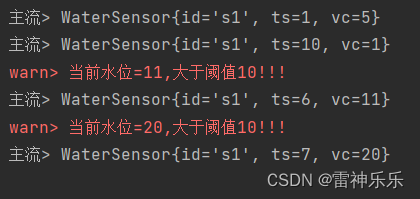
Flink的处理函数——processFunction
目录
一、处理函数概述
二、Process函数分类——8个
(1)ProcessFunction
(2)KeyedProcessFunction
(3)ProcessWindowFunction
(4)ProcessAllWindowFunction
ÿ…
Flink之Watermark策略代码模板
方式作用WatermarkStrategy.noWatermarks()不生成watermarkWatermarkStrategy.forMonotonousTimestamps()紧跟最大事件时间watermark生成策略WatermarkStrategy.forBoundedOutOfOrderness()允许乱序watermark生成策略WatermarkStrategy.forGenerator()自定义watermark生成策略 …
Flink+Doris 实时数仓
Flink+Doris 实时数仓
Doris基本原理
Doris基本架构非常简单,只有FE(Frontend)、BE(Backend)两种角色,不依赖任何外部组件,对部署和运维非常友好。架构图如下 可以 看到Doris 的数仓架构十分简洁,不依赖 Hadoop 生态组件,构建及运维成本较低。
FE(Frontend)以 Java 语…
【实战-07】flink 自定义Trigger 实现count 和timeout
有用的实战功能,搭配了适度源码讲解 背景代码番外篇: 聊聊eventTime迟到数据的时候什么时候清理窗口数据 背景
加入我们需要基于processTime 处理数据,使用5 分钟的滑动窗口。伪代码如下
window(TumblingProcessingTimeWindows.of(Time.min…
Flink session集群运维
1、集群job manager挂了
kubectl describe pod session-deployment-only-84b8d674c7-ckl9w -n flink kubectl get pod -n flink -owide kubectl describe pod session-deployment-only-84b8d674c7-ms758 -n flink
两个job manager都挂了
准备重新部署集群
删除操作(删除fli…
flinkcdc 体验
0 flink版本 踩雷
java代码操作 flink Table/SQL API 和 DataStream API 编写程序后,打成jar包丢到flink集群运行,报错首选需要考虑flink集群版本和 jar包中maven依赖的版本是否一致。 目前网上flink、flinkcdc相关博文绝大部分是基于flink1.13、1.14编…
Flink---14、Flink SQL(SQL-Client准备、流处理中的表、时间属性、DDL)
星光下的赶路人star的个人主页 你生而真实,而非完美 文章目录 1、Flink SQL1.1 SQL-Client准备1.1.1 基于yarn-session模式1.1.2 常用配置 1.2 流处理中的表1.2.1 动态表和持续查询1.2.2 将流转换为动态表1.2.3 用SQL持续查询1.2.4 将动态表转换为流 1.3 时间属性1.…
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
Flink之转换算子Transformation
转换算子Transformation 概述基本转换算子映射Map扁平映射flatMap过滤Filter 聚合算子按键分区keyBy归约聚合reduce简单聚合sum、min、max、minBy、maxBy 物理分区算子随机分配轮询分配重缩放广播全局分区自定义分区 分流操作Filter分流SideOutPut分流Split分流 合流操作联合Un…

优秀的推荐系统架构与应用:从YouTube到Pinterest、Flink和阿里巴巴
文章目录 🌟 业界经典:YouTube深度学习推荐系统的经典架构长什么样?🍊 基础架构🍊 深度学习模型🍊 额外组件 🌟 图神经网络:Pinterest如何应用图神经网络的?🍊…
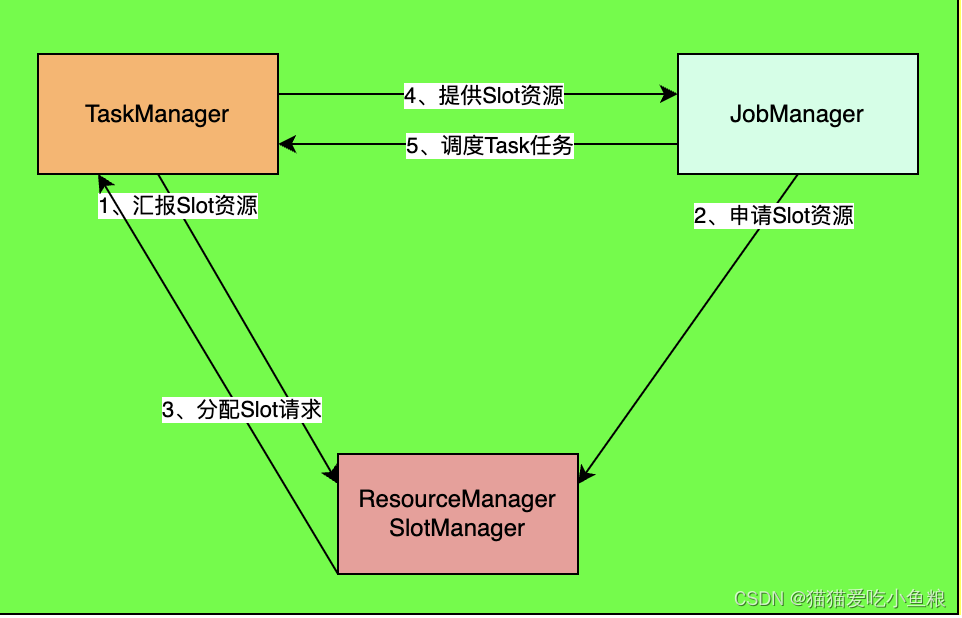
Flink 的集群资源管理
集群资源管理
一、ResourceManager 概述
1、ResourceManager 作为统一的集群资源管理器,用于管理整个集群的计算资源,包括 CPU资源、内存资源等。
2、ResourceManager 负责向集群资源管理器申请容器资源启动TaskManager实例,并对TaskManag…

Flink的算子列表状态的使用
背景
算子的列表状态是平时比较常见的一种状态,本文通过官方的例子来看一下怎么使用算子列表状态
算子列表状态
算子列表状态支持应用的并行度扩缩容,如下所示: 使用方法参见官方示例,我加了几个注解:
public class Bufferin…
Flink SQL 时区 -- 时间字符串转时间戳并转换时区
文章目录 一、数据需求:二、探索路程1、UNIX_TIMESTAMP CONVERT_TZ2、UNIX_TIMESTAMP 三、解决方案TIMESTAMPADD TO_TIMESTAMP 一、数据需求:
将时间字符串格式化,转变成时间戳,再加8小时后写入clickhouse
2023-10-17T03:00:4…
Flink1.14 SourceReader概念入门讲解与源码解析 (三)
目录
SourceReader 概念
SourceReader 源码方法
void start();
InputStatus pollNext(ReaderOutput output) throws Exception;
List snapshotState(long checkpointId);
CompletableFuture isAvailable();
void addSplits(List splits);
参考 SourceReader 概念
Sour…
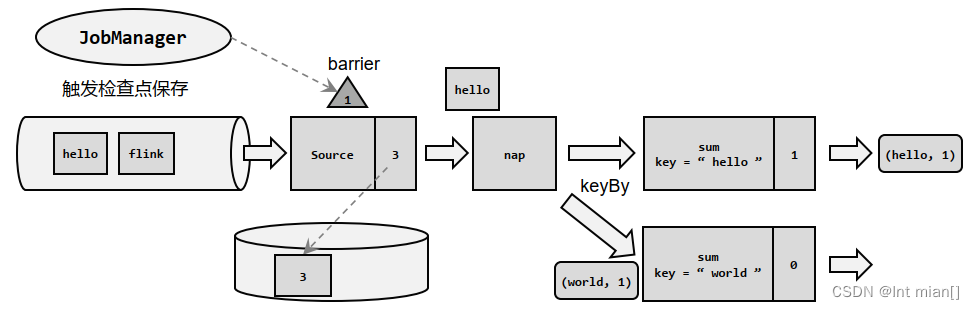
尚硅谷Flink(四)处理函数
目录 🦍处理函数 🐒基本处理函数 🐒按键分区处理函数(KeyedProcessFunction) 🐵定时器(Timer)和定时服务(TimerService) // 1、事件时间的案例 // 2、处理…

增加并行度后,发现Flink窗口不会计算的问题。
文章目录 前言一、现象二、结论三、解决 前言
窗口没有关闭计算的问题,一直困扰了很久,经过多次验证,确定了问题的根源。 一、现象
Flink使用了window,同时使用了watermark ,并且还设置了较高的并行度。生产是设置了…

大数据Flink(九十六):DML:Deduplication
文章目录
DML:Deduplication DML:Deduplication
Deduplication 定义(支持 Batch\Streaming):Deduplication 其实就是去重,也即上文介绍到的 TopN 中 row_number = 1 的场景,但是这里有一点不一样在于其排序字段一定是时间属性列,不能是其他非时间属性的普通列。在 ro…
32、Flink table api和SQL 之用户自定义 Sources Sinks实现及详细示例
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
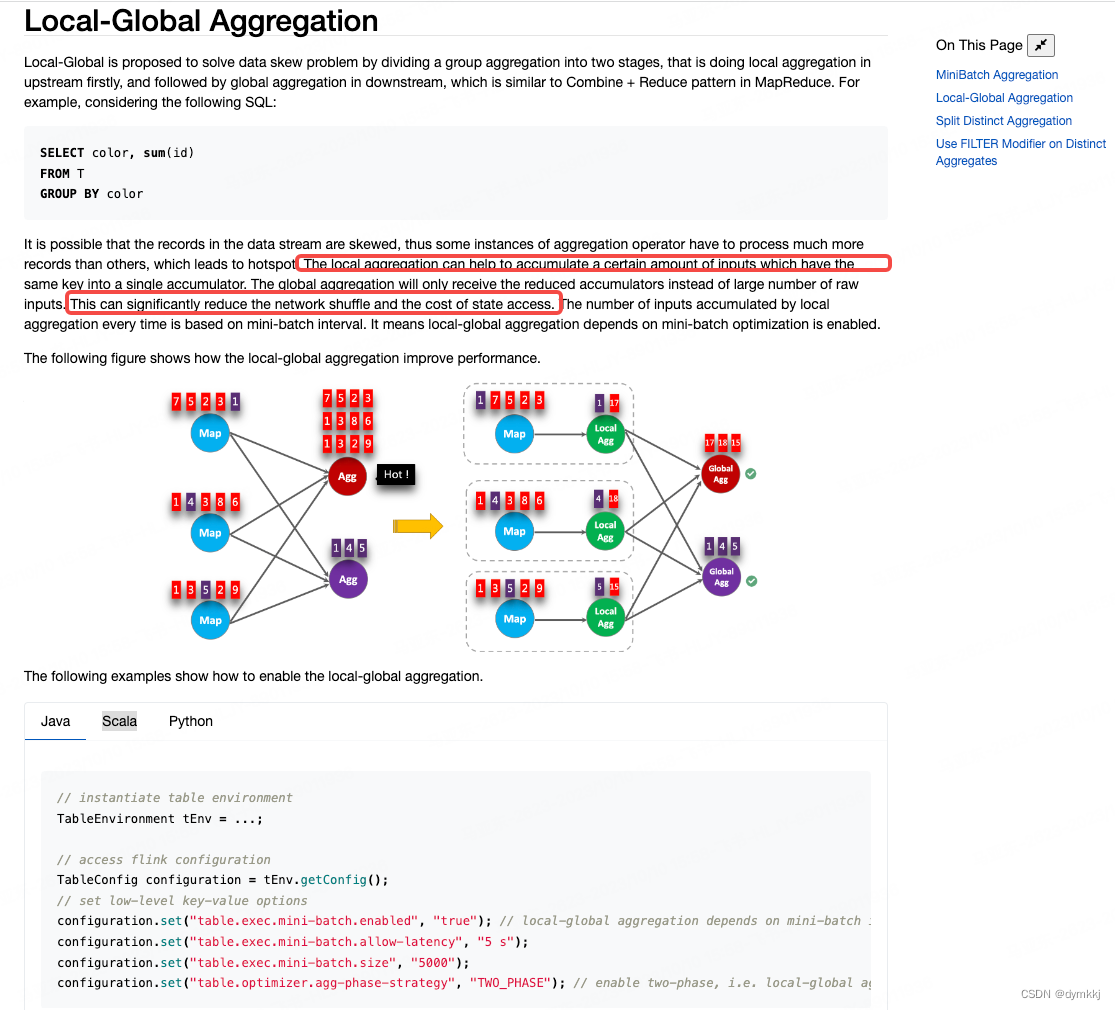
Flink-SQL join 优化 -- MiniBatch + local-global
背景
问题1. 近期在开发flink-sql期间,发现数据在启动后,任务总是进行重试,运行一段时间后,container心跳超时,内存溢出,作业无法进行正常工作
023-10-07 14:53:30,408 | INFO | [flink-akka.actor.defa…
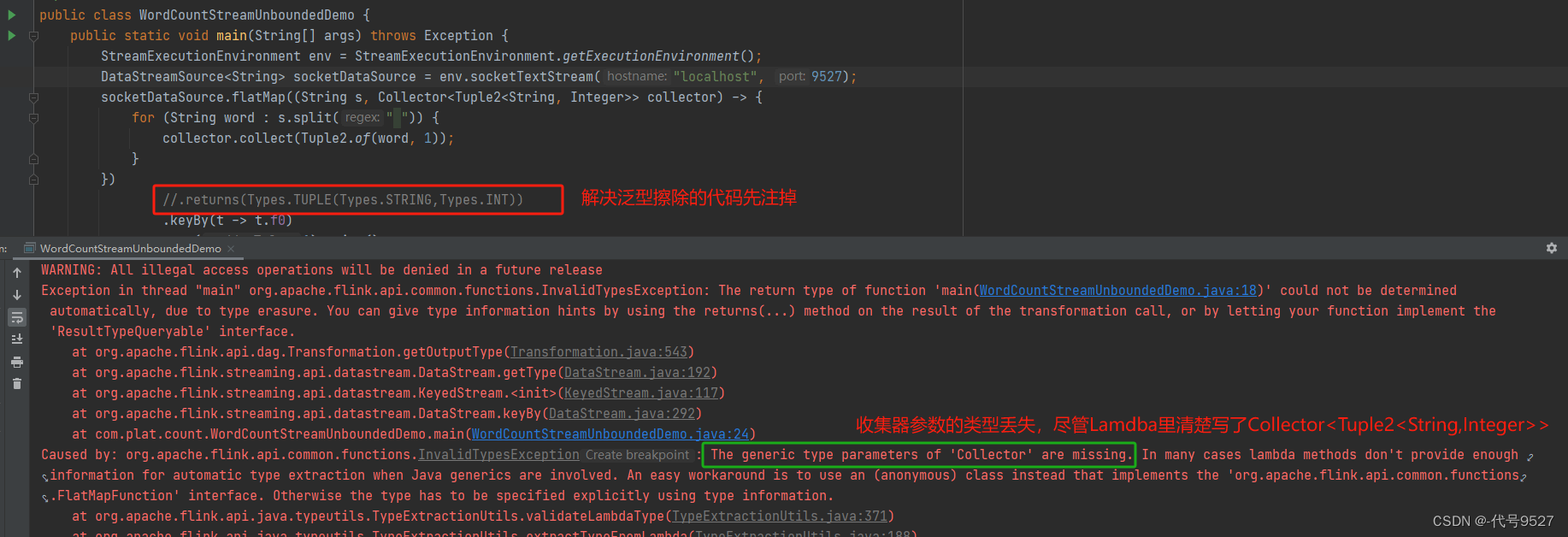
【基础篇】二、Flink的批处理和流处理API
文章目录 0、demo模块创建1、批处理有界流2、流处理有界流3、流处理无界流4、The generic type parameters of Collector are missing 0、demo模块创建
创建个纯Maven工程来做演示,引入Flink的依赖:(注意不同本版需要导入的依赖不一样&#…
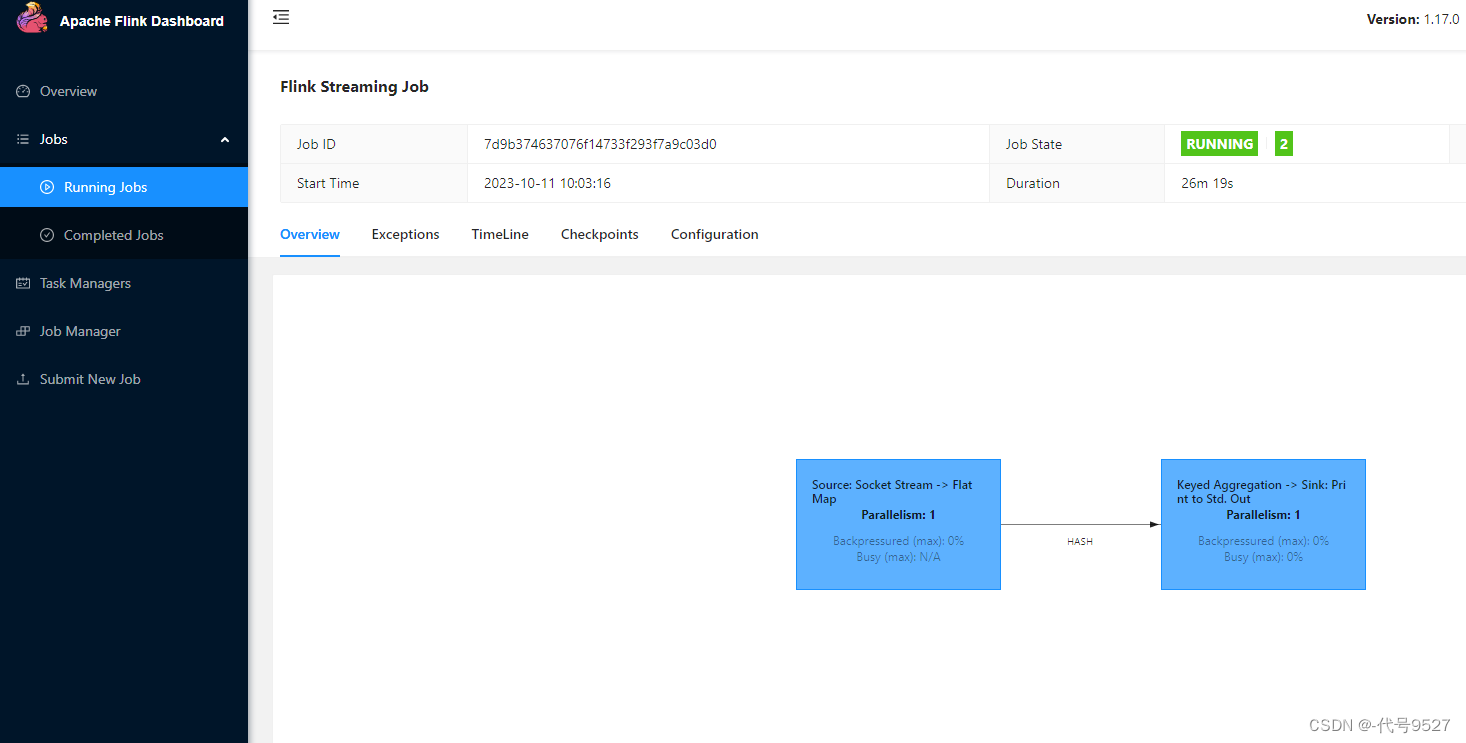
Flink报错could not be loaded due to a linkage failure
文章目录 1、报错2、原因3、解决 1、报错
在Flink上提交作业,点Submit没反应,F12看到接口报错信息为: 大概意思是,由于链接失败,无法加载程序的入口点类xx。没啥鸟用的信息,去日志目录继续分析:…
流式数据湖平台Hudi核心概念三:索引
1.索引 Hudi通过索引机制将给定的hoodie key(record key+分区路径)映射到文件id,实现了高效的upstart。一旦将记录的第一个版本写入文件,record key和文件组/文件id之间的映射就永远不会改变。简而言之,映射的文件组包含一组记录的所有版本。 对于Copy-On-Write表,可以实…
Flink Log4j 2.x使用Filter过滤日志类型
Flink Log4j 2.x使用Filter过滤日志类型(区别INFO、ERROR) 文章目录 Flink Log4j 2.x使用Filter过滤日志类型(区别INFO、ERROR)ThresholdFilterLevelMatchFilter 日志级别: ALL < TRACE < DEBUG < INFO < …
【基础篇】四、本地部署Flink
文章目录 1、本地独立部署会话模式的Flink2、本地独立部署会话模式的Flink集群3、向Flink集群提交作业4、Standalone方式部署单作业模式5、Standalone方式部署应用模式的Flink Flink的常见三种部署方式:
独立部署(Standalone部署)基于K8S部署…
Flink之DataStream API开发Flink程序过程与Flink常见数据类型
开发Flink程序过程与Flink常见数据类型 DataStream APIFlink三层APIDataStream API概述 开发Flink程序过程添加依赖创建执行环境执行模式创建Data Source应用转换算子创建Data Sink触发程序执行示例 Flink常见数据类型基本数据类型字符串类型时间和日期类型数组类型元组类型列表…
源码解析FlinkKafkaConsumer支持周期性水位线发送
背景
当flink消费kafka的消息时,我们经常会用到FlinkKafkaConsumer进行水位线的发送,本文就从源码看下FlinkKafkaConsumer.assignTimestampsAndWatermarks指定周期性水位线发送的流程
FlinkKafkaConsumer水位线发送
1.首先从Fetcher类开始,…
Linux运行环境搭建系列-Flink安装
Flink安装
## 下载
https://archive.apache.org/dist/flink/flink-1.16.2
## 解压
tar -zxvf flink-1.16.2-bin-scala_2.12.tgz && rm -rf flink-1.16.2-bin-scala_2.12.tgz
## 启动
cd flink-1.16.2/bin
## 修改/etc/hosts文件,把第一行的127.0.0.1改成自…

从Flink的Kafka消费者看算子联合列表状态的使用
背景
算子的联合列表状态是平时使用的比较少的一种状态,本文通过kafka的消费者实现来看一下怎么使用算子列表联合状态
算子联合列表状态
首先我们看一下算子联合列表状态的在进行故障恢复或者从某个保存点进行扩缩容启动应用时状态的恢复情况 算子联合列表状态主…
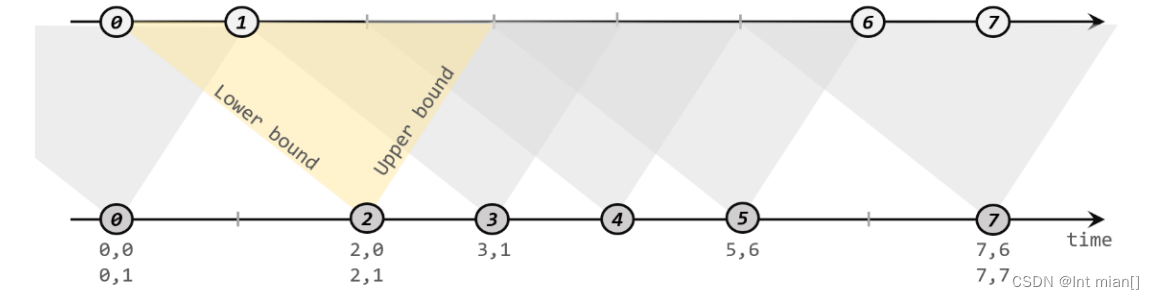
尚硅谷Flink(三)时间、窗口
1
🎰🎲🕹️ 🎰时间、窗口
🎲窗口
🕹️是啥
Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就…
Flink Data Sink
本专栏案例代码和数据集链接: https://download.csdn.net/download/shangjg03/88477960 1. Data Sinks 在使用 Flink 进行数据处理时,数据经 Data Source 流入,然后通过系列 Transformations 的转化,最终可以通过 Sink 将计算结果进行输出,Flink Data Sinks 就是用于定义…

识别flink的反压源头
背景
flink中最常见的问题就是反压,这种情况下我们要正确的识别导致反压的真正的源头,本文就简单看下如何正确识别反压的源头
反压的源头
首先我们必须意识到现实中轻微的反压是没有必要去优化的,因为这种情况下是由于偶尔的流量峰值,Task…
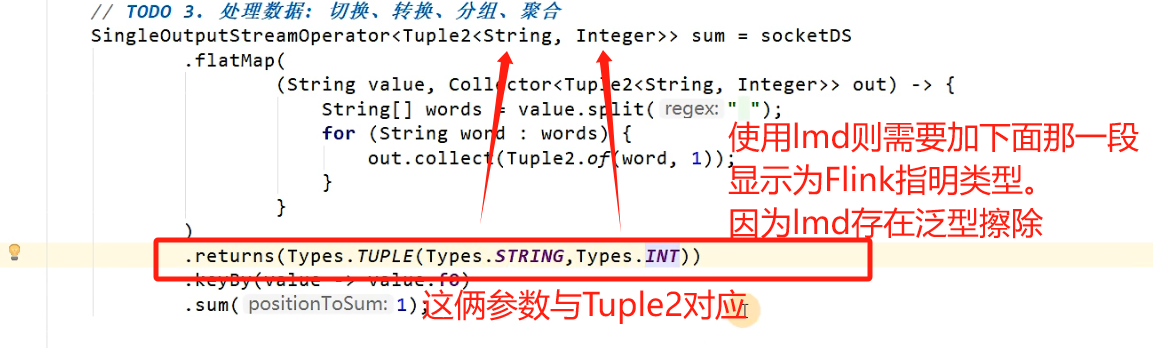
Java修仙传之Flink篇
大道三千:最近我修Flink 目前个人理解:
处理有界,无界流的工具
FLINK:
FLINK定义: Flink特点 Flink分层API 流的定义
有界数据流(批处理):
有界流:数据结束了,程序也…
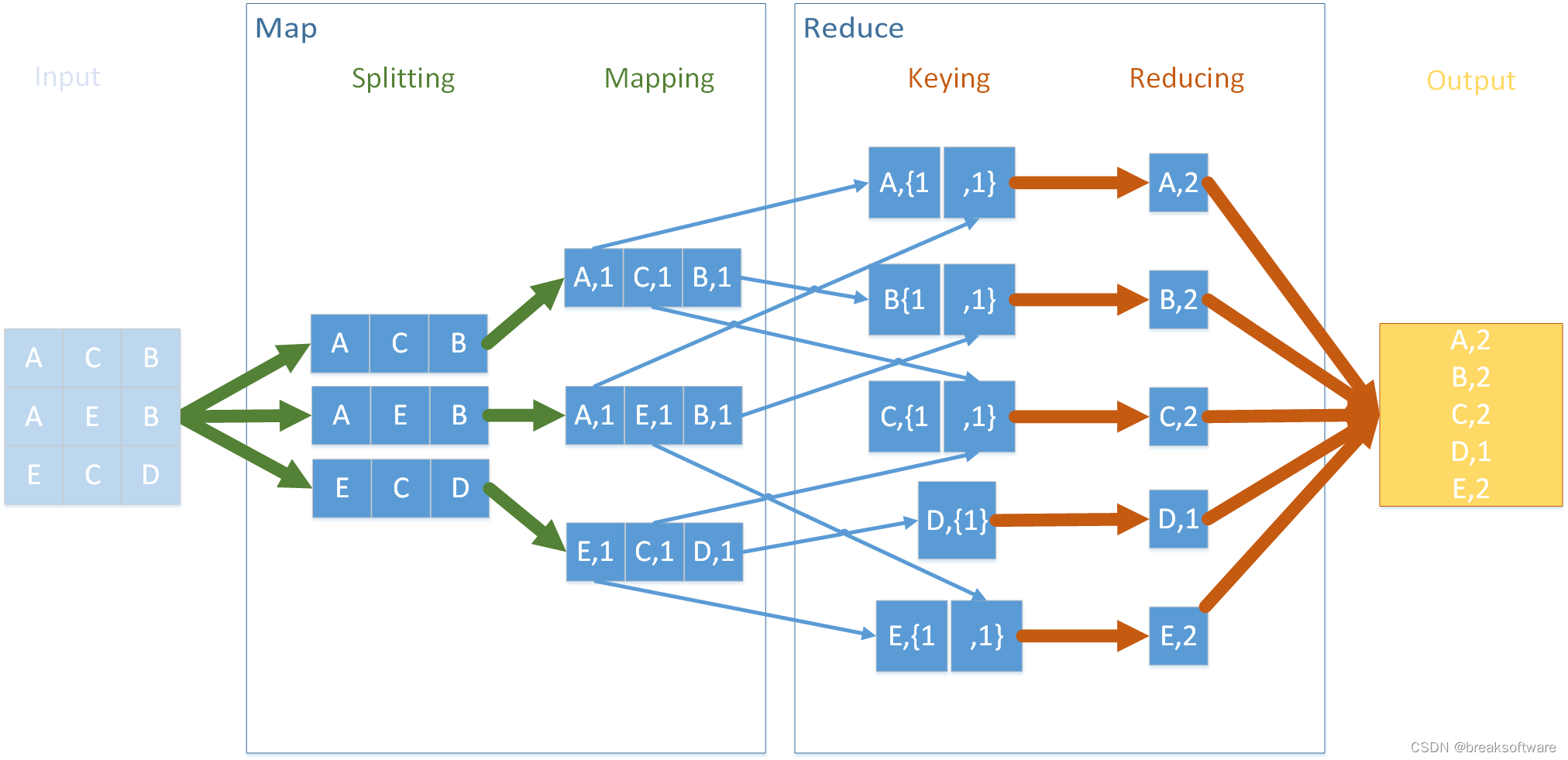
0基础学习PyFlink——使用DataStream进行字数统计
大纲 sourceMapSplittingMapping ReduceKeyingReducing 完整代码结构参考资料 在《0基础学习PyFlink——模拟Hadoop流程》一文中,我们看到Hadoop在处理大数据时的MapReduce过程。 本节介绍的DataStream API,则使用了类似的结构。
source
为了方便&…
flink常用的几种调优手段的优缺点
背景:
不管是基于减少反压还是基于减少端到端的延迟的目的,我们有时候都需要对flink进行调优,本文就整理下几种常见的调优手段以及他们的优缺点
flink调优手段
1.使用事件时间EventTime模式时,可以设置水位线发送的时间间隔,比…
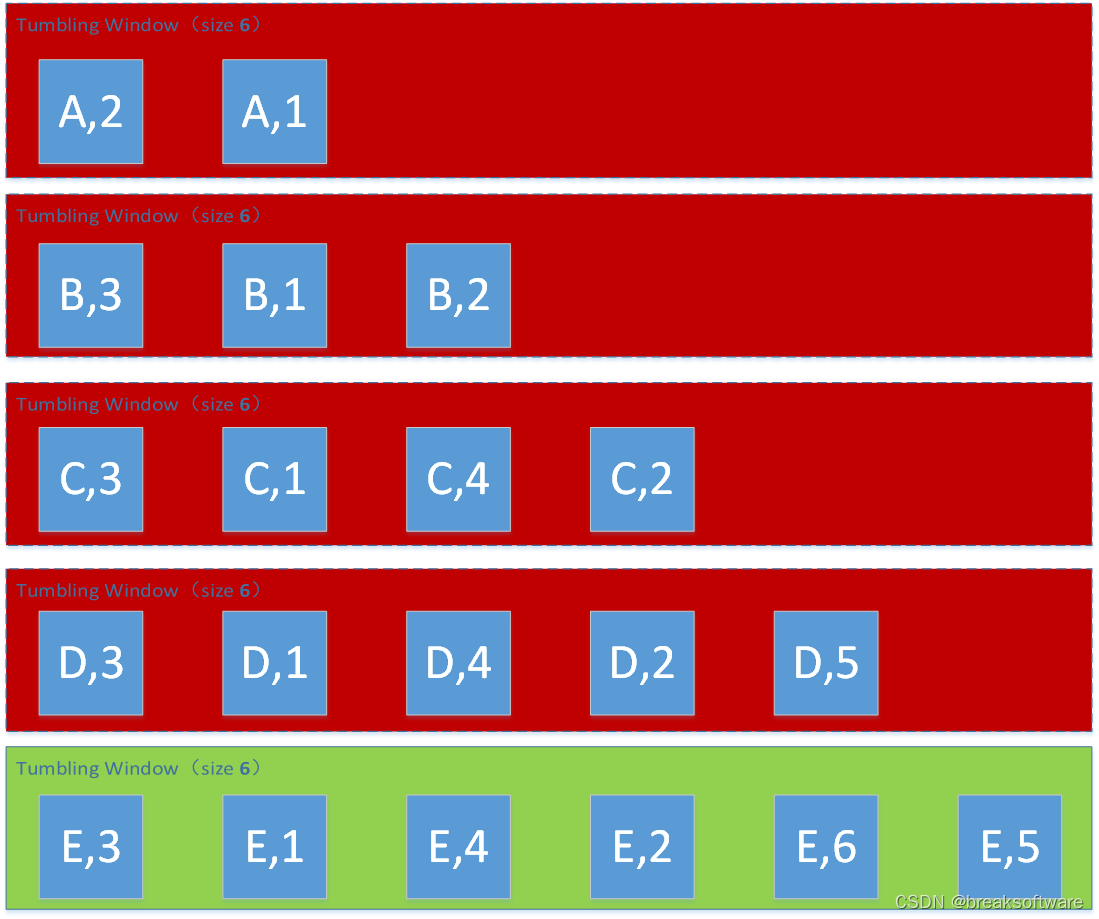
0基础学习PyFlink——个数滚动窗口(Tumbling Count Windows)
大纲 Tumbling Count WindowsmapreduceWindow Size为2Window Size为3Window Size为4Window Size为5Window Size为6 完整代码参考资料 之前的案例中,我们的Source都是确定内容的数据。而Flink是可以处理流式(Streaming)数据的,就是…
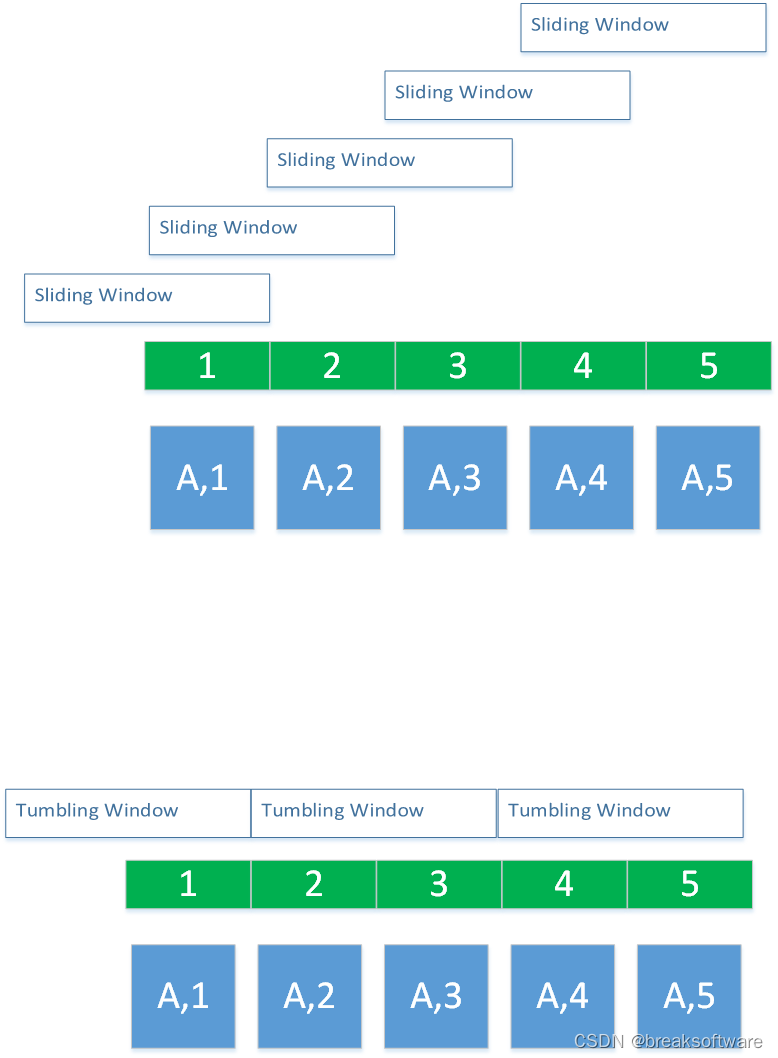
0基础学习PyFlink——事件时间和运行时间的窗口
大纲 定制策略运行策略Reduce完整代码滑动窗口案例参考资料 在
《0基础学习PyFlink——时间滚动窗口(Tumbling Time Windows)》一文中,我们使用的是运行时间(Tumbling
ProcessingTimeWindows)作为窗口的参考时间: reducedkeyed.window(TumblingProcess…
Flink之Watermark水印、水位线
Watermark水印、水位线 水位线概述水印本质生成WatermarkWatermark策略WatermarkStrategy工具类使用Watermark策略 内置Watermark生成器单调递增时间戳分配器固定延迟的时间戳分配器 自定义WatermarkGenerator周期性Watermark生成器标记Watermark生成器Watermark策略与Kafka连接…
Flink学习之旅:(四)Flink转换算子(Transformation)
1.基本转换算子 基本转换算子说明映射(map)将数据流中的数据进行转换,形成新的数据流过滤(filter)将数据流中的数据根据条件过滤扁平映射(flatMap)将数据流中的整体(如:集…

Flink之Window窗口机制
窗口Window机制 窗口概述窗口的分类是否按键分区按键分区窗口非按键分区 按照驱动类型按具体分配规则滚动窗口Tumbling Windows滑动窗口 Sliding Windows会话窗口 Session Windows全局窗口 Global Windows 时间语义窗口分配器 Window Assigners时间窗口计数窗口例子 窗口函数 W…
24、Flink 的table api与sql之Catalogs(java api操作分区与函数、表)-4
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

Flink学习之旅:(三)Flink源算子(数据源)
1.Flink数据源 Flink可以从各种数据源获取数据,然后构建DataStream 进行处理转换。source就是整个数据处理程序的输入端。 数据集合数据文件Socket数据kafka数据自定义Source 2.案例
2.1.从集合中获取数据 创建 FlinkSource_List 类,再创建个 Student 类…
1. Flink程序打Jar包
文章目录 步骤注意事项 步骤
用 maven 打 jar 包,需要在 pom.xml 文件中添加打包插件依赖
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><ver…

flink中使用GenericWriteAheadSink的优缺点
背景
GenericWriteAheadSink是flink中提供的实现几乎精确一次输出的数据汇抽象类,本文就来看一下使用GenericWriteAheadSink的优缺点
GenericWriteAheadSink的优缺点
先看一下GenericWriteAheadSink的原理图
优点:
几乎可以精确一次的输出…
flink的TwoPhaseCommitSinkFunction怎么做才能提供精准一次保证
背景
TwoPhaseCommitSinkFunction是flink中基于二阶段事务提交和检查点机制配合使用实现的精准一次的输出数据汇,但是想要实现精准一次的输出,实际使用中需要注意几个方面,否则不仅仅达不到精准一次输出,反而可能导致数据丢失&am…
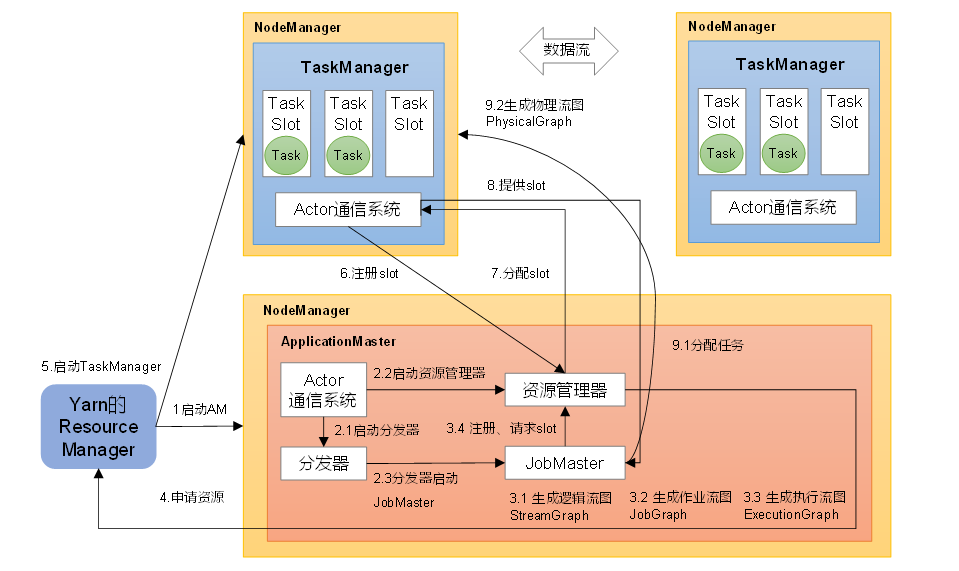
Flink部署模式及核心概念
一.部署模式
1.1会话模式(Session Mode)
需要先启动一个 Flink 集群,保持一个会话,所有提交的作业都会运行在此集群上,且启动时所需的资源以确定,无法更改,所以所有已提交的作业都会竞争集群中…
Flink实时写入Apache Doris如何保证高吞吐和低延迟
随着实时分析需求的不断增加,数据的时效性对于企业的精细化运营越来越重要。借助海量数据,实时数仓在有效挖掘有价值信息、快速获取数据反馈、帮助企业更快决策、更好的产品迭代等方面发挥着不可替代的作用。
在这种情况下,Apache Doris 作为一个实时 MPP 分析数据库脱颖而出,…
修炼k8s+flink+hdfs+dlink(六:学习k8s-pod)
一:增(创建)。
直接进行创建。
kubectl run nginx --imagenginx使用yaml清单方式进行创建。 直接创建方式,并建立pod。
kubectl create deployment my-nginx-deployment --imagenginx:latest 先创建employment,不…
0基础学习PyFlink——使用PyFlink的SQL进行字数统计
在《0基础学习PyFlink——Map和Reduce函数处理单词统计》和《0基础学习PyFlink——模拟Hadoop流程》这两篇文章中,我们使用了Python基础函数实现了字(符)统计的功能。这篇我们将切入PyFlink,使用这个框架实现字数统计功能。
PyFl…
【入门Flink】- 03Flink部署
集群角色
Flik提交作业和执行任务,需要几个关键组件: 客户端(Client):代码由客户端获取并做转换,之后提交给JobManger JobManager:就是Fink集群里的“管事人”,对作业进行中央调度管理;而它获…
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
【API篇】六、Flink输出算子Sink
文章目录 1、输出到外部系统2、输出到文件3、输出到KafKa4、输出到MySQL(JDBC)5、自定义Sink输出 Flink做为数据处理引擎,要把最终处理好的数据写入外部存储,为外部系统或应用提供支持。与输入算子Source相对应的,输出…
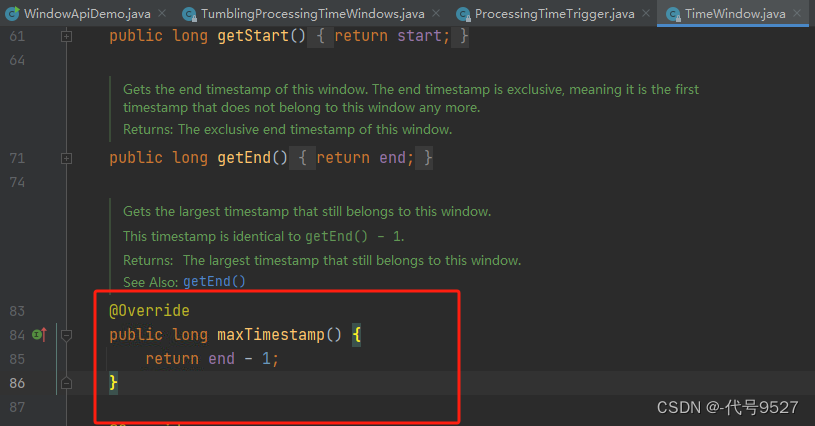
【API篇】八、Flink窗口函数
文章目录 1、增量聚合之ReduceFunction2、增量聚合之AggregateFunction3、全窗口函数full window functions4、增量聚合函数搭配全窗口函数5、会话窗口动态获取间隔值6、触发器和移除器7、补充 //窗口操作
stream.keyBy(<key selector>).window(<window assigner>)…

【flink】Task 故障恢复详解以及各重启策略适用场景说明
文章目录 一. 重启策略种类(Restart Strategies)1. Fixed Delay Restart Strategy2. Failure Rate Restart Strategy3. Fallback Restart Strategy4. No Restart Strategy 二. 故障恢复策略(Failover Strategies)1. (全…
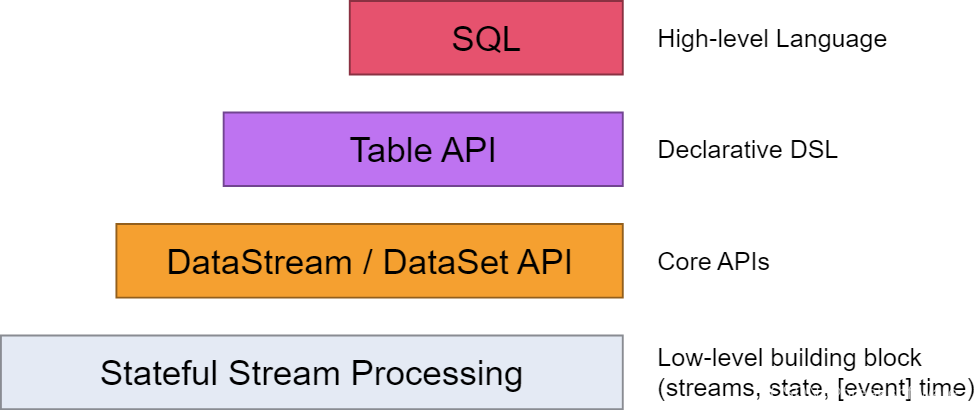
0基础学习PyFlink——使用Table API实现SQL功能
在《0基础学习PyFlink——使用PyFlink的Sink将结果输出到Mysql》一文中,我们讲到如何通过定义Souce、Sink和Execute三个SQL,来实现数据读取、清洗、计算和入库。 如下图所示SQL是最高层级的抽象,在它之下是Table API。本文我们会将例子中的SQ…
Flink几个性能调优
1 配置内存
操作场景
Flink是依赖内存计算,计算过程中内存不够对Flink的执行效率影响很大。可以通过监控GC(Garbage Collection),评估内存使用及剩余情况来判断内存是否变成性能瓶颈,并根据情况优化。 监控节点进程的…
flink接入mqtt数据源
flink没有原生的mqtt数据源,但可以通过自定义数据源进行添加mqtt的数据源。
package com.agioe.flink.source.mqtt;import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.eclipse.paho.mqttv5.client.*;
import org.eclipse.pa…
0基础学习PyFlink——不可以用UDTAF装饰器装饰function的原因分析
在研究Flink的“用户自定义方法”(UserDefinedFunction)时,我们看到存在如下几种类型的装饰器:
UDF:User Defined Scalar FunctionUDTF:User Defined Table FunctionUDAF:User Defined Aggrega…
Flink将数据写入MySQL(JDBC)
一、写在前面
在实际的生产环境中,我们经常会把Flink处理的数据写入MySQL、Doris等数据库中,下面以MySQL为例,使用JDBC的方式将Flink的数据实时数据写入MySQL。
二、代码示例
2.1 版本说明 <flink.version>1.14.6</flink.version…
0基础学习PyFlink——使用datagen生成流式数据
大纲 可控参数字段级规则生成方式数值控制时间戳控制 表级规则生成速度生成总量 结构生成环境定义行结构定义表信息 案例随机Int型顺序Int型随机型Int数组带时间戳的多列数据 完整代码参考资料 在研究Flink的水印(WaterMark)技术之前,我们可能…
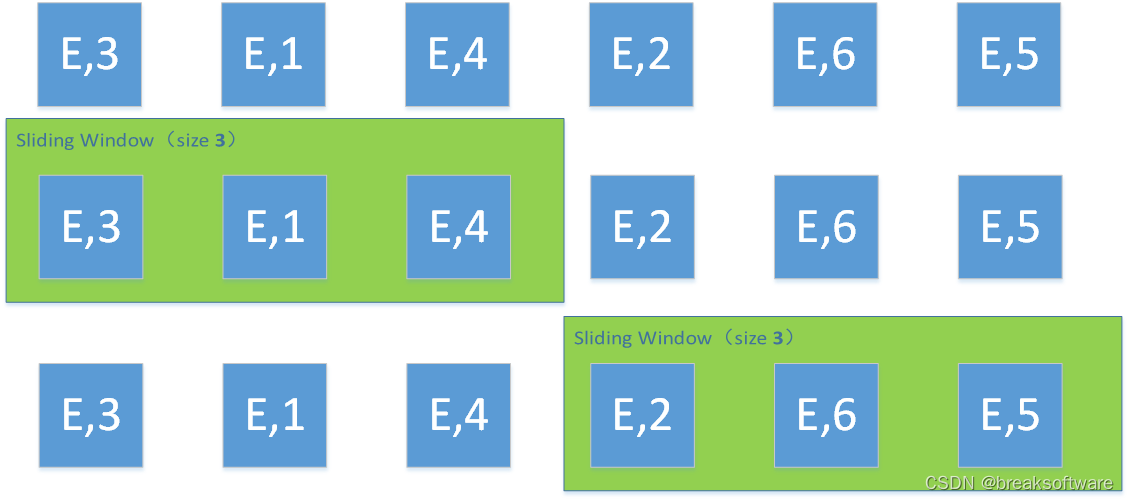
0基础学习PyFlink——个数滑动窗口(Sliding Count Windows)
大纲 滑动(Sliding)和滚动(Tumbling)的区别样例窗口为2,滑动距离为1窗口为3,滑动距离为1窗口为3,滑动距离为2窗口为3,滑动距离为3 完整代码参考资料 在
《0基础学习PyFlink——个数…
Flink源码解析四之任务调度和负载均衡
源码概览 jobmanager scheduler:这部分与 Flink 的任务调度有关。 CoLocationConstraint:这是一个约束类,用于确保某些算子的不同子任务在同一个 TaskManager 上运行。这通常用于状态共享或算子链的情况。CoLocationGroup & CoLocationGroupImpl:这些与 CoLocationCon…
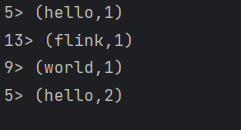
【入门Flink】- 02Flink经典案例-WordCount
WordCount
需求:统计一段文字中,每个单词出现的频次
添加依赖 <properties><flink.version>1.17.0</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><…
Flink日志采集-ELK可视化实现
一、各组件版本
组件版本Flink1.16.1kafka2.0.0Logstash6.5.4Elasticseach6.3.1Kibana6.3.1 针对按照⽇志⽂件⼤⼩滚动⽣成⽂件的⽅式,可能因为某个错误的问题,需要看好多个⽇志⽂件,还有Flink on Yarn模式提交Flink任务,在任务执…
Flink源码解析三之执行计划⽣成
JobManager Leader 选举
首先flink会依据配置获取RecoveryMode,RecoveryMode一共两两种:STANDALONE和ZOOKEEPER。 如果用户配置的是STANDALONE,会直接去配置中获取JobManager的地址如果用户配置的是ZOOKEEPER,flink会首先尝试连接zookeeper,利用zookeeper的leadder选举服务发现…
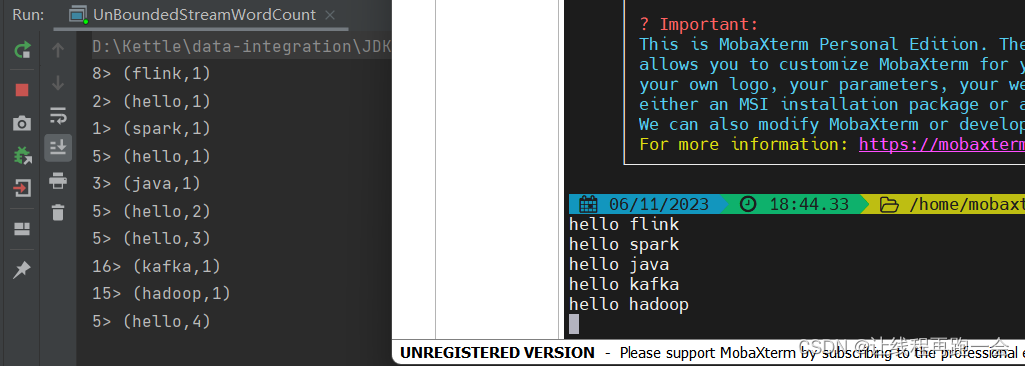
Flink(一)【WordCount 快速入门】
前言 学完了 Hadoop、Spark,本想着先把 Kafka、Flume 这些工具先学完的,但想了想还是把核心的技术先学完最后再去把那些工具学学。 最近心有点累哈哈哈,偷偷立个 flag,反正也没人看,明年的今天来这里还愿哈,…

云服务器搭建flink集群
文章目录 1.集群配置2.修改集群配置3. 访问Web UI4. 提交作业方式5.Yarn部署模式配置5.1 会话模式部署(Session Mode)5.2 单作业模式(Per-job Mode)5.3 应用模式部署(推荐)5.3.1 上传HDFS提交(推荐) 5.4 历…

Flink SQL Regular Join 、Interval Join、Temporal Join、Lookup Join 详解
Flink ⽀持⾮常多的数据 Join ⽅式,主要包括以下三种:
动态表(流)与动态表(流)的 Join动态表(流)与外部维表(⽐如 Redis)的 Join动态表字段的列转⾏…
flink的CoProcessFunction使用示例
背景
在flink中对两个流进行connect之后进行出处理的场景很常见,我们本文就以书中的一个例子为例说明下实现一个CoProcessFunction的一些要点
实现CoProcessFunction的一些要点
这个例子举例的是当收到某个传感器放行的控制消息时,从传感器传来的温度…
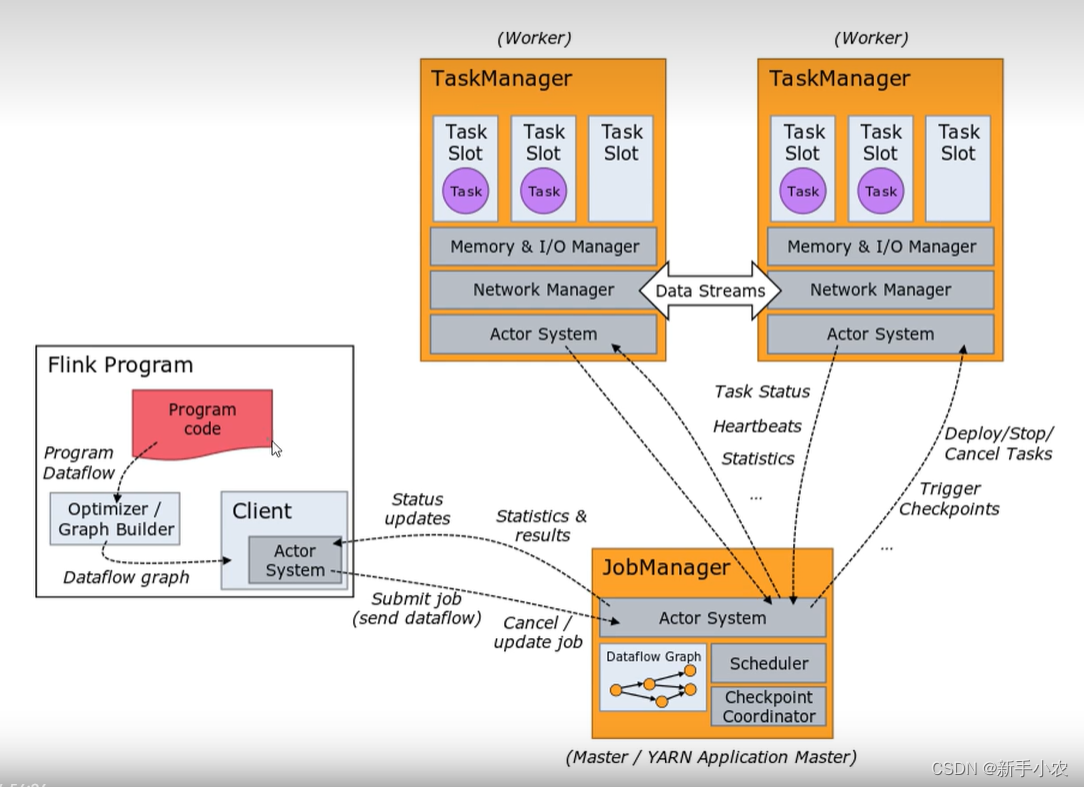
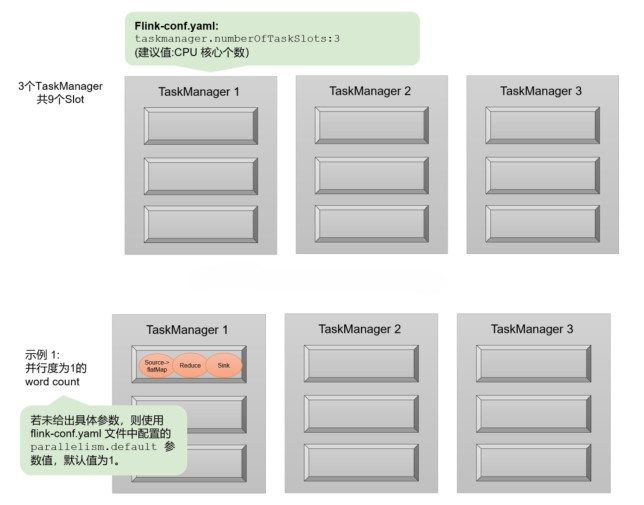
【Flink】全网最详细4W字Flink全面解析与实践(上)
本文已收录至GitHub,推荐阅读 👉 Java随想录 微信公众号:Java随想录 原创不易,注重版权。转载请注明原作者和原文链接 文章目录 流处理 & 批处理无界流Unbounded Streams有界流Bounded Streams Flink的特点和优势Flink VS Spa…
【flink】flink获取-D参数方式
参考官网
一、idea 本地运行
使用Flink官方的ParameterTool或者其他工具都可以。
二、集群运行flink run/run-application
(1)ParameterTool 获取参数
以-D开头的参数:
ParameterTool parameter ParameterTool.fromSystemProperties()…
Flink 基础 -- 应用开发(项目配置)
1、概述
本节中的指南将向您展示如何通过流行的构建工具(Maven, Gradle)配置项目,添加必要的依赖项(即连接器和格式,测试),并涵盖一些高级配置主题。
每个Flink应用程序都依赖于一组Flink库。至少,应用程序依赖于Flink api&…
FlinK之检查点与保存点机制
检查点与保存点 检查点Checkpoint概述保存时机保存与恢复检查点算法 检查点配置启用检查点指定存储位置其它配置通用增量 保存点Savepoint概述使用保存点切换状态后端 检查点Checkpoint
概述 在 Flink 中,检查点是用于实现状态一致性和故障恢复的关键机制。检查点功…

flink的带状态的RichFlatMapFunction函数使用
背景
使用RichFlatMapFunction可以带状态来决定如何对数据流进行转换,而且这种用法非常常见,根据之前遇到过的某个key的状态来决定再次遇到同样的key时要如何进行数据转换,本文就来简单举个例子说明下RichFlatMapFunction的使用方法
RichFl…
flink的KeyedBroadcastProcessFunction测试
背景
我们经常需要对KeyedBroadcastProcessFunction函数进行单元测试,以确保上线之前这个函数的功能是正常的,包括里面的广播状态和键值分区状态
测试KeyedBroadcastProcessFunction类 Testpublic void testHarnessForKeyedBroadcastProcessFunction()…
Flink中的时间和窗口操作
1.窗口概念 在大多数场景下,我们需要统计的数据流都是无界的,因此我们无法等待整个数据流终止后才进行统计。通常情况下,我们只需要对某个时间范围或者数量范围内的数据进行统计分析:如每隔五分钟统计一次过去一小时内所有商品的点击量;或者每发生1000次点击后,都去统计一…
Flink—— Flink Data transformation(转换)
Flink数据算子转换有很多类型,各位看官看好,接下来,演示其中的十八种类型。
1.Map(映射转换) DataStream → DataStream 将函数作用在集合中的每一个元素上,并返回作用后的结果,其中输入是一个数据流&…
Flink 基础 -- 应用开发(Table API SQL) 概念和通用API
1、概述
Apache Flink提供了两个关系API——Table API和SQL——用于统一的流和批处理。Table API是一个用于Java、Scala和Python的语言集成查询API,它允许以非常直观的方式组合来自关系操作符(如选择、过滤和连接)的查询。Flink的SQL支持基于Apache Calcite&#x…
25、Flink 的table api与sql之函数(自定义函数示例)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
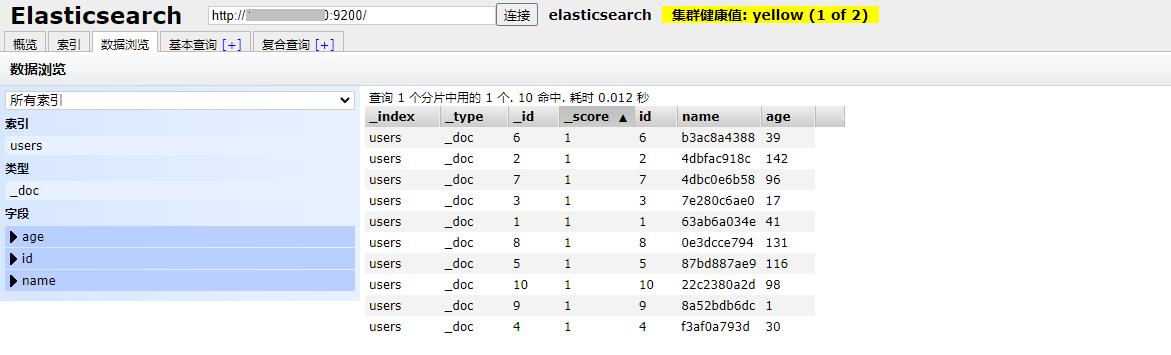
Flink之Table API SQL连接器
连接器 Table API & SQL连接器1.概述2.支持连接器 DataGen连接器1.概述2.SQL客户端执行3.Table API执行 FileSystem连接器1.创建FileSystem映射表2.创建source数据源表3.写入数据4.解决异常5.查询fileTable6.查看HDFS Kafka连接器1.添加kafka连接器依赖2.重启yarn-session、…
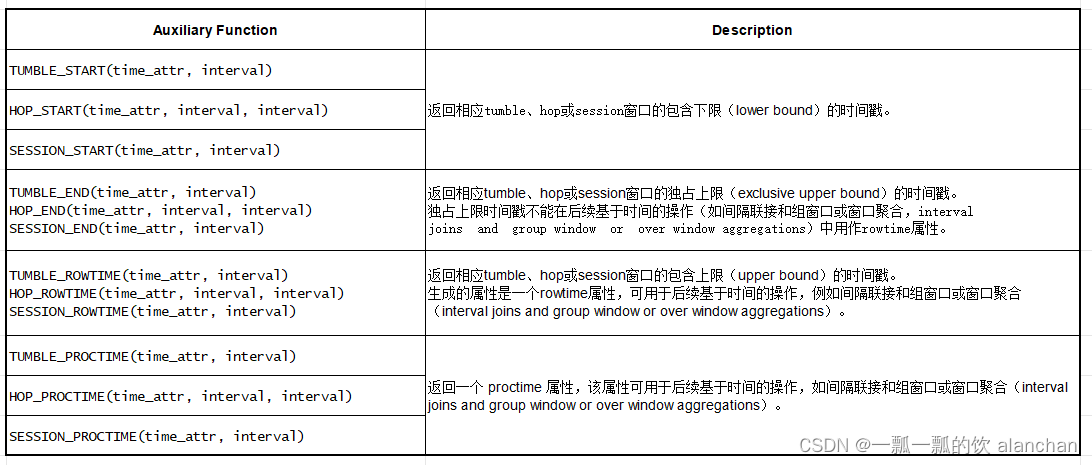
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
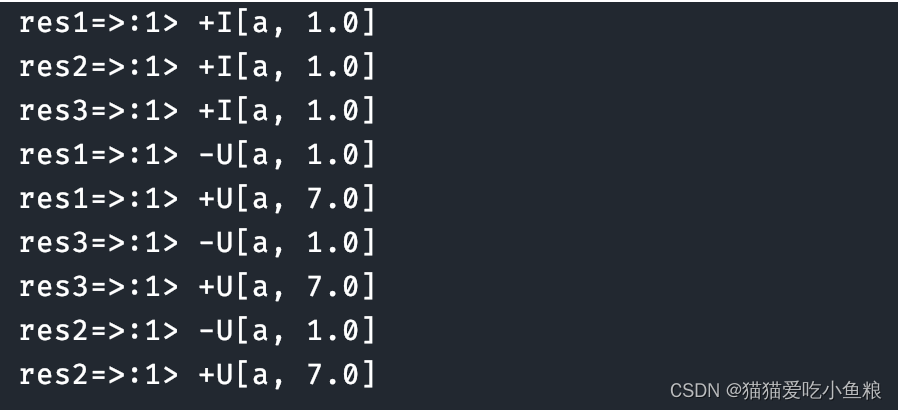
FlinkSQL聚合函数(Aggregate Function)详解
使用场景: 聚合函数即 UDAF,常⽤于进多条数据,出⼀条数据的场景。 上图展示了⼀个 聚合函数的例⼦ 以及 聚合函数包含的重要⽅法。
案例场景:
关于饮料的表,有三个字段,分别是 id、name、price࿰…
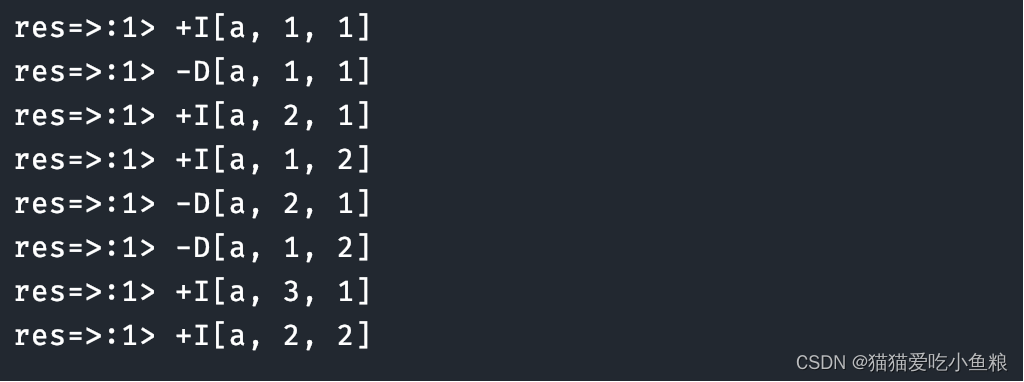
Flink SQL 表值聚合函数(Table Aggregate Function)详解
使用场景: 表值聚合函数即 UDTAF,这个函数⽬前只能在 Table API 中使⽤,不能在 SQL API 中使⽤。
函数功能:
在 SQL 表达式中,如果想对数据先分组再进⾏聚合取值:
select max(xxx) from source_table gr…
33、Flink 的Table API 和 SQL 中的时区
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
Flink SQL -- CheckPoint
1、开启CheckPoint
checkpoint可以定时将flink任务的状态持久化到hdfs中,任务执行失败重启可以保证中间结果不丢失
# 修改flink配置文件
vim flink-conf.yaml# checkppint 间隔时间
execution.checkpointing.interval: 1min
# 任务手动取消时保存checkpoint
execu…
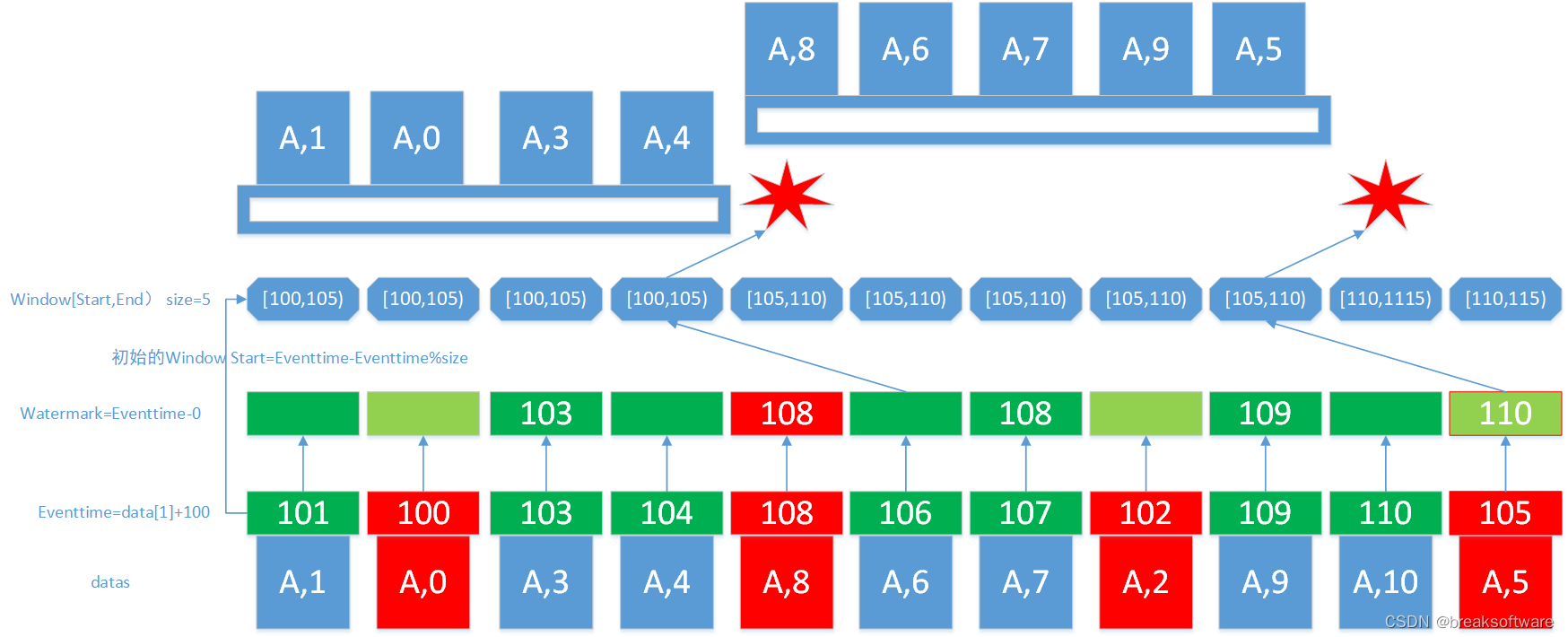
0基础学习PyFlink——水位线(watermark)触发计算
在《0基础学习PyFlink——个数滚动窗口(Tumbling Count Windows)》和《0基础学习PyFlink——个数滑动窗口(Sliding Count Windows)》中,我们发现如果窗口中元素个数没有把窗口填满,则不会触发计算。
为了解决长期不计算的问题&a…
21、Flink 的table API与DataStream API 集成(2)- 批处理模式和inser-only流处理
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
21、Flink 的table API与DataStream API 集成(1)- 介绍及入门示例、集成说明
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
Flink之数据擦除及自定义Evictor
1 窗口数据移除机制 Flink中窗口数据移除机制是通过Evictor来控制的, Flink内置的Evictor如下: DeltaEvictorTimeEvictorCountEvictor Evictor的作用就是在窗口触发前或窗口触发中将其中的某些数据进行移除. 1.1 源码解析
关于Evictor的源码只需要关注三个方法就可以了evictBe…

GZ033 大数据应用开发赛题第04套
2023年全国职业院校技能大赛
赛题第04套 赛项名称: 大数据应用开发
英文名称: Big Data Application Development
赛项组别: 高等职业教育组
赛项编号: GZ033 …

【Flink 问题集】The generic type parameters of ‘Collector‘ are missing
错误展示: Exception in thread "main" org.apache.flink.api.common.functions.InvalidTypesException: The return type of function main(CollectionDemo.java:33) could not be determined automatically, due to type erasure. You can give type in…
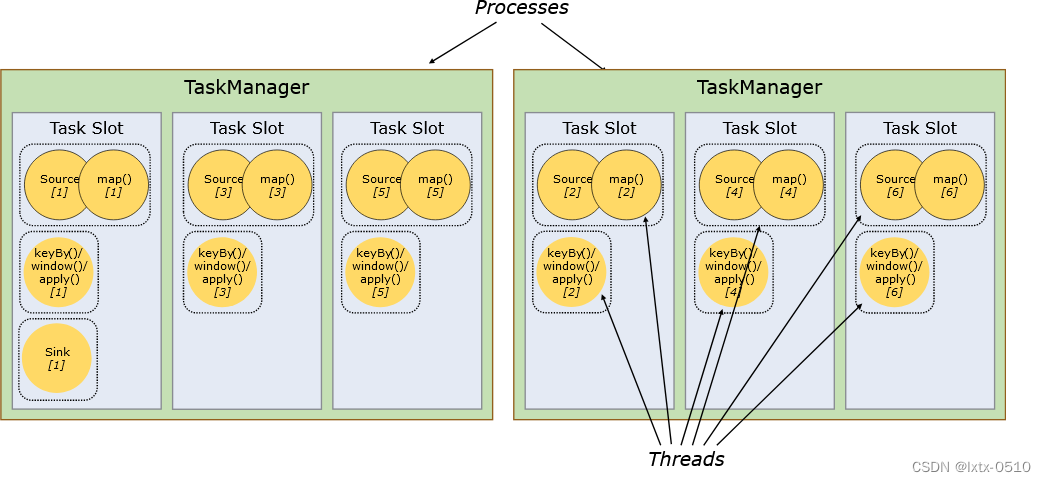
【Flink】核心概念:任务槽(Task Slots)
任务槽
每个 worker(TaskManager)都是一个 JVM 进程,可以在单独的线程中执行一个或多个 subtask。为了控制一个 TaskManager 中接受多少个 task,就有了所谓的 task slots(至少一个)。
每个任务槽…
flinksql kafka到mysql累计指标练习
flinksql 累计指标练习
数据流向:kafka ->kafka ->mysql
模拟写数据到kafka topic:wxt中
import com.alibaba.fastjson.JSONObject;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Produ…
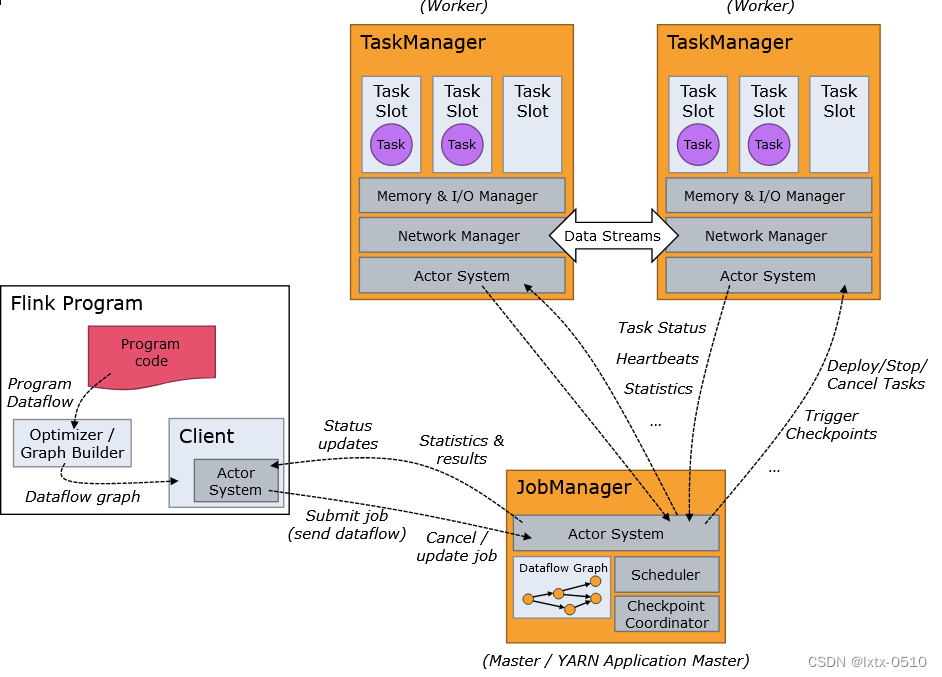
【Flink】系统架构
DataStream API 将你的应用构建为一个 job graph,并附加到 StreamExecutionEnvironment 。当调用 env.execute() 时此 graph 就被打包并发送到 JobManager 上,后者对作业并行处理并将其子任务分发给 Task Manager 来执行。每个作业的并行子任务将在 task…
flink 1.17.1的pom.xml模板
flink 1.17.1的pom.xml模板
<?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apa…
GZ033 大数据应用开发赛题第05套
2023年全国职业院校技能大赛
赛题第05套 赛项名称: 大数据应用开发
英文名称: Big Data Application Development
赛项组别: 高等职业教育组
赛项编号: GZ033 …
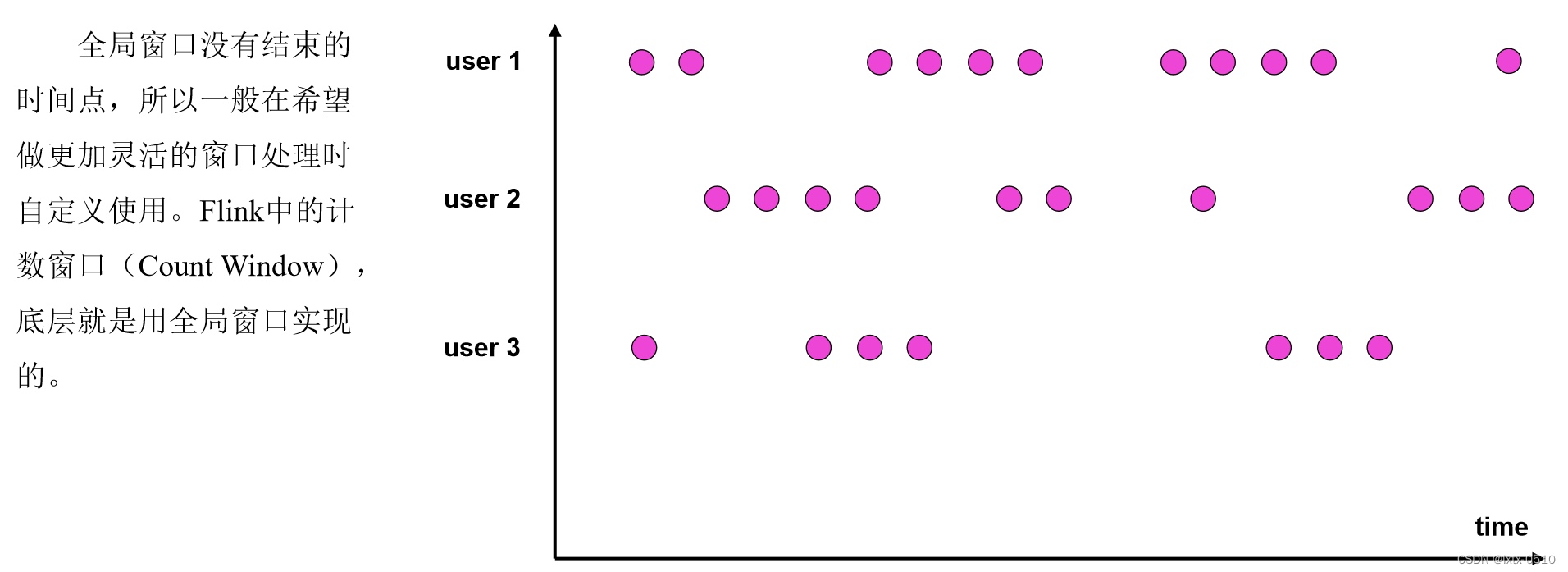
【Flink】窗口(Window)
窗口理解
窗口(Window)是处理无界流的关键所在。窗口可以将数据流装入大小有限的“桶”中,再对每个“桶”加以处理。 本文的重心将放在 Flink 如何进行窗口操作以及开发者如何尽可能地利用 Flink 所提供的功能。
对窗口的正确理解ÿ…
Flink Operator 使用指南 之 全局配置
背景
在上一个章节中已经介绍了基本的Flink-Operator安装,但是在实际的数据中台的项目中,用户可能希望看到Flink Operator的运行日志情况,当然这可以通过修改Flink-Operator POD的文件实现卷挂载的形势将日志输出到宿主机器的指定目录下,但是这种办法对数据中台的产品不是…
Flink 统计接入的数据量-滚动窗口和状态的使用
1、概述
在生产场景值,经常需要和上游、下游对数,离线场景可以直接 group by 再 count ,但是实时场景中,如果使用 kafka 作为中间件,中间经过几个 job 的过滤转化后,再对照像 Doris 或 Clickhouse 中最终层…
flink的起源定义
flink的起源 Flink的起源可以追溯到2010年,当时它作为一个研究项目开始。该项目最初由德国柏林工业大学(Berlin Institute of Technology)的一群研究人员发起,包括Matei Zaharia、Kostas Tzoumas和Stephan Ewen等。 项目最初被称为…
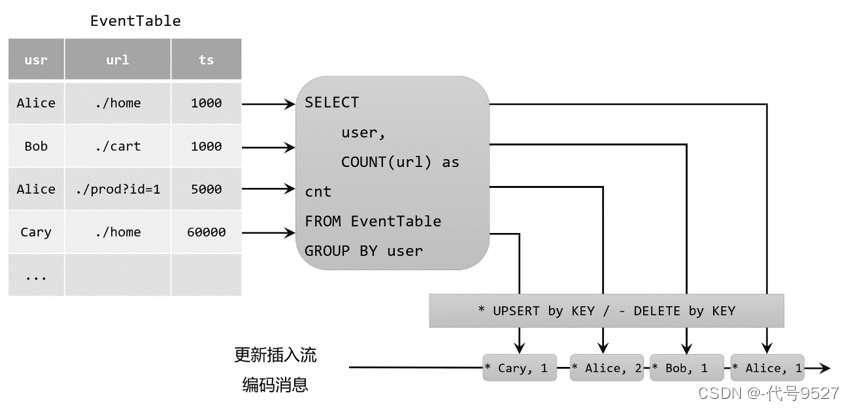
【SQL篇】一、Flink动态表与流的关系以及DDL语法
文章目录 1、启动SQL客户端2、SQL客户端常用配置3、动态表和持续查询4、将流转为动态表5、用SQL持续查询6、动态表转为流7、时间属性8、DDL-数据库相关9、DDL-表相关 1、启动SQL客户端
启动Flink(基于yarn-session模式为例):
/opt/module/f…

Apache Flink(十四):Flink 本地模式开启WebUI
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录

19、Flink 的Table API 和 SQL 中的内置函数及示例(1)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
Flink Operator 使用指南 之 Flink Operator安装
介绍
Flink Kubernetes Operator 充当控制平面来管理 Apache Flink 应用程序的完整部署生命周期。尽管 Flink 的Native Kubernetes 集成已经允许用户在运行的 Kubernetes(k8s) 集群上直接部署 Flink 应用程序,但自定义资源和Operator Pattern 也已成为 Kubernetes 原生部署体…

Flink 运行架构和核心概念
Flink 运行架构和核心概念
几个角色的作用:
客户端:提交作业JobManager进程 任务管理调度 JobMaster线程 一个job对应一个JobMaster 负责处理单个作业ResourceManager 资源的分配和管理,资源就是任务槽分发器 提交应用,为每一个…
21、Flink 的table API与DataStream API 集成(完整版)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

Flink1.17 DataStream API
目录
一.执行环境(Execution Environment)
1.1 创建执行环境
1.2 执行模式
1.3 触发程序执行
二.源算子(Source)
2.1 从集合中读取数据
2.2 从文件读取数据
2.3 从 RabbitMQ 中读取数据
2.4 从数据生成器读取数据
2.5 …
Flink SQL DataGen Connector 示例
Flink SQL DataGen Connector 示例
1、概述
使用 Flink SQL DataGen Connector,可以快速地生成符合规则的测试数据,可以在不依赖真实数据的情况下进行开发和测试。
2、使用示例
创建一个名为 “users” 的表,包含 6 个字段:id…
GZ033 大数据应用开发赛题第09套
2023年全国职业院校技能大赛
赛题第09套 赛项名称: 大数据应用开发
英文名称: Big Data Application Development
赛项组别: 高等职业教育组
赛项编号: GZ033 …

40、Flink 的Apache Kafka connector(kafka source 和sink 说明及使用示例) 完整版
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

关于Flink的旁路缓存与异步操作
1. 旁路缓存
1. 什么是旁路缓存?
将数据库中的数据,比较经常访问的数据,保存起来,以减少和硬盘数据库的交互 比如: 我们使用mysql时 经常查询一个表 , 而这个表又一般不会变化,就可以放在内存中,查找时直接对内存进行查找,而不需要再和mysql交互
2. 旁路缓存例子使用
dim层…
物流实时数仓:数仓搭建(ODS)
系列文章目录
物流实时数仓:采集通道搭建 物流实时数仓:数仓搭建 文章目录 系列文章目录前言一、IDEA环境准备1.pom.xml2.目录创建 二、代码编写1.log4j.properties2.CreateEnvUtil.java3.KafkaUtil.java4.OdsApp.java 三、代码测试总结 前言
现在我们…
flink源码分析之功能组件(二)-kubeclient
简介 本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metrics,future。其中kubeclient上一个系列介绍过,为了系列完整性,这里“copy”一下。
kubeclient组件…
《十堂课学习 Flink SQL》第二章:Flink 基础
第二章是关于 Flink 的基础内容。主要包括 Apache Flink 框架概述;Flink 数据流处理和批处理的基本概念;Flink 编程模型;Table 以及 SQL 的简单介绍。本章节核心在于 Flink 的基本原理以及编程模式,不涉及环境搭建以及项目开发。 …
Flink流批一体计算(22):Flink SQL之单流kafka写入mysql
1. 准备工作
什么是Kafka源表
Kafka是分布式、高吞吐、可扩展的消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域。
docker部署zookeeper
docker pull wurstmeister/zookeeperdocker run -d --restartalways \
--log-dr…
Hdoop学习笔记(HDP)-Part.18 安装Flink
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …
flink源码分析 - standalone模式下jobmanager启动过程配置文件加载
flink版本: flink-1.11.2
代码位置: org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint#main
/** Licensed to the Apache Software Foundation (ASF) under one* or more contributor license agreements. See the NOTICE file* distributed with t…
Flink之状态TTL机制
在Flink状态使用过程中有时需要清除State中不许需要的数据,否则State中的数据会越来越多,既增加了内存压力,也降低了计算效率.而TTL机制可以很好的帮我们解决这个分体,利用TTL机制可以将状态中的冷热数据分离,将使用率很低的冷数据及时清除. 这里以Operator State为例子
class…
flink sqlClient提交hiveIceberg
flink sqlClient提交hiveIceberg 环境准备sqlclient启动前准备启动sqlclientinit.sqlinsert.sql 环境准备
组件名版本flink客户端1.14.4-2.12hadoop集群3.1.4hive客户端3.1.2icebergiceberg-flink-runtime-1.14-0.13.2.jariceberg-hive依赖iceberg-hive-runtime-0.13.2.jar
s…

Apache Doris 整合 FLINK 、 Hudi 构建湖仓一体的联邦查询入门
1.概览
多源数据目录(Multi-Catalog)功能,旨在能够更方便对接外部数据目录,以增强Doris的数据湖分析和联邦数据查询能力。
在之前的 Doris 版本中,用户数据只有两个层级:Database 和 Table。当我们需要连…

Flink入门之部署(二)
三种部署模式 standalone集群,会话模式部署:先启动flink集群 web UI提交shell命令提交:bin/flink run -d -m hadoop102:8081 -c com.atguigu.flink.deployment.Flinke1_NordCount./Flink-1.0-SNAPSHOT.jar --hostname hadoop102 --port 8888 …
Flink之DataStream API的转换算子
简单转换算子
函数的实现方式
自定义类,实现函数接口:编码麻烦,使用灵活匿名内部类:编码简单Lambda:编码简洁
public class Flink02_FunctionImplement {public static void main(String[] args) {//1.创建运行环境StreamExecutionEnvironment env StreamExecut…
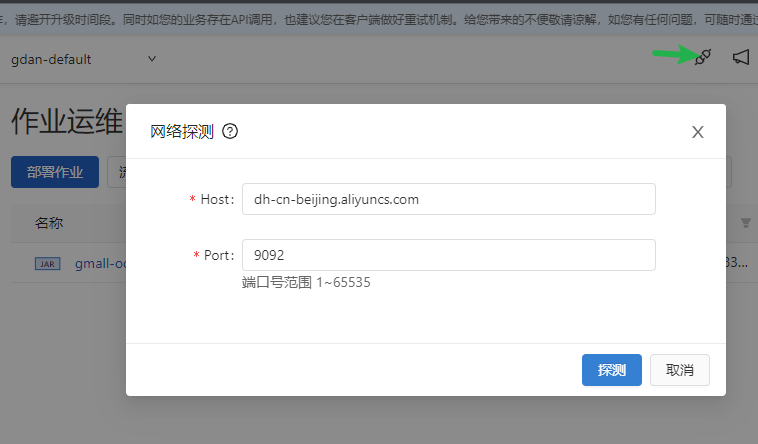
阿里云实时数据仓库HologresFlink
1. 实时数仓Hologres特点
专注实时场景:数据实时写入、实时更新,写入即可见,与Flink原生集成,支持高吞吐、低延时、有模型的实时数仓开发,满足业务洞察实时性需求。亚秒级交互式分析:支持海量数据亚秒级交…

kyuubi整合flink yarn application model
目录 概述配置flink 配置kyuubi 配置kyuubi-defaults.confkyuubi-env.shhive 验证启动kyuubibeeline 连接使用hive catalogsql测试 结束 概述
flink 版本 1.17.1、kyuubi 1.8.0、hive 3.1.3、paimon 0.5
整合过程中,需要注意对应的版本。
注意以上版本 姊妹篇 k…

基于 Flink 的典型 ETL 场景实现方案
目录
1.实时数仓的相关概述
1.1 实时数仓产生背景
1.2 实时数仓架构
1.3 传统数仓 vs 实时数仓
2.基于 Flink 实现典型的 ETL 场景
2.1 维表 Join
■ 2.1.1 预加载维表
方案 1:
方案 2:
■ 2.1.2 热存储关联
■ 2.1.3 广播维表
■ 2.1.4 Tem…
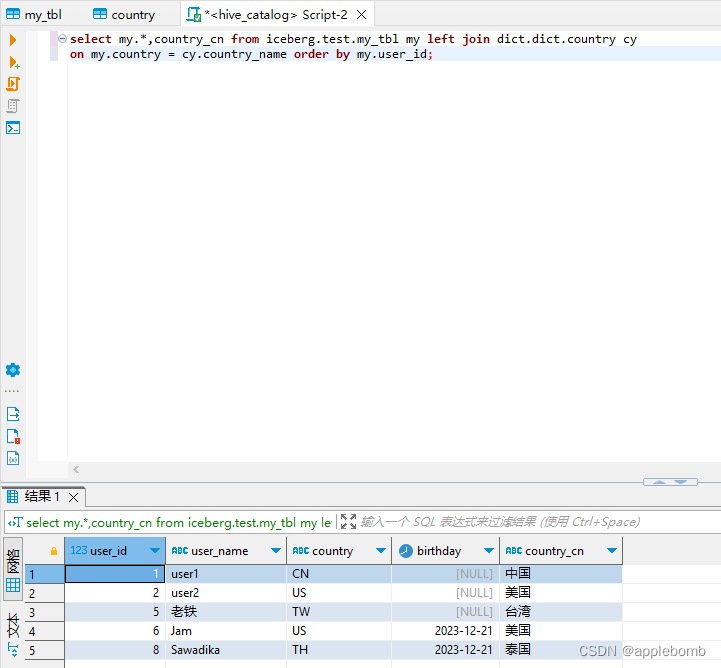
【湖仓一体尝试】MYSQL和HIVE数据联合查询
爬了两天大大小小的一堆坑,今天把一个简单的单机环境的流程走通了,记录一笔。
先来个完工环境照: mysqlhadoophiveflinkicebergtrino
得益于IBM OPENJ9的优化,完全启动后的内存占用:
1)执行联合查询后的…
flink on k8s几种创建方式
在此之前需要部署一下私人docker仓库,教程搭建 Docker 镜像仓库
注意:每台节点的daemon.json都需要配置"insecure-registries": ["http://主机IP:8080"] 并重启 一、session 模式
Session 模式是指在 Kubernetes 上启动一个共享的…
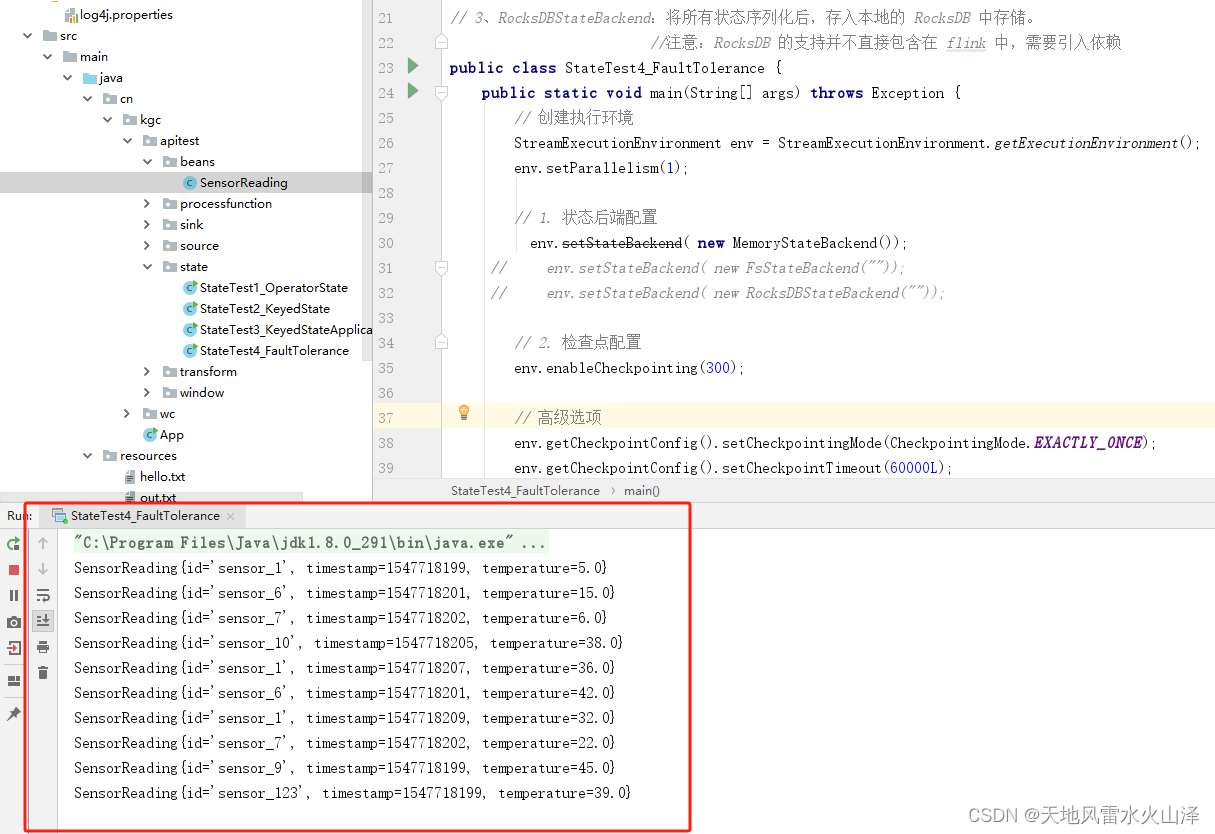
二百零一、Flink——Flink配置状态后端运行后报错:Can not create a Path from an empty string
一、目的
在尚硅谷学习用Flink配置状态后端的项目中,运行报错Exception in thread "main" java.lang.IllegalArgumentException: Can not create a Path from an empty string
二、Flink的状态后端(state backend)类型
(一)Memo…
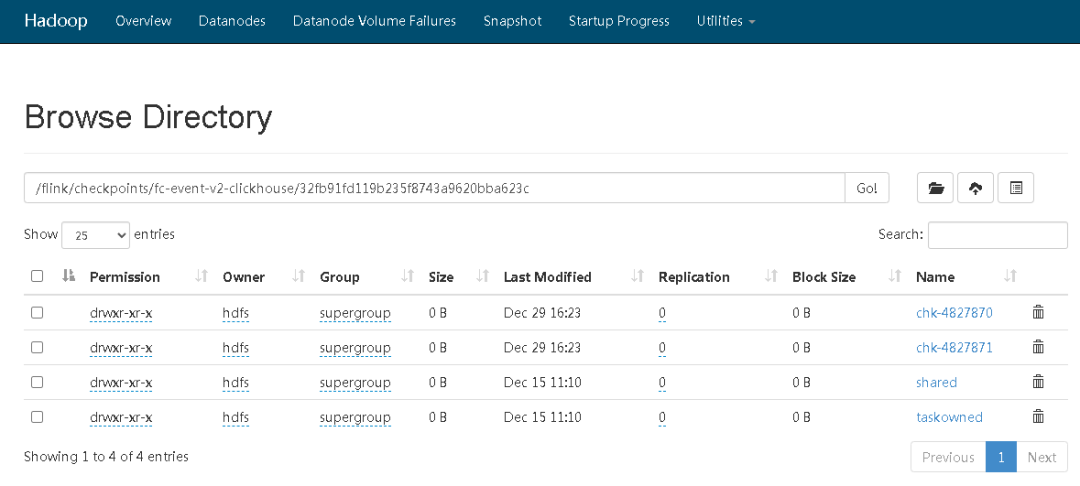
Flink状态容错savepoint与checkpoint
本文目录 Checkpoints State BackendsSavepointsCheckpoints 与 Savepoints区别 Flink可以保证exactly once,与其容错机制checkpoint和savepoint分不开的。本文主要讲解两者的机制与使用,同时会对比两者的区别。 Checkpoints Checkpoint 使 Flink 的状态…
Flink on K8S集群搭建及StreamPark平台安装
1.环境准备
1.1 介绍
在使用 Flink&Spark 时发现从编程模型, 启动配置到运维管理都有很多可以抽象共用的地方, 目前streampark提供了一个flink一站式的流处理作业开发管理平台, 从流处理作业开发到上线全生命周期都做了支持, 是一个一站式的流出来计算平台。 未来spark开…

Flink Job 执行流程
Flink On Yarn 模式
基于Yarn层面的架构类似 Spark on Yarn模式,都是由Client提交App到RM上面去运行,然后 RM分配第一个container去运行AM,然后由AM去负责资源的监督和管理。需要说明的是,Flink的Yarn模式更加类似Spark on Ya…

1、Flink基础概念
1、基础知识
(1)、数据流上的有状态计算
(2)、框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
(3)、事件驱动型应用,有数据流就进行处理,无数据流就不…

Apache Flink连载(十八):Flink On Yarn运行原理及环境准备
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录
1. Flink On Yarn运行原理…

Flink 常用物理分区算子(Physical Partitioning)
Flink 物理分区算子(Physical Partitioning)
在Flink中,常见的物理分区策略有:随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast)。 接下来,我们通过源码和Demo分别了解每种物理分区算子的作用和区别。
(1) 随机…
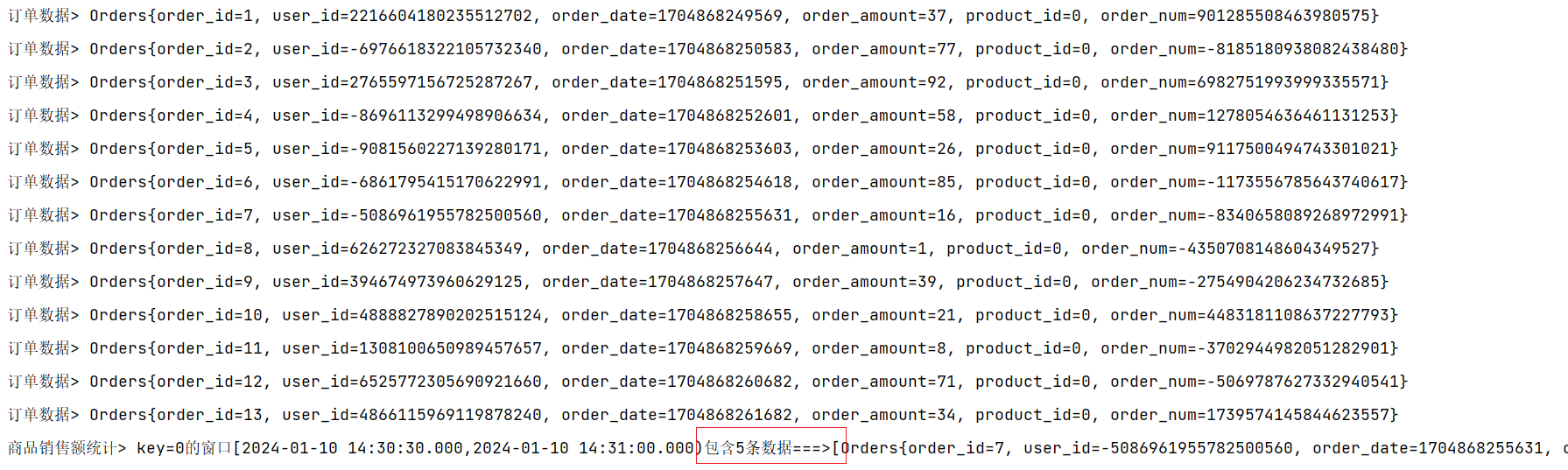
FlinkAPI开发之窗口(Window)
案例用到的测试数据请参考文章: Flink自定义Source模拟数据流 原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048
窗口的概念
Flink是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。…
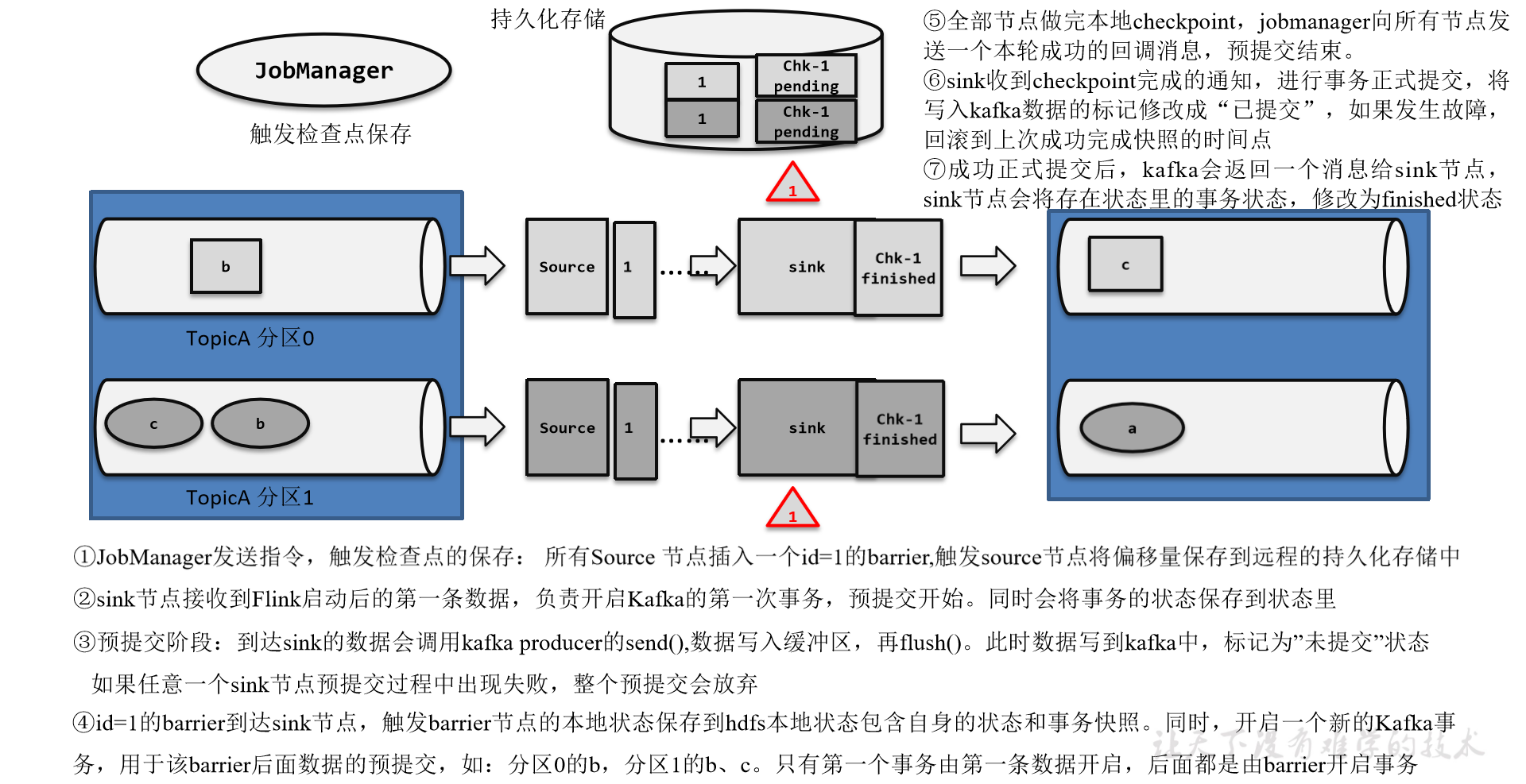
Flink1.17实战教程(第六篇:容错机制)
系列文章目录
Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…

Flink项目实战篇 基于Flink的城市交通监控平台(上)
系列文章目录
Flink项目实战篇 基于Flink的城市交通监控平台(上) Flink项目实战篇 基于Flink的城市交通监控平台(下) 文章目录 系列文章目录1. 项目整体介绍1.1 项目架构1.2 项目数据流1.3 项目主要模块 2. 项目数据字典2.1 卡口…
Flink 基础 -- 应用开发(Table API SQL) Table API
Table API是用于流和批处理的统一关系API。表API查询可以在批处理或流输入上运行,而无需修改。Table API是SQL语言的超集,专为与Apache Flink一起工作而设计。Table API是Scala、Java和Python的语言集成API。与将查询指定为SQL中常见的字符串值不同&…
Flink实时电商数仓之DWS层
需求分析
关键词 统计关键词出现的频率
IK分词
进行分词需要引入IK分词器,使用它时需要引入相关的依赖。它能够将搜索的关键字按照日常的使用习惯进行拆分。比如将苹果iphone 手机,拆分为苹果,iphone, 手机。
<dependency><grou…


Apache Flink连载(十九):Flink On Yarn运行-Yarn Session模式
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录
1. 任务提交命令
2. 任…

搭建flink集群 —— 筑梦之路
Apache Flink 是一个框架和分布式处理引擎, 用于在无边界和有边界数据流上进行有状态的计算。 Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 Flink并没有依靠自身实现所有分布式系统需要解决的问题, 而是在已有集群…
Shell - cron_protect.sh 监控 Python、Streaming 程序
目录
一.引言
二.Flink 程序监控
1.shell 脚本
2.crontab 配置
三.Python 程序监控
1.shell 脚本
2.crontab 配置
四.总结 一.引言
业务有流式处理数据的需求,需要 7x24 通过 Flink Python 程序进行处理。为了监控 Flink 与 Python 的程序运行状态并在程…
flink udtaf 常年不能用
[FLINK-32807] when i use emitUpdateWithRetract of udtagg,bug error - ASF JIRA flink1.18发布的时候 他都显示未解决 但是文档上一直有udtaf
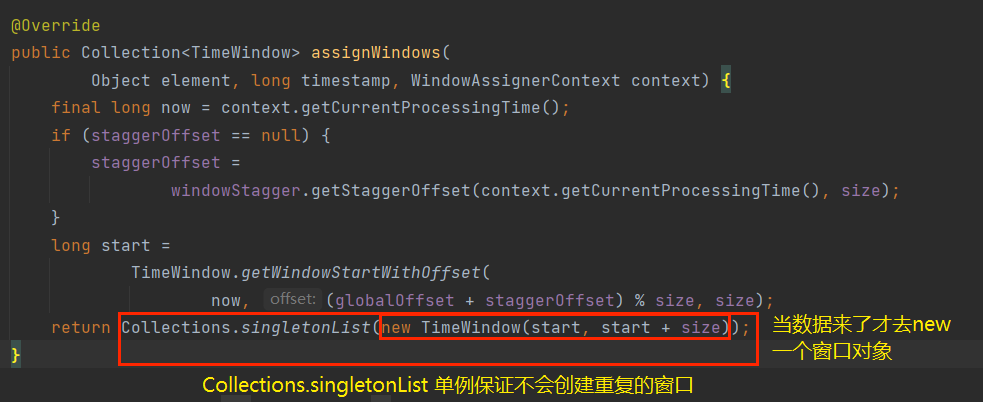
Flink(八)【窗口】
前言 终于忙完了四门专业课的期末,确实挺累啊。今天开始继续学习 Flink ,接着上次的内容。
今日摘录: 他觉得一个人奋斗更轻松自在。跟没有干劲的人在一起厮混,只会徒增压力。 -《解忧杂货店》 1、窗口 之前我们已经了解了…
PiflowX组件-WriteToKafka
WriteToKafka组件
组件说明
将数据写入kafka。
计算引擎
flink
有界性
Streaming Append Mode
组件分组
kafka
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子kafka_hostKAFKA_HOST“”无是逗号…
尚硅谷大数据技术-数据湖Hudi视频教程-笔记01【概述、编译安装】
大数据新风口:Hudi数据湖(尚硅谷&Apache Hudi联合出品) B站直达:https://www.bilibili.com/video/BV1ue4y1i7na 尚硅谷数据湖Hudi视频教程百度网盘:https://pan.baidu.com/s/1NkPku5Pp-l0gfgoo63hR-Q?pwdyyds阿里…

Flink on K8S生产集群使用StreamPark管理
(一)直接部署(手动测试用,不推荐)
Flink on Native Kubernetes 目前支持 Application 模式和 Session 模式,两者对比 Application 模式部署规避了 Session 模式的资源隔离问题、以及客户端资源消耗问题&am…
Flink 项目系列
Flink项目系列1-项目介绍 - 墨天轮
Flink实时电商实战项目: 基于尚硅谷开源项目的Flink电商实战项目(全流程)
大数据Flink电商数仓实战项目流程全解(一)_尚硅谷 flinksql大数据项目实战-CSDN博客
实时即未来,大数据…

创建第一个 Flink 项目
一、运行环境介绍
Flink执行环境主要分为本地环境和集群环境,本地环境主要为了方便用户编写和调试代码使用,而集群环境则被用于正式环境中,可以借助Hadoop Yarn、k8s或Mesos等不同的资源管理器部署自己的应用。
环境依赖: 【1】…

工作实践篇 Flink(一:flink提交jar)
一:参数
flink 模式 – standalone
二:步骤
1. 将本地测试好的代码进行本地运行。确保没问题,进行打包。 2. 找到打好的jar包,将jar包上传到对应的服务器。 3. 执行flink命令,跑代码。
/opt/flink/flink-1.13.6/bi…
flink源码分析之功能组件(六)-心跳组件
简介 本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metrics,future。 本文解释心跳组件,心跳组件监听组件间连接活性,超时触发重连,保证连接有效性;断连…
Flink电商实时数仓(四)
日志数据结构
业务数据:数据都是MySQL中的表格数据, 使用Flink SQL 处理 日志数据:分为page页面日志(页面信息,曝光信息,动作信息,报错信息)和启动日志(启动信息,报错信…
【flink番外篇】1、flink的23种常用算子介绍及详细示例(完整版)
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…
flink1.12.4消费kafka 报错 The coordinator is not available
报错 You should retry committing the latest consumed offsets.
Caused by: org.apache.kafka.common.errors.CoordinatorNotAvailableException: The coordinator is not available.
但是任务还在正常跑. 开源bug
[FLINK-28060] Kafka Commit on checkpointing fails rep…
Flink流批一体计算(24):Flink SQL之mysql维表实时关联
目录 1.维表
2.数据准备
创建源数据
创建维度表
创建Sink表
3.配置任务
Flink SQL创建kafka源表
Flink SQL创建MySQL维表
Flink SQL创建MySQL结果表
编写计算任务
核验数据 1.维表
目前在实时计算的场景中,大多数都使用过MySQL、Hbase、redis作为维表引擎…
【核心重点】Flink四大基石
1. Time(时间机制)
时间概念
处理时间:执行具体操作时的机器时间(例如 Java的 System.currentTimeMillis()) )事件时间:数据本身携带的时间,事件产生时的时间。摄入时间:数据进入 …

flink-1.17.2的单节点部署
flink 简介
Apache Flink 是一个开源的流处理和批处理框架,用于大数据处理和分析。它旨在以实时和批处理模式高效处理大量数据。Flink 支持事件时间处理、精确一次语义、有状态计算等关键功能。
以下是与Apache Flink相关的一些主要特性和概念: 流处理…
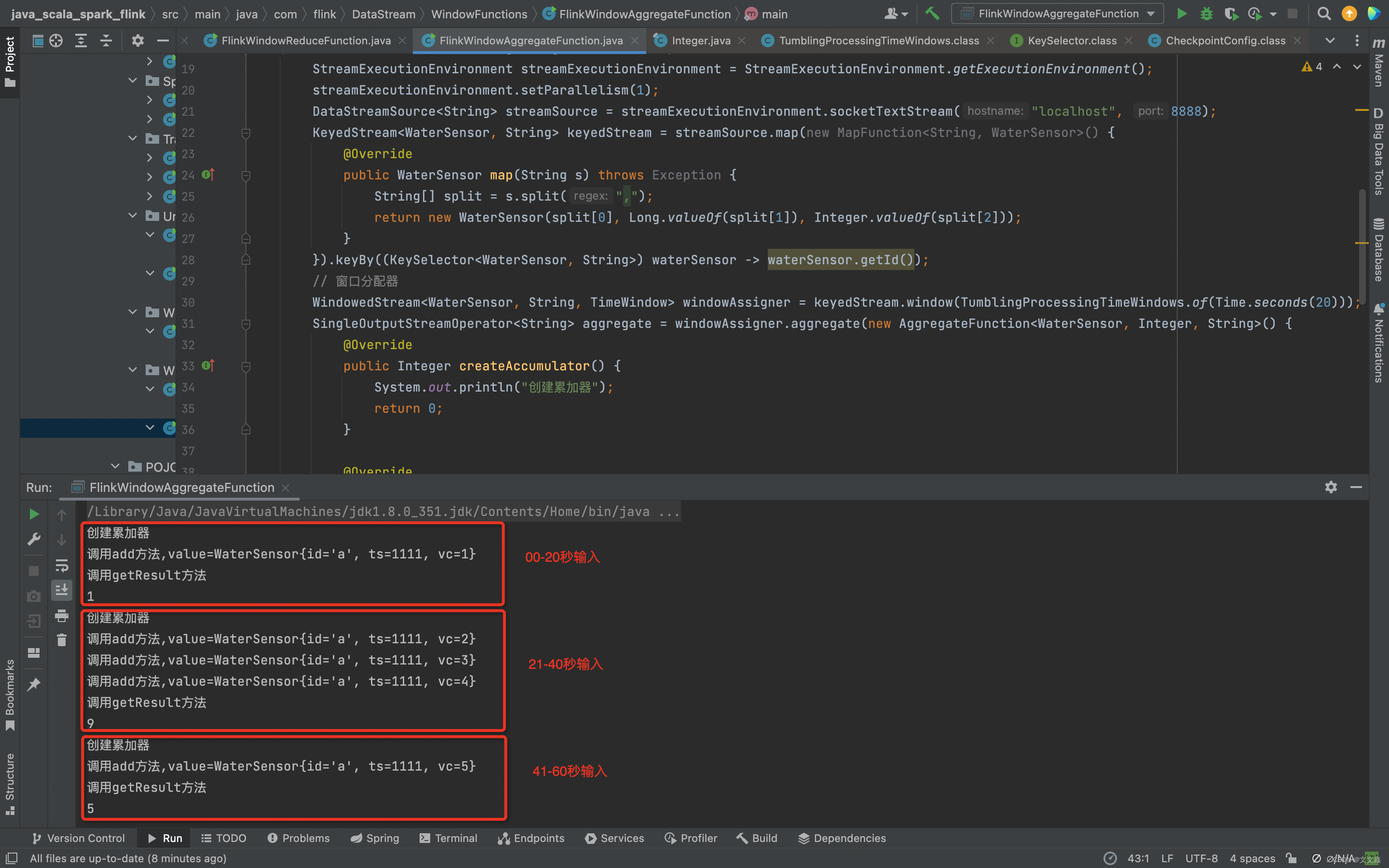
Flink Window中典型的增量聚合函数(ReduceFunction / AggregateFunction)
一、什么是增量聚合函数
在Flink Window中定义了窗口分配器,我们只是知道了数据属于哪个窗口,可以将数据收集起来了;至于收集起来到底要做什么,其实还完全没有头绪,这也就是窗口函数所需要做的事情。所以在窗口分配器…
flink源码分析之功能组件(五)-高可用组件
简介 本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metrics,future。 本文解释高可用组件,包括两项服务,主节点选举和主节点变更通知* 高可用服务常见有两…

物流实时数仓:数仓搭建(DWD)一
系列文章目录
物流实时数仓:采集通道搭建 物流实时数仓:数仓搭建 物流实时数仓:数仓搭建(DIM) 物流实时数仓:数仓搭建(DWD)一 文章目录 系列文章目录前言一、文件编写1.目录创建2.b…
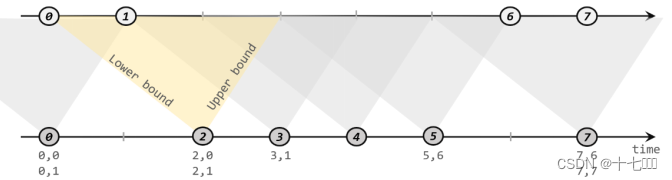
Flink之迟到的数据
迟到数据的处理
推迟水位线推进: WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2))设置窗口延迟关闭:.allowedLateness(Time.seconds(3))使用侧流接收迟到的数据: .sideOutputLateData(lateData)
public class Flink12_LateDataC…
【Flink on k8s】 -- flink kubernetes operator 1.7.0 发布
目录
前言
重大特性
1、自动伸缩
2、版本支持
3、savepoint 触发改进
4、jdk 支持 前言 Flink 官方博客于 2023-11-22 发布了 flink kubernetes operator 1.7.0 发布的消息。这个版本对自动缩放进行了大量的改进,包括与 Kubernetes 的完全分离,以便…
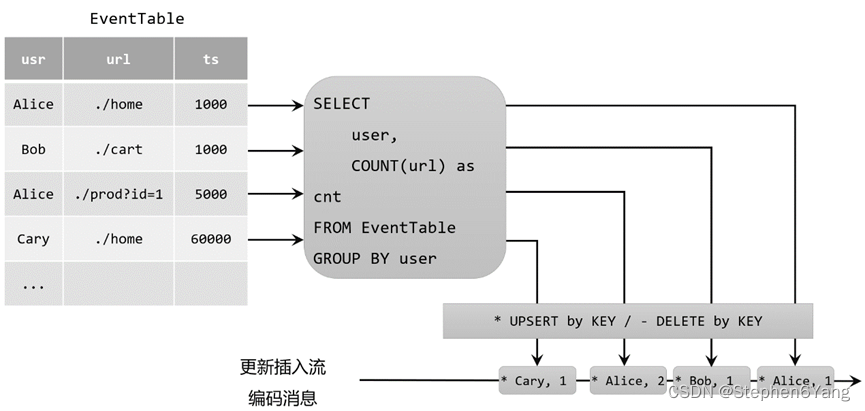
Flink去重计数统计用户数
1.数据
订单表,分别是店铺id、用户id和支付金额
"店铺id,用户id,支付金额",
"shop-1,user-1,1",
"shop-1,user-2,1",
"shop-1,user-2,1",
"shop-1,user-3,1",
"shop-1,user-3,1",
"shop-1,user…
【Flink-Kafka-To-Hive】使用 Flink 实现 Kafka 数据写入 Hive
【Flink-Kafka-To-Hive】使用 Flink 实现 Kafka 数据写入 Hive 1)导入相关依赖2)代码实现2.1.resources2.1.1.appconfig.yml2.1.2.log4j.properties2.1.3.log4j2.xml2.1.4.flink_backup_local.yml 2.2.utils2.2.1.DBConn2.2.2.CommonUtils 2.3.conf2.3.1…
Flink的检查点算法
Flink的恢复机制基于应用状态的一致检查点。在有状态的流应用中,一个一致性检查点是:在所有tasks处理了一个(相同的)输入后,当前时间点每个task的state副本。
在为application做一个一致性检查点时,一个基…
53、Flink 的Broadcast State 模式介绍及示例
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…
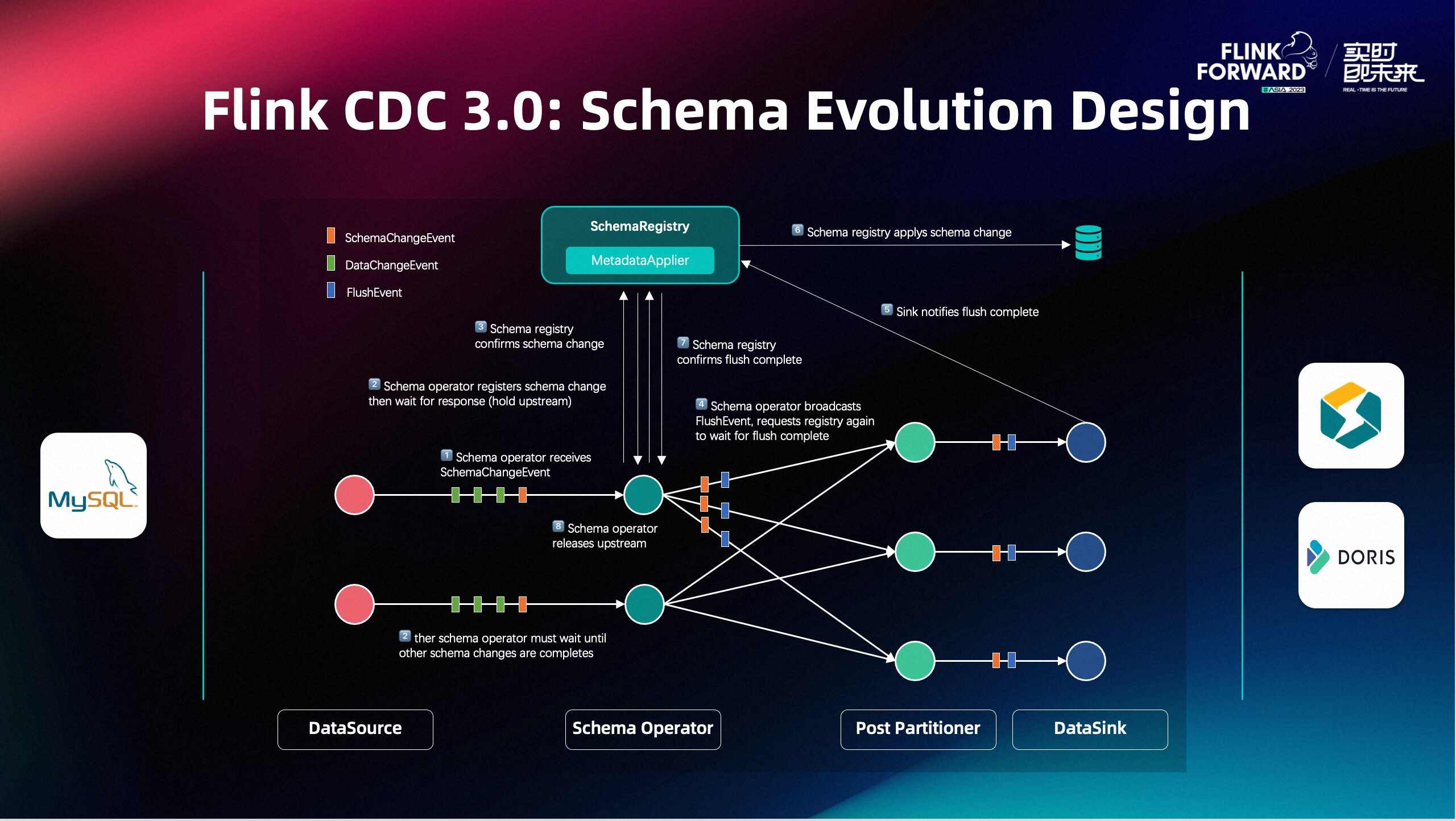
【大数据】Flink CDC 的概览和使用
Flink CDC 的概览和使用 1.什么是 CDC2.什么是 Flink CDC3.Flink CDC 前生今世3.1 Flink CDC 1.x3.2 Flink CDC 2.x3.3 Flink CDC 3.x 4.Flink CDC 使用5.Debezium 标准 CDC Event 格式详解 1.什么是 CDC
CDC(Change Data Capture,数据变更抓取…
为什么 Flink 抛弃了 Scala
曾经红遍一时的Scala
想当初Spark横空出世之后,Scala简直就是语言界的一颗璀璨新星,惹得大家纷纷侧目,连Kafka这类技术框架也选择用Scala语言进行开发重构。 可如今,Flink竟然公开宣布弃用Scala
在Flink1.18的官方文档里&#x…

Flink多流转换(1)—— 分流合流
目录
分流
代码示例
使用侧输出流
合流
联合(Union)
连接(Connect) 简单划分的话,多流转换可以分为“分流”和“合流”两大类
目前分流的操作一般是通过侧输出流(side output)来实现&…
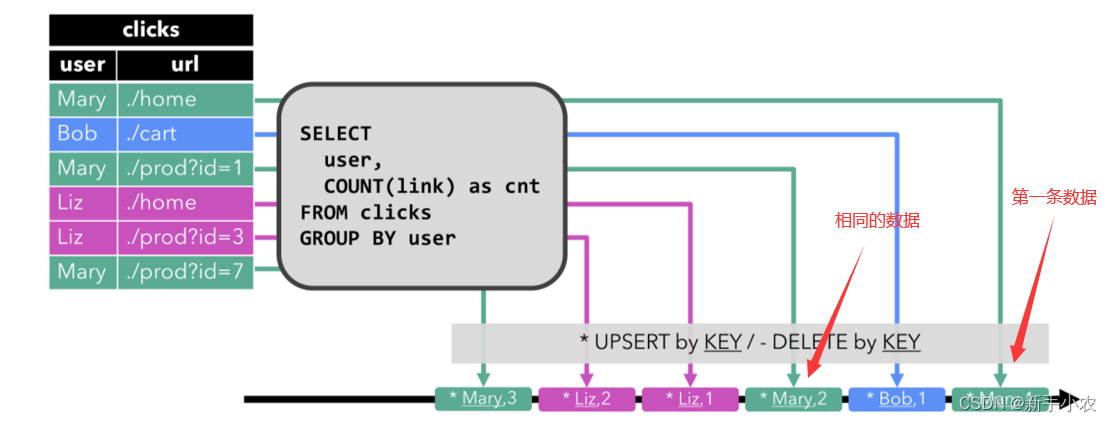
Flink SQL -- 概述
1、Flink SQL中的动态表和连续查询 1、动态表: 因为Flink是可以做实时的,数据是在不断的变化的,所以动态表指的是Flink中一张实时变换的表,表中会不断的有新的数据。但是这张表并不是真正的物理表。 2、连续查询: 连续…
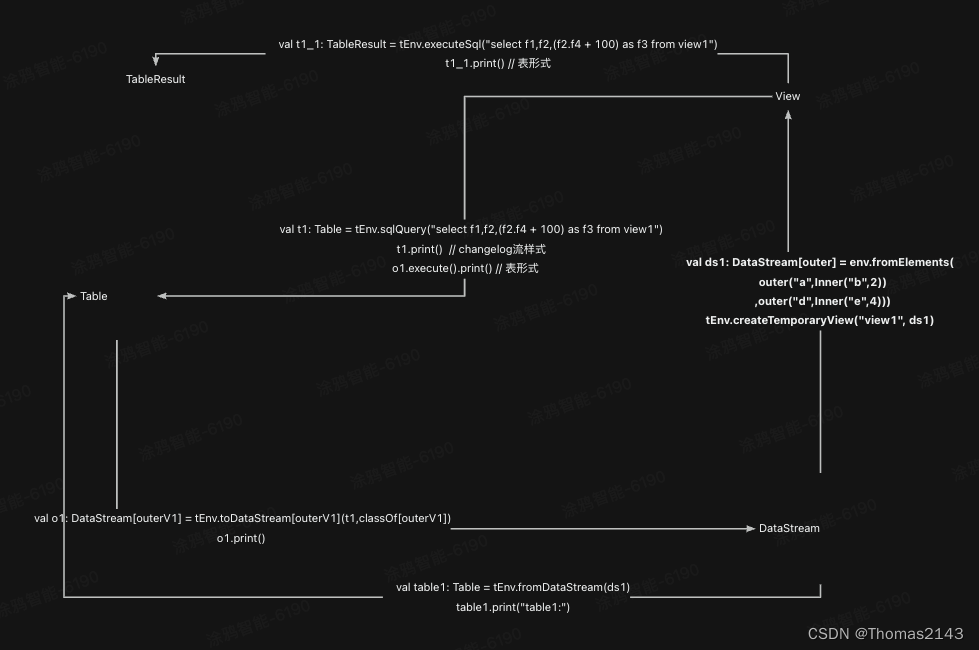
flink table view datastream互转
case class outer(f1:String,f2:Inner) case class outerV1(f1:String,f2:Inner,f3:Int) case class Inner(f3:String,f4:Int)
测试代码
package com.yy.table.convertimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.tabl…
大数据毕设分享 flink大数据淘宝用户行为数据实时分析与可视化
文章目录 0 前言1、环境准备1.1 flink 下载相关 jar 包1.2 生成 kafka 数据1.3 开发前的三个小 tip 2、flink-sql 客户端编写运行 sql2.1 创建 kafka 数据源表2.2 指标统计:每小时成交量2.2.1 创建 es 结果表, 存放每小时的成交量2.2.2 执行 sql &#x…
flink1.18.0 flink维表join新思路
以往常见实现 通过Lookup join来实现维表join
弊端: 虽然缓存可以减轻维表负担,但是如果事实表数据量很大,每秒千万条,维度表只有百万条,也就是说 你会看到大量的无法关联的数据仍然需要查询维度表. cache缓存千万数据量内存压力又比较大, 那么怎么减轻维表数据库压力,还能做…
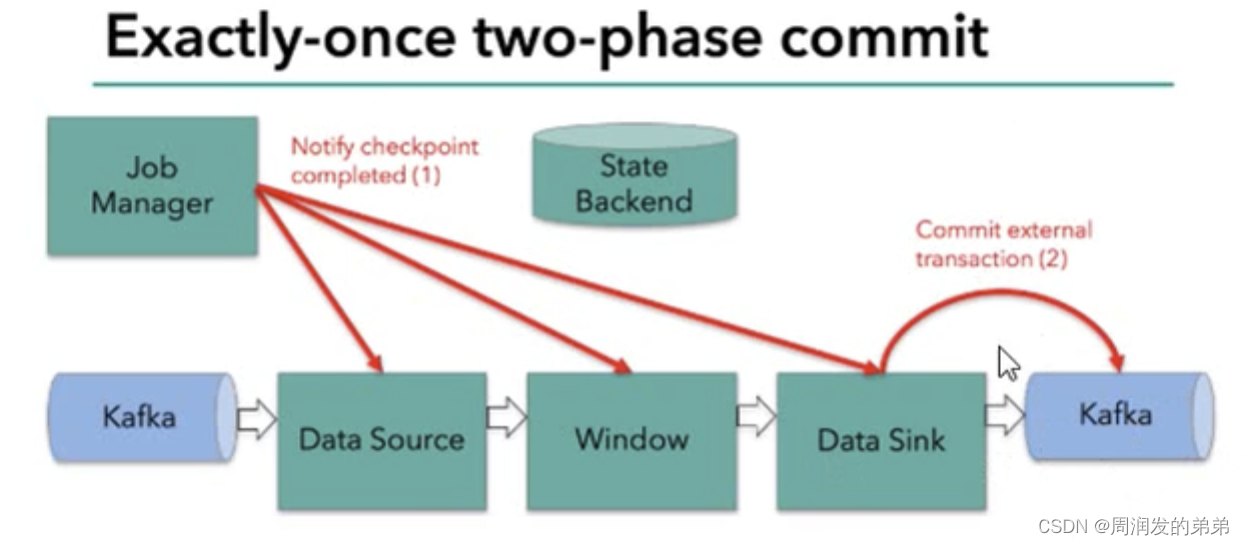
【Flink系列六】Flink里面的状态一致性
状态一致性
有状态的流处理,内部每个算子任务都可以有自己的状态,对于流处理器内部来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确。一条数据不应该丢失,也不应该重复计算。再遇到有故障时可以恢复状态…
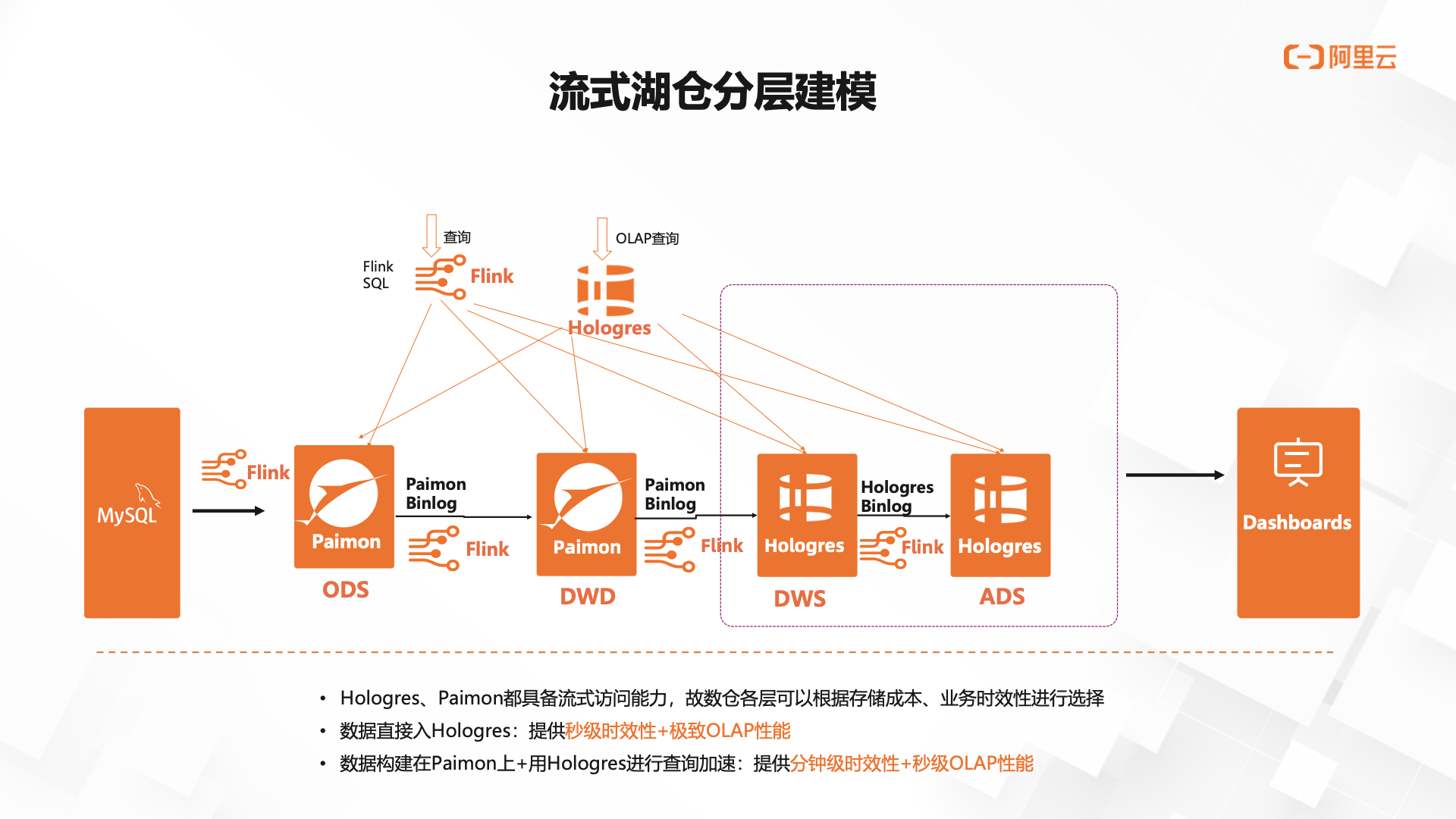
流式湖仓增强,Hologres + Flink构建企业级实时数仓
2023年12月,由阿里云主办的实时计算闭门会在北京举行,阿里云实时数仓Hologres研发负责人姜伟华现场分享HologresFlink构建的企业级实时数仓,实现全链路的数据实时计算、实时写入、实时更新、实时查询。同时,随着流式湖仓的兴起&am…
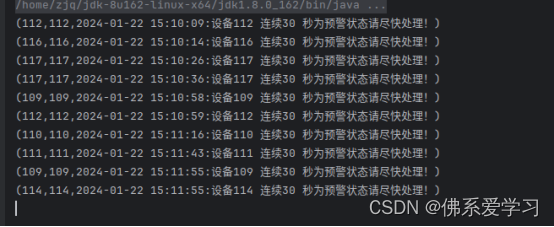
使用Flink处理Kafka中的数据
目录 使用Flink处理Kafka中的数据
前提: 一, 使用Flink消费Kafka中ProduceRecord主题的数据
具体代码为(scala)
执行结果
二, 使用Flink消费Kafka中ChangeRecord主题的数据 具体代码(scala) 具体执行代码① 重要逻…
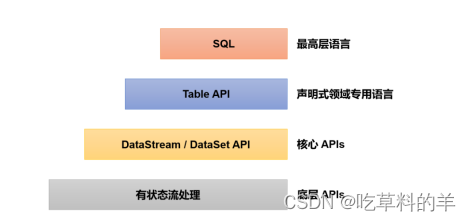
flink学习之窗口处理函数
窗口处理函数
什么是窗口处理函数
Flink 本身提供了多层 API,DataStream API 只是中间的一环,在更底层,我们可以不定义任何具体的算子(比如 map(),filter(),或者 window()),而只是…
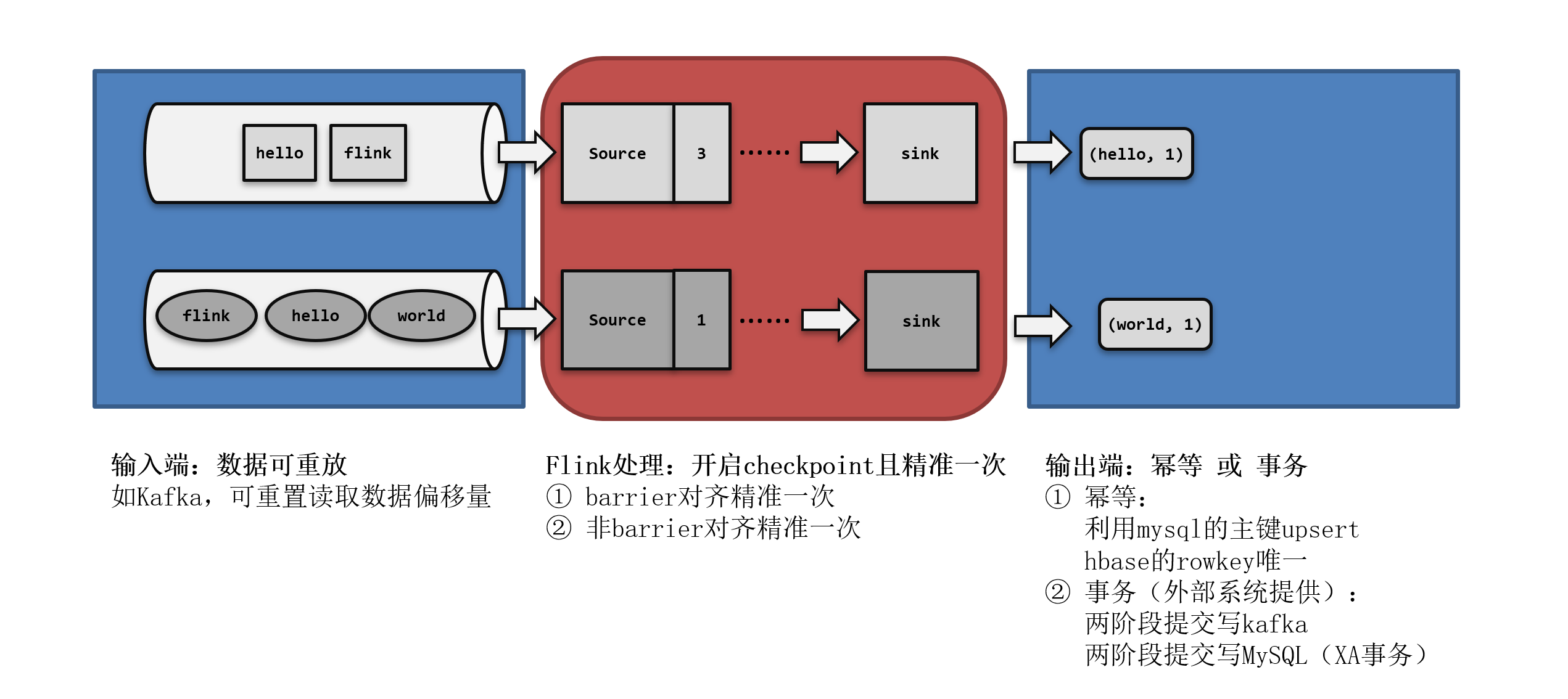
Flink中的容错机制
一.容错机制
在Flink中,有一套完整的容错机制来保证故障后的恢复,其中最重要的就是检查点。
1.1 检查点(Checkpoint)
在流处理中,我们可以用存档读档的思路,将之前某个时间点的所有状态保存下来…
k8s之flink的几种创建方式
在此之前需要部署一下私人docker仓库,教程搭建 Docker 镜像仓库
注意:每台节点的daemon.json都需要配置"insecure-registries": ["http://主机IP:8080"] 并重启 一、session 模式
Session 模式是指在 Kubernetes 上启动一个共享的…
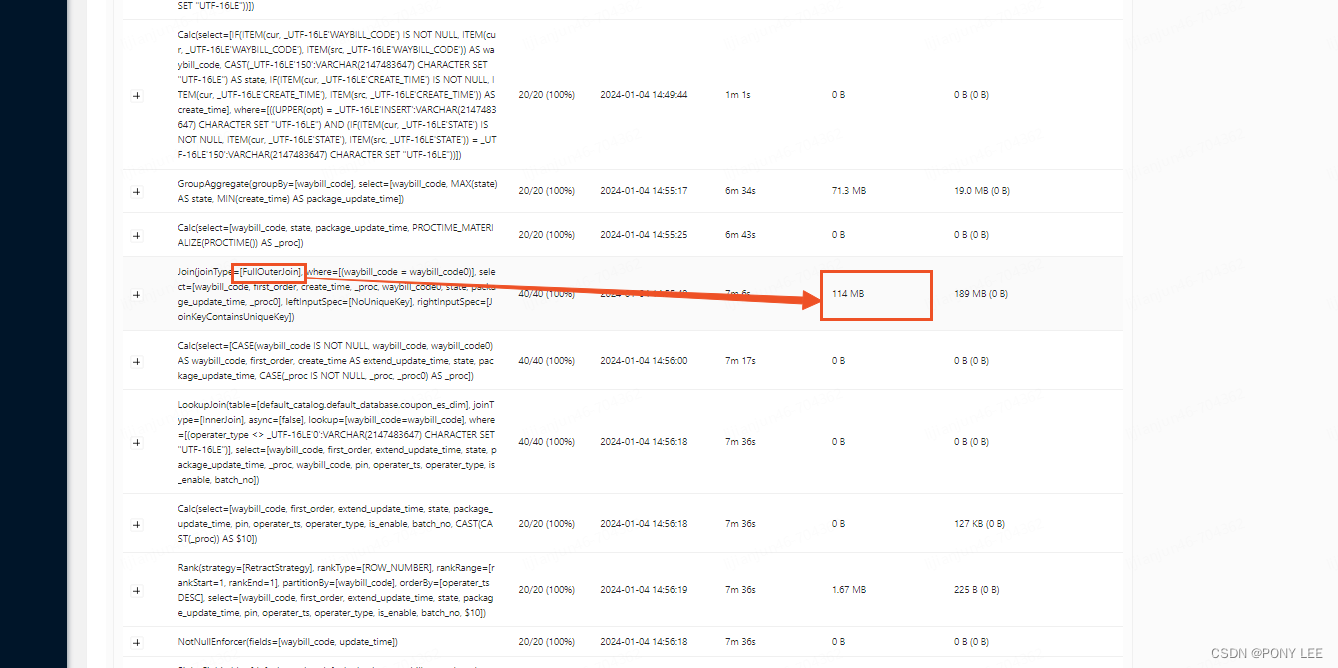
FlinkSQL中【FULL OUTER JOIN】使用实例分析(坑)
Flink版本:flink1.14 最近有【FULL OUTER JOIN】场景的实时数据开发需求,想要的结果是,左右表来了数据都下发数据;左表存在的数据,右表进来可以关联下发(同样,右表存在的数据,左表进…
50、Flink的单元测试介绍及示例
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…

Flink-CEP 实战教程
文章目录 1. 基本概念1.1 CEP 是什么1.2 模式(Pattern)1.3 应用场景 2. 快速上手2.1 引入依赖2.2 入门实例 3. 模式API(Pattern API)3.1 个体模式3.1.1 基本形式3.1.2 量词(Quantifiers )3.1.3 条件&#x…
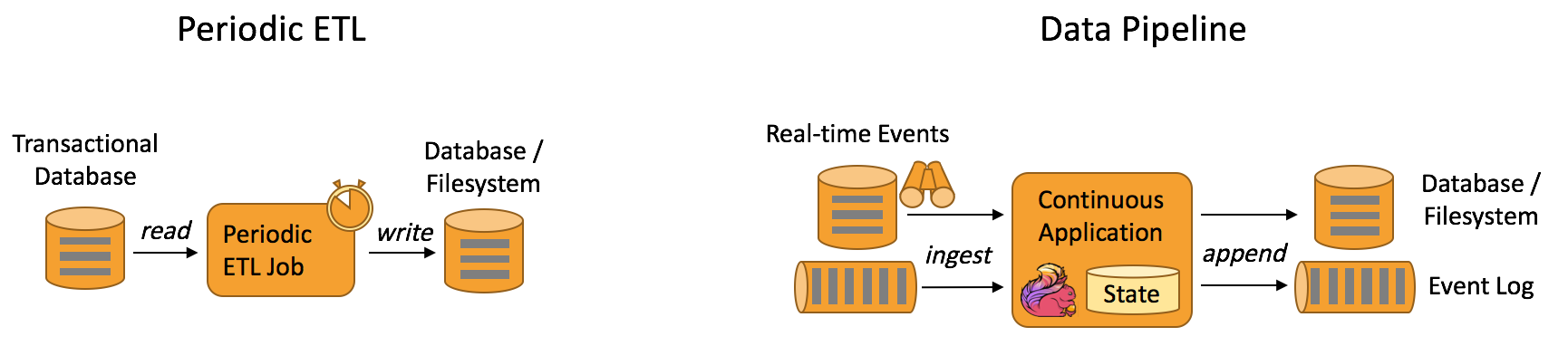
【极数系列】Flink 初相识(01)
# 【极数系列】Flink 初相识(01)
引言
Flink官网:https://flink.apache.org/
Flink版本:https://flink.apache.org/blog/
Flink文档:https://ci.apache.org/projects/flink/flink-docs-release-1.12/
Flink代码库…
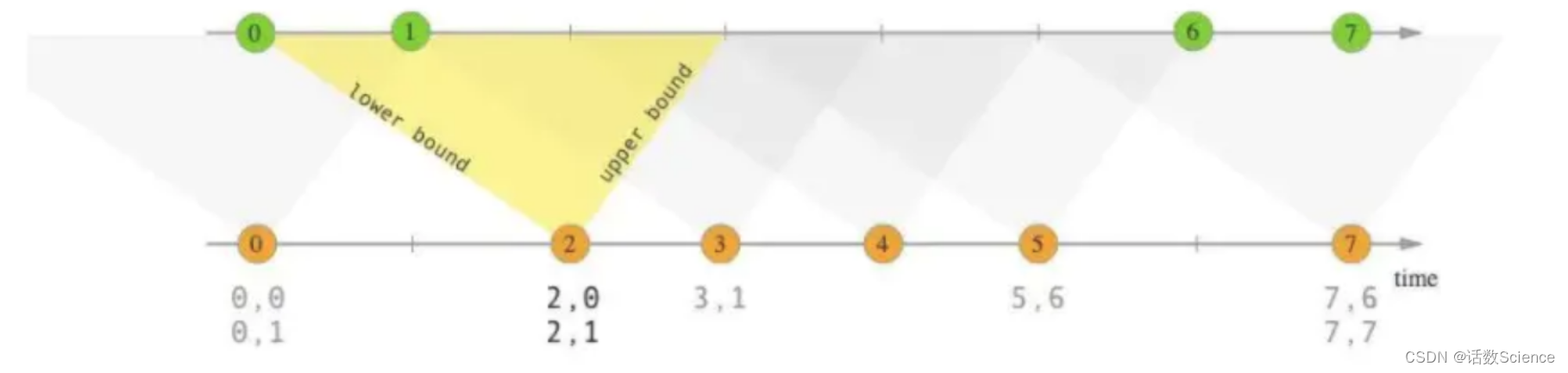
【Flink精讲】Flink数据延迟处理
面试题:Flink数据延迟怎么处理?
将迟到数据直接丢弃【默认方案】将迟到数据收集起来另外处理(旁路输出)重新激活已经关闭的窗口并重新计算以修正结果(Lateness)
Flink数据延迟处理方案
用一个案例说明三…
PiflowX-MysqlCdc组件
MysqlCdc组件
组件说明
MySQL CDC连接器允许从MySQL数据库读取快照数据和增量数据。
计算引擎
flink
组件分组
cdc
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子hostnameHostname“”无是MySQL…
Flink maven日志配置
Flink maven日志配置
maven 配置 <slf4j.version>1.7.30</slf4j.version>
<!-- 引入日志管理相关依赖--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</…

Flink窗口(2)—— Window API
目录
窗口分配器
时间窗口
计数窗口
全局窗口
窗口函数
增量聚合函数
全窗口函数(full window functions)
增量聚合和全窗口函数的结合使用 Window API 主要由两部分构成:窗口分配器(Window Assigners)和窗口函…
如何基于Flink实现定制化功能的开发
前言: 技术为需求服务,通用需求由开源软件提供功能,一些特殊的需求,需要基于场景定制化开发功能。而对于自定义开发功能,Flink则提供了这样的SDK接口能力。
本文将从定制化功能需求分析和如何基于Flink构建定制化功能…
Flink之Task重启策略
Task重启策略
1 策略API noRestart 无参数,task失败后不重启,整个job同时失败,默认策略. 代码示例 RestartStrategies.noRestart();fixedDelayRestart 参数注释restartAttempts最大重启次数delayBetweenAttempts重启时间间隔代码示例 // 最多重启5次,每次任务失败后间隔1s重启…
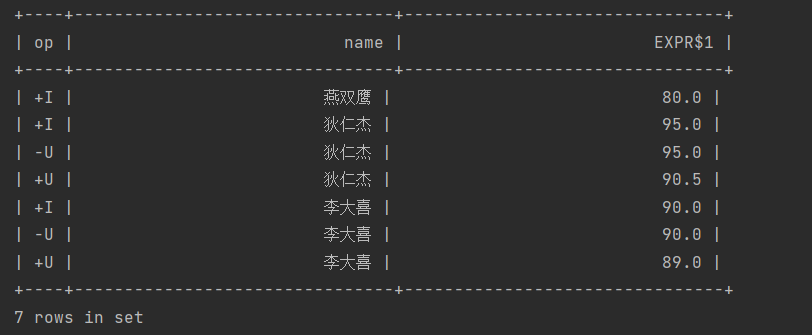
Flink(十五)【Flink SQL Connector、savepoint、CateLog、Table API】
前言 今天一天争取搞完最后这一部分,学完赶紧把 Kafka 和 Flume 学完,就要开始做实时数仓了。据说是应届生得把实时数仓搞个 80%~90% 才能差不多找个工作,太牛马了。
1、常用 Connector 读写 之前我们已经用过了一些简单的内置连接器&#x…
flink源码分析 - yaml解析
flink版本: flink-1.12.1
代码位置: org.apache.flink.configuration.GlobalConfiguration
主要看下解析yaml文件的方法: org.apache.flink.configuration.GlobalConfiguration#loadYAMLResource /** Licensed to the Apache Software Foundation (ASF) under one* or…
物流实时数仓DWD层——1.准备工作
目录
1.创建主程序——DwdOrderRelevantApp类
2.创建DWD层的事实表——来源于订单表和订单明细表
(1)创建订单表实体类
(2)创建订单明细表实体类
(3)创建交易域:下单事务事实表实体类,并整合(1)与(2),采用下单时间
(4)创建交易域&#…
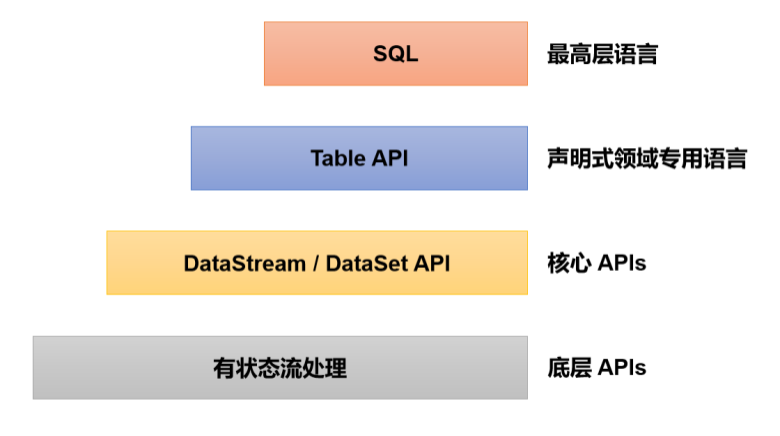
Flink 处理函数(1)—— 基本处理函数
在 Flink 的多层 API中,处理函数是最底层的API,是所有转换算子的一个概括性的表达,可以自定义处理逻辑 在处理函数中,我们直面的就是数据流中最基本的元素:数据事件(event)、状态(st…
【Flink-1.17-教程】-【二】Flink 集群搭建、Flink 部署、Flink 运行模式
【Flink-1.17-教程】-【二】Flink 集群搭建、Flink 部署、Flink 运行模式 1)集群角色2)Flink 集群搭建2.1.集群启动2.2.向集群提交作业 3)部署模式3.1.会话模式(Session Mode)3.2.单作业模式(Per-Job Mode&…

【大数据】Flink 详解(九):SQL 篇 Ⅱ
《Flink 详解》系列(已完结),共包含以下 10 10 10 篇文章:
【大数据】Flink 详解(一):基础篇【大数据】Flink 详解(二):核心篇 Ⅰ【大数据】Flink 详解&…

Flink(十二)【容错机制】
前言 最近已经放假了,但是一直在忙一个很重要的自己的一个项目,用 JavaFX 和一个大数据组件联合开发一个功能,也算不枉我学了一次 JavaFX,收获很大,JavaFX 它作为一个 GUI 开发语言,本质还是 Javaÿ…

详解flink exactly-once和两阶段提交
以下是我们常见的三种 flink 处理语义:
最多一次(At-most-Once):用户的数据只会被处理一次,不管成功还是失败,不会重试也不会重发。
至少一次(At-least-Once):系统会保…
StreamX流批一体一站式大数据平台:大数据Flink可视化工具的革命性突破,让你的数据更高效、更直观!
介绍:StreamX,开源的流批一体一站式大数据平台,致力于让Flink开发更简单。它极大地降低了学习成本和开发门槛,使开发者可以专注于最核心的业务。StreamX支持Flink多版本, 与Flink SQL WebIDE兼容,并可以进行…
FlinkSQL【分组聚合-多维分析-性能调优】应用实例分析
FlinkSQL处理如下实时数据需求: 实时聚合不同 类型/账号/发布时间 的各个指标数据,比如:初始化/初始化后删除/初始化后取消/推送/成功/失败 的指标数据。要求实时产出指标数据,数据源是mysql cdc binlog数据。
代码实例
--SET t…
深入理解与应用Flink中的水印机制
在Apache Flink这一现代大数据处理框架中,对实时流数据的高效、准确处理是一个核心诉求。为实现这一目标,Flink引入了一种独特而强大的时间管理机制——水印(Watermark),它在处理无界流时起到了关键的作用,…
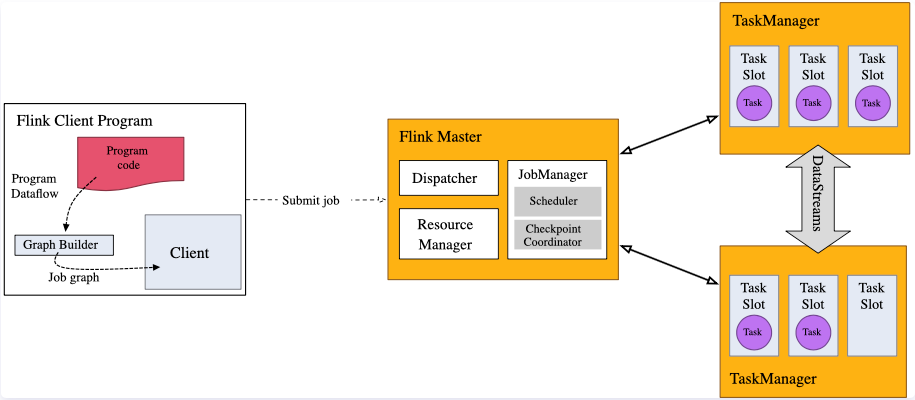
Flink编程——最小程序MiniProgram
最小程序MiniProgram
前面我们已经搭建起了Flink 的基础环境,这一节我们就在上一节的基础上,进行编写我们的第一个Flink 程序,开始之前我们先看一下一个完整的Flink 程序是什么样的
Flink 程序结构
为了演示Flink 程序结构,我们…
【Flink-1.17-教程】-【四】Flink DataStream API(5)转换算子(Transformation)【分流】
【Flink-1.17-教程】-【四】Flink DataStream API(5)转换算子(Transformation)【分流】 1)使用 filter 简单实现2)使用侧输出流实现 所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多…
Flink(十三)【Flink SQL(上)】
前言 最近在假期实训,但是实在水的不行,三天要学完SSM,实在一言难尽,浪费那时间干什么呢。SSM 之前学了一半,等后面忙完了,再去好好重学一遍,毕竟这玩意真是面试必会的东西。 今天开始学习 Flin…
物流实时数仓——概述与准备工作
目录
一、架构设计与技术栈
(一)数仓架构设计 (二)所用技术栈
(三)最终效果
二、关于离线与实时的相关概念
三、实时数仓设计思路 一、架构设计与技术栈
(一)数仓架构设计 (二)所用技术栈 Hadoop 3.3.4 Zookeeper 3.7.1 Kafka 3.3.1 Hbase 2.4.11 Redis 6.0.8 Flink 1.17…
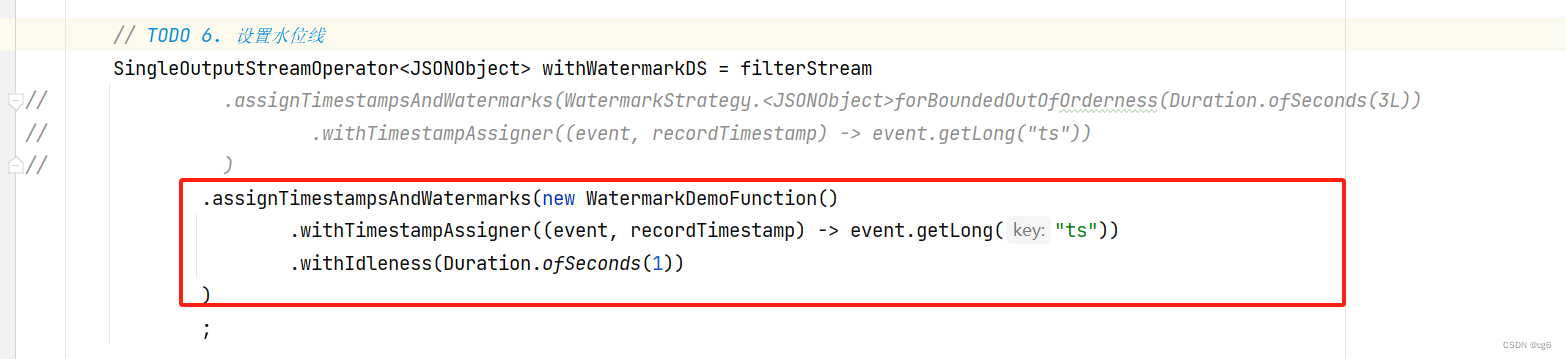
flink 最后一个窗口一直没有新数据,窗口不关闭问题
flink 最后一个窗口一直没有新数据,窗口不关闭问题 自定义实现 WatermarkStrategy接口 自定义实现 WatermarkStrategy接口
代码: public static class WatermarkDemoFunction implements WatermarkStrategy<JSONObject>{private Tuple2<Long,B…
【性能调优】local模式下flink处理离线任务能力分析
文章目录 一. flink的内存管理1.Jobmanager的内存模型2.TaskManager的内存模型2.1. 模型说明2.2. 通讯、数据传输方面2.3. 框架、任务堆外内存2.4. 托管内存 3.任务分析 二. 单个节点的带宽瓶颈1. 带宽相关理论2. 使用speedtest-cli 测试带宽3. 任务分析3. 其他工具使用介绍 本…

【大数据】Flink 系统架构
Flink 系统架构 1.Flink 组件1.1 JobManager1.2 ResourceManager1.3 TaskManager1.4 Dispatcher 2.应用部署2.1 框架模式2.2 库模式 3.任务执行4.高可用设置4.1 TaskManager 故障4.2 JobManager 故障 Flink 是一个用于状态化并行流处理的分布式系统。它的搭建涉及多个进程&…
Flink状态应用测试程序示例
Flink状态应用测试程序示例
1. 创建执行环境 // 1. 创建执行环境StreamExecutionEnvironment env StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1); 2. 创建数据流 // 2. 创建数据流DataStream<Tuple2<String, Integer>> inputSt…
flink 1.18 sql demo
flink 1.18 sql demo
更换flink-table-planner 为 flink-table-planner-loader pom.xml <dependencies><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-uber --><dependency><groupId>org.apache.flink</groupId…
基于 Hologres+Flink 的曹操出行实时数仓建设
本文整理自曹操出行实时计算负责人林震基于 HologresFlink 的曹操出行实时数仓建设的分享,内容主要分为以下六部分: 曹操出行业务背景介绍曹操出行业务痛点分析HologresFlink 构建企业级实时数仓曹操出行实时数仓实践曹操出行业务成果分析未来展望 一、曹…

Flink编程——风险欺诈检测
Flink 风险欺诈检测 文章目录 Flink 风险欺诈检测背景准备条件FraudDetectionJob.javaFraudDetector.java 代码分析执行环境创建数据源对事件分区 & 欺诈检测输出结果运行作业欺诈检测器 欺诈检测器 v1:状态欺诈检测器 v2:状态 时间完整的程序期望的…
【Flink】FlinkSQL读取Mysql表中时间字段相差13个小时
问题:Flink版本1.13,在我们使用FlinkSQL读取Mysql中数据的时候,发现读取出来的时间字段中的数据和Mysql表中的数据相差13个小时,Mysql建表语句及插入的数据如下; CREATE TABLE `mysql_example` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 自增ID, `name` v…
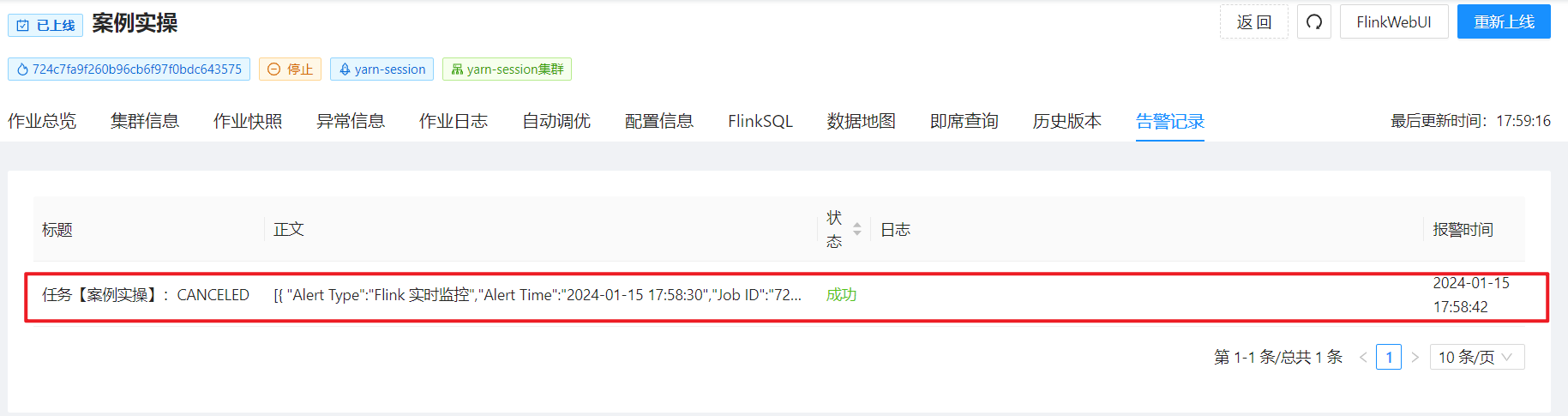
【总结】Dinky学习笔记
概述
Dinky 是一个开箱即用、易扩展,以 Apache Flink 为基础,连接 OLAP 和数据湖等众多框架的一站式实时计算平台,致力于流批一体和湖仓一体的探索与实践 官网:Dinky
核心特性
沉浸式:提供专业的 DataStudio 功能&a…
【flink番外篇】15、Flink维表实战之6种实现方式-通过Temporal table实现维表数据join
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…

基于华为MRS3.2.0实时Flink消费Kafka落盘至HDFS的Hive外部表的调度方案
文章目录 1 Kafka1.1 Kerberos安全模式的认证与环境准备1.2 创建一个测试主题1.3 消费主题的接收测试 2 Flink1.1 Kerberos安全模式的认证与环境准备1.2 Flink任务的开发 3 HDFS与Hive3.1 Shell脚本的编写思路3.2 脚本测试方法 4 DolphinScheduler 该需求为实时接收对手Topic&a…

flink if函数false时对字符串做阶段的bug
背景
flink官网对if函数就是我们正常的理解 我们之前在使用flink1.12时候也没有发现问题,但是最近一个1.15的任务出现了一个bug 本来应该返回cdefg,但是返回了cde if(false,abc,cdefg) --返回cde我们找了一下这个函数,发现代码确实是这样理…

【大数据】流处理基础概念(一):Dataflow 编程基础、并行流处理
流处理基础概念(一):Dataflow 编程基础、并行流处理 1.Dataflow 编程基础1.1 Dataflow 图1.2 数据并行和任务并行1.3 数据交换策略 2.并行流处理2.1 延迟与吞吐2.1.1 延迟2.1.2 吞吐2.1.3 延迟与吞吐 2.2 数据流上的操作2.2.1 数据接入和数据…
flinkcdc 3.0 尝鲜
本文会将从环境搭建到demo来全流程体验flinkcdc 3.0 包含了如下内容 flink1.18 standalone搭建doris 1fe1be 搭建整库数据同步测试各同步场景从检查点重启同步任务 环境搭建
flink环境(Standalone模式)
下载flink 1.18.0 链接 : https://archive.apache.org/dist/flink/flink…
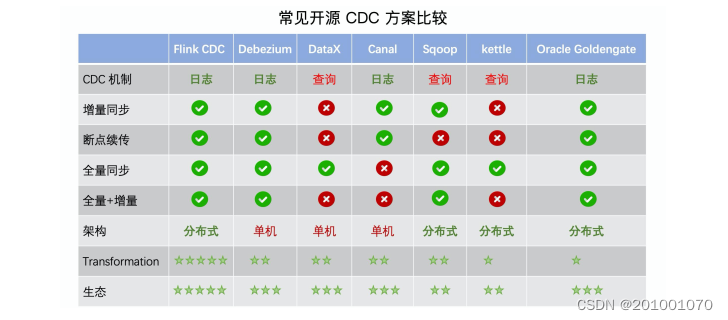
flink1.13环境搭建
1、本地启动非集群模式
最简单的启动方式,其实是不搭建集群,直接本地启动。本地部署非常简单,直接解压安装包就可以使用,不用进行任何配置;一般用来做一些简单的测试。 具体安装步骤如下:
1.1 下载安装包…

【大数据】流处理基础概念(二):时间语义(处理时间、事件时间、水位线)
流处理基础概念(二):时间语义 1.流处理场景下一分钟的含义2.处理时间3.事件时间4.水位线5.处理时间与事件时间 本篇博客,我们将介绍流式场景中时间语义和不同的时间概念。我们将讨论流处理引擎如何基于乱序事件产生精确结果&#…
Flink对接Kafka的topic数据消费offset设置参数
scan.startup.mode 是 Flink 中用于设置消费 Kafka topic 数据的起始 offset 的配置参数之一。
scan.startup.mode 可以设置为以下几种模式:
earliest-offset:从最早的 offset 开始消费数据。latest-offset:从最新的 offset 开始消费数据。…
【大数据】Flink 中的数据传输
Flink 中的数据传输 1.基于信用值的流量控制2.任务链接 在运行过程中,应用的任务会持续进行数据交换。TaskManager 负责将数据从发送任务传输至接收任务。它的网络模块在记录传输前会先将它们收集到 缓冲区 中。换言之,记录并非逐个发送的,而…
flink部署模式介绍
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink 为各种场景提供了不同的部署模式,主要有以下三种,它们的区别主要在于:
集群的生命周期以及资源的分配方式;应用的 main 方法到…
Flink State backend状态后端
概述
Flink在v1.12到v1.14的改进当中,其状态后端也发生了变化。老版本的状态后端有三个,分别是MemoryStateBackend、FsStateBackend、RocksDBStateBackend,在flink1.14中,这些状态已经被废弃了,新版本的状态后端是 HashMapStateBackend、EmbeddedRocksDBStateBackend。
…
Spring SpEL在Flink中的应用-与FlatMap结合实现数据动态计算
文章目录 前言一、POM依赖二、主函数代码示例三、RichFlatMapFunction实现总结 前言
SpEL表达式与Flink FlatMapFunction或MapFunction结合可以实现基于表达式的简单动态计算。有关SpEL表达式的使用请参考Spring SpEL在Flink中的应用-SpEL详解。 可以将计算表达式放入数据库&a…
【Flink】记录Flink 任务单独设置配置文件而不使用集群默认配置的一次实践
前言
我们的大数据环境是 CDP 环境。该环境已经默认添加了Flink on Yarn 的客户端配置。 我们的 Flink 任务类型是 Flink on Yarn 的任务。
默认的配置文件是在 /etc/flink/conf 目录下。如今我们的需求是个别任务提供的配置仅用于配置执行参数,例如影响作业的配置…
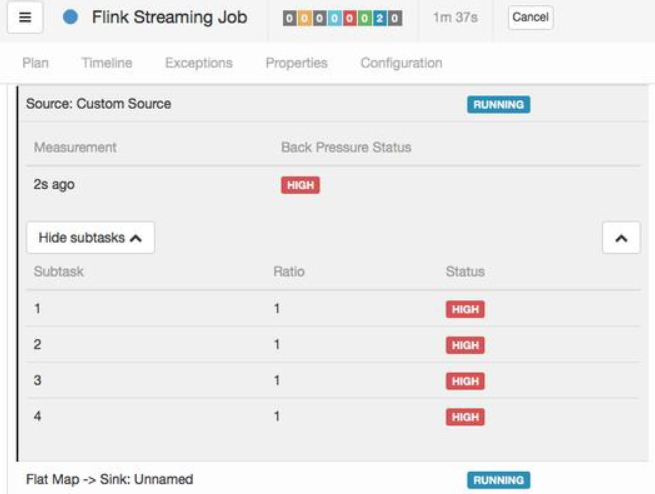
Flink生产环境相关问题
1. FlinkKafka保证精确一次消费相关问题?
Fink的检查点和恢复机制和可以重置读位置的source连接器结合使用,比如kafka,可以保证应用程序不会丢失数据。尽管如此,应用程序可能会发出两次计算结果,因为从上一次检查点恢…
spark-flink设计思想之吸星大法-1
Spark和Flink都是大数据处理框架,它们的设计思想有一些不同之处。以下是对它们设计思想的简要对比: 数据模型和计算模型: Spark:Spark使用弹性分布式数据集(RDD)作为其核心数据结构。RDD是只读的、不可变的…

【大数据】详解 Flink 中的 WaterMark
详解 Flink 中的 WaterMark 1.基础概念1.1 流处理1.2 乱序1.3 窗口及其生命周期1.4 Keyed vs Non-Keyed1.5 Flink 中的时间 2.Watermark2.1 案例一2.2 案例二2.3 如何设置最大乱序时间2.4 延迟数据重定向 3.在 DDL 中的定义3.1 事件时间3.2 处理时间 1.基础概念
1.1 流处理
流…

【大数据】Flink 中的状态管理
Flink 中的状态管理 1.算子状态2.键值分区状态3.状态后端4.有状态算子的扩缩容4.1 带有键值分区状态的算子4.2 带有算子列表状态的算子4.3 带有算子联合列表状态的算子4.4 带有算子广播状态的算子 在前面的博客中我们指出,大部分的流式应用都是有状态的。很多算子都…
【大数据】Flink 架构(四):状态管理
Flink 架构(四):状态管理 1.算子状态2.键值分区状态3.状态后端4.有状态算子的扩缩容4.1 带有键值分区状态的算子4.2 带有算子列表状态的算子4.3 带有算子联合列表状态的算子4.4 带有算子广播状态的算子 在前面的博客中我们指出,大…
【大数据】Flink 架构(一):系统架构
Flink 架构(一):系统架构 1.Flink 组件1.1 JobManager1.2 ResourceManager1.3 TaskManager1.4 Dispatcher 2.应用部署2.1 框架模式2.2 库模式 3.任务执行4.高可用设置4.1 TaskManager 故障4.2 JobManager 故障 Flink 是一个用于状态化并行流处…
【极数系列】docker环境搭建Flink1.18版本(04)
文章目录 引言01 Linux安装Docker1.安装yum-utils软件包2.安装docker3.启动docker4.设置docker自启动5.配置Docker使用systemd作为默认Cgroup驱动6.重启docker 02 docker部署Flink1.18版本1.拉取最新镜像2.检查镜像3.编写dockerFile文件4.执行dockerFile5.检查flink是否启动成功…

【大数据】Flink 架构(六):保存点 Savepoint
《Flink 架构》系列(已完结),共包含以下 6 篇文章:
Flink 架构(一):系统架构Flink 架构(二):数据传输Flink 架构(三):事件…
【极数系列】Flink环境搭建Docker版本(04)
文章目录 引言01 Linux安装Docker1.安装yum-utils软件包2.安装docker3.启动docker4.设置docker自启动5.配置Docker使用systemd作为默认Cgroup驱动6.重启docker 02 docker部署Flink1.18版本1.拉取最新镜像2.检查镜像3.编写dockerFile文件4.执行dockerFile5.检查flink是否启动成功…

60、Flink CDC 入门介绍及Streaming ELT示例(同步Mysql数据库数据到Elasticsearch)-完整版
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…
【极数系列】Flink环境搭建Linux版本 (03)
文章目录 引言01 Linux部署JDK11版本1.下载Linux版本的JDK112.创建目录3.上传并解压4.配置环境变量5.刷新环境变量6.检查jdk安装是否成功 02 Linux部署Flink1.18.0版本1.下载Flink1.18.0版本包2.上传压缩包到服务器3.修改flink-config.yaml配置4.启动服务5.浏览器访问6.停止服务…

【大数据】Flink SQL 语法篇(二):WITH、SELECT WHERE、SELECT DISTINCT
Flink SQL 语法篇(二) 1.WITH 子句2.SELECT & WHERE 子句3.SELECT DISTINCT 子句 1.WITH 子句
应用场景(支持 Batch / Streaming):With 语句和离线 Hive SQL With 语句一样的,语法糖 1,使用…
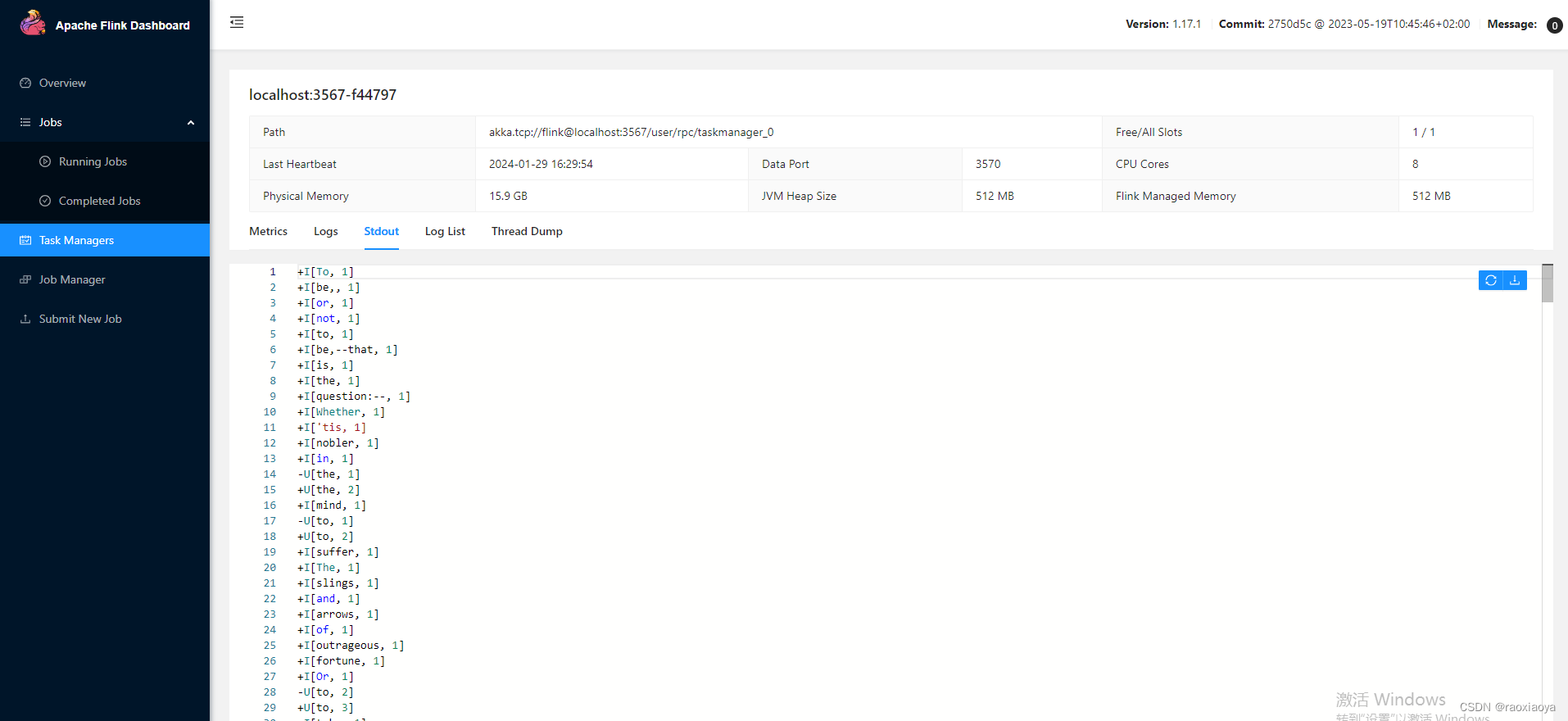
PyFlink使用教程,Flink,Python,Java
环境准备
环境要求
Java 11
Python 3.7, 3.8, 3.9 or 3.10文档:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/dev/python/installation/
打开 Anaconda3 Prompt
> java -version
java version "11.0.22" 2024-01-16 LTS
J…
Flink的SQL开发
概叙
Flink有关FlinkSQL的官网:
https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/dev/table/sql/overview/
阿里云有关FlinkSQL的官网:
https://help.aliyun.com/zh/flink/developer-reference/overview-5?spma2c4g.11186623.0.0.3f55bbc6H3LVyo Ta…
Flink CDC 3.0 表结构变更的处理流程
Flink CDC 3.0 表结构变更的处理流程
表结构变更主要涉及到三个类SchemaOperator、DataSinkWriterOperator(Sink端)和SchemaRegistry(协调器);SchemaOperator接收结构变更消息时会通知sink端和协调器,并…
37、Flink 的CDC 格式:debezium部署以及mysql示例(1)-debezium的部署与示例
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、…

【大数据】Flink SQL 语法篇(三):窗口聚合(TUMBLE、HOP、SESSION、CUMULATE)
Flink SQL 语法篇(三):窗口聚合 1.滚动窗口(TUMBLE)1.1 Group Window Aggregation 方案(支持 Batch / Streaming 任务)1.2 Windowing TVF 方案(1.13 只支持 Streaming 任务ÿ…
Flink CEP实现10秒内连续登录失败用户分析
1、什么是CEP?
Flink CEP即 Flink Complex Event Processing,是基于DataStream流式数据提供的一套复杂事件处理编程模型。你可以把他理解为基于无界流的一套正则匹配模型,即对于无界流中的各种数据(称为事件),提供一种组合匹配的…
【极数系列】Flink集成DataSource读取Socket请求数据(09)
文章目录 01 引言02 简介概述03 基于socket套接字读取数据3.1 从套接字读取。元素可以由分隔符分隔。3.2 windows安装netcat工具(1)下载netcat工具(2)安装部署(3)启动socket端口监听 04 源码实战demo4.1 po…
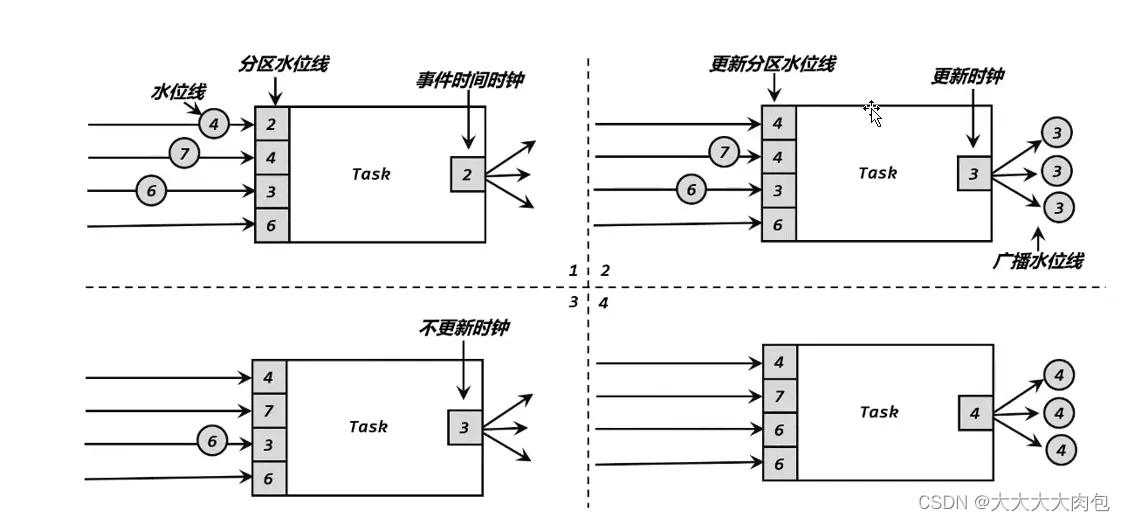
Flink中的时间语义和TTL
时间语义
事件时间(Event Time)
事件时间是数据生成的时间,是数据流中每个元素或者每个事件自带的时间属性,一般是事件发生的时间,在实际项目中作为前端的一个属性嵌入。在理想情况下,数据应当按照事件时…

使用 Paimon + StarRocks 极速批流一体湖仓分析
摘要:本文整理自阿里云智能高级开发工程师王日宇,在 Flink Forward Asia 2023 流式湖仓(二)专场的分享。本篇内容主要分为以下四部分: StarRocksPaimon 湖仓分析的发展历程使用 StarRocksPaimon 进行湖仓分析主要场景和…
Flink实战五_状态机制
接上文:Flink实战四_TableAPI&SQL 在学习Flink的状态机制之前,我们需要理解什么是状态。回顾我们之前介绍的很多流计算的计算过程,有些计算方法,比如说我们之前多次使用的将stock.txt中的一行文本数据转换成Stock股票对象的ma…

Flink 1.18.1的基本使用
系统示例应用
/usr/local/flink-1.18.1/bin/flink run /usr/local/flies/streaming/SocketWindowWordCount.jar --port 9010nc -l 9010
asd asd sdfsf sdf sdfsdagd sdf单次统计示例工程
cd C:\Dev\IdeaProjectsmvn archetype:generate -DarchetypeGroupIdorg.apache.flink -…
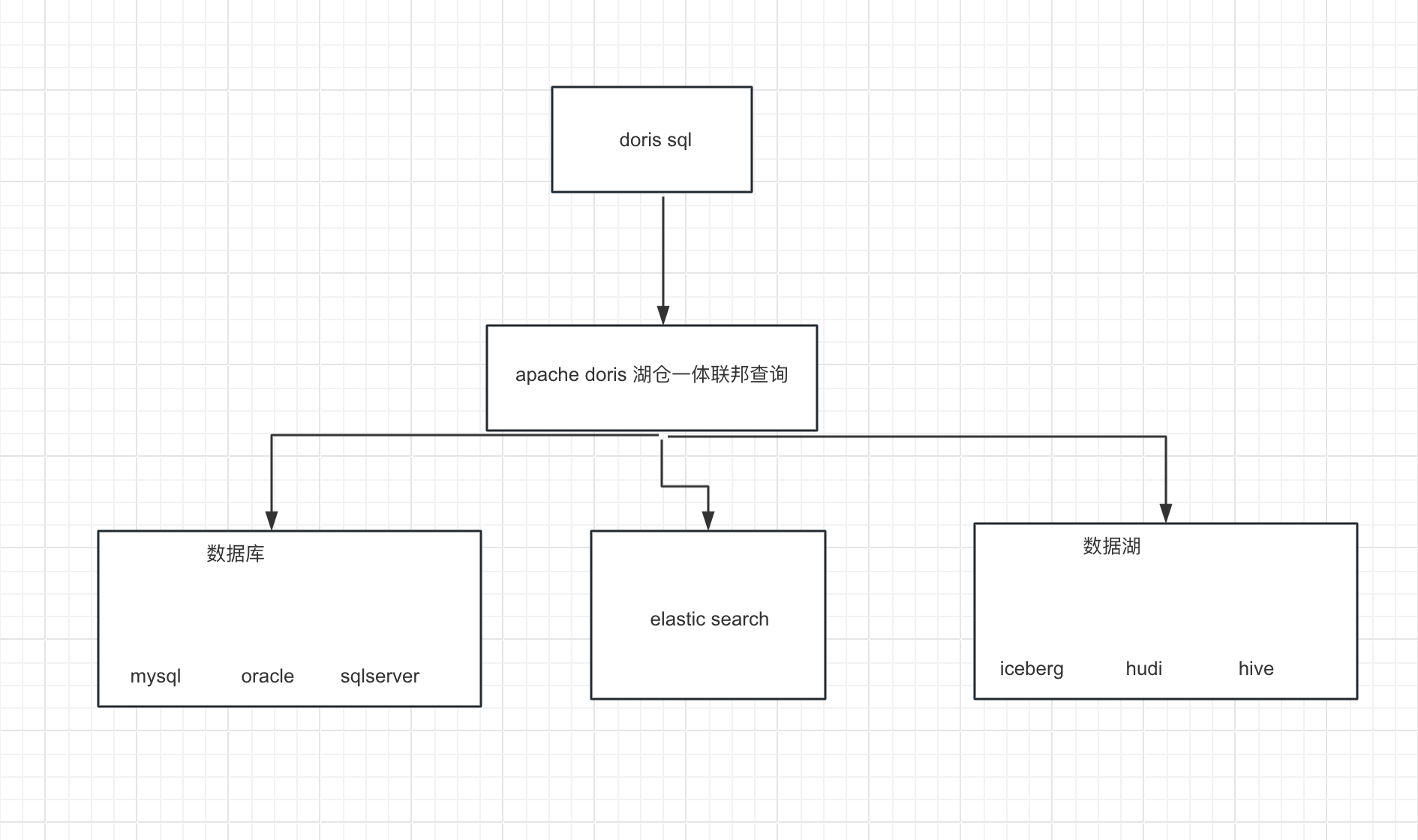
Apache Doris 整合 FLINK CDC + Iceberg 构建实时湖仓一体的联邦查询
1概况
本文展示如何使用 Flink CDC Iceberg Doris 构建实时湖仓一体的联邦查询分析,Doris 1.1版本提供了Iceberg的支持,本文主要展示Doris和Iceberg怎么使用,大家按照步骤可以一步步完成。完整体验整个搭建操作的过程。
2系统架构
我们整…
Flink实时数仓同步:流水表实战详解
一、背景
在大数据领域,初始阶段业务数据通常被存储于关系型数据库,如MySQL。然而,为满足日常分析和报表等需求,大数据平台采用多种同步方式,以适应这些业务数据的不同存储需求。这些同步存储方式包括离线仓库和实时仓…
FlinkCDC全量及增量采集SqlServer数据
本文将详细介绍Flink-CDC如何全量及增量采集Sqlserver数据源,准备适配Sqlserver数据源的小伙伴们可以参考本文,希望本文能给你带来一定的帮助。 一、Sqlserver的安装及开启事务日志
如果没有Sqlserver环境,但你又想学习这块的内容&#x…
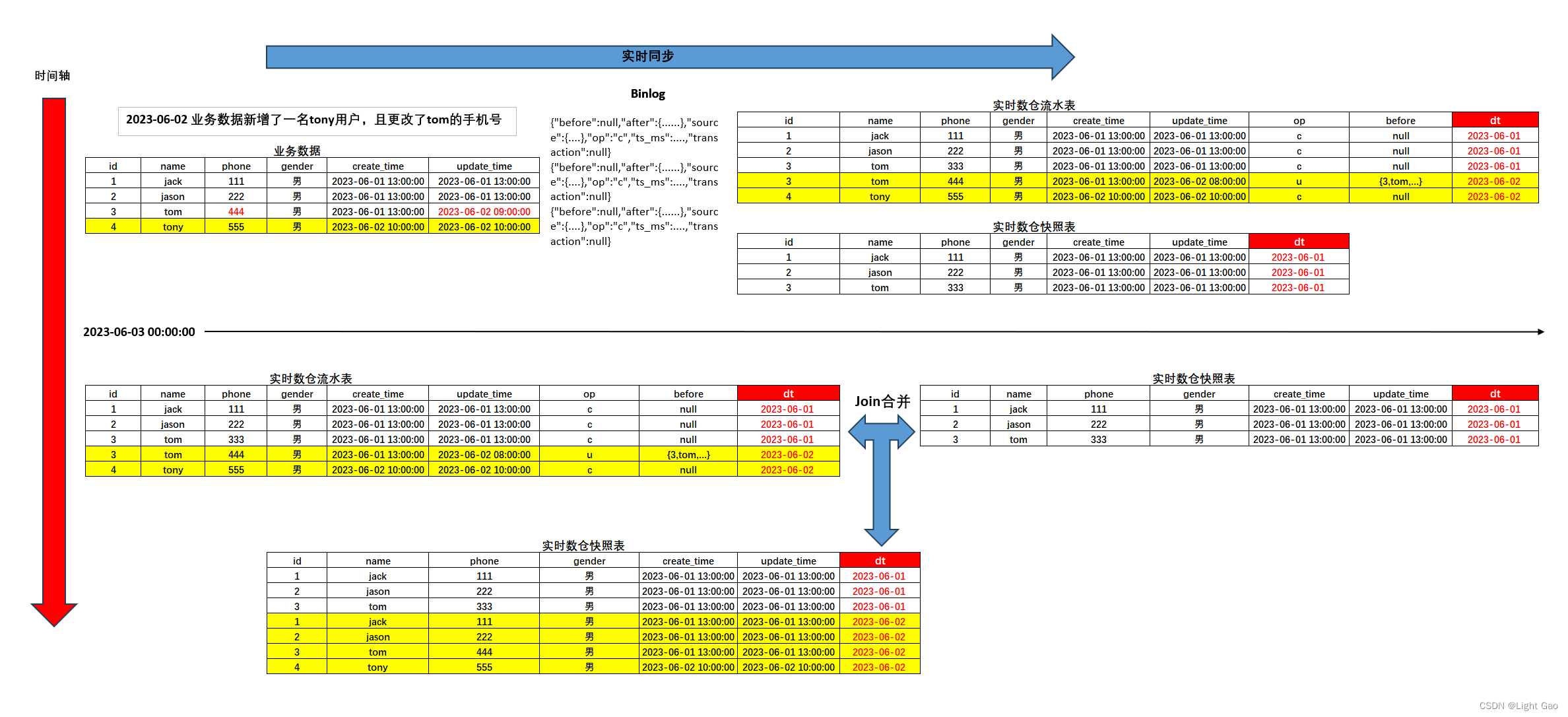
Flink实时数仓同步:快照表实战详解
一、背景
在大数据领域,初始阶段业务数据通常被存储于关系型数据库,如MySQL。然而,为满足日常分析和报表等需求,大数据平台采用多种同步方式,以适应这些业务数据的不同存储需求。这些同步存储方式包括离线仓库和实时仓…
Fink CDC数据同步(二)MySQL数据同步
1 开启binlog日志 2 数据准备
use bigdata;
drop table if exists user;CREATE TABLE user(id INTEGER NOT NULL AUTO_INCREMENT,name VARCHAR(20) NOT NULL DEFAULT ,birth VARCHAR(20) NOT NULL DEFAULT ,gender VARCHAR(10) NOT NULL DEFAULT ,PRIMARY KEY(id)
);
ALTER TA…
flink实战--flink的job_listener使用解析
背景 生产环境可能有如下的需求:当一个flink作业提交完成或者是运行中不定时给我们触发某个接口或发送一个消息,然后我们在做其他的操作,尤其是batch作业。 flink的job_listener就可以满足我们监听flink任务提交和运行状态的需求,具体如何使用本文将全面介绍一下。
注册入…
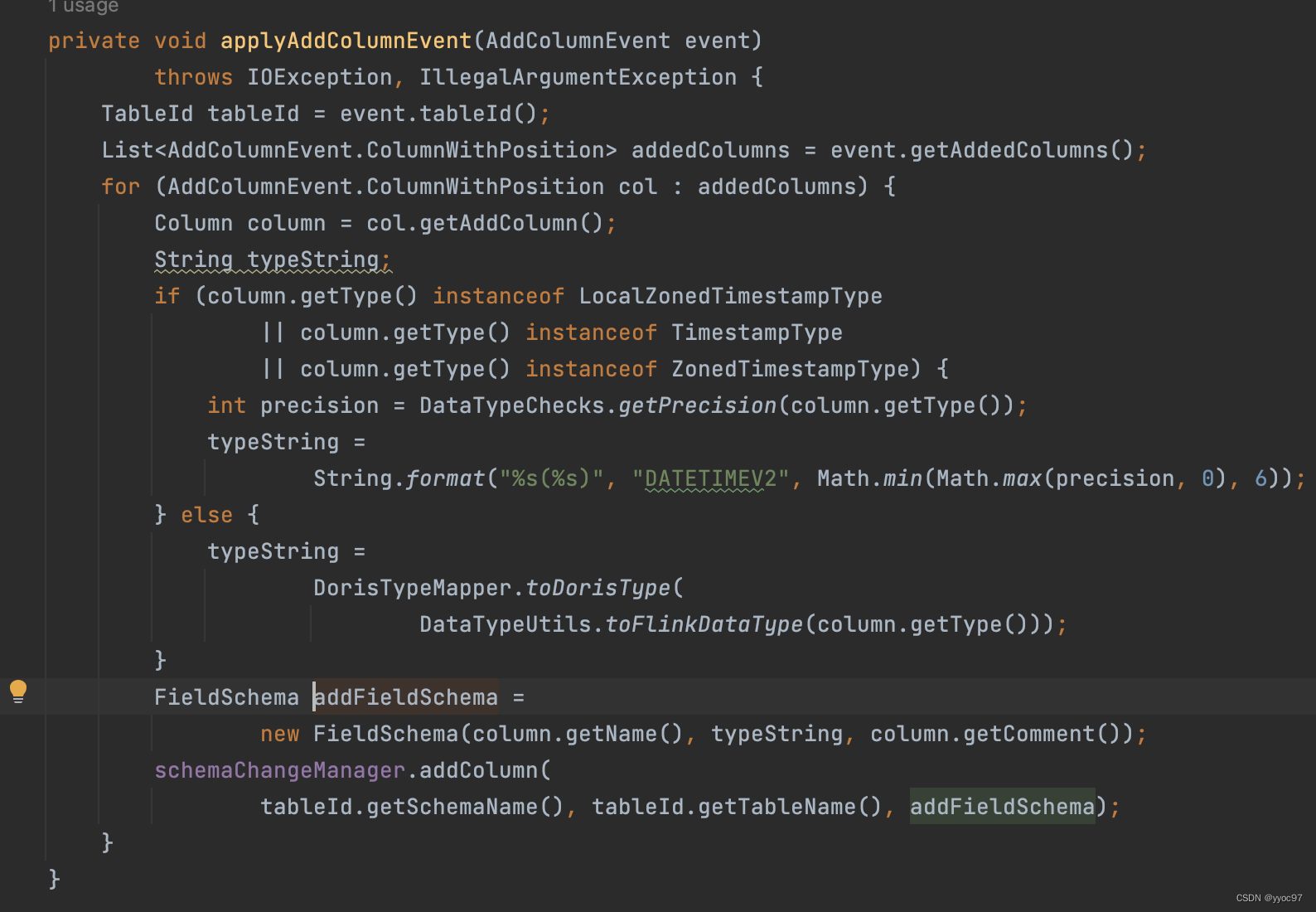
Flink cdc3.0动态变更表结构——源码解析
文章目录 前言源码解析1. 接收schema变更事件2. 发起schema变更请求3. schema变更请求具体处理4. 广播刷新事件并阻塞5. 处理FlushEvent6. 修改sink端schema 结尾 前言
上一篇Flink cdc3.0同步实例 介绍了最新的一些功能和问题,本篇来看下新功能之一的动态变更表结…

Flink 动态表 (Dynamic Table) 解读
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
【Flink】FlinkSQL实现数据从Kafka到MySQL
简介 未来Flink通用化,代码可能就会转换为sql进行执行,大数据开发工程师研发Flink会基于各个公司的大数据平台或者通用的大数据平台,去提交FlinkSQL实现任务,学习Flinksql势在必行。 本博客在sql-client中模拟大数据平台的sql编辑器执行FlinkSQL,使用Flink实现数据从Kafka传…
通过 docker-compose 部署 Flink
概要
通过 docker-compose 以 Session Mode 部署 flink
前置依赖
Docker、docker-composeflink 客户端docker-compose.yml
version: "2.2"
services:jobmanager:image: flink:1.17.2ports:- "8081:8081"command: jobmanagervolumes:- ${PWD}/checkpoin…
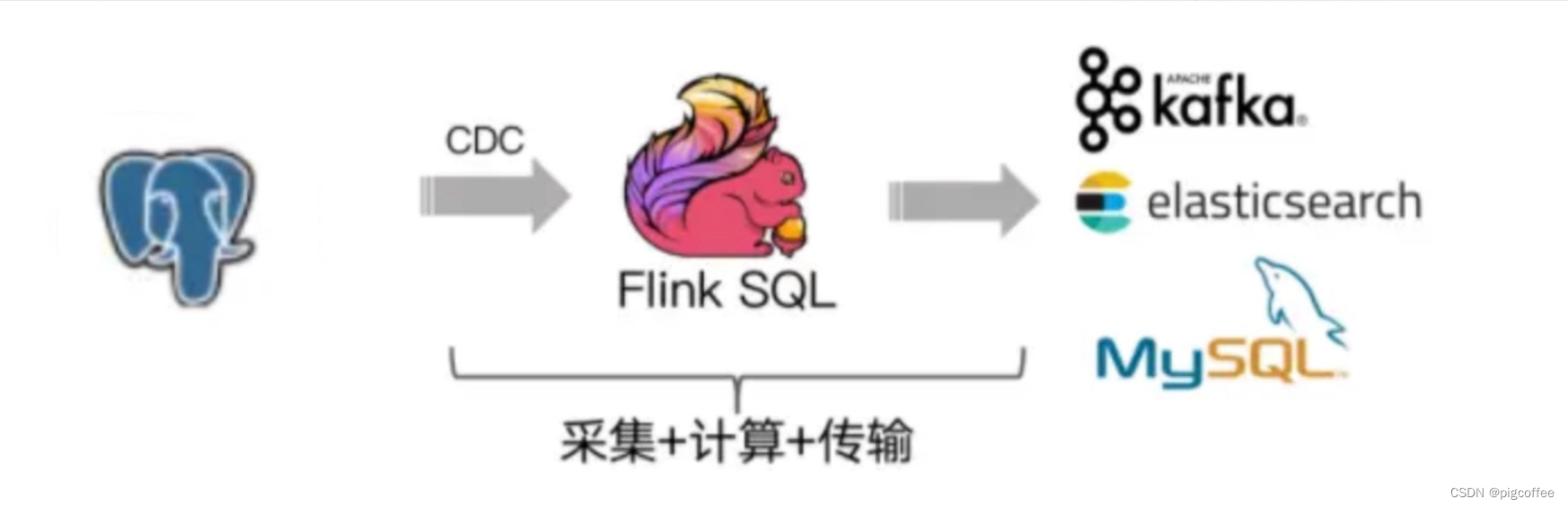
Flink-CDC实时读Postgresql数据
前言 CDC,Change Data Capture,变更数据获取的简称,使用CDC我们可以从数据库中获取已提交的更改并将这些更改发送到下游,供下游使用。这些变更可以包括INSERT,DELETE,UPDATE等。
用户可以在如下的场景使用cdc: 实时数据同步:比如将Postgresql库中的数据同步到我们的数仓中…
【大数据面试题】005 谈一谈 Flink Watermark 水印
一步一个脚印,一天一道面试题。
感觉我现在很难把水印描述的很好,但,完成比完美更重要。后续我再补充。各位如果有什么建议或补充也欢迎留言。
在实时处理任务时,由于网络延迟,人工异常,各种问题…
Flink实战六_直播礼物统计
接上文:Flink实战五_状态机制 1、需求背景
现在网络直播平台非常火爆,在斗鱼这样的网络直播间,经常可以看到这样的总榜排名,体现了主播的人气值。
人气值计算规则:用户发送1条弹幕互动,赠送1个荧光棒免费…
FlinkSql通用调优策略
历史文章迁移,稍后整理 使用DataGenerator 提前进行压测,了解数据的处理瓶颈、性能测试和消费能力 开启minibatch:"table.exec.mini-batch.enabled", "true"
开启LocalGlobal 两阶段聚合:"table.exec.m…
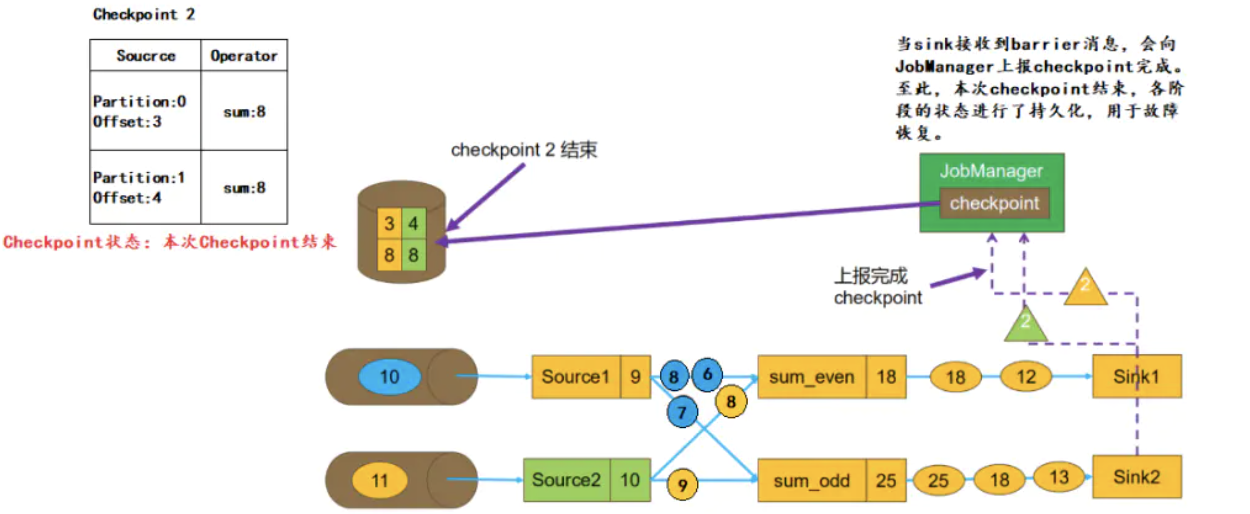
Flink Checkpoint过程
Checkpoint 使用了 Chandy-Lamport 算法
流程
1. 正常流式处理(尚未Checkpoint)
如下图,Topic 有两个分区,并行度也为 2,根据奇偶数
我们假设任务从 Kafka 的某个 Topic 中读取数据,该Topic 有 2 个 Pa…

Flink Format系列(2)-CSV
Flink的csv格式支持读和写csv格式的数据,只需要指定 format csv,下面以kafka为例。
CREATE TABLE user_behavior (user_id BIGINT,item_id BIGINT,category_id BIGINT,behavior STRING,ts TIMESTAMP(3)
) WITH (connector kafka,topic user_behavior…

【大数据】Flink on YARN,如何确定 TaskManager 数
Flink on YARN,如何确定 TaskManager 数 1.问题2.并行度(Parallelism)3.任务槽(Task Slot)4.确定 TaskManager 数 1.问题
在 Flink 1.5 Release Notes 中,有这样一段话,直接上截图。 这说明从 …
可以讲讲Flink的优化吗,具体以项目中某个例子举例一下?
优化的话:可以参考下面几点
GC的配置 (1)调整老年代与新生代的比值 或者 更换垃圾收集器 (2)增加JVM内存数据倾斜 (1)需要重新设计key,以更小粒度的key使得task大小合理化。
&…
【Flink状态管理(二)各状态初始化入口】状态初始化流程详解与源码剖析
文章目录 1. 状态初始化总流程梳理2.创建StreamOperatorStateContext3. StateInitializationContext的接口设计。4. 状态初始化举例:UDF状态初始化 在TaskManager中启动Task线程后,会调用StreamTask.invoke()方法触发当前Task中算子的执行,在…
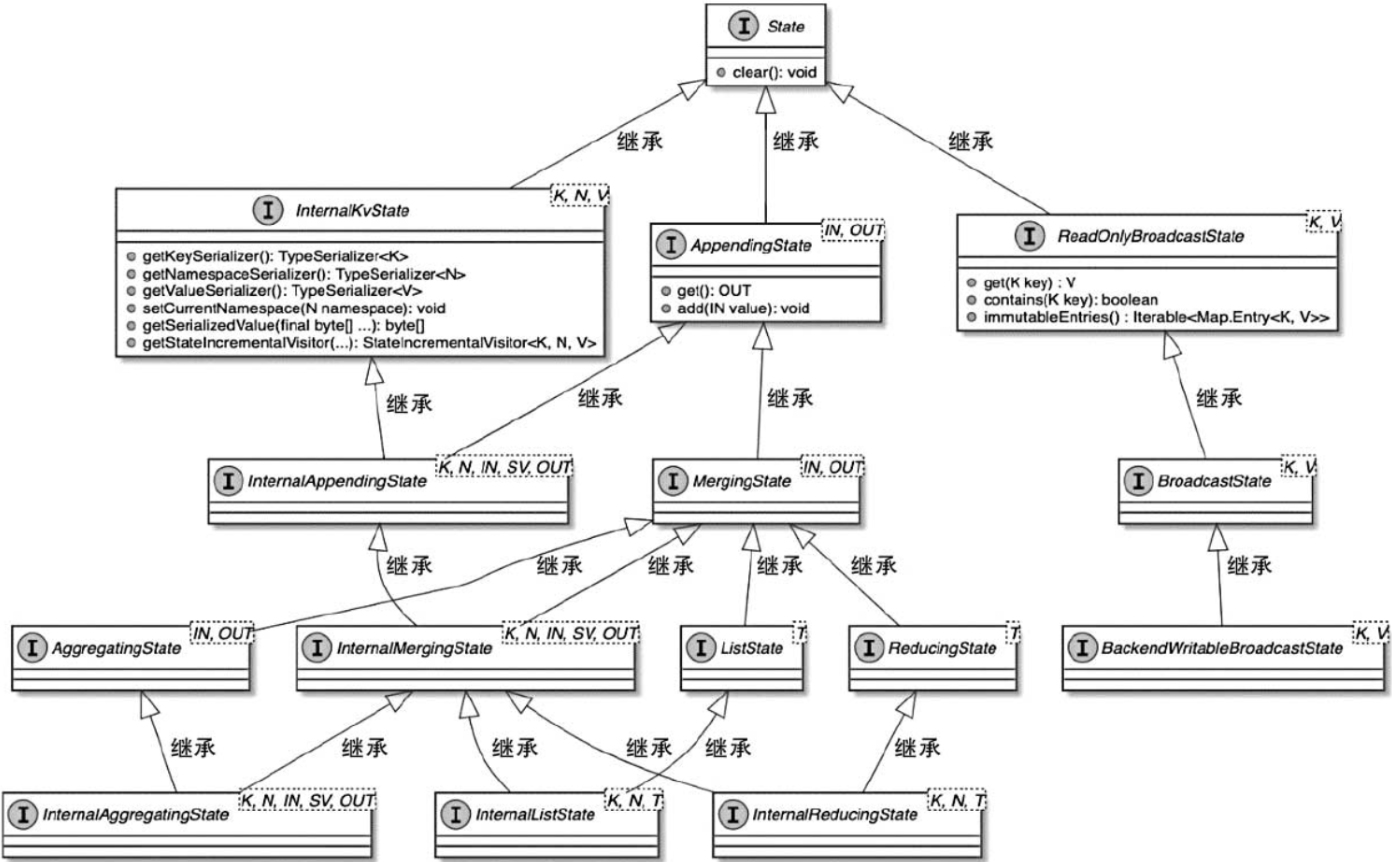
【状态管理一】概览:状态使用、状态分类、状态具体使用
文章目录 一. 状态使用概览二. 状态的数据类型1. 算子层面2. 接口层面2.1. UML与所有状态类型介绍2.2. 内部状态:InternalKvState 将知识与实际的应用场景、设计背景关联起来,这是学以致用、刨根问底知识的一种直接方式。 本文介绍
状态数据管理&#x…
【flink状态管理(四)】MemoryStateBackend的实现
文章目录 1.基于MemoryStateBackend创建KeyedStateBackend1.1. 状态初始化1.2. 创建状态 2. 基于MemoryStateBackend创建OperatorStateBackend3.基于MemoryStateBackend创建CheckpointStorage 在Flink中,默认的StateBackend实现为MemoryStateBackend,本文…
Flink 2.0 状态存算分离改造实践
本文整理自阿里云智能 Flink 存储引擎团队兰兆千在 FFA 2023 核心技术(一)中 的分享,内容关于 Flink 2.0 状态存算分离改造实践的研究,主要分为以下四部分: Flink 大状态管理痛点 阿里云自研状态存储后端 Gemini 的存…

Flink从入门到实践(一):Flink入门、Flink部署
文章目录 系列文章索引一、快速上手1、导包2、求词频demo(1)要读取的数据(2)demo1:批处理(离线处理)(3)demo2 - lambda优化:批处理(离线处理&…
Flink CDC 与 Kafka 集成:Snapshot 还是 Changelog?Upsert Kafka 还是 Kafka?
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,京东购书链接:https://item.jd.com/12677623.html,扫描左侧二维…

Flink生产环境常见问题及解决方法
在Flink生产环境中,可能会遇到一些常见的问题。下面简单的介绍几个常见问题,并且提供一些解决方法,来帮助你更好地应对这些问题。
故障转移和高可用性
Flink提供了故障转移和高可用性机制,但在配置和使用时可能会遇到问题。如果…
Flink从入门到实践(二):Flink DataStream API
文章目录 系列文章索引三、DataStream API1、官网2、获取执行环境(Environment)3、数据接入(Source)(1)总览(2)代码实例(1.18版本已过时的)(3&…

【大数据】Flink on Kubernetes 原理剖析
Flink on Kubernetes 原理剖析 1.基本概念2.架构图3.核心概念4.架构5.JobManager6.TaskManager7.交互8.实践8.1 Session Cluster8.2 Job Cluster 9.问题解答 Kubernetes 是 Google 开源的 容器集群管理系统,其提供应用部署、维护、扩展机制等功能,利用 K…
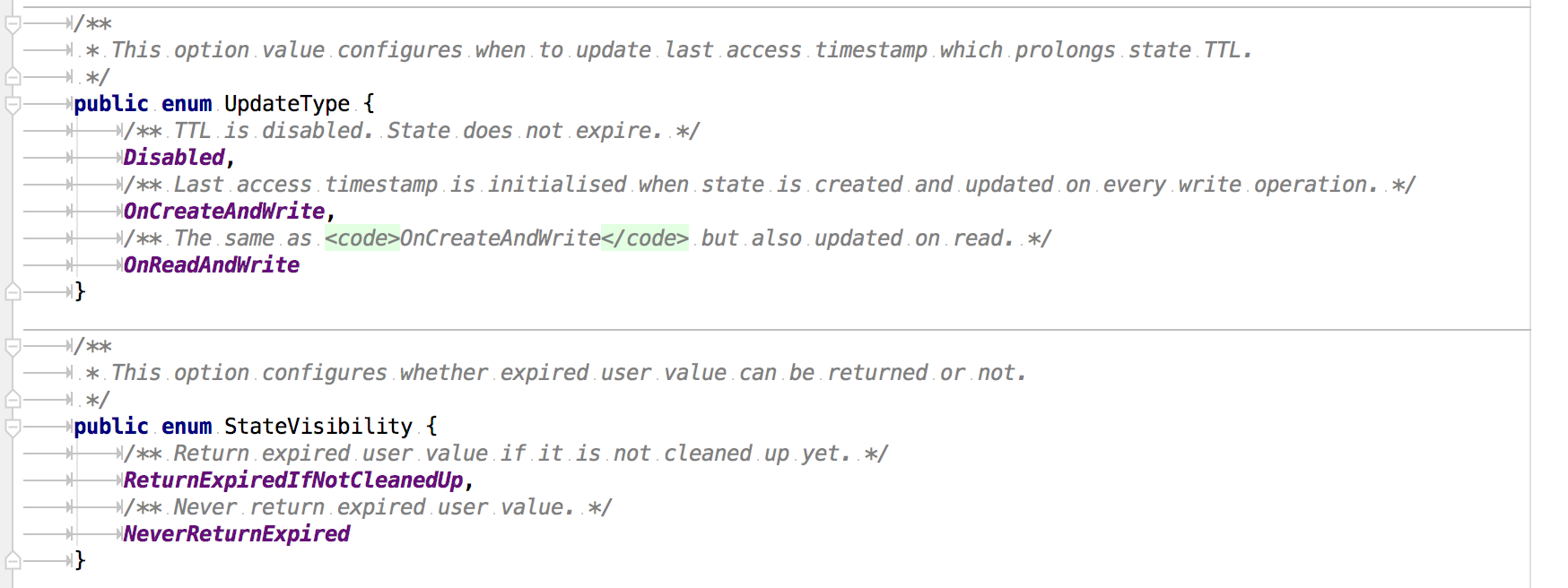
Flink理论—容错之状态
Flink理论—容错之状态
在 Flink 的框架中,进行有状态的计算是 Flink 最重要的特性之一。所谓的状态,其实指的是 Flink 程序的中间计算结果。Flink 支持了不同类型的状态,并且针对状态的持久化还提供了专门的机制和状态管理器。
Flink 使用…

七天爆肝flink笔记
一.flink整体介绍及wordcount案例代码
1.1整体介绍
从上到下包含有界无界流 支持状态 特点 与spark对比 应用场景 架构分层 1.2示例代码
了解了后就整个demo吧
数据源准备 这里直接用的文本文件 gradle中的主要配置
group com.example
version 0.0.1-SNAPSHOTjava {sour…
【天衍系列 04】深入理解Flink的ElasticsearchSink组件:实时数据流如何无缝地流向Elasticsearch
文章目录 01 Elasticsearch Sink 基础概念02 Elasticsearch Sink 工作原理03 Elasticsearch Sink 核心组件04 Elasticsearch Sink 配置参数05 Elasticsearch Sink 依赖管理06 Elasticsearch Sink 初阶实战07 Elasticsearch Sink 进阶实战7.1 包结构 & 项目配置项目配置appl…
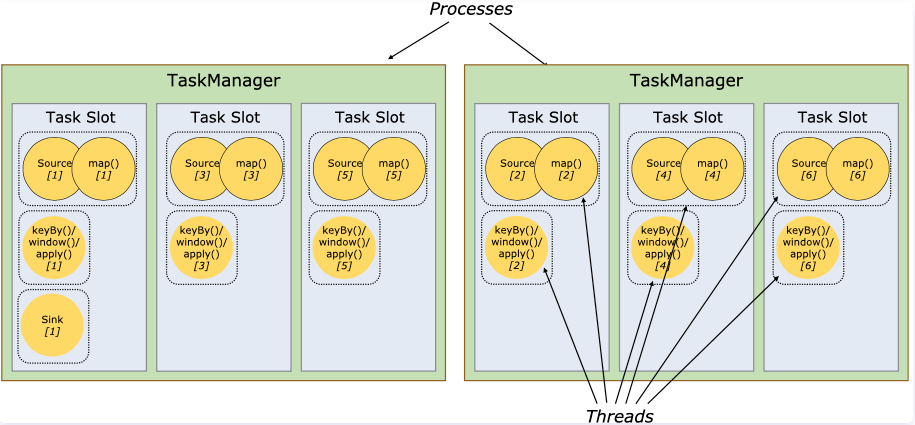
Flink理论—Flink架构设计
Flink架构设计
Flink 是一个分布式系统,需要有效分配和管理计算资源才能执行流应用程序。它集成了所有常见的集群资源管理器,例如Hadoop YARN,但也可以设置作为独立集群甚至库运行,例如Spark 的 Standalone Mode
本节概述了 Flink 架构&…
[ 2024春节 Flink打卡 ] -- 理论基础
2024,游子未归乡。工作需要,flink coding。觉知此事要躬行,未休,特记 之后,文档格式整理 文尾有word链接 相关代码陆续上传 Apache Flink 是一个在有界数据流和无界数据流上进行有状态计算分布式处理引擎和框架。Flink…
![[Flink02] Flink架构和原理](https://img-blog.csdnimg.cn/img_convert/a5c0c7ac41e553eb0021ff93cc2e99b2.png)
[Flink02] Flink架构和原理
这是继第一节之后的Flink入门系列的第二篇,本篇主要内容是是:了解Flink运行模式、Flink调度原理、Flink分区、Flink安装。
1、运行模式
Flink有多种运行模式,可以运行在一台机器上,称为本地(单机)模式&am…
![[Flink04] Flink部署实践](https://img-blog.csdnimg.cn/direct/9c94f985a0cd4a7c9b9ea4f89dd047cc.png)
[Flink04] Flink部署实践
Flink部署支持三种模式:本地部署、Standalone部署、Flink on Yarn部署。 独立(Standalone)模式由Flink自身提供资源,无需其他框架,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但Flink 是大…
FlinkSql一个简单的测试程序
FlinkSql一个简单的测试程序 以下是一个简单的 Flink SQL 示例,展示了如何使用 Flink Table API 和 Flink SQL 进行基本的数据流处理。 定义数据实体 CC : - CC 类表示数据流中的元素,包含两个字段: character (字符&a…
【天衍系列 05】Flink集成KafkaSink组件:实现流式数据的可靠传输 高效协同
文章目录 01 KafkaSink 版本&导言02 KafkaSink 基本概念03 KafkaSink 工作原理1.初始化连接2.定义序列化模式3.创建KafkaSink算子4.创建数据源5.将数据流添加到KafkaSink6.内部工作机制 04 KafkaSink参数配置05 KafkaSink 应用依赖06 KafkaSink 快速入门6.1 包结构6.2 项目…
【Flink】ClassNotFoundException: org.apache.hadoop.conf.Configuration
问题背景
在Flink的sql-client客户端中执行连接hive的sql代码时出现如下错误,版本Flink1.13.6 Flink SQL> create catalog test with( > type=hive, > default-database=default, > hive-conf-dir=/opt/hive/conf);[ERROR] Could not execute SQL statement. R…
【天衍系列 01】深入理解Flink的 FileSource 组件:实现大规模数据文件处理
文章目录 01 基本概念02 工作原理03 数据流实现04 项目实战4.1 项目结构4.2 maven依赖4.3 StreamFormat读取文件数据4.4 BulkFormat读取文件数据4.5 使用小结 05 数据源比较06 总结 01 基本概念
Apache Flink 是一个流式处理框架,被广泛应用于大数据领域的实时数据…
Flink join详解
Flink SQL支持对动态表进行复杂而灵活的连接操作。 为了处理不同的场景,需要多种查询语义,因此有几种不同类型的 Join。
默认情况下,joins 的顺序是没有优化的。表的 join 顺序是在 FROM 从句指定的。可以通过把更新频率最低的表放在第一个、…
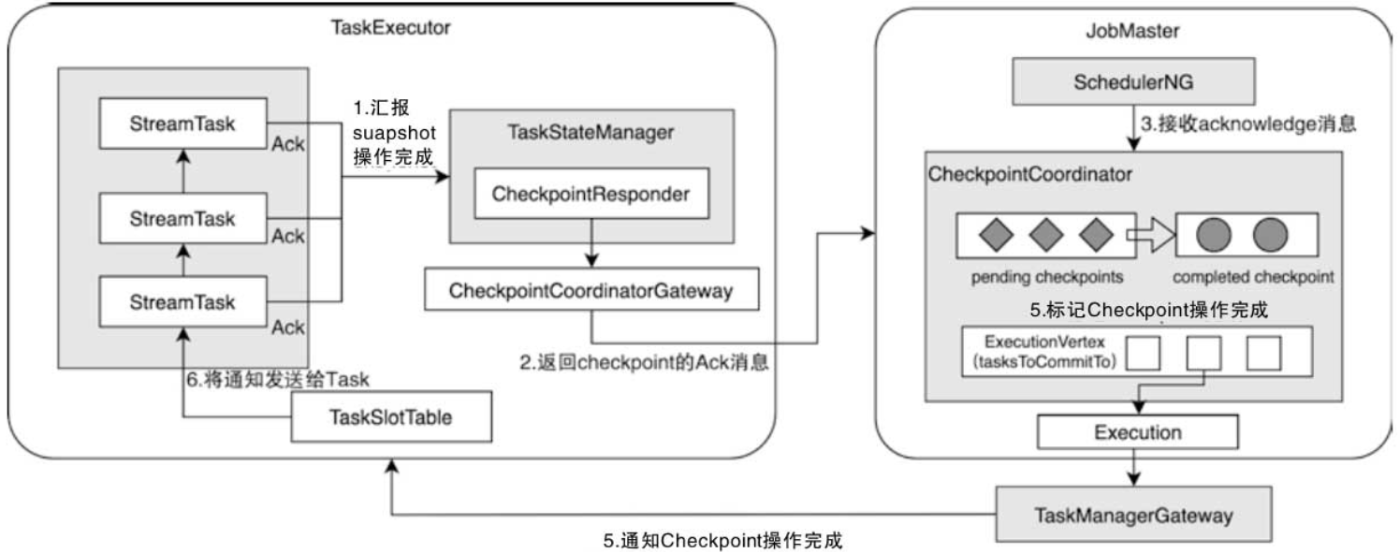
【Flink状态管理(八)】Checkpoint:CheckpointBarrier对齐后Checkpoint的完成、通知与对学习状态管理源码的思考
文章目录 一. 调用StreamTask执行Checkpoint操作1. 执行Checkpoint总体代码流程1.1. StreamTask.checkpointState()1.2. executeCheckpointing1.3. 将算子中的状态快照操作封装在OperatorSnapshotFutures中1.4. 算子状态进行快照1.5. 状态数据快照持久化 二. CheckpointCoordin…
【Flink精讲】Flink内核源码分析:命令执行入口
官方推荐per-job模式,一个job一个集群,提交时yarn才分配集群资源;
主要的进程:JobManager、TaskManager、Client
提交命令:bin/flink run -t yarn-per-job /opt/module/flink-1.12.0/examples/streaming/SocketWind…
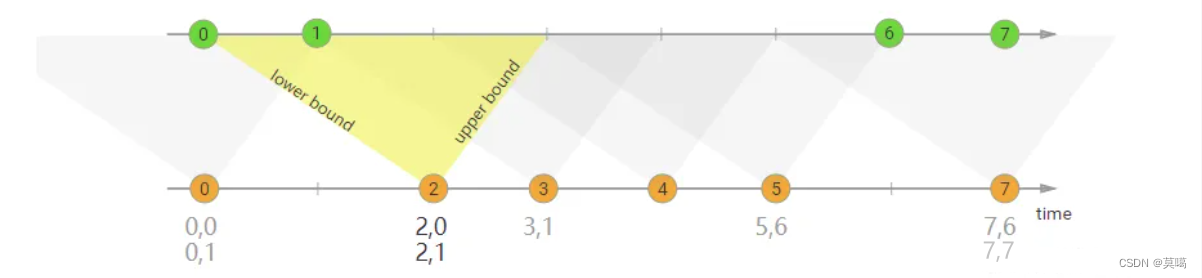
Flink双流(join)
一、介绍
Join大体分类只有两种:Window Join和Interval Join Window Join有可以根据Window的类型细分出3种:Tumbling(滚动) Window Join、Sliding(滑动) Window Join、Session(会话) Widnow Join。 🌸Window 类型的join都是利用window的机制…
![[Flink01] 了解Flink](https://img-blog.csdnimg.cn/img_convert/b0b9d2f91f96416892929e5c57157887.png)
[Flink01] 了解Flink
Flink入门系列文章主要是为了给想学习Flink的你建立一个大体上的框架,助力快速上手Flink。学习Flink最有效的方式是先入门了解框架和概念,然后边写代码边实践,然后再把官网看一遍。
Flink入门分为四篇,第一篇是《了解Flink》&…

【大数据】Flink 之部署篇
Flink 之部署篇 1.概述和参考架构2.可重复的资源清理3.部署模式3.1 Application 模式3.2 Per-Job 模式(已废弃)3.3 Session 模式 Flink 是一个多用途框架,支持多种不同的混合部署方案。下面,我们将简要介绍 Flink 集群的构建模块、…
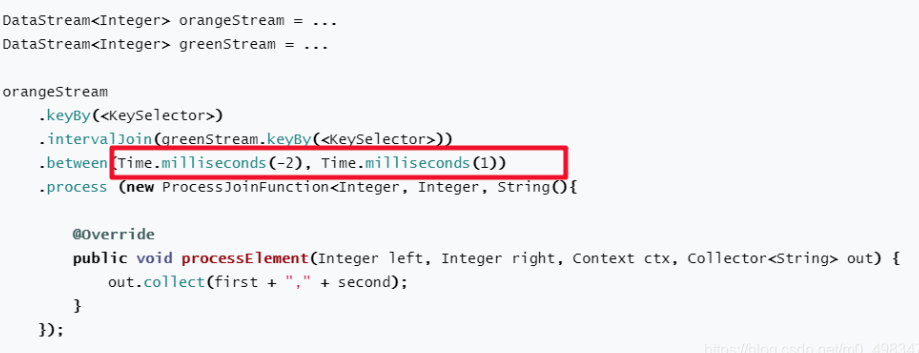
Flink中的双流Join
1. Flink中双流Join介绍
Flink版本Join支持类型Join API1.4innerTable/SQL1.5inner,left,right,fullTable/SQL1.6inner,left,right,fullTable/SQL/DataStream
Join大体分为两种:Window Join 和 Interval Join 两种。
Window Join又可以根据Window的类型细分为3种…
Flink 侧输出流(SideOutput)
🌸在平时大部分的 DataStream API 的算子的输出是单一输出,也就是某一种或者说某一类数据流,流向相同的地方。
🌸在处理不同的流中,除了 split 算子,可以将一条流分成多条流,这些流的数据类型也…
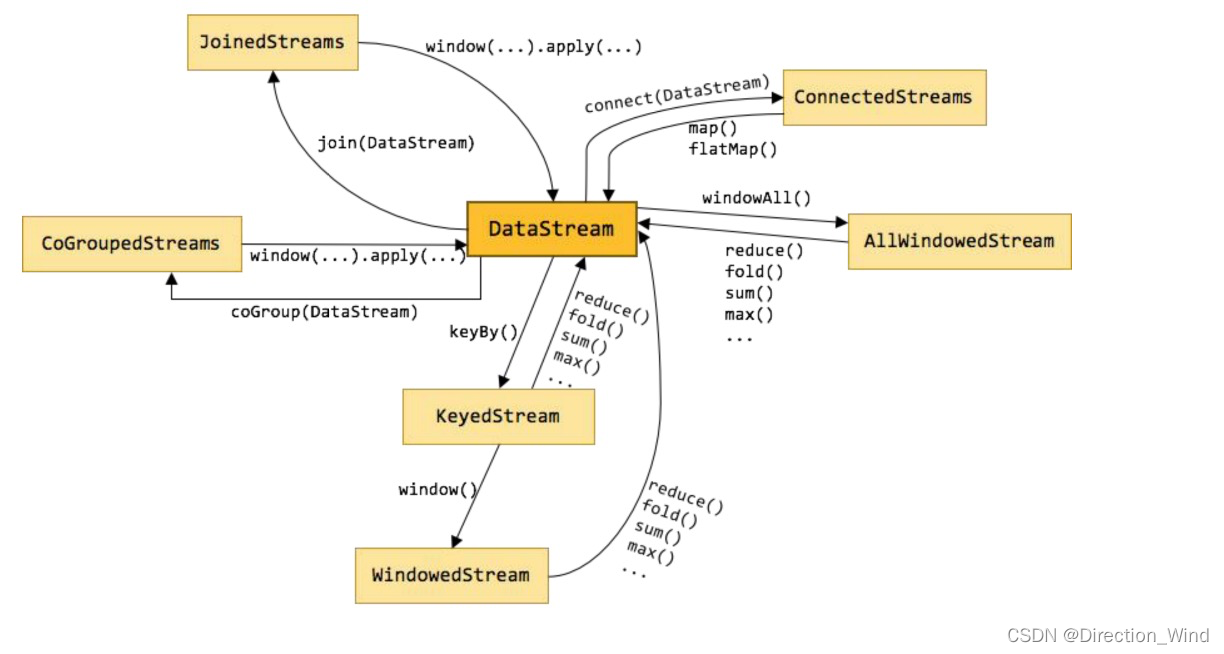
Flink/flinksql 语法 窗口与join 一文全 相关概念api汇总总结,底层process算子总结,与数据延迟处理,超时场景解决方案
Flink 窗口概念与join汇总总结 1 SQL语法中窗口语法相关(仅仅是flinksql中 窗口的语法)1.1 sql窗口1.2 window topN 2 java/SQL join语法与介绍2.1 有界join2.1.1 Window Join2.1.2 Interval Join2.1.3 Temporary Join2.1.4 LoopUp Join2.2 无界join2.2.…
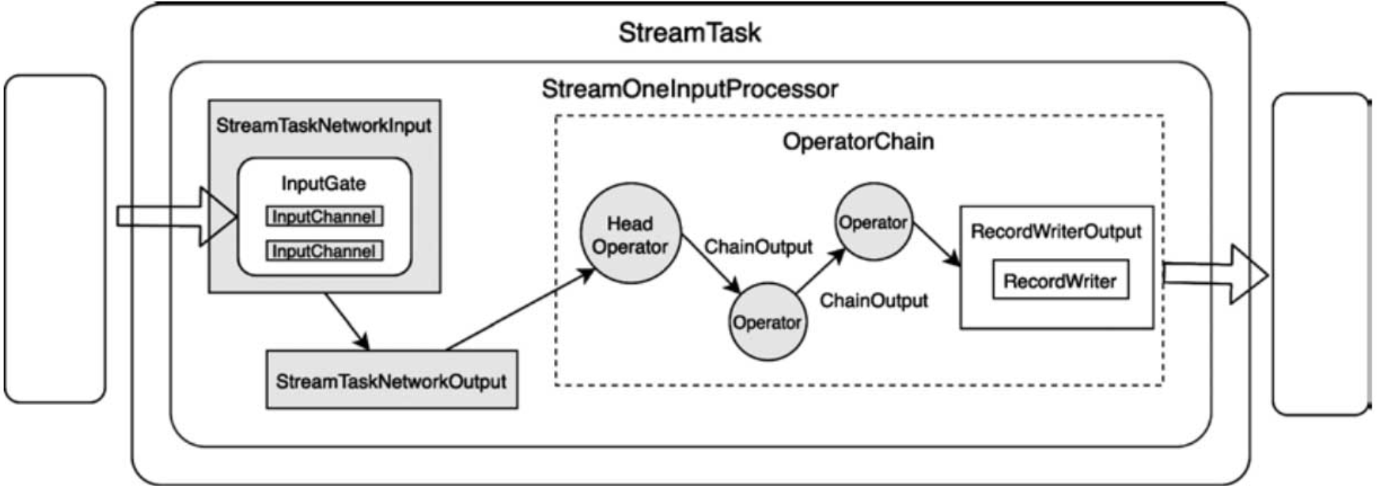
【Flink数据传输(一)】NetworkStack架构概述:实现tm之间的数据交换
文章目录 1. NetworkStack整体架构2. StreamTask内数据流转过程 NetworkStack提供了高效的网络I/O和反压控制 除了各个组件之间进行RPC通信之外,在Flink集群中TaskManager和TaskManager节点之间也会发生数据交换,尤其当用户提交的作业涉及Task实例运行在…

【大数据】Flink 内存管理(一):设置 Flink 进程内存
Flink 内存管理(一):设置 Flink 进程内存 1.配置 Total Memory2.JVM 参数3.根据比例限制的组件(Capped Fractionated Components) Apache Flink 通过严格控制各种组件的内存使用,在 JVM 上提供高效的工作负…
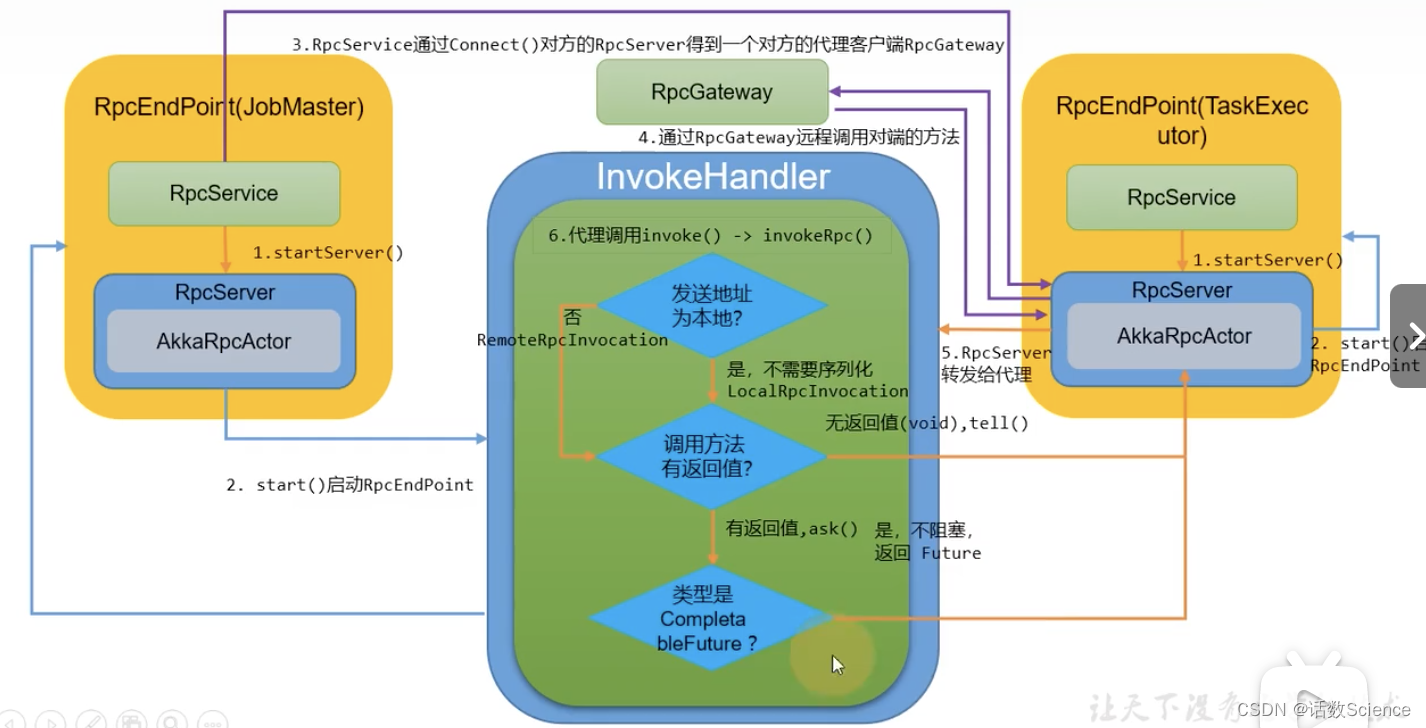
【Flink精讲】Flink组件通信
主要指三个进程中的通讯
CliFrontendYarnJobClusterEntrypointTaskExecutorRunner
Flink内部节点之间的通讯使用Akka,比如JobManager和TaskManager之间。而operator之间的数据传输是利用Netty。
RPC是统称,Akka,Netty是实现
Akka与Ac…
CDC 整合方案:MySQL > Flink CDC + Schema Registry + Avro > Kafka > Hudi
本文是《CDC 整合方案:MySQL > Flink CDC > Kafka > Hudi》的增强版,在打通从源端数据库到 Hudi 表的完整链路的前提下,还额外做了如下两项工作: 引入 Confluent Schema Registry,有效控制和管理上下游的 Schema 变更 使用 Avro 格式替换 Json,搭配 Schema Registry,…
Flink 在蚂蚁实时特征平台的深度应用
摘要:本文整理自蚂蚁集团高级技术专家赵亮星云,在 Flink Forward Asia 2023 AI 特征工程专场的分享。本篇内容主要分为以下四部分: 蚂蚁特征平台特征实时计算特征 Serving特征仿真回溯 一、蚂蚁特征平台 蚂蚁特征平台是一个多计算模式融合的高…
Flink-1.18.1环境搭建
下载
下载flink安装包
Index of /dist/flink/flink-1.18.1
下载flink-cdc安装包
Release Release 3.0.0 ververica/flink-cdc-connectors GitHub
安装
添加环境变量
vi ~/.bash_profile
export FLINK_HOME=/home/postgres/flink/flink-1.18.1
export PATH=$PATH:$FL…
seatunnel数据集成(一)简介与安装
seatunnel数据集成(一)简介与安装seatunnel数据集成(二)数据同步seatunnel数据集成(三)多表同步seatunnel数据集成(四)连接器使用 1、背景
About Seatunnel | Apache SeaTunnel
…

FlinkCDC详解
1、FlinkCDC是什么
1.1 CDC是什么
CDC是Chanage Data Capture(数据变更捕获)的简称。其核心原理就是监测并捕获数据库的变动(例如增删改),将这些变更按照发生顺序捕获,将捕获到的数据,写入数据…
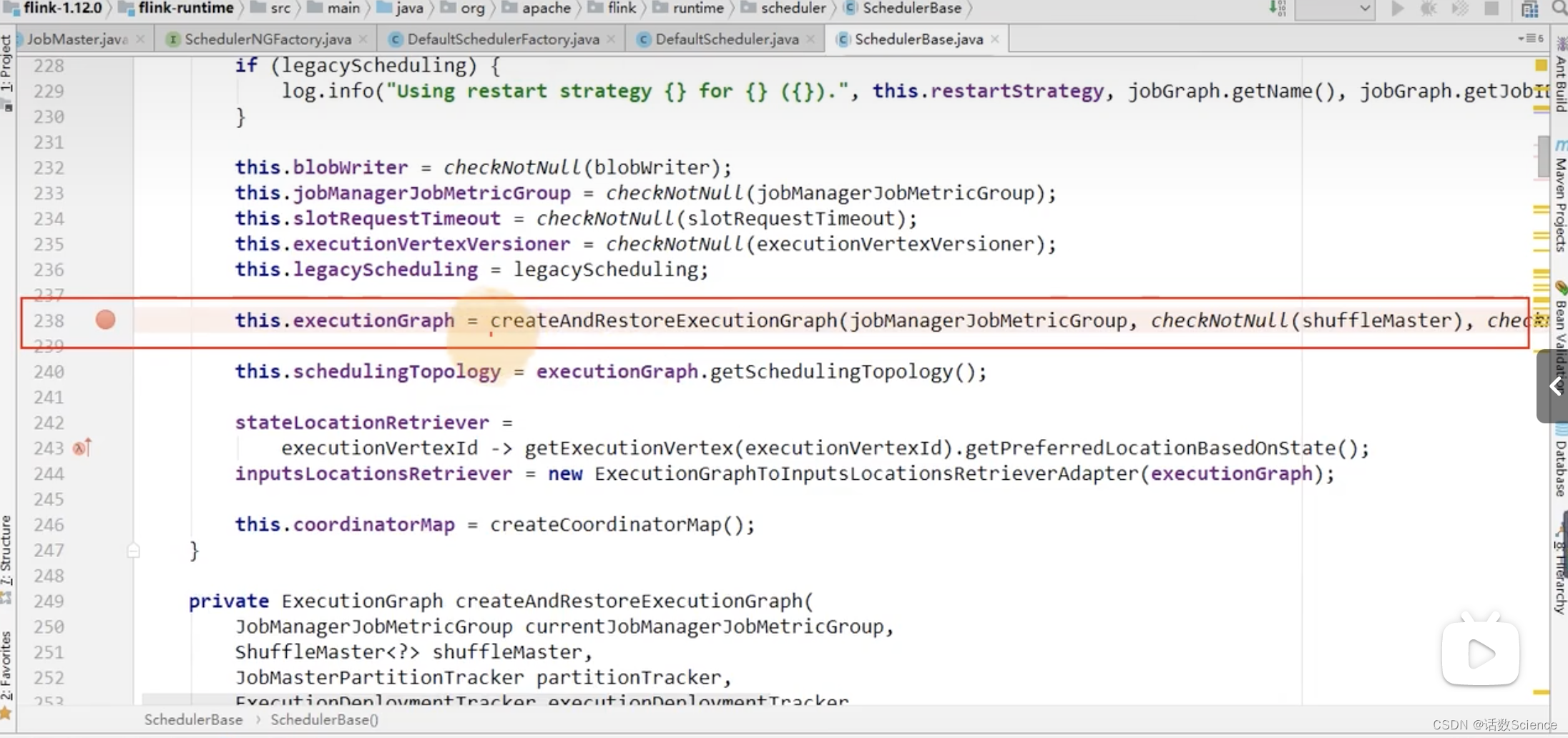
【Flink精讲】Flink任务调度机制
Graph 的概念
Flink 中的执行图可以分成四层: StreamGraph -> JobGraph -> ExecutionGraph -> 物理执 行图。
StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。JobGraph: StreamGraph …
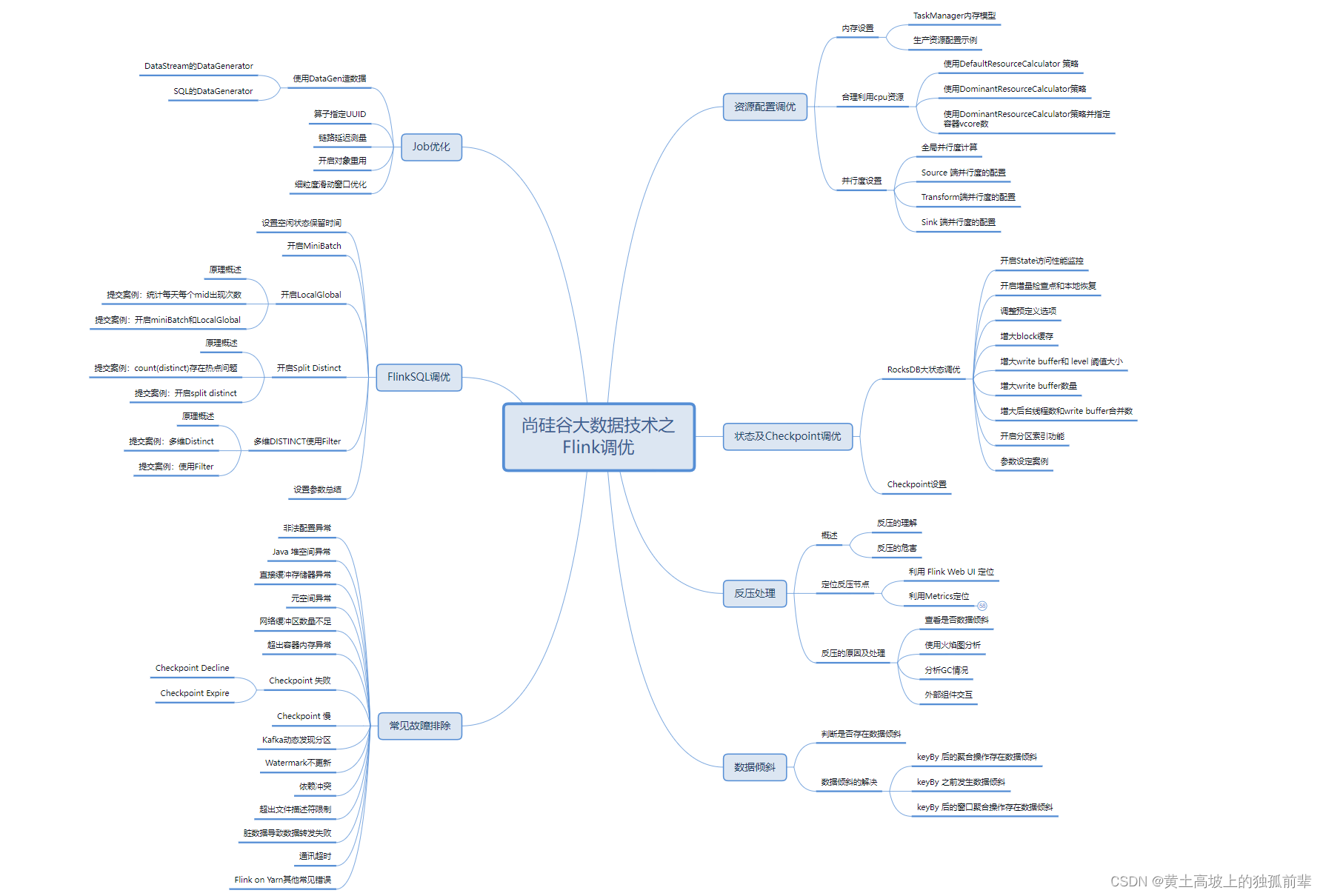
大数据之Flink优化
文章目录 导言:Flink调优概览第1章 资源配置调优1.1 内存设置1.1.1 TaskManager 内存模型1.1.2 生产资源配置示例 1.2 合理利用 cpu 资源1.2.1 使用 DefaultResourceCalculator 策略1.2.2 使用 DominantResourceCalculator 策略1.2.3 使用DominantResourceCalculato…
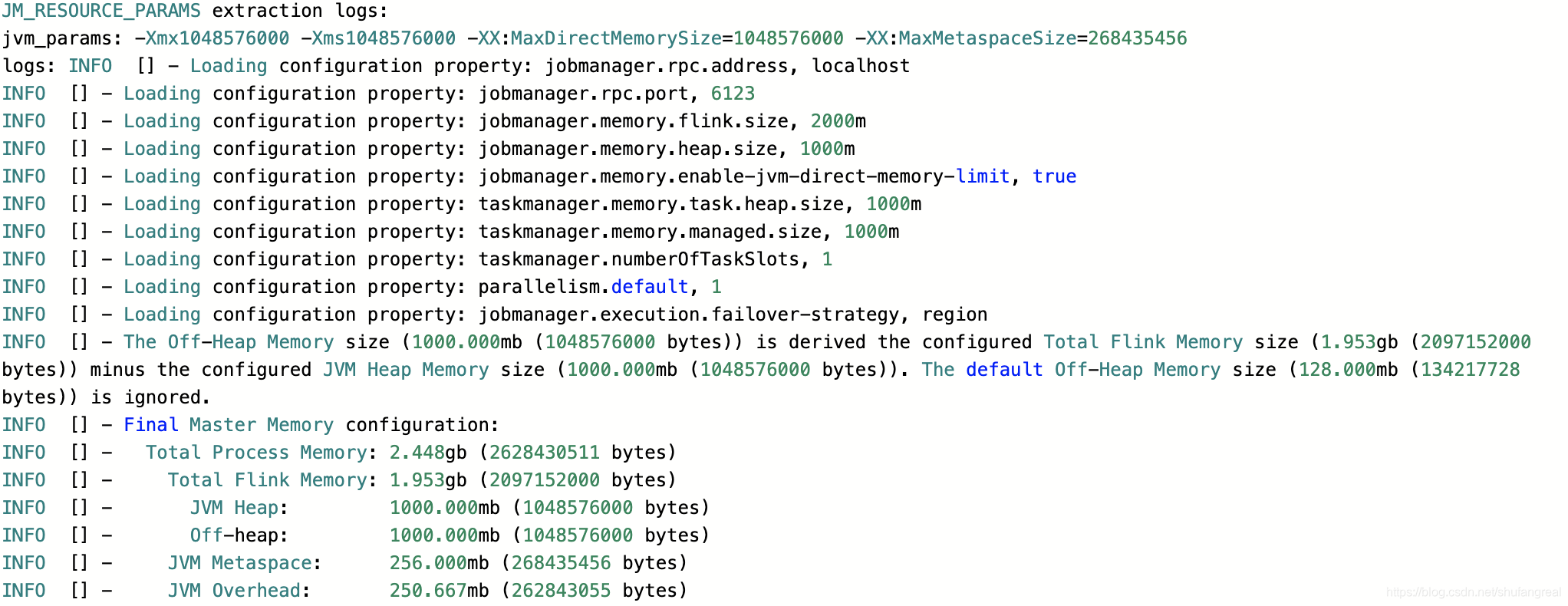
【大数据】Flink 内存管理(二):JobManager 内存分配(含实际计算案例)
Flink 内存管理(二):JobManager 内存分配 1.分配 Total Process Size2.分配 Total Flink Size3.单独分配 Heap Size4.分配 Total Process Size 和 Heap Size5.分配 Total Flink Size 和 Heap Size JobManager 是 Flink 集群的控制元素。它由三…
Flink:流上的“确定性”(Determinism)
1. 什么是“确定性” 先明确一下什么叫“确定性”:对于一个“操作”来说,如果每次给它的“输入”不变,操作输出的“结果”也不变,那么这个操作就是“确定性“的。通常,我们认为批处理的操作都是确定的,比如…

【大数据】Flink 内存管理(三):TaskManager 内存分配(理论篇)
《Flink 内存管理》系列(已完结),共包含以下 4 篇文章:
Flink 内存管理(一):设置 Flink 进程内存Flink 内存管理(二):JobManager 内存分配(含实际…
05 Flink 的 WordCount
前言
本文对应于 spark 系列的 Spark 的 WordCount
这里主要是 从宏观上面来看一下 flink 这边的几个角色, 以及其调度的整个流程
一个宏观 大局上的任务的处理, 执行
基于 一个本地的 flink 集群 测试用例
/*** com.hx.test.Test01WordCount** author Jerry.X.He* ver…

flink源码分析 - 获取调用位置信息
flink版本: flink-1.11.2
调用位置: org.apache.flink.streaming.api.datastream.DataStream#flatMap(org.apache.flink.api.common.functions.FlatMapFunction<T,R>)
代码核心位置: org.apache.flink.api.java.Utils#getCallLocationName() flink算子flatmap中调用了一…

电商风控系统(flink+groovy+flume+kafka+redis+clickhouse+mysql)
一.项目概览
电商的防止薅羊毛的风控系统
需要使用 groovy 进行风控规则引擎的编写 然后其它技术进行各种数据的 存储及处理 薅羊毛大致流程 如果单纯使用 if else在业务代码中进行风控规则的编写 那么 维护起来会比较麻烦 并且跟业务系统强绑定不合适 所以一般独立成一个单…
Flink word count入门
一下是一个简单的flink word count任务demo代码
pom配置文件
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:sche…
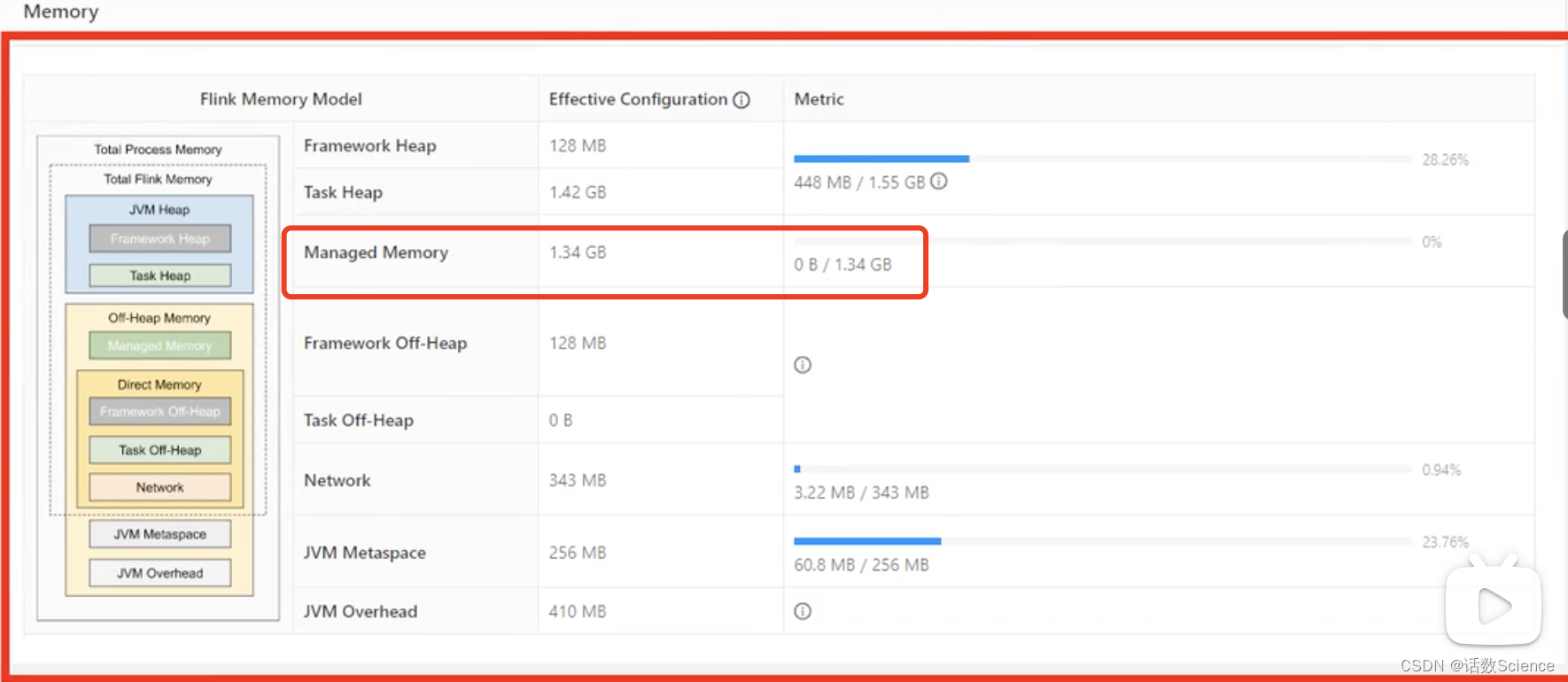
【Flink精讲】Flink性能调优:内存调优
内存调优
内存模型
JVM 特定内存
JVM 本身使用的内存,包含 JVM 的 metaspace 和 over-head 1) JVM metaspace: JVM 元空间 taskmanager.memory.jvm-metaspace.size,默认 256mb 2) JVM over-head 执行开销࿱…

【大数据】Flink 内存管理(四):TaskManager 内存分配(实战篇)
《Flink 内存管理》系列(已完结),共包含以下 4 篇文章:
Flink 内存管理(一):设置 Flink 进程内存Flink 内存管理(二):JobManager 内存分配(含实际…

Flink代码单词统计 ---批处理
flatMap:一对多转换操作,输入句子,输出分词后的每个词groupBy:按Key分组,0代表选择第1列作为Keysum:求和,1代表按照第2列进行累加print:打印最终结果
1.WordCount代码编写
需求&am…
【大数据】Flink SQL 语法篇(六):Temporal Join
Flink SQL 语法篇(六):Temporal Join 1.Versioned Table 的两种定义方式1.1 PRIMARY KEY 定义方式1.2 Deduplicate 定义方式 2.应用案例2.1 案例一(事件时间)2.2 案例二(处理时间) Temporal Joi…
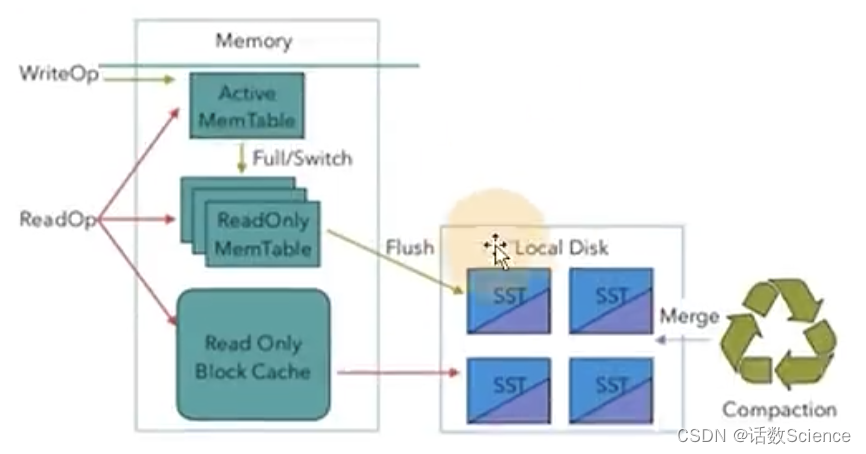
【Flink精讲】Flink状态及Checkpoint调优
RocksDB大状态调优 RocksDB 是基于 LSM Tree 实现的(类似 HBase) ,写数据都是先缓存到内存中, 所以 RocksDB 的写请求效率比较高。 RocksDB 使用内存结合磁盘的方式来存储数据,每 次获取数据时,先从内存中 …
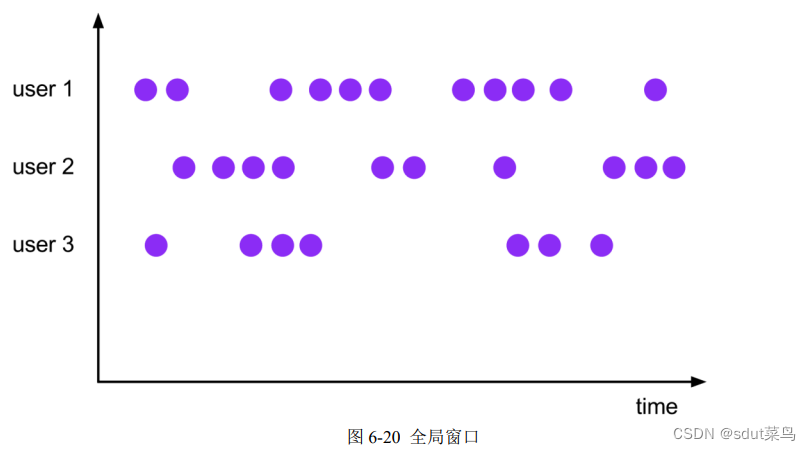
【Flink】Flink 中的时间和窗口之窗口(Window)
1. 窗口的概念
Flink是一种流式计算引擎,主要是来处理无界数据流,数据流的数据是一直都有的,等待流结束输入数据获取所有的流数据在做聚合计算是不可能的。为了更方便高效的处理无界流,一种方式就是把无限的流数据切割成有限的数…
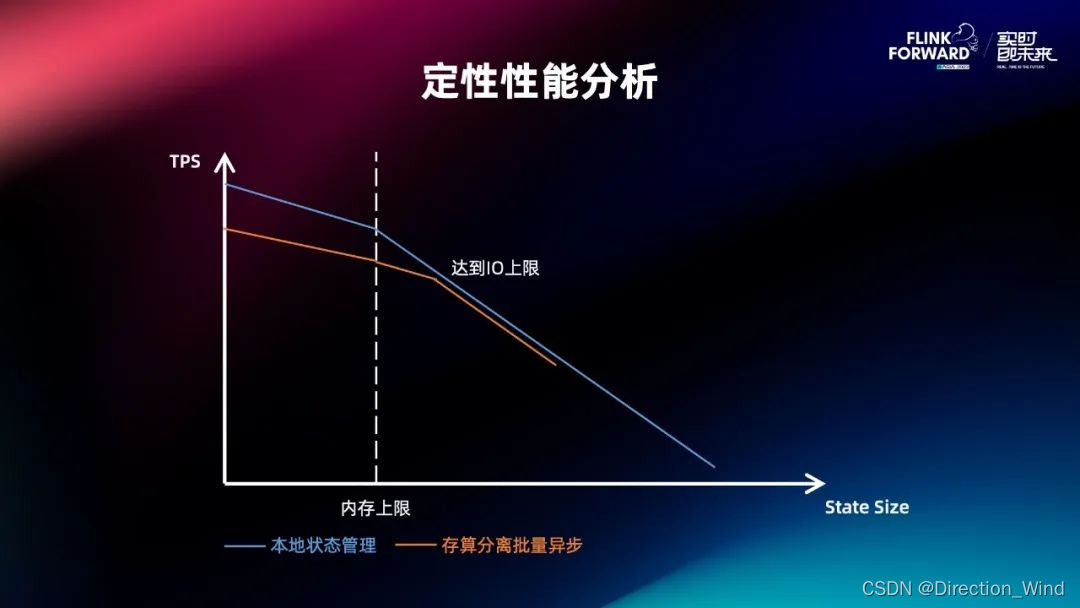
Flink 2.0 状态管理存算分离架构演进与分离改造实践
Flink 2.0 状态管理存算分离架构演进与分离改造实践 1 引言2 为什么状态对 Flink 如此重要2.1 状态的角色2.2 Flink状态管理的需求以及现存的问题 3 状态存储提升 —— 社区和商业版状态存储3.1 分布式快照架构升级3.2 面向云原生:高效弹性扩缩容3.3 Gemini…
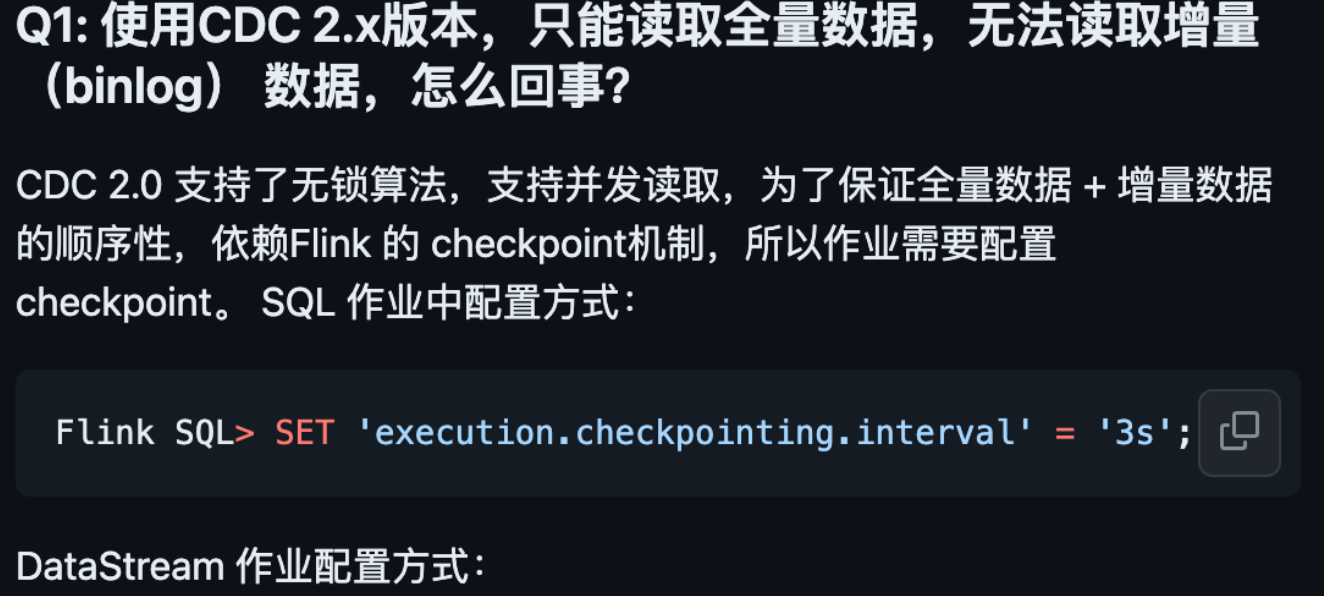
【Flink CDC(一)】实现mysql整表与增量读取
文章目录 一. 运行前准备1. 依赖1.1. Maven dependency1.2. SQL Client JAR(推荐) 2. 配置 MySQL 服务器(必须) 二. 功能说明1. 启动模式2. 全量阶段支持 checkpoint3. 关于无主键表Exactly-Once 处理 三. 实战1. 实现mysql整表与…
弱结构化日志 Flink SQL 怎么写?SLS SPL 来帮忙
作者:潘伟龙(豁朗)
背景
日志服务 SLS 是云原生观测与分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务,基于日志服务的便捷的数据接入能力,可以将系统日志、业务日志等接入 …

Flink CDC 提取记录变更时间作为事件时间和 Hudi 表的 precombine.field 以及1970-01-01 取值问题
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
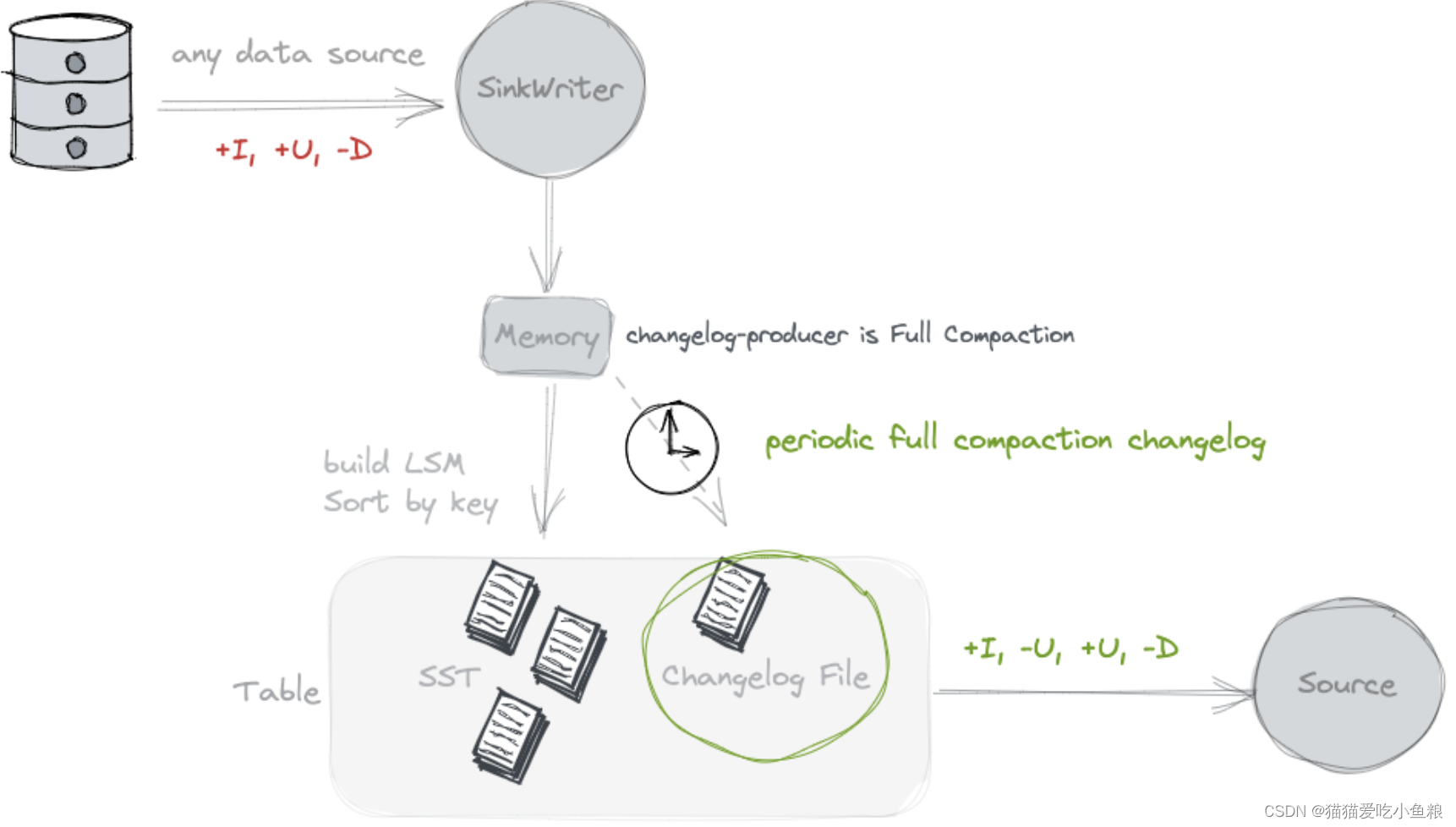
Apache Paimon 主键表解析
Primary Key Table-主键表
1.概述
主键表是创建表时的默认表类型,用户可以插入、更新或删除表中的记录;
主键由一组列组成,这些列包含每条记录的唯一值;
Paimon通过对每个桶中的主键排序来强制数据有序,允许用户在…
【大数据】Flink SQL 语法篇(七):Lookup Join、Array Expansion、Table Function
Flink SQL 语法篇(七):Lookup Join、Array Expansion、Table Function 1.Lookup Join(维表 Join)2.Array Expansion(数组列转行)3.Table Function(自定义列转行) 1.Looku…
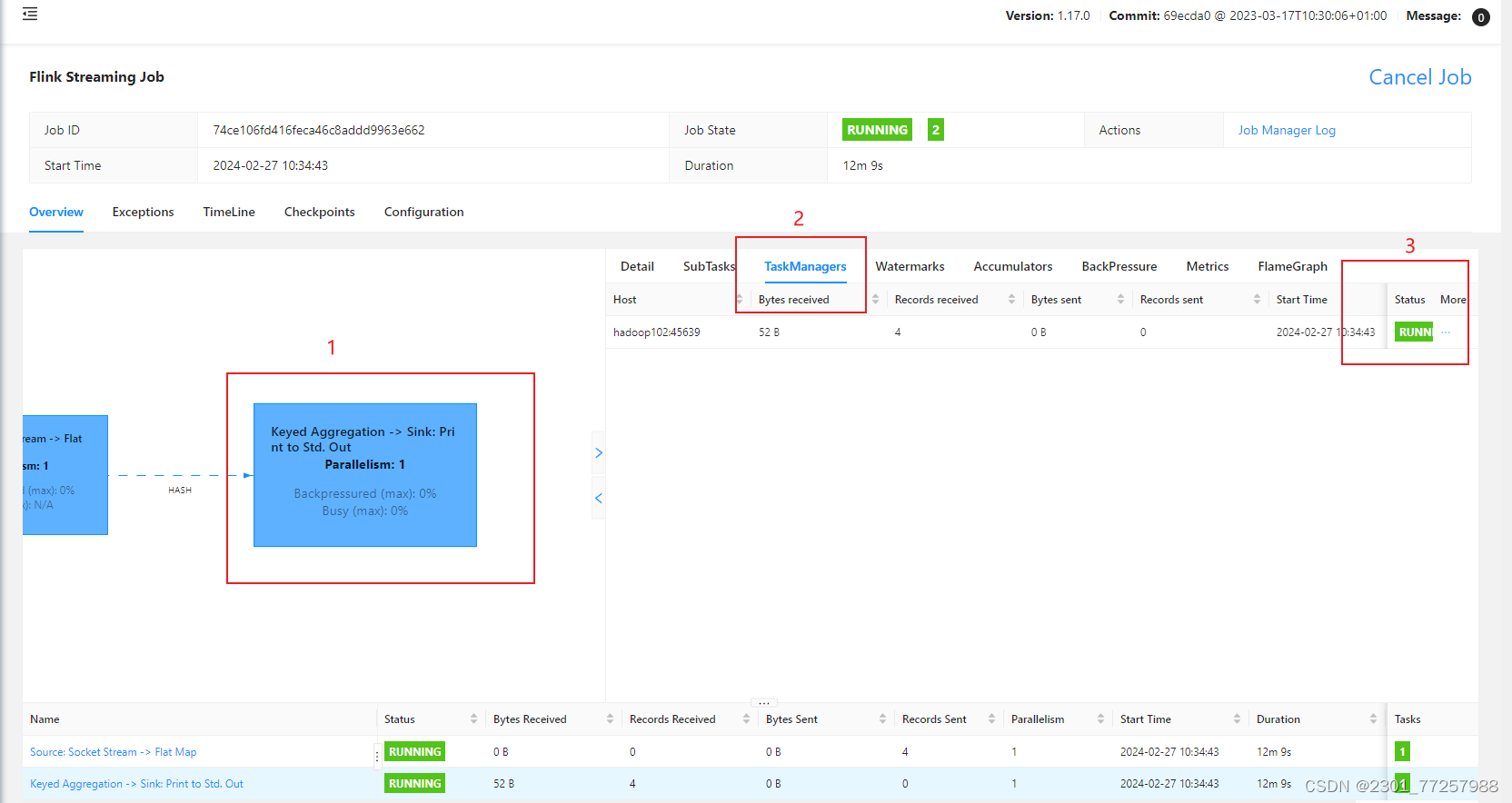
在Web UI上提交Flink作业
1)任务打包完成后,我们打开Flink的WEB UI页面,在右侧导航栏点击“Submit New Job”,然后点击按钮“ Add New”,选择要上传运行的JAR包 JAR包上传完成,如下图所示 (2)点击该JAR包&…
Flink Catalog
1.Flink侧创建 按照SQL的解析处理流程在Parse解析SQL以后,进入执行流程——executeInternal。 其中有个分支专门处理创建Catalog的SQL命令
} else if (operation instanceof CreateCatalogOperation) {return createCatalog((CreateCatalogOperation) operatio…
Flink:流上的“不确定性”(Non-Determinism)
1. 什么是“确定性” 先明确一下什么叫“确定性”:对于一个“操作”来说,如果每次给它的“输入”不变,操作输出的“结果”也不变,那么这个操作就是“确定性“的。通常,我们认为批处理的操作都是确定的,比如…
【大数据】Flink SQL 语法篇(九):Window TopN、Deduplication
Flink SQL 语法篇(九):Window TopN、Deduplication 1.Window TopN2.Deduplication2.1 案例 1(事件时间)2.2 案例 2(处理时间) 1.Window TopN
Window TopN 定义(支持 Streaming&…
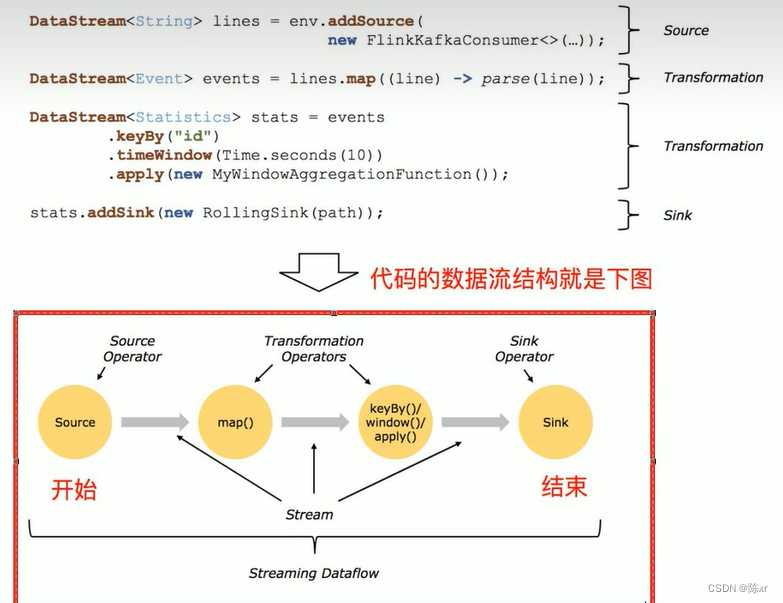
2024-02-28(Kafka,Oozie,Flink)
1.Kafka的数据存储形式 一个主题由多个分区组成
一个分区由多个segment段组成
一个segment段由多个文件组成(log,index(稀疏索引),timeindex(根据时间做的索引)) 2.读数据的流程
…

【大数据】Flink SQL 语法篇(八):集合、Order By、Limit、TopN
Flink SQL 语法篇(八):集合、Order By、Limit、TopN 1.集合操作2.Order By、Limit 子句2.1 Order By 子句2.2 Limit 子句 3.TopN 子句 1.集合操作
集合操作支持 Batch / Streaming 任务。 UNION:将集合合并并且去重。UNION ALL&a…

flink重温笔记(八):Flink 高级 API 开发——flink 四大基石之 Window(涉及Time)
Flink学习笔记 前言:今天是学习 flink 的第八天啦!学习了 flink 高级 API 开发中四大基石之一: window(窗口)知识点,这一部分只要是解决数据窗口计算问题,其中时间窗口涉及时间,计数…
Flink SQL 使用UDF函数实现将多行值转为数组
1、背景
在使用Flink SQL同步数据的实际场景中,会碰到需要将多行数据转为数组的情况。 以MySQL同步ES为例,假如我们需要把每个学生的选修课程用数组格式存到ES。
namecourse苏苏语文苏苏数学苏苏英语橙橙政治橙橙物理橙橙计算机
需要得到以下结果&…
Apache Paimon Append Queue表解析
a) 定义
在此模式下,将append table视为由bucket分隔的queue。
同一bucket中的每条record都是严格排序的,流式读取将完全按照写入顺序将record传输到下游。
使用此模式,无需特殊配置,所有数据都将作为queue进入一个bucket&…
Flink 的历史版本特性介绍(一)
如果你还不了解 Flink 是什么,可以查看我之前的介绍文章:Flink 介绍
如果你想跟着我一起学习 flink,欢迎查看订阅专栏:Flink 专栏
这篇文章列举了 Flink 每次发布的版本中的重要特性,从中可以看出 Flink 是如何一步一步发展到今天的。
Flink 的前身是 Stratosphere 项目…
Flink算子通用状态应用测试样例
Flink算子通用状态应用测试样例
1. 获取Flink执行环境 final StreamExecutionEnvironment env StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);2. 创建数据源,生成随机数据 DataStream<Map<String, String>> source e…
Flink:动态表 / 时态表 / 版本表 / 普通表 概念区别澄清
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
使用KeyedCoProcessFunction解决Flink中的数据倾斜问题
Apache Flink 是一个流处理和批处理的开源框架,它提供了一种高级别的抽象来处理分布式数据流。KeyedCoProcessFunction 是 Flink 中一个特殊的函数,用于处理具有相同 key 的数据。当使用 keyBy 操作并且数据分布不均导致某些 key 的数据量特别大…
大数据之Flink(一)
1、简介
flink是一个分布式计算/处理引擎,用于对无界和有界数据流进行状态计算。
flink处理流程 应用场景:
电商销售:实时报表、广告投放、实时推荐物联网:实时数据采集、实时报警物流配送、服务:订单状态跟踪、信…
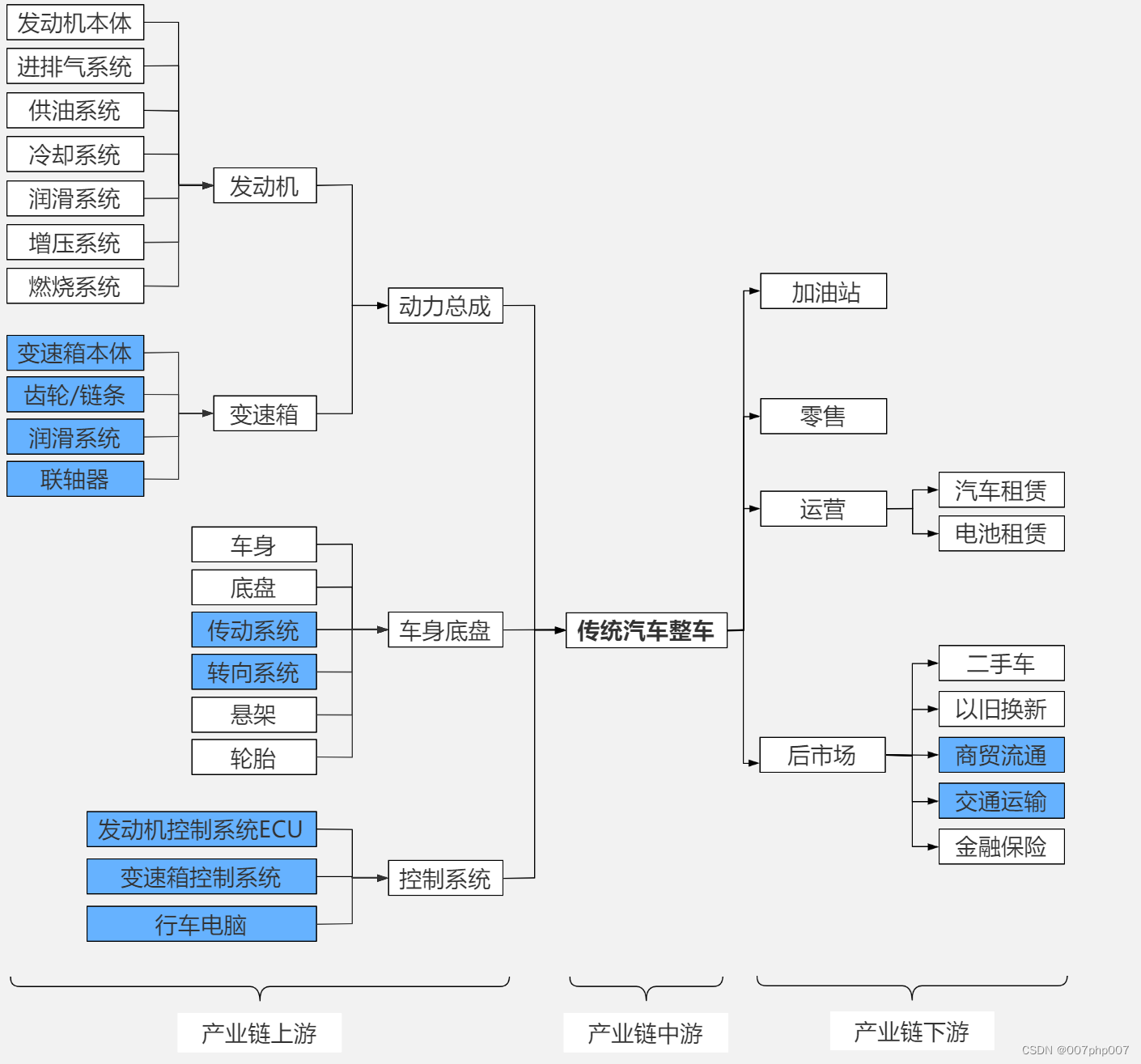
智慧回收与售后汽车平台架构设计与实现:打造可持续出行生态
随着汽车保有量的增加和环保意识的提升,汽车回收和售后服务成为了整个汽车产业链中不可或缺的一环。如何设计和实现一个智慧化的回收与售后汽车平台架构,成为了当前汽车行业关注的热点话题。本文将从需求分析、技术架构、数据安全等方面,探讨…

Apache Flink连载(三十六):Flink基于Kubernetes部署(6)-Kubernetes 集群搭建-2
🏡 个人主页:IT贫道-CSDN博客 🚩 私聊博主:私聊博主加WX好友,获取更多资料哦~ 🔔 博主个人B栈地址:豹哥教你学编程的个人空间-豹哥教你学编程个人主页-哔哩哔哩视频 目录
1. calico安装
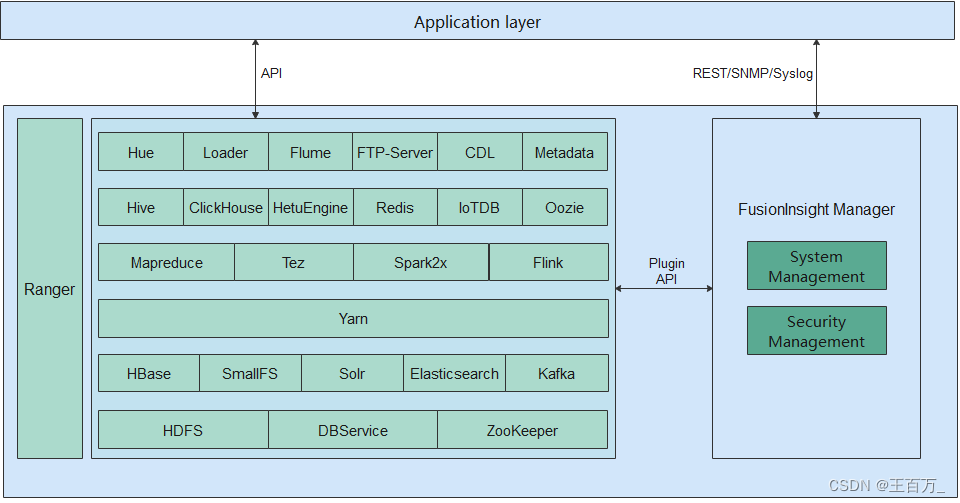
华为大数据平台-FusionInsight MRS
1、产品定位
(1) 关于华为的大数据平台,本人之前用过FusionInsight HD版本,近期也在用MRS结合MPP和治理平台做湖仓一体的开发,其实MRS是在HD基础上进行的升级、改版,MRS是集成一些开源的大数据组件,有自己的运维和安全…
Flink CDC 3.0 Starrocks建表失败会导致任务卡主!
Flink CDC 3.0 Starrocks建表失败会导致任务卡主!
现象
StarRocks建表失败,然后任务自动重启,重启完毕后数据回放,jobMaster打印下面日志后,整个任务会卡主
There are already processing requests. Wait for proce…
flink - sink - hive
依赖
以下依赖均可以放到flink lib中,然后在pom中声明为provided
flink-connector-hive
flink对hive的核心依赖 <dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_${scala.version}</artifactId>…
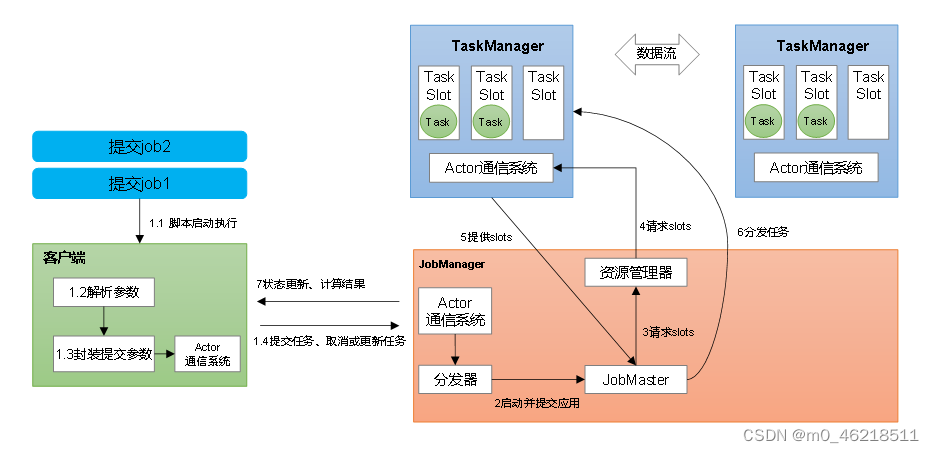
大数据基础设施搭建 - Flink
文章目录 一、上传并解压压缩包二、修改集群配置2.1 修改flink-conf.yaml文件2.2 修改workers文件2.3 修改masters文件2.4 分发配置文件2.5 修改其他两台机器的配置文件flink-conf.yaml 三、启动关闭集群(Standalone模式)四、访问WEB-UI五、向集群提交作…
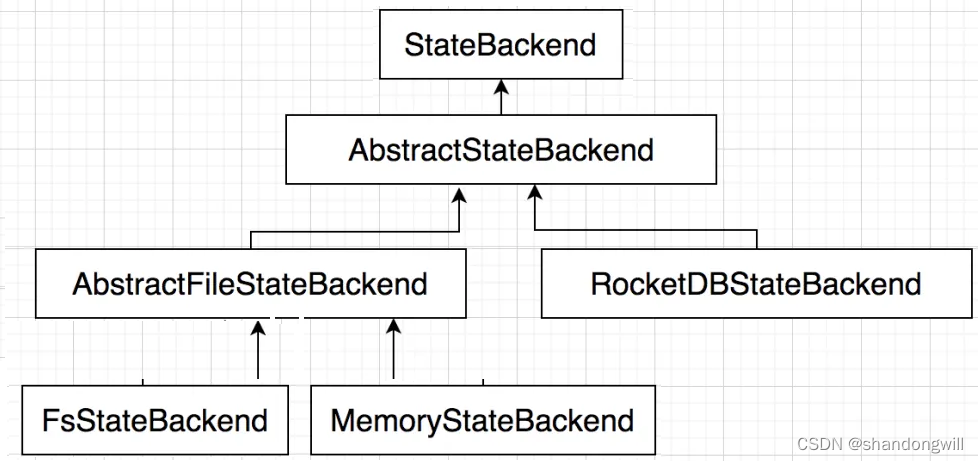
Flink状态存储-StateBackend
文章目录 前言一、MemoryStateBackend二、FSStateBackend三、RocksDBStateBackend四、StateBackend配置方式五、状态持久化六、状态重分布OperatorState 重分布KeyedState 重分布 七、状态过期 前言
Flink是一个流处理框架,它需要对数据流进行状态管理以支持复杂的…
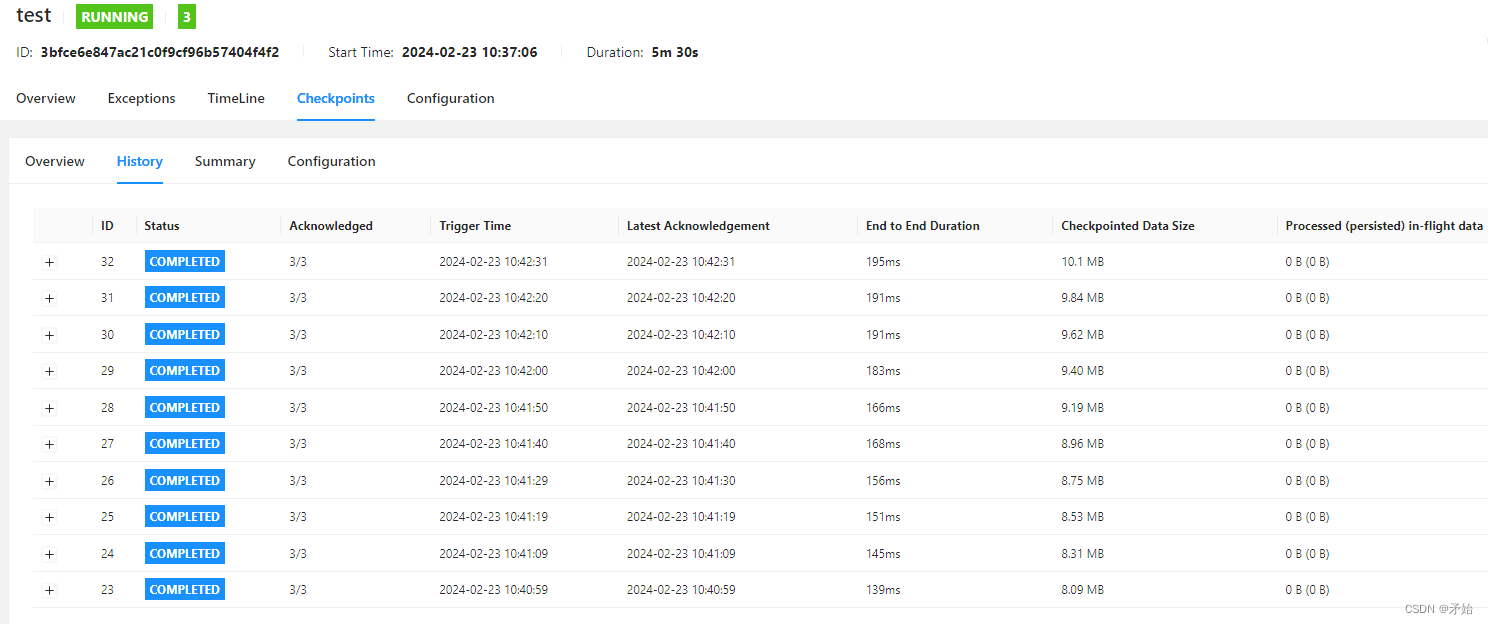
【flink】Rocksdb TTL状态全量快照持续递增
flink作业中的MapState开启了TTL,并且使用rocksdb作为状态后端配置了全量快照方式(同时启用全量快照清理),希望能维持一个平稳的运行状态,但是经观察后发现效果不达预期,不仅checkpoint size持续缓慢递增&a…

FlinkSQL ChangeLog
01 Changelog相关优化规则
0101 运行upsert-kafka作业
登录sql-client,创建一个upsert-kafka的sql作业(注意,这里发送给kafka的消息必须带key,普通只有value的消息无法解析,这里的key即是主键的值)
CREA…
Flink基本原理 + WebUI说明 + 常见问题分析
Flink 概述
Flink 是一个用于进行大规模数据处理的开源框架,它提供了一个流式的数据处理 API,支持多种编程语言和运行时环境。Flink 的核心优点包括:
低延迟:Flink 可以在毫秒级的时间内处理数据,提供了低延迟的数据…
获取Flink作业在HDFS上保存的最新的savepoint文件路径
获取Flink作业在HDFS上保存的最新的savepoint文件路径
代码:
savepoint$(hadoop fs -ls hdfs://xxxApp/flink-checkpoints/xxxflinkjob/*/chk-*/_metadata |grep -vw Found |sort -k6,7 -r |head -n 1 |awk {print $8})上面的代码是一个Shell命令,用于…
Iceberg Flink FLIP-27实现
1 Flink基础接口 Flink的基础接口是Source,核心是两个接口:createEnumerator和createReader createEnumerator负责数据发现和分片器的创建;createReader负责实际读取器的创建
public interface Source<T, SplitT extends SourceSplit…
Apache Paimon Flink引擎解析
Paimon 支持 Flink 1.17, 1.16, 1.15 和 1.14,当前 Paimon 提供了两类 Jar 包,一类支持数据读写,另一类支持其它操作(compaction)
Version Type Jar
Flink 1.18 Bundled Jar paimon-flink-1.18-0.7…

Apache Flink连载(三十七):Flink基于Kubernetes部署(7)-Kubernetes 集群搭建-2
🏡 个人主页:IT贫道-CSDN博客 🚩 私聊博主:私聊博主加WX好友,获取更多资料哦~ 🔔 博主个人B栈地址:豹哥教你学编程的个人空间-豹哥教你学编程个人主页-哔哩哔哩视频 目录
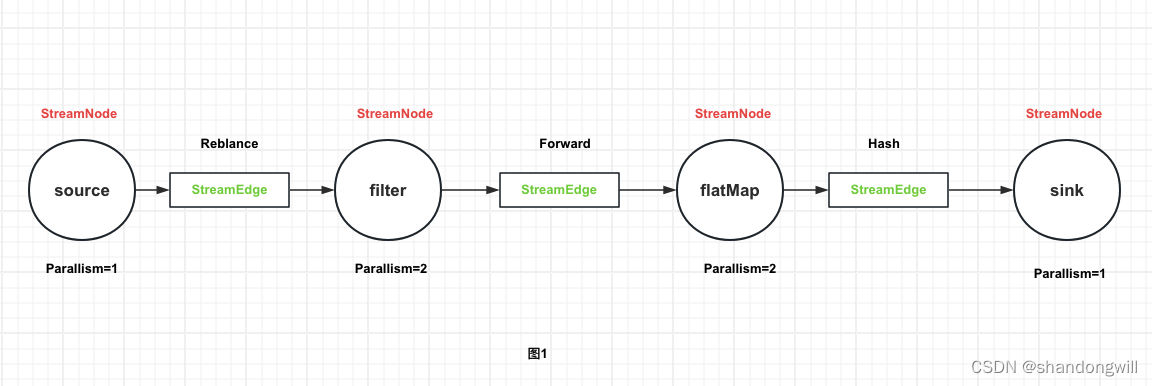
Flink StreamGraph生成过程
文章目录 概要SteramGraph 核心对象SteramGraph 生成过程 概要
在 Flink 中,StreamGraph 是数据流的逻辑表示,它描述了如何在 Flink 作业中执行数据流转换。StreamGraph 是 Flink 运行时生成执行计划的基础。 使用DataStream API开发的应用程序&#x…
Apache Flink连载(三十七):Flink基于Kubernetes部署(7)-Kubernetes 集群搭建-3
🏡 个人主页:IT贫道-CSDN博客 🚩 私聊博主:私聊博主加WX好友,获取更多资料哦~ 🔔 博主个人B栈地址:豹哥教你学编程的个人空间-豹哥教你学编程个人主页-哔哩哔哩视频 目录
Flink:Temporal Table Function(时态表函数)和 Temporal Join
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…

Apache Flink连载(三十八):Kubernetes集群UI及主机资源监控
🏡 个人主页:IT贫道-CSDN博客 🚩 私聊博主:私聊博主加WX好友,获取更多资料哦~ 🔔 博主个人B栈地址:豹哥教你学编程的个人空间-豹哥教你学编程个人主页-哔哩哔哩视频 目录
Iceberg Changelog
01 Iceberg Changelog使用
0101 Flink使用
CREATE CATALOG hive_catalog WITH (typeiceberg,catalog-typehive,urithrift://xxxx:19083,clientimecol5,property-version1,warehousehdfs://nameservice/spark
);use CATALOG hive_catalog;CREATE TABLE test2(
id B…
在docker中玩flink时候记录一些组合命令
前言
玩docker的时候记录一些组合命令,一方面是可以直接拿上来使用,还有的话也可以拿过来改改,主要是我自己有这种经历,过一阵子我自己也忘,与其去搜人家的博客还不如自己记录一把。好了,没啥所谓的规律性…
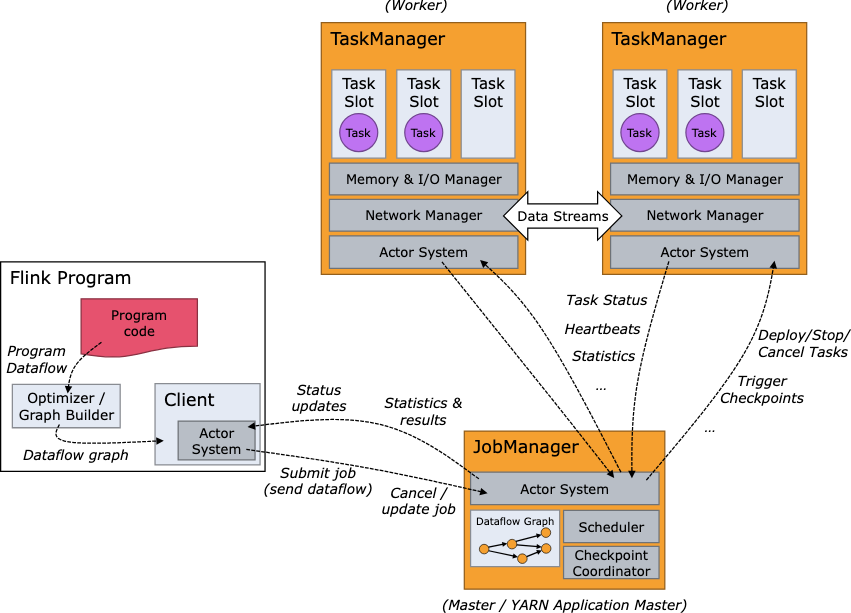
Flink 面试题总结及答案
基础 state的分类
key state和operate state
state 的重分布
Flink状态管理详解:Keyed State和Operator List State深度解析 - 掘金 checkpoint 和save point
https://zhuanlan.zhihu.com/p/79526638 flink job 的容错策略 如果在没有持续消息输出的情况下&…
flink on yarn paimon
目录 概述实践paimon 结束 概述
ogg kafka paimon
实践
前置准备请看如下文章
文章链接hadoop一主三从安装链接spark on yarn链接flink的yarn-session环境链接
paimon
目标:
1.同步表2.能过 kafka 向 paimon写入
SET parallelism.default 2;
set table.exec.sink.not-n…
[AIGC] Flink中的Max和Reduce操作:区别及使用场景
Apache Flink提供了一系列的操作,用于对流数据进行处理和转换。在这篇文章中,我们将重点关注两种常见的操作:Max和Reduce。虽然这两种操作在表面上看起来类似——都是对数据进行一些形式的聚合,但它们在应用和行为上有一些关键的区…
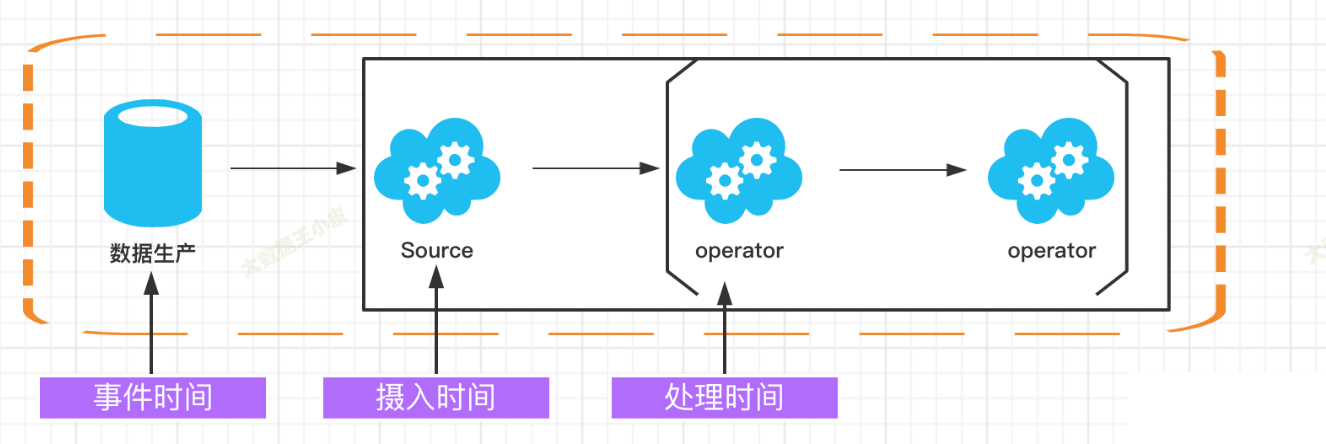
【Flink入门修炼】2-1 Flink 四大基石
前一章我们对 Flink 进行了总体的介绍。对 Flink 是什么、能做什么、入门 demo、架构等进行了讲解。 本章我们将学习 Flink 重点概念、核心特性等。 本篇对 Flink 四大基石进行概括介绍,是 Flink 中非常关键的四个内容。
一、四大基石
Flink四大基石分别是&#x…
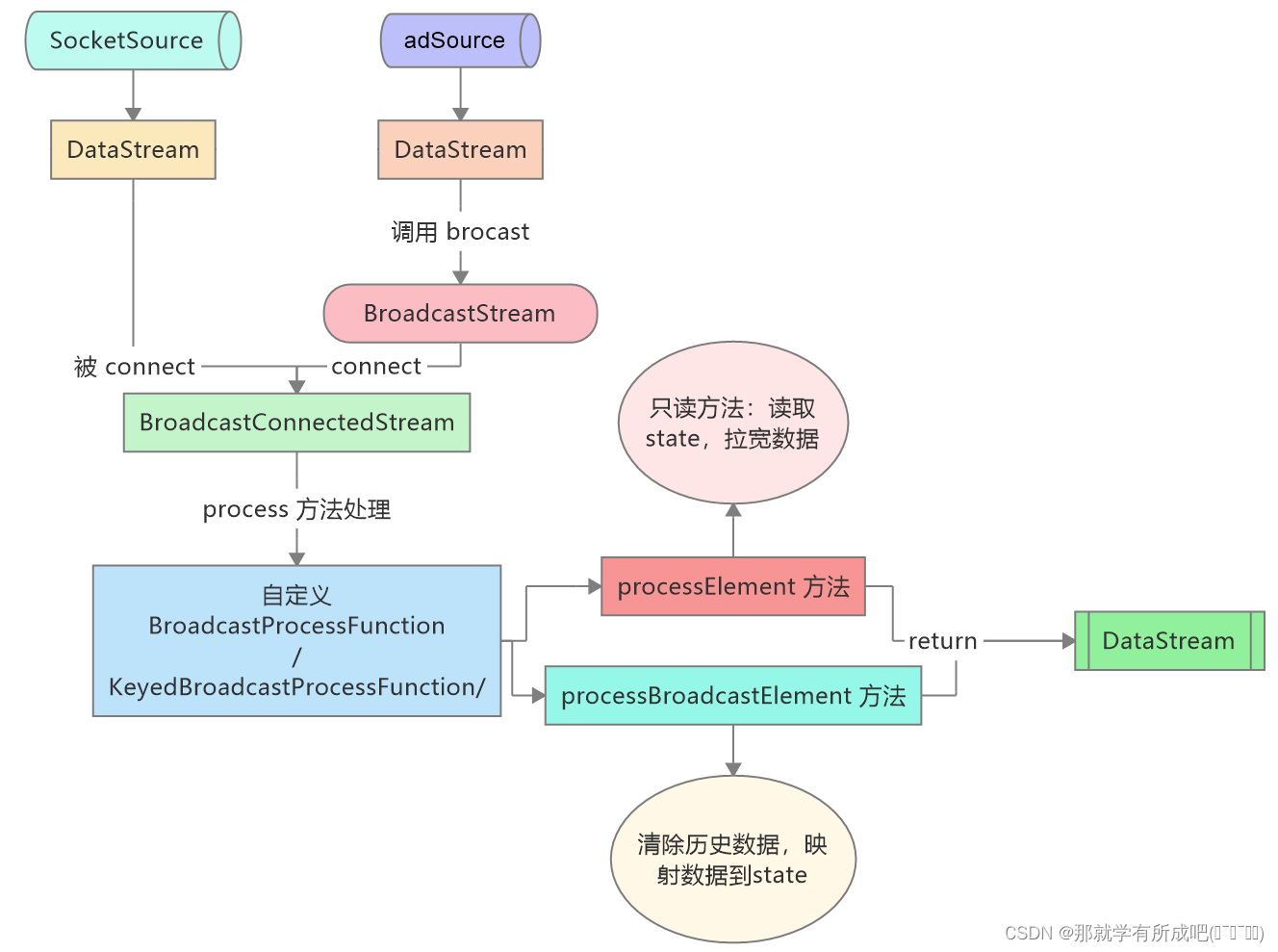
flink重温笔记(十):Flink 高级 API 开发——flink 四大基石之 State(涉及Checkpoint)
Flink学习笔记 前言:今天是学习 flink 的第 10 天啦!学习了 flink 四大基石之 State (状态),主要是解决大数据领域增量计算的效果,能够保存已经计算过的结果数据状态!重点学习了 state 的类型划…
StreamTask数据流:StreamTask能力概述、Flink处理网络数据逻辑
文章目录 一. StreamTask核心组件与能力二. OneInputStreamTask接入网络数据并处理三. 处理数据1. StreamElement类别2. 业务数据处理逻辑 四. 小结 先来看数据是如何经过网络写入下游Task节点并通过算子进行处理的,这里以OneInputStreamTask为例进行说明。
一. St…
SpringBoot集成flink
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。 最大亮点是流处理,最适合的应用场景是低时延的数据处理。 场景:高并发pipeline处理数据,时延毫秒级,且兼具…
[AIGC] 深入理解Flink中的窗口、水位线和定时器
Apache Flink是一种流处理和批处理的混合引擎,它提供了一套丰富的APIs,以满足不同的数据处理需求。在本文中,我们主要讨论Flink中的三个核心机制:窗口(Windows)、水位线(Watermarks)…
Flink部署-yarn模式和K8S模式
一、yarn模式
以Yarn模式部署Flink任务时,要求Flink是有 Hadoop 支持的版本,Hadoop 环境需要保证版本在 2.2 以上,并且集群中安装有 HDFS 服务。
Flink提供了两种在yarn上运行的模式,分别为Session-Cluster和Per-Job-Cluster模式…
sprintboot集成flink快速入门demo
一、flink介绍 Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。Flink最适合的应用场景是低时延的数据处理(Data Processing&…
【Flink网络数据传输(4)】RecordWriter(下)封装数据并发送到网络的过程
文章目录 一. RecordWriter封装数据并发送到网络1. 数据发送到网络的具体流程2. 源码层面2.1. Serializer的实现逻辑a. SpanningRecordSerializer的实现b. SpanningRecordSerializer中如何对数据元素进行序列化 2.2. 将ByteBuffer中间数据写入BufferBuilder 二. BufferBuilder申…

【Flink网络数据传输】OperatorChain的设计与实现
文章目录 1.OperatorChain的设计与实现2.OperatorChain的创建和初始化3.创建RecordWriterOutput 1.OperatorChain的设计与实现
OperatorChain的大致逻辑 在JobGraph对象的创建过程中,将链化可以连在一起的算子,常见的有StreamMap、StreamFilter等类型的…
flink重温笔记(十一):Flink 高级 API 开发——flink 四大基石之 Checkpoint(详解存储后端)
Flink学习笔记 前言:今天是学习 flink 的第 11 天啦!学习了 flink 四大基石之 Checkpoint (检查点),主要是解决大数据领域持久化中间结果数据,以及取消任务,下次启动人可以恢复累加数据问题&…

Flink学习4 - 富函数 + 数据重分区操作 + sink 操作(kafka、redis、jdbc)
1、富函数 - 函数类接口,可以获取运行环境的上下文,实现更复杂的功能 2、数据重分区操作 3、sink操作
sink - kafka
1、引入kafka的pom依赖
<dependency><groupId>org.apache.flink</groupId>
<!--<artifactId>flink-conn…
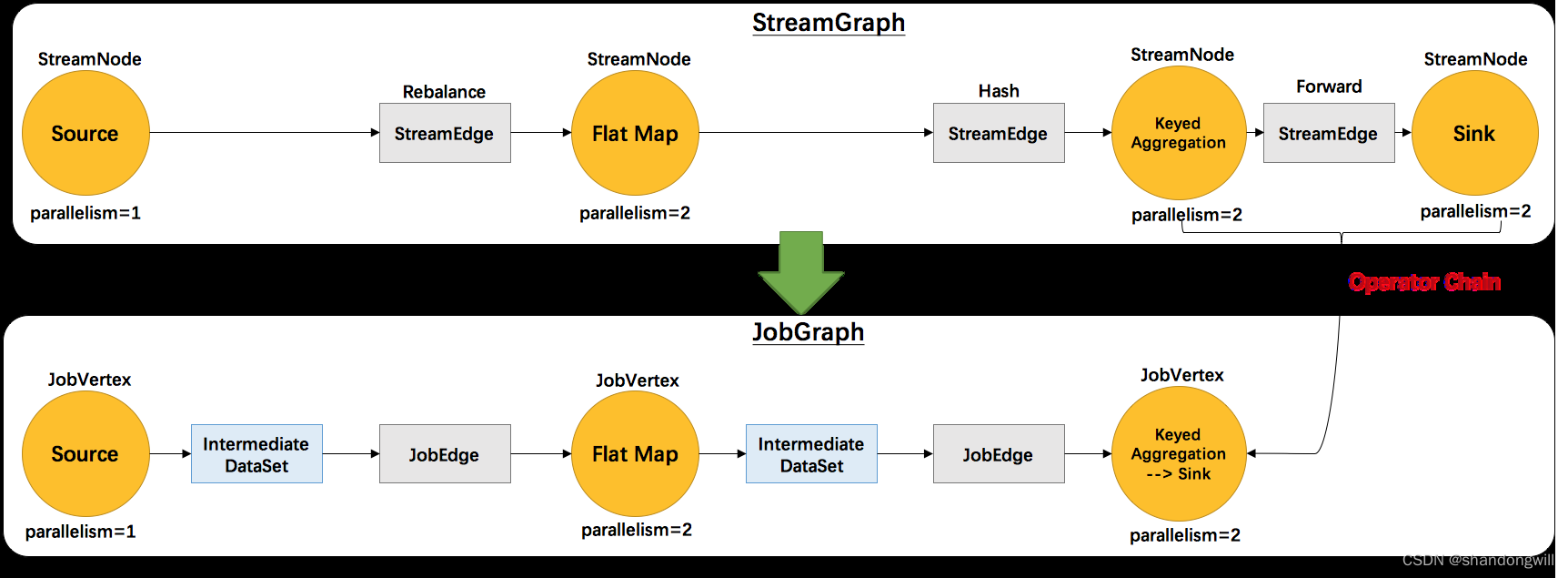
Flink JobGraph构建过程
文章目录 前言JobGraph创建的过程总结 前言
在StreamGraph构建过程中分析了StreamGraph的构建过程,在StreamGraph构建完毕之后会对StreamGraph进行优化构建JobGraph,然后再提交JobGraph。优化过程中,Flink会尝试将尽可能多的StreamNode聚合在…
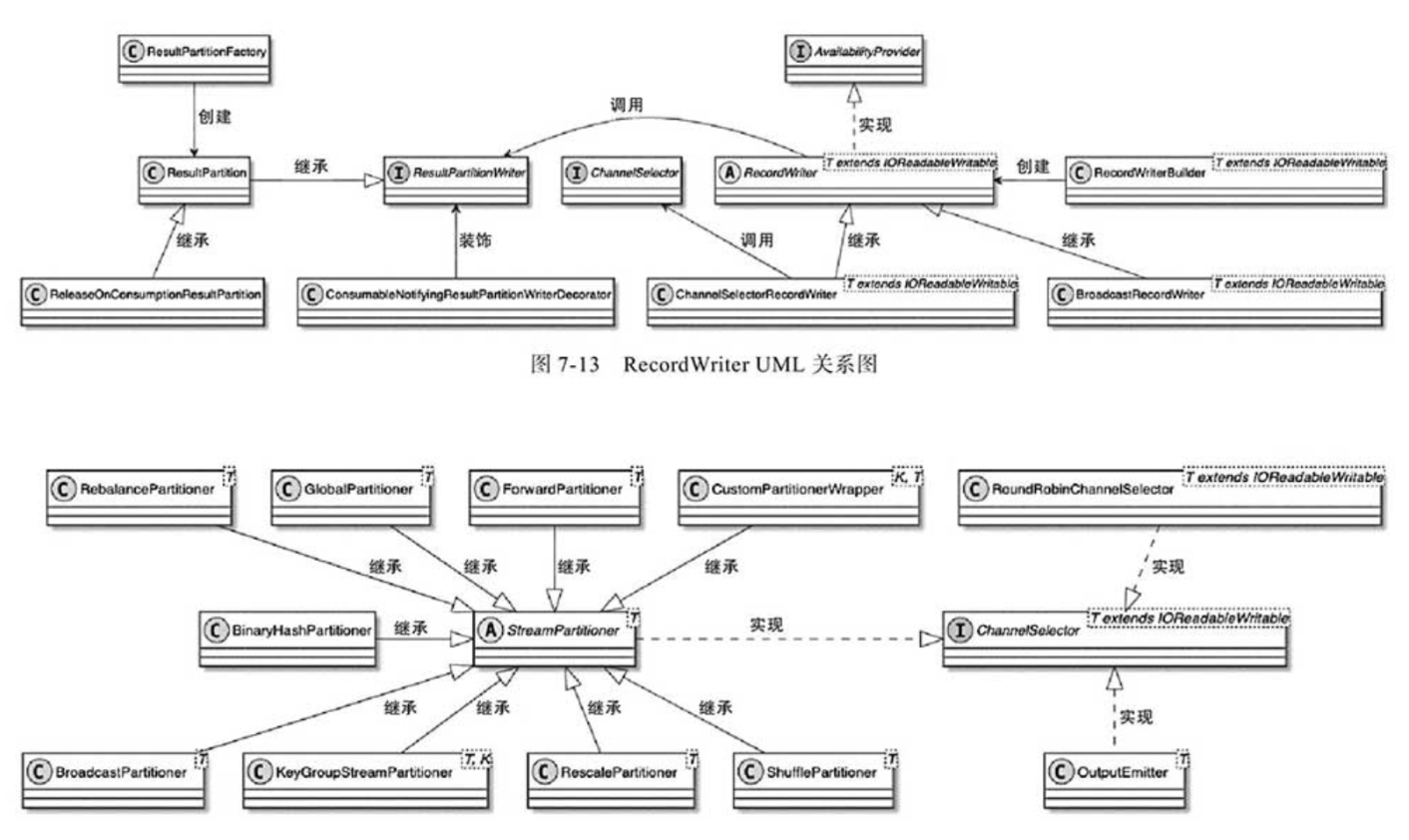
【Flink网络数据传输(3)】RecordWriter的能力:实现数据分发策略或广播到下游InputChannel
文章目录 一.创建RecordWriter实例都做了啥1. 根据recordWrites数量创建不同的代理类2. 创建RecordWriters3. 单个RecordWriter的创建细节 二. RecordWriter包含的主要组件1. RecordWriter两种实现类分别实现分发策略和广播2. ChannelSelectorRecordWriter的发送策略2.1. Chann…

Flink:Temporal Table 的两种实现方式 Temporal Table DDL 和 Temporal Table Function
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
使用 SPL 高效实现 Flink SLS Connector 下推
作者:潘伟龙(豁朗)
背景
日志服务 SLS 是云原生观测与分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务,基于日志服务的便捷的数据接入能力,可以将系统日志、业务日志等接入 …
java Flink(四十一)Flink+avro+广播流broadcast实现流量的清洗
背景简介
本文简单模拟对流量的处理,大概步骤如下:
1、通过获取一个维度流,内容是流量内容的元数据信息,获取解析并进行广播
2、获取实时流量流,做延迟处理(防止数据关联不上)
3、流量流关联…
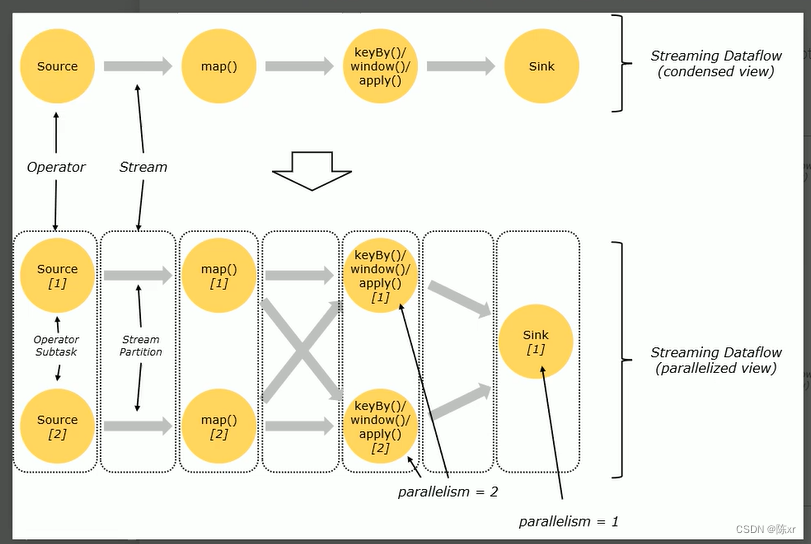
2024-02-29(Flink)
1.Flink原理(角色分工) 2.Flink执行流程
on yarn版: 3.相关概念
1)DataFlow:Flink程序在执行的时候会被映射成一个数据流模型;
2)Operator:数据流模型中的每一个操作被称作Operat…
测试环境搭建整套大数据系统(七:集群搭建kafka(2.13)+flink(1.13.6)+dinky(0.6)+iceberg)
一:搭建kafka。
1. 三台机器执行以下命令。
cd /opt
wget wget https://dlcdn.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgz
tar zxvf kafka_2.13-3.6.1.tgz
cd kafka_2.13-3.6.1/config
vim server.properties修改以下俩内容 1.三台机器分别给予各自的broker_id…
【大数据】Flink SQL 语法篇(五):Regular Join、Interval Join
《Flink SQL 语法篇》系列,共包含以下 10 篇文章:
Flink SQL 语法篇(一):CREATEFlink SQL 语法篇(二):WITH、SELECT & WHERE、SELECT DISTINCTFlink SQL 语法篇(三&…
flink: 从kafka读取数据
一、添加相关依赖
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/P…
[AIGC] Flink入门教程:理解DataStream API(Java版)
简介
Apache Flink是一款开源的流处理框架,它在大数据处理场景中被广泛应用。Flink的数据流API(DataStream API)是一个强大的、状态匹配的流处理API,它可以处理有界和无界数据流。
本教程将向你介绍如何使用Java来编写使用DataS…
flink:自定义数据分区
shuffle随机地将数据分配到下游的子任务。 rebalance用round robbin模式将数据分配到下游的子任务。 global把所有的数据都分配到一个分区。 partitionCustom: 自定义数据分区。
package cn.edu.tju.demo;
import org.apache.flink.api.common.functions.; import org.apache…
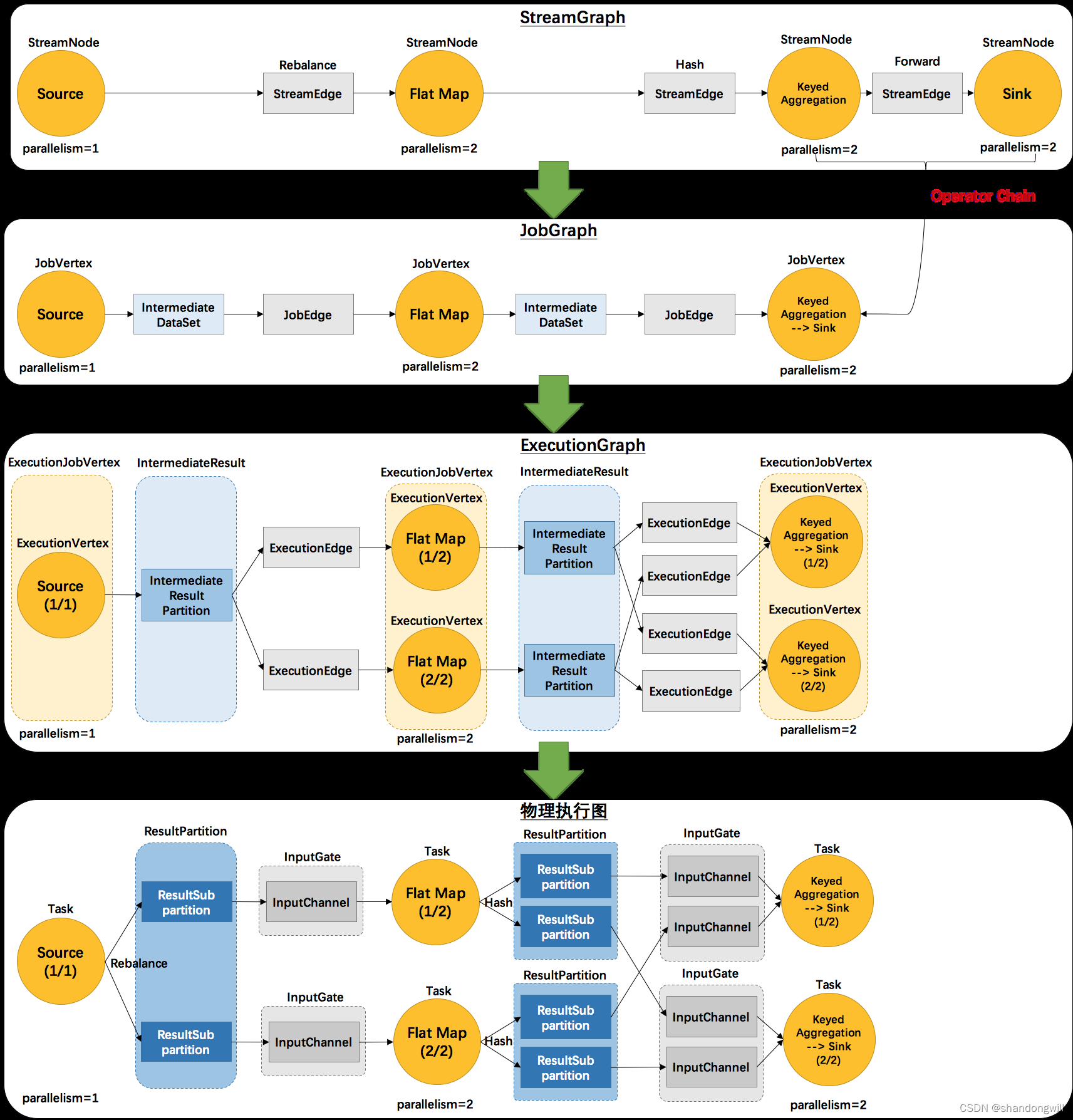
Flink 物理执行图
文章目录 物理执行图一、Task二、ResultPartition三、ResultSubpartition四、InputGate五、InputChannel 物理执行图
JobManager根据ExecutionGraph对作业进行调度,并在各个TaskManager上部署任务。这些任务在TaskManager上的实际执行过程就形成了物理执行图。物理…
Flink 学习3 - 流处理API的基本转换算子 + 多流转换算子
流处理API-Transform
1、基本转换算子
map、flatMap、filter通常被统一称为基本转换算子(简单转换算子) DataStream 里没有 reduce 和 sum 这类聚合操作的方法,因为 Flink 设计中,所有数据必须先分组才能做聚合操作。 先 keyB…

Flink hello world
下载并且解压Flink
Downloads | Apache Flink 启动Flink.
$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host harrydeMacBook-Pro.local.
Starting taskexecutor daemon on host harrydeMacBook-Pro.local.
访问localhost:8081 Flink…
Flink 资源管理
文章目录 前言ResourceManager详解Slot 管理器SlotProviderSlot资源池Slot共享Slot共享的优点Slot 共享组与 Slot 共享管理器Slot资源申请 总结 前言
在Flink中,资源管理是一个核心组件,它负责分配和管理计算资源,以确保任务能够高效、稳定地…
Flink时间语义WindowAPIWatermark详解:时间与乱序对实时处理的影响
文章目录 一、认识时间语义1、官网2、event time与process time3、Windows:窗口 二、Window详解1、Window的分类(1)按照是否是KeyBy划分:Keyed Windows(2)按照是否是KeyBy划分:Non-Keyed Window…

flink重温笔记(十三): flink 高级特性和新特性(2)——ProcessFunction API 和 双流 join
Flink学习笔记 前言:今天是学习 flink 的第 13 天啦!学习了 flink 高级特性和新特性之ProcessFunction API 和 双流 join,主要是解决大数据领域数据从数据增量聚合的问题,以及快速变化中的流数据拉宽问题,即变化中多个…

【Flink】Apache Flink 常见问题定位指南
Apache Flink 常见问题定位指南 1.问题分析概览1.1 如何分析 Flink 问题 2.常见问题处理2.1 作业自动停止2.2 输出量稳定但不及预期2.3 输出量逐步减少或完全无输出2.4 个别数据缺失2.5 作业频繁重启 3.问题追因技巧3.1 常用工具3.1.1 内存3.1.2 CPU3.1.3 磁盘 I/O3.1.4 网络 I…

【Flink】Flink 的八种分区策略(源码解读)
Flink 的八种分区策略(源码解读) 1.继承关系图1.1 接口:ChannelSelector1.2 抽象类:StreamPartitioner1.3 继承关系图 2.分区策略2.1 GlobalPartitioner2.2 ShufflePartitioner2.3 BroadcastPartitioner2.4 RebalancePartitioner2…
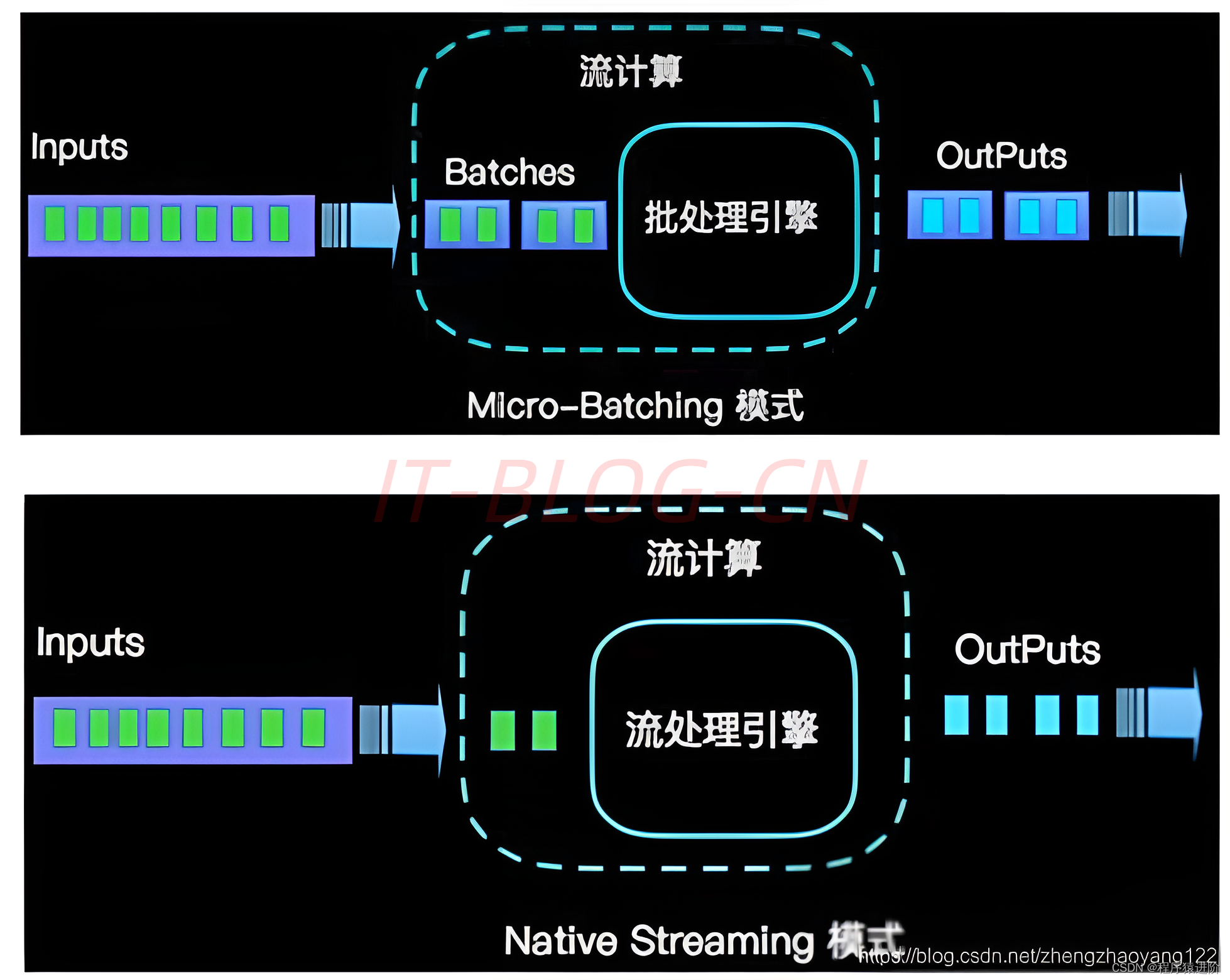
为什么选择 Flink 做实时处理
优质博文:IT-BLOG-CN 为什么选择 Flink
【1】流数据更真实地反映了我们的生活方式(实时聊天); 【2】传统的数据架构是基于有限数据集的(Spark 是基于微批次数据处理); 【3】我们的目标…
flink-cdc-学习笔记(一)
1.flink cdc简介
Flink 1.11 引入了 CDC. Flink CDC 是一款基于 Flink 打造一系列数据库的连接器。Flink 是流处理的引擎,其主要消费的数据源是类似于一些点击的日志流、曝光流等数据,但在业务场景中,点击流的日志数据只是一部分,…
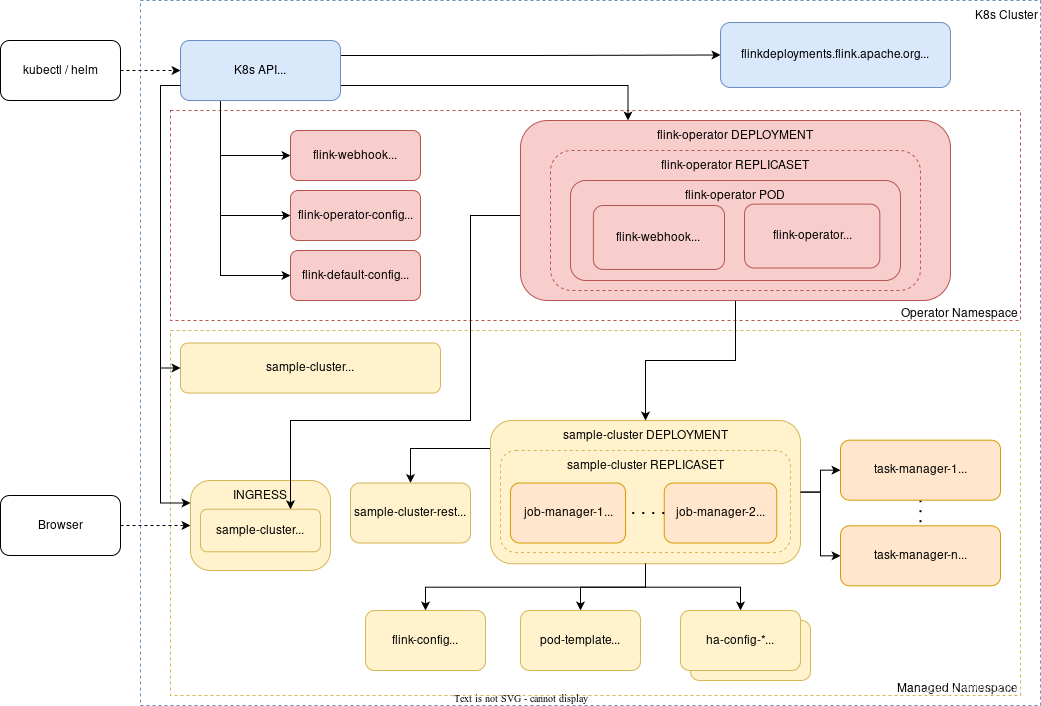
【梳理】k8s使用Operator搭建Flink集群(高可用可选)
文章目录 架构图安装cert-manager依赖helm 安装operator运行集群实例k8s上的两种模式:Native和Standalone两种CRDemo1:Application 集群Demo2:Session集群优劣创建ingress 高可用部署问题1:High availability should be enabled w…
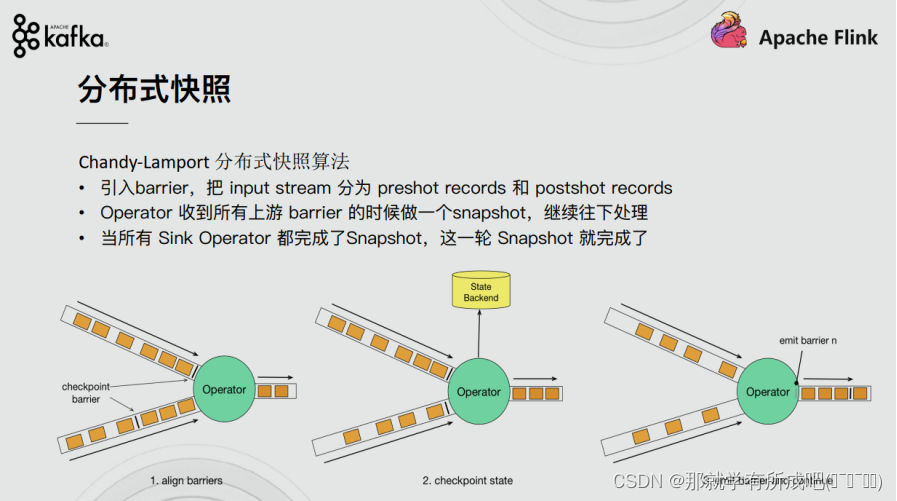
flink重温笔记(十二): flink 高级特性和新特性(1)——End-to-End Exactly-Once(端到端精确一致性语义)
Flink学习笔记 前言:今天是学习 flink 的第 12 天啦!学习了 flink 高级特性和新特性之 End-to-End Exactly-Once(端到端精确一致性语义),主要是解决大数据领域数据从数据源到数据落点的一致性,不会容易造成…
Flink读取iceberg表
1. 添加依赖包
这里使用的版本时1.14.6,scala版本是2.12. <dependency><groupId>org.apache.iceberg</groupId><artifactId>iceberg-flink-runtime-1.14</artifactId></dependency><dependency><groupId>org.apac…
【Flink SQL】Flink SQL 基础概念:数据类型
Flink SQL 基础概念:数据类型 1.原子数据类型1.1 字符串类型1.2 二进制字符串类型1.3 精确数值类型1.4 有损精度数值类型1.5 布尔类型:BOOLEAN1.6 日期、时间类型 2.复合数据类型3.用户自定义数据类型 Flink SQL 内置了很多常见的数据类型,并…
flink重温笔记(十五): flinkSQL 顶层 API ——实时数据流转化为SQL表的操作
Flink学习笔记 前言:今天是学习 flink 的第 15 天啦!学习了 flinkSQL 基础入门,主要是解决大数据领域数据处理采用表的方式,而不是写复杂代码逻辑,学会了如何初始化环境,鹅湖将流数据转化为表数据ÿ…
Apache Paimon 使用之 Lookup Joins 解析
Lookup Join 是流式查询中的一种 Join,Join 要求一个表具有处理时间属性,另一个表由lookup source connector支持。
Paimon支持在主键表和附加表上进行Lookup Join。
a) 准备
创建一个Paimon表并实时更新它。
-- Create a paimon catalog
CREATE CAT…
Apache Paimon系列之:Flink集成Paimon
Apache Paimon系列之:Flink集成Paimon 一、准备Paimon Jar File二、快速开始1.第1步:下载Flink2.第 2 步:复制 Paimon 捆绑 Jar3.第 3 步:复制 Hadoop 捆绑 Jar4.步骤4:启动Flink本地集群5.第 5 步:创建目录和表6.第6步:写入数据7.第7步:OLAP查询8.步骤8:流式查询9.第…

【Flink SQL】Flink SQL 基础概念:SQL 的时间属性
Flink SQL 基础概念:SQL 的时间属性 1.Flink 三种时间属性简介2.Flink 三种时间属性的应用场景2.1 事件时间案例2.2 处理时间案例2.3 摄入时间案例 3.SQL 指定时间属性的两种方式4.SQL 事件时间案例5.SQL 处理时间案例 与离线处理中常见的时间分区字段一样ÿ…
Flink广播流 BroadcastStream
文章目录 前言BroadcastStream代码示例Broadcast 使用注意事项 前言
Flink中的广播流(BroadcastStream)是一种特殊的流处理方式,它允许将一个流(通常是一个较小的流)广播到所有的并行任务中,从而实现在不同…
flink的自动类型推导:解决udf的通用类型问题
问题背景
一开始编写了一个udf函数:
public class ArrayContains extends ScalarFunction {private static final int EXIST 1;private static final int NOT_EXIST -1;// 第一个参数是待检查的数组,第二个参数是待验证元素是否存在于第一个参数中pu…
Apache Paimon 的 CDC Ingestion 概述
CDC Ingestion
1)概述
Paimon支持schema evolution将数据插入到Paimon表中,添加的列将实时同步到Paimon表,并且无需重启同步作业。
目前支持的同步方式如下:
MySQL Synchronizing Table: 将MySQL中的一个或多个表同步到一个Pa…
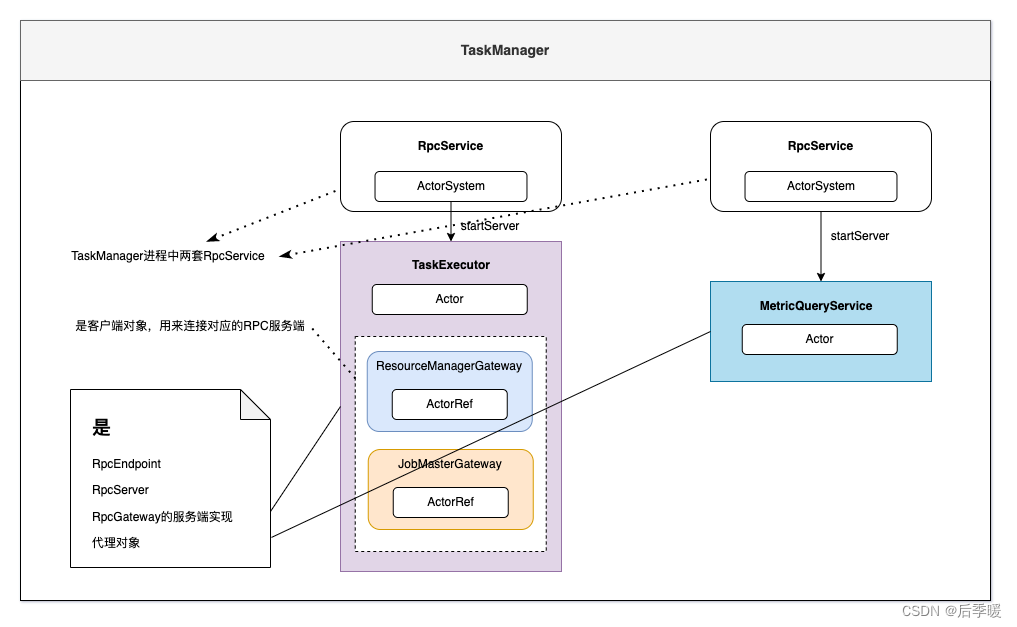
Flink通讯模型—Akka与Actor模型
Carl Hewitt 在1973年对Actor模型进行了如下定义:"Actor模型是一个把Actor作为并发计算的通用原语". Actor是异步驱动,可以并行和分布式部署及运行的最小颗粒。也就是说,它可以被分配,分布,调度到不同的CPU&…
Apache Paimon 的 Query Service 使用
Query Service
可以运行Flink流作业来启动表的查询服务,当QueryService存在时,Flink Lookup Join将优先从中获取数据,这将有效地提高查询性能。
Flink SQL
CALL sys.query_service(database_name.table_name, parallelism);Flink Action
…

如何高效接入 Flink: Connecter / Catalog API 核心设计与社区进展
本文整理自阿里云实时计算团队 Apache Flink Committer 和 PMC Member 任庆盛在 FFA 2023 核心技术专场(二)中的分享,内容主要分为以下四部分: Source APISink API将 Connecter 集成至 Table /SQL APICatalog API 在正式介绍这些 …
Flink 流处理框架核心性能
Apache Flink 是一款先进的开源分布式数据处理框架,其核心特性体现了对大规模数据处理的高度适应性和灵活性,尤其在实时流处理领域展现出了卓越的技术优势:
1 高性能实时处理
Flink 引擎设计注重高吞吐量与低延迟的完美结合,可轻…
flink重温笔记(十七): flinkSQL 顶层 API ——SQLClient 及流批一体化
Flink学习笔记 前言:今天是学习 flink 的第 17 天啦!学习了 flinkSQL 的客户端工具 flinkSQL-client,主要是解决大数据领域数据计算避免频繁提交jar包,而是简单编写sql即可测试数据,文章中主要结合 hive,即…

记一次Flink任务无限期INITIALIZING排查过程
1.前言
环境:Flink-1.16.1,部署模式:Flink On YARN,现象:Flink程序能正常提交到 YARN,Job状态是 RUNNING,而 Task状态一直处于 INITIALIZING,如下图:
通过界面可以看到…

Flink实时数仓之用户埋点系统(一)
需求分析及框架选型 需求分析数据采集用户行为采集业务数据采集 行为日志分析用户行为日志页面日志启动日志APP在线日志 业务数据分析用户Insert数据用户Update数据 技术选型Nginx配置Flume配置MaxWellHadoopFlink架构图 需求分析
数据采集
用户行为采集
行为数据࿱…
FlinkCDC快速搭建实现数据监控
引入依赖
<project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelV…
Flink异步io关联Hbase
主程序 public static void main(String[] args) throws Exception {//1.获取流执行环境StreamExecutionEnvironment env StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SimpleDateFormat formatter new SimpleDateFormat("yyyy-MM-dd H…
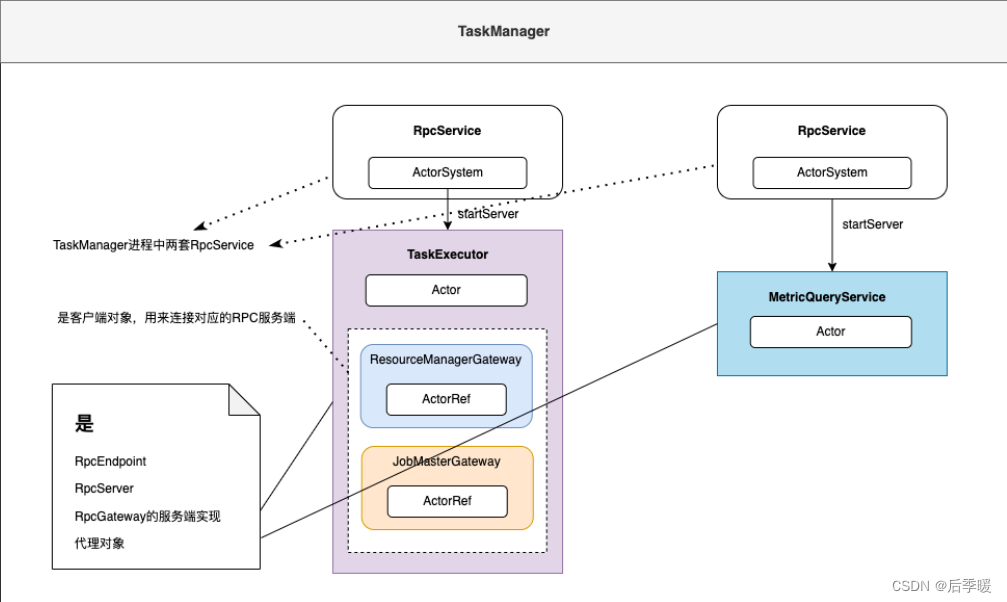
Flink源码解析(1)TM启动
首先在看之前,回顾一下akka模型:
Flink通讯模型—Akka与Actor模型-CSDN博客
注:ActorRef就是actor的引用,封装好了actor
下面是jm和tm在通讯上的概念图: RpcGateway 用于定义RPC协议,是客户端和服务端沟通的桥梁。服务端实现了RPC协议,即实现了接口中定义的方法,做具…
【Flink SQL】Flink SQL 基础概念(五):SQL 时区问题
《Flink SQL 基础概念》系列,共包含以下 5 篇文章:
Flink SQL 基础概念(一):SQL & Table 运行环境、基本概念及常用 APIFlink SQL 基础概念(二):数据类型Flink SQL 基础概念&am…
流式数据湖平台实战 | 在Flink DataStream API中集成和使用Hudi
1.Flink Datastream API中使用Hudi
添加相应版本的maven依赖
<!-- Flink 1.13 -->
<dependency><groupId>org.apache.hudi</groupId><artifactId>hudi-flink1.13-bundle</artifactId><version>0.14.0</version>
</depend…
Flink实时写Hudi报NumberFormatException异常
Flink实时写Hudi报NumberFormatException异常
问题描述
在Flink项目中,针对Hudi表 xxxx_table 的 bucket_write 操作由于 java.lang.NumberFormatException 异常而从运行状态切换到失败状态。异常信息显示在解析字符串"ddd7a1ec"为整数时出现了问题。报…
Flink 数据目录体系:深入理解 Catalog、Database 及 Table 概念
Apache Flink 在其数据处理框架中引入了 Catalog、Database、Table 等一系列概念,旨在为用户提供一种结构化的元数据管理和访问机制,从而简化大数据环境下的数据源整合和处理流程。以下是这三个核心概念的详细介绍: Catalog(目录&…
flink重温笔记(十八): flinkSQL 顶层 API ——时态表实现表数据动态变化(涵盖全面实用的 API )
Flink学习笔记 前言:今天是学习 flink 的第 18 天啦!很多小伙伴私信说,自己只会SQL语法来编写flinkSQL,如何使用代码来操作呢?因为工作中都是要用到代码编写的。还有小伙伴说,想要实现表是动态变化的&#…
flink day1
一切皆流, 有界流和无界流不同层级api ,
越顶层越抽象,表达含义越简明, 使用起来越简单. 越底层越具体,表达能力,使用能力越丰富.
flink table /sql /dynamic tablesstream /batch processing ( data stream api ) (stream windiws)statefull event /driver applications
…
flink状态后端和检查点的关系
在 Apache Flink 中,检查点(Checkpoints)和状态后端(State Backend)是两个核心概念,它们之间有着紧密的联系。为了更好地理解这种联系,我们首先需要分别了解这两个概念。 检查点(Che…
Flink程序员开发利器本地化WebUI生成
前言
在flink程序开发或者调试过程中,每次部署到集群上都需要不断打包部署,其实是比较麻烦的事情,其实flink一直就提供了一种比较好的方式使得开发同学不用部署就可以观察到flink执行情况。
上代码
第一步:开发之前需要引入在本…
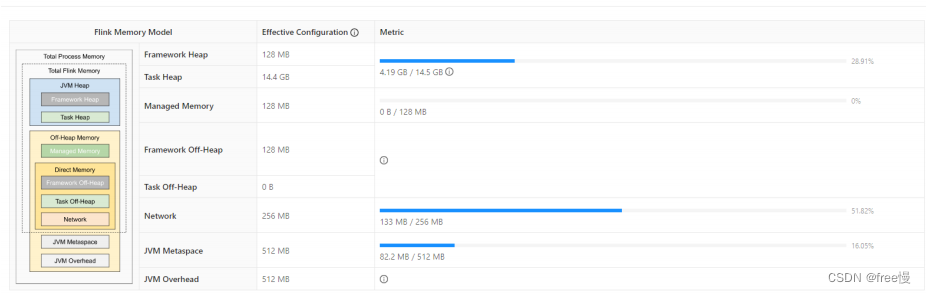
Flink 性能优化总结(内存配置篇)
内存配置优化
Flink 内存模型 内存模型详解
进程内存(Total Process Memory):Flink 进程内存分为堆上内存和堆外内存,堆上内存和 堆外内存的主要区别在于它们的管理方式不同和使用方式不同,这些会影响到它们的性能和…
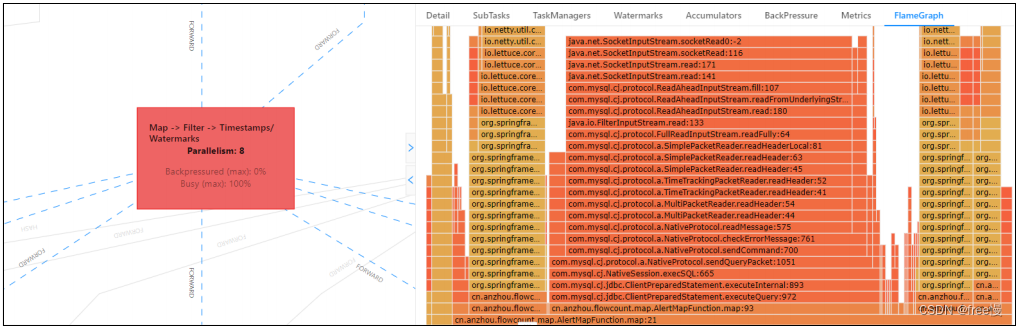
Flink 性能优化总结(反压优化篇)
反压的理解
Flink 中每个节点间的数据都以阻塞队列的方式传输,下游来不及消费导致队列被占满后,上游的生产也会被阻塞,最终导致数据源的摄入被阻塞。简单来说就是系统接收数据的速率远高于它处理数据的速率。 反压如果不能得到正确的处理&am…
Flink创建TableEnvironment
在官网上,Flink创建TableEnvironment有两种方式:1.通过静态方法 TableEnvironment.create() 创建;2.从现有的 StreamExecutionEnvironment 创建一个 StreamTableEnvironment 与 DataStream API 互操作
import org.apache.flink.table.api.En…
【Flink SQL】Flink SQL 基础概念:SQL Table 运行环境、基本概念及常用 API
Flink SQL 基础概念:SQL & Table 运行环境、基本概念及常用 API 1.SQL & Table 简介及运行环境1.1 简介1.2 SQL 和 Table API 运行环境依赖 2.SQL & Table 的基本概念及常用 API2.1 一个 SQL / Table API 任务的代码结构2.2 SQL 上下文:Tabl…
flink:通过table api把文件中读取的数据写入MySQL
当写入数据到外部数据库时,Flink 会使用 DDL 中定义的主键。如果定义了主键,则连接器将以 upsert 模式工作,否则连接器将以 append 模式工作
package cn.edu.tju.demo2;import org.apache.flink.streaming.api.environment.StreamExecutionE…
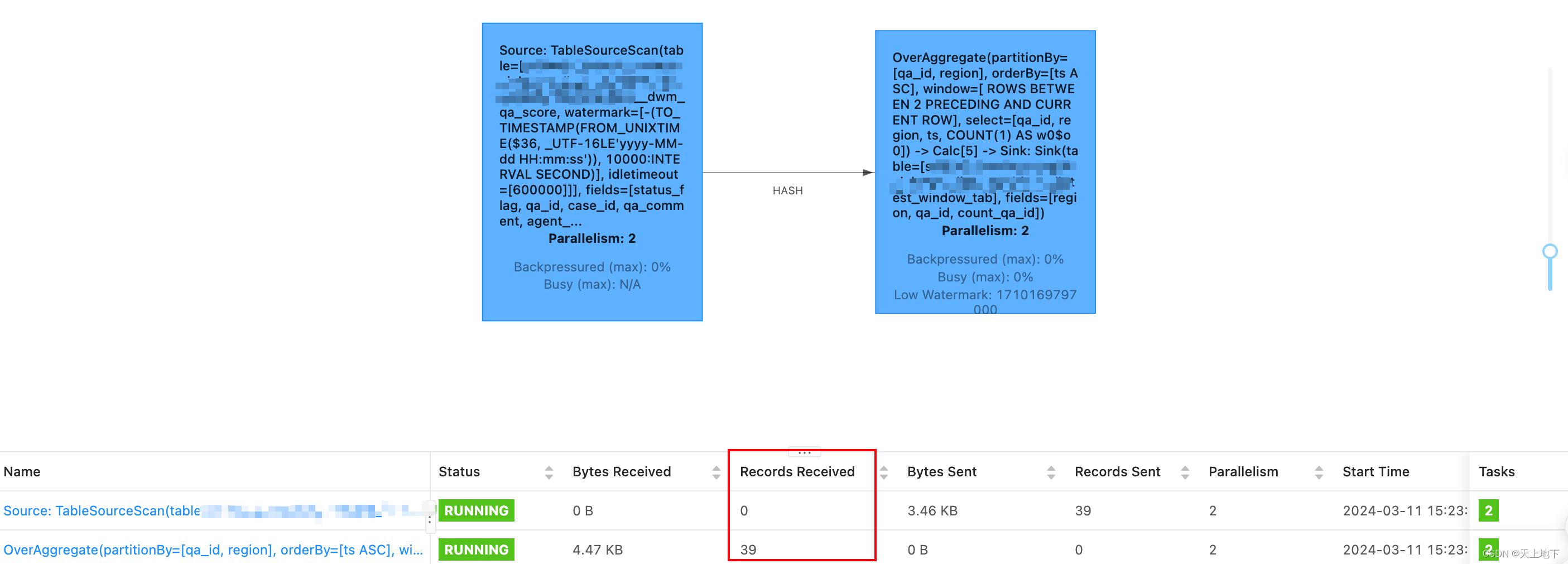
flink的分组聚合、over聚合、窗口聚合对比
【背景】
flink有几种聚合,使用上是有一些不同,需要加以区分:
分组聚合:group agg
over聚合:over agg
窗口聚合:window agg 省流版: 触发计算时机 结果流类型 状态大小 分组聚合group ag…
【flink】flink on yarn jar异常,类冲突:原因本地上传jar和hdfs的jar冲突
flink jar异常,类冲突可能原因:
报错如下
java.sql.SQLException: ERROR 2006 (INT08): Incompatible jars detected between client and server. Ensure that phoenix-[version]-server.jar is put on the classpath of HBase in every region server…
linux 单机部署flink1.13.5
1.下载flink安装包
https://archive.apache.org/dist/flink/flink-1.13.5/
2.上传到Linux
rz
3.解压安装包
tar -zxvf flink-1.13.5-bin-scala_2.11.tgz
4.进入conf目录
cd flink-1.13.5/conf
5.放开其他服务器访问权限 6.输入地址访问即可查看任务
http://IP:8081/
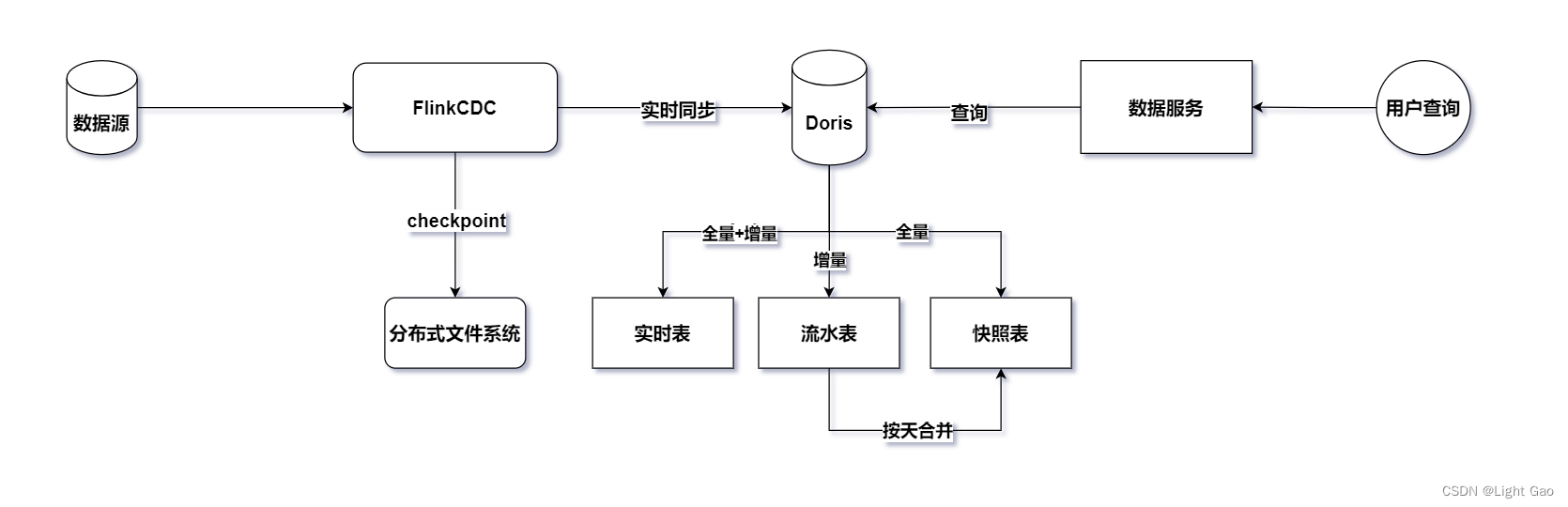
Flink实时数仓同步:实时表、流水表、快照表整合实战详解
一、背景
在大数据领域,数据分析、实时数仓已经成为平台上常见的功能之一。无论是进行实时分析还是离线分析,都离不开数仓中的表数据。
特别是在实时分析领域,查阅实时数据、历史数据以及历史变更数据是非常常见的需求。而这些功能的实现主…
flink重温笔记(十六): flinkSQL 顶层 API ——实时数据流结合外部系统
Flink学习笔记 前言:今天是学习 flink 的第 16 天啦!学习了 flinkSQL 与企业级常用外部系统结合,主要是解决大数据领域数据计算后,写入到文件,kafka,还是mysql等 sink 的问题,即数据计算完后保存…
【Flink SQL】Flink SQL 基础概念:SQL 动态表 连续查询
Flink SQL 基础概念:SQL 动态表 & 连续查询 1.SQL 应用于流处理的思路2.流批处理的异同点及将 SQL 应用于流处理核心解决的问题3.SQL 流处理的输入:输入流映射为 SQL 动态输入表4.SQL 流处理的计算:实时处理底层技术 - SQL 连续查询5.SQL…
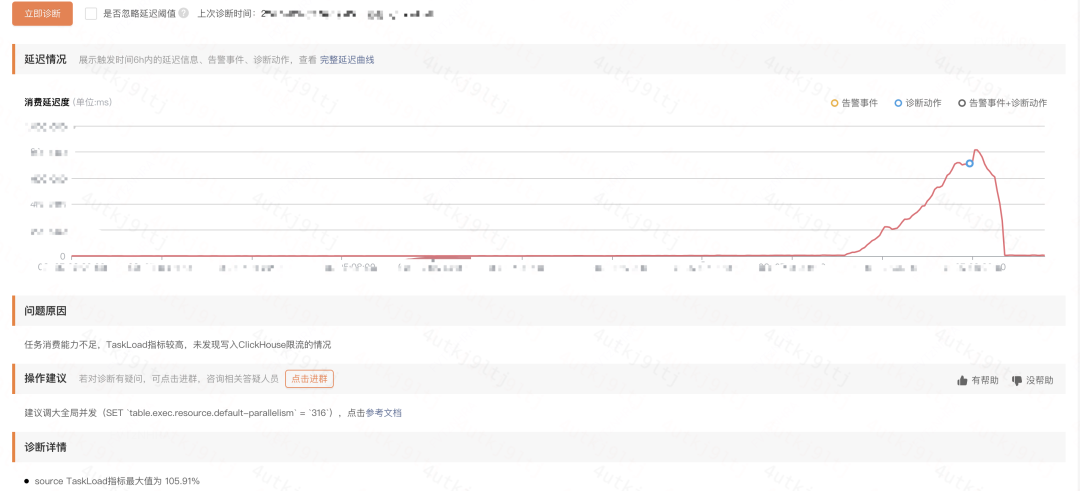
滴滴 Flink 指标系统的架构设计与实践
毫不夸张地说,Flink 指标是洞察 Flink 任务健康状况的关键工具,它们如同 Flink 任务的眼睛一般至关重要。简而言之,这些指标可以被理解为滴滴数据开发平台实时运维系统的数据图谱。在实时计算领域,Flink 指标扮演着举足轻重的角色…
[flink总结]什么是flink背压 ,有什么危害? 如何解决flink背压?flink如何保证端到端一致性?
1 Flink的背压(Backpressure)是指当下游算子处理数据的速度不及上游算子传递数据的速度时,会导致数据始终堆积在网络层或内存中,会导致系统效率下降,出现背压现象。
背压的危害: 系统性能下降:…
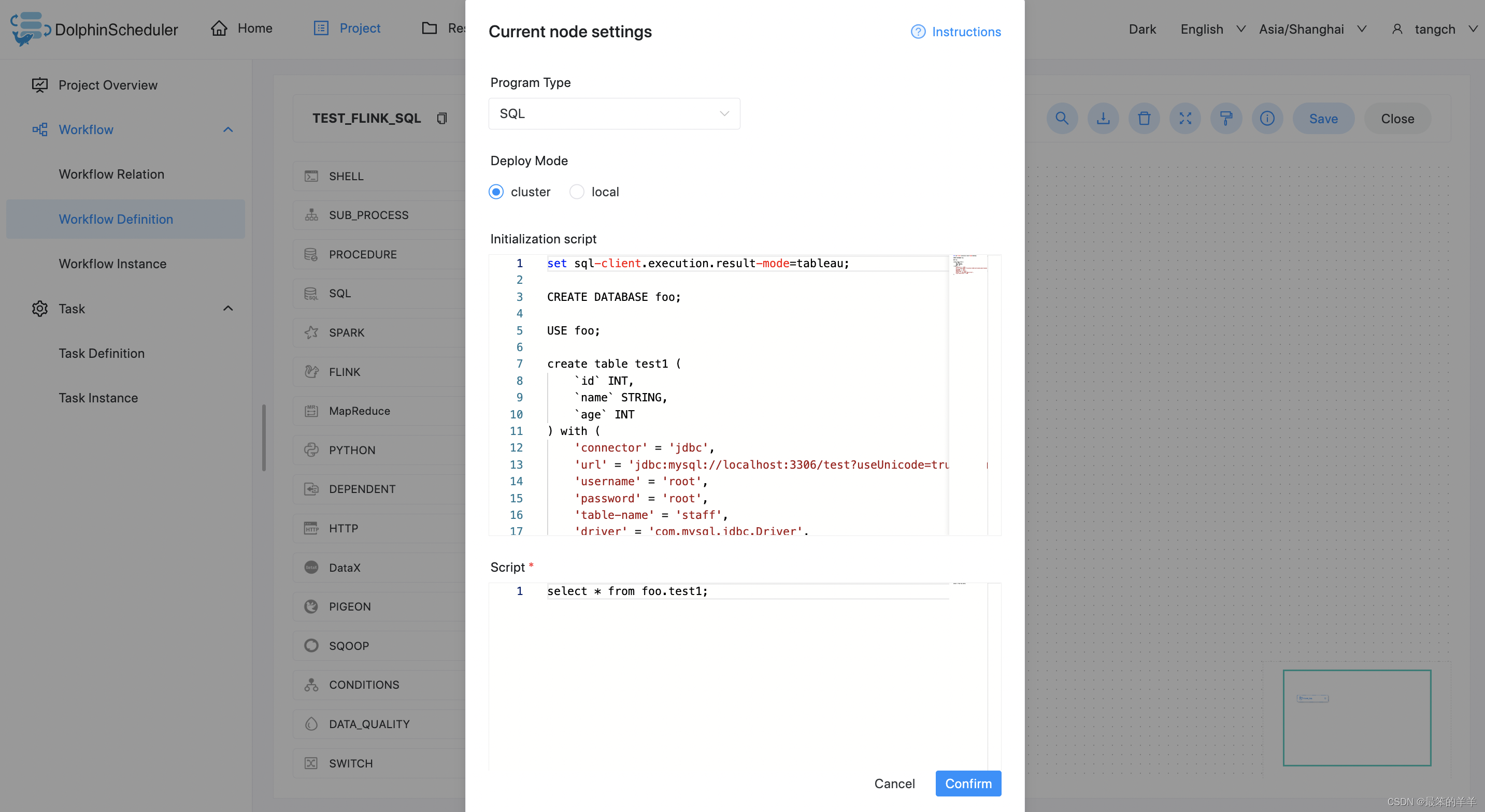
海豚调度系列之:任务类型——Flink节点
海豚调度系列之:任务类型——Flink节点 一、Flink节点二、创建任务三、任务参数四、任务样例1.在 DolphinScheduler 中配置 flink 环境2.任务流程 五、注意事项 一、Flink节点
Flink 任务类型,用于执行 Flink 程序。对于 Flink 节点:
当程序…
[2024年]-flink面试真题(四)
(上海) Flink与Spark有什么主要区别?(上海) 关于Flink的流处理和批处理,你了解多少?(上海) 你能解释一下Flink的架构吗?(上海) Flink是如何处理事件时间(Event Time)和处理时间(Processing Time…
【Flink SQL】Flink SQL 基础概念(四):SQL 的时间属性
《Flink SQL 基础概念》系列,共包含以下 5 篇文章:
Flink SQL 基础概念(一):SQL & Table 运行环境、基本概念及常用 APIFlink SQL 基础概念(二):数据类型Flink SQL 基础概念&am…
Apache Paimon 使用 Kafka CDC 获取数据
a.依赖准备
flink-sql-connector-kafka-*.jarb.支持的文件格式
Flink提供了几种Kafka CDC格式:Canal、Debezium、Ogg和Maxwell JSON。
如果Kafka的Topic中的消息是使用Change Data Capture(CDC)工具从另一个数据库捕获的change event&…
【Flink】Flink 中的时间和窗口之窗口API使用
1. 窗口的API概念
窗口的API使用分为按键分区和非按键分区,在定义窗口操作之前,首先就要确定好是基于按键分区Keyed的数据流KeyedStream来开窗还是基于没有按键分区的DataStream上开窗。
1.1 按键分区窗口(Keyed Windows)
按键…
flinksql在实时数仓hologres的计算问题排查
要排查 Flink 实时计算从 Hologres 源表到目标表的错误,可以采取以下步骤: 检查 Flink 程序逻辑: 确保 Flink 程序中源表到目标表的数据转换逻辑正确。检查是否正确地连接了源表和目标表,并且字段映射正确。检查 Hologres 连接: 确保 Flink 程序正确地连接到 Hologres 数据…
Flink Temporal Join 系列 (1):用 Temporal Table DDL 实现基于事件时间的关联
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
Flink:使用 Faker 和 DataGen 生成测试数据
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
flink重温笔记(十八): flinkSQL 顶层 API ——实时数据Table化(涵盖全面实用的 API )
Flink学习笔记 前言:今天是学习 flink 的第 18 天啦!很多小伙伴私信说,自己只会SQL语法来编写flinkSQL,如何使用代码来操作呢?因为工作中都是要用到代码编写的。还有小伙伴说,想要实现表是动态变化的&#…
Apache Paimon 使用 Postgres CDC 获取数据
a.依赖准备
flink-connector-postgres-cdc-*.jarb.Synchronizing Tables(同步表)
在Flink DataStream作业中使用 PostgresSyncTableAction 或直接通过flink run,可以将PostgreSQL中的一个或多个表同步到一个Paimon表中。
<FLINK_HOME&g…
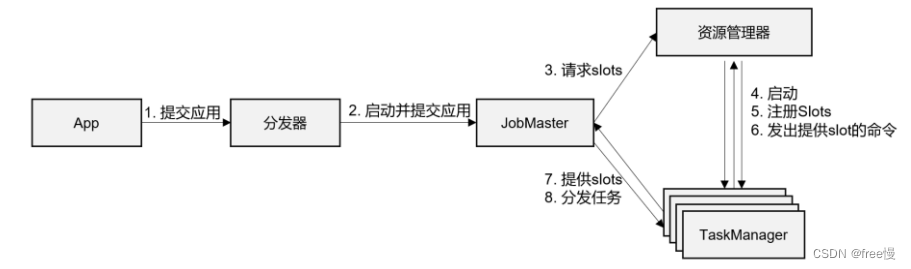
Flink中JobManager与TaskManage的运行架构以及原理详解
Flink中JobManager与TaskManage的运行架构详解
整体架构 Flink的运行时架构中,最重要的就是两大组件:作业管理器(JobManger)和任务管理器(TaskManager)。对于一个提交执行的作业,JobManager是真…

官宣|Apache Flink 1.19 发布公告
Apache Flink PMC(项目管理委员)很高兴地宣布发布 Apache Flink 1.19.0。与往常一样,这是一个充实的版本,包含了广泛的改进和新功能。总共有 162 人为此版本做出了贡献,完成了 33 个 FLIPs、解决了 600 多个问题。感谢…
flink启动错误(使用YARN)
##flink启动错误信息 Executor found. Please make sure to export the HADOOP_CLASSPATH environment
##需要手动添加HADOOP_CLASSPATH: vim /etc/profile export HADOOP_HOME“/opt/cloudera/parcels/CDH/lib/hadoop” export PATH P A T H : PATH: PATH:HADOOP_…
Flink CDC 1.18.1 Oracle 数据同步到postgresql
1、下载flink-1.18.1-bin-scala_2.12.tgz,linux通过: wget https://archive.apache.org/dist/flink/flink-1.18.1/flink-1.18.1-bin-scala_2.12.tgz
2、oracle11g客户端安装,下载:
instantclient-basic-linux.x64-11.2.0.4.0.zi…
初探Flink集群【持续更新】
周末下雨,倒杯茶,在家练习Flink相关。 开发工具:IntelliJ Idea
第一步、创建项目
打开Idea,新建Maven项目,包和项目命名 在pom.xml 文件中添加依赖
<properties><flink.version>1.13.0</flink.vers…
在Flink SQL中使用watermark进阶功能
摘自官网
在Flink SQL中使用watermark进阶功能
在Flink1.18中对Watermark的很多进阶功能(比如watermark对齐)通过datastream api很容易使用。在sql中使用不是很方便,在Flink1.18中对这些功能进行扩展。在sql中也能使用这些功能。
只有实现…

【phoenix】flink程序执行phoenix,phoenix和flink-sql-connector-hbase包类不兼容
问题报错
Caused by: java.lang.RuntimeException: java.lang.RuntimeException: class org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.ClusterStatusListener$MulticastListener not org.apache.hadoop.hbase.client.ClusterStatusListener$Listener如下图&…

Flink RocksDB状态后端优化总结
截至当前,Flink 作业的状态后端仍然只有 Memory、FileSystem 和 RocksDB 三种可选,且 RocksDB 是状态数据量较大(GB 到 TB 级别)时的唯一选择。RocksDB 的性能发挥非常仰赖调优,如果全部采用默认配置,读写性…
Apache Flink 中 Watermark 机制详解及其核心原理与应用示例
Watermark(水印)概念
在 Apache Flink 流处理框架中,Watermark 是一个关键的时间概念,用于处理事件时间窗口(event-time processing)中的乱序事件问题。事件时间是指事件本身携带的时间戳,而非…
flink自定义函数如何从崩溃中恢复数据
背景
flink 提供的标准算子已经实现了可以从之前的checkpoint中恢复数据
思考
程序开发中,通常会自定义函数和计算指标,比较复杂
实现
通常情况下实现 CheckpointedFunction 这个接口即可
统计词频的小例子
public class SumTestProcessFunction extends ProcessFunct…
FlinkSQL之保序任务对于聚合SQL影响分析
本文以一个示例说明FlinkSQL如何针对上游乱序数据源设计保序任务,从而保证下游数据准确性。废话不多说,这里以交易数据场景为例. 数据表结构为: create table tbl_order_source(order_id int comment 订单ID,shop_…
Flink Temporal Join 系列 (2):用 Temporal Table DDL 实现基于处理时间的关联
本文要演示的是:使用 Temporal Table DDL 定义被关联表(维表),然后基于主动关联表(事实表)的“处理时间”去进行Temporal Join(关联时间维度上对应版本的维表数据)。该演示涉及三个要点: 被关联的表(维表)是用 Temporal Table DDL 形式定义,必须是一张时态表(版本…
FlinkSQL之保序任务对于Join SQL影响分析
本文以一个示例说明FlinkSQL如何针对上游乱序数据源设计保序任务,从而保证下游数据准确性。废话不多说,这里以交易数据场景为例. 数据表结构为: -- 订单表结构
create table tbl_order_source(order_id int comme…
Flink:Lookup Join 实现与示例代码
本文要演示的是:在流上关联一张外部表(例如 MySQL 数据库中的一张维表),用于丰富流上的数据,实际上,这正是最普遍的 ”维表 Join“ 的实现方式。通过这种方式和外部维表关联时,依然能关联到最新…

Flink实战之FlinkSQL键设计对于数据保序的必要性
乱序数据处理对于实时ETL至关重要,处理不好将会导致数据不一致场景发生。对于数据乱序场景,一般工程师已知上游数据乱序会对本身消费数据产生影响,但不一定晓得的是,一个SQL本身也可能造成数据乱序,严格意义上的数据乱…
![[实时流基础 flink] 窗口](https://img-blog.csdnimg.cn/img_convert/bf88acf050deddebb5a9b9b8ea8de090.png)
[实时流基础 flink] 窗口
在批处理统计中,我们可以等待一批数据都到齐后,统一处理。但是在实时处理统计中,我们是来一条就得处理一条,那么我们怎么统计最近一段时间内的数据呢?引入“窗口”。 文章目录 6.1 窗口的概念6.2 窗口的分类**1&#x…
Apache Flink:实时流处理与批处理的统一框架
导语 在大数据处理领域,流处理和批处理是两种主要的处理方式。然而,传统的系统通常将这两者视为独立的任务,需要不同的工具和框架来处理。Apache Flink是一个开源的流处理框架,它打破了这种界限,提供了一个统一的平台来…
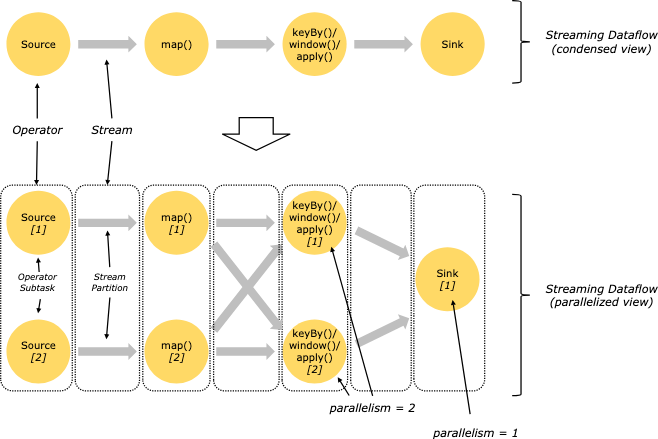
Flink学习(二)-基础概念
一、流处理
分为有界流(bounded stream)和无界流(unbounded stream)。 通过上图 ,可以知道,
有界流:有明显的边界;而无界流,则只有开始,没有结束。 批处理是…
CentOS7安装Flink1.17伪分布式
前提条件
拥有1台CentOS7
CentOS7安装好jdk,官方文档要求java 11,使用java 8也可以。可参考 CentOS7安装jdk8 下载安装包 下载安装包
[hadoopnode1 ~]$ cd installfile/
[hadoopnode1 installfile]$ wget https://archive.apache.org/dist/flink/flin…
Flink实现两阶段提交协议原理介绍
Apache Flink 是一个流式处理引擎,它支持事件驱动的、分布式的大规模数据处理。在 Flink 中,两阶段提交(Two-Phase Commit,简称 2PC)用于保证 Flink 作业的 Exactly-Once 语义,即保证在面对故障时ÿ…
CentOS7安装flink1.17完全分布式
前提条件
准备三台CenOS7机器,主机名称,例如:node2,node3,node4
三台机器安装好jdk8,通常情况下,flink需要结合hadoop处理大数据问题,建议先安装hadoop,可参考 hadoop安…

Flink 流批一体在模型特征场景的使用
摘要:本文整理自B站资深开发工程师张杨老师在 Flink Forward Asia 2023 中 AI 特征工程专场的分享。内容主要为以下四部分: 模型特征场景流批一体性能优化未来展望 一、 模型特征场景
以下是一个非常简化并且典型的线上实时特征和样本的生产过程。 前面…
flink1.18源码本地调试环境
01 源码本地调试环境搭建
1. 从github拉取源码创建本地项⽬ https://github.com/apache/flink.git 可以拉取github上官⽅代码 https://github.com/apache/flink.git GitHub - apache/flink: Apache Flink 2. 配置编译环境 ctrlaltshifts (或菜单)打…
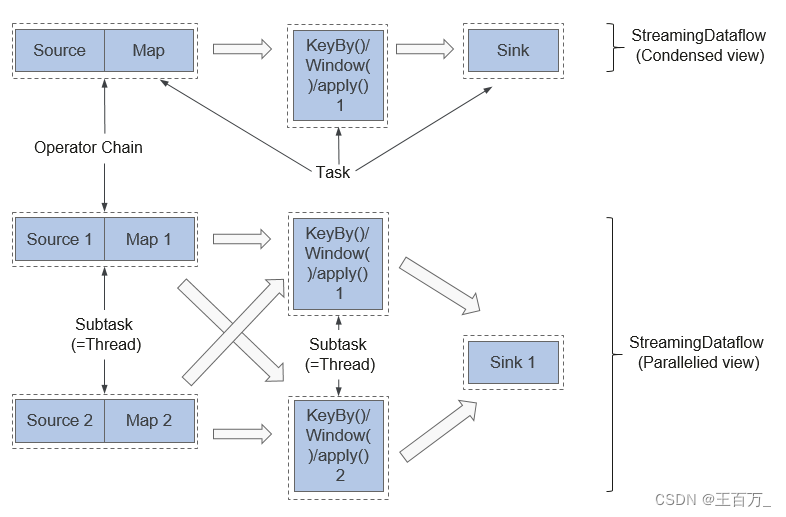
【Flink技术原理构造及特性】
1、Flink简介
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。
Flink最适合的应用场景是低时延的数据处理(Data Processin…
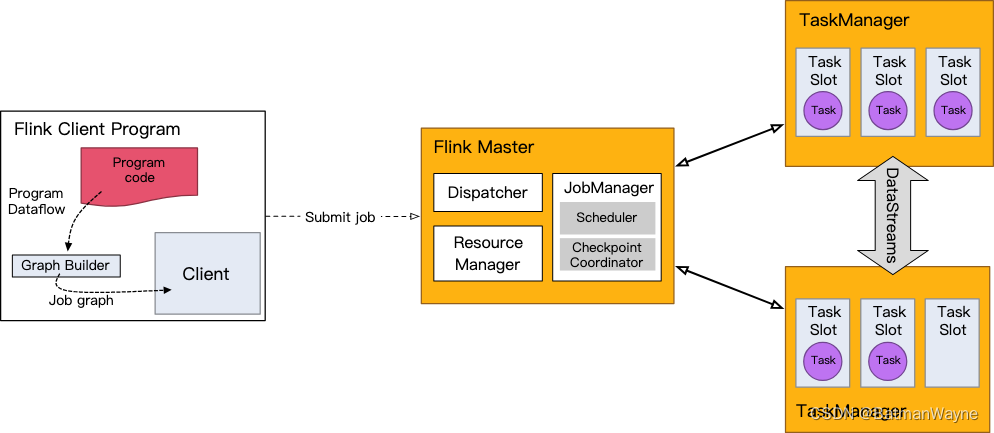
FLink学习(三)-DataStream
一、DataStream
1,支持序列化的类型有
基本类型,即 String、Long、Integer、Boolean、Array复合类型:Tuples、POJOs 和 Scala case classes
Tuples
Flink 自带有 Tuple0 到 Tuple25 类型
Tuple2<String, Integer> person Tuple2.…
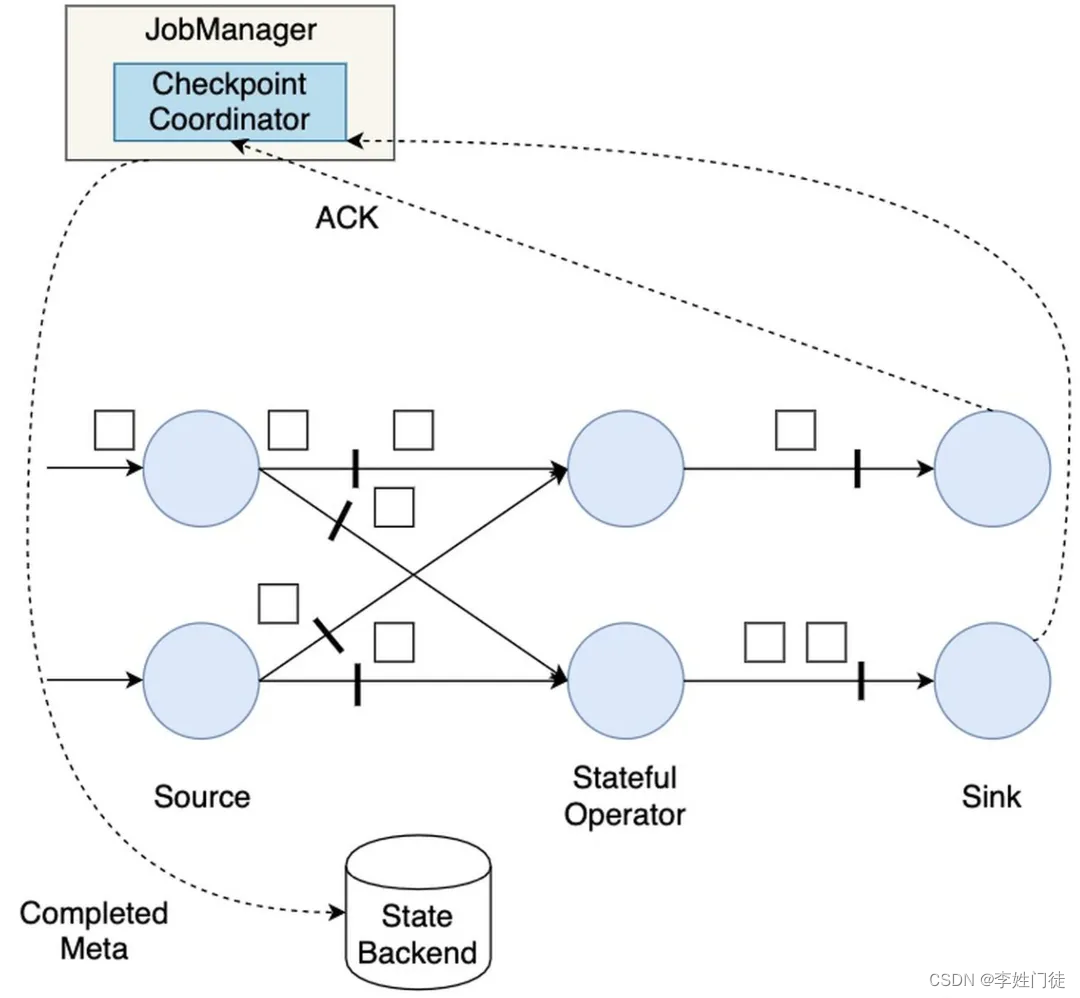
Flink运行机制相关概念介绍
Flink运行机制相关概念介绍 1. 流式计算和批处理2. 流式计算的状态与容错3. Flink简介及其在业务系统中的位置4. Flink模型5. Flink的架构6. Flink的重要概念7. Flink的状态、状态分区、状态缩放(rescale)和Key Group8. Flink数据交换9. 时间语义10. 水位…
【Flink实战系列】Flink 双流 Join 出现数据倾斜如何解决?
【Flink实战系列】Flink 双流 Join 出现数据倾斜如何解决?
在 Flink 里面常见的数据倾斜有两种 计算场景Join 场景第一种计算场景,比如我们常说的 WordCount 计算,这种问题可以参考这篇文章,Flink发生数据倾斜怎么优化任务?(两段聚合的方式)
第二种 Join 场景,是我们今…
flink源码编译-job提交
1、启动standalone集群的taskmanager
standalone集群中的taskmanager启动类为 TaskManagerRunner 2 打开master启动类 通过 ctrln快捷键,找到、并打开类: org.apache.flink.runtime.taskexecutor.TaskManagerRunner 3 修改运⾏配置 基本完全按照mas…
Spark, Storm, Flink简介
目录 1.Spark VS Storm2.Storm VS Flink 本文主要介绍Spark, Storm, Flink的区别。
1.Spark VS Storm
Spark和Storm都是大数据处理框架,但它们在设计理念和使用场景上有一些区别:
实时性:Storm是一个实时计算框架,适合需要实时…
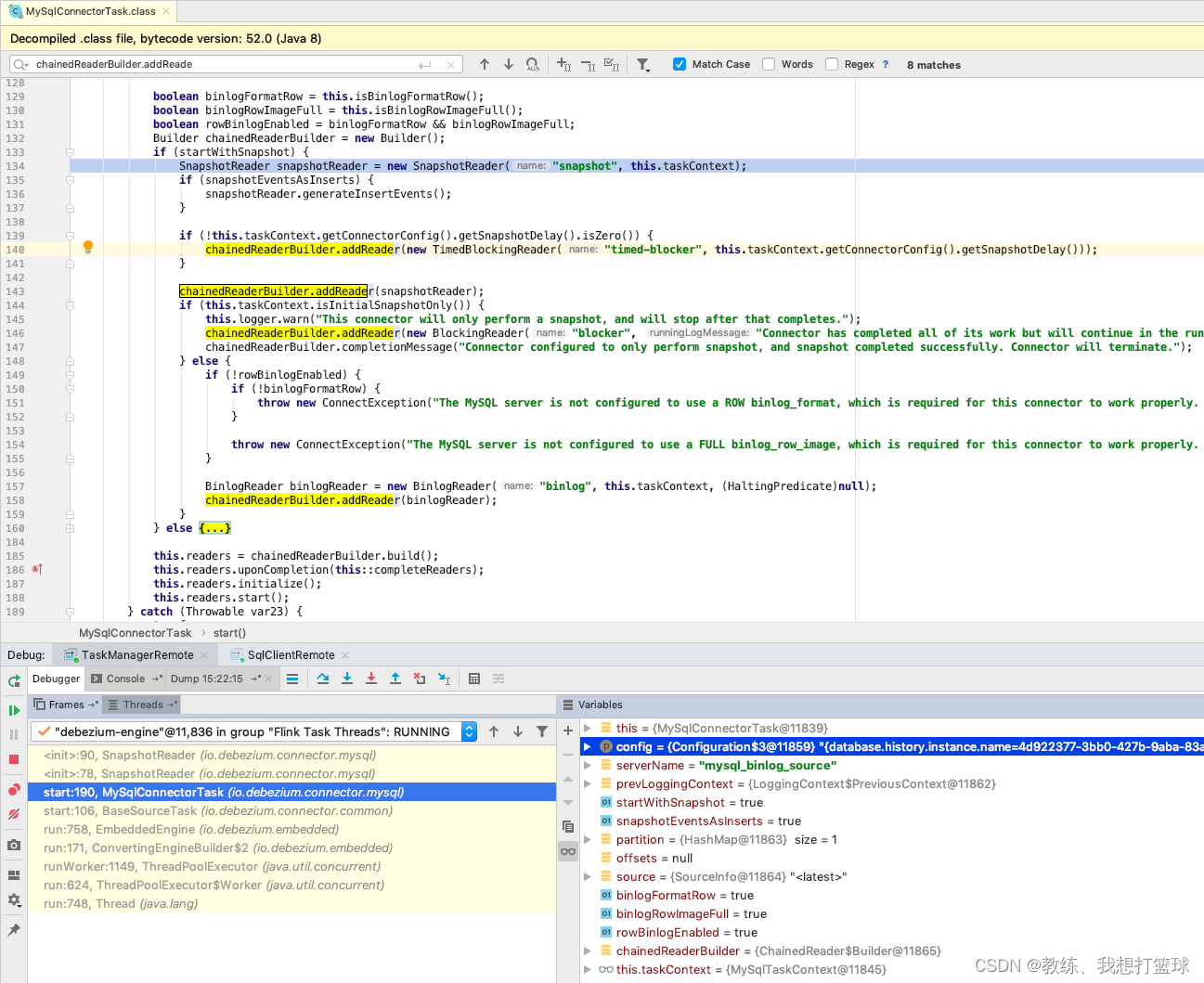
09 flink-sql 中基于 mysql-cdc 的 select * from test_user 的具体实现
前言
这也是最近帮一个朋友看问题 遇到的一个问题
然后 引发了一下 对于 flink-sql 里面的一些 常规处理的思考, 理解
原始问题主要是 在测试库可以使用 flink-sql 可以正常同步, 但是 在生产环境 无法正常同步数据
这个问题 我们后面单独 记录一篇文章 测试用例
下载…
![[实时流基础 flink] 窗口函数](https://img-blog.csdnimg.cn/img_convert/66ccb6e366cf65bc2520f423b90c91c4.png)
[实时流基础 flink] 窗口函数
尚硅谷学习笔记 6.5 窗口函数 增量聚合函数(ReduceFunction / AggregateFunction)
窗口将数据收集起来,最基本的处理操作当然就是进行聚合。我们可以每来一个数据就在之前结果上聚合一次,这就是“增量聚合”。 典型的增量聚合函数…
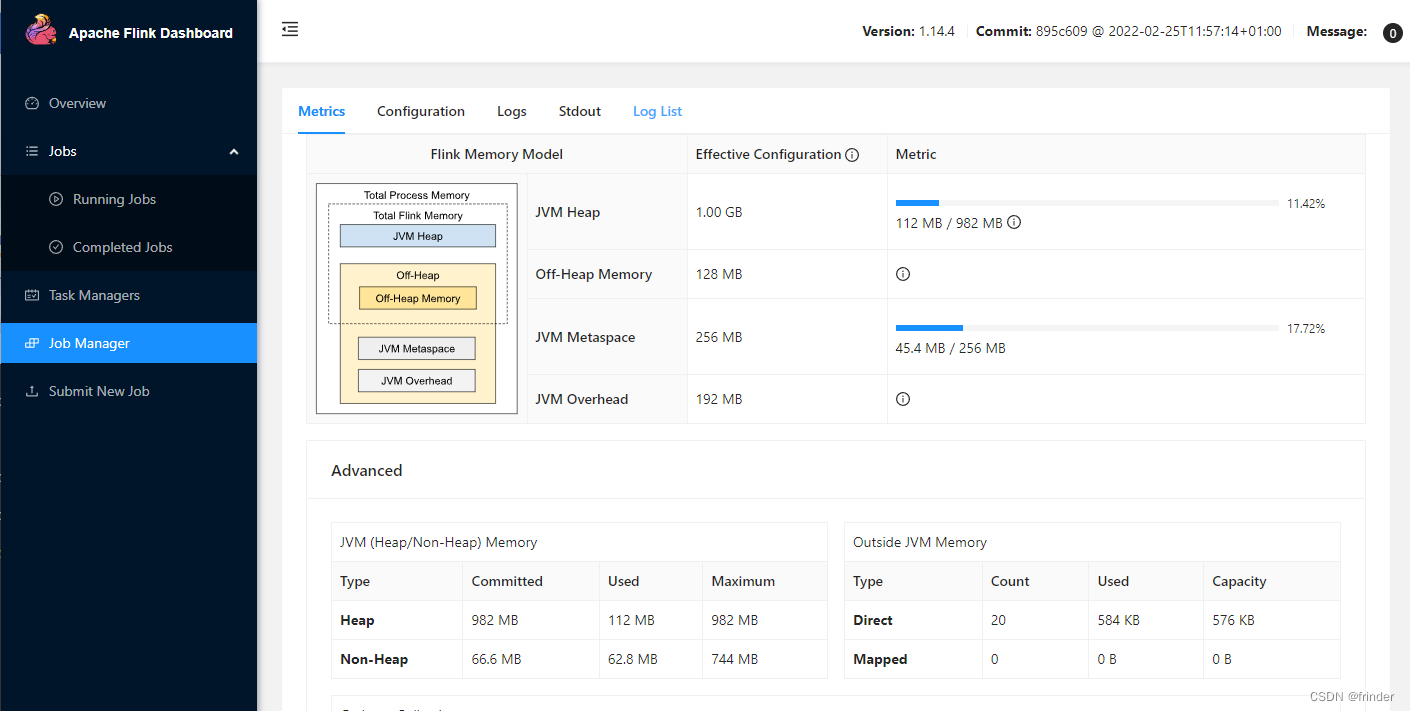
Windows下Docker搭建Flink集群
编写docker-compose.yml
参照:https://github.com/docker-flink/examples/blob/master/docker-compose.yml version: "2.1"
services:jobmanager:image: flink:1.14.4-scala_2.11expose:- "6123"ports:- "18081:8081"command: jobma…
实时数仓之实时数仓架构(Doris)
目前比较流行的实时数仓架构有两类,其中一类是以Flink+Doris为核心的实时数仓架构方案;另一类是以湖仓一体架构为核心的实时数仓架构方案。本文针对Flink+Doris架构进行介绍,这套架构的特点是组件涉及相对较少,架构简单,实时性更高,且易于Lambda架构实现,Doris本身可以支…

再谈 Flink 的 “动态表” 和 “流表二象性”
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
Flink WordCount实践
目录
前提条件
基本准备
批处理API实现WordCount
流处理API实现WordCount
数据源是文件
数据源是socket文本流
打包
提交到集群运行
命令行提交作业
Web UI提交作业
上传代码到gitee 前提条件
Windows安装好jdk8、Maven3、IDEA
Linux安装好Flink集群,可…
[尚硅谷flink学习笔记] 实战案例TopN 问题
实时统计一段时间内的出现次数最多的水位。* 例如,统计最近10秒钟内出现次数最多的两个水位,并且每5秒钟更新一次。* 我们知道,这可以用一个滑动窗口来实现。于是就需要开滑动窗口收集传感器的数据,按照不同的水位进行统计&#x…
Flink Get Start MVN 命令执行报错
执行新建工程命令后报错:
mvn archetype:generate \-DarchetypeGroupIdorg.apache.flink \-DarchetypeArtifactIdflink-quickstart-java \-DarchetypeVersion1.19.0org.apache.maven.lifecycle.MissingProjectException:
The goal you specified…

Flink常见面试问题(附答案)
目录 基础篇1. 什么是Apache Flink?2. Flink与Hadoop的区别是什么?3. Flink中的事件时间(Event Time)和处理时间(Processing Time)有什么区别?4. Flink的容错机制是如何实现的?5. 什…
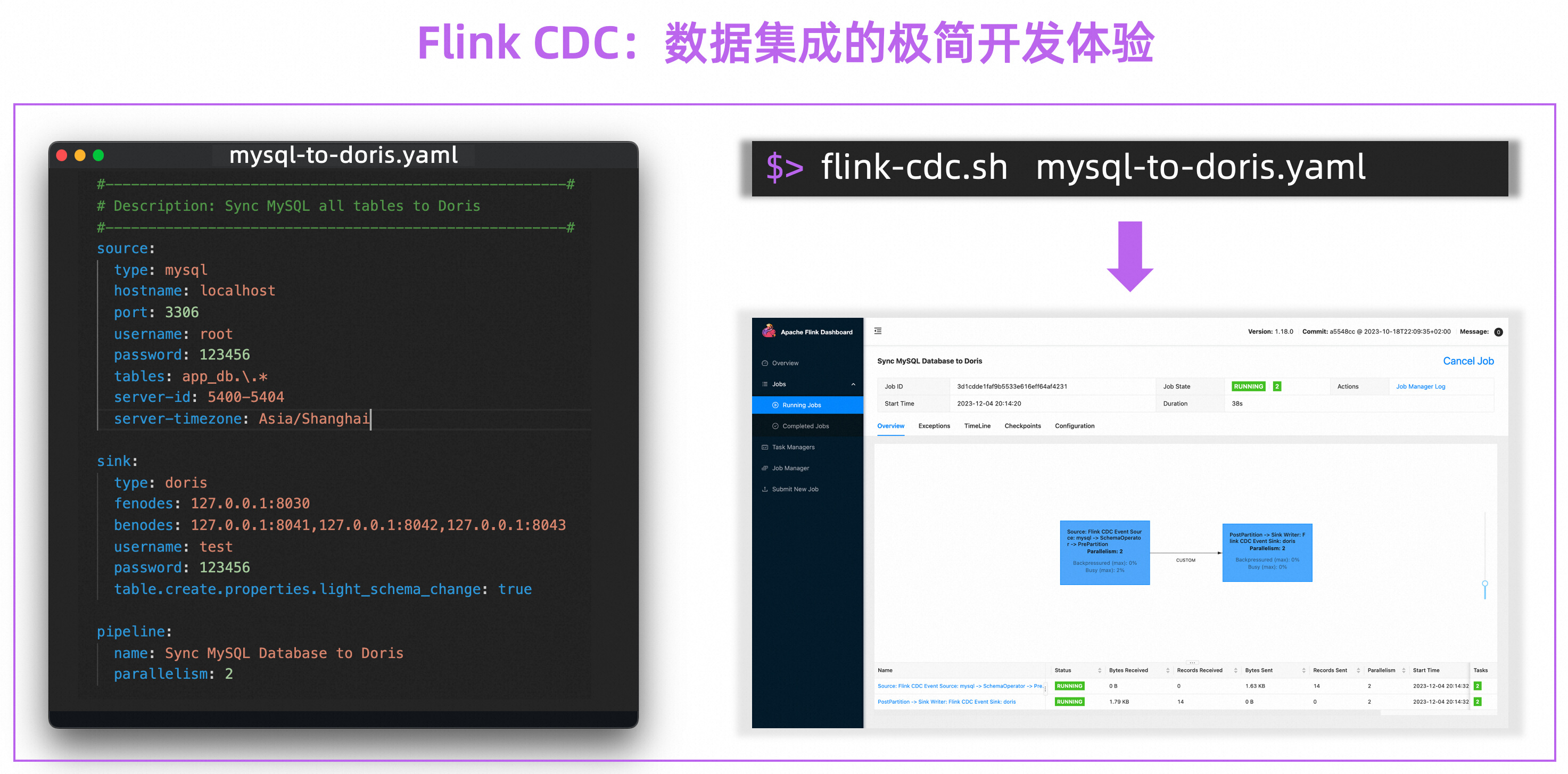
官宣|阿里巴巴捐赠的 Flink CDC 项目正式加入 Apache 基金会
摘要:本文整理自阿里云开源大数据平台徐榜江 (雪尽),关于阿里巴巴捐赠的 Flink CDC 项目正式加入 Apache 基金会,内容主要分为以下四部分: 1、Flink CDC 新仓库,新流程 2、Flink CDC 新定位,新玩法 3、Flin…
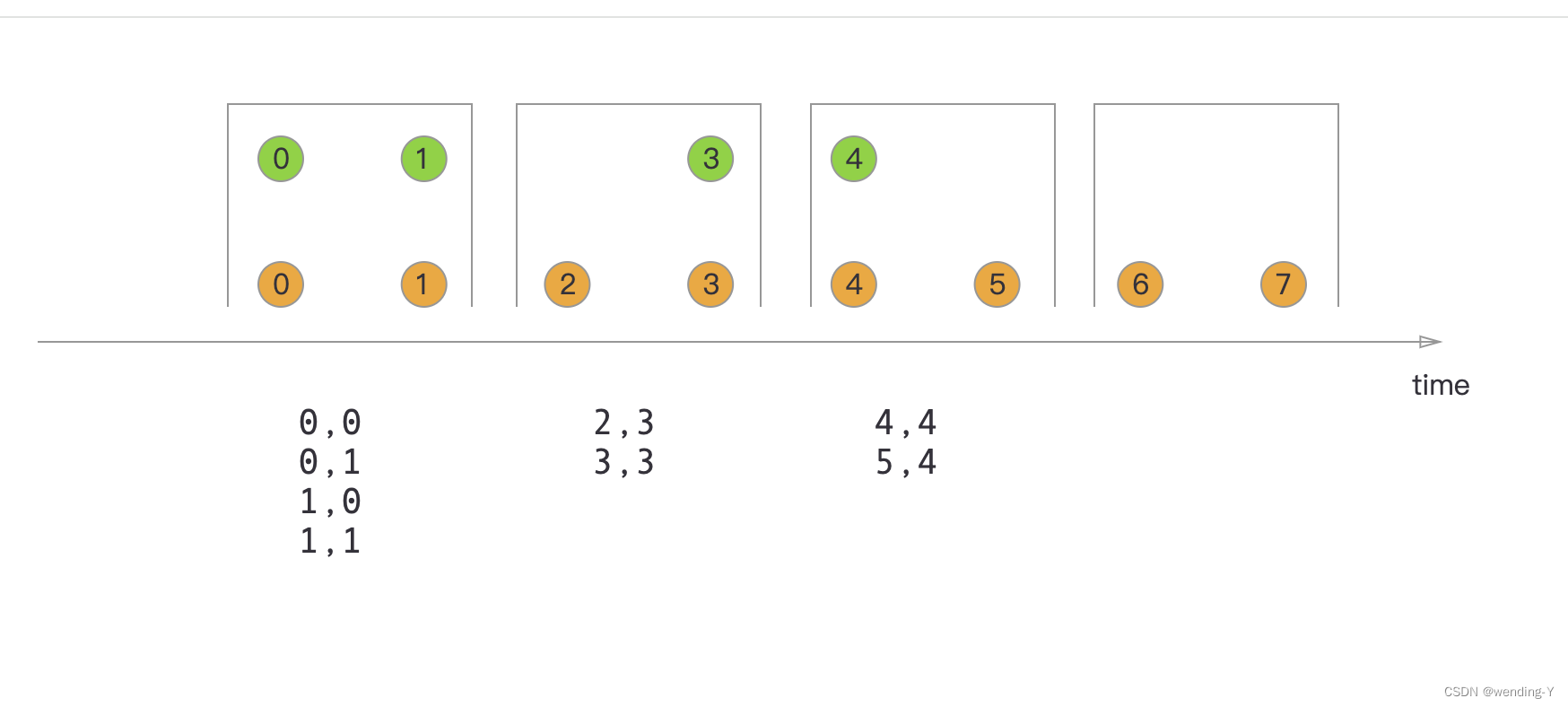
flink join的分类
带窗口的join
下图是固定窗口,同样的还有滑动窗口和会话窗口join DataStream<Integer> orangeStream = ...;
DataStream<Integer> greenStream = .
Flink Temporal Join 系列 (3):用 Temporal Table Function 实现基于事件时间的关联
本文要演示的是:使用 Temporal Table Function 定义被关联表(维表),然后基于主动关联表(事实表)的“事件时间”去进行Temporal Join(关联时间维度上对应版本的维表数据)。
本文实现的效果与《Flink Temporal Join 系列 (1):用 Temporal Table DDL 实现基于事件时间的…
java Flink(四十二)Flink的序列化以及TypeInformation介绍(源码分析)
Flink的TypeInformation以及序列化
TypeInformation主要作用是为了在 Flink系统内有效地对数据结构类型进行管理,能够在分布式计算过程中对数据的类型进行管理和推断。同时基于对数据的类型信息管理,Flink内部对数据存储也进行了相应的性能优化。
Flin…
Flink 架构深度解析
## 1. 引言
在当今的数据驱动世界中,实时数据处理变得越来越重要。Flink 提供了一个高性能、可扩展的平台,用于构建实时数据分析和处理应用。它支持事件时间处理和精确一次(exactly-once)处理语义,确保数据的准确性和…
java Flink(四十三)Flink Interval Join源码解析以及简单实例
背景
之前我们在一片文章里简单介绍过Flink的多流合并算子
java Flink(三十六)Flink多流合并算子UNION、CONNECT、CoGroup、Join
今天我们通过Flink 1.14的源码对Flink的Interval Join进行深入的理解。
Interval Join不是两个窗口做关联,…
Flink1.18 如何配置算子级别的TTL
1. 解释
从 Flink 1.18 开始,Table API & SQL 支持配置细粒度的状态 TTL 来优化状态使用,可配置粒度为每个状态算子的入边数。具体而言,OneInputStreamOperator 可以配置一个状态的 TTL,而 TwoInputStreamOperator࿰…
【Flink】Flink 中的时间和窗口之窗口其他API的使用
1. 窗口的其他API简介
对于一个窗口算子而言,窗口分配器和窗口函数是必不可少的。除此之外,Flink 还提供了其他一些可选的 API,可以更加灵活地控制窗口行为。
1.1 触发器(Trigger)
触发器主要是用来控制窗口什么时候…
FlinkSQL之Flink SQL Join二三事
Flink SQL支持对动态表进行复杂而灵活的连接操作。 为了处理不同的场景,需要多种查询语义,因此有几种不同类型的 Join。默认情况下,joins 的顺序是没有优化的。表的 join 顺序是在 FROM 从句指定的。可以通过把更新频率最低的表放在第一个…
使用 Flink + Faker Connector 生成测试数据压测 MySQL
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
Flink-CDC 无法增量抽取SQLServer数据
1.问题
因部署在WindowsServer服务器SQLServer发生过期后重启,Flink-CDC同步进行作业重启,启动后无报错信息,数据正常抽取。但是观察几天后发现当天数据计算指标无法展示
2.定位
因为没用进行任何修改,故初步判断不是因Flink-C…
Flink基于Hudi维表Join缺陷解析及解决方案
Hudi,这个近年来备受瞩目的数据存储解决方案,无疑是大数据领域的一颗耀眼新星。其凭借出色的性能和稳定性,以及对于数据湖场景的深度适配,赢得了众多企业和开发者的青睐。然而,正如任何一项新兴技术,Hudi在…
阿里云CentOS7安装Flink1.17
前提条件
阿里云CentOS7安装好jdk,官方文档要求java 11,使用java 8也可以。可参 hadoop安装 的jdk安装部分。 下载安装包
下载安装包
[hadoopnode1 ~]$ cd softinstall/
[hadoopnode1 softinstall]$ wget https://archive.apache.org/dist/flink/flin…
Flink 中 Slot 机制详解:概念、原理与开发实践
Flink Slot 概念
在 Apache Flink 中,Slot 是 TaskManager 中资源分配的基本单位,代表着 TaskManager 的一部分计算资源,主要包括 CPU、内存以及其他可能的资源(如磁盘空间、网络带宽等)。每个 TaskManager 可以划分为…
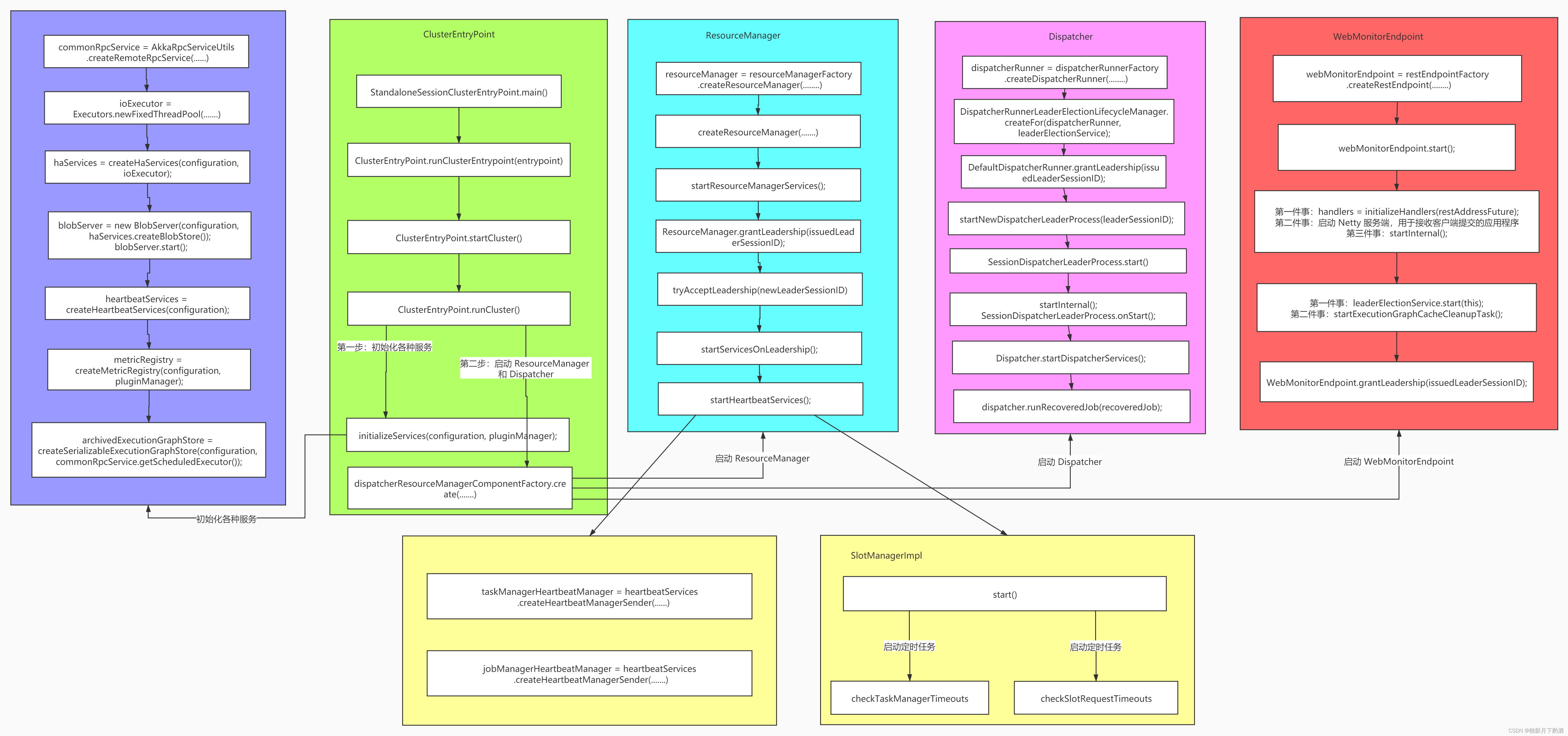
Flink集群主节点JobManager启动分析
1.概述 JobManager 是 Flink 集群的主节点,它包含三大重要的组件:
ResourceManager Flink集群的资源管理器,负责slot的管理和申请工作。 Dispatcher 负责接收客户端提交的 JobGraph,随后启动一个Jobmanager,类似 Yarn…

阿里云实时计算Flink的产品化思考与实践【下】
摘要:本文整理自阿里云高级产品专家黄鹏程和阿里云技术专家陈婧敏在 FFA 2023 平台建设专场中的分享。内容主要为以下五部分: 阿里云实时计算 Flink 产品化思考 产品化实践 SQL 产品化思考及实践 展望 接上篇:阿里云实时计算Flink的产品…
flink: 将接收到的tcp文本流写入HBase
一、依赖:
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.o…
![[flink 实时流基础]源算子和转换算子](https://img-blog.csdnimg.cn/img_convert/b6b3026c6ba5c3c64079df5c81888e22.png)
[flink 实时流基础]源算子和转换算子
文章目录 1. 源算子 Source1. 从集合读2. 从文件读取3. 从 socket 读取4. 从 kafka 读取5. 从数据生成器读取数据 2. 转换算子基本转换算子(map/ filter/ flatMap) 1. 源算子 Source
Flink可以从各种来源获取数据,然后构建DataStream进行转换…
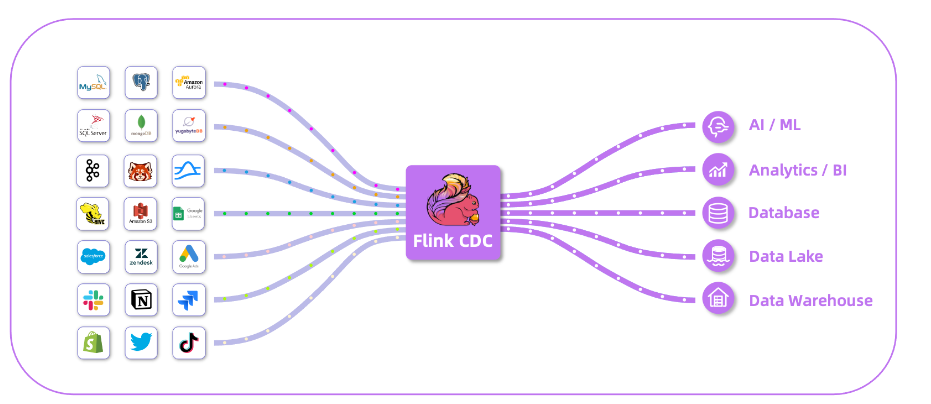
Flink CDC 同步数据到Doris
Flink CDC 同步数据到Doris
Flink CDC 是基于数据库日志 CDC(Change Data Capture)技术的实时数据集成框架,支持了全增量一体化、无锁读取、并行读取、表结构变更自动同步、分布式架构等高级特性。配合 Flink 优秀的管道能力和丰富的上下游生态,Flink CDC 可以高效实现海量…
Flink中流式的各种聚合
11.1 MiniBatch 聚合
针对无界聚合算子,说简单点就是把一组输入的数据放到缓存里,减少吞吐的开销 默认情况下,对于无界聚合算子来说,mini-batch 优化是被禁用的。开启这项优化,需要设置选项
TableConfig configurat…
Flink 中 Task(任务)的概念、定位及应用详解与易混淆点梳理
在 Apache Flink 中,Task(任务)扮演着核心的角色,它是分布式流处理和批处理作业执行的基本单位。以下是关于 Flink 中 Task 概念的详细说明以及定位与应用的相关内容,同时也会指出一些易混淆之处。
Task(任…
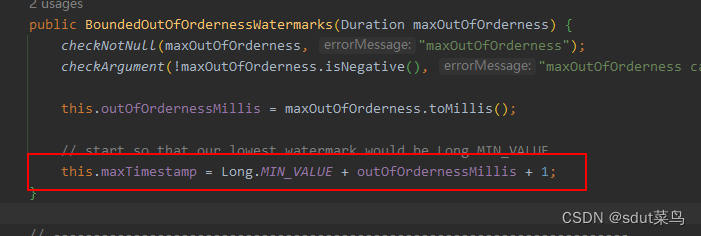
【Flink】Flink 处理函数之基本处理函数(一)
1. 处理函数介绍
流处理API,无论是基本的转换、聚合、还是复杂的窗口操作,都是基于DataStream进行转换的,所以统称为DataStreamAPI,这是Flink编程的核心。
但其实Flink为了更强大的表现力和易用性,Flink本身提供了多…

【Flink】窗口实战:TUMBLE、HOP、SESSION
窗口实战:TUMBLE、HOP、SESSION 1.TUMBLE WINDOW1.1 语法1.2 标识函数1.3 模拟用例 2.HOP WINDOW2.1 语法2.2 标识函数2.3 模拟用例 3.SESSION WINDOW3.1 语法3.2 标识函数3.3 模拟用例 4.更多说明 在流式计算中,流通常是无穷无尽的,我们无法…
Flink SQL填坑记3:两个kafka数据关联查询
在一个项目中,实时生成的统计数据需要关联另外一张表(并非维表),需要统计的数据表是Kafka数据,而需要关联的表,由于不是维度,不能按照主键查询,所以如果放在MySQL上,将存在严重的性能问题,这个时候我想到用将两张表的数据都生成为Kafka数据,然后进行Join操作。中途发…
【Flink connector】文件系统 SQL 连接器:实时写文件系统以及(kafka到hive)实战举例
文章目录 一. 滚动策略:sink后文件切分(暂不关注)1. 切分分区目录下的文件2. 小文件合并 二. 分区提交1. 分区提交触发器 (什么时候创建分区)1.1. 逻辑说明1.2. 举例说明 2. 分区时间提取器 (由分区字段来写分区名)2.1. 逻辑说明2.2. 举例说明…
【Flink实战】Flink hint更灵活、更细粒度的设置Flink sql行为与简化hive连接器参数设置
文章目录 一. create table hints1. 语法2. 示例3. 注意 二. 实战:简化hive连接器参数设置三. select hints(ing) SQL 提示(SQL Hints)是和 SQL 语句一起使用来改变执行计划的。本章介绍如何使用 SQL 提示来实现各种干预。
SQL 提示一般可以…

【大数据】Flink学习笔记
认识Flink Docker安装Flink
version: "2.1"
services:jobmanager:image: flinkexpose:- "6123"ports:- "20010:8081"command: jobmanagerenvironment:- JOB_MANAGER_RPC_ADDRESSjobmanagertaskmanager:image: flinkexpose:- "6121"- …
Flink 学习资料
今天就不发帖子啦,今天发现一个好东西啊,喜欢Flink的同学赶紧学习起来啊!!!!!! 课程网页链接:
GitHub - flink-china/flink-training-course: Flink 中文视频课程&#…
hive 、spark 、flink之想一想
hive 、spark 、flink之想一想
hive
1:hive是怎么产生的?
Hive是由Facebook开发的,目的是让拥有SQL知识的分析师能够在Hadoop上进行数据查询。Hive提供了类SQL的查询语言HiveQL,通过将HiveQL查询转换为MapReduce任务来在Hadoop…
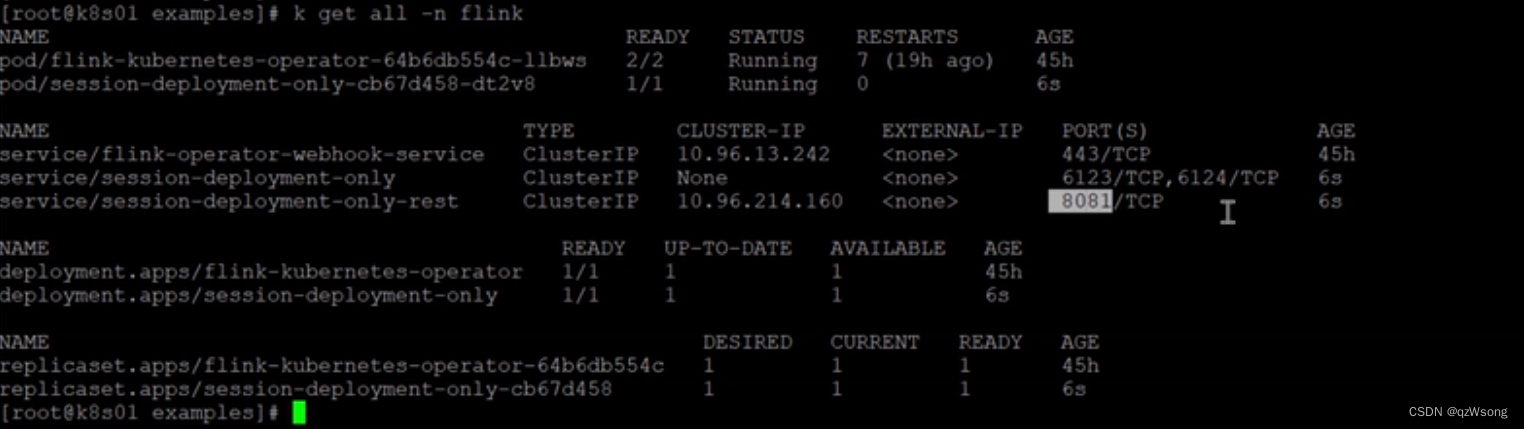
Flink on Kubernetes (flink-operator) 部署Flink
flink on k8s 官网
https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-release-1.1/docs/try-flink-kubernetes-operator/quick-start/ 我的部署脚本和官网不一样,有些地方官网不够详细
部署k8s集群
注意,按照默认配置至少有两台wo…
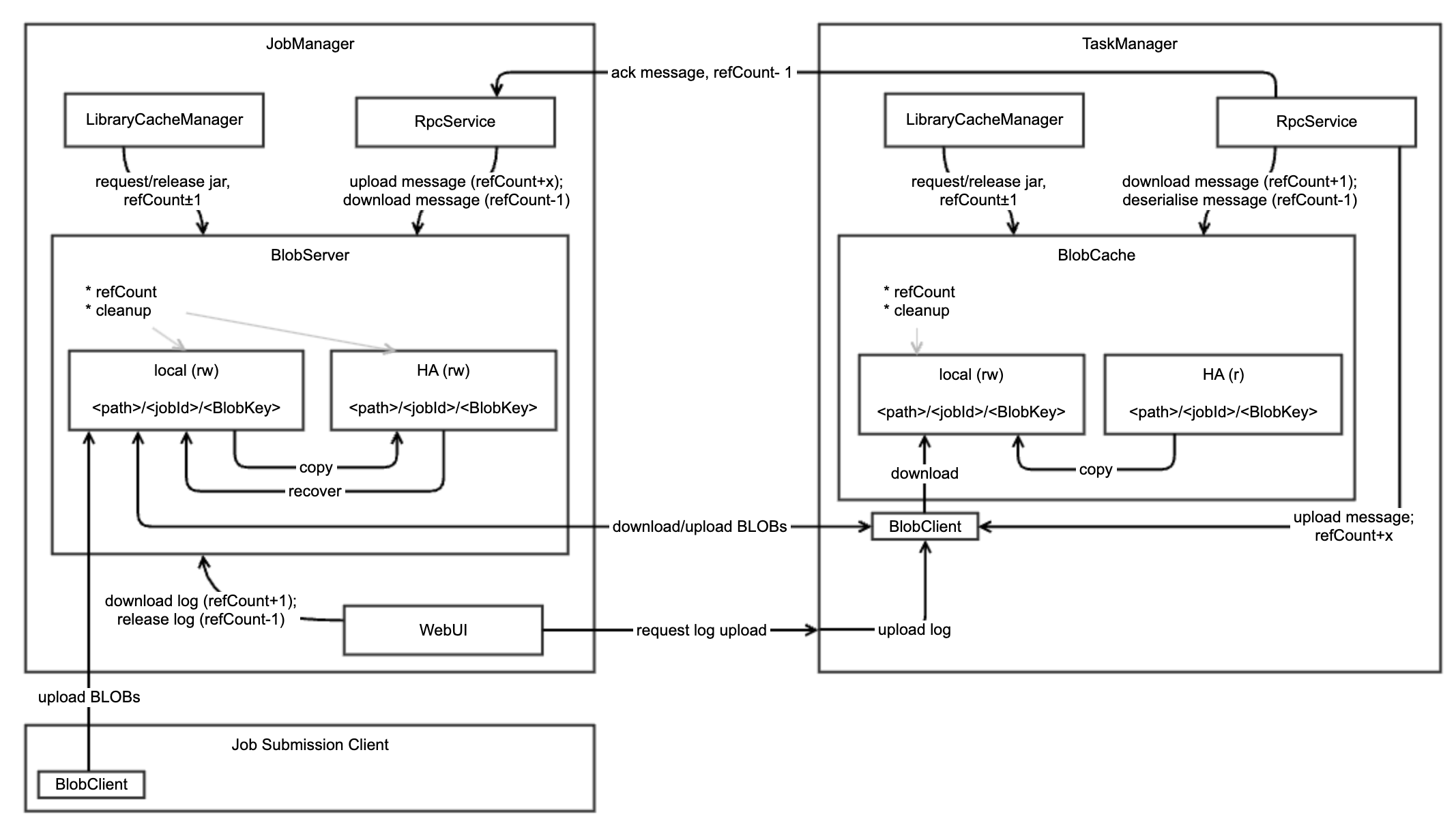
【Flink架构】关于FLink BLOB的组织架构:FLIP-19: Improved BLOB storage architecture:官网解读
文章目录 一. BlobServer架构1.BlobClient2. BlobServer3. BlobCache4. LibraryCacheManager 二、BLOB的生命周期1. 分阶段清理2. BlobCache的生命周期3. BlobServer 三、文件上下载流程1. BlobCache 下载2. BlobServer 上传3. BlobServer 下载 四. Flink中支持的BLOB文件类型1…

使用Flink实现Kafka到MySQL的数据流转换:一个基于Flink的实践指南
使用Flink实现Kafka到MySQL的数据流转换
在现代数据处理架构中,Kafka和MySQL是两种非常流行的技术。Kafka作为一个高吞吐量的分布式消息系统,常用于构建实时数据流管道。而MySQL则是广泛使用的关系型数据库,适用于存储和查询数据。在某些场景…
flink: 向clickhouse写数据
一、依赖
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0…
使用Flink实现MySQL到Kafka的数据流转换
使用Flink实现MySQL到Kafka的数据流转换
本篇博客将介绍如何使用Flink将数据从MySQL数据库实时传输到Kafka,这是一个常见的用例,适用于需要实时数据connector的场景。
环境准备
在开始之前,确保你的环境中已经安装了以下软件:…
Flink 反压问题处理
在分布式流处理系统中,反压(Backpressure)是一个常见的问题,它发生在下游处理速度跟不上上游数据发送速度时。Apache Flink 是一个高性能的流处理框架,它提供了多种机制来处理反压问题。下面是一步步分析问题原因&…
![[flink 实时流基础] 转换算子](https://img-blog.csdnimg.cn/img_convert/bab20ca044a79d3de50547bd843110a7.png)
[flink 实时流基础] 转换算子
flink学习笔记 数据源读入数据之后,我们就可以使用各种转换算子,将一个或多个DataStream转换为新的DataStream。 文章目录 基本转换算子(map/ filter/ flatMap)聚合算子(Aggregation)按键分区(…
![[flink 实时流基础] flink 源算子](https://img-blog.csdnimg.cn/img_convert/78c4568ddf6674593c21cd9c65d34c7f.png)
[flink 实时流基础] flink 源算子
学习笔记 Flink可以从各种来源获取数据,然后构建DataStream进行转换处理。一般将数据的输入来源称为数据源(data source),而读取数据的算子就是源算子(source operator)。所以,source就是我们整…
Mac m1 Flink的HelloWorld
首先在官方下载Downloads | Apache Flink
下载好压缩包后解压,得到Flink文件夹 进入:cd flink-1.19.0
ls 查看里面的文件: 执行启动集群 ./bin/start-cluster.sh 输出显示它已经成功地启动了集群,并且正在启动 standalonesessio…
![[flink 实时流基础] 输出算子(Sink)](https://img-blog.csdnimg.cn/img_convert/ff79c6132ee253c18634b47fa02f07fe.png)
[flink 实时流基础] 输出算子(Sink)
学习笔记 Flink作为数据处理框架,最终还是要把计算处理的结果写入外部存储,为外部应用提供支持。 文章目录 **连接到外部系统****输出到文件**输出到 Kafka输出到 mysql自定义 sink 连接到外部系统
Flink的DataStream API专门提供了向外部写入数据的方…
![[尚硅谷flink] 水位线](https://img-blog.csdnimg.cn/img_convert/c7b2b95049d62f67eb73906a0782c98b.png)
[尚硅谷flink] 水位线
在事件时间语义窗口下,标记当前时间之前的数据全部到达的一个逻辑标记时间戳。 文章目录 7.1 生成水位线的总体原则7.2 水位线生成策略7.3 flink 的内置水位线有序流乱序流 7.4 水位线的传递7.5 迟到数据的处理 7.1 生成水位线的总体原则
完美的水位线是“绝对正确…
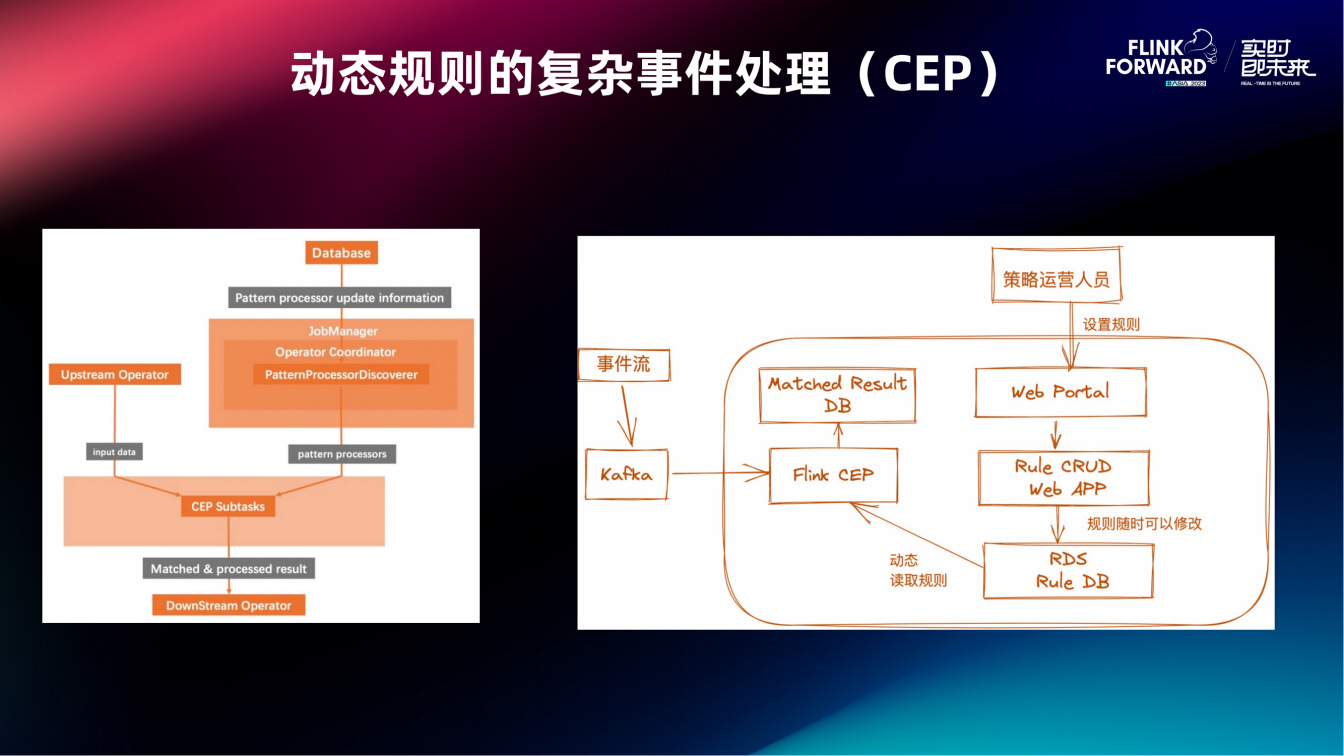
阿里云实时计算Flink的产品化思考与实践【上】
摘要:本文整理自阿里云高级产品专家黄鹏程和阿里云技术专家陈婧敏在 FFA 2023 平台建设专场中的分享。内容主要为以下五部分: 阿里云实时计算 Flink 简介产品化思考产品化实践SQL 产品化思考及实践展望 该主题由黄鹏程和陈婧敏共同完成,前半程…
flink: 从pulsar中读取数据
一、依赖
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0…

CDP7 下载安装 Flink Percel 包
下载链接:https://www.cloudera.com/downloads/cdf/csa-trial.html
点击后选择版本, 然后点击download now,会有一个协议,勾选即可,然后就有三个文件列表, 我这里是已经注册登录的状态,如果没…
![[flink 实时流基础系列]揭开flink的什么面纱基础一](https://img-blog.csdnimg.cn/img_convert/d0824649fa1fc96f28c0d14dcc09e360.png)
[flink 实时流基础系列]揭开flink的什么面纱基础一
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 文章目录 0. 处理无界和有界数据无界流有界流 1. Flink程序和数据流图2. 为什么一定要…
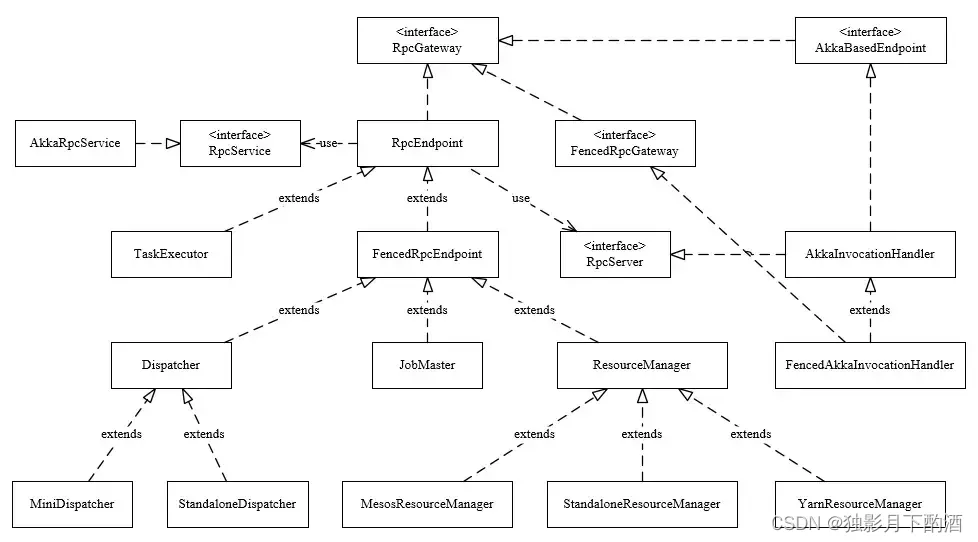
Flink RPC初探
1.RPC概述 RPC( Remote Procedure Call ) 的主要功能目标是让构建分布式计算(应用)更容易,在提供强大的远程调用能力时不损失本地调用的语义简洁性。 为实现该目标,RPC 框架需提供一种透明调用机制让使用者不必显式的区分本地调用和远程调用。 总而言之&…
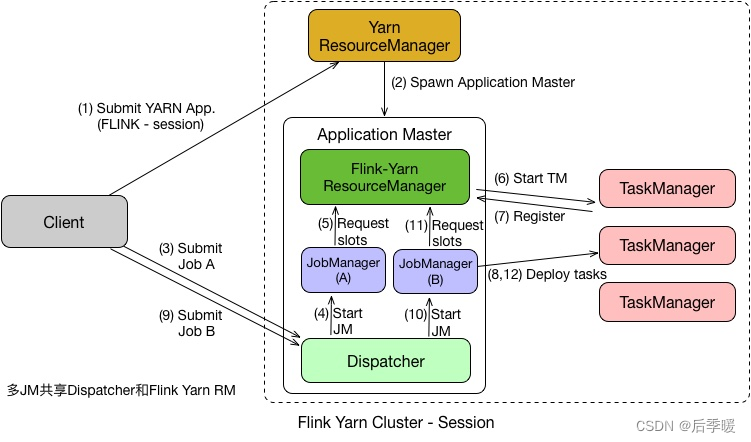
flink on yarn-per job源码解析、flink on k8s介绍
Flink 架构概览–JobManager JobManager的功能主要有: 将 JobGraph 转换成 Execution Graph,最终将 Execution Graph 拿来运行Scheduler 组件负责 Task 的调度Checkpoint Coordinator 组件负责协调整个任务的 Checkpoint,包括 Checkpoint 的开始和完成通过 Actor System 与 …
![[尚硅谷 flink] 基于时间的合流——双流联结(Join)](https://img-blog.csdnimg.cn/img_convert/fd3ef199f979f32951d09d309c95dda1.png)
[尚硅谷 flink] 基于时间的合流——双流联结(Join)
文章目录 8.1 窗口联结(Window Join)8.2 **间隔联结(Interval Join)** 8.1 窗口联结(Window Join)
Flink为基于一段时间的双流合并专门提供了一个窗口联结算子,可以定义时间窗口,并…